本帖最后由 向晚AVA 于 2024-8-21 13:32 编辑 最近做了一个项目,使用 NLTK 库对简单文本进行处理和分析。 NLTK ( Natural Language Toolkit )是一个广泛使用的自然语言处理工具包,提供了丰富的功能和资源,帮助用户处理和分析文本数据。作为一个开源项目, NLTK 库被设计用于教育和研究领域,为学生、研究人员和开发者提供了强大的工具和资源。 该项目的应用场景为中小学生的中英文语法教学,教师可以利用 NLTK 库进行文本预处理、特征提取、语言模型构建等,从而实现文本的分析和教学。众所周知,中小学中英文学习中比较难以理解的部分就是语法和词性教学,很多时候由于学生的词汇量不足导致学生无法理解句子的结构,进而无法理解句子的情感和句中单词的词性。 NLTK 库中包含了各种功能模块,包括分词、词性标注、命名实体识别、句法分析、情感分析等,涵盖了自然语言处理的各个方面。 该项目设计的目的就是利用 NLTK 库帮助中小学生通过一些简单句子的练习,锻炼分析句子结构的能力,以此提高对陌生句子语义和情感的分析能力。学生可以自己先对陌生句子进行自行理解,之后利用该项目提供的硬件和代码对句子进行精确的分析,将标准答案和自己的答案进行比较,得出自己的不足,在不知不觉中培养中英文语句的分析能力。 第一部分:所需硬件 本项目所有功能均为软件实现,所以硬件我只使用了 DFROBOT 出品的行空板 UNIHIKER 。 硬件清单:
第二部分:软件编程 1、导入库模块 NLTK 库:包括分词、词性标注、语法分析等,适用于构建和训练语言模型。
Jieba 库:支持中文文本的分词、词性标注、关键词提取等功能。
Translate 库:翻译文本。
GUI 库: UNIHIKER 的自带 UI 界面库。
Pingpong 库: UNIHIKER 的自带函数功能库。
上传代码前,请确保 UNIHIKER 上已安装 NLTK 库。输入“ pip install nltk ”在终端中进行安装,等待安装成功完成,安装成功之后再输入 “ pip install nltk ” 如下图所示。
代码: import nltk
from nltk import pos_tag
from nltk.tokenize import word_tokenize
from nltk.corpus import stopwords
from unihiker import GUI
import time
import jieba.posseg as pseg
import jieba.analyse
from nltk.sentiment import SentimentIntensityAnalyzer
from translate import Translator 复制代码 2、下载所需要的环境 nltk.download('maxent_ne_chunker')
nltk.download('words')
nltk.download('punkt')
nltk.download('averaged_perceptron_tagger')
nltk.download('stopwords')
