本帖最后由 云天 于 2022-4-22 09:55 编辑
【项目背景】现在最火的领域是什么?人工智能。人工智能领域最热门的话题是什么?机器学习。什么是机器学习?机器学习就是在不直接编程的情况下训练电脑进行学习,是创建类似于人脑的人工神经网络的最佳方式。是不是一看到定义就头疼?没关系,谷歌开发了一款会学习的机器,称为Teachable Machine,不但能帮助我们理解什么是机器学习,而且还允许我们亲自去教机器学习。但在国内想访问谷歌网站是有困难的,所以我找了一个国内平台,“英荔AI训练平台”https://train.aimaker.space/train。但前一段时间也用不了,这一段时间又能使用了。(本人个人猜测,国内这个平台,依然借用的是谷歌Teachable Machine)
【项目设计】
将使用Google Teachable Machine来训练我们的深度学习模型,并LattePanda上使用Mind+的Python模式来实现,当“主人”来到面前时,“小兔”的耳朵会高兴动起来,大家参考我的项目过程,肯定能制作出更多、更有趣的作品,让我们一起走近AI。
【训练模型】
1、图像分类
在这个平台你可以为姿势估计、图像分类或音频分类创建模型,因为我们的任务是图像分类,所以选择“图像项目(Image Project)”。
访问“图像分类”:https://train.aimaker.space/train/image/
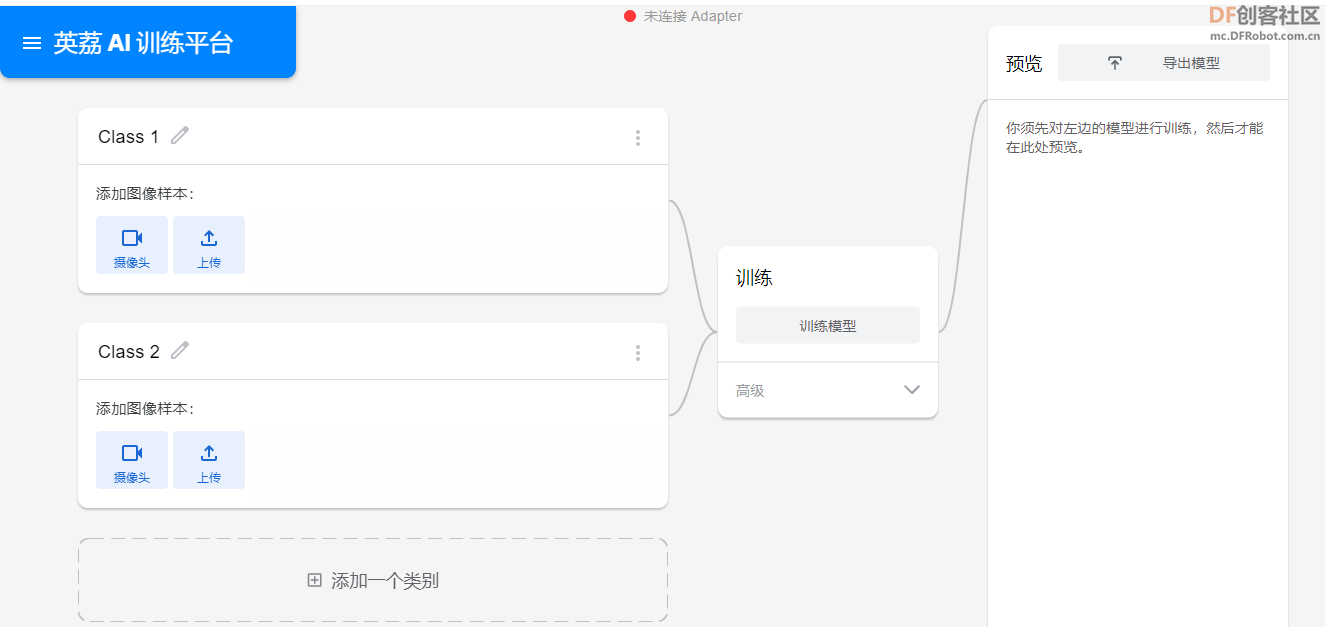
