项目背景

为满足新课标中八年级“物联网实践与探索”内容要求, 结合教材中人工智能教学相关的需求,因此设计了AI 大模型语音聊天机器人的项目。通过当前应用案例的学习,学生可以收获如何通过Mind + 结合对应的上位机Python 来来实现一个自定义的语音助手,以及上位机的相关应用。 比如说如何调用第三方的API接口来实现文字到语音或者语音到文字的互相转, base64编码,和反向代理服务器Nginx的基本使用。同时结合通义千问来实现AI助手的相关功能。
项目介绍
项目开发难度 : 难(具体体现在上位机的逻辑处理上)
项目所需物料 : 行空板K10 + SD卡
项目所需第三方API Key
项目所需前置技术:
- Arduino 环境和Mind + 环境的基础使用
- 串口相关知识
- C语言文件保存和Python文件保存相关知识
- PIP包管理器的使用
- WAV音频编码相关知识
- Nginx反向代理服务器的使用
- base64编码
项目原理
项目主要是采用了K10作为语音的采集和播放终端, 当K10上的按键A被按下时那么触发本地的语音采集。之后K10会将采集的WAV语音文件保存到内存卡中。 之后通过串口的方式将wav的语音文件发送到上位机Python。 当Python收到K10发送到的数据之后,首先将二进制的数据转换成Bin文件,之后再根据Wav格式的编码将bin文件转换成和内存卡内相同的wav文件并且保存在上位机(Python). 之后通过调用讯飞语音的语音转文字的API接口,上位机可以获取到语音数据中的文字信息。 同时当上位机拿到了文字信息之后。上位机会将文字信息通过调用通义千问的Turbo模型来实现AI的聊天功能。此时上位机继续将通义千问返回的消息发送给讯飞的文字转语音功能。当文字转换语音完毕之后。语音的数据将会编码为base64格式发送给上位机。上位机需要将base64编码转换成wav文件,接着将wav文件生成到由nginx代理的静态目录中。 当wav文件生成完毕,上位机会通过串口给K10发送一条命令,来通知K10语音文件已经准备就绪。K10随即发送HTTP GET请求来将上位机nginx代理的静态目录中的音频文件下载到SD卡中再由Mind + 提供的语音播放API进行播放从事实现整体的聊天功能。
简要时序图如下

项目实现步骤
1- SD卡准备阶段
由于需要使用到SD卡来保存音频的相关数据,因此在项目的开始之前最好确认一下SD卡的相关信息。如果SD卡的容量超过了32GB的话,请参考官方文档来对SD卡进行初始化操作。
2- 打开Mind + , 并且选取开发板为K10
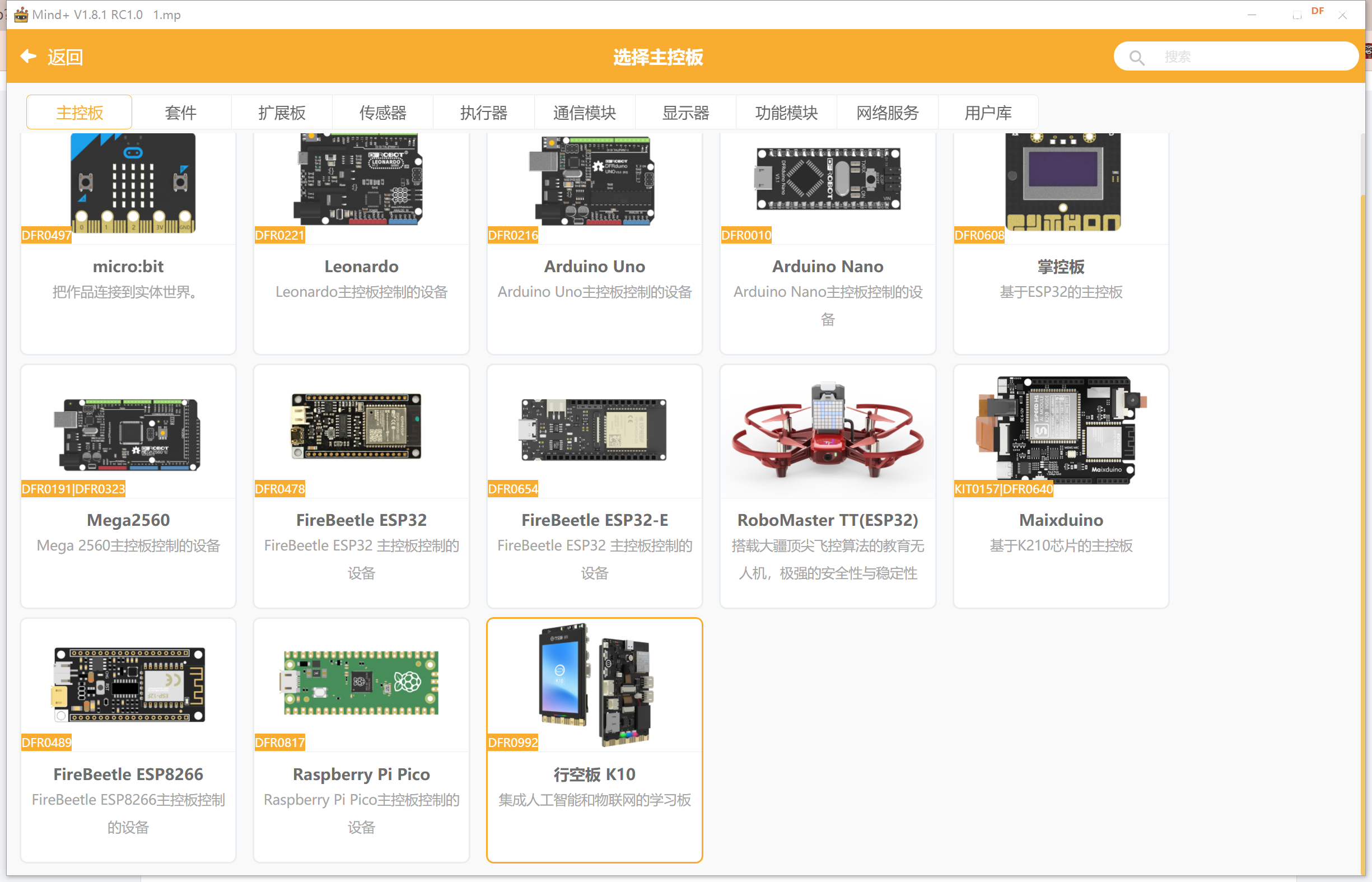
3- 选择网络模块的拓展
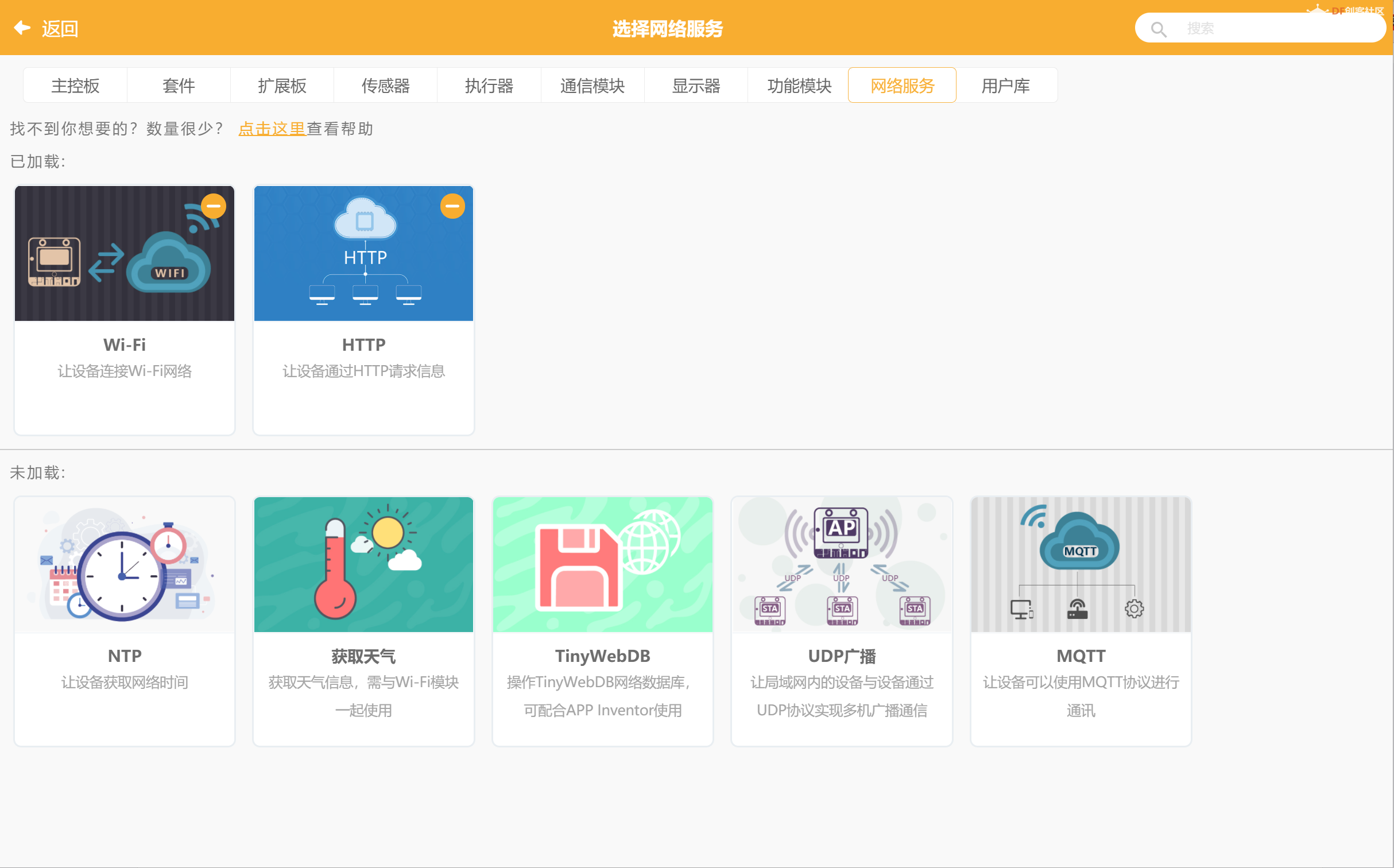
网络模块选择了WIFI,用于连接2.4GAP, 而HTTP模块的引入则可以发送对应的HTTP请求。
4- 返回编辑器打开手动编辑模式。并且引入必须的库文件。
- #include "asr.h"
- #include <DFRobot_Iot.h>
- #include "unihiker_k10.h"
- #include <DFRobot_HTTPClient.h>
5- 定义程序需要使用的对象信息。
- // 创建对象
- DFRobot_Iot myIot;
- UNIHIKER_K10 k10;
- ASR asr;
- Music music;
- DFRobot_HTTPClient http;
6- 需要注意的一点是DFRobot_HTTPClient.h 这个库并不支持直接访问内部的httpclient对象,因此想要成功的从http响应的stream中获取数据的话,还需要做一点小小的修改。 我们可以使用everything这个软件来搜索DFRobot_HTTPClient.h
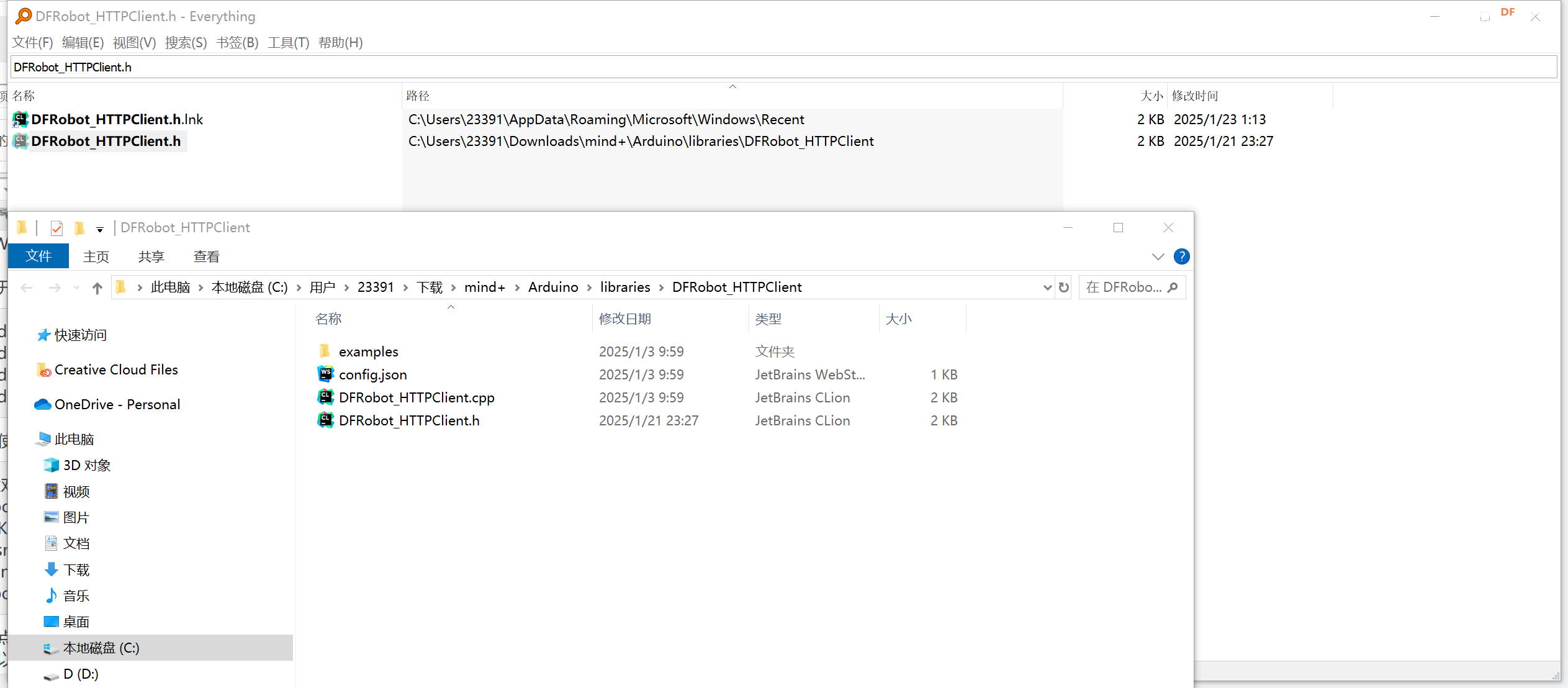
7- 修改DFRobot_HTTPClient.h 内部的httpclient的访问修饰符,从private 修改为public使其可以被外部访问直接调用。如下代码所示,为修改之后的内容。
- #ifndef DFROBOT_HTTPCLIENT_H
- #define DFROBOT_HTTPCLIENT_H
-
- #include <Arduino.h>
-
- #if defined(ARDUINO_ARCH_ESP8266)
- #include <ESP8266HTTPClient.h>
- #include <WiFiClientSecureBearSSL.h>
- #else
- #include <HTTPClient.h>
- #endif
-
-
- class DFRobot_HTTPClient
- {
- public:
- void init();
- void addParam(const String& name, const String& value);
- void addParam(float name, const String& value) {this->addParam(String(name), value);}