nltk.download('vader_lexicon') 复制代码 3、基本的语法规则 ( 教师可以在这里设定不同的语法规则,以此来对学生进行不同语句的教学。) 英文缩写释义: 句子( S )由名词短语( NP )和动词短语( VP )组成 名词短语( NP )由限定词( DT )和名词( NN )组成 动词短语( VP )由动词( V )和名词短语( NP )组成 限定词( DT ) 名词( NN ) 动词( V ) 代码: grammar = nltk.CFG.fromstring("""
S -> NP VP
NP -> DT NN
VP -> V NP
DT -> 'the'
NN -> 'cat' | 'dog'
V -> 'chased'
""") # 定义一个简单的语法规则 复制代码 4、界面UI部分 我通过 UNIHIKER 自带的 GUI 库对 UNIHIKER 的屏幕进行美化。 gui.draw_round_rect() 函数为在屏幕上画方形函数, gui.fill_rect() 函数为在屏幕上填充颜色函数, title = gui.draw_text() 函数为在屏幕上打出文字函数。 代码: gui = GUI()
gui.fill_rect(x=0, y=0, w=240, h=320, color="#99CCFF")
title = gui.draw_text(x=70, y=10, text='文本分析器', font_size=14, color='blue')
gui.draw_round_rect(x=1, y=40, w=237, h=42, r=8, width=1)
gui.draw_round_rect(x=1, y=100, w=237, h=42, r=8, width=1)
gui.draw_round_rect(x=1, y=160, w=237, h=42, r=8, width=1)
gui.draw_round_rect(x=1, y=220, w=237, h=42, r=8, width=1)
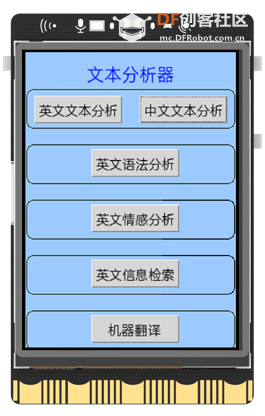
gui.draw_round_rect(x=1, y=280, w=237, h=42, r=8, width=1) 复制代码 我通过 UNIHIKER 自带的 GUI 库在 UNIHIKER 上添加所需要的按钮。通过按钮调用上文的回调函数。 button_A = gui.add_button() 为 添加所需要的按钮函数。 代码: button_A = gui.add_button(x=10, y=47, w=100, h=30, text="英文文本分析", onclick=click_A)
button_B = gui.add_button(x=130, y=47, w=100, h=30, text="中文文本分析", onclick=click_B)
button_c = gui.add_button(x=75, y=105, w=100, h=30, text="英文语法分析", onclick=click_C)
button_D = gui.add_button(x=75, y=165, w=100, h=30, text="英文情感分析", onclick=click_D)
