|
13805| 9
|
[M10教程] 图形化玩转人工智能机器学习 |

|
在学习人工智能机器学习的过程中,一般的流程是获取图片(拍照或者爬虫)、处理图片、标注图片、训练模型、编写代码。在这个过程中对图片的处理和标注是最累人的,而且容易出错,对于学生而言过程极其痛苦,最近发现一种特别简单的图形化方式实现人工智能机器学习,只需要点点鼠标即可完成。 今年参加了第二届”少年硅谷——全国青少年人工智能教育成果展示大赛“其中的一个项目——火星环境探测挑战赛,在这个比赛中使用到英荔公司的创作平台、硬件编程平台,发现他们的训练平台非常好用,简单快捷。 无意之间发现这个训练平台可以不用登录也可以使用,而且还可以下载模型,那岂不是可以借助这个平台来实现训练模型? 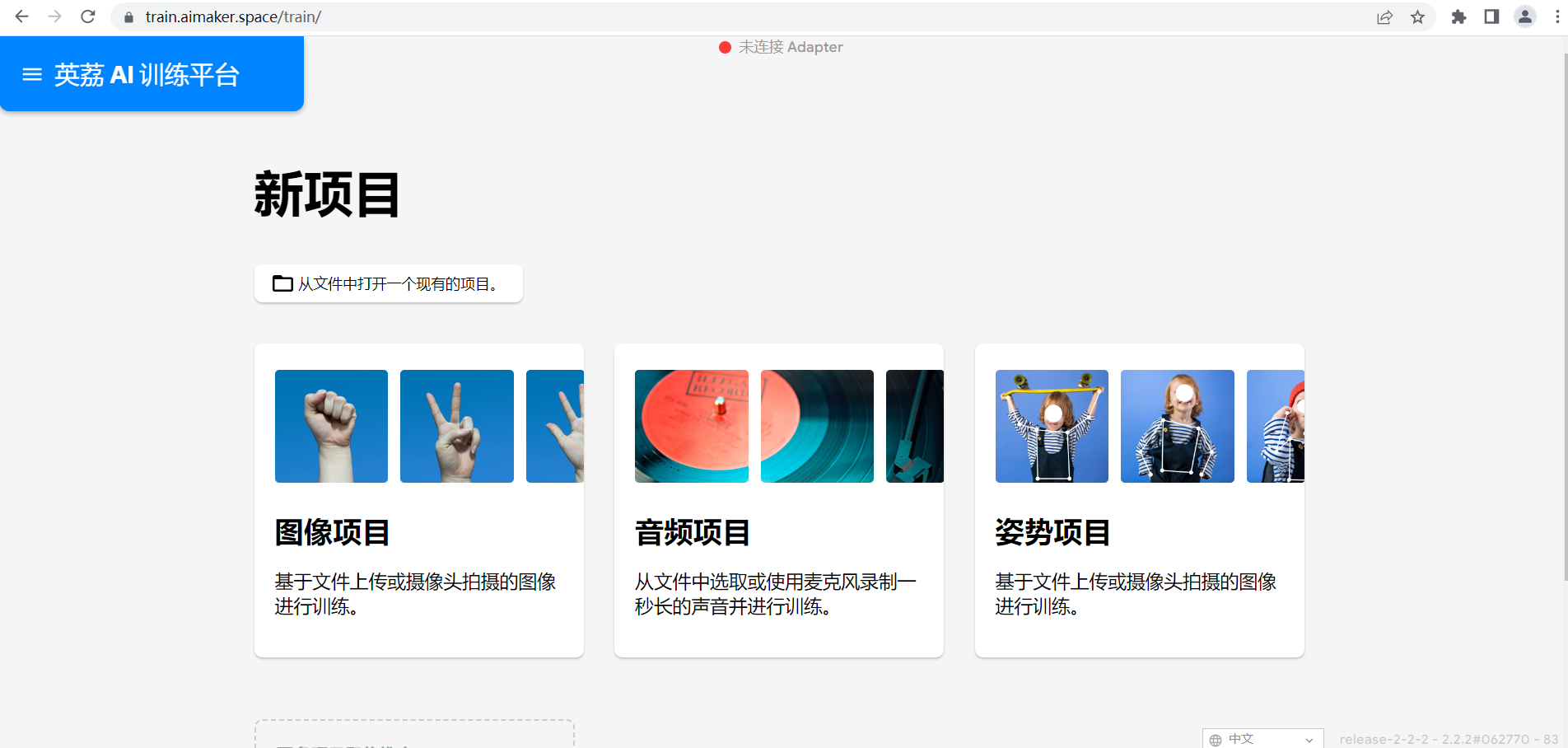 可以看到这个平台可以训练图像项目、音频项目和姿势项目,今天先来试试图像项目,点击图像项目进入。 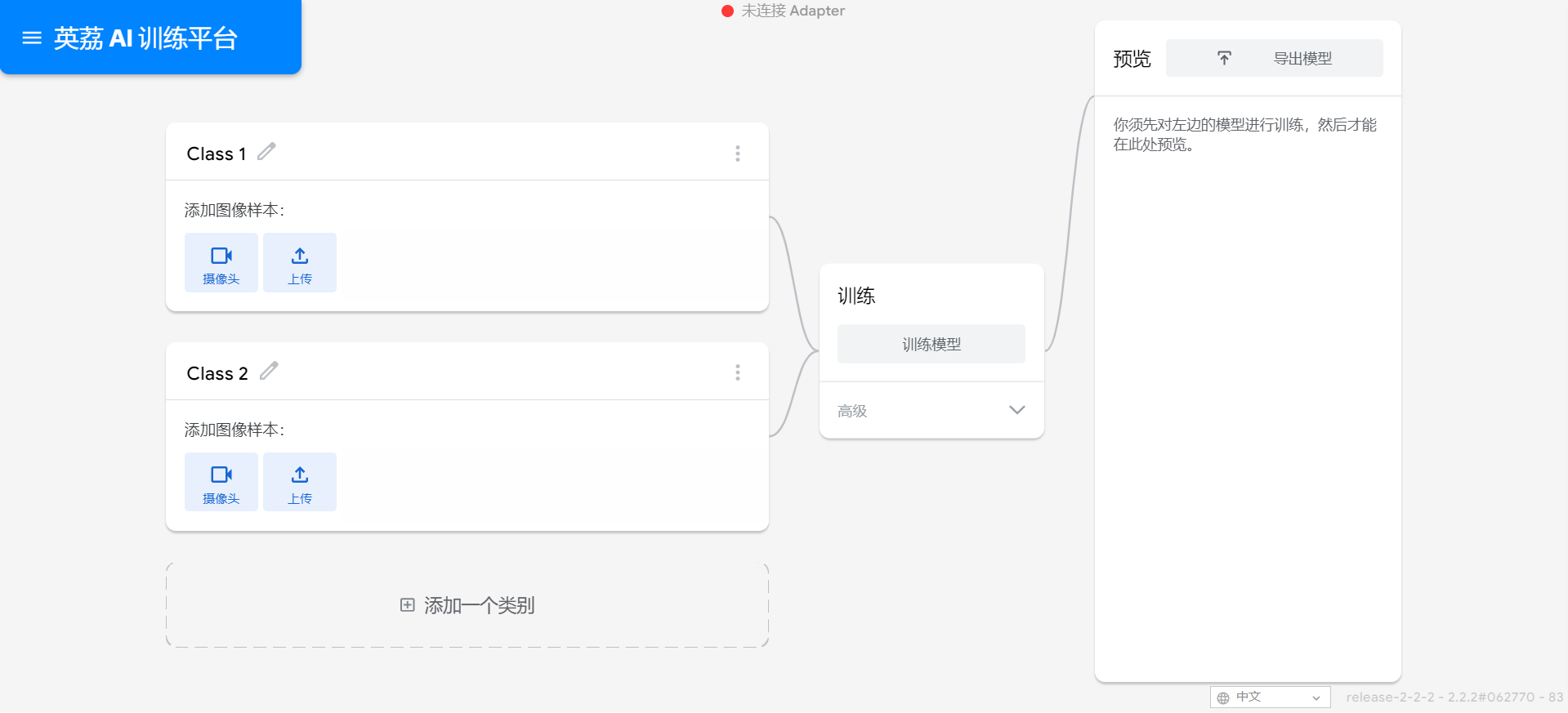 界面非常简洁,已经有两个类别Class1和Class2,点击类目名后面的笔图案可以改类目的名称,注意尽量不要使用中文。 