|
22972| 0
|
[动态] 分享8 个TinyML框架和兼容硬件平台(TensorFlow Lite、Edge ... |

|
<p>TinyML 框架提供了强大而高效的基础架构,使组织和开发人员能够有效地利用其数据并在边缘设备上部署高级算法。这些框架提供了专门设计用于推动 Tiny Machine Learning 战略计划的各种工具和资源。本文重点介绍了用于 TinyML 实现的 8 个知名框架,例如 TensorFlow Lite (TF Lite)、Edge Impulse、PyTorch Mobile、uTensor,以及 STM32Cube.AI、NanoEdgeAIStudio、NXP eIQ 和 Microsoft 的嵌入式学习库等平台。它还概述了这些框架的兼容硬件平台和目标应用程序,帮助用户快速识别最合适的 TinyML 框架。</p> <h2>什么是 TinyML?</h2> <p>TinyML 是机器学习的一个分支,专注于在低功耗、小尺寸微控制器(如 Arduino)上创建和实施机器学习模型。机器学习模型需要大量计算能力。它不能用于在依靠电池供电的设备上制作模型,在这种情况下使用微型机器学习 (tinyML)。</p> <h2>为什么我们需要 TinyML?</h2> <p>TinyML 支持在小型微控制器(包括 Raspberry Pi 和 ESP32 等设备)上执行机器学习模型。虽然这些设备非常出色,但即使是最小的 Raspberry Pi 也会消耗数百毫瓦的功率,与主 CPU 类似。</p> <h3>tinyML 可以实现于:</h3> <ul> <li>紧凑且低成本的设备(微控制器)功耗极低(tinyML 消耗的功率不到一毫瓦)</li> <li>内存容量有限</li> <li>低滞后时间(几乎即时)集成机器学习算法分析。</li> </ul> <h2>什么是 TinyML 框架?</h2> <p>TinyML 框架是一种专用软件或工具,可帮助开发人员和工程师训练专为部署在边缘设备和嵌入式系统上的机器学习模型。这些平台提供必要的基础设施、算法和资源,以促进 Tiny 机器学习 (TinyML) 模型的训练过程,这些模型经过优化,可在资源受限且功耗低的设备上运行。