以上是我们项目的初始设置,类代表不同的分类类别。我们可以使用网络摄像头直接从网络浏览器记录样本(创建数据集),另外,我们也可以从本地机器或谷歌云端硬盘上传图片。
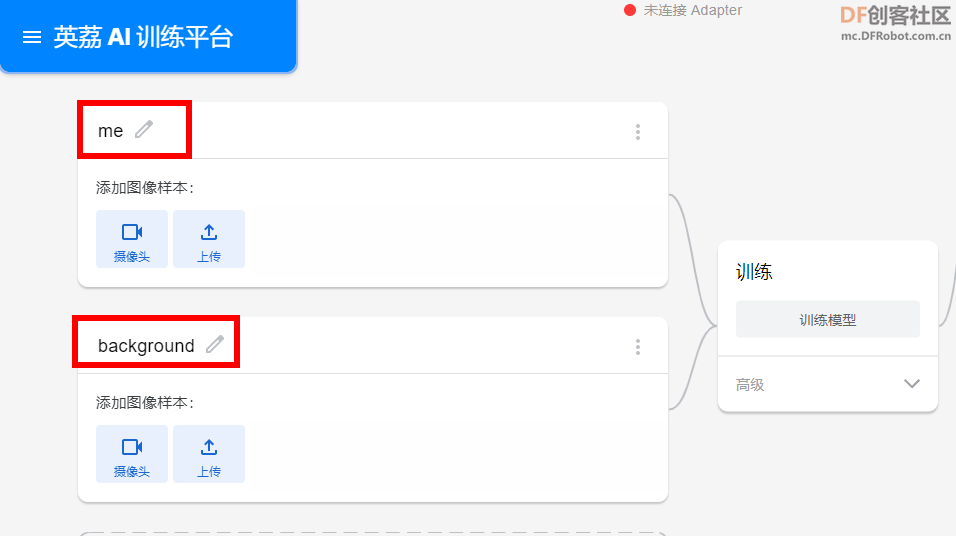
2、如下所示,创建2个类(me,background),“me”为自己的图像,“background”为环境背景图像。
3、采集图像样本
单击“ me”类中的“摄像头”按钮,从不同的距离和角度录制图片可以确保模型能够很好地概括,并且不会过拟合。
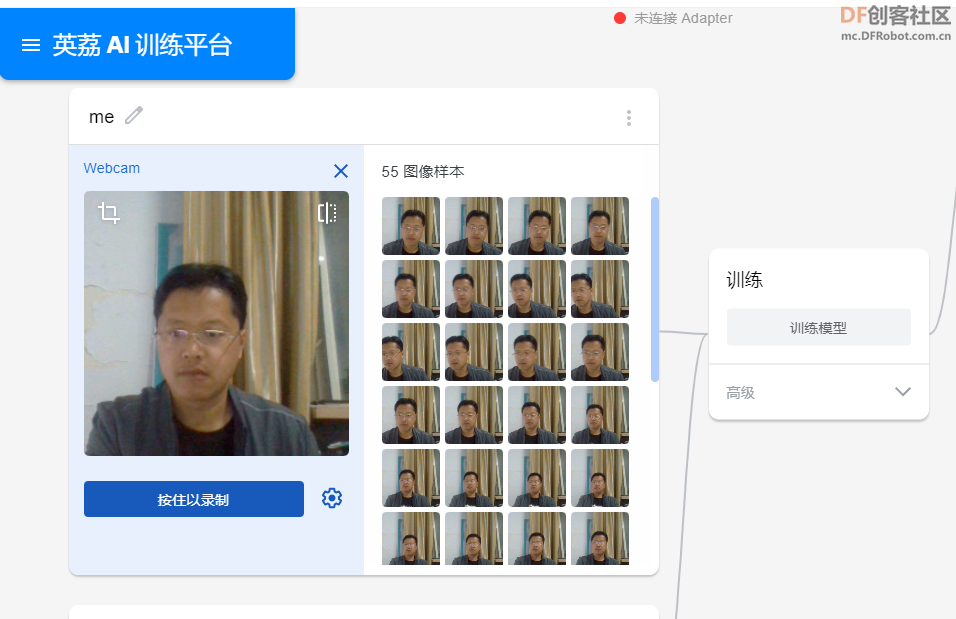
现在,点击“按住以录制”按钮并记录你的样本。
完成此操作后,可以从样本中选择单个图像,并删除或更改其标签(如果是错误录制的)。
对“background”类重复此过程(收集背景图像)。
注意:尝试为所有类提供大致相等数量的图像,这样模型就不会偏向于任何一个特定的类。
4、训练模型
单击“训练模型”按钮开始在刚刚收集的图像上训练模型!也可以单击“高级”部分下拉列表来更改超参数。
5、预览
训练完成后,你可以在浏览器上测试你的模型,以确定模型是否在所有可能的情况下都经过了充分训练,或者是否要添加更多图像。
 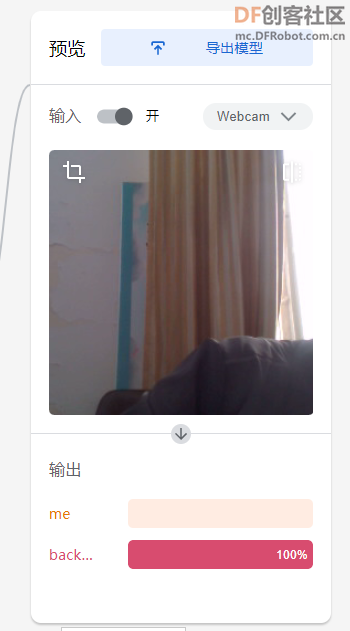
6、导出模型
可以点击顶部的“导出模型”按钮来导出模型,选择Tensorflow->Keras的模型类型。你还可以将模型转换为其他格式,如Tensorflow.js或Tensorflow Lite,具体取决于你的用例。单击“下载我的模型”并解压Zip文件以获取模型权重和标签。
