本帖最后由 lickies 于 2025-1-2 15:31 编辑
一、系统目标
使用 K10 在 micropython 刷机版本下实现大模型的调用,打造 K10 大模型对话机器人,通过特定按键操作实现角色选择及内容输入,具备录音、声音转文本、文本调用大模型获取答案、答案转声音以及声音播放等功能,以满足用户便捷的对话交互需求。 二、开发的背景和意义
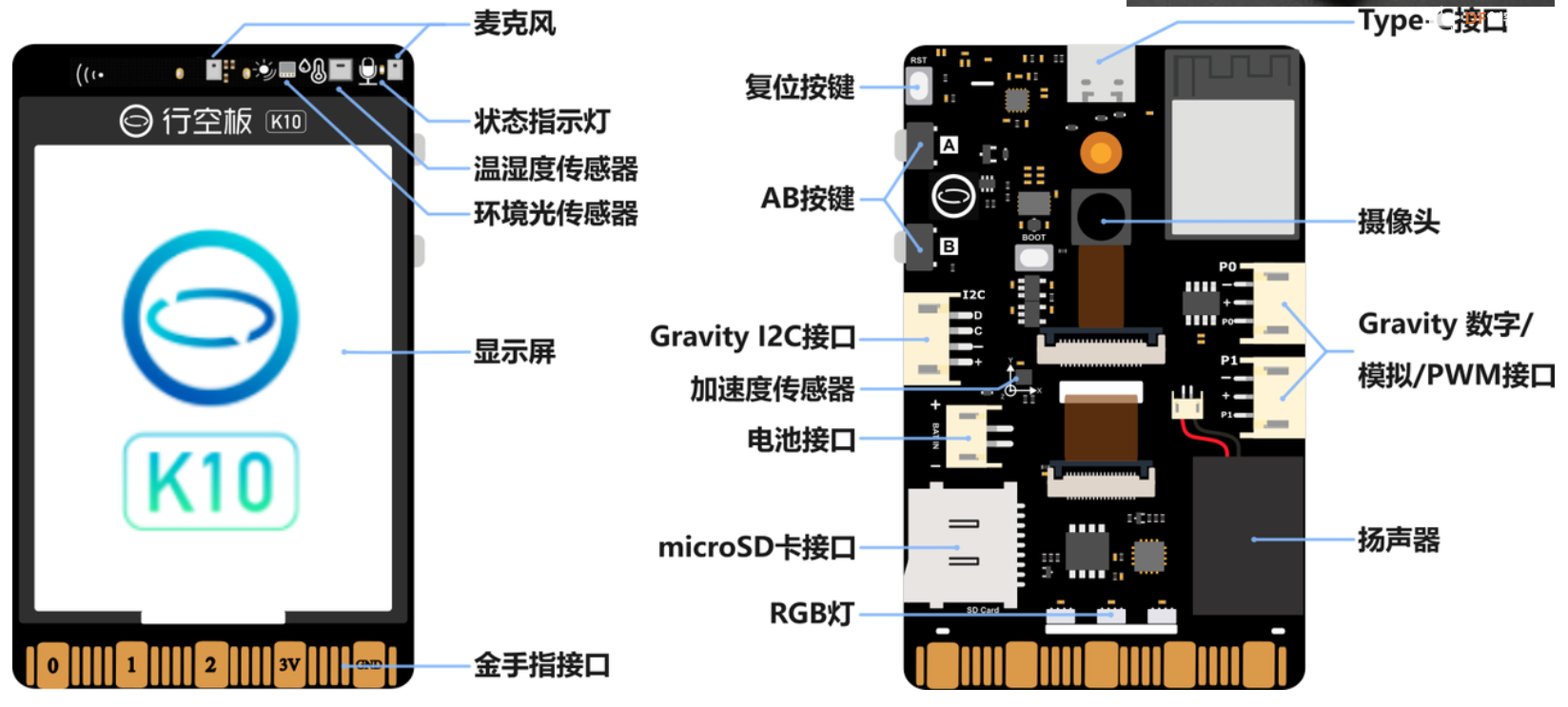
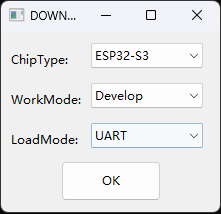
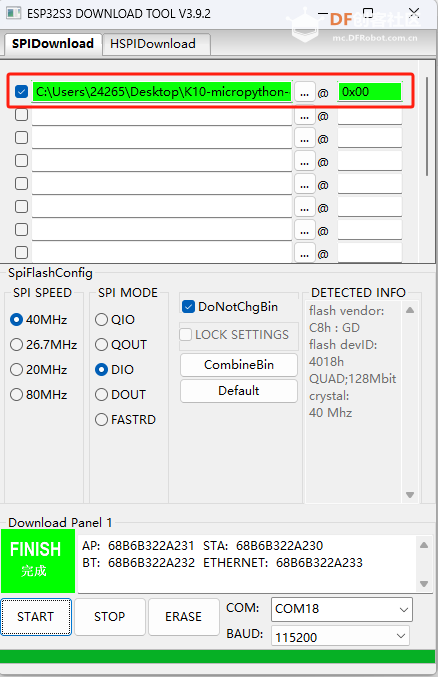
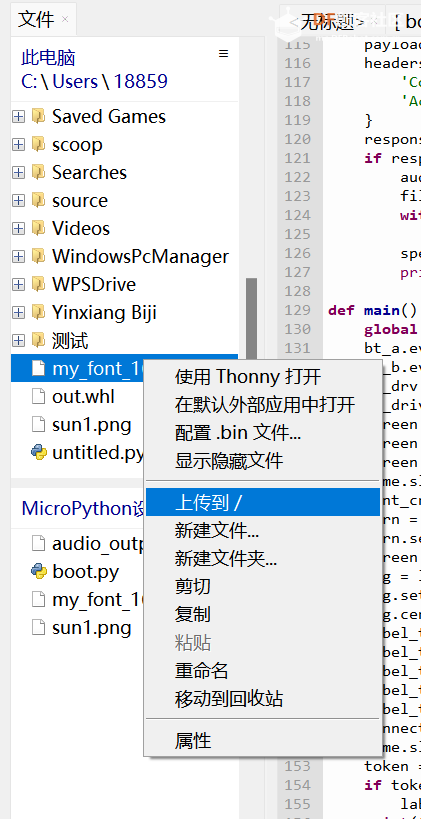
随着人工智能技术的飞速发展,大模型在自然语言处理领域展现出强大的能力,能够为用户提供精准、智能的信息解答。在日常生活和工作中,人们对于智能对话设备的需求日益增长,希望能够通过简单的操作与设备进行自然流畅的对话,获取各种知识和信息。本项目旨在利用 K10 硬件平台结合 micropython 编程环境,开发一款具有实用价值的大模型对话机器人,为用户提供更加便捷、高效的交互体验,同时也为硬件开发与人工智能技术的融合应用提供一种可行的解决方案,推动智能硬件设备在更多场景中的应用和发展。 三、项目整体开发概况 1、硬件选型:选择 K10 作为核心开发板,其具备足够的性能来运行 micropython 操作系统,并支持与各种外部设备的连接,如麦克风、扬声器等,为实现对话机器人的各项功能提供硬件基础。 本次采用的K10用到的传感器如下: 麦克风 图片显示(显示屏) 文字显示(显示屏) urequest网络库 扬声器 2、软件环境搭建:对 K10 进行 micropython 刷机操作,搭建稳定的开发环境,确保能够顺利进行后续的代码编写和调试工作。 3、功能模块开发: 按键功能实现:通过编程设置,当按下 B 键时,实现角色选择功能,若未选择则默认设定为 “万事通” 角色;按下 A 键时,准备接收用户要输入的对话内容。 l 录音模块:连接合适的麦克风到 K10 开发板,利用 micropython 的音频处理库,实现对用户语音的录制功能,并将录制的音频数据进行存储,以便后续处理。 l 声音转文本模块:采用成熟的语音识别技术或相关的语音转文字库,将录制的音频数据转换为文本格式,为调用大模型做准备。 l 文本调用大模型模块:利用网络连接功能,将转换后的文本发送到大模型的接口,获取大模型生成的答案文本。这需要与特定的大模型平台进行对接,遵循其 API 规范进行数据交互和请求处理。 