TinyML 框架通常支持数据收集、模型训练、优化和部署在边缘设备上等任务,从而可以开发针对边缘计算环境量身定制的高效机器学习模型。</p> <h2>8 个 TinyML 框架</h2> <h3>1. TensorFlow Lite</h3> <p>TensorFlow 是 Google 的开源机器学习框架,可帮助快速开发机器学习模型。对于 TinyML,有 TensorFlow Lite Micro,它是 TensorFlow 的专用版本,适用于微控制器和其他只有几千字节内存的设备。核心运行时在 Arm Cortex M3 上仅占 16 KB,可以运行许多基本模型。它不需要操作系统支持、任何标准 C 或 C++ 库或动态内存分配。它主要与<a href="https://developer.arm.com/Processors#aq=%40navigationhierarchiesproducts%3D%3D%22IP%20Products%22%20AND%20%40navigationhierarchiescontenttype%3D%3D%22Product%20Information%22&numberOfResults=48&f[navigationhierarchiesprocessortype]=Microcontrollers">Arm Cortex-M 系列</a>处理器兼容。<a href="https://www.espressif.com/en/products/socs/esp32">ESP32端口</a>也可用。 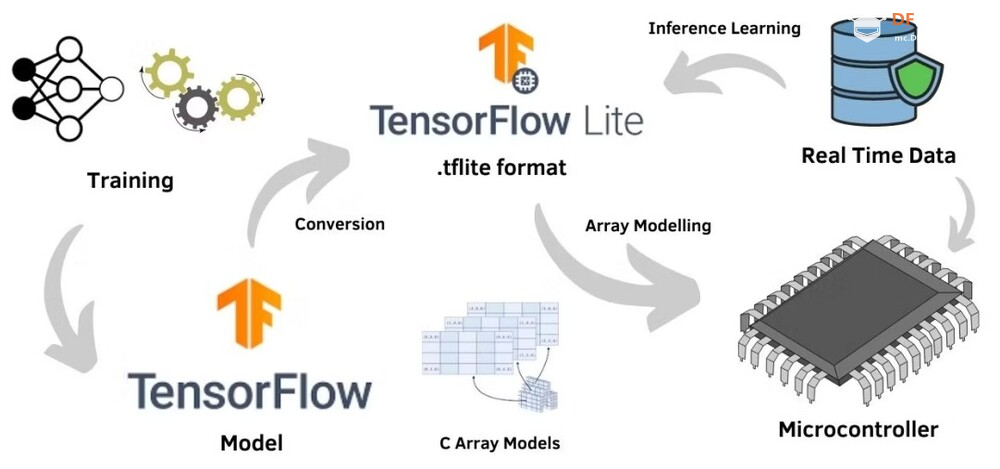 TensorFlow Lite </p><h3>主要优势</h3> <ul> <li>**快速推理:**利用 GPU 和 DSP 等硬件加速器,实现移动设备上的快速处理。这为对象检测和手势识别等实时应用提供了快速高效的推理。</li> <li>**灵活性:**此格式支持 Android、iOS、Linux 和微控制器,因此适用于不同的设备。有关支持的详细硬件平台,请参阅表一:8 个 TinyML 框架的硬件平台。