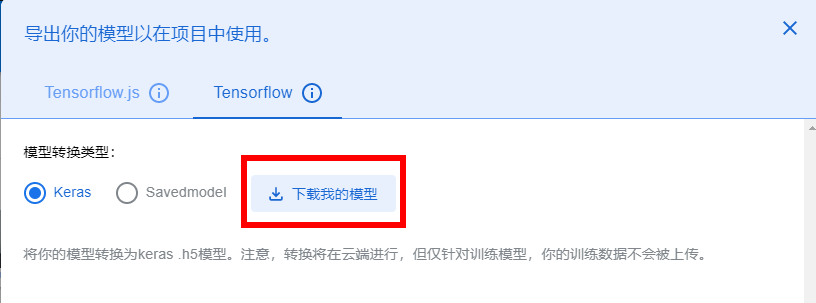
现在,模型已经准备好了。
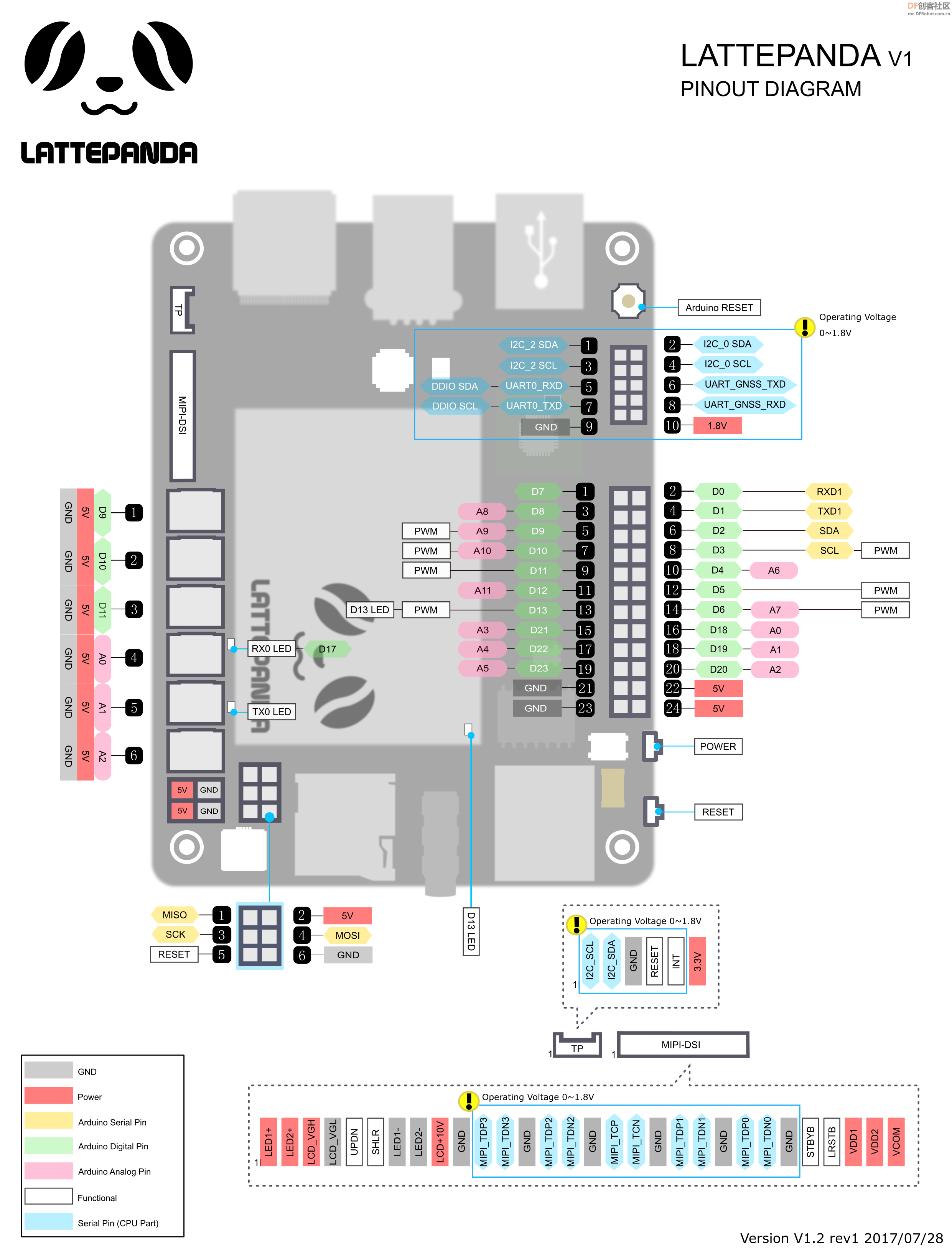
【硬件准备】
Lattepanda熊猫板+触摸屏+摄像头


再加上两个“舵机耳机”

【编写程序】
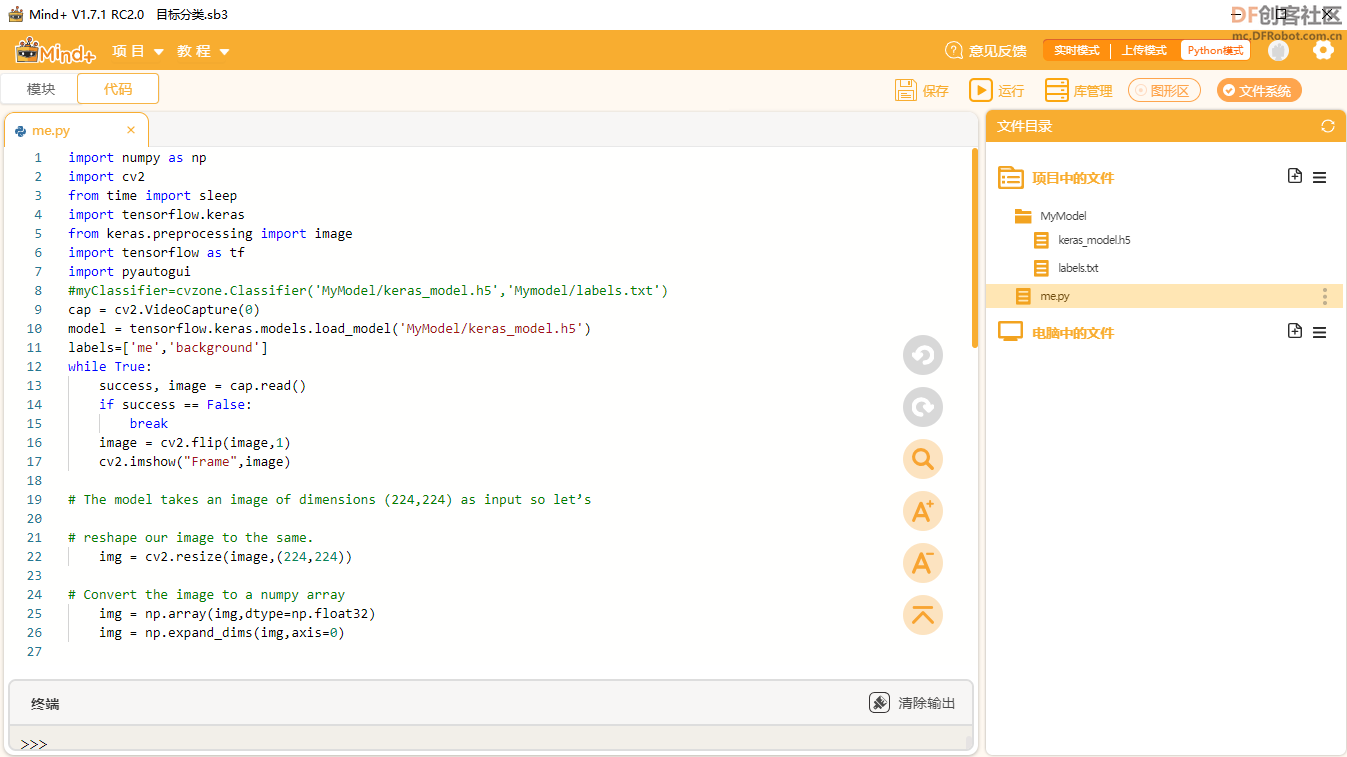
将下载的模型,解压到Lattepanda的Mind+Python模式下的工作目录下。
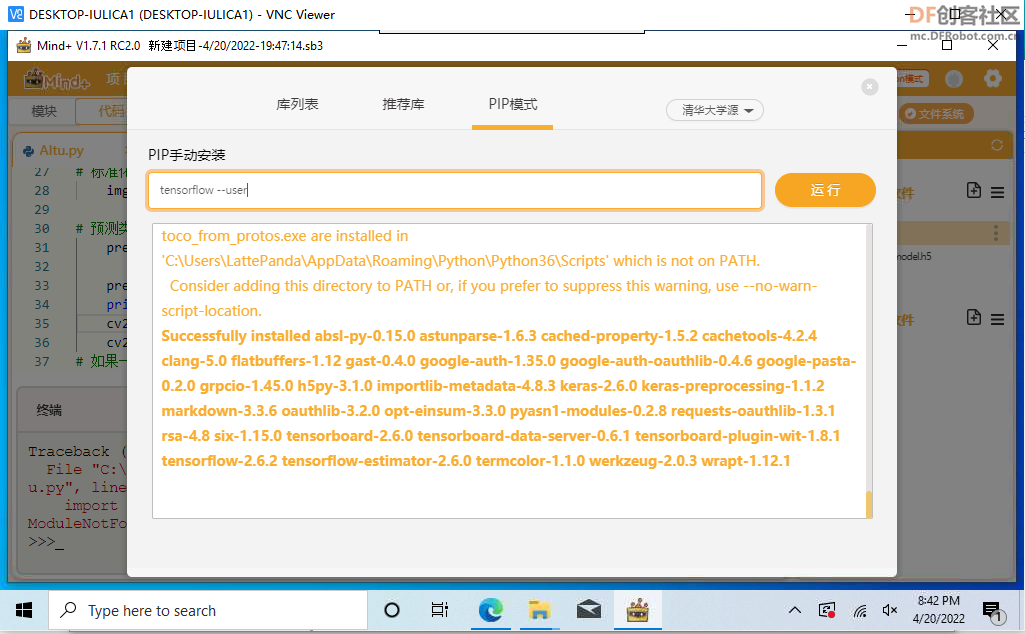
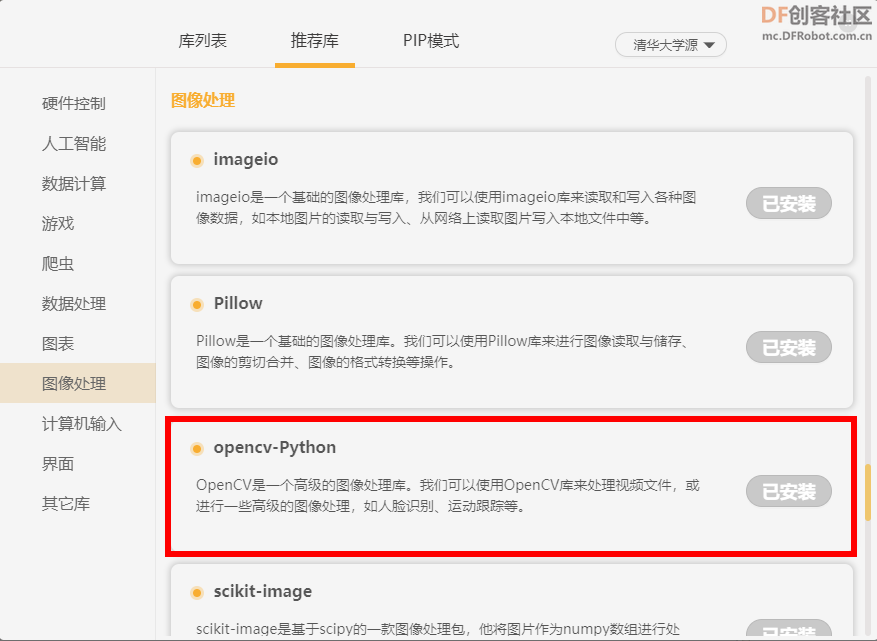
安装必要的库,tensorflow库,通过“库管理”——“PIP模式”手动安装。
OpenCV库,通过“库管理”——“推荐库”安装。
【测试程序】
测试代码:
-
- import numpy as np
- import cv2
- from time import sleep
- import tensorflow.keras
- from keras.preprocessing import image
- import tensorflow as tf
-
- cap = cv2.VideoCapture(0)
- model = tensorflow.keras.models.load_model('MyModel/keras_model.h5')
- labels=['me','background']
- font= cv2.FONT_HERSHEY_SIMPLEX