l 答案转声音模块:借助文字转语音(TTS)技术,将大模型返回的文本答案转换为语音数据,以便通过扬声器播放给用户。 l 声音播放模块:连接扬声器到 K10 开发板,编写代码实现对转换后的语音数据进行播放,将大模型的回答以声音的形式呈现给用户,完成整个对话交互流程。 4、系统集成与测试:在各个功能模块开发完成后,进行系统的集成工作,确保各个模块之间的协同工作正常,对整个对话机器人进行全面的测试,包括不同场景下的对话测试、按键操作测试、音频输入输出测试等,针对测试过程中发现的问题进行优化和修复,以提高系统的稳定性和可靠性,最终实现一个能够稳定运行、准确回答用户问题的 K10 大模型对话机器人。 四、项目详细开发步骤 1、刷机教程。 1)下载ESP32固件烧录器 点击下载 2)下载固件文件 固件下载 3)打开esp32固件烧录器 选择esp32-s3 点击OK 4)选择对应的文件,填入相应地址,并勾选最前面的对号,注意输入0x00 5)按住行空板K10背面的BOOT按钮,连接板子与电脑,在软件中选择对应的端口 6)先点击“ERASE”清除flsh,待成功后再点击"START"进行烧录 7)烧录完成后摁下行空板K10板子的RST复位键 2、开发环境设置 1)下载thonny 点击下载 2)插上k10 打开thonny 点击右下角选择硬件 3)打开左侧文件夹窗格 点击上方菜单的视图,点击文件(为了后面拷贝程序到设备上) 4)编写python程序 五、程序开发步骤 1)引入库
- #引用区
-
- from unihiker_k10 import screen#屏幕
-
- from unihiker_k10 import camera#摄像头
-
- from unihiker_k10 import tf_card#tf卡
-
- from unihiker_k10 import temp_humi#温湿度
-
- from unihiker_k10 import light#光敏
-
- from unihiker_k10 import acce#重力传感器
-
- from unihiker_k10 import rgb#颜色灯
-
- from unihiker_k10 import button#按钮
-
- from unihiker_k10 import mic#麦克风
-
- from unihiker_k10 import wifi#wifi
-
- from unihiker_k10 import speaker#扬声器
-
- import urequests #网络请求库
-
- import ujson #json格式转化库
-
- import time#时间库