- void addParam(const String& name, float value) {this->addParam(name, String(value));}
- void addParam(float name, float value) {this->addParam(String(name), String(value));}
-
- void addHeader(const String& name, const String& value);
- void addHeader(float name, const String& value) {this->addHeader(String(name), value);}
- void addHeader(const String& name, float value) {this->addHeader(name, String(value));}
- void addHeader(float name, float value) {this->addHeader(String(name), String(value));}
-
- void addString(const String& text);
- void addString(float text) {this->addString(String(text));}
-
- void GET(String url, float timeout = 10000);
- void POST(String url, float timeout = 10000);
-
- String getLine();
- String getString();
- HTTPClient _httpclient;
- String _params, _body;
- int _httpcode;
- };
-
- #endif
8 - 重启MIND + 并且重新载入工程使其修改的文件生效。
9- 在setup() 方法中初始化开发板信息、串口、语音合成播放速度、初始化SD卡和初始化wifi连接。
- // 主程序开始
- void setup() {
- k10.begin();
- Serial.begin(115200);
- asr.setAsrSpeed(1);
- k10.initSDFile();
- myIot.wifiConnect("ImmortalWrt", "mazha1997");
- while (!myIot.wifiStatus()) {}
- }
10 - 现在初始化工作已经完成了,现在我们希望当按下K10上的A键的时候将会开始录制一段音频数据,并且保存到SD卡然后通过串口发送到Python上位机。
复制代码
代码解读: 上述代码中通过调用积木编程的API来实现了音频文件的录制和保存。 当录制完成之后, 通过串口将SD卡内的音频文件发送到了Python上位机。需要注意的是上述代码中的START_OF_FILE 和 END_OF_FILE 是用来区分音频的起始和结束标志位。 由于上位机也是无限循环等待,所以这里需要使用起始位的方式来进行处理从而来实现无限的对话功能。
11- 上位机文件接收和转码
如果想在python中使用串口功能的话则需要pyserial的这个库, 我们可以在pip中直接通过下述命令进行安装。
复制代码
导入pyserial
复制代码
之后以和开发板与之匹配的串口号和波特率打开串口。
- if __name__ == '__main__':
- port = 'COM38'
- baud_rate = 115200
- ser = serial.Serial(port, baud_rate, timeout=1)
我们希望程序在运行时一直监控K10 发送过来的消息, 一旦接收到开始标志即开始接收串口数据,然后保存为BIN文件方便后面的转码。所以我们需要在main入口中再加上一个while循环来读取串口的数据
- if __name__ == '__main__':
- port = 'COM38'
- baud_rate = 115200
- ser = serial.Serial(port, baud_rate, timeout=1)
- while True:
- save_serial_data_to_bin()
对于这个save_serial_data_to_bin() 方法则为下述定义
- def save_serial_data_to_bin():
- try:
- with open(OUTPUT_FILE_PATH, 'wb') as f:
- in_block = False
-
- while True:
- if ser.in_waiting > 0:
- data = ser.readline()
-
- if START_OF_FILE in data:
- in_block = True
- continue
-
- if END_OF_FILE in data:
- in_block = False
- print("End of file marker detected. Stopping.")