</li> <li><strong>易于集成:</strong> TensorFlow Lite 与现有的 TensorFlow 工作流程无缝集成,允许开发人员使用 TensorFlow 的工具和库训练模型,然后将其转换为 TensorFlow Lite 格式以进行移动和嵌入式部署。TensorFlow Lite 还提供与 Python、Java 和 C++ 等流行编程语言兼容的 API,从而可以轻松地将机器学习功能集成到移动和嵌入式应用陈旭中。</li> </ul> <h3>限制</h3> <p>适用于微控制器的 TensorFlow Lite 专为微控制器开发的特定约束而设计。如果您正在开发功能更强大的设备(例如,Raspberry Pi 等嵌入式 Linux 设备),则标准 TensorFlow Lite 框架可能更易于集成。</p> <p>应考虑以下限制:</p> <ul> <li>支持有限的 TensorFlow 操作子集</li> <li>支持有限的设备</li> <li>需要手动内存管理的低级 C++ API</li> <li>不支持设备上训练</li> </ul> <h2>2. 边缘脉冲</h2> <p>Edge Impulse 提供最新的机器学习工具,使所有企业都能构建更智能的边缘产品。Edge Impulse 无疑是任何人收集数据、训练模型并将其部署在微控制器上的最简单方法。</p> <h3>Edge Impulse 的主要优势</h3> <h4>边缘 AI 生命周期</h4> <p>Edge Impulse 可帮助完成边缘 AI 生命周期的每个步骤,包括收集数据、提取特征、设计机器学习 (ML) 模型、训练和测试这些模型以及将模型部署到终端设备。Edge Impulse 可轻松插入其他机器学习框架,以便您可以根据需要扩展和自定义模型或管道。<br /> 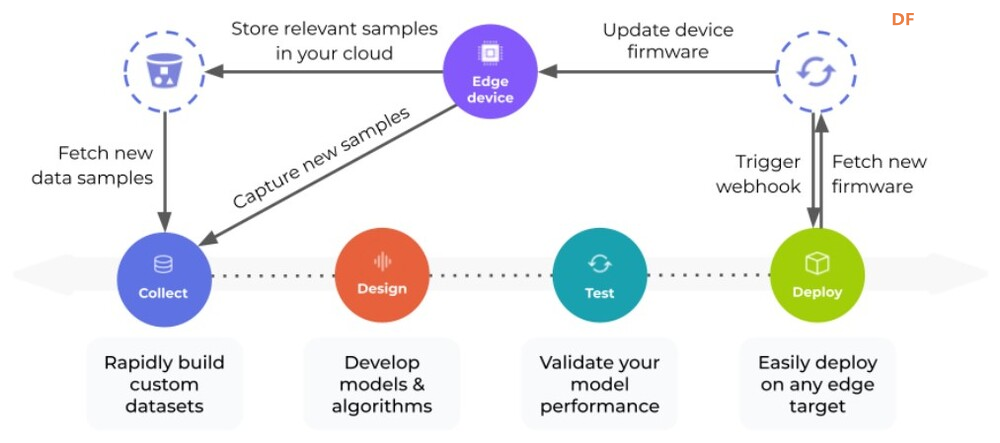 <h3>边缘优化神经 (EON™) 编译器</h3> <p>优化神经 (EON™) 编译器,与微控制器版 TensorFlow Lite 相比,它可以让您在减少 25-55% 的 RAM 和减少高达 35% 的闪存的情况下运行神经网络,同时保持相同的准确性。