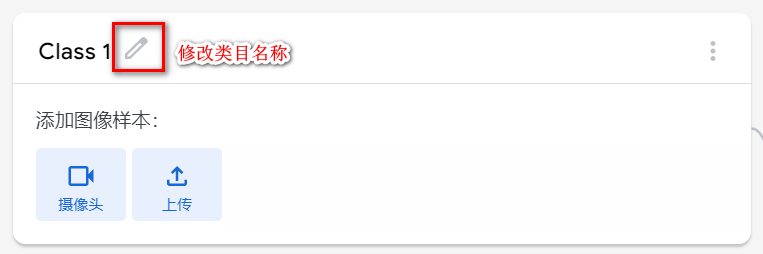 我以识别石头、剪刀、布为例,类目名我就懒得改了,分别为: Class1——布 Class2——石头 Class3——剪刀 Class4——背景 先来训练”布“ 点击Class1下面的摄像头 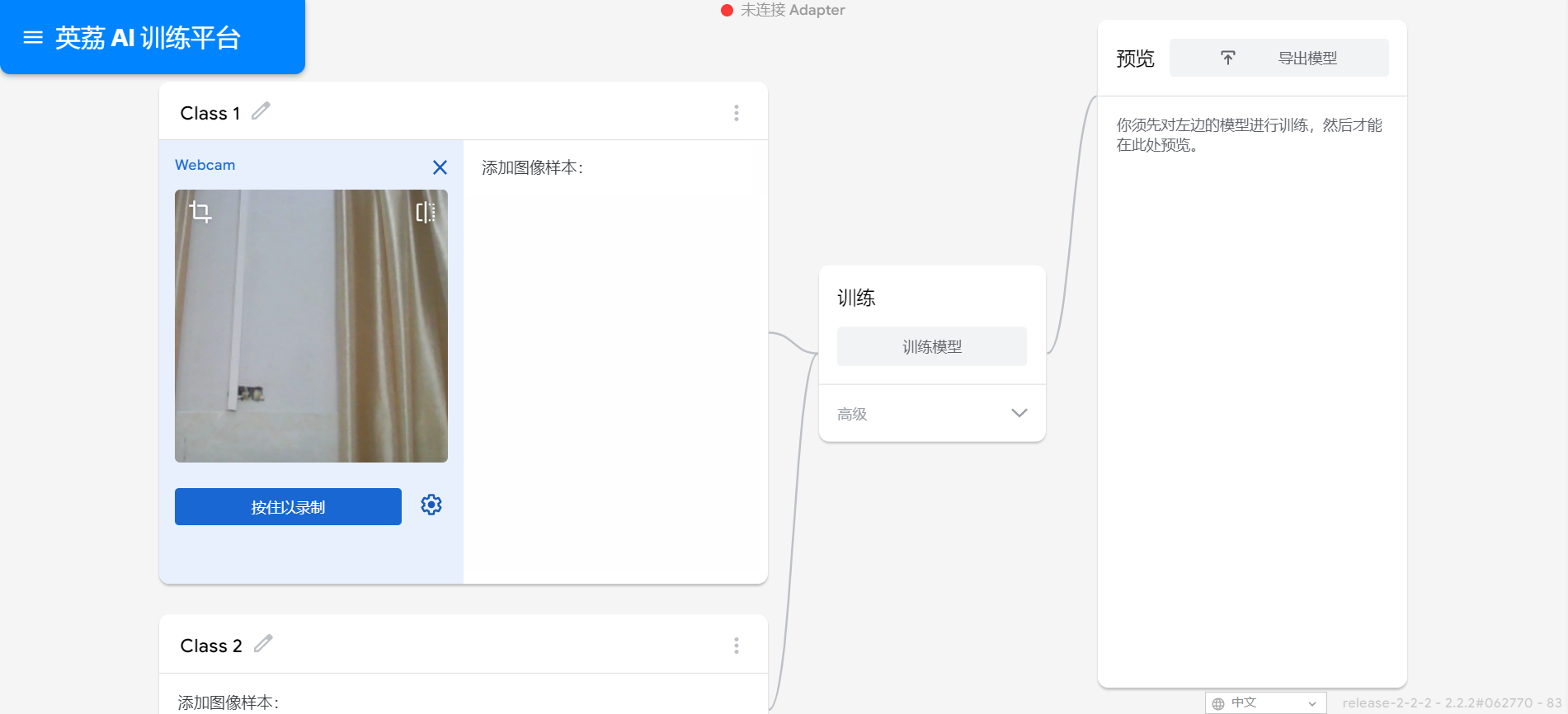 可以看到平台打开了摄像头,下面有个按钮”按住以录制“,根据提示我们将”布“的手势放入摄像头,然后按住这个按钮不松开 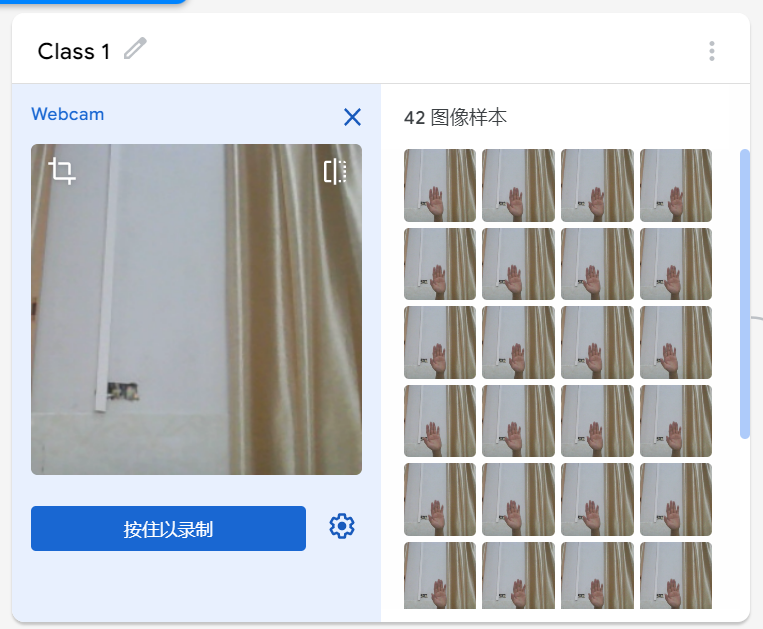 右边就会出现很多”布“手势的图片,尽量将各种可能出现的布手势都做出来,数量的话建议尽量多一点,不要少于30张。 