|
5950| 0
|
[M10教程] 基于行空板的opencv人脸特征点绘制 |
一、实践目标本项目借助行空板,对人脸图像进行检测并在其上绘制人脸特征点。 二、知识目标1、学习使用harr算法进行人脸检测的方法。 三、实践准备硬件准备 Mind+编程软件 四、实践过程1、硬件搭建通过USB连接线将行空板连接到计算机。  软件编写第一步:打开Mind+,远程连接行空板  第二步:在“行空板的文件”中新建一个名为AI的文件夹,在其中再新建一个名为“基于行空板的opencv人脸特征点绘制”的文件夹,导入本节课的人脸图片和模型,以及依赖安装包和文件。 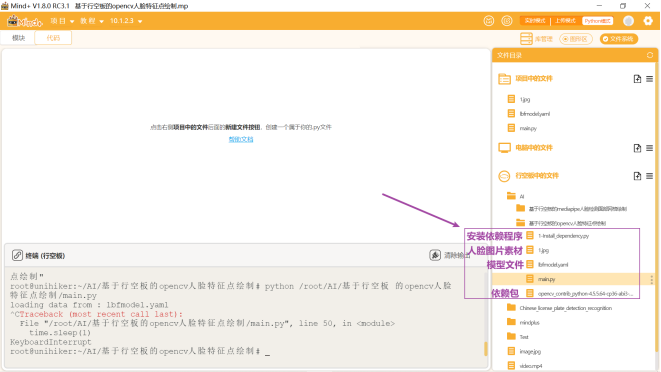 第三步:编写程序 在上述图片和模型文件的同级目录下新建一个项目文件,并命名为“main.py”。 示例程序: 3、运行调试第一步:运行“1-Install_dependency.py”程序文件,等待自动安装依赖包,完成示意图如下。 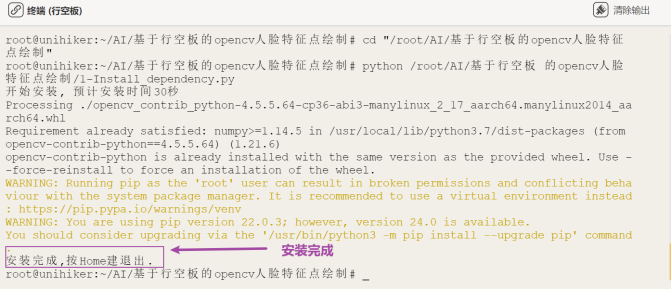 第二步:运行主程序 运行“main.py”程序,可以看到初始时屏幕显示了一张人脸,几秒后,通过小圆点对人脸的眼睛、鼻子、嘴巴、眉毛等特征进行了描绘。  同时,也可以在同级路径下看到保存的人脸图片“output.jpg”。 4、程序解析在上述的“main.py”文件中,我们主要通过opencv库的Haar特征分类器来进行人脸检测,在检测到人脸后通过Facemark的LBF(Local Binary Features)算法进行面部特征点检测,整体流程如下: 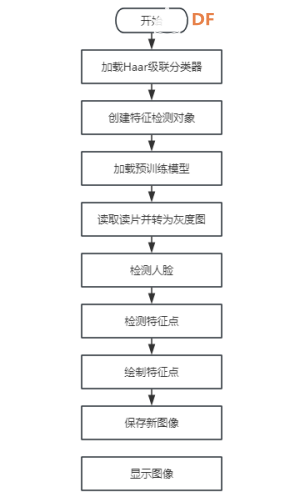 五、知识园地1、1.了解haar cascade算法haar cascade算法,又称haar级联算法,是一种在计算机视觉中广泛应用的对象检测方法,尤其在面部检测领域得到了广泛应用。它是一种基于机器学习的方法,通过训练大量的正样本(包含目标对象)和负样本(不包含目标对象)来生成一个级联分类器。是一种在计算机视觉中广泛应用的对象检测方法,尤其在面部检测领域得到了广泛应用。它是一种基于机器学习的方法,通过训练大量的正样本(包含目标对象)和负样本(不包含目标对象)来生成一个级联分类器。 那么它是如何工作的呢?下面,借助一张流程图来帮助我们了解harr级联算法的工作流程。 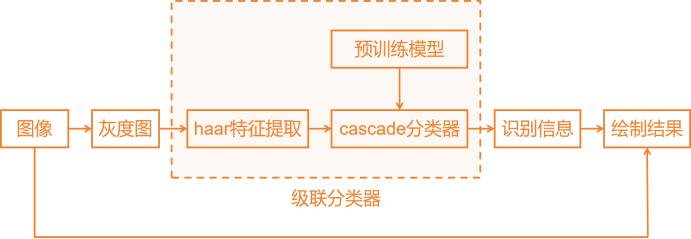 获取原始图像 获取原始图像,使用“cv2.imread('1.jpg')”指令,从当前路径下获取一张原始图像“1.jpg”。  