button_E = gui.add_button(x=75, y=225, w=100, h=30, text="英文信息检索", onclick=click_E)
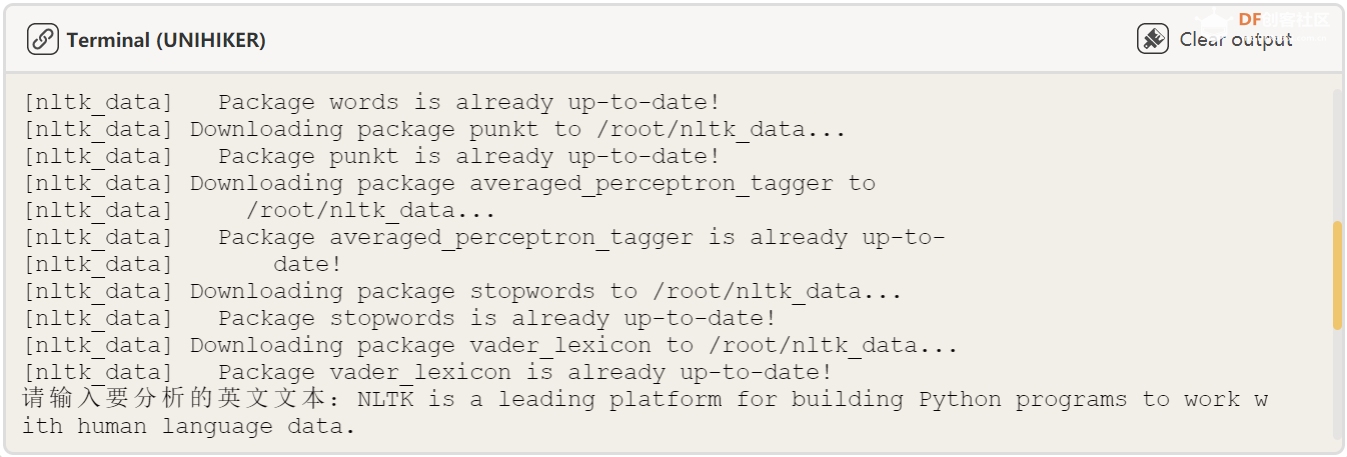
button_F = gui.add_button(x=75, y=285, w=100, h=30, text="机器翻译", onclick=click_F) 复制代码 效果展示: 5、英文文本分析部分 本节代码分三部分,都是使用了 NLTK 库中自带的函数。第一部分首先要将输入的英文文本进行分词,第二部分将文本中类似“ a ”、“ the ”这样的词略去,第三部分将去掉这些词的英文文本进行词性标注。 代码: def click_A():
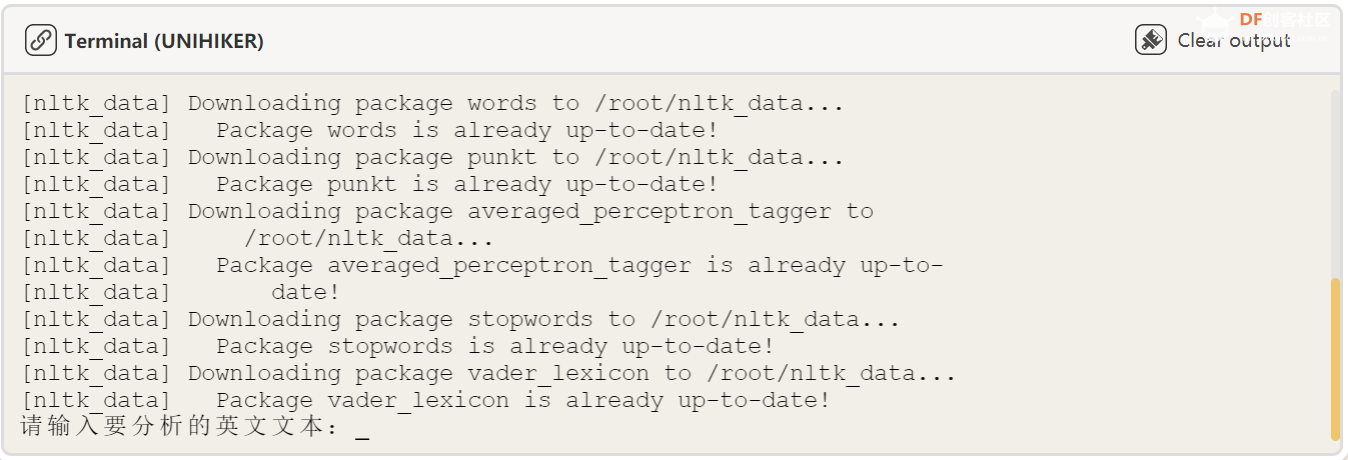
text = input("请输入要分析的英文文本:") # 输入文本
tokens = word_tokenize(text) # 分词
print("分词:")
print(tokens)
stop_words = set(stopwords.words('english')) # 去除停用词
filtered_tokens = [word for word in tokens if word.lower() not in stop_words]
print("分词略去停用词:")
print(filtered_tokens)
tagged_tokens = pos_tag(tokens) # 词性标注
print("词性标注:")
print(tagged_tokens)
print("分析完成") 复制代码 效果展示: 首先我们输入英文文本: 然后我们进行文本分析结果为:
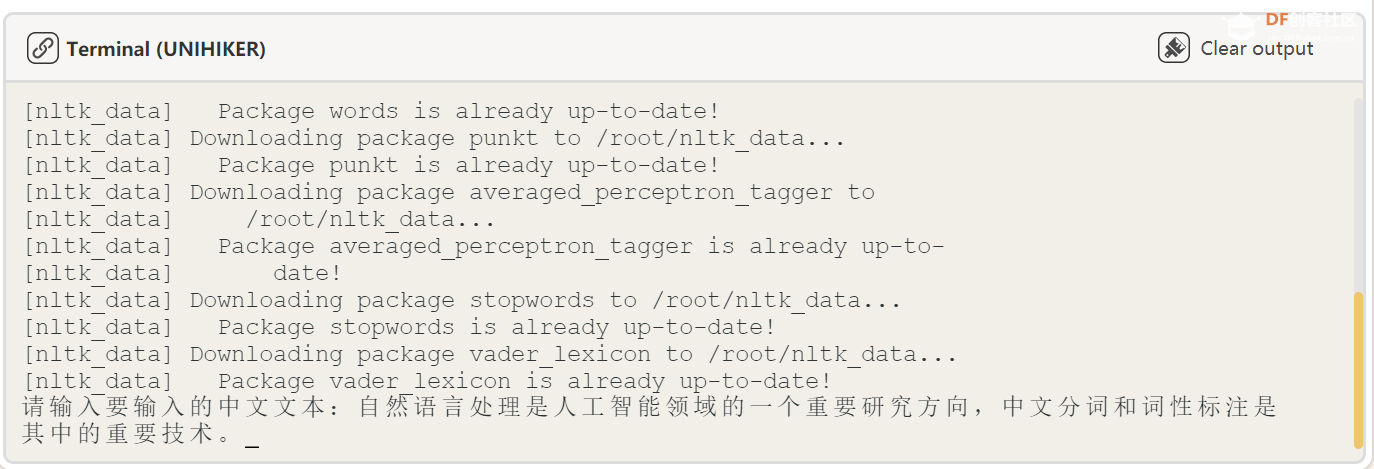
6、中文文本分析部分 本节代码与上一节代码类似,也是分为三个部分:分词、去除停用词和词性标注。只是 NLTK 库并不支持中文相关文本分析,所以我引入了 jieba 库专用于中文文本分析,请输入“ pip install jiaba ”安装 jieba 库后使用。 代码: def click_B():
text = input("请输入要输入的中文文本:")
# "自然语言处理是人工智能领域的一个重要研究方向,中文分词和词性标注是其中的重要技术。"
# 中文分词(使用 jieba)
words = list(pseg.cut(text))
tokens = [word.word for word in words]
# 去除停用词
stop_words = set(stopwords.words('chinese'))
filtered_tokens = [word for word in tokens if word not in stop_words]
# 词性标注
tagged_tokens = [(word.word, word.flag) for word in words]
# 输出结果
print("原始文本:")
print(text)
print("\n中文分词结果:")