</p> <p>以下是 EON 对 Edge Impulse 中典型模型的影响示例。下面您将看到在 Cortex-M4F 上运行的带有 2D 卷积神经网络的关键字识别模型的每次推理时间、RAM 和 ROM 使用情况。顶部:EON,底部:使用 TensorFlow Lite for Microcontrollers 运行的相同模型。<br /> 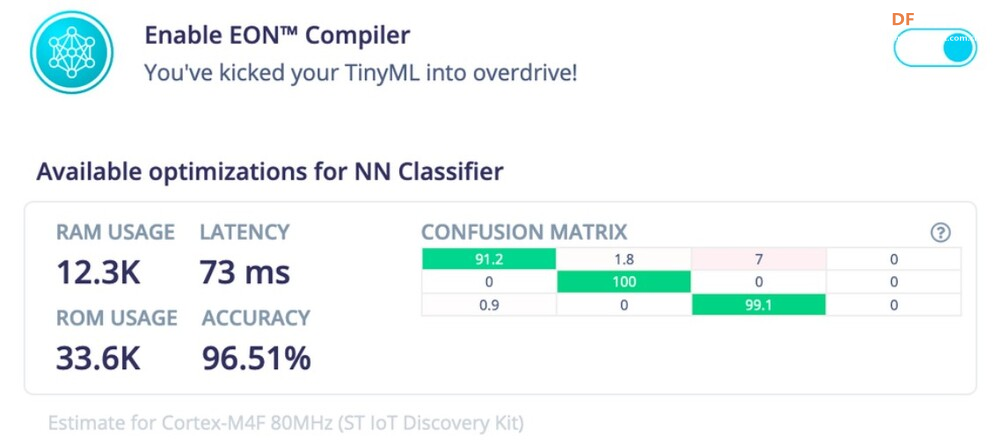 在 EON 下运行的 2D 卷积神经网络 </p><h3>边缘脉冲限制</h3> <h4>兼容性问题</h4> <p>某些高级定制选项、与特定硬件的兼容性或对于机器学习和物联网技术新手的学习曲线存在一些限制。</p> <h4>有限定制</h4> <p>在构建非常复杂或专业的模型方面,该平台可能会受到一定限制。具有高级机器学习需求的用户可能需要更广泛的自定义选项或对更高级模型架构的支持。</p> <h2>3.PyTorch 移动版</h2> <p>它属于 PyTorch 生态系统,旨在支持从训练到将机器学习模型部署到智能手机(例如 Android、iOS)的所有阶段。有几种 API 可用于预处理移动应用程序中的机器学习(PyTorch,2021 年)。它可以支持 TorchScript IR 的脚本编写和跟踪。针对 ARM CPU 的 XNNPACK 8 位量化内核提供了进一步的支持。它还可以支持 GPU、数字信号处理器和神经处理单元。通过移动解释器为手机部署铺平了优化设施。目前,它支持图像分割、对象检测、视频处理、语音识别和问答任务。</p> <h3>主要特点:</h3> <ul> <li>1.多平台支持:PyTorch Mobile 可以在 iOS、Android 和 Linux 上运行,为开发人员提供了广泛的部署选择。</li> <li>2.API 可用性:它提供涵盖常见预处理和集成任务的 API,促进机器学习与移动应用程序的集成。</li> <li>3.TorchScript 支持:通过 TorchScript IR 支持跟踪和脚本编写,以满足不同的部署需求。</li> </ul> <h3>PyTorch 与 TensorFlow</h3> <ul> <li> <ol> <li>PyTorch 和 TensorFlow 都达到了类似的准确率,但是 TensorFlow 需要更长的训练时间,同时占用的内存更少。