|
41753| 5
|
如何在行空板上运行 YOLOv10n? |

|
本帖最后由 RRoy 于 2024-8-1 10:28 编辑 YOLOv10介绍 YOLO(You Only Look Once)系列是当前最主流的端侧目标检测算法,由Joseph Redmon等人首次提出,并随着时间发展,已经推出了多个版本,每个版本“似乎”都在性能和速度上有所提升。  本文为大家介绍的是 YOLOv10在行空板的运行。YOLOv10是由清华大学研究团队最新提出的,同样遵循 YOLO 系列设计原则,致力于打造实时端到端的高性能目标检测器。 YOLOv10解决了以往版本YOLO系列目标检测算法在后处理和模型架构方面的不足。通过消除非极大值抑制(NMS)操作和优化模型架构,YOLOv10在显著降低计算开销的同时还实现了最先进的性能。在标准目标检测基准上进行的广泛实验表明,YOLOv10在各种模型规模下,在计算-准确度权衡方面显著优于先前的最先进模型。 如下图所示,在类似性能下,YOLOv10-S / X分别比RT-DETR R18 / R101快1.8倍/1.3倍。与YOLOv9-C相比,YOLOv10-B在相同性能下实现了46%的延迟降低。此外,YOLOv10展现出了极高的参数利用效率。YOLOv10-L / X在参数数量分别减少了1.8倍和2.3倍的情况下,比YOLOv8-L / X高出0.3 AP和0.5 AP。YOLOv10-M在参数数量分别减少了23%和31%的情况下,与YOLOv9-M / YOLO-MS实现了相似的AP。 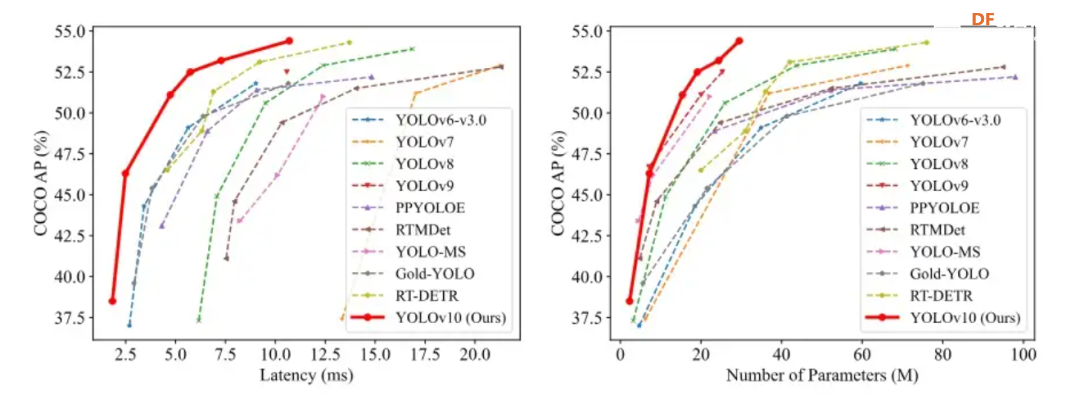 yolov10性能参数对比图 行空板硬件介绍 行空板是一款专为Python学习和使用设计的新一代国产开源硬件,采用单板计算机架构,集成LCD彩屏、WiFi蓝牙、多种常用传感器和丰富的拓展接口。