紧接着录制其他手势的照片。 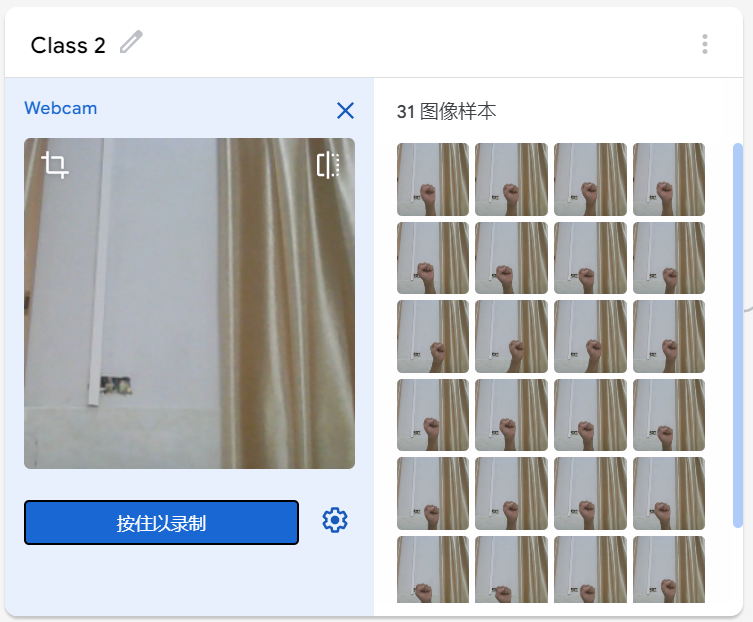 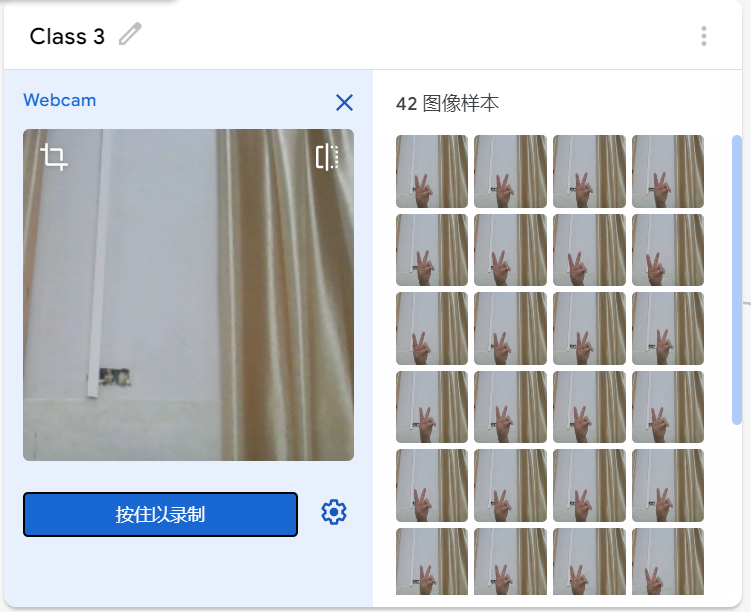 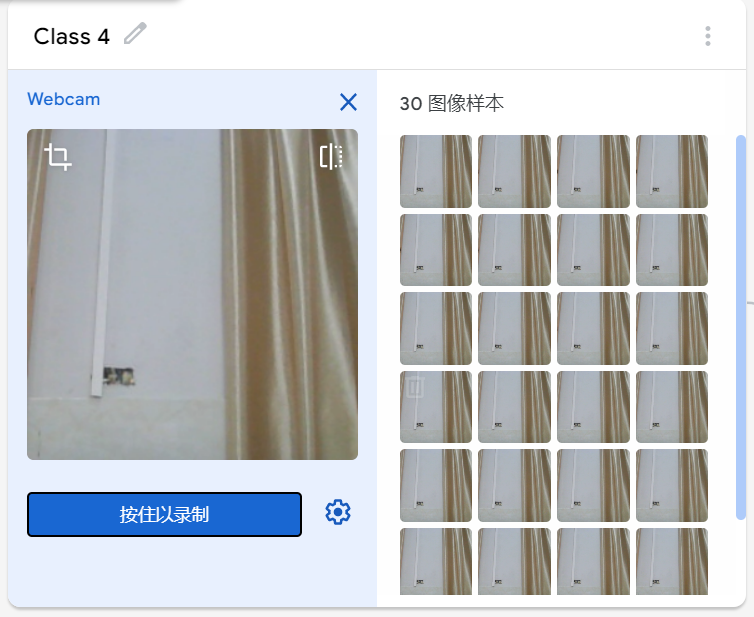 图片准备完毕,点击中间的训练模型 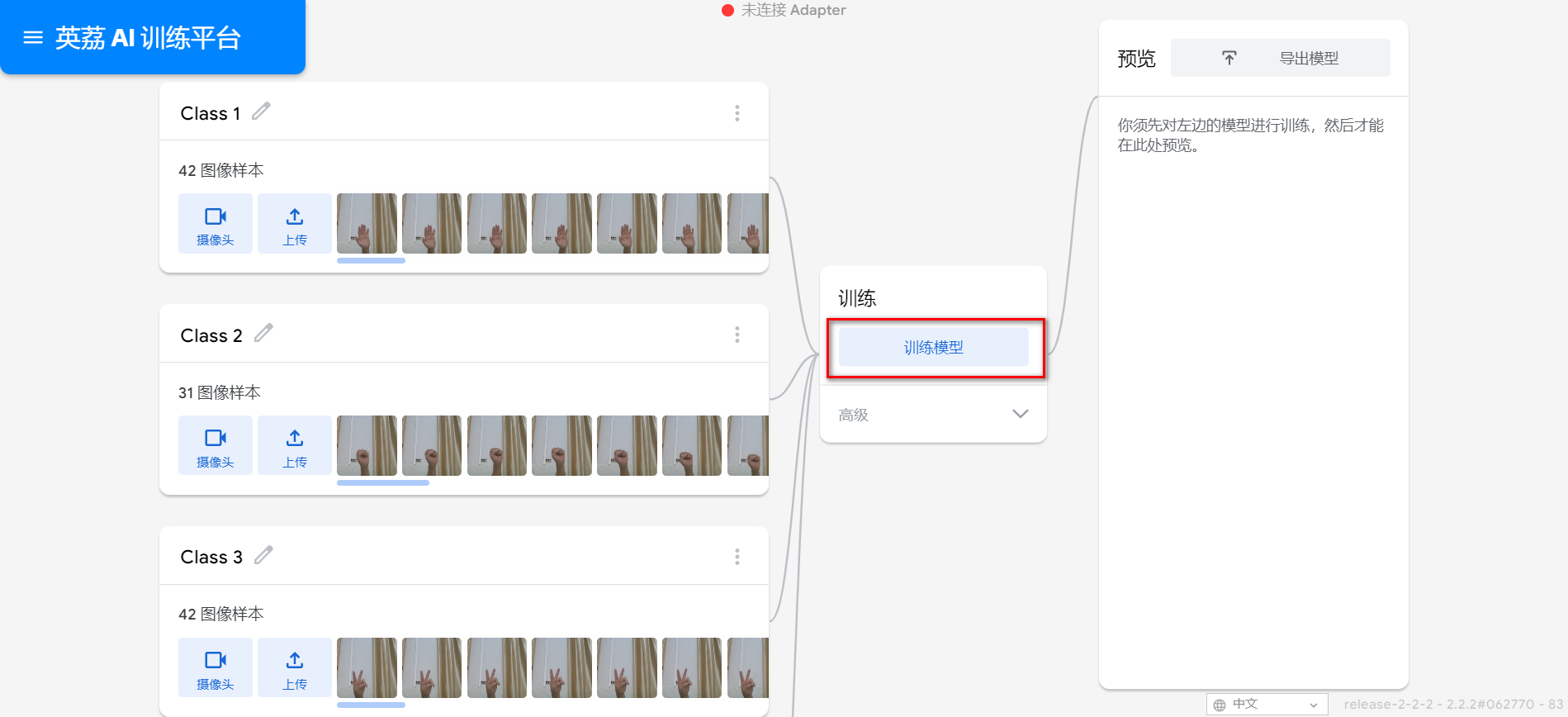 然后平台就会开始训练 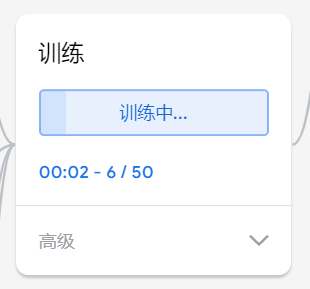 训练过程是非常快的,基本上1-2分钟就可以训练完毕。 