print(tokens)
print("\n去除停用词后的结果:")
print(filtered_tokens)
print("\n词性标注结果:")
print(tagged_tokens)
print("分析完成") 复制代码 效果展示: 首先我们输入中文文本: 然后我们进行文本分析,结果为:
7、英文语法分析部分 本节代码根据上文教师自己定义的语法规则,利用 NLTK 库自带的语法分析器对语法进行分析。 代码: def click_C(): # nltk不支持中文语法处理
parser = nltk.ChartParser(grammar) # 创建一个自带语法解析器
sentence = input("请输入要分析的英文文本:") # 对句子进行语法分析
for tree in parser.parse(sentence.split()):
print(tree)
print("分析完成") 复制代码 效果展示 首先我们输入英文文本: 然后进行语法分析,结果为:
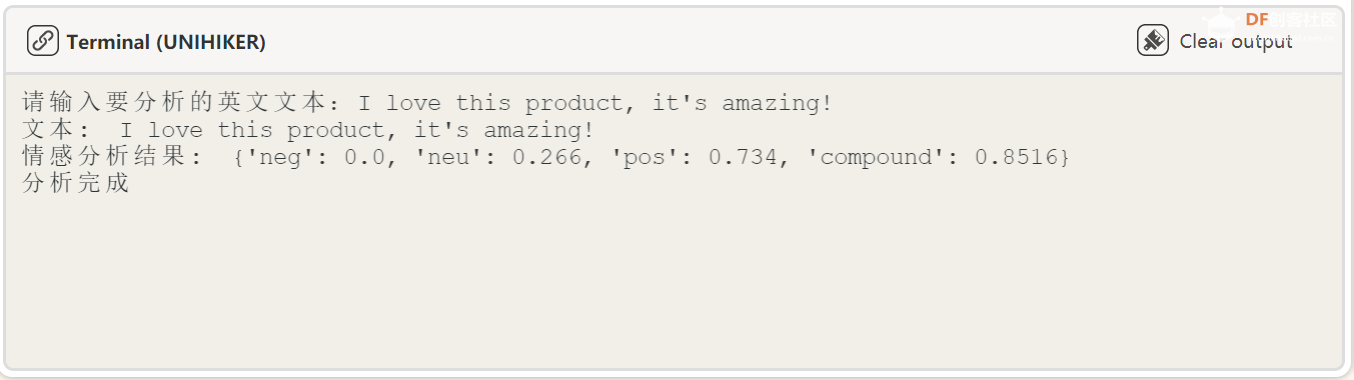
8、英文情感分析部分 本节代码利用 NLTK 库自带的情感分析器对文本进行情感分析。 我 使用了 NLTK 的 SentimentIntensityAnalyzer 类来计算文本的情感得分,分别是: neg : 表示文本中负面情感的得分; neu : 表示文本中中性情感的得分; pos : 表示文本中积极情感的得分; compound : 综合情感得分,综合考虑了 neg 、 neu 、 pos 三个得分,可以作为文本整体情感的衡量标准,取值范围为 -1 (最负面)到 1 (最积极)。 代码: def click_D():
# 创建情感分析器
sia = SentimentIntensityAnalyzer()
# 自定义文本
text = input("请输入要分析的英文文本:")
# 进行情感分析
sentiment_score = sia.polarity_scores(text)
# 输出情感分析结果
print("文本: ", text)
print("情感分析结果: ", sentiment_score)
print("分析完成")
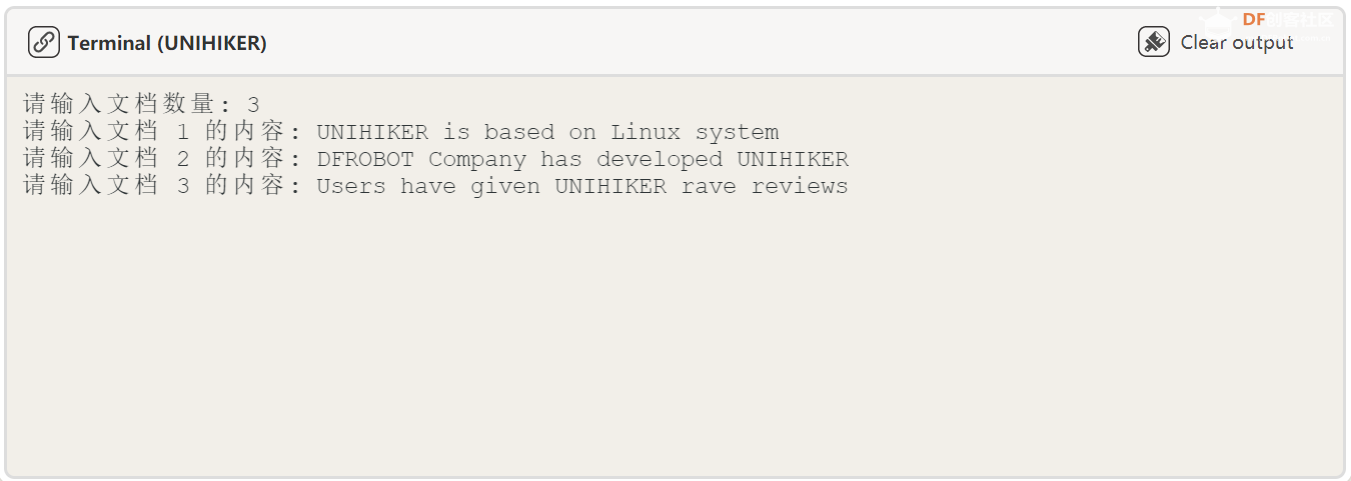
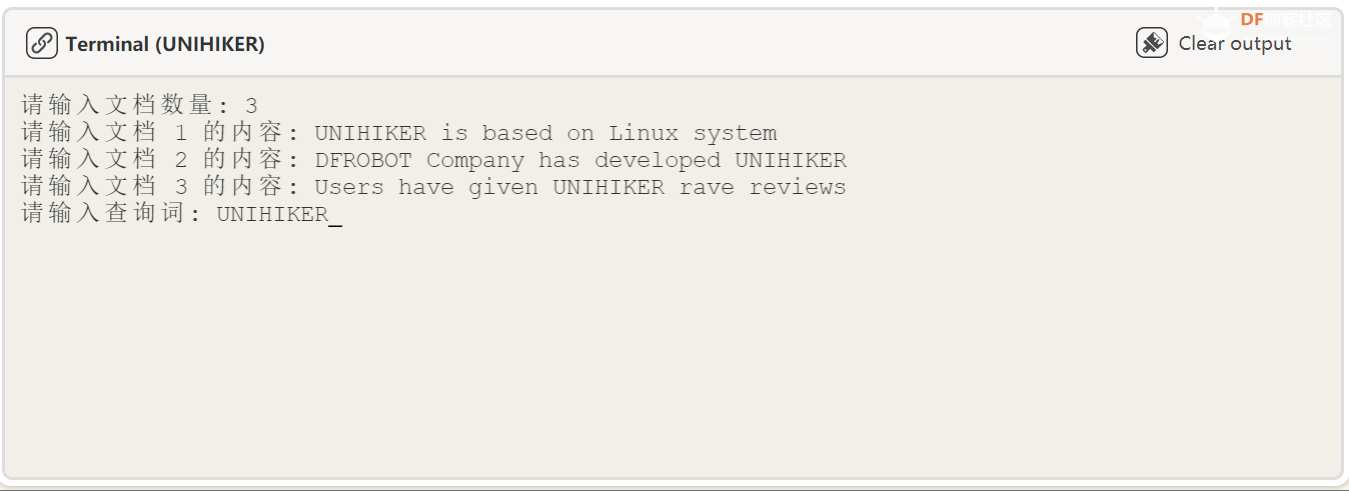
复制代码 效果展示: 首先我们输入英文文本: 9、英文信息检索部分 本节代码利用一个常见的扫描循环,将学生想输入的文本逐行扫描进入信息检索处理代码,通过构建经典的检索查找算法,利用 NLTK 库的函数进行查词定位。 代码: def click_E():
documents = {}
num_documents = int(input("请输入文档数量: "))
for i in range(1, num_documents+1):
doc_text = input(f"请输入文档 {i} 的内容: ")
documents[i] = doc_text
# 构建倒排索引
inverted_index = {}
stop_words = set(stopwords.words('english'))