-
- import os#文件库获取存储声音
-
- import lvgl as lv#显示库,文字和图片
-
- import fs_driver, math#字体读取库
1)加载字体 解释:由于k10默认的加载文字和字体不支持,所以我们需要用lv库自动加载字体的方式解决。 首先将字体文件 点击下载 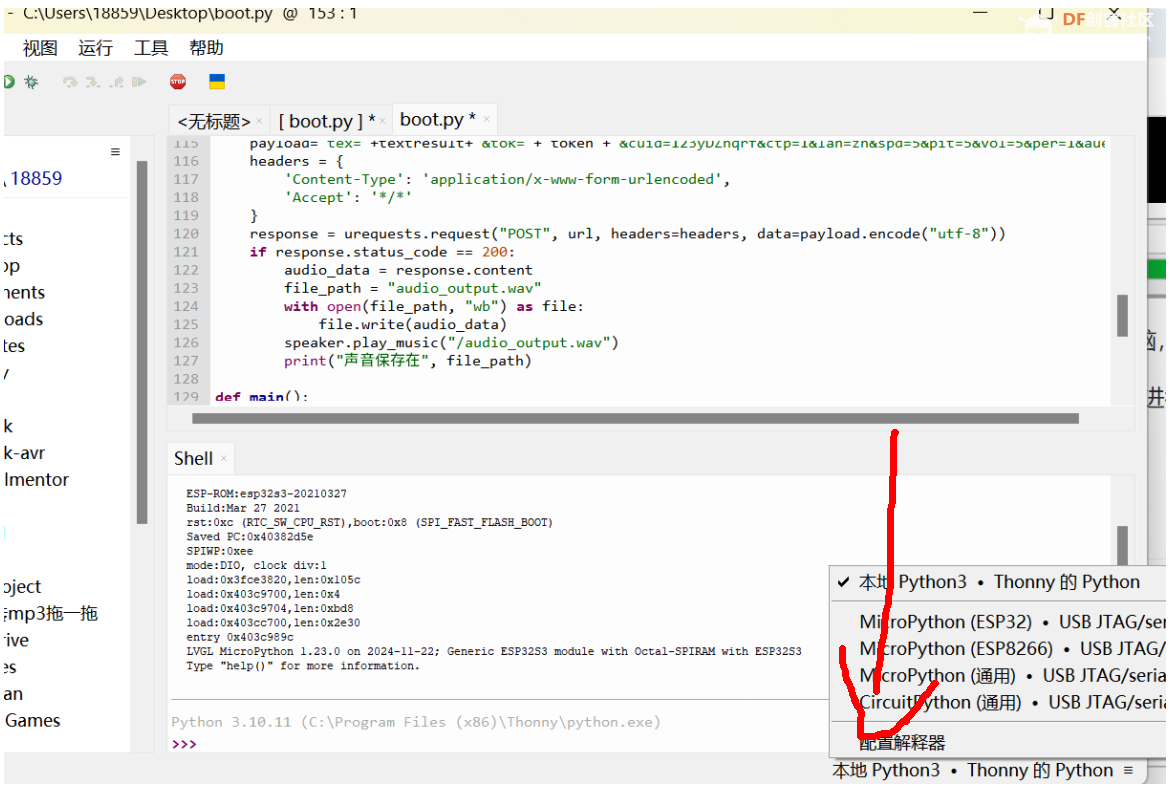 下载到硬件上 其次在MAIN里增加代码
- fs_drv = lv.fs_drv_t()
- fs_driver.fs_register(fs_drv, 'S')
- font_cn = lv.binfont_create("S:my_font_16.bin") #加载字体
- scrn = lv.screen_active() #加载文字显示屏幕
- scrn.set_style_bg_color(lv.color_hex(0x000000), 0)
- label_title = lv.label(scrn) #新建label
- label_title.set_text("文字加载成功\n")
- label_title.set_width(230)
- label_title.align(lv.ALIGN.TOP_LEFT, 8, 8)
- label_title.set_style_text_font(font_cn, 0) # 设置中文字体
2)连接wifi
复制代码
- 在上方定义函数
- def connect_wifi():
- print("正在连接wifi...")
- screen.show_draw()
- wifi.connect(ssid="MAMALE", psd="1234567890", timeout=10000)
- if not wifi.status():
- while not wifi.status():
- time.sleep(1)
- print("网络链接成功")
请将ssid和密码修改为你自己的。
3)获取百度语音平台的token
- 登录百度ai平台https://ai.baidu.com/并点击右上角控制台 点击中间的语音技术(如果没有就搜索)
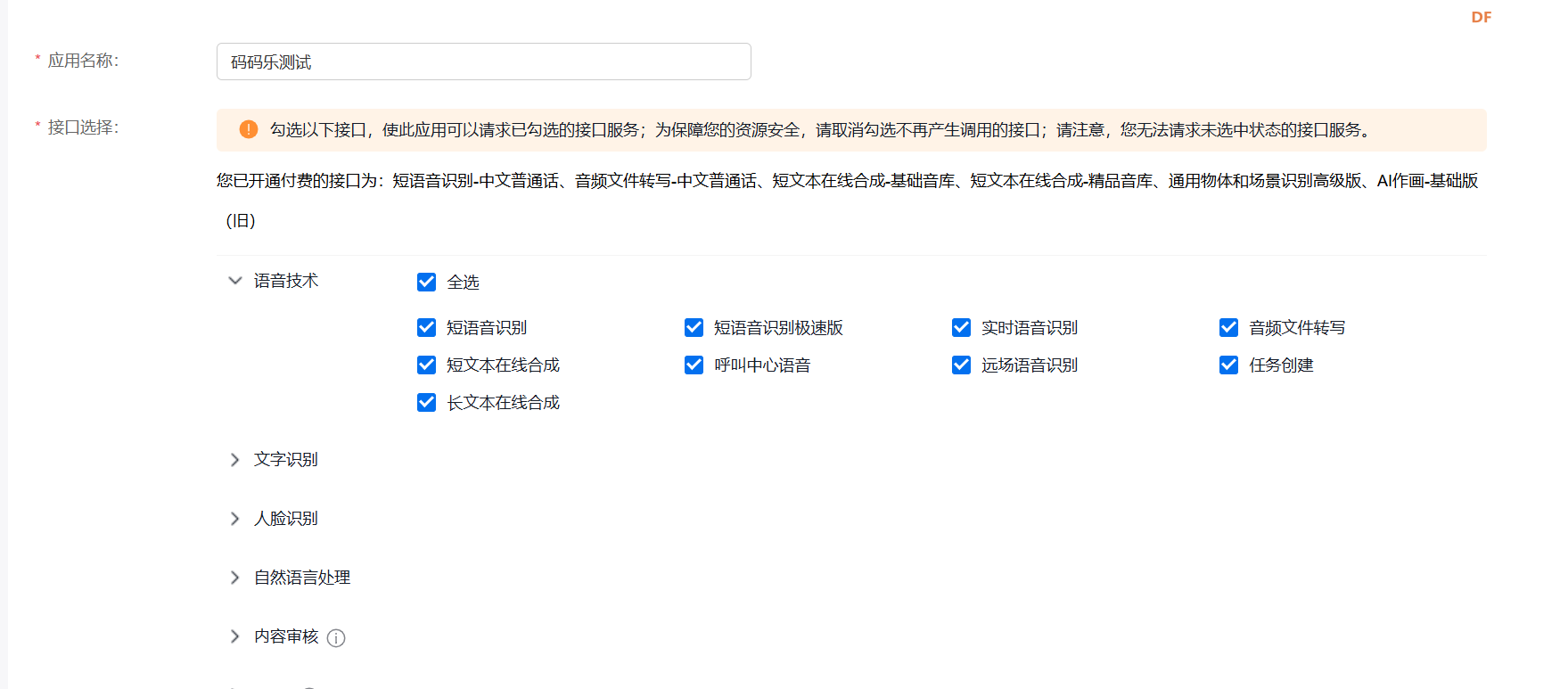
- 复制出你的API Key和Secret Key。等下调用代码有需要

- token = get_baidu_token() # 获取百度 API 访问令牌
- if token=="":
- label_title.set_text("获取不到token\n")