- break
-
- if in_block:
- f.write(data)
- # print(f"Data written: {data}")
-
- except serial.SerialException as e:
- print(f"Error opening serial port: {e}")
上述代码用于将K10发送的数据直接保存为BIN格式,方便我们之后的数据转码。修改后的代码如下所示- if __name__ == '__main__':
- port = 'COM38'
- baud_rate = 115200
- ser = serial.Serial(port, baud_rate, timeout=1)
- while True:
- save_serial_data_to_bin()
- add_wav_header(OUTPUT_FILE_PATH, "sound.wav", sample_rate=32000, num_channels=1, bits_per_sample=16)
对于add_wav_header方法的定义则是如下所示,用于将bin文件转换为wav格式(增加文件头信息等)。
- def add_wav_header(bin_file, wav_file, sample_rate=16000, num_channels=1, bits_per_sample=16):
- with open(bin_file, "rb") as bin_f:
- audio_data = bin_f.read()
-
- # 计算头部字段
- subchunk2_size = len(audio_data)
- chunk_size = 36 + subchunk2_size
- byte_rate = sample_rate * num_channels * (bits_per_sample // 8)
- block_align = num_channels * (bits_per_sample // 8)
-
- # 构建 WAV 文件头
- wav_header = struct.pack(
- '<4sI4s4sIHHIIHH4sI',
- b'RIFF', # ChunkID
- chunk_size, # ChunkSize
- b'WAVE', # Format
- b'fmt ', # Subchunk1ID
- 16, # Subchunk1Size
- 1, # AudioFormat (1 = PCM)
- num_channels, # NumChannels
- sample_rate, # SampleRate
- byte_rate, # ByteRate
- block_align, # BlockAlign
- bits_per_sample, # BitsPerSample
- b'data', # Subchunk2ID
- subchunk2_size # Subchunk2Size
- )
-
- # 写入 WAV 文件
- with open(wav_file, "wb") as wav_f:
- wav_f.write(wav_header) # 写入头部
- wav_f.write(audio_data) # 写入音频数据
12 - 调用讯飞文字转换语音的API来将我们K10采集的人声转换成文字。首先在讯飞文档中心的语音识别的导航下的极速语音转写下找到WEBAPI的调用文档。点击接口demo下载来下载调用的demo程序。并且选择python进行下载。
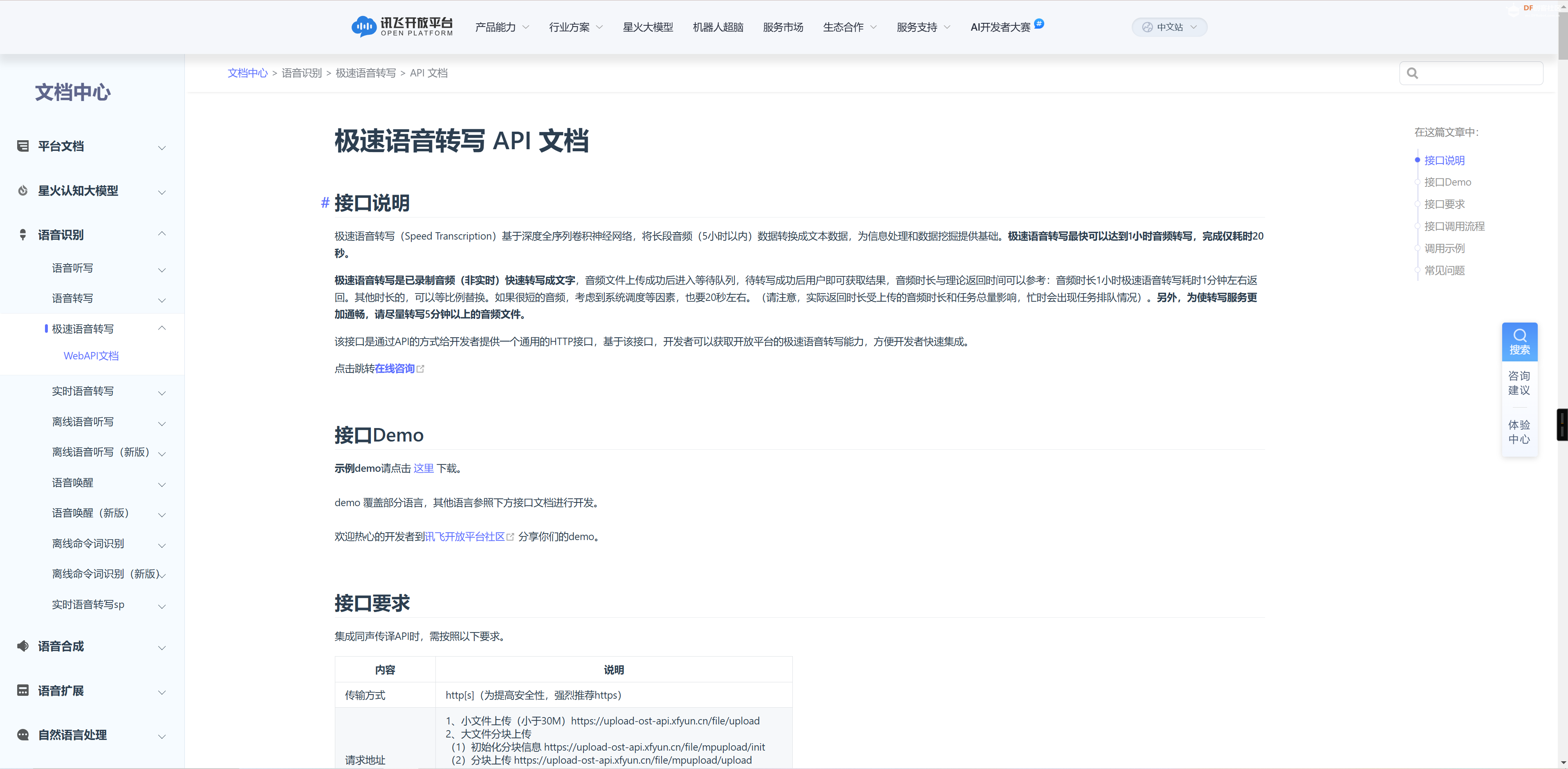
之后我们需要注册讯飞开放平台,在讯飞开放平台中选择产品的试用
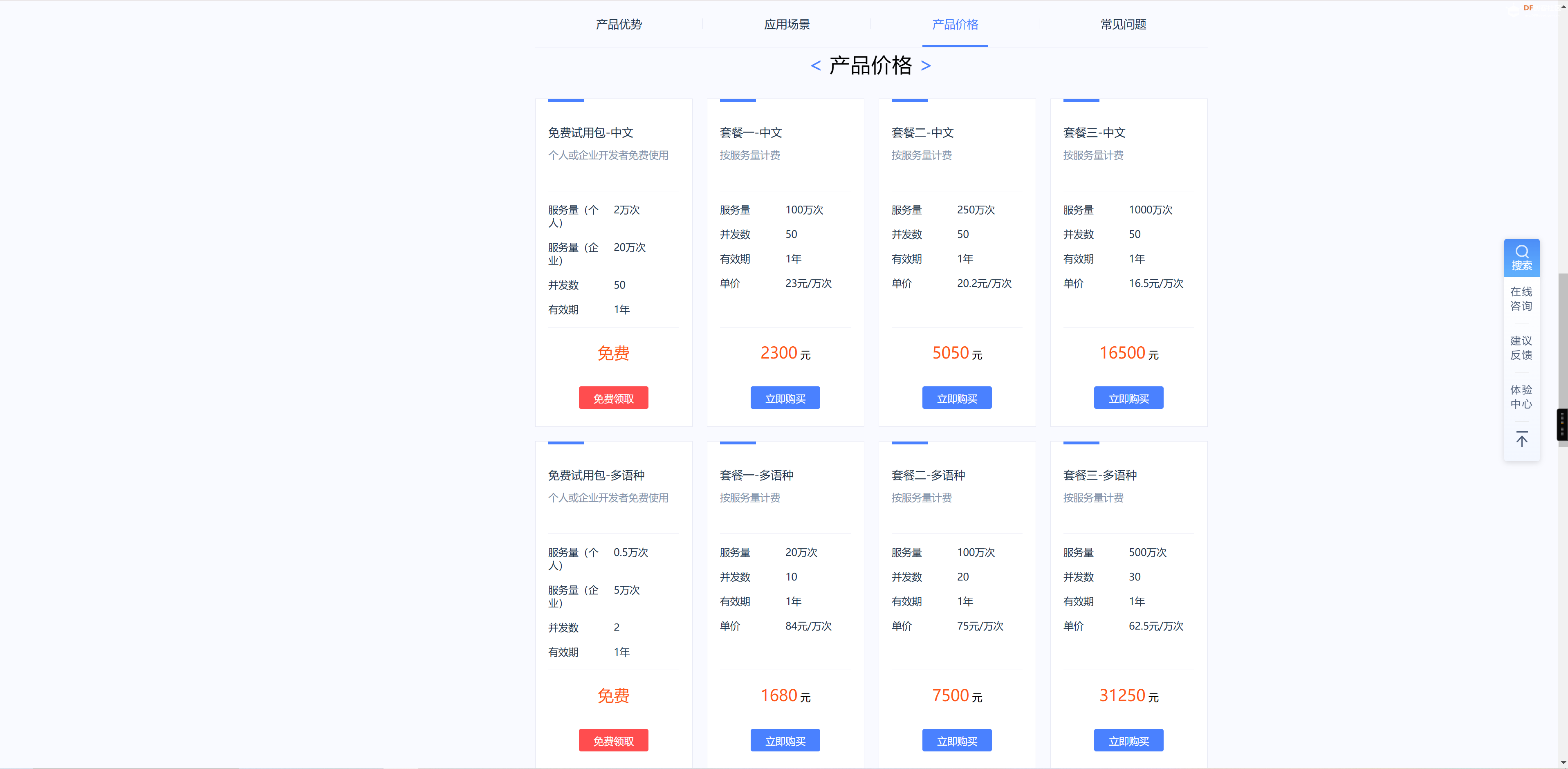 。 。
在控制台中拷贝自己的Key和密钥信息。
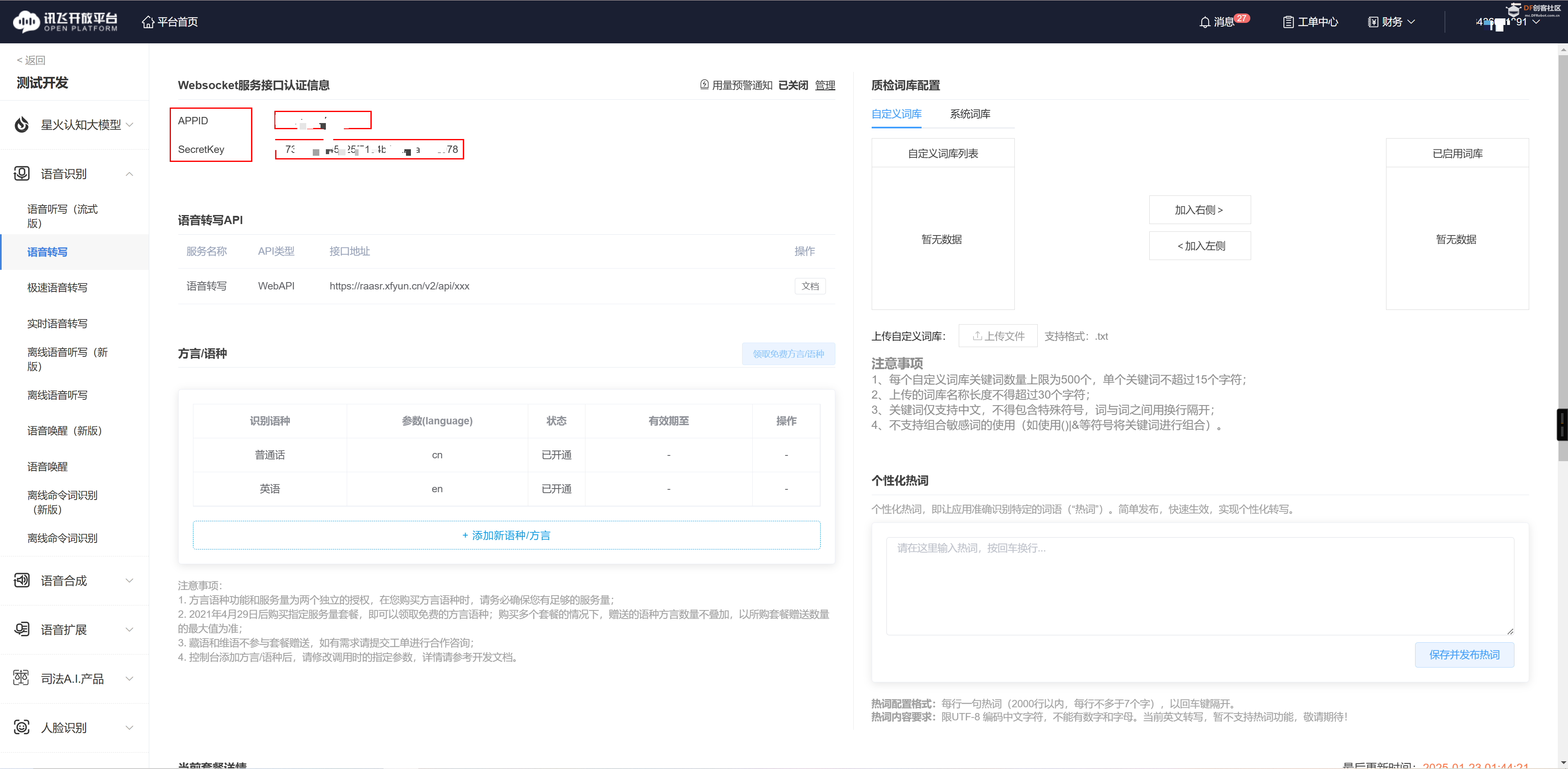
之后我们来调用语音转换文字的功能。
- if __name__ == '__main__':
- port = 'COM38'
- baud_rate = 115200
- ser = serial.Serial(port, baud_rate, timeout=1)
- while True:
- save_serial_data_to_bin()
- add_wav_header(OUTPUT_FILE_PATH, "sound.wav", sample_rate=32000, num_channels=1, bits_per_sample=16)
- api = RequestApi(appid="你的应用ID", secret_key="你的KEY", upload_file_path=r"sound.wav")
- api.all_api_request()
对应的请求和处理代码如下所示
- def __init__(self, appid, secret_key, upload_file_path):
- self.appid = appid
- self.secret_key = secret_key
- self.upload_file_path = upload_file_path
-