同时,其自带Linux操作系统和Python环境,还预装了常用的Python库,让广大师生只需两步就能进行Python教学。  行空板是一款基于RK3308 Arm 64位四核处理器的开发板,主频达到1.2GHz,配备512MB DDR3内存和16GB eMMC硬盘,运行Debian 10操作系统。此外,它支持2.4G Wi-Fi和蓝牙4.0,采用RTL8723DS芯片。行空板还集成了GD32VF103C8T6 RISC-V协处理器,主频108MHz,具备64KB Flash和32KB SRAM。 行空板拥有多种板载元件,包括Home按键、A/B按键,2.8英寸可触控彩色屏幕,分辨率为240x320。设备还配备了电容式硅麦克风、PT0603光敏三极管光线传感器、无源蜂鸣器和蓝色LED。此外,它还内置了ICM20689六轴传感器,包括三轴加速度和三轴陀螺仪。 在接口方面,行空板提供了多种连接选项。具有USB Type-C接口,用于将CPU与PC连接进行编程或为主板供电。还有USB TYPE-A接口,用于连接外部USB设备。此外,板上还有microSD卡接口用于扩展存储空间,3Pin I/O支持3路10位PWM和2路12位ADC,独立的4Pin I2C接口,以及与micro:bit兼容的19路独立I/O金手指,支持多种通信协议和功能。 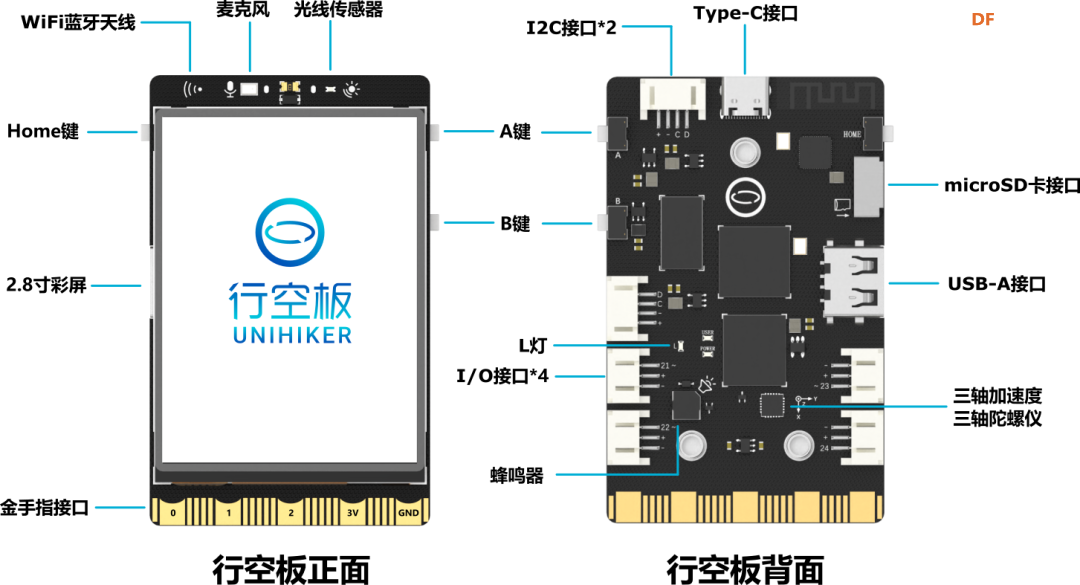 在行空板上运行YOLOv10的物体检测功能 在这篇文章中,我们将使用DFRobot公司研发的行空板来运行YOLOv10,并尝试通过转换onnx格式进行加速。 将YOLOv10部署在行空板上具有重要的实用和学习意义:
