前言
自动语音识别技术(Automatic Speech Recognition)是一种将人的语音转换为文本的技术。简称:ASR。Maixduino 开发板集成了一颗MEMS麦克风,maixpy支持两种语音识别模式:isolated_word(孤立词 MFCC 模块) 与 maix_asr(语音识别模块)!那么我们就用前者!来做一个语音识别的小案例:语音控制开关灯
硬件清单
| 序号 |
硬件名称 |
数量 |
| 1 |
Maixduino |
1 |
| 2 |
扩展板 |
1 |
| 3 |
LED模块 |
1 |
电路连接
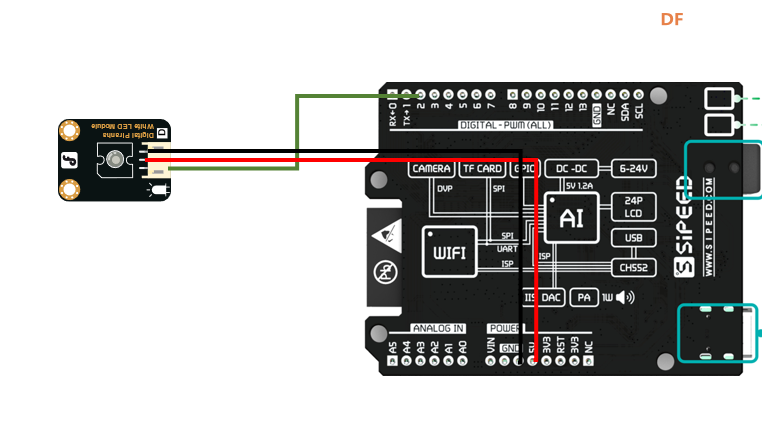
准备阶段
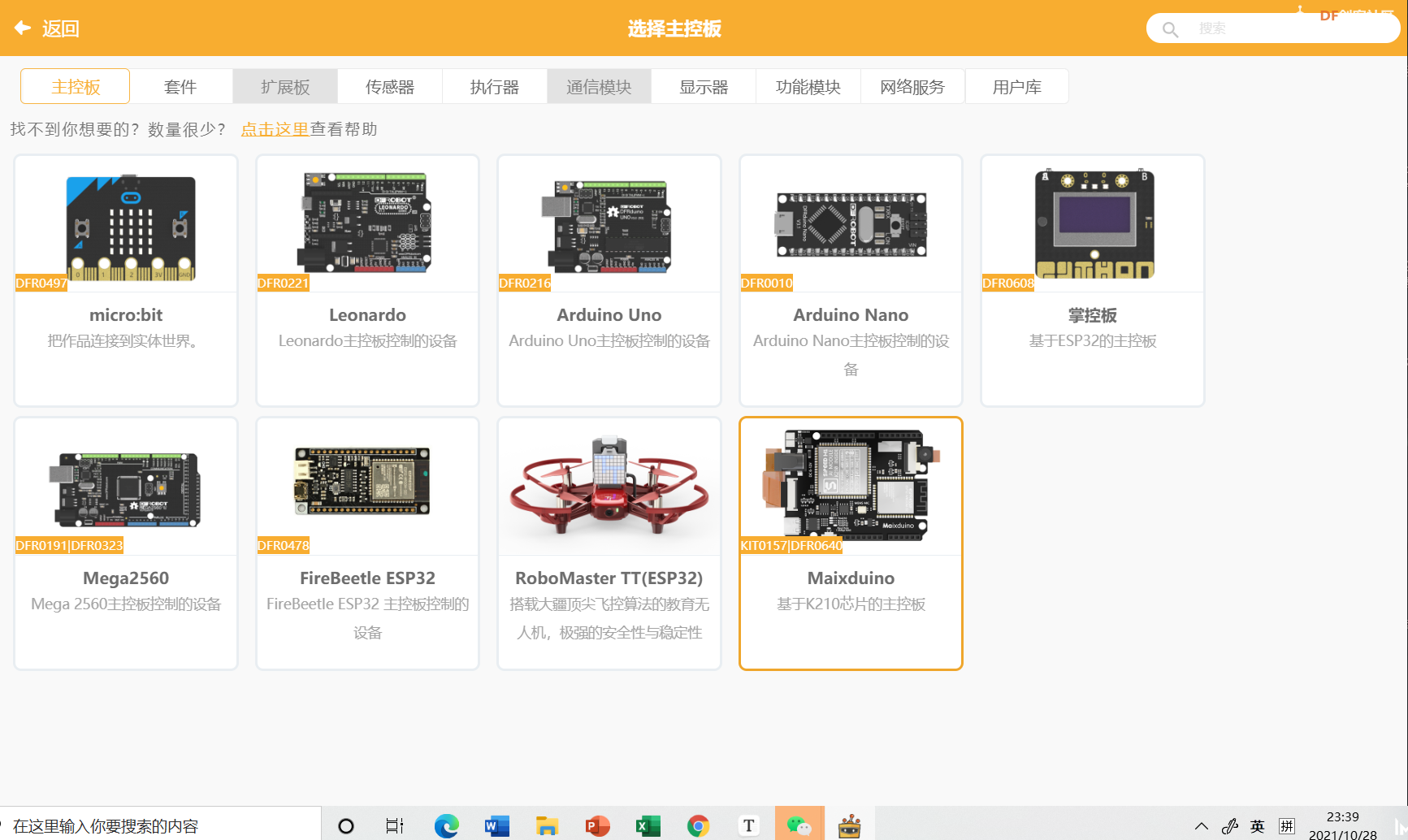
1、 打开mind+ ,在上传模块下--主控选择Maixduino
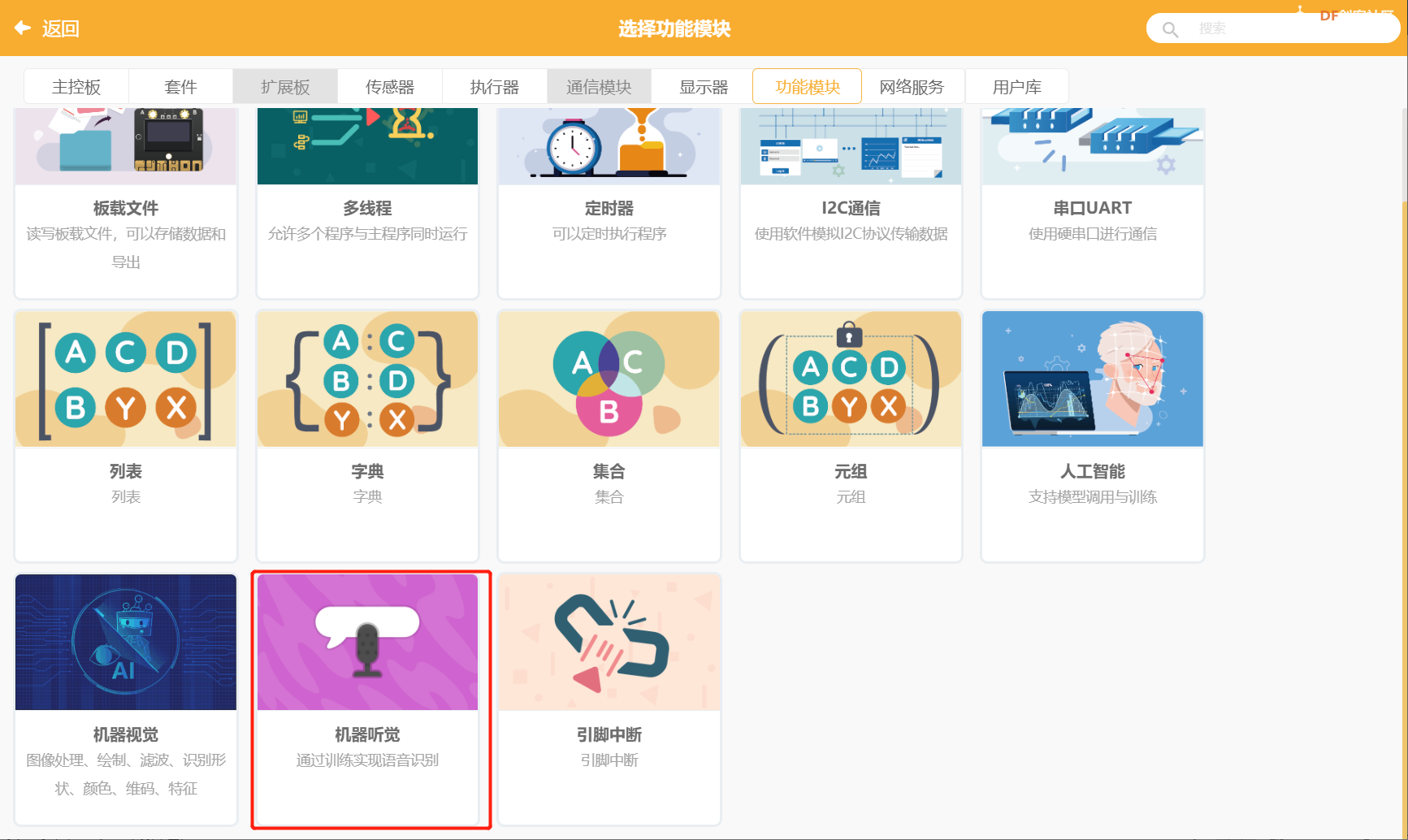
2、功能模块下--选择机器听觉
程序编写
一、进行语音训练,保存模型到flash
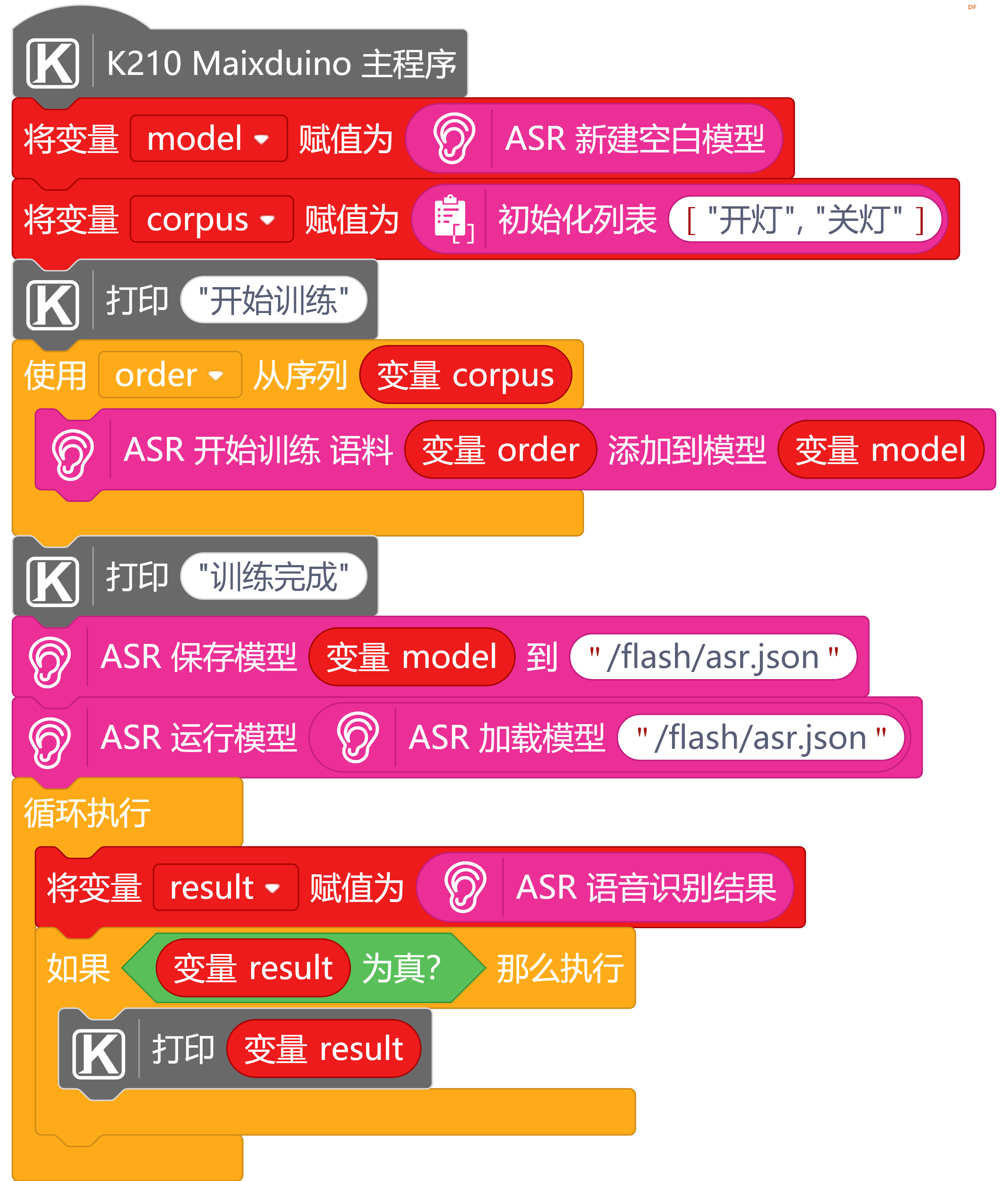
# MindPlus
# maixduino
from ASR import asr
model = asr.newModel()
corpus = ["开灯", "关灯"]
print("开始训练")
for order in corpus:
asr.training(order, model)
print("训练完成")
asr.save(model, "/flash/asr.json")
asr.run(asr.load("/flash/asr.json"))
while True:
result = asr.recognize()