- # 根据不同的apiname生成不同的参数,本示例中未使用全部参数您可在官网(https://doc.xfyun.cn/rest_api/%E8%AF%AD%E9%9F%B3%E8%BD%AC%E5%86%99.html)查看后选择适合业务场景的进行更换
- def gene_params(self, apiname, taskid=None, slice_id=None):
- appid = self.appid
- secret_key = self.secret_key
- upload_file_path = self.upload_file_path
- ts = str(int(time.time()))
- m2 = hashlib.md5()
- m2.update((appid + ts).encode('utf-8'))
- md5 = m2.hexdigest()
- md5 = bytes(md5, encoding='utf-8')
- # 以secret_key为key, 上面的md5为msg, 使用hashlib.sha1加密结果为signa
- signa = hmac.new(secret_key.encode('utf-8'), md5, hashlib.sha1).digest()
- signa = base64.b64encode(signa)
- signa = str(signa, 'utf-8')
- file_len = os.path.getsize(upload_file_path)
- file_name = os.path.basename(upload_file_path)
- param_dict = {}
-
- if apiname == api_prepare:
- # slice_num是指分片数量,如果您使用的音频都是较短音频也可以不分片,直接将slice_num指定为1即可
- slice_num = int(file_len / file_piece_sice) + (0 if (file_len % file_piece_sice == 0) else 1)
- param_dict['app_id'] = appid
- param_dict['signa'] = signa
- param_dict['ts'] = ts
- param_dict['file_len'] = str(file_len)
- param_dict['file_name'] = file_name
- param_dict['slice_num'] = str(slice_num)
- elif apiname == api_upload:
- param_dict['app_id'] = appid
- param_dict['signa'] = signa
- param_dict['ts'] = ts
- param_dict['task_id'] = taskid
- param_dict['slice_id'] = slice_id
- elif apiname == api_merge:
- param_dict['app_id'] = appid
- param_dict['signa'] = signa
- param_dict['ts'] = ts
- param_dict['task_id'] = taskid
- param_dict['file_name'] = file_name
- elif apiname == api_get_progress or apiname == api_get_result:
- param_dict['app_id'] = appid
- param_dict['signa'] = signa
- param_dict['ts'] = ts
- param_dict['task_id'] = taskid
- return param_dict
-
- # 请求和结果解析,结果中各个字段的含义可参考:https://doc.xfyun.cn/rest_api/%E8%AF%AD%E9%9F%B3%E8%BD%AC%E5%86%99.html
- def gene_request(self, apiname, data, files=None, headers=None):
- response = requests.post(lfasr_host + apiname, data=data, files=files, headers=headers)
- result = json.loads(response.text)
- print(f"打印的数据:{result}")
- print(f"打印的数据2:{str(result)}")
- print(result["data"] if "data" in result else None)
- if apiname == api_get_result:
- try:
- global text
- # 从结果中提取数据
- res = json.loads(result["data"])
- data = res[0]["onebest"]
- text = data;
-
- except Exception as e:
- print(f"串口操作失败: {e}")
-
- if result["ok"] == 0:
- print("{} success:".format(apiname) + str(result))
- return result
- else:
- print("{} error:".format(apiname) + str(result))
- exit(0)
- return result
-
- # 预处理
- def prepare_request(self):
- return self.gene_request(apiname=api_prepare,
- data=self.gene_params(api_prepare))
-
- # 上传
- def upload_request(self, taskid, upload_file_path):
- file_object = open(upload_file_path, 'rb')
- try:
- index = 1
- sig = SliceIdGenerator()
- while True:
- content = file_object.read(file_piece_sice)
- if not content or len(content) == 0:
- break
- files = {
- "filename": self.gene_params(api_upload).get("slice_id"),
- "content": content
- }
- response = self.gene_request(api_upload,
- data=self.gene_params(api_upload, taskid=taskid,
- slice_id=sig.getNextSliceId()),
- files=files)
- if response.get('ok') != 0:
- # 上传分片失败
- print('upload slice fail, response: ' + str(response))
- return False
- print('upload slice ' + str(index) + ' success')
- index += 1
- finally:
- 'file index:' + str(file_object.tell())
- file_object.close()
- return True
-
- # 合并
- def merge_request(self, taskid):
- return self.gene_request(api_merge, data=self.gene_params(api_merge, taskid=taskid))
-
- # 获取进度
- def get_progress_request(self, taskid):
- return self.gene_request(api_get_progress, data=self.gene_params(api_get_progress, taskid=taskid))
-
- # 获取结果
- def get_result_request(self, taskid):
- return self.gene_request(api_get_result, data=self.gene_params(api_get_result, taskid=taskid))
-
- def all_api_request(self):
- # 1. 预处理
- pre_result = self.prepare_request()
- taskid = pre_result["data"]
- # 2 . 分片上传
- self.upload_request(taskid=taskid, upload_file_path=self.upload_file_path)
- # 3 . 文件合并
- self.merge_request(taskid=taskid)
- # 4 . 获取任务进度
- while True:
- # 每隔20秒获取一次任务进度
- progress = self.get_progress_request(taskid)
- progress_dic = progress
- if progress_dic['err_no'] != 0 and progress_dic['err_no'] != 26605:
- print('task error: ' + progress_dic['failed'])
- return
- else:
- data = progress_dic['data']
- task_status = json.loads(data)
- if task_status['status'] == 9:
- print('task ' + taskid + ' finished')
- break
- print('The task ' + taskid + ' is in processing, task status: ' + str(data))
-
- # 每次获取进度间隔20S
- time.sleep(20)
- # 5 . 获取结果
- self.get_result_request(taskid=taskid)