转换灰度图 将获取的原图图像,通过“cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)”指令,将彩色图像转换为灰度图像。  haar特征提取 haar特征提取,就是拿一个个黑白矩形去图片的相应位置进行比对,看看是否符合灰度的分布特征。  第一幅人脸检测图中,表明眼睛区域比眼睛下面的脸颊颜色深;第二幅人脸检测图中,表明了左右眼区域比鼻梁区域颜色深。以这种方式,进行整个图像的特征提取,如果提取的特征符合人脸数据模型,那说明人脸特征提取成功。 注意:人脸数据模型,是提前训练好的,这里不做详细介绍。 识别信息 (1)缩放比例  至于金字塔有多少层,通常取决于具体的人脸检测器设置和输入图像的大小。如果输入图像的原始尺寸较大,金字塔可能要包含更多的层级,输入图像较小,层级就越少。缩放比例取决于应用的需求和性能要求,通常情况下,可以根据实验和性能优化来选择适当的缩放比例,以获取最佳的人脸检测效果。我们测出将缩放比例设置为1.3时,是最佳的人脸检测效果。 (2)相邻个数 注意:关于相邻个数,你也可以根据实验结果来选择合适的参数。 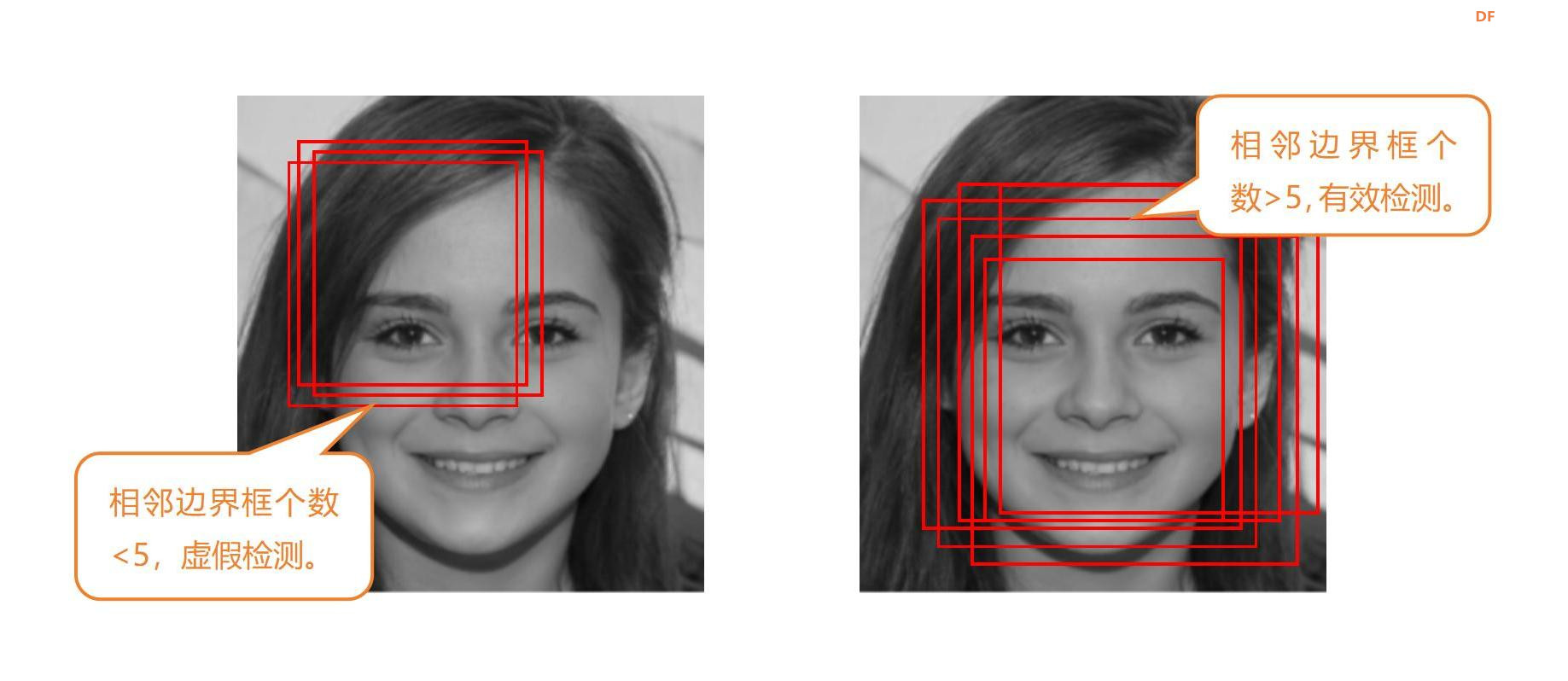 2.了解Facemark框架的LBF算法 Facemark是OpenCV库中的一个用于面部特征点检测的框架。它提供了一个通用的接口,可以通过实现不同的算法来进行面部特征点的检测。其中,LBF(Local Binary Features)是一种实现方法。 LBF是一种基于局部二值特征的人脸特征点检测算法。这种算法首先使用级联回归方法来预测面部特征点的粗略位置,然后使用局部二值特征来描述面部的外观信息,并利用这些信息来修正特征点的位置,从而得到更准确的检测结果。 LBF算法的主要优点是检测精度高,并且计算效率也相对较高。它可以在各种不同的情况下,如不同的光照、表情和姿态等,都能得到较好的检测结果。 在OpenCV的Facemark框架中,可以使用cv2.face.createFacemarkLBF()函数来创建一个基于LBF算法的特征点检测对象,然后使用这个对象的fit()方法来进行特征点的检测。 附录附录1:素材及拓展程序链接  基于行空板的opencv人脸特征点绘制.zip 基于行空板的opencv人脸特征点绘制.zip |



 沪公网安备31011502402448
沪公网安备31011502402448© 2013-2026 Comsenz Inc. Powered by Discuz! X3.4 Licensed


 置顶卡
置顶卡 变色卡
变色卡 千斤顶
千斤顶
 萌萌哒新人
萌萌哒新人
 活跃会员
活跃会员
 宣传大使
宣传大使
 志“童”道合
志“童”道合
 编辑选择奖
编辑选择奖






