|
24537| 0
|
[动态] 使用 OpenVINO 在 LattePanda Mu(Intel N100 处理器)上运行 YOLOv8 |

介绍本文介绍利用DFRobot最新的微型x86计算模块LattePanda Mu,通过OpenVINO加速运行YOLOv8,实现高效、准确的物体检测,同时解决传统高性能计算机体积大、使用不便的问题。 随着物体检测技术在各个领域的应用越来越广泛,越来越多的工业和商业用户开始利用 YOLO 进行实时检测、物体跟踪等应用。其中,由 Ultralytics 于 2023 年提出的 YOLOv8 尤为受欢迎。然而,YOLOv8 虽然功能强大,但计算资源要求高,在轻量级计算设备上经常会卡顿。高性能计算机虽然可以满足 YOLO 的要求,但通常体积较大,不便于携带和部署。 因此,在本文中,我们将使用 DFRobot 最新的 Mu 核心板来运行 YOLOv8,并尝试通过 OpenVINO 对其进行加速。LattePanda Mu 是一款微型 x86 计算模块,配备英特尔 N100 四核处理器、8GB LPDDR5 内存和 64GB 存储。该模块提供丰富的扩展引脚,例如 3 个 HDMI/DisplayPort、8 个 USB 2.0、最多 4 个 USB 3.2 和最多 9 个 PCIe 3.0 通道,结合开源载板设计文件,使用户可以轻松设计或定制载板以满足其独特需求。 与其他产品不同,这款卡片大小的计算模块可以轻松嵌入到空间受限的设备中,在不占用太多空间的情况下提供强大的计算能力。此外,英特尔 N100 处理器的 TDP(热设计功率)可在 6W 至 35W 之间调整,使用户能够在功耗和性能之间灵活选择,以满足不同应用场景的需求。 利用该模块,可以在享受便携设备便利的同时,在各种应用场景中实现更高效、更准确的物体检测。 您可以在GitHub 链接中找到本文中使用的所有代码和模型文件。 