</li> </ol> </li> <li> <ol start="2"> <li>与 TensorFlow 相比,PyTorch 可以更快地进行原型设计。但是,如果神经网络中需要自定义功能,TensorFlow 可能是更好的选择。</li> </ol> </li> <li> <ol start="3"> <li>TensorFlow 将神经网络视为静态对象;如果要更改模型的行为,则必须从头开始。使用 PyTorch,您可以在运行时动态调整神经网络,从而更轻松地优化模型。</li> </ol> </li> <li> <ol start="4"> <li>使用 TensorFlow 进行有效调试需要特殊的调试工具,该工具可以检查网络节点在每个步骤中的计算方式。可以使用许多广泛使用的 Python 调试工具来调试 PyTorch。</li> </ol> </li> <li> <ol start="5"> <li>PyTorch 和 TensorFlow 都提供了加速模型开发和减少样板代码的方法。但是,PyTorch 和 TensorFlow 之间的核心区别在于,PyTorch 更“Python 化”且基于面向对象的方法,而 TensorFlow 总体上提供了更多灵活性选项。</li> </ol> </li> </ul> <h2>4. uTensor</h2> <p>uTensor 是一个轻量级机器学习推理框架,针对 Arm 平台进行了优化,基于 TensorFlow。它使用 Keras 进行训练,获取神经网络模型。然后将训练好的模型转换为 C++。uTensor 有助于转换模型,以便在 Mbed、ST 和 K64 板上进行适当部署。uTensor 是一个小尺寸模块,仅需 2 KB 磁盘空间。Python SDK 用于从头开始定制 uTensor。它依赖于以下工具集,例如 Python、uTensor-CLI、Jupyter、Mbed-CLI 和 ST-link(用于 ST 板)。首先,创建一个模型,然后定义量化效果。下一步是为合适的边缘设备生成代码。<br />  在 TensorFlow 中,模型以流程的方式构建和训练。