if bool(result):
print(result)
训练结果

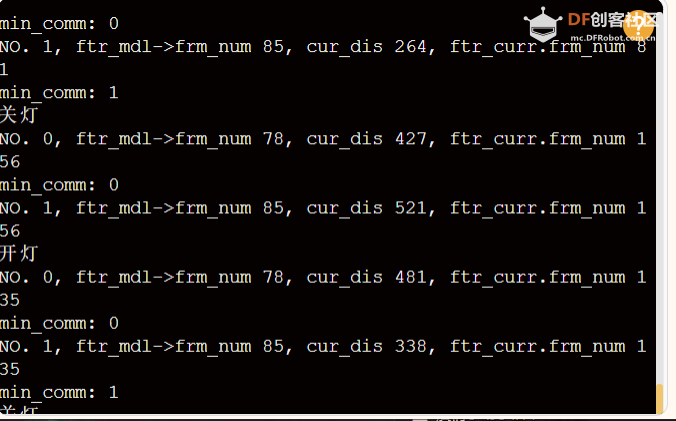
上传好程序后,我们只需要根据控制台提示的指令进行语料的训练。训练完成后,我们需要测试一下:当我们说开灯,串口会打印出开灯的,当我们说关灯,串口会打印出关灯(PS:目前对噪声这块还木有好的处理办法,导致发出声音会被识别到。)
二、加载训练模型,进行语音识别
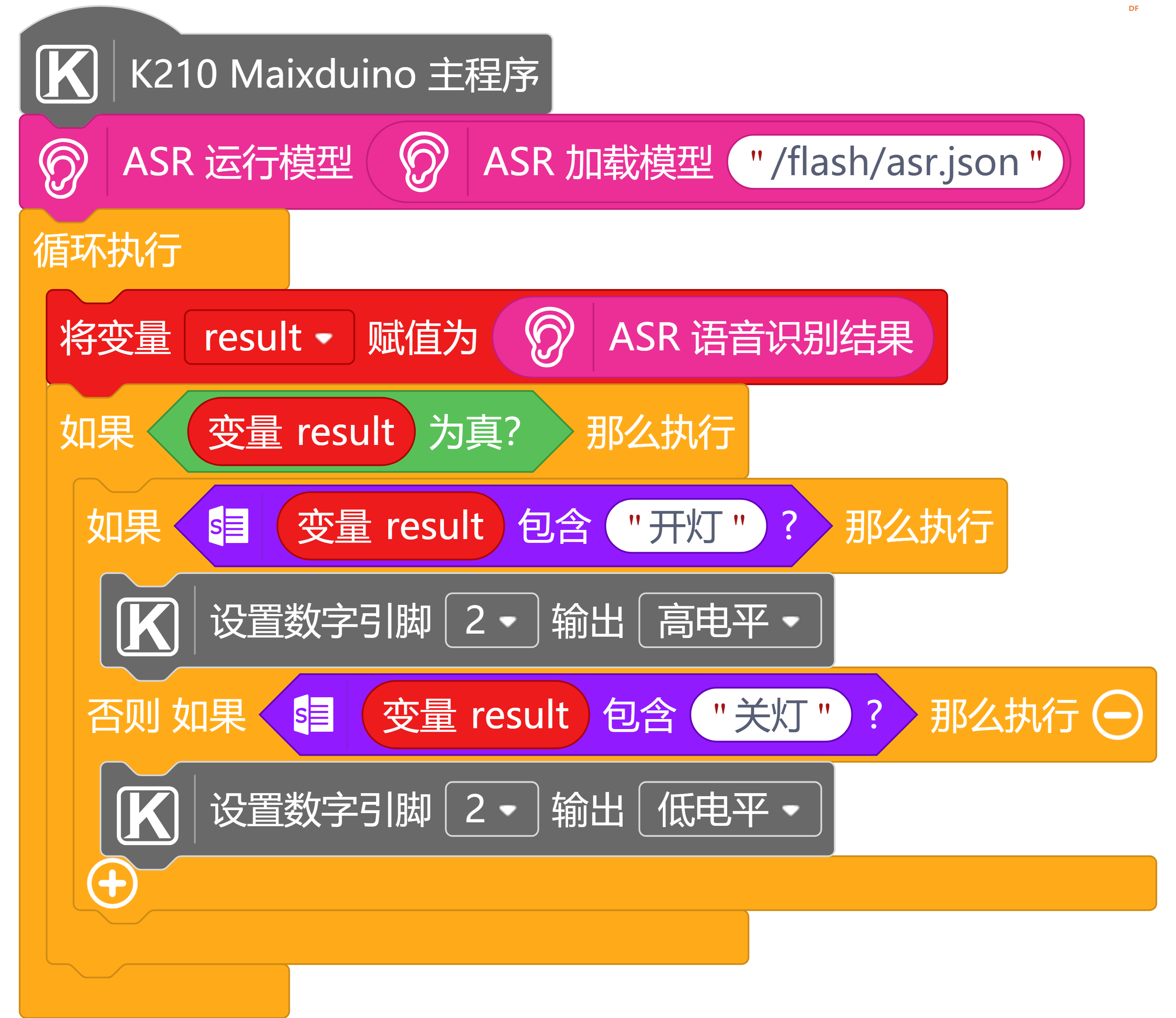
# MindPlus
# maixduino
from board import board_info
from ASR import asr
from pin import Pin
asr.run(asr.load("/flash/asr.json"))
while True:
result = asr.recognize()
if bool(result):
if (result.find("开灯")!=-1):
Pin.digital_write(board_info.PIN2, 1)
elif (result.find("关灯")!=-1):
Pin.digital_write(board_info.PIN2, 1)
实验现象

注:
该使用识别功能主要用到的是:Maixpy API中的isolated_world(孤立词 MFCC 模块)API文档详细 isolated_word(孤立词 MFCC 模块)
上文中用到的ASR.py是由df团队编写(感谢李工提供),具体代码如下:
import time
import json
from Maix import GPIO, I2S
from fpioa_manager import fm