本地YOLO 部署首先我们测试了在没有任何量化加速的情况下直接在MU上运行YOLOv8n模型,可以看出运行性能比较卡顿,无法实现高速、精准的流式物体识别任务。 代码这些库包括: ·ultralytics:用于快速设置和运行YOLO模型的库。 ·opencv-python:提供丰富的图像处理函数,用于处理和显示图像。 ·numpy:用于数组和矩阵操作,是Python中常用的数值计算库。 安装库后,下载 GitHub 文件: 代码确保 Mu 已经连接好 USB 摄像头,然后才能进行下面的操作。  图 1. 将相机连接到任意 LattePanda USB 端口
物体检测 (CPU)1.下载模型yolov8n.pt(包含在GitHub文件夹中) 官方下载链接:[https ://github.com/ultralytics/assets/releases/download/v8.1.0/yolov8n.pt](https ://github.com/ultralytics/assets/releases/download/v8.1.0/yolov8n.pt) YOLOv8 物体检测模型包含 5 个变体,均在 COCO 数据集上训练。模型后缀的含义及其性能如下: ·n:纳米(超轻量) 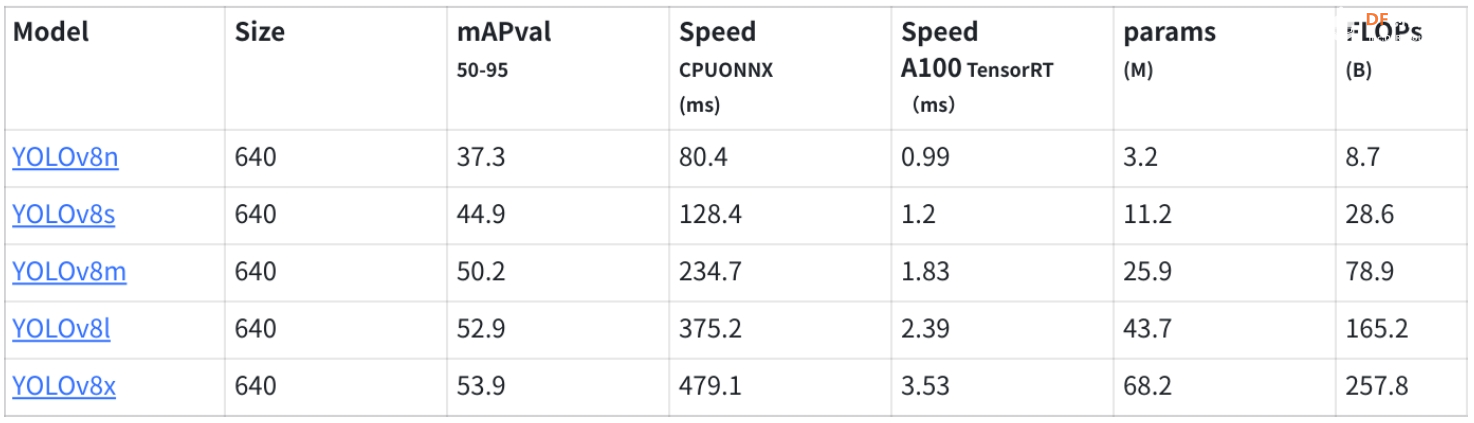 表 1. 不同尺寸的 YOLOv8 物体检测模型性能比较
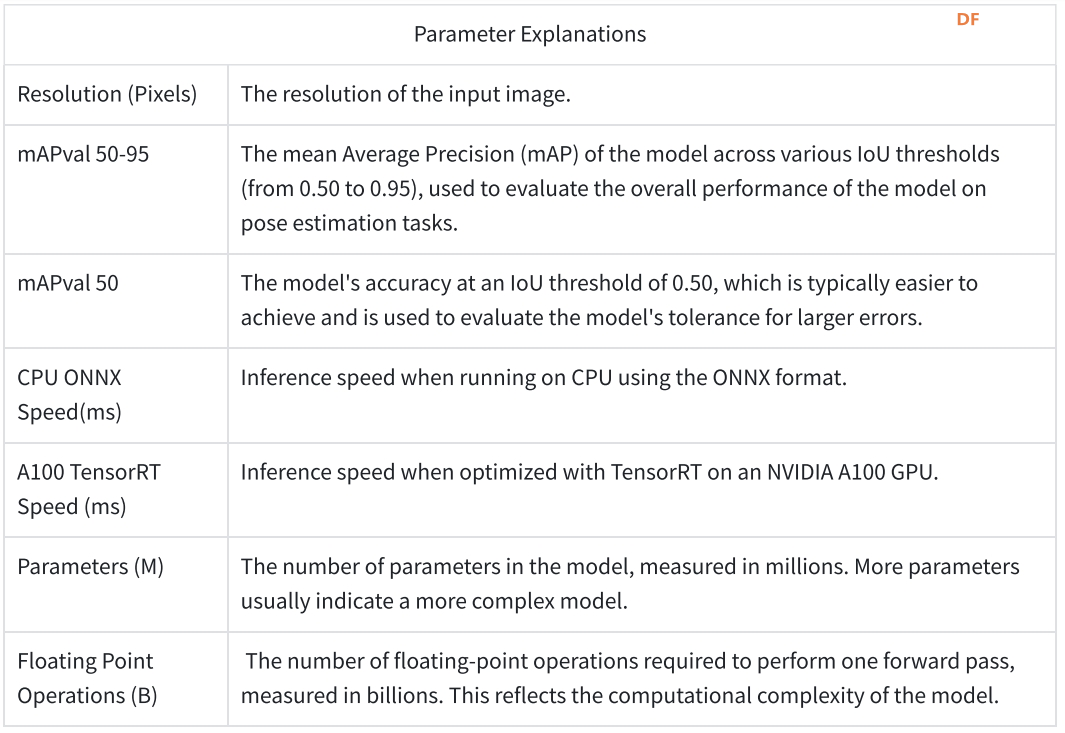 表 2. 参数说明
为了实现快速物体识别,本示例使用 YOLOv8n 进行物体检测。YOLOv8n 是 YOLOv8 系列中最轻量级的模型,能够以更低的计算资源和更快的速度完成物体检测任务,同时保持准确性。它特别适合资源受限的应用程序。 2.运行yolo.py文件 代码代码解释: · 加载 YOLOv8n 模型:使用 3.