uTensor 获取模型并生成 .cpp 和 .hpp 文件。这些文件包含用于推理的生成的 C++11 代码。在嵌入式端使用 uTensor 就像复制粘贴一样简单。<br /> 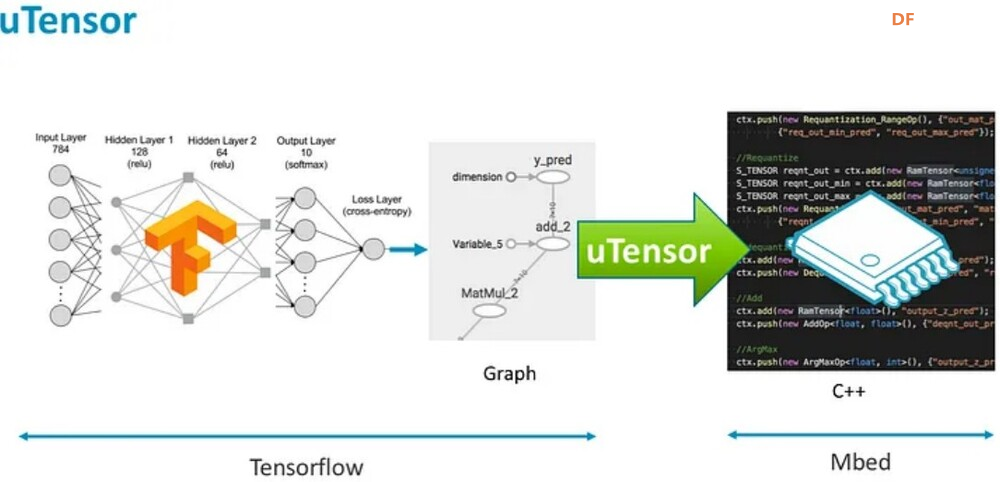 <h3>主要特点:</h3> <ul> <li>**安全可靠:**通过管理专用内存区域中的元数据和实际数据,uTensor 可确保内存使用量保持在预定义的限制内并提供编译时错误检查。</li> <li>**用户友好的 API:**通过高级语言风格的界面,uTensor 简化了开发过程,同时支持直接在 C++ 级别优化性能。</li> <li>**灵活的可扩展性:**从核心库到默认实现,uTensor 允许定制和优化,包括张量实现、运算符、内存分配器等</li> </ul> <h2>5.STM32Cube.AI</h2> <p>它是一款代码生成和优化软件,可让基于 STM32 ARM Cortex M 的开发板更轻松地完成机器学习和 AI 相关任务。使用 STM32Cube.AI 将神经网络转换为最合适 MCU 的优化代码,即可直接在 STM32 开发板上实现神经网络。它可以在运行时优化内存使用情况。它可以使用任何由传统工具(如 TFL、ONNX、Matlab 和 PyTorch)训练的模型。该工具实际上是原始 STM32CubeMX 框架的扩展,可帮助 STM32Cube.AI 执行目标 STM32 边缘设备的代码生成和中间件参数估计。</p> <h3>主要特点:</h3> <ul> <li>允许您从预先训练的神经网络和典型的机器学习模型生成一个库,该库针对 STM32 进行了优化</li> <li>支持最流行的框架(Tensor Flow Lite、Keras、qKeras、Pytorch、ONNX 等)</li> <li>通过 STM32Cube 集成,可轻松跨不同 STM32 微控制器系列移植</li> <li>通过面向应用的代码示例(功能包),可以更轻松地集成转换后的神经网络库<br /> 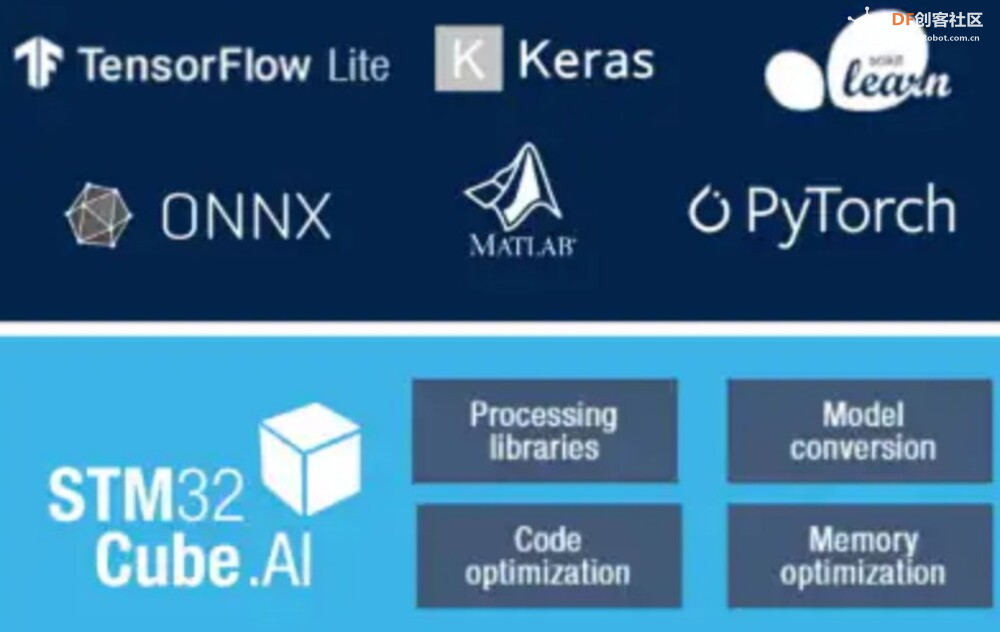 </ul> <h2>6.NanoEdgeAIStudio</h2> <p>NanoEdgeAIStudio 是一款专为 STM32 开发人员设计的自动化机器学习工具。