- print(token)
- 新增get_baidu_token()函数,并自行修改自己的appid和key
- def get_baidu_token():
- token_url = "https://aip.baidubce.com/oauth/2.0/token"
- headers = {'Content-Type': 'application/data; charset=UTF-8'}
- payload1="grant_type=client_credentials&client_id=修改为你的APPID&client_secret=修改为你自己的key"
- response = urequests.post(token_url, data=payload1, headers=headers)
- result = ujson.loads(response.text)
- return result.get('access_token')
4)获取百度大模型平台的llmtoken - 登录百度ai平台https://ai.baidu.com/并点击右上角控制台 点击中间的百度智能云千帆(如果没有就搜索)

图片可下载  (100*100) (100*100)
- img = lv.image(scrn)
- img.set_src("S:sun1.png") #加载图片
- img.center()
4.全部代码解析 -
- #引用区
- from unihiker_k10 import screen#屏幕
- from unihiker_k10 import camera#摄像头
- from unihiker_k10 import tf_card#tf卡
- from unihiker_k10 import temp_humi#温湿度
- from unihiker_k10 import light#光敏
- from unihiker_k10 import acce#重力传感器
- from unihiker_k10 import rgb#颜色灯
- from unihiker_k10 import button#按钮
- from unihiker_k10 import mic#麦克风
- from unihiker_k10 import wifi#wifi
- from unihiker_k10 import speaker#扬声器
- import urequests #网络请求库
- import ujson #json格式转化库
- import time#时间库
- import os#文件库获取存储声音