训练完毕后,右边就会自动进行测试,我们在摄像头前摆出各种手势,右边就会根据模型判断出是哪种手势。  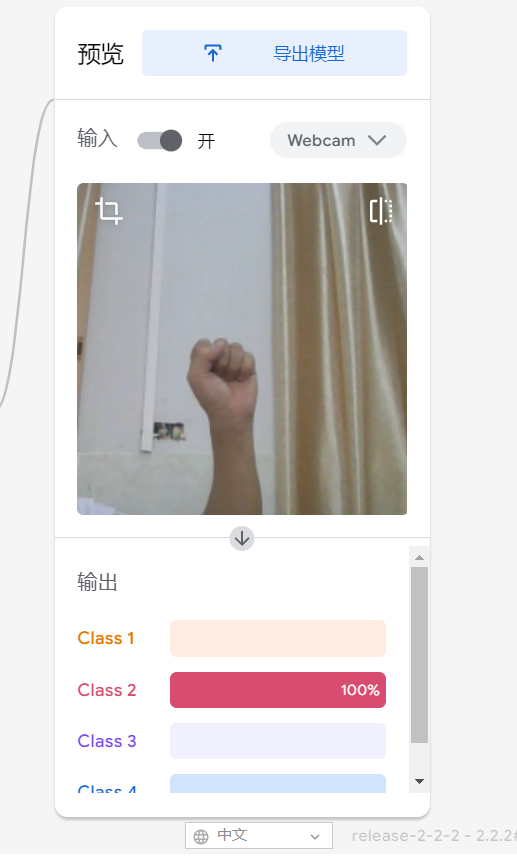  因为手势比较简单,准确率还是非常高的。如果发现准确率比较低,那就多拍点图片,再次训练模型,将准确率提高。 接下来我们就可以下载模型了,点击导出模型 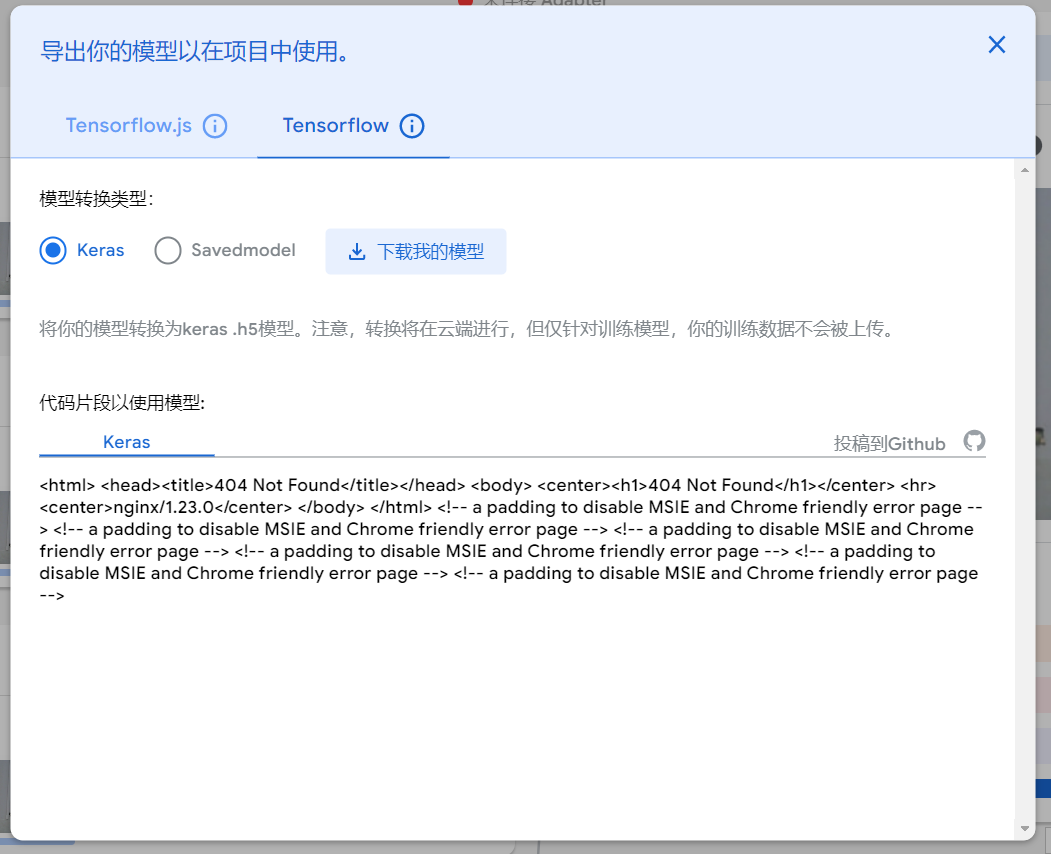 选择 Tensorflow,然后点击下载我的模型,就会下载到两个文件。 