准备:运行YOLOv10的环境配置为了在行空板上成功运行YOLOv10,我们将使用Ultralytics官方提供的库进行部署。首先,我们需要确保行空板上的Python环境满足YOLOv10的要求,即Python版本需升级到3.8以上。为此,我们推荐使用MiniConda进行版本管理,这样可以轻松切换和管理不同版本的Python环境。 步骤大致如下:
通过上述步骤,我们可以在行空板上成功部署YOLOv10,充分利用其强大的物体检测能力。这种方法不仅能确保YOLOv10的高效运行,还能方便地进行环境管理和版本控制,为后续的开发和实验提供了稳定的基础。同时,通过使用MiniConda进行版本管理,我们可以更灵活地应对不同项目对Python环境的需求,提高开发效率。 下面是详细步骤。 step 1 查看当前python版本: 在终端输入: python --version 终端显示: Python 3.7.3 ultralytics不支持低版本python,需简要将python升级。选择使用mini conda进行版本管理和升级。
step 2 下载mini conda 在终端输入: 下载完后终端显示: 已保存 “Miniforge3-Linux-aarch64.sh” [74300552/74300552]) step 3 安装mini conda 在终端输入: sudo bash Miniforge3-Linux-aarch64.sh 过程中遇到需要输入ENTER键或者yes键的照做。最后终端显示: > Added mamba to /root/.bashrc > > ==> For changes to take effect, close and re-open your current shell. <== > > Thank you for installing Miniforge3!  