- import lvgl as lv#显示库,文字和图片
- import fs_driver, math#字体读取库
-
- # 初始化变量区
- bt_a=button(button.a)#初始化板载按键传感器 A
- bt_b=button(button.b)#初始化板载按键传感器 B
- type_a=0#设置变量,防止重复按a按键
- type_b=0#设置变量,防止重复按b按键
- token = None # 全局变量, 存储百度语音的token
- llmtoken = None # 全局变量 存储百度大模型的token
- hitext=None #语音输入的文字存储
- role="无所不知的万事通"
- textresult=None#大模型返回的文字存储
- label_title=None#屏幕文字的变量存储
- def button_a_pressed():
- global token,llmtoken,hitext,type_a,textresult,role # 声明我们要使用全局变量
- if type_a==0:
- type_a=1
- mic.recode_tf(name="demo.wav", time=5)# 录制音频
- hitext=send_audio_to_baidu(token)# 发送音频文件到百度语音识别接口
- textresult=send_text_to_baidullm(hitext,llmtoken,role)
- speaktext(token,textresult)
- type_a=0
- def button_b_pressed():
- global token,llmtoken,hitext,type_b,textresult,role # 声明我们要使用全局变量
- if type_b==0:
- type_b=1
- mic.recode_tf(name="demo.wav", time=5)# 录制音频
- role=send_audio_to_baidu(token)# 发送音频文件到百度语音识别接口
- speaktext(token,"设置角色为"+role)
- type_b=0
- def connect_wifi():
- print("正在连接wifi...")
- screen.show_draw()
- wifi.connect(ssid="MAMALE", psd="1234567890", timeout=10000)
- if not wifi.status():
- while not wifi.status():
- time.sleep(1)