该工具不需要用户具备专门的数据科学技能或人工智能 (AI) 领域的专业知识,因为它提供了用户友好的环境并支持所有 STM32 产品。NanoEdge AI Studio 的数据记录功能可帮助您收集和管理来自工业级传感器的高速数据,而无需编写任何处理工业级传感器的代码。NanoEdge AI Studio 还提供自动搜索引擎、异常检测、分类、回归算法等功能,使边缘设备上的机器学习更容易实现。</p> <h3>STM32Cube.AI 与 NanoEdgeAIStudio</h3> <p>  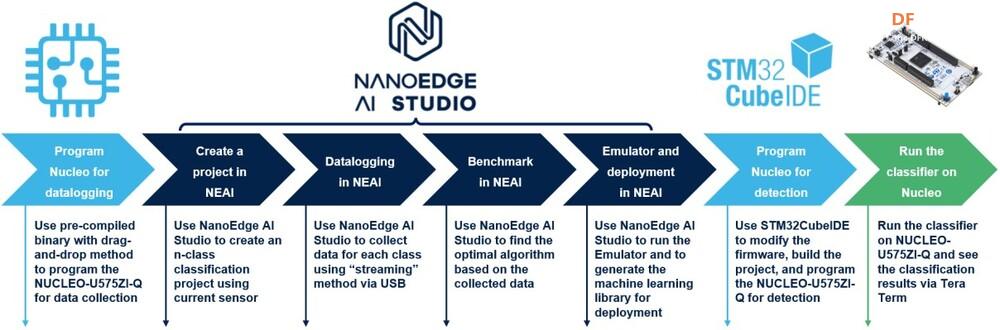 <h2>7. NXP eIQ® 机器学习软件开发环境</h2> <p>NXP Semiconductors eIQ 机器学习软件开发环境是库和开发工具的组合,可与 NXP 微处理器和微控制器配合使用。eIQ 机器学习软件包括 DeepViewRT™ 专有推理引擎。该软件从嵌入式系统上的神经网络 (NN) 人工智能 (AI) 模型进行推理。eIQ 机器学习 (ML) 软件提供在边缘部署各种 ML 算法的关键要素(eIQ = 边缘智能),包括推理引擎、NN 编译器、视觉和传感器解决方案以及硬件抽象层。支持四个主要推理引擎和库 - OpenCV、Arm® NN、Arm CMSIS-NN、TensorFlow Lite 和专有 DeepViewRT 运行时推理。<br />  NXP eIQ® 机器学习软件开发环境 </p><h3>主要特点:</h3> <ul> <li>广泛的优化工具和 Model Zoo</li> <li>具有通用 API 的多种推理引擎选择,包括自动质量选项</li> <li>在多个处理器核心上运行 ML 工作负载</li> </ul> <h2>8.嵌入式学习库(ELL)</h2> <p>微软开发了 ELL,用于支持 TinyML 生态系统的嵌入式学习。它为 Raspberry Pi、Arduino 和 micro:bit 平台提供支持。部署在这些设备中的模型与互联网无关,因此不需要云访问。