for doc_id, doc_text in documents.items():
tokens = word_tokenize(doc_text.lower())
for token in tokens:
if token not in stop_words:
if token in inverted_index:
inverted_index[token].append(doc_id)
else:
inverted_index[token] = [doc_id]
# 查询词
query = input("请输入查询词: ")
# 查询倒排索引
query_tokens = word_tokenize(query.lower())
result_docs = set()
for token in query_tokens:
if token in inverted_index:
result_docs.update(set(inverted_index[token]))
# 输出查询结果
print("查询词:", query)
print("查询结果:")
for doc_id in result_docs:
print(f"Document {doc_id}: {documents[doc_id]}")
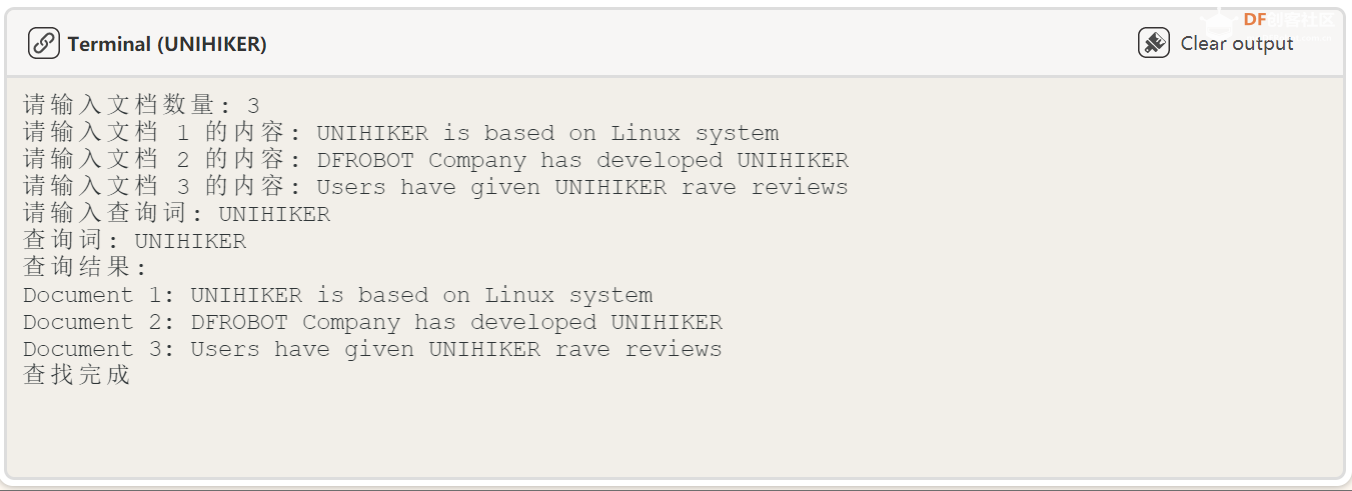
print("查找完成") 复制代码 效果展示: 首先我们输入英文文本,这里首先输入你想输入的英文文本行数,然后逐行输入: 然后我们输入查询词:
最后得出查询结果:
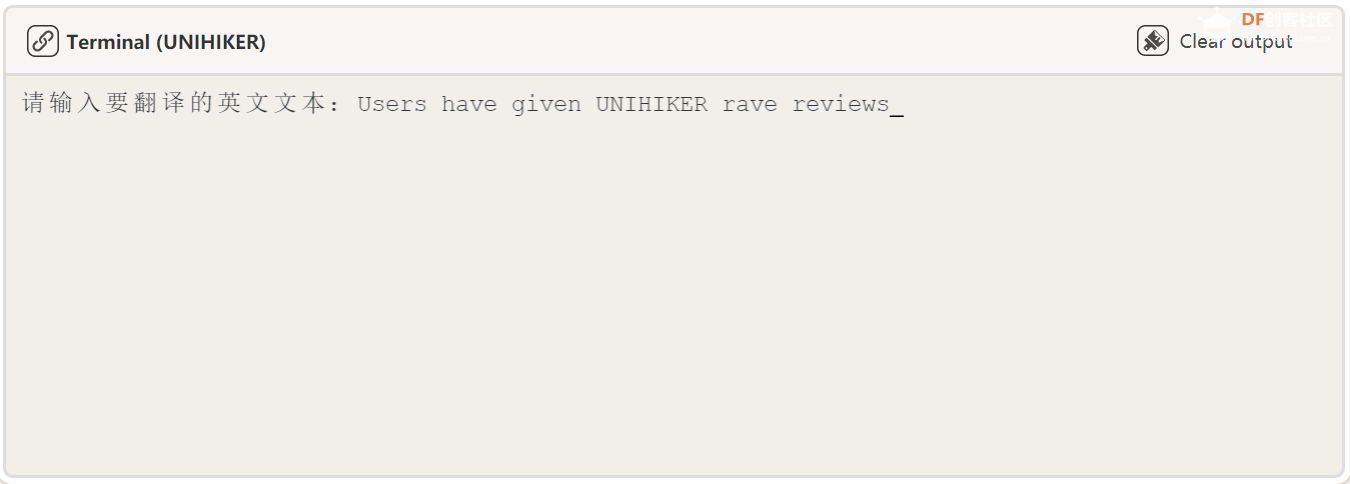
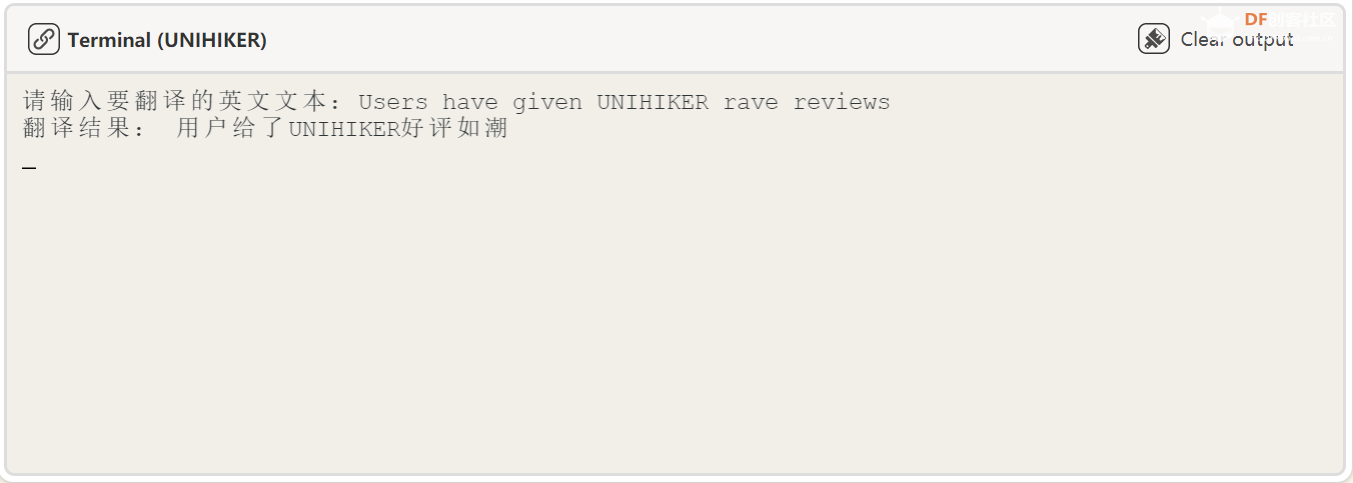
10、机器翻译部分 由于 NLTK 库的翻译功能的环境搭建需要过长的时间,这里使用了效果差不多的 translate 库实现机器翻译功能,这里最多能输入 500 个英文单词的翻译。本节代码通过构建文本翻译器,将英文翻译为中文。 代码: def click_F():
# 创建 Translator 对象
translator = Translator(to_lang="zh")
# 输入要翻译的英文文本
text_en = input("请输入要翻译的英文文本:")
# 翻译文本为中文
text_translated = translator.translate(text_en)
# 输出翻译后的中文文本
print("翻译结果:", text_translated) 复制代码 效果展示: 我们输入想要翻译的文本: 得出翻译结果:
11、代码整体展示 import nltk
from nltk import pos_tag
from nltk.tokenize import word_tokenize
from nltk.corpus import stopwords
from unihiker import GUI
import time
import jieba.posseg as pseg
import jieba.analyse
from nltk.sentiment import SentimentIntensityAnalyzer