- print("网络链接成功")
- def get_baidu_token():
- token_url = "https://aip.baidubce.com/oauth/2.0/token"
- headers = {'Content-Type': 'application/data; charset=UTF-8'}
- payload1="grant_type=client_credentials&client_id=vXrYHOgMtprFqBPAEtOMLgnh&client_secret=ej74ideuw8tYDJRdosnbkKj7yAnxodcX"
- response = urequests.post(token_url, data=payload1, headers=headers)
- result = ujson.loads(response.text)
- return result.get('access_token')
- def get_baiduLLM_token():
- token_url = "https://aip.baidubce.com/oauth/2.0/token"
- headers = {'Content-Type': 'application/data; charset=UTF-8'}
- payload1="grant_type=client_credentials&client_id=EOSj7l6NztlPSoW3WEHHBKr7&client_secret=WSZMRM7sqxNvkCyVGP9DAA8NQyjNxU0g"
- response = urequests.post(token_url, data=payload1, headers=headers)
- result = ujson.loads(response.text)
- return result.get('access_token')
- def display_result(response_json):
- global token,llmtoken,hitext
- atext=""
- if 'result' in response_json:
- result_list = response_json['result']
- for result in result_list:
- atext=atext+result.encode('utf-8').decode('unicode_escape')
- else:
- print("No result found in the response.")