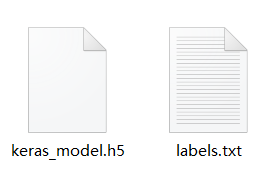 其中keras_model.h5就是模型文件,而labels.txt就是类别名称文件,将这两个文件放入一个文件夹。 接下来就是利用这两个文件进行编写程序。 打开Mind+,切换到Python模式,点击左下角扩展,加入两个官方库。 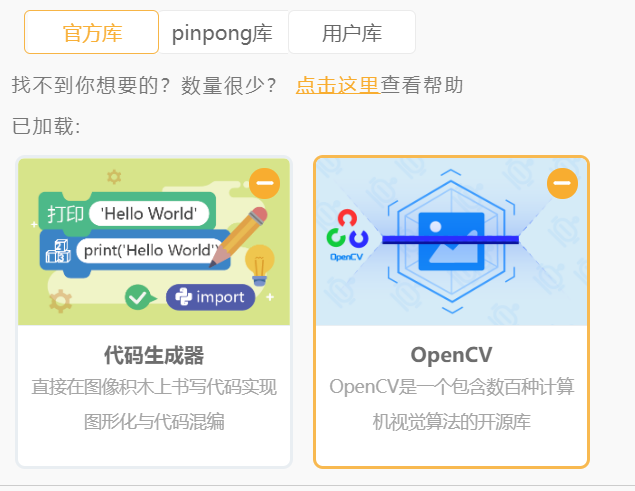 代码如下: 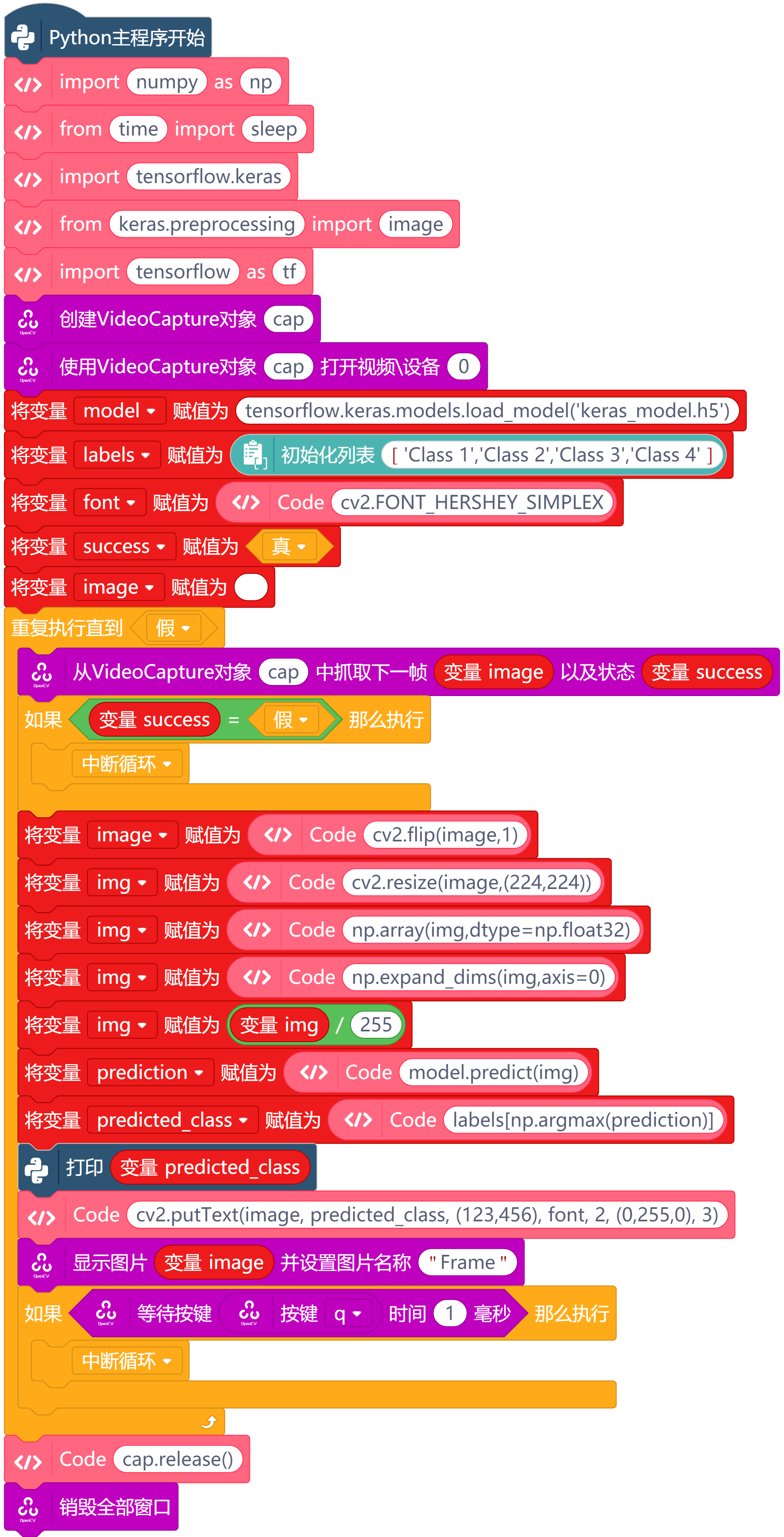 注意先保存,然后再运行,文件保存的路径要和模型文件保存的路径一致。 