运行结果: 当使用 Mu 上的 CPU 时,使用 YOLOv8n 进行对象检测的帧速率 (FPS) 大约在 4 到 7 之间。 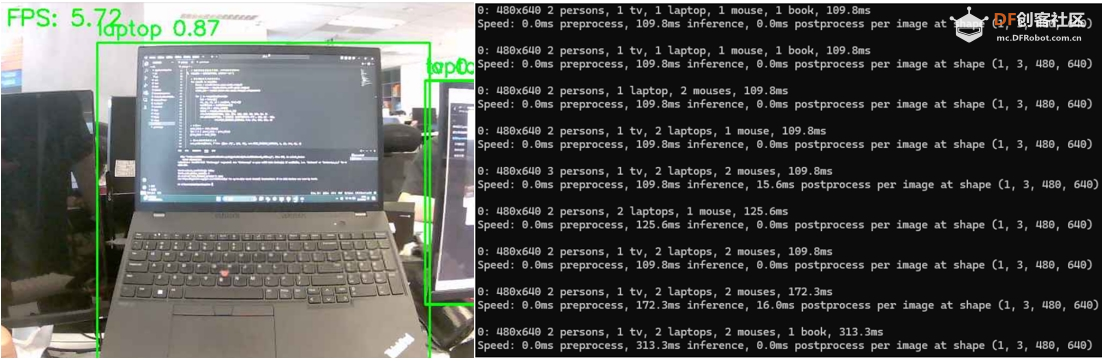 图 2. 在 LattePanda Mu x86 计算机模块上运行 YOLOv8n 物体检测模型
对象分割 (CPU)1.下载官方模型(包含在GitHub文件夹中) 与之前类似,YOLOv8的五种物体分割模型在COCO数据集上进行训练,其性能如下: 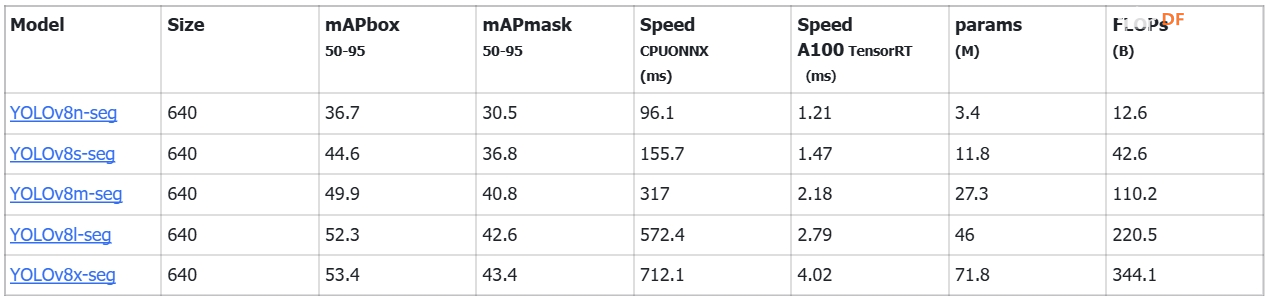 表 3. 不同尺寸的 YOLOv8 物体分割模型性能比较
2.运行yolo_seg.py文件 代码代码解释: · 加载 YOLO 模型:实例化 YOLOv8n 模型(yolov8n-seg.pt 文件)用于对象分割。 · 打开相机:使用 OpenCV 库中的 VideoCapture 函数打开相机。 · 检测相机是否打开:使用isOpened方法检测相机是否打开成功,若未打开则输出错误信息并退出程序。 · 获取视频帧的宽度和高度:使用OpenCV库中的get方法获取视频帧的宽度和高度。 · 初始化计时器和 FPS:使用变量 prev_time 和 fps 初始化计时器和帧速率 (FPS)。 · 循环读取视频帧并处理:使用while循环连续读取摄像头捕获的视频帧。 · 将帧传递给模型进行预测:使用 YOLO 模型对每一帧进行对象检测,并将检测结果存储在变量 results 中。 · 处理预测结果并绘制框架: · 将预测结果转换为 PIL 图像,然后转换为 NumPy 数组。 · 获取检测的边界框、置信度和类别 ID,并迭代绘制边界框和标签。 · 计算并绘制FPS:计算每秒处理的帧数(FPS),并将其绘制在视频帧的左上角。 · 显示帧并退出循环:使用 OpenCV 中的 imshow 函数显示已处理的视频帧,同时监听键盘输入。如果按下“Q”键,则退出循环。 · 释放摄像头并关闭窗口:释放摄像头资源并关闭OpenCV窗口。 3.运行结果: 当使用 Mu 上的 CPU 时,使用 YOLOv8n 进行对象分割的帧速率 (FPS) 大约在 2 到 5 之间。 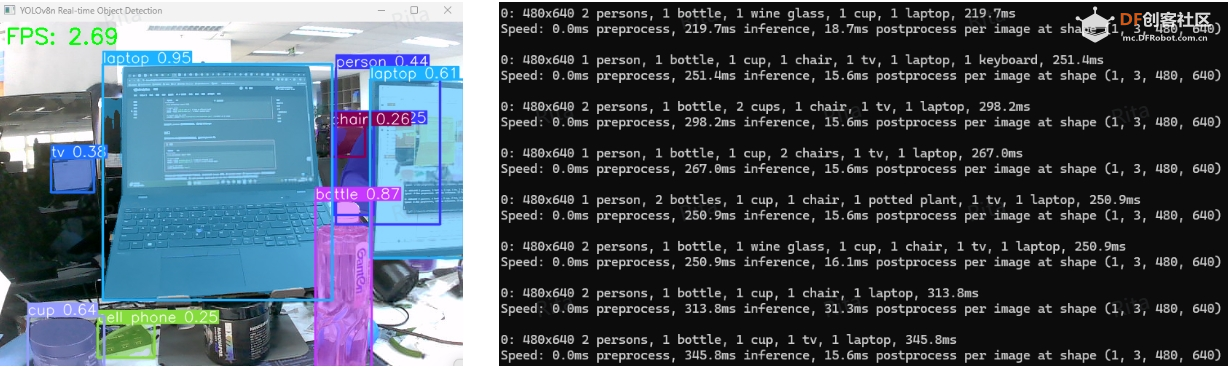 图 3. 在 LattePanda Mu x86 计算机模块上运行 YOLOv8n 对象分割模型
姿势估计(CPU)1.下载官方模型(包含在GitHub文件夹中)。 YOLOv8 共有 6 个姿态估计模型,在 COCO 数据集上进行训练。模型性能如下。YOLOv8x-pose-p6 是 YOLOv8x 的一个变体,它使用更大的输入尺寸(1280 像素),提供更高的准确率,但需要更多的计算资源。 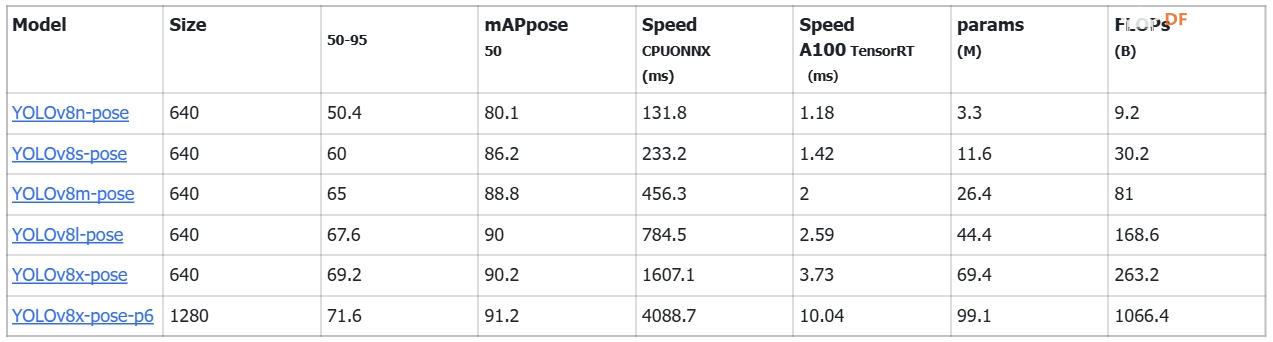 表4 不同尺寸YOLOv8姿态估计模型性能对比
2.运行yolo_pos.py文件 代码代码解释: · 加载 YOLO 模型:实例化 YOLOv8n 模型(yolov8n-pose.pt 文件)用于人体姿势检测。 如果要使用摄像头而不是本地视频文件,请跳过此步骤并更改代码: 代码进入: 代码3.运行结果: 当使用 Mu 上的 CPU 时,使用 YOLOv8n 进行人体姿势检测的帧速率 (FPS) 大约在 3 到 6 之间。  图 4. 在 LattePanda Mu x86 计算机模块上运行 YOLOv8n 姿态估计模型