在终端输入: source ~/.bashrc 安装完成,在终端输入: conda 终端显示:  Step 4 激活conda 在终端输入: conda activate 可以看到终端的显示由  变成  说明已经成功激活了conda。 Step 5 在conda中建立YOLO环境 名字叫yolo,python版本选择3.11。在终端输入: conda create -n yolo python==3.11 过程中显示:  输入y, 环境建立完终端显示:  Step 6 激活yolo环境 在终端中输入: conda activate yolo 可以看到终端显示由 变成  说明激活yolo环境成功。 Step 7 安装utralytics 在终端输入: pip install ultralytics 完成后终端显示:  Step 8 安装Pillow库 在终端输入: pip install pillow 如果已安装,终端显示: > Requirement already satisfied: pillow in /root/miniforge3/envs/yolo/lib/python3.11/site-packages (10.3.0) Step 9 安装OpenCV 在终端输入: pip install opencv-python 如果已安装,终端显示: > Requirement already satisfied: opencv-python in /root/miniforge3/envs/yolo/lib/python3.11/site-packages (4.9.0.80) > > Requirement already satisfied: numpy>=1.21.2 in /root/miniforge3/envs/yolo/lib/python3.11/site-packages (from opencv-python) (1.26.4) Step 10 安装huggingface库 终端输入: pip install huggingface  Step 11 安装huggingface_hub库 终端输入: pip install huggingface_hub  快速开始:原生YOLOv10的运行 Step 1 github上下载项目 Yolov10项目地址:https://github.com/THU-MIG/yolov10 终端输入: git clone https://github.com/THU-MIG/yolov10.git 下载yolov10的项目。然后进入目录,终端输入: cd yolov10 Step 2 需要准备的文件 权重文件(可以在文末下载):  Step 3 创建python文件 quick_start.py 样例代码: Step 4 确认开启yolo环境: 在终端输入: conda activate yolo 确认终端显示:  Step 5 运行编写的python脚本 在终端输入: python quick_start.py 可以看到终端中显示:  可以看到,使用原生yolov10n的模型进行单张图片的推理需要大约7秒。 自动下载了图片bus.jpg,这是我们准备的让yolo推理的图片,如下所示:  最后模型推理,将结果储存为了result_bus.jpg: 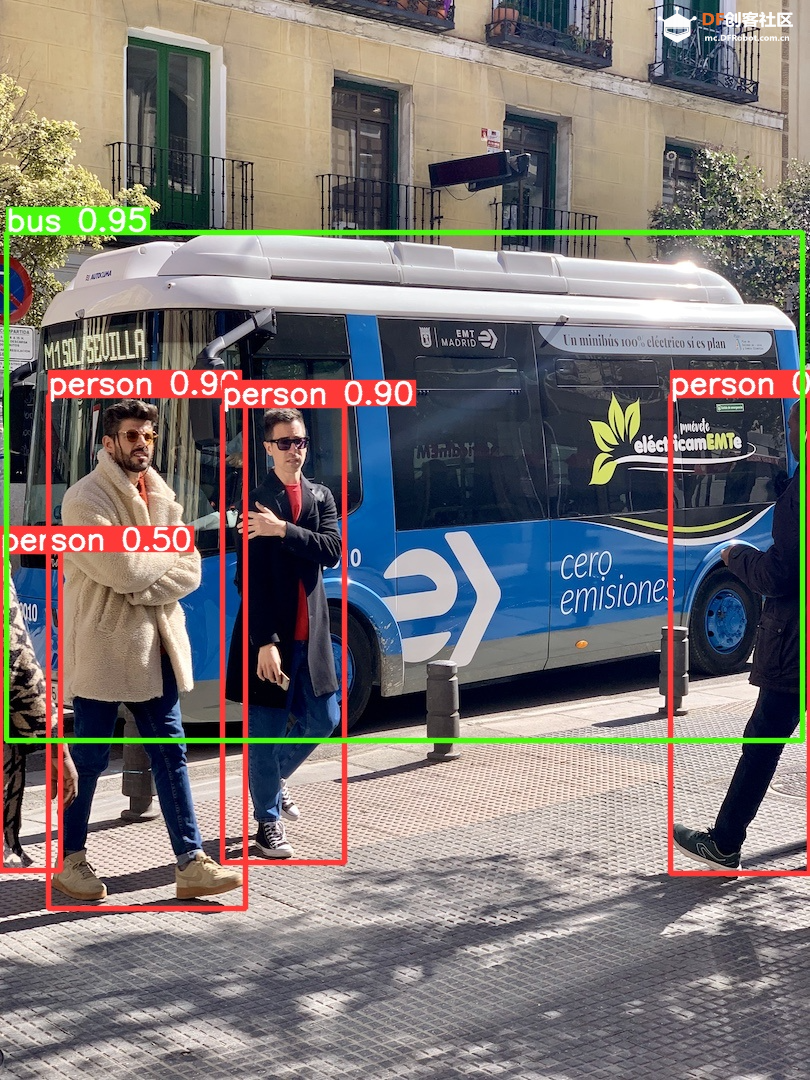 优化:转换onnx格式 在使用原生yolov10n运行的时候,速度是很慢的,所以我们需要对其进行格式转换以加速其运行。 本节介绍如何将yolov10n.pt转换成onnx格式以加快运行速度。