上述的代码来自于讯飞官方,只需要替换你自己的key 和 密钥 即可完成语音转换文字的功能。
13 - 使用语音转换后的文本来发送到通义千问,获取大模型的回复。首先我们需要根据通义千问的官方文档来进行注册和试用操作。
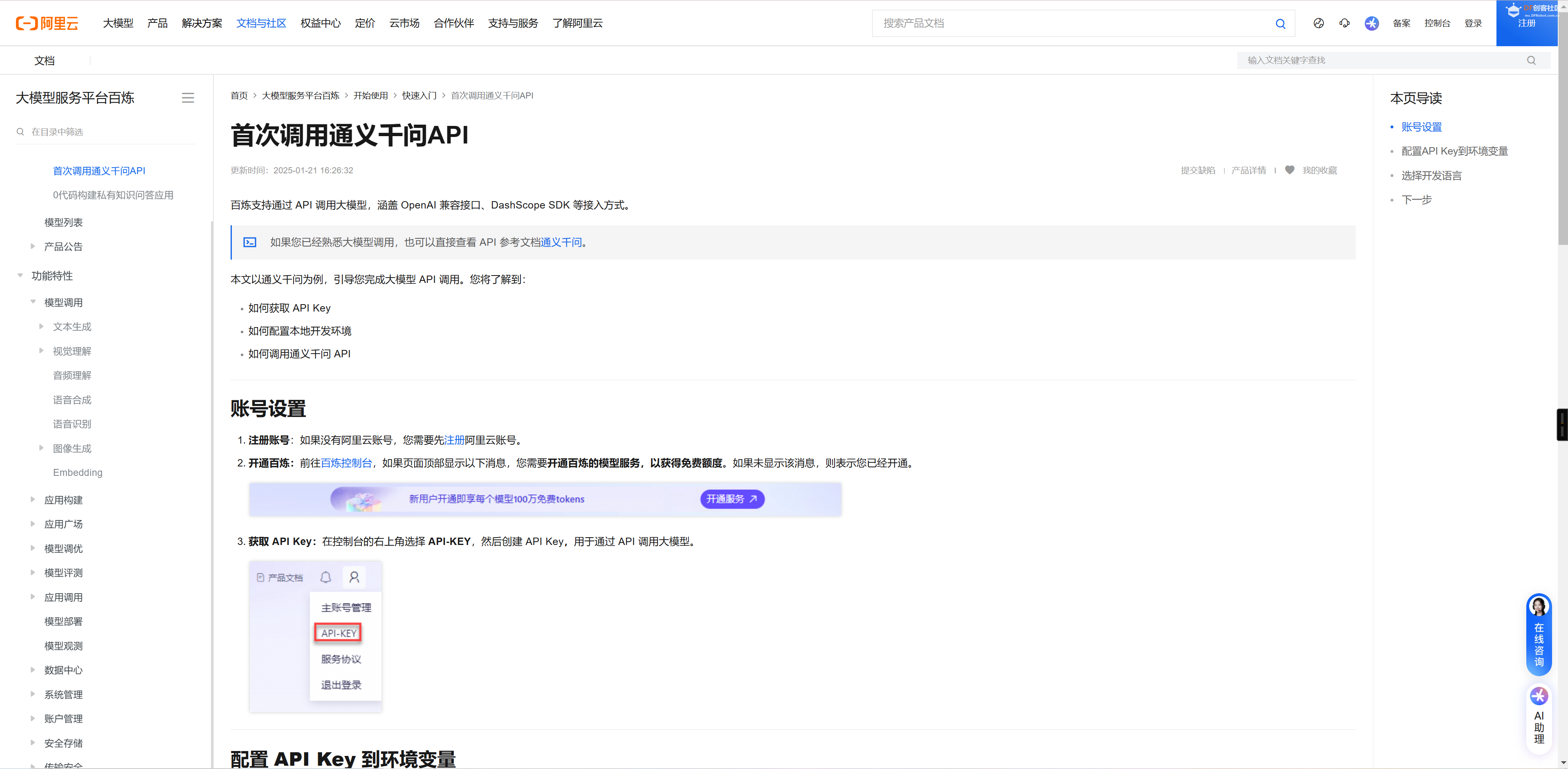
根据官方的教程配置KEY到环境变量中
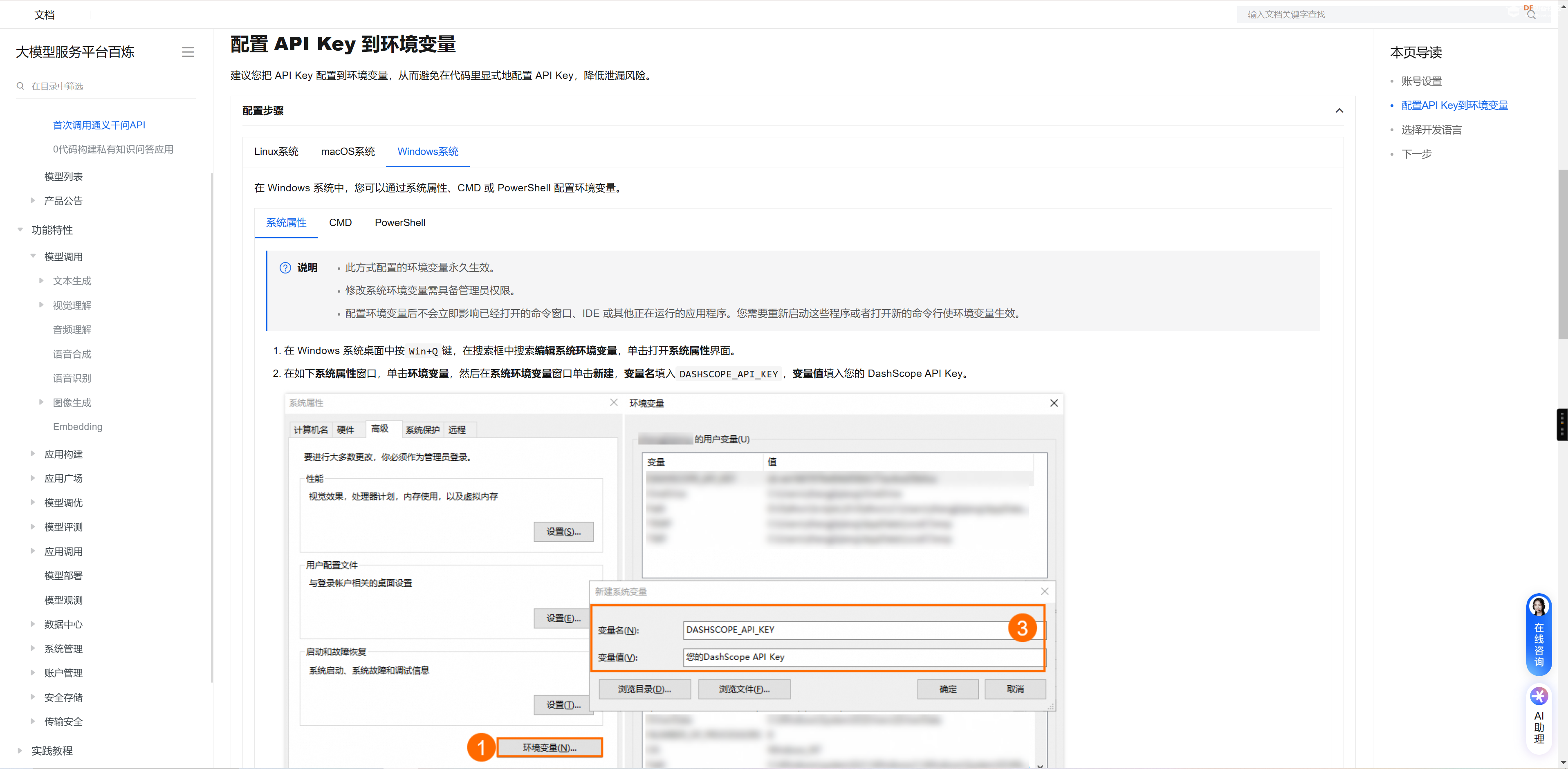
安装和调用大模型
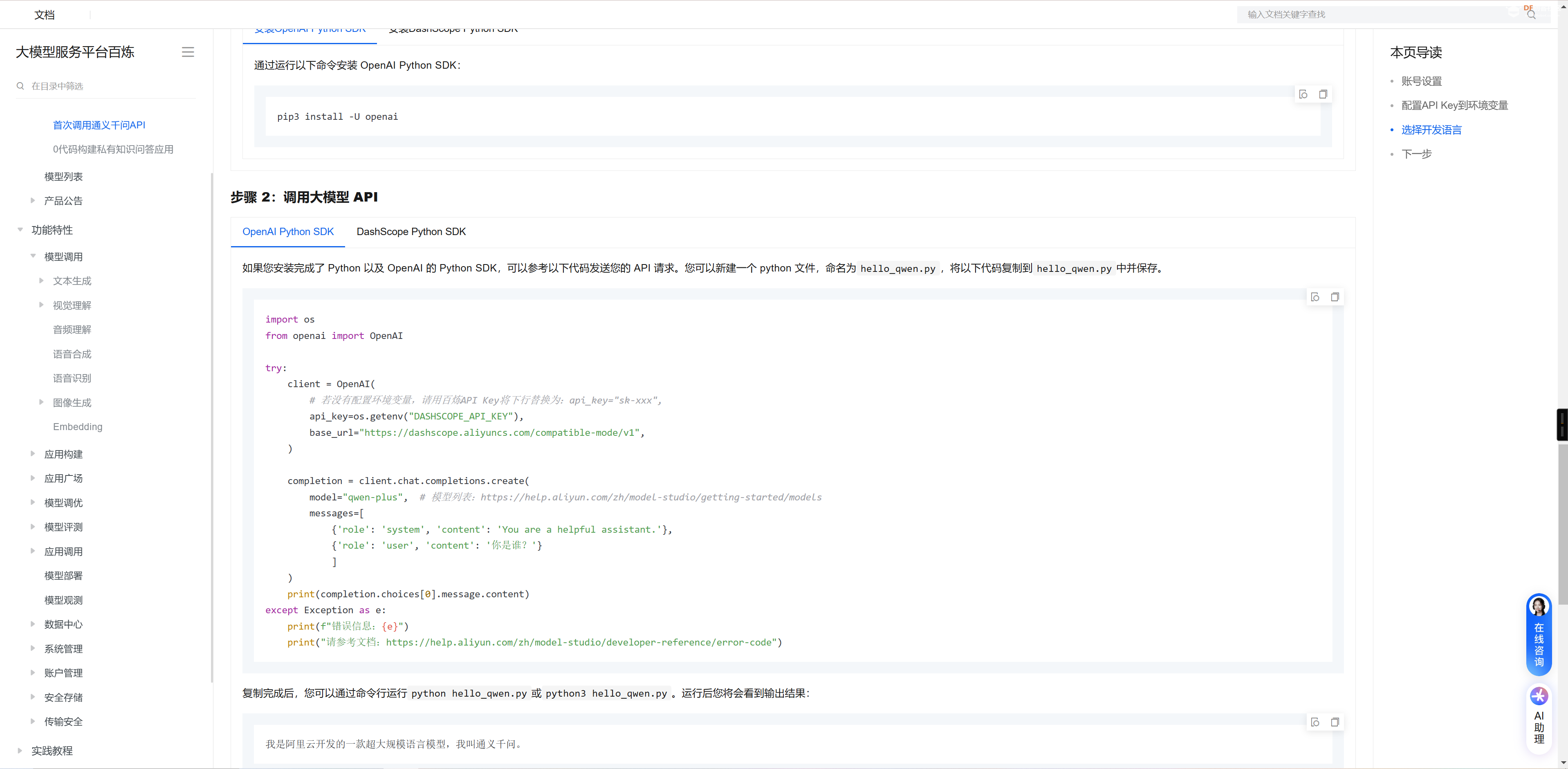
- def Turbo(msg):
- global ai_res
- try:
- client = OpenAI(
- # 若没有配置环境变量,请用百炼API Key将下行替换为:api_key="sk-xxx",
- api_key=os.getenv("DASHSCOPE_API_KEY"),
- base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
- )
-
- completion = client.chat.completions.create(
- model="qwen-plus", # 模型列表:https://help.aliyun.com/zh/model-studio/getting-started/models
- messages=[
- {'role': 'system', 'content': 'You are a helpful assistant.'},
- {'role': 'user', 'content': msg}
- ]
- )
- ai_res = completion.choices[0].message.content
- print(completion.choices[0].message.content)
- except Exception as e:
- print(f"错误信息:{e}")
- print("请参考文档:https://help.aliyun.com/zh/model-studio/developer-reference/error-code")
之后我们便可以将上述语音转换文本的内容发送给通义千问模型(速度很快)然后等待通义千问返回结果, 同时将返回的结果定义并且保存到全局的变量中,用于下文的讯飞文字转换语音功能。
相同的, 讯飞也为我们提供了文字转换语音的API, 我们只需要将上述的通义千问返回的数据作为请求的参数传递给讯飞文字转换语音的API之后, 对应的语音数据会以base64编码返回到本地。
Base64,就是包括小写字母a-z、大写字母A-Z、数字0-9、符号"+"、"/"一共64个字符的字符集,(任何符号都可以转换成这个字符集中的字符,这个转换过程就叫做base64编码。
如下图所示为Base64编码的图表示意。
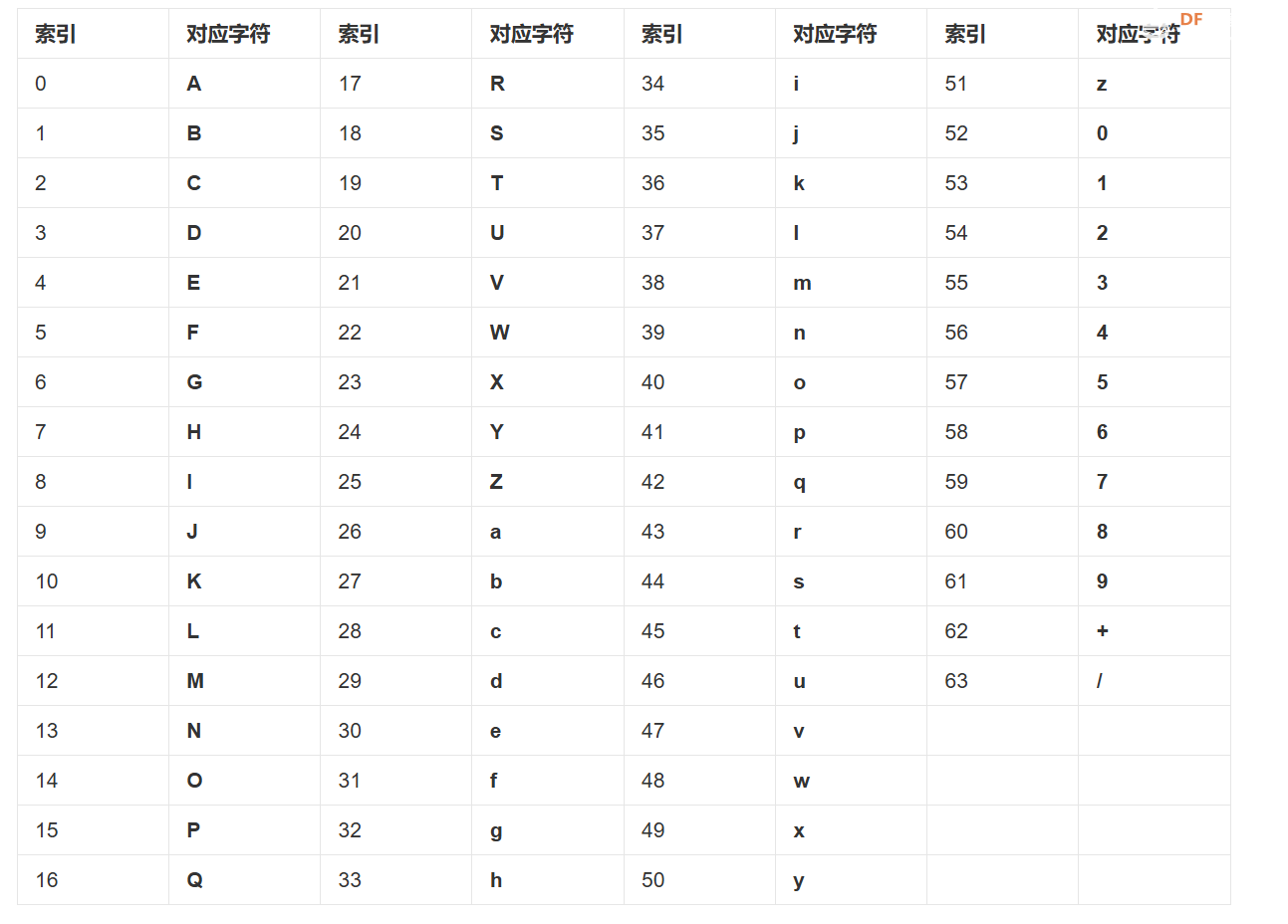
那么具体是怎么转码呢? 现在我们需要对a进行转码(encode),首先查找a的ASCII索引为97, 然后把97转换为二进制,为01100001. 然后按照base64的要求, 6位一组,分为4组,并且不满足6bit的补零处理。 注意上述的补零为低位补0, 因为分成了4份,每一份为6bit,所以地位补零也不会影响到原本的数据。 且2^6 正好等于64,正好为base64的格式。 转换后的数据为01100001 00000000 00000000, 然后分成四份。011000 010000 000000 000000, 接着把上述的数据转换为10进制去根据base64的图表进行查询。即可得到编码后的数据为YQ== (0的话以=代替)
13 - 讯飞语音合成
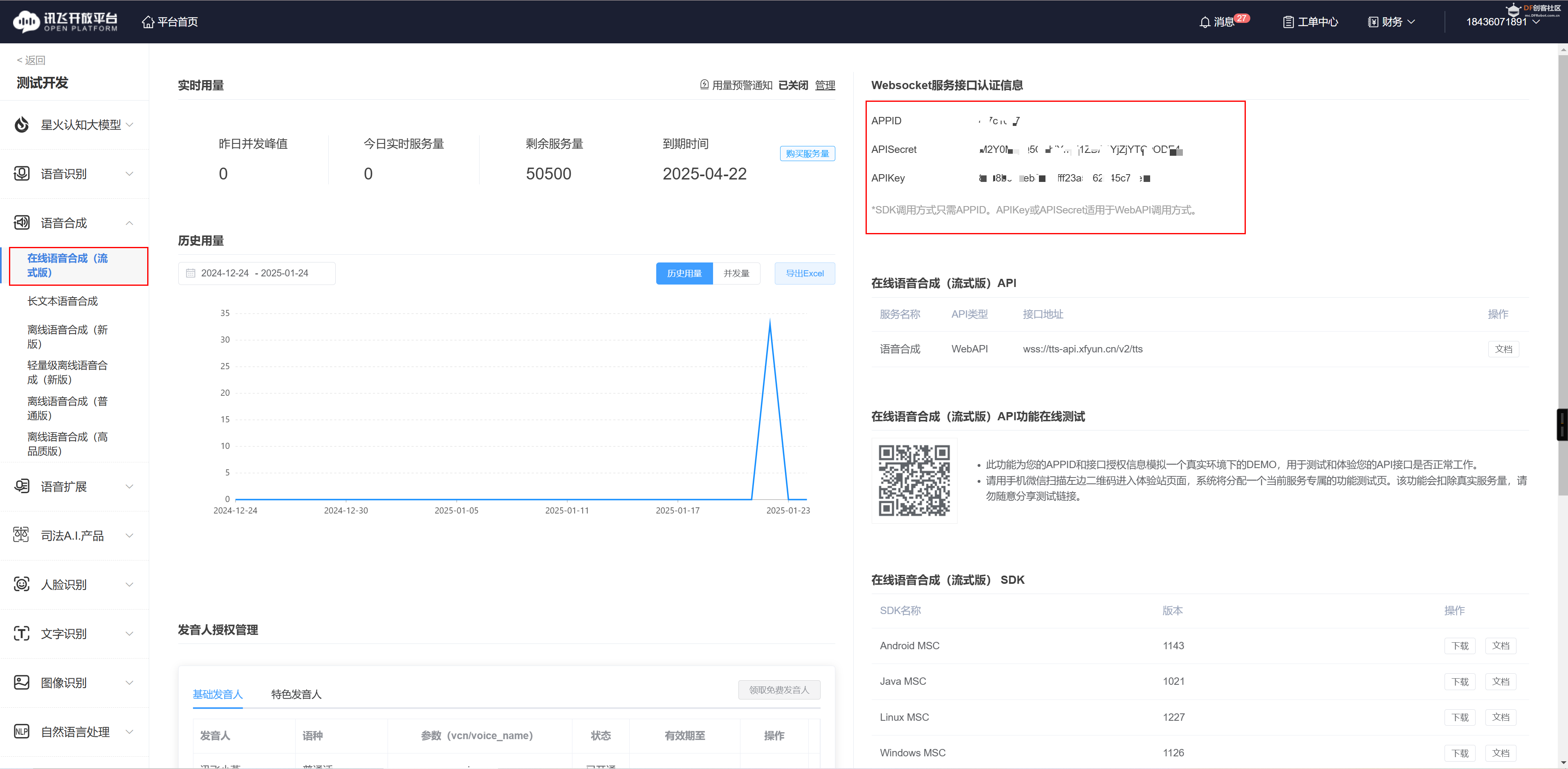
之后我们可以按照上述类似语音转文字的方式来获取讯飞语音合成的key和密钥信息。
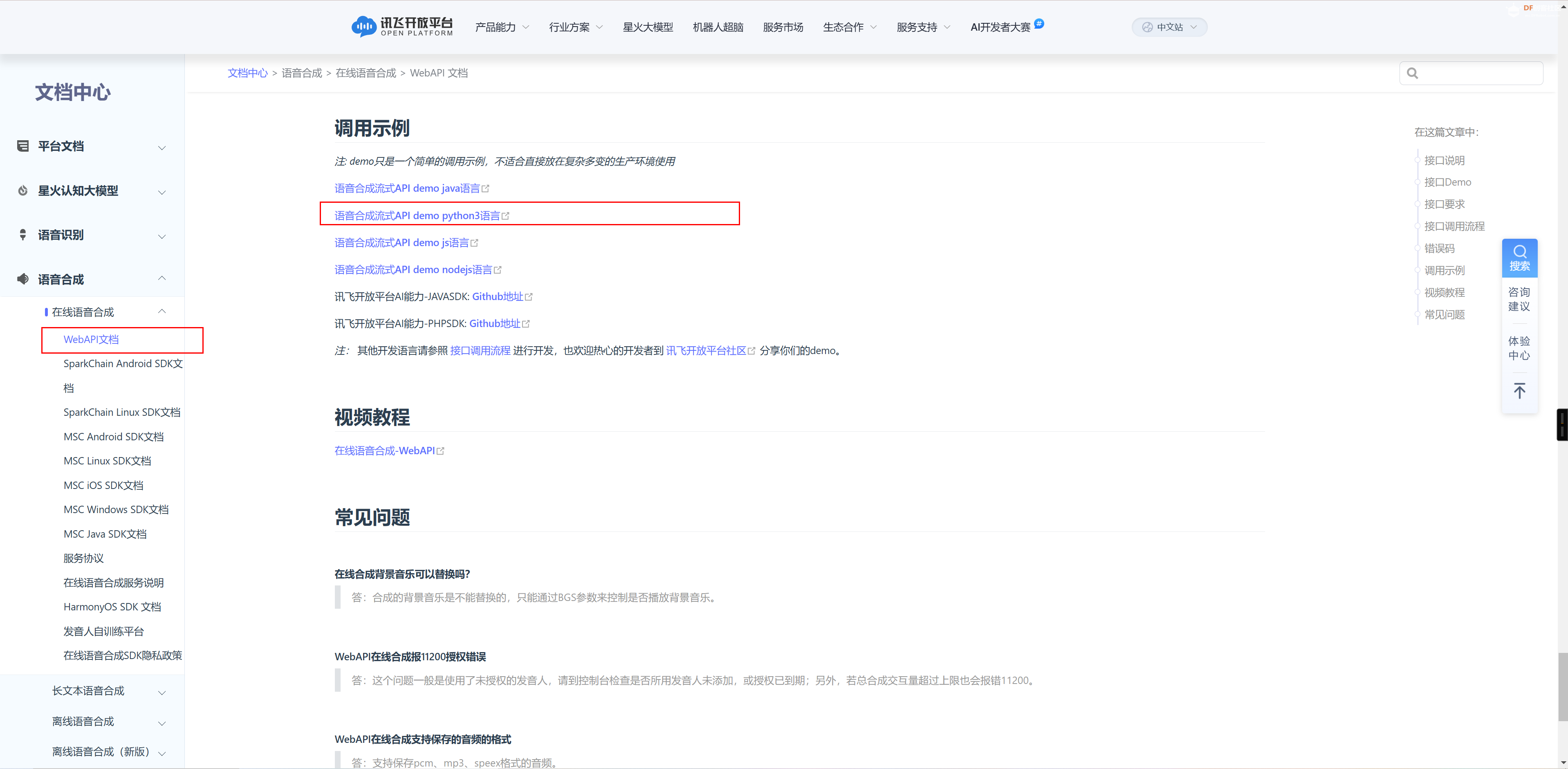
同时在上述的文档中心处,获取对应的python代码。并且将上述的key替换代码中的key参数等。 代码如下所示
- if __name__ == '__main__':
- port = 'COM38'
- baud_rate = 115200
- ser = serial.Serial(port, baud_rate, timeout=1)
- while True:
- save_serial_data_to_bin()
- add_wav_header(OUTPUT_FILE_PATH, "sound.wav", sample_rate=32000, num_channels=1, bits_per_sample=16)
- api = RequestApi(appid="应用ID", secret_key="密钥", upload_file_path=r"sound.wav")
- api.all_api_request()
-
- Turbo(text)
-
- # 文字转换语音
- wsParam = Ws_Param(APPID='你的应用ID', APISecret='你的密钥',
- APIKey='你的key',
- Text=ai_res)
-
- websocket.enableTrace(False)