- while True:
- success, image = cap.read()
- if success == False:
- break
- image = cv2.flip(image,1)
-
-
- # 模型以尺寸(224)的图像作为输入
-
- img = cv2.resize(image,(224,224))
-
- # 将图像转换为numpy数组
- img = np.array(img,dtype=np.float32)
- img = np.expand_dims(img,axis=0)
-
- # 标准化输入图像
- img = img/255
-
- # 预测类
- prediction = model.predict(img)
-
- predicted_class = labels[np.argmax(prediction)]
- print(predicted_class)
- cv2.putText(image, predicted_class, (123,456), font, 2, (0,255,0), 3)
- cv2.imshow("Frame",image)
- # 如果一秒钟过去并按下“q”,关闭所有窗口
- if cv2.waitKey(1) & 0xFF == ord('q'):
- break
-
- # 释放所有打开的连接
- cap.release()
- cv2.destroyAllWindow()
-
测试效果:
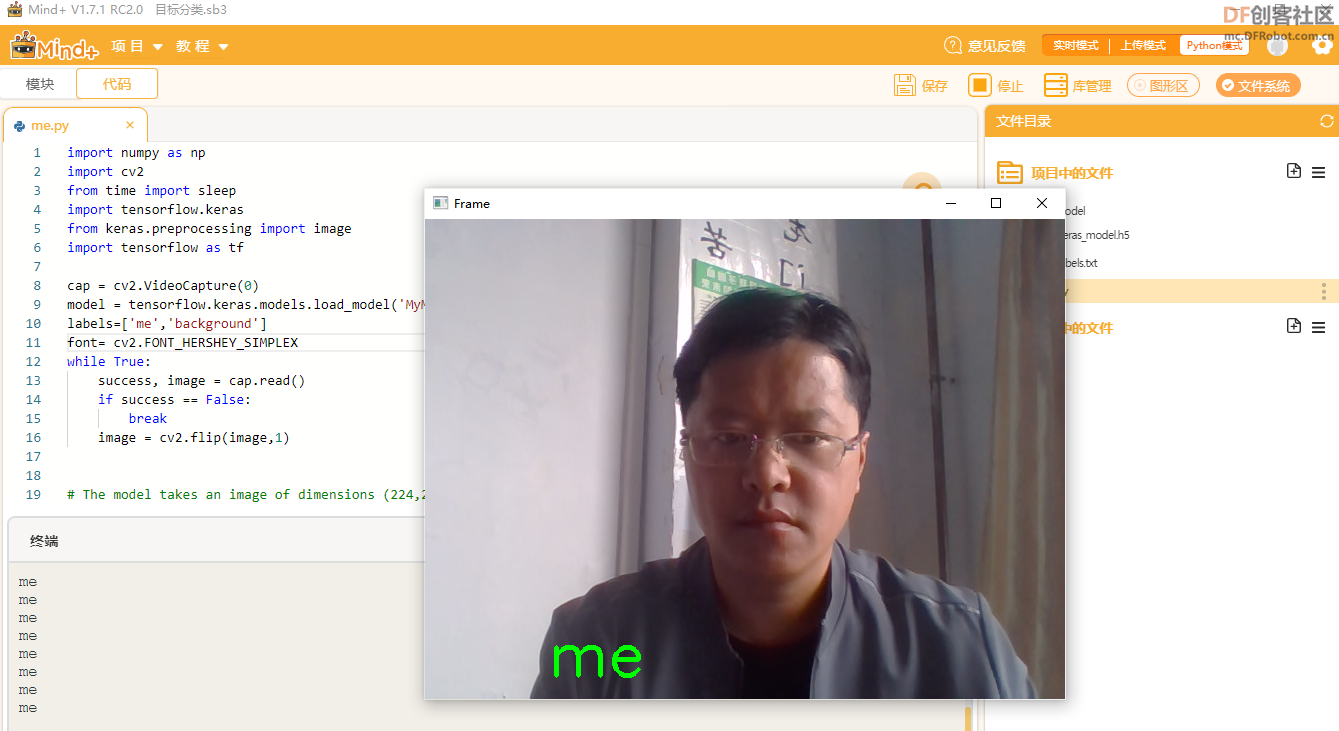