下面是详细步骤: Step 1 移动到上一节中创建的yolo目录 在终端中输入: cd yolov10 Step 2 建立python文件,名为:export_onnx.py,代码如下: Step 3 确认开启yolo环境: 在终端输入: conda activate yolo 确认终端显示: Step 4 运行编写的python脚本 在终端输入: python export_onnx.py 终端中显示: 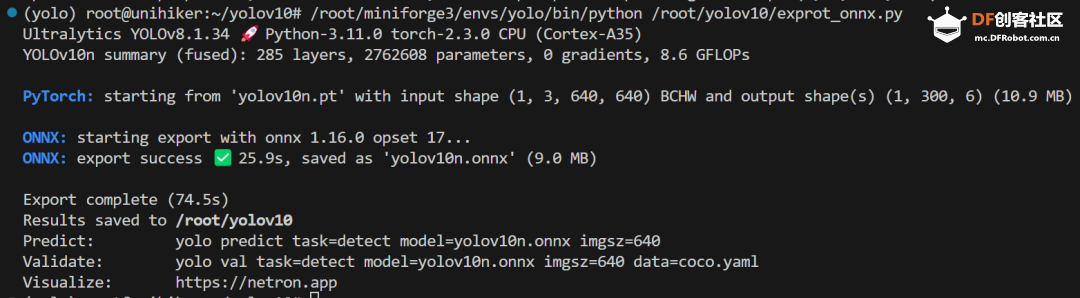 可以看到,最终自动保存了转换好的文件yolov10n.onnx Step 5 编写运行onnx模型的文件 建立predict_onnx.py文件,并编写如下代码: Step 6 运行推理代码 在终端输入: python predict_onnx.py 终端显示:  目录中产生预测结果: 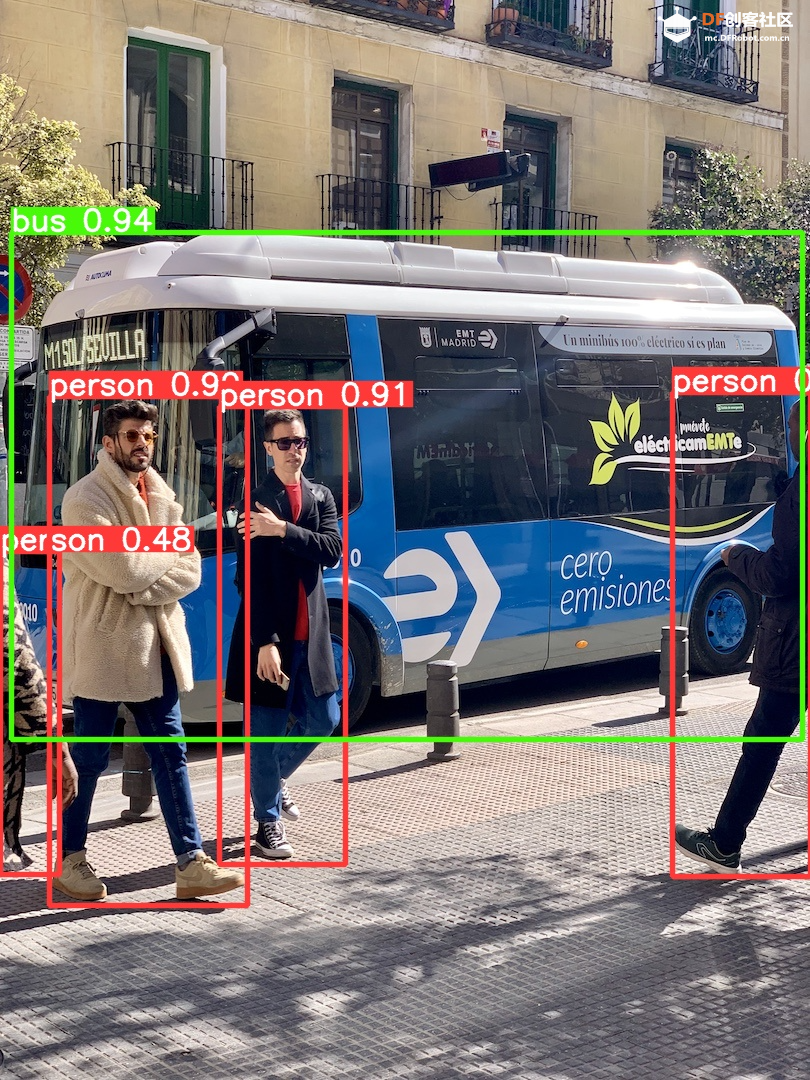 可以看到,使用onnx模型进行目标检测大约耗时6.5秒,比原生模型快了0.5秒。 进一步优化:减小输入图片的尺寸 可以看出,目前的推理速度仍然较慢。 如果想提高推理速度,可以减少输入图片的尺寸。导出onnx模型的时候,我们可以设置参数imgsz来规定输入图片的尺寸,如果输入图片的尺寸不确定,我们也可以将dynamic参数设置为True,这时候导出的onnx可以接受任意尺寸的图片输入进行推理。具体步骤如下: Step 1 移动到上一节中创建的yolo目录 在终端中输入: cd yolov10 Step 2 建立python文件,名为:export_onnx.py,代码如下: Step 3 确认开启yolo环境: 在终端输入: conda activate yolo 确认终端显示: Step 4 运行编写的python脚本 在终端输入: python export_onnx.py 终端中显示: 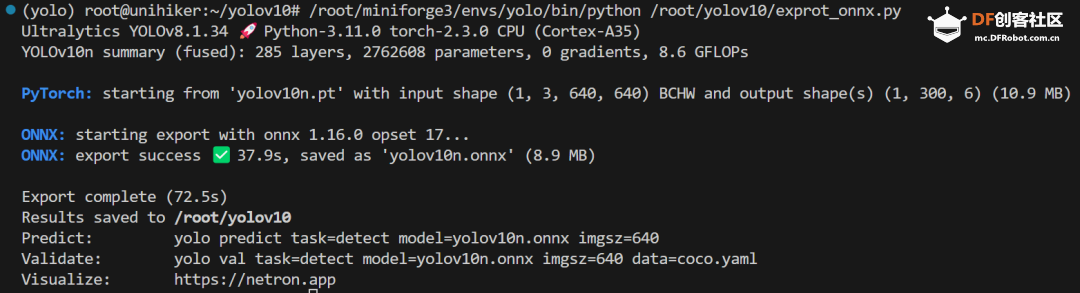 可以看到,自动保存了转换好的文件yolov10n.onnx。 