from translate import Translator
nltk.download('maxent_ne_chunker')
nltk.download('words')
nltk.download('punkt')
nltk.download('averaged_perceptron_tagger')
nltk.download('stopwords')
nltk.download('vader_lexicon')
grammar = nltk.CFG.fromstring("""
S -> NP VP
NP -> DT NN
VP -> V NP
DT -> 'the'
NN -> 'cat' | 'dog'
V -> 'chased'
""") # 定义一个简单的语法规则
gui = GUI()
gui.fill_rect(x=0, y=0, w=240, h=320, color="#99CCFF")
title = gui.draw_text(x=70, y=10, text='文本分析器', font_size=14, color='blue')
gui.draw_round_rect(x=1, y=40, w=237, h=42, r=8, width=1)
gui.draw_round_rect(x=1, y=100, w=237, h=42, r=8, width=1)
gui.draw_round_rect(x=1, y=160, w=237, h=42, r=8, width=1)
gui.draw_round_rect(x=1, y=220, w=237, h=42, r=8, width=1)
gui.draw_round_rect(x=1, y=280, w=237, h=42, r=8, width=1)
def click_A():
text = input("请输入要分析的英文文本:") # 输入文本
tokens = word_tokenize(text) # 分词
print("分词:")
print(tokens)
stop_words = set(stopwords.words('english')) # 去除停用词
filtered_tokens = [word for word in tokens if word.lower() not in stop_words]
print("分词略去停用词:")
print(filtered_tokens)
tagged_tokens = pos_tag(tokens) # 词性标注
print("词性标注:")
print(tagged_tokens)
print("分析完成")
def click_B():
text = input("请输入要输入的中文文本:")
# "自然语言处理是人工智能领域的一个重要研究方向,中文分词和词性标注是其中的重要技术。"
# 中文分词(使用 jieba)
words = list(pseg.cut(text))
tokens = [word.word for word in words]
# 去除停用词
stop_words = set(stopwords.words('chinese'))