from speech_recognizer import isolated_word
class ASR:
def __init__(self):
self.asr = None
self.i2s = None
self.model = None
def __start(self, size):
if self.asr:
del self.asr
if self.i2s:
del self.i2s
try:
fm.register(20,fm.fpioa.I2S0_IN_D0, force=True)
fm.register(18,fm.fpioa.I2S0_SCLK, force=True)
fm.register(19,fm.fpioa.I2S0_WS, force=True)
self.i2s = I2S(I2S.DEVICE_0)
self.i2s.channel_config(self.i2s.CHANNEL_0, self.i2s.RECEIVER, align_mode=I2S.STANDARD_MODE)
self.i2s.set_sample_rate(16000)
self.asr = isolated_word(dmac=2, i2s=I2S.DEVICE_0, size=size)
self.asr.set_threshold(0, 0, 15000)
return True
except:
return False
def newModel(self):
return []
def training(self, corpus, model):
if not corpus or not self.__start(1) or not self.asr:
return
rc=1
co=0
while True:
time.sleep_ms(100)
if self.asr.Done == self.asr.record(0):
model.append({'name': corpus, 'data': self.asr.get(0)})
print("complete")
break
if self.asr.Speak == self.asr.state():
if rc != -1:
print()
print("speak: " + str(corpus))
rc = -1
else:
if co%2==0:
print("\rready" + "."*rc + " "*(3-rc), end='')
rc += 1
if rc > 3:
rc = 1
co += 1
def run(self, model):
if not model or len(model)<1 or not self.__start(len(model)) or not self.asr:
return None
for i in range(len(model)):
self.asr.set(i, model[i]['data'])
self.model = model
def recognize(self):
if not self.model or len(self.model)<1 or not self.asr:
return None
for i in range(20):
if self.asr.Done == self.asr.recognize():
result = self.asr.result()
if result:
return self.model[result[0]]['name']
return None
def save(self, model, path):
if not model or not path:
return False
try:
for i in range(len(model)):
model[i]['data'] = list(model[i]['data'])
model[i]['data'][1] = list(model[i]['data'][1])
with open(path, "wb") as f:
json.dump(model,f)
f.close()
return True
except:
return False
def load(self, path):
if not path:
return []
try:
with open(path, "rb") as f:
model = json.load(f)
for i in range(len(model)):
model[i]['data'][1] = bytes(model[i]['data'][1])
model[i]['data'] = tuple(model[i]['data'])
f.close()
return model
except:
return []
asr = ASR()
总结
通过上面的列子,我们就可以用Maixduino 进行机器听觉训练,进而去完成某一指令相应的动作!如果我们需要去做一个语音识别垃圾分类助手该怎么去实现呢?请同学们动动你脑筋尝试着去实现!更多教程,欢迎关注个人博客:www.hockel.club




 沪公网安备31011502402448
沪公网安备31011502402448
 置顶卡
置顶卡 变色卡
变色卡 千斤顶
千斤顶
 萌萌哒新人
萌萌哒新人
 活跃会员
活跃会员
 宣传大使
宣传大使
 编辑选择奖
编辑选择奖
 编辑选择奖
编辑选择奖