Step 5 编写运行onnx模型的文件 建立predict_onnx.py文件,并编写如下代码: 在这段代码中,我们分别测试原始尺寸的图片、256尺寸的图片、128尺寸的图片和64尺寸的图片的运行情况。 Step 6 运行推理代码 在终端输入: python predict_onnx.py 终端显示: 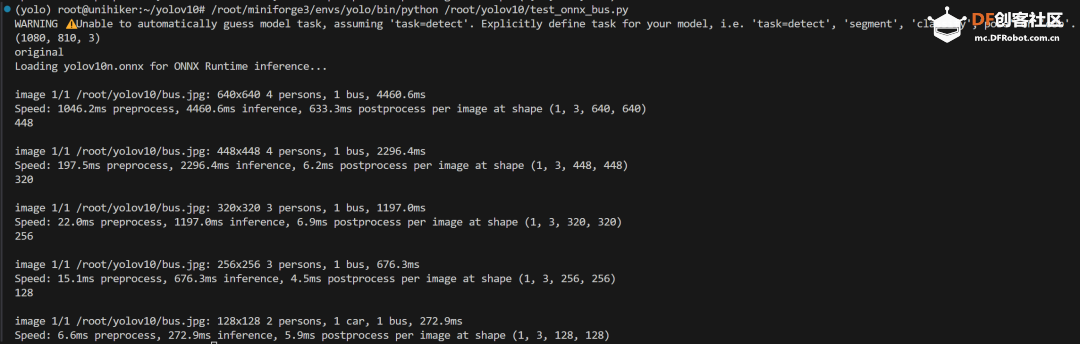 原图片尺寸是1080*810,原始yolov10n的最大预测尺寸是640,此时耗时大约6秒。结果如下: 输入尺寸为448时,耗时大约为秒。结果如下: 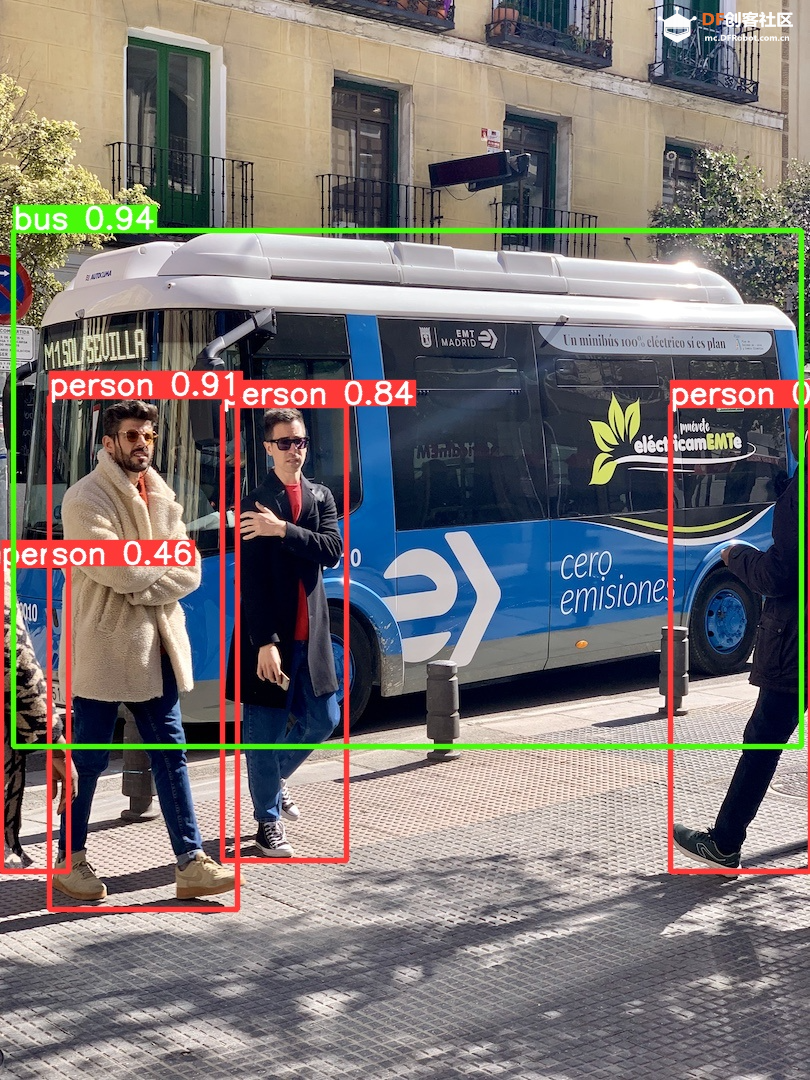 输入尺寸为320时,耗时大约为1.2秒。结果如下: 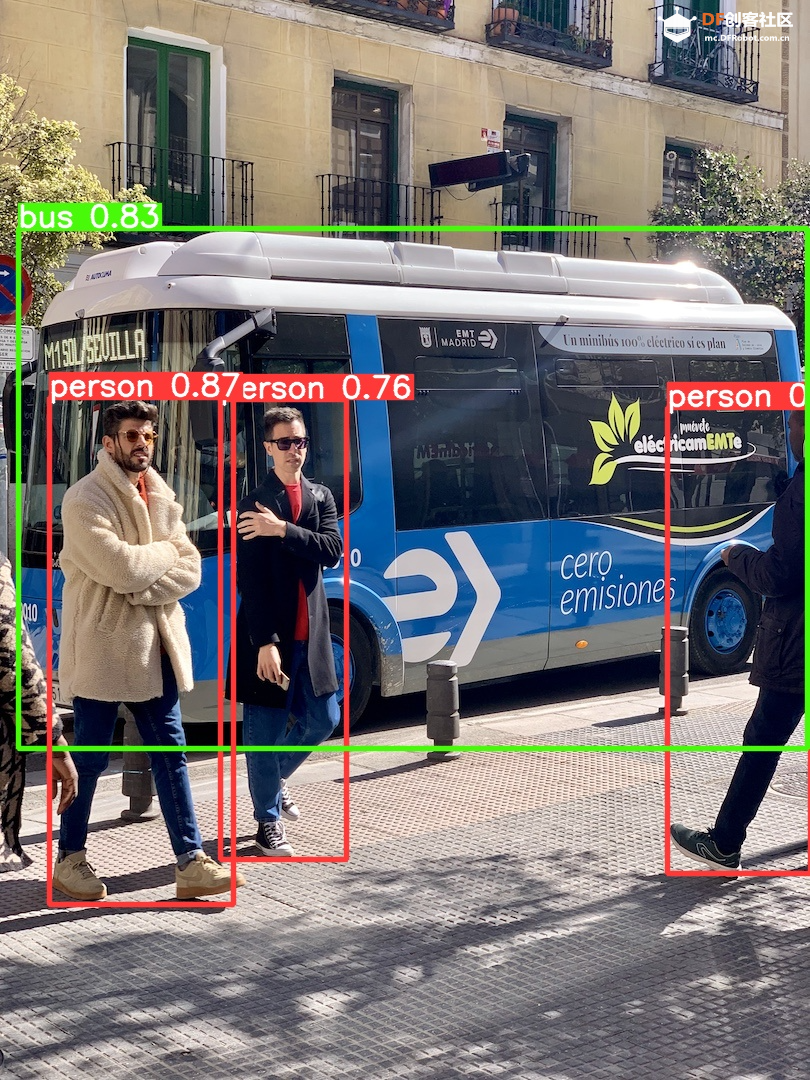 输入尺寸为256时,耗时大约为0.8秒。  输入尺寸为128时,耗时大约为0.4秒。  总结如下:
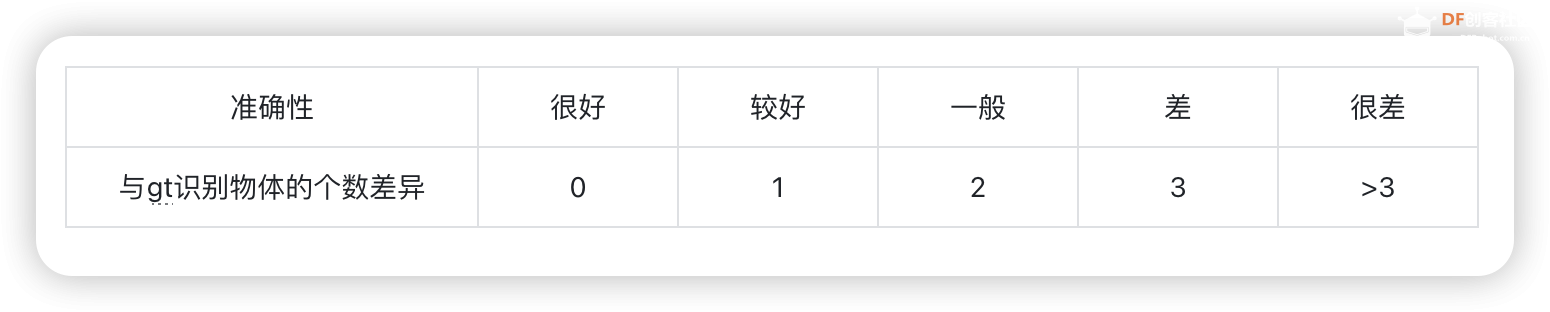 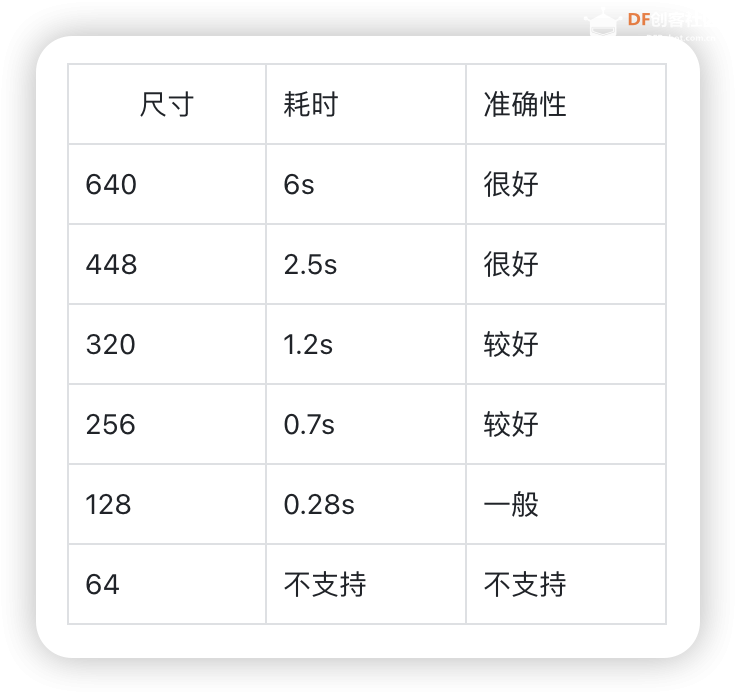 与YOLOv8n的对比 使用官方代码,图片尺寸与运行耗时的对比如下:
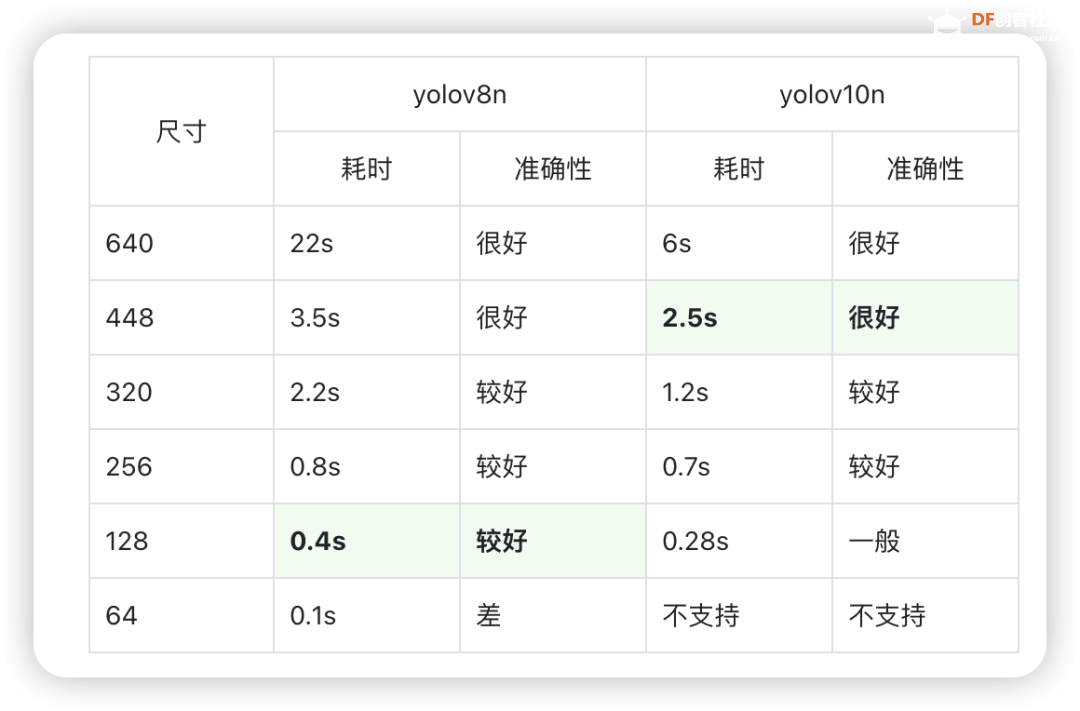 结论
使用行空板可以用简单的代码运行yolov10n,并且速度比yolov8n略快。
虽然yolov10是基于ultralytics开发,但是只安装ultralytics库不能直接运行yolov10,仍需要clone官方仓库。