点击运行,效果如下 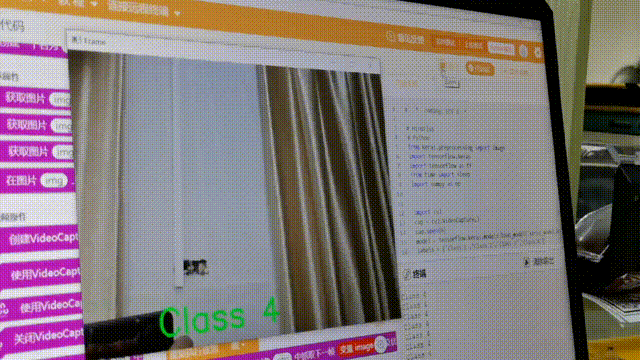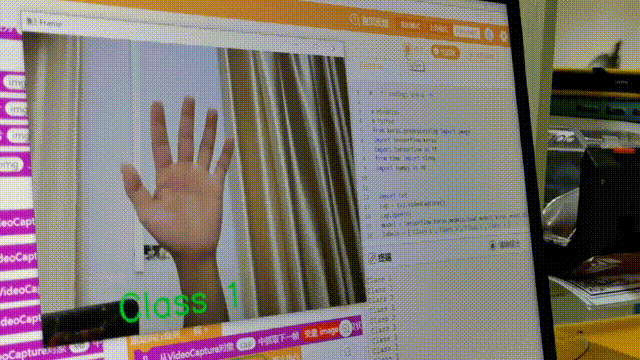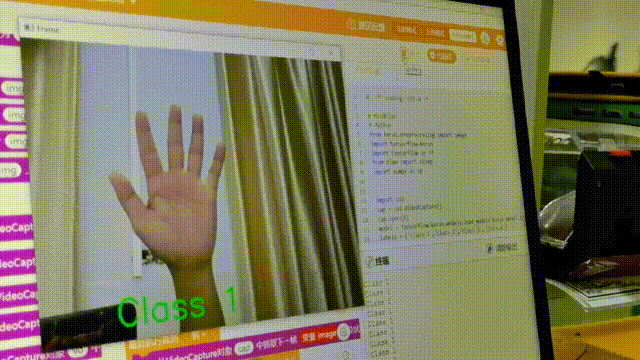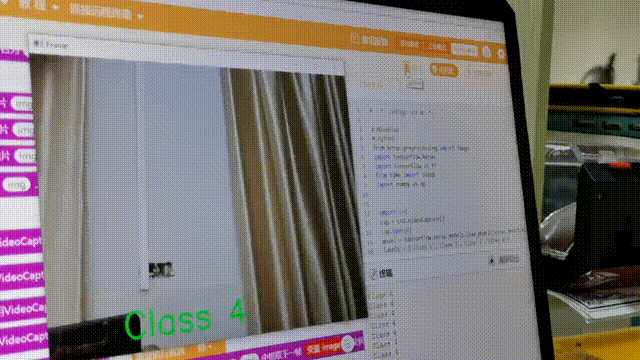 可以看到效果还是很不错的,这是人工智能图像识别中的物体分类功能,对于中小学生入门人工智能机器学习还是很有帮助的,简单的动动鼠标就可以体验整个学习过程。 后续还可以通过加入pinpong库,对开源硬件进行操作,比如加入一个RGB灯,剪刀就亮红色,石头就亮绿色,布就亮蓝色…… 只需要在  的前后加入判断即可。 