filtered_tokens = [word for word in tokens if word not in stop_words]
# 词性标注
tagged_tokens = [(word.word, word.flag) for word in words]
# 命名实体识别
ner_tags = nltk.ne_chunk(tagged_tokens)
# 关键词提取
keywords = jieba.analyse.extract_tags(text, topK=5)
# 输出结果
print("原始文本:")
print(text)
print("\n中文分词结果:")
print(tokens)
print("\n去除停用词后的结果:")
print(filtered_tokens)
print("\n词性标注结果:")
print(tagged_tokens)
print("分析完成")
def click_C(): # nltk不支持中文语法处理
parser = nltk.ChartParser(grammar) # 创建一个自带语法解析器
sentence = input("请输入要分析的英文文本:") # 对句子进行语法分析
for tree in parser.parse(sentence.split()):
print(tree)
print("分析完成")
def click_D():
# 创建情感分析器
sia = SentimentIntensityAnalyzer()
# 自定义文本
text = input("请输入要分析的英文文本:")
# 进行情感分析
sentiment_score = sia.polarity_scores(text)
# 输出情感分析结果
print("文本: ", text)
print("情感分析结果: ", sentiment_score)
print("分析完成")
def click_E():
documents = {}
num_documents = int(input("请输入文档数量: "))
for i in range(1, num_documents+1):
doc_text = input(f"请输入文档 {i} 的内容: ")
documents[i] = doc_text
# 构建倒排索引
inverted_index = {}
stop_words = set(stopwords.words('english'))
for doc_id, doc_text in documents.items():
tokens = word_tokenize(doc_text.lower())
for token in tokens:
if token not in stop_words:
if token in inverted_index:
inverted_index[token].append(doc_id)
else:
inverted_index[token] = [doc_id]
# 查询词
query = input("请输入查询词: ")
# 查询倒排索引
query_tokens = word_tokenize(query.lower())