如果使用行空板用于图片的目标检测,可以考虑使用448分辨率的输入,此种情况下一张图片的处理时间大约为2.5秒,同时准确性很好。如果使用行空板用于视频的目标检测,限于行空板的算力,推荐使用128分辨率的输入,此种情况下一张图片的处理时间大约为0.28秒左右,但是此时效果表现一般。更值得考虑的是使用yolov8n的128分辨率输入,此时准确性表现较好。再次强调:准确性表现以bus.jpg测试。如果您有自己的数据集,可能需要更多的测试。
我们将持续对yolov10n在行空板上的运行进行优化,欢迎关注。 |

6.46 MB, 下载次数: 4145
|
为什么 dynamic = True,加了上去后,还是识别不了640以下的图片? onnxruntime.capi.onnxruntime_pybind11_state.InvalidArgument: [ONNXRuntimeError] : 2 : INVALID_ARGUMENT : Got invalid dimensions for input: images for the following indices index: 2 Got: 256 Expected: 640 index: 3 Got: 256 Expected: 640 Please fix either the inputs/outputs or the model. |



 沪公网安备31011502402448
沪公网安备31011502402448© 2013-2026 Comsenz Inc. Powered by Discuz! X3.4 Licensed

 置顶卡
置顶卡 变色卡
变色卡 千斤顶
千斤顶


 萌萌哒新人
萌萌哒新人
 宣传大使
宣传大使
 小蘑菇
小蘑菇
 ARD DAY
ARD DAY
 编辑选择奖
编辑选择奖
 摸鱼团员
摸鱼团员
 编辑选择奖
编辑选择奖
 编辑选择奖
编辑选择奖
 编辑选择奖
编辑选择奖