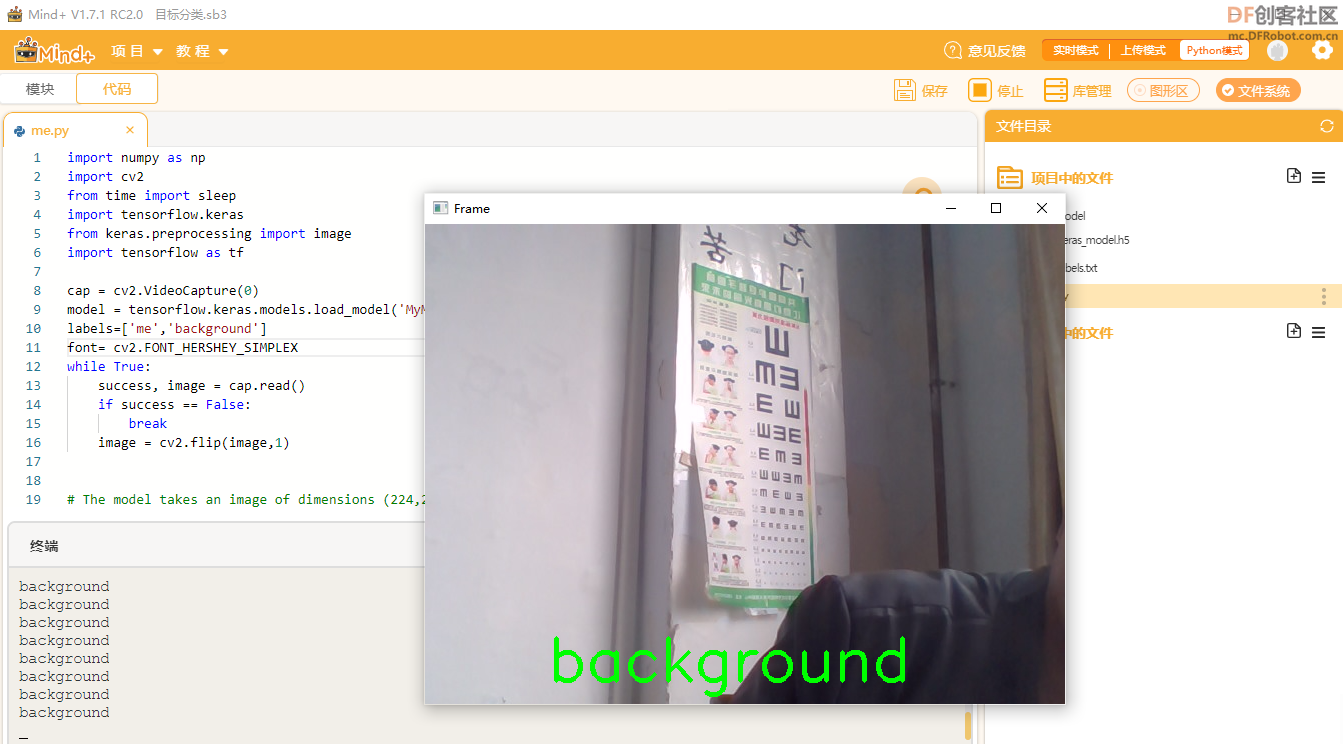 【测试舵机】 【测试舵机】
Mind+Python模式测试舵机
- import serial
- import time
- ser = serial.Serial('COM4', 115200, timeout=0)
- def send(val):
- data = bytes(val, 'UTF8')
- ser.write(data)
- time.sleep(2000)
- send('a')
- time.sleep(2000)
- send('b')
将Arduino程序提前下载到,Lattepanda集成的Leonardo板中,接收Mind+程序通过串口传来的指令,控制Arduino GPIO,驱动舵机。
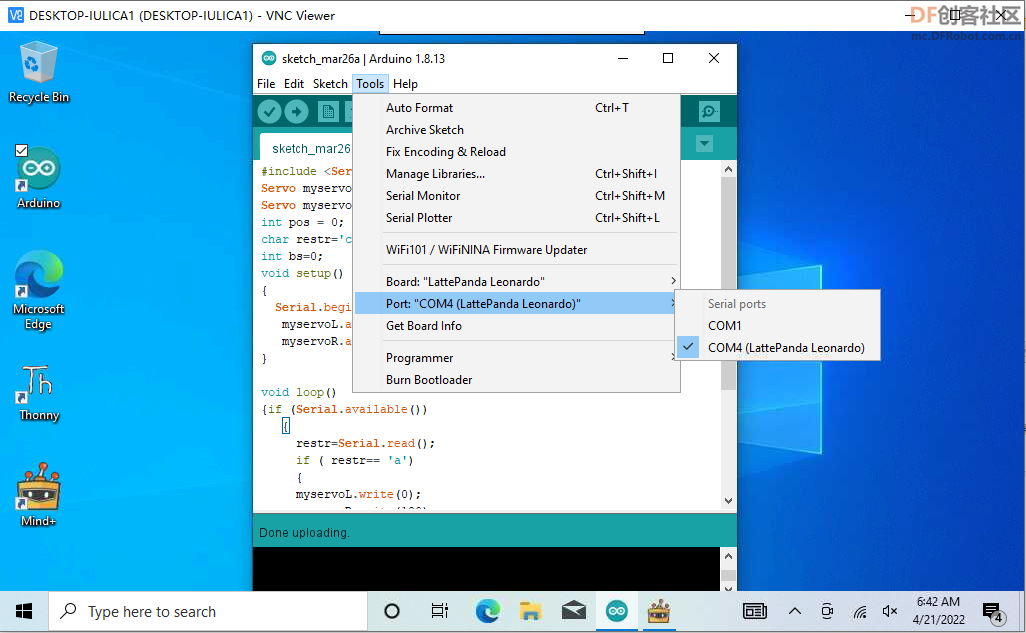
-
- #include <Servo.h>
- Servo myservoL;
- Servo myservoR;
- int pos = 0;
- char restr='c';
- int bs=0;
- void setup()
- {
- Serial.begin(115200);
- myservoL.attach(9);
- myservoR.attach(10);
- }
-
- void loop()
- {if (Serial.available())
- {
- restr=Serial.read();
- if ( restr== 'a')
- {
- myservoL.write(0);