- wsUrl = wsParam.create_url()
- ws = websocket.WebSocketApp(wsUrl, on_message=on_message, on_error=on_error, on_close=on_close)
- ws.on_open = on_open
- ws.run_forever(sslopt={"cert_reqs": ssl.CERT_NONE})
具体的websocket请求相关代码(用于获取文字转语音,并且将PCM数据保存在本地)
-
- class Ws_Param(object):
- # 初始化
- def __init__(self, APPID, APIKey, APISecret, Text):
- self.APPID = APPID
- self.APIKey = APIKey
- self.APISecret = APISecret
- self.Text = Text
-
- # 公共参数(common)
- self.CommonArgs = {"app_id": self.APPID}
- # 业务参数(business),更多个性化参数可在官网查看
- self.BusinessArgs = {"aue": "raw", "auf": "audio/L16;rate=16000", "vcn": "xiaoyan", "tte": "utf8"}
- self.Data = {"status": 2, "text": str(base64.b64encode(self.Text.encode('utf-8')), "UTF8")}
- #使用小语种须使用以下方式,此处的unicode指的是 utf16小端的编码方式,即"UTF-16LE"”
- #self.Data = {"status": 2, "text": str(base64.b64encode(self.Text.encode('utf-16')), "UTF8")}
-
- # 生成url
- def create_url(self):
- url = 'wss://tts-api.xfyun.cn/v2/tts'
- # 生成RFC1123格式的时间戳
- now = datetime.now()
- date = format_date_time(mktime(now.timetuple()))
-
- # 拼接字符串
- signature_origin = "host: " + "ws-api.xfyun.cn" + "\n"
- signature_origin += "date: " + date + "\n"
- signature_origin += "GET " + "/v2/tts " + "HTTP/1.1"
- # 进行hmac-sha256进行加密
- signature_sha = hmac.new(self.APISecret.encode('utf-8'), signature_origin.encode('utf-8'),
- digestmod=hashlib.sha256).digest()
- signature_sha = base64.b64encode(signature_sha).decode(encoding='utf-8')
-
- authorization_origin = "api_key="%s", algorithm="%s", headers="%s", signature="%s"" % (
- self.APIKey, "hmac-sha256", "host date request-line", signature_sha)
- authorization = base64.b64encode(authorization_origin.encode('utf-8')).decode(encoding='utf-8')
- # 将请求的鉴权参数组合为字典
- v = {
- "authorization": authorization,
- "date": date,
- "host": "ws-api.xfyun.cn"
- }
- # 拼接鉴权参数,生成url
- url = url + '?' + urlencode(v)
- # print("date: ",date)
- # print("v: ",v)
- # 此处打印出建立连接时候的url,参考本demo的时候可取消上方打印的注释,比对相同参数时生成的url与自己代码生成的url是否一致
- # print('websocket url :', url)
- return url
-
-
- def on_message(ws, message):
- try:
- message = json.loads(message)
- code = message["code"]
- sid = message["sid"]
- audio = message["data"]["audio"]
- audio = base64.b64decode(audio)
- status = message["data"]["status"]
- print(message)
- if status == 2:
- print("ws is closed")
