|
4378| 0
|
[OpenVINO™入门] 英特尔® OpenVINOTM 工具套件 2020 分 发版发行说明 |
|
英特尔® OpenVINO™工具套件分发版: 英特尔® OpenVINO™工具套件2020分发版发行说明作者:Andrey Z.,2020年2月5日发布 注:如欲查看2019版发行说明,请参见英特尔® OpenVINO™工具套件2019分发版发行说明。 简介英特尔® OpenVINO™工具套件分发版是一款全面的工具套件,支持快速开发可模拟人类视觉的应用和解决方案。该工具套件基于卷积神经网络(CNN),可在英特尔®硬件中扩展CV工作负载,实现卓越性能。它通过从边缘到云端部署的高性能AI和深度学习推理来加速应用。 英特尔® OpenVINO™工具套件分发版:
版本1中的全新和变更内容要点综述
相比v.2019 R3.1的向后不兼容变更
模型优化器常见变更
ONNX*
TensorFlow*
MXNet*
Kaldi*
推理引擎常见变更
I420格式进行推理。推理引擎会在推理之前将数据自动转换为BGR。
CPU插件
GPU插件
MYRIAD插件
HDDL插件
GNA插件
FPGA插件
模型优化器和nGraph集成至推理引擎
训练后优化工具该工具的主要目标:
精度执行)
该工具支持针对各类IA硬件的OpenVINO中间表示(IR)模型的量化:
工具的获取地址为
深度学习工作台
OpenCV*
示例和教程
工具
Open Models Zoo
模型下载器工具配置文件放置在每个模型的单独文件夹中,以改进用户体验并简化分布流程(在同时开发/合并多个模型时,减少合并冲突)。该列表已扩展为支持以下Caffe2*、TensorFlow*、MXNet*和PyTorch*格式的公共模型:
预览功能术语预览功能是为了获得早期开发人员反馈而推出的功能。我们鼓励大家提出与预览功能相关的评论 、问题和建议 ,并通过https://software.intel.com/en-us/forums/computer-vision提交给论坛。 预览功能的关键属性:
注:预览功能将来可能会更改。未来版本中可能会删除或更改。预览功能更改不需要弃用和删除过程。不建议在生产代码库中使用预览功能。 已知问题
此版本中包含英特尔® OpenVINO™工具套件分发版提供以下版本:
在何处下载此版本https://software.intel.com/en-us/OpenVINO-toolkit/choose-download 系统要求英特尔® CPU处理器硬件
英特尔®处理器显卡(GEN显卡)硬件
注: 英特尔® OpenVINO™工具套件分发版中不包含安装此硬件所需的驱动程序 注: 英特尔®至强®处理器需采用支持处理器显卡的芯片组。所有处理器都不包含处理器显卡。如欲了解有关您的处理器的信息,请访问https://ark.intel.com/。 操作系统
英特尔®高斯神经加速器操作系统
英特尔 ® FPGA处理器注: 仅适用于支持FPGA、面向Linux的英特尔® OpenVINO™工具套件分发版 硬件
操作系统
英特尔 ® FPGA处理器装有相应操作系统的硬件
法律信息您不得使用或方便他人使用本文档对此处描述的相关英特尔产品作任何侵权或其他法律分析。您同意就此后起草的任何专利权利(包括此处披露的主题)授予英特尔非排他性的免版税许可。 本文件不构成对任何知识产权的授权,包括明示的、暗示的,也无论是基于禁止反言的原则或其他。 此处提供的所有信息如有更改,恕不另行通知。请联系您的英特尔代表,了解最新的英特尔产品规格和路线图。 所述产品可能包含设计缺陷或错误(即勘误表),这可能会使产品与已发布的技术规格有所偏差。英特尔提供最新的勘误表备索。 英特尔技术的特性和优势取决于系统配置,并需要借助兼容的硬件、软件或服务来实现。如欲了解更多信息,请访问http://www.intel.cn/,或联系OEM或零售商。任何计算机系统都无法提供绝对的安全性。 英特尔、Arria、酷睿、Movidius、至强、OpenVINO和英特尔标识是英特尔公司在美国和/或其他国家的商标。 OpenCL和OpenCL标识是Apple Inc.的商标,经Khronos许可授权使用。 *其他的名称和品牌可能是其他所有者的资产。 ©2020英特尔公司版权所有。保留所有权利。 前往了解DFRobot行业AI开发者大赛 |



 沪公网安备31011502402448
沪公网安备31011502402448© 2013-2026 Comsenz Inc. Powered by Discuz! X3.4 Licensed


 支持OpenModelZoo上的新
支持OpenModelZoo上的新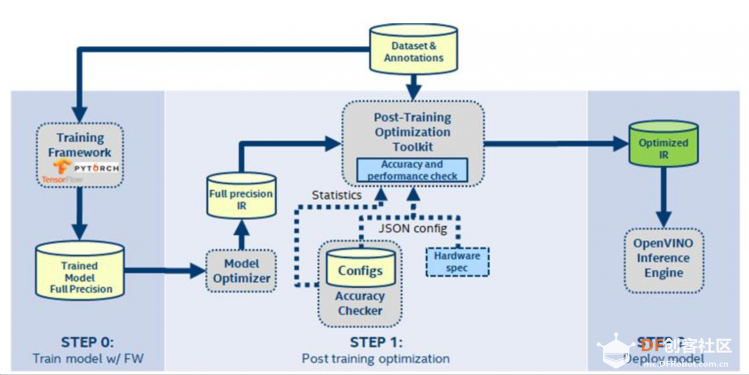
 这些功能有新教程:
这些功能有新教程:
 置顶卡
置顶卡 变色卡
变色卡 千斤顶
千斤顶
 活跃会员
活跃会员
 宣传大使
宣传大使
 牛X认证
牛X认证
 蘑菇人
蘑菇人
 蘑菇老人
蘑菇老人
 荣誉教师
荣誉教师
 编辑选择奖
编辑选择奖
 编辑选择奖
编辑选择奖
 物联网挑战
物联网挑战
 编辑选择奖
编辑选择奖
 ARD DAY
ARD DAY
 ARD DAY
ARD DAY
 摸鱼团员
摸鱼团员