- myservoR.write(180);
- }
- if ( restr== 'b')
- {
-
- myservoL.write(180);
- myservoR.write(0);
- }
- }
- }
【完整程序】
- import numpy as np
- import cv2
- from time import sleep
- import tensorflow.keras
- from keras.preprocessing import image
- import tensorflow as tf
- import serial
- ser = serial.Serial('COM4', 115200, timeout=0)
- cap = cv2.VideoCapture(0)
- model = tensorflow.keras.models.load_model('MyModel/keras_model.h5')
- labels=['me','background']
- font= cv2.FONT_HERSHEY_SIMPLEX
- bs=0
- def send(val):
- data = bytes(val, 'UTF8')
- ser.write(data)
-
- while True:
- success, image = cap.read()
- if success == False:
- break
- image = cv2.flip(image,1)
-
-
- # The model takes an image of dimensions (224,224) as input so let’s
-
- # reshape our image to the same.
- img = cv2.resize(image,(224,224))
-
- # Convert the image to a numpy array
- img = np.array(img,dtype=np.float32)
- img = np.expand_dims(img,axis=0)
-
- # Normalizing input image
- img = img/255
-
- # Predict the class
- prediction = model.predict(img)
-
- predicted_class = labels[np.argmax(prediction)]
- print(predicted_class)
- cv2.putText(image, predicted_class, (123,456), font, 2, (0,255,0), 3)
- if predicted_class=='me' and bs==0:
- send('a')
- bs=1
- if predicted_class=="background" and bs==1:
- send('b')
- bs=0
- cv2.imshow("Frame",image)
- # Close all windows if one second has passed and ‘q’ is pressed