- return atext
- def send_audio_to_baidu(token):
- llmtoken,hitext
- with open("/sd/demo.wav", 'rb') as f:
- audio_data = f.read()
- headers = {
- 'Content-Type': 'audio/wav; rate=16000',
- 'Authorization': 'Bearer ' + token
- }
- url = "https://vop.baidu.com/server_api?format=wav&dev_pid=1537&rate=16000&channel=1&cuid=3&token=" + token
- response =urequests.request("POST", url, data=audio_data,headers=headers)
- result = ujson.loads(response.text)
- print(display_result(result))
- return display_result(result)
- def send_text_to_baidullm(hitext,llmtoken,role):
- payload = {
- "messages": [
- {
- "role": "user",
- "content": "假设你是一名"+str(role)+",你的问题是"+str(hitext)+"请给我50个字以内的回复,最后加上一个完字作为结束"
- }
- ]
- }
- json_payload = ujson.dumps(payload)
- json_payload_bytes = json_payload.encode('utf-8')
- headers = {
- 'Content-Type': 'application/json'
- }
- url = "https://aip.baidubce.com/rpc/2.0/ai_custom/v1/wenxinworkshop/chat/completions_pro?access_token=" + llmtoken
- response = urequests.request("POST", url, headers=headers, data=json_payload_bytes)
- response_data = ujson.loads(response.text)
- print(response_data.get("result"))
- return response_data.get("result")
- def speaktext(token,textresult):
- url = "https://tsn.baidu.com/text2audio"
- payload='tex='+textresult+'&tok='+ token +'&cuid=123yDZhqrf&ctp=1&lan=zh&spd=5&pit=5&vol=5&per=1&aue=6'
- headers = {
- 'Content-Type': 'application/x-www-form-urlencoded',
- 'Accept': '*/*'
- }
- response = urequests.request("POST", url, headers=headers, data=payload.encode("utf-8"))
- if response.status_code == 200:
- audio_data = response.content
- file_path = "audio_output.wav"
- with open(file_path, "wb") as file:
- file.write(audio_data)
- speaker.play_music("/audio_output.wav")
- print("声音保存在", file_path)
-
- def main():
- global token,llmtoken, label_title # 声明我们要使用全局变量
- bt_a.event_pressed = button_a_pressed #设置a按键的事件参数
- bt_b.event_pressed = button_b_pressed #设置B按键的事件参数
- fs_drv = lv.fs_drv_t()
- fs_driver.fs_register(fs_drv, 'S')
- screen.init(dir=2)
- screen.draw_text(text=" Loading......\n",line=6,font_size=24,color=0xFFFFFF)
- screen.show_draw()
- time.sleep(1)
- font_cn = lv.binfont_create("S:my_font_16.bin") #加载字体
- scrn = lv.screen_active() #加载文字显示屏幕
- scrn.set_style_bg_color(lv.color_hex(0x000000), 0)
- screen.clear()
- img = lv.image(scrn)
- img.set_src("S:sun1.png") #加载图片
- img.center()
- label_title = lv.label(scrn) #新建
- label_title.set_text("文字加载成功\n")
- label_title.set_width(230)
- label_title.align(lv.ALIGN.TOP_LEFT, 8, 8)
- label_title.set_style_text_font(font_cn, 0) # 设置中文字体
- connect_wifi()# 连接 Wi-Fi
- time.sleep(1)
- token = get_baidu_token() # 获取百度 API 访问令牌
- if token=="":
- label_title.set_text("获取不到token\n")
- print(token)
- llmtoken=get_baiduLLM_token() # 获取百度 API 访问令牌
- if llmtoken=="":
- label_title.set_text("获取不到token\n")
- print(llmtoken)
- label_title.set_text("按A说问题,按B说角色例如老师、科学家、爱因斯坦\n")
-
-
- if __name__ == "__main__":
- main()
-
5.项目中可能存在的经验: 重新刷新后需要重新上传字体 - 系统刚开始加载字体需要一些时间,因为默认字体是所有字体。如果想缩短时间也可以自行生成字体,可以只输入你想加载的字体。
- 因为担心大模型返回的字体比较多,我们可以在提示词输入,请给我70个字以内的回复
- 此程序为范例程序,按照程序的健全性需要增加各种文件是否存在的判断
- 因为百度语音转化后,最后一个字默认会被剪掉,所以我增加了一个文字“完”
整体演示视频如下:
|




 沪公网安备31011502402448
沪公网安备31011502402448
 置顶卡
置顶卡 变色卡
变色卡 千斤顶
千斤顶