ONNX 变换YOLOv8n 模型支持导出为不同的格式,例如 ONNX、CoreML 等,具体可导出的格式如下表所示,可以使用 format 参数,即format='onnx'或format='engine',也可以直接对导出的模型进行预测或验证,即 YOLO predict model=yolov8n.onnx,导出完成后会展示一个使用该模型的示例。 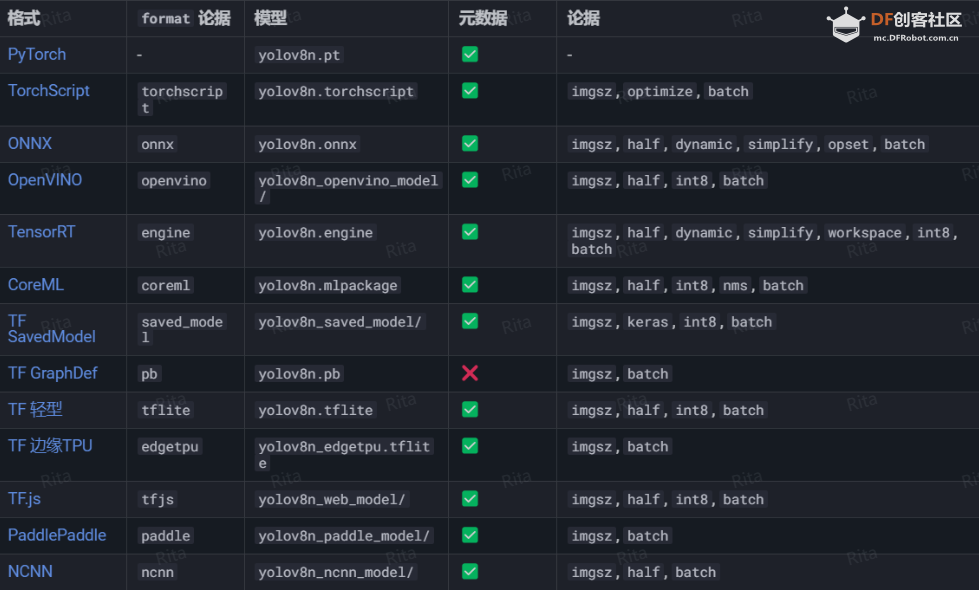 图 5. YOLOv8 导出格式
本文将模型导出为.onnx格式,可以拥有更强的跨平台兼容性和部署灵活性,模型转换代码如下: 代码:输出如下: 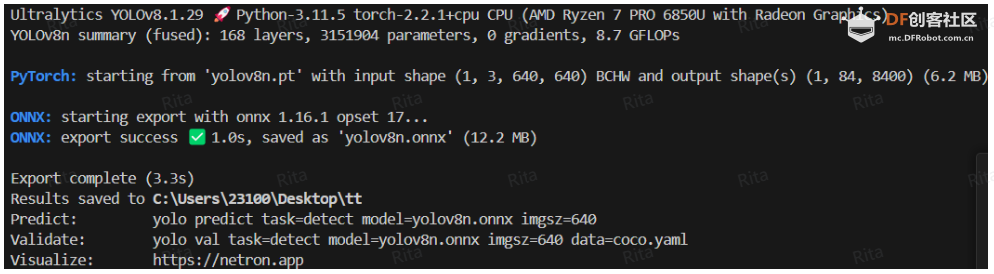 图 6. 成功将模型转换为 ONNX 格式
在Mu上测试ONNX模型(首次运行会自动安装onnxruntime),在目前的测试环境和硬件条件下,如果不改变输入图像大小(推理大小),.pt模型和ONNX模型的速度差别并不大,因此就不再赘述了  图 7. 在 LattePanda Mu 上运行 ONNX 模型(原始图像大小)
使用 OpenVINO 优化在对原生模型进行测试后发现,在实时推理环境下,推理速度还有相当大的提升空间,因此我们在慕课的Intel集成GPU上测试了使用OpenVINO优化的YOLOv8n模型的性能,在模型准确率没有明显下降的情况下,推理速度得到了大幅提升。 环境配置1.安装Anaconda 进入官网,下载对应系统版本的安装包,按照步骤提示确认安装完成。 2.下载GIT
4.创建Conda环境,并在Anaconda Prompt中指定Python版本。 代码注意:建议指定Python版本3.8,3.11版本可能与YOLOv8库存在兼容性问题,不利于后续自定义数据训练。 5.安装OpenVINO(以Windows环境为例) 将笔记本存储库从 GitHub 克隆到本地机器。 代码安装 OpenVINO 环境 代码