- if cv2.waitKey(1) & 0xFF == ord('q'):
- break
-
- # Release open connections
- cap.release()
- cv2.destroyAllWindow()
-
程序讲解:
导入所需的库:NumPy(图像处理)、cv2(用于视频捕获的OpenCV)、TensorFlow和Keras以加载模型、serial(舵机驱动)。
使用OpenCV库连接网络摄像头。
将模型加载到“model”中,并创建一个名为“labels”的列表,该列表将存储模型的类名称。
现在,将从摄像头采集的图像对其进行预处理,以便将其输入到我们的模型中。
如果预测类是“me”,这意味着用户人脸图像来到摄像头前,驱动舵机运行。
如果预测的类是“background”,则意味着是只有背景图像,驱动舵机到指定位置不动。
当按下按钮“q”时,程序将结束,这相当于停止录制。
最后,我们释放所有打开的连接。
【演示视频】
 converted_keras (1).zip converted_keras (1).zip
| 




 沪公网安备31011502402448
沪公网安备31011502402448
 置顶卡
置顶卡 变色卡
变色卡 千斤顶
千斤顶


 。。。
。。。


 活跃会员
活跃会员
 宣传大使
宣传大使
 牛X认证
牛X认证
 创客造
创客造
 编辑选择奖
编辑选择奖
 志“童”道合
志“童”道合
 编辑选择奖
编辑选择奖
 编辑选择奖
编辑选择奖
 编辑选择奖
编辑选择奖
 编辑选择奖
编辑选择奖