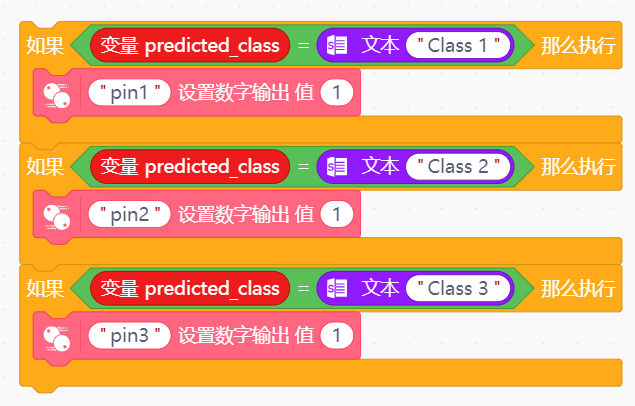 期待大家玩出更多创意。 也可以将自动生存的代码保存为py文件,和模型文件,类别标签文件一并部署到树莓派、冲锋舟、拿铁熊猫、行空板等上面实现物体分类功能。 代码
附件 |
 创作达人
创作达人



 沪公网安备31011502402448
沪公网安备31011502402448© 2013-2026 Comsenz Inc. Powered by Discuz! X3.4 Licensed

 置顶卡
置顶卡 变色卡
变色卡 千斤顶
千斤顶