代码然后就可以在jupyter notebook中选择YOLOv8优化项目并在本地运行了。 物体检测(CPU/GPU)使用 YOLOv8n 进行 INT8 量化 精度变化参数解释: · 精度:模型识别相关对象的准确率。 · 召回率:衡量模型检测所有真实对象的能力。 · mAP@t:平均精度,表示为数据集中所有类别的精确度-召回率曲线下的面积,其中 t 是交并比 (IOU) 阈值,即真实值和预测对象之间的重叠程度。因此,mAP@.5 表示在 0.5 IOU 阈值下计算的平均精度,而 mAP@.5:.95 表示相同的精度,但在 0.5 到 0.95 的 IOU 阈值范围内以 0.05 的步长计算。 运行结果 经过 INT8 量化后,在 Mu 的 CPU 上使用 YOLOv8 进行物体检测的帧率(FPS)大约在 7 到 9 之间。 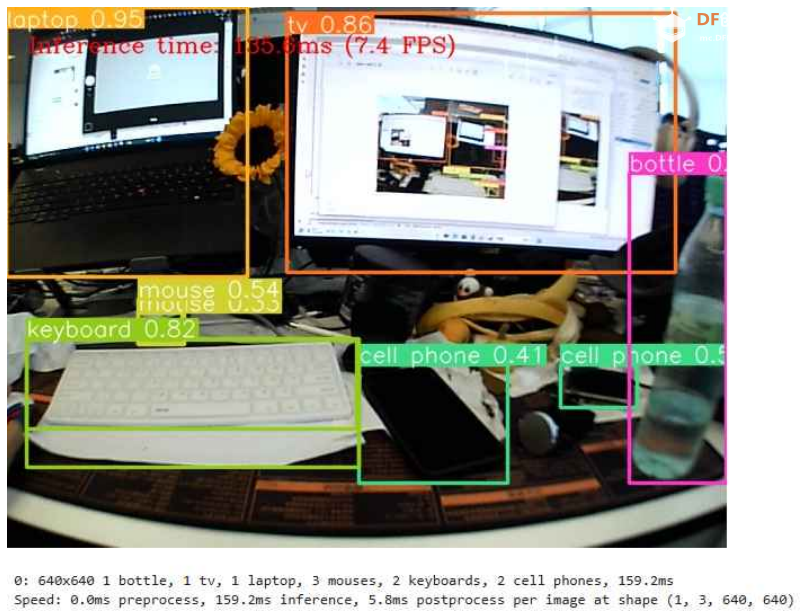 图 10.在经过 OpenVINO 优化的 LattePanda Mu CPU 上运行 YOLOv8n 对象检测模型 图形处理器 经过 INT8 量化后,在 Mu 的集成 GPU 上使用 YOLOv8 进行对象检测的帧率 (FPS) 大约在 15 到 20 之间。 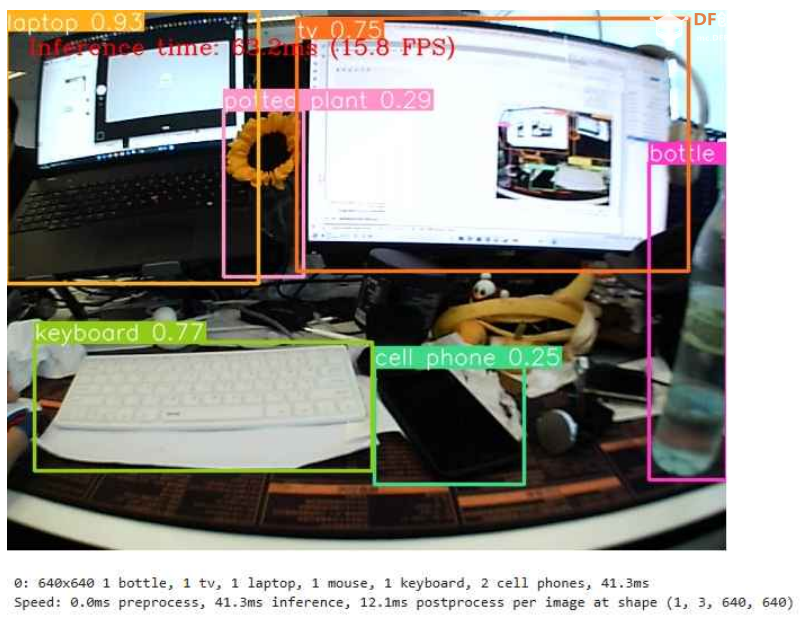 图 11.在 LattePanda Mu GPU 上运行 YOLOv8n 对象检测模型,并采用 OpenVINO 优化
对象分割(CPU/GPU)模型量化后的准确率对比 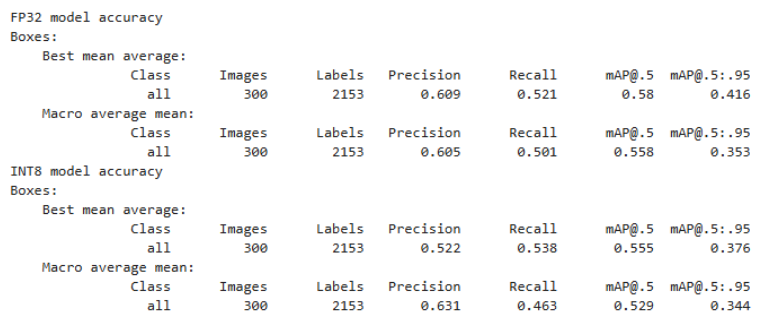 图12. 训练NFCC和INT8量化后的准确率 中央处理器 经过 INT8 量化后,在 Mu 的集成 GPU 上使用 YOLOv8 进行对象分割的帧率 (FPS) 大约在 5 到 7 之间。  图 13.在采用 OpenVINO 优化的 LattePanda Mu CPU 上运行 YOLOv8n 对象分割模型