result_docs = set()
for token in query_tokens:
if token in inverted_index:
result_docs.update(set(inverted_index[token]))
# 输出查询结果
print("查询词:", query)
print("查询结果:")
for doc_id in result_docs:
print(f"Document {doc_id}: {documents[doc_id]}")
print("查找完成")
def click_F():
# 创建 Translator 对象
translator = Translator(to_lang="zh")
# 输入要翻译的英文文本
text_en = input("请输入要翻译的英文文本:")
# 翻译文本为中文
text_translated = translator.translate(text_en)
# 输出翻译后的中文文本
print("翻译结果:", text_translated)
button_A = gui.add_button(x=10, y=47, w=100, h=30, text="英文文本分析", onclick=click_A)
button_B = gui.add_button(x=130, y=47, w=100, h=30, text="中文文本分析", onclick=click_B)
button_c = gui.add_button(x=75, y=105, w=100, h=30, text="英文语法分析", onclick=click_C)
button_D = gui.add_button(x=75, y=165, w=100, h=30, text="英文情感分析", onclick=click_D)
button_E = gui.add_button(x=75, y=225, w=100, h=30, text="英文信息检索", onclick=click_E)
button_F = gui.add_button(x=75, y=285, w=100, h=30, text="机器翻译", onclick=click_F)
while True: # circulate
time.sleep(0.5) # Delay by 0.5 seconds 复制代码 第三部分:总结 本项目通过 NLTK 库、 jieba 库、 translate 库构建了一个基于中小学语法教育、中英文文本分析场景下的简单文本分析助手,目的在于能够通过将便携式的移动平台 UNIHIKER 、高性能的文本处理语言 python 和最流行的文本处理语言模型 NLTK 库等结合起来,针对语言教学中最困难的文本分析部分进行教学新模式的探索。利用基于 UNIHIKER 构建的便携式文本分析助手,学生能够自主地进行语法和文本分析的学习,在不知不觉中提高自己的语言能力。 







 沪公网安备31011502402448
沪公网安备31011502402448

 置顶卡
置顶卡 变色卡
变色卡 千斤顶
千斤顶







