|
7210| 6
|
带你走进被Google四亿美金收购的深度学习公司DeepMind |
 Google对DeepMind的收购似乎开了个好头,相信在不久之后,互联网巨头们就不在满足于自己的研究室和技术迭代,而是会开始越来越亲睐收购这些机器学习相关的商业服务创业公司。 今年年初Google四亿美金对DeepMind的收购为深度学习和人工智能领域的研究起到了很好的推动作用,而如此巨额的收购背后DeepMind的相关介绍却很少,其官网也仅仅是一个单调的页面。遍寻网络之后终于在DeepMind少之又少的资料中找到一篇去年十二月份发表的一篇论文《通过深度学习玩雅达利游戏》,雅达利拥有大家所熟知的太空侵略者、打砖块、吃豆人等著名电视游戏。在这里,来自塔尔图大学计算机科学研究所的研究员将为您详细说明这篇论文中所描述的深度学习。 这篇论文描述了一个基于屏幕图像和获奖信号(游戏分数的增加或减少)通过选择上下左右等动作来学习玩几款老得电视游戏的简单系统。
最初,在开始训练之前,这个程序对这款游戏一点也不知道:它不知道游戏的目标,是一直保持存活,还是杀掉些什么或者是破解一个谜题,它也不按下按键后的后果,也就是说,它看不到游戏中的任何物体。通过不断的试错,这个深度学习系统逐步的学习应该如何动作才能得到一个分数。还需要注意的是,这套系统面对所有不同类型的游戏均使用的是同一套架构,而不是由程序员根据每种游戏来设置有多少种可能的动作,比如前、后、左、右、开火(空格)等。
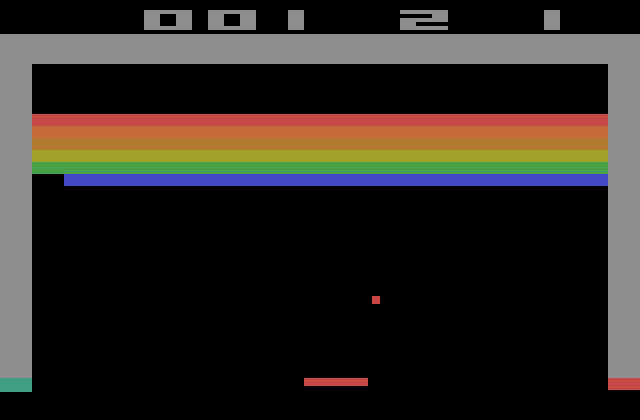
这项报告的结果显示,这套系统可以处理几种游戏,并且比人类玩家玩得要好。这结果可以视为在人工一般智能(artificial general intelligence,简称 AGI)迈出了非常出色的一步。下面就为您展示这个实现的详细细节。 任务 这张图片显示的是最简单的一款游戏,打砖块,当系统看到游戏屏幕时,开始分析然后选择一个行动,执行后系统告知分数是否增加、减少或没有改变。基于这些信息,在完成大量的尝试之后,这套系统学会了如何提高游戏的分数。
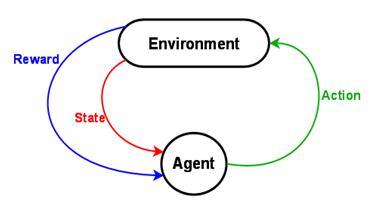
在机器学习中一个非常常见的任务是:根据对象的信息判定它属于哪个类别。在这里DeepMind所面临的就是根据游戏当前状态决定执行哪个动作。机器学习算法是从大量的例子中学习得来:给定大量示例和对应的分类,算法计算出对象的哪些特点对于识别分类是非常有帮助的。这样,该算法得出一个提高正确率的模型。此模型可以用于预测未知对象的分类。 人工神经网络(ANN)是机器学习算法其中之一。它是受人类大脑结构的启发。该网络中有大量的如同人类大脑中由轴突、树突和突触彼此连接的神经元。对于每一个神经元,我们必须指定神经元在某个特定情况下才能向前传输信号。通过改变连接之间的强度就可以让这个网络实现计算。现代神经网络的架构通常包括:
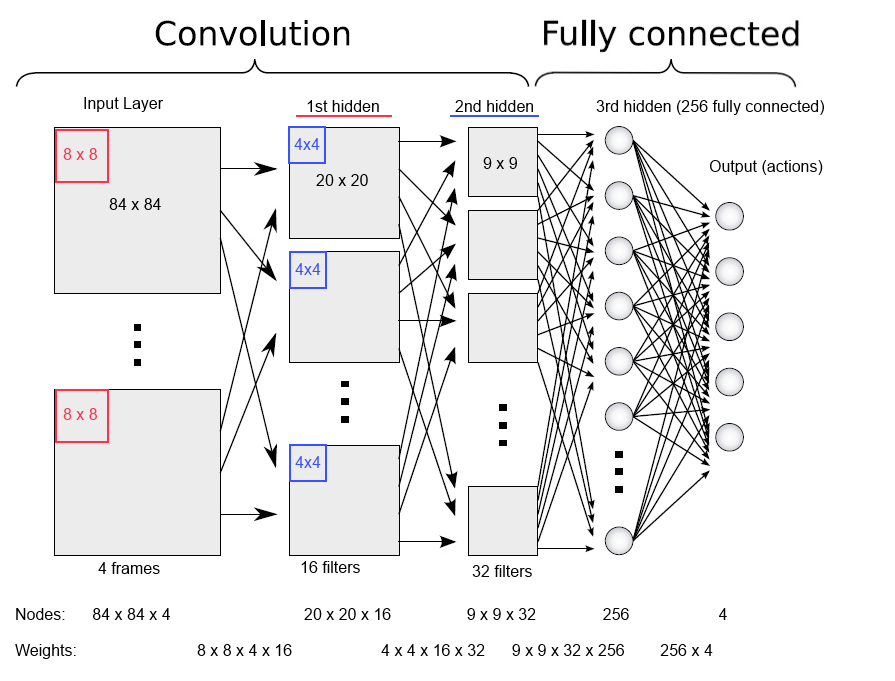
完成学习之后,我们可以添加一些新对象到网络中,并查看输出层在每个类别的分数。 DeepMind 在这个系统中,神经网络用于在当前游戏状态下为每个可能的动作赋予一个预期回报。该网络可以回答诸如“现在这样行动怎么样呢?”的问题。网络中在任意时间节点的输入都包含了游戏最新的四个场景,输入系统的并不是只有最后一个位置,而是游戏进行中最新的信息。然后这个输入通过神经元三个连续的隐藏层到达神经网络的输出层。
输出层中对应每个可能的动作都有一个节点,代表预期汇报的节点的激活则意味着最高的预期汇报被选中执行了。但是,这网络又是如何计算以一个良好和正确的方法计算预期的分数呢? 学习的过程定义这套网络的结构之后只有一件事你仍然可以改变:连接的强度。学习过程仅仅是一定程度上改变网络中所有训练样本带来奖励的动作所占的权重。 这是一个随着时间推移最大限度获得回报的优化问题。这个问题可以通过结合梯度下降与强化学习相关的简单想法:此网络试图最大化时不仅仅是最近的回报,也有未来行动的累积回报。这可以通过使用当前的神经网络估计下一个屏幕中的预期值来实现。换一种方式,传统上你会用“收到的回报-估计的回报”作为梯度下降的误差信号,但是在这种情况下,我们还需要考虑到下一个画面的奖励估计。 总结总结我们看到的所有片段,最后看到的样子:
该结果可以看作是从传统的机器学习迈向人工一般智能的一小步。这可能是非常小的一步,也许会有人说,系统并不“知道”或“理解”它在做的事情,但是DeepMind系统的学习能力将远超它之前的任何一代。并且可以解决不需要程序员具体提示的问题范围将宽很多。 复制DeepMind并开放源码目前我们正在尝试将这个项目复制出来,并开放给科学界以便进一步研究使用,该项目可以在Github下载源代码。 对神经网络和机器学习可以查看以下几个信息源 转自:http://oszine.com/deepmind/ |
 活跃会员
活跃会员



 沪公网安备31011502402448
沪公网安备31011502402448© 2013-2026 Comsenz Inc. Powered by Discuz! X3.4 Licensed

 置顶卡
置顶卡 变色卡
变色卡 千斤顶
千斤顶