图形处理器 经过 INT8 量化后,在 Mu 的 GPU 上使用 YOLOv8 进行对象分割的帧率 (FPS) 大约在 12 到 14 之间。  图 14.在 LattePanda Mu GPU 上运行 YOLOv8n 对象分割模型,并采用 OpenVINO 优化
姿势估计(CPU/GPU)INT8量化精度对比 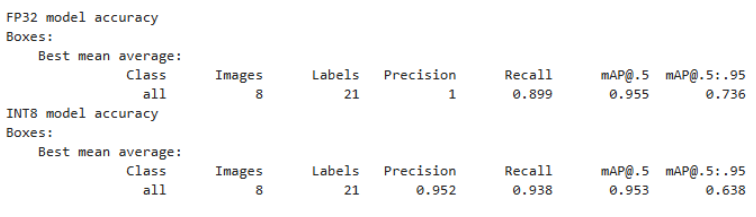 图15.训练NFCC和INT8量化后的准确率 中央处理器 经过int8量化后,在mu的CPU上运行YOLOv8人体关键点检测的帧率(FPS)大约在8到9之间。  图 16.在 LattePanda Mu CPU 上运行 YOLOv8n 姿势估计模型,并采用 OpenVINO 优化
图形处理器 经过int8量化之后,在mu的GPU上运行yolov8n人体关键点检测的帧率(FPS)大约在19到22之间。  图 17.在 LattePanda Mu GPU 上运行 YOLOv8n 姿势估计模型,并采用 OpenVINO 优化
结论 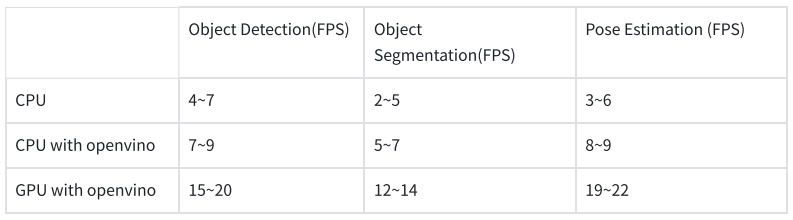 表 5:在 LattePanda Mu 上以不同方式运行 YOLOv8n 的帧率(FPS)结果
录制数据截图可能会造成fps下降,实际情况下可以在上述范围上增加1~2个。 参考2.Ultralytics官方网站 |



 沪公网安备31011502402448
沪公网安备31011502402448© 2013-2026 Comsenz Inc. Powered by Discuz! X3.4 Licensed


 置顶卡
置顶卡 变色卡
变色卡 千斤顶
千斤顶
 萌萌哒新人
萌萌哒新人
 活跃会员
活跃会员
 宣传大使
宣传大使
 志“童”道合
志“童”道合
 编辑选择奖
编辑选择奖