它目前支持图像和音频分类。该库还提供了一组软件工具和一个可选的 Python 接口,用现代 C++ 编写<br /> 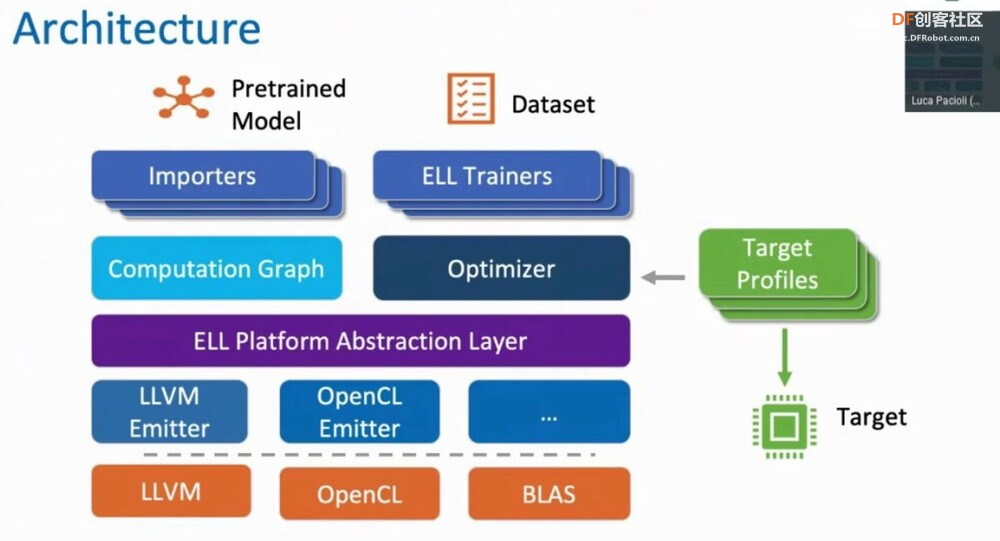 Microsoft 嵌入式学习库 (ELL) </p><h2>8 种 TinyML 框架的兼容硬件平台</h2> <p>您可能对 8 个 TinyML 训练平台支持哪些硬件平台感兴趣。下表列出了支持设计环境(即框架/库)的可用硬件平台的详细信息。<br /> 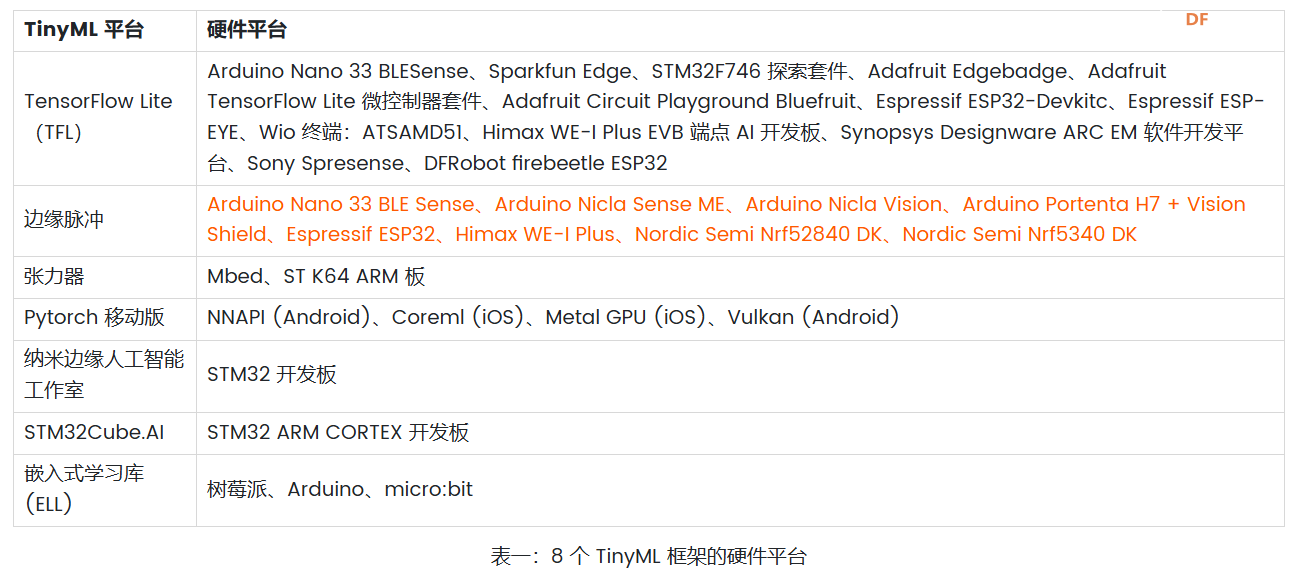 <h2>8 个 TinyML 框架的目标应用</h2> <p> 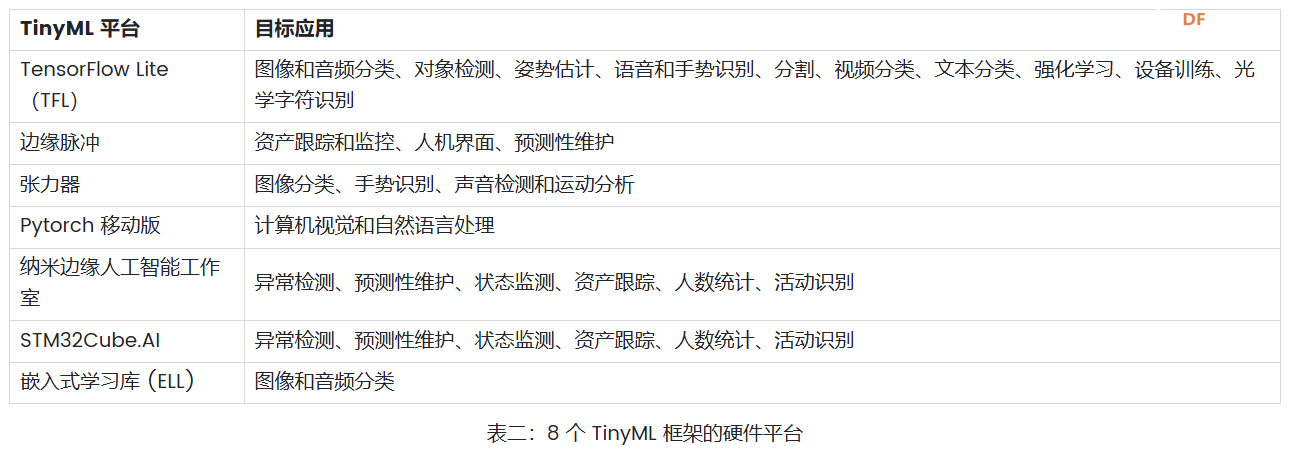 <h2>结论</h2> <p>本文探讨了 8 个最著名的 TinyML 框架,详细介绍了它们的主要功能和局限性。在这些平台中,TensorFlow 以其出色的灵活性脱颖而出,支持 20 多个硬件平台,例如 Arduino Nano、Sparkfun Edge 和 STM32F746 Discovery Kit。它适用于一系列目标应用,包括图像和音频分类、对象检测、姿势估计、语音和手势识别。Edge Impulse 引入了边缘优化神经 (EON™) 编译器,能够将神经网络 RAM 使用率降低 25-55%,将闪存使用率降低高达 35%。与 TensorFlow 相比,PyTorch 提供了更快的原型设计,而 uTensor 是一个紧凑型模块,仅需要 2 KB 的磁盘空间。此外,行业领导者 ST、NXP 和 Microsoft 也推出了他们的 TinyML 实施平台,进一步推动了 TinyML 技术的发展。</p> |



 沪公网安备31011502402448
沪公网安备31011502402448© 2013-2026 Comsenz Inc. Powered by Discuz! X3.4 Licensed


 置顶卡
置顶卡 变色卡
变色卡 千斤顶
千斤顶
 萌萌哒新人
萌萌哒新人
 活跃会员
活跃会员
 宣传大使
宣传大使
 志“童”道合
志“童”道合
 编辑选择奖
编辑选择奖