- ws.close()
- if code != 0:
- errMsg = message["message"]
- print("sid:%s call error:%s code is:%s" % (sid, errMsg, code))
- else:
-
- with open('./demo.pcm', 'ab') as f:
- f.write(audio)
-
- except Exception as e:
- print("receive msg,but parse exception:", e)
-
-
- # 收到websocket错误的处理
- def on_error(ws, error):
- print("### error:", error)
-
-
- # 收到websocket关闭的处理
- def on_close(ws):
- print("### closed ###")
-
-
- # 收到websocket连接建立的处理
- def on_open(ws):
- def run(*args):
- d = {"common": wsParam.CommonArgs,
- "business": wsParam.BusinessArgs,
- "data": wsParam.Data,
- }
- d = json.dumps(d)
- print("------>开始发送文本数据")
- ws.send(d)
- if os.path.exists('./demo.pcm'):
- os.remove('./demo.pcm')
-
- thread.start_new_thread(run, ())
-
接着我们可以将生成的PCM音频数据转换成wav格式,同时保存在本地nginx代理的资源目录下, 这样的话行空板K10 发送http请求的话可以直接从上位机nginx代理的资源目录来下载程序。同时,当生成数据完毕之后,便可以向K10 发送命令从而来通知K10, 音频数据已经就绪。K10将会发送Http get请求来获取到音频文件,从而保存到内存卡而实现播放功能。
- if __name__ == '__main__':
- port = 'COM38'
- baud_rate = 115200
- ser = serial.Serial(port, baud_rate, timeout=1)
- while True:
- save_serial_data_to_bin()
- add_wav_header(OUTPUT_FILE_PATH, "sound.wav", sample_rate=32000, num_channels=1, bits_per_sample=16)
- api = RequestApi(appid="XXXXXX", secret_key="XXXXXX", upload_file_path=r"sound.wav")
- api.all_api_request()
-
- Turbo(text)
-
- # 文字转换语音
- wsParam = Ws_Param(APPID='XXXXXX', APISecret='XXXXXXX',
- APIKey='8e18b042eb8294fff23a5562d45c7eef',
- Text=ai_res)
-
- websocket.enableTrace(False)
- wsUrl = wsParam.create_url()
- ws = websocket.WebSocketApp(wsUrl, on_message=on_message, on_error=on_error, on_close=on_close)
- ws.on_open = on_open
- ws.run_forever(sslopt={"cert_reqs": ssl.CERT_NONE})
-
- # PCM 文件路径
- pcm_file = './demo.pcm'
- # WAV 文件路径
- wav_file = 'C:\\Users\\23391\\Downloads\\Compressed\\nginx-1.26.2\\nginx-1.26.2\\html\\1.wav'
-
- if os.path.exists(pcm_file):
- save_pcm_as_wav(pcm_file, wav_file)
- else:
- print("未找到 PCM 文件,转换失败。")
- try:
- print(f"已连接到 {port},波特率 {baud_rate}")
-
- time.sleep(2) # Arduino 启动完成
-
- command = "FINISHED\n"
- ser.write(command.encode('utf-8'))
- print(f"发送指令:{command.strip()}")
-
- # 轮询等待 Arduino 状态完成
- start_time = time.time()
- while time.time() - start_time < 60: # 超时 30 秒
- if ser.in_waiting > 0:
- response = ser.readline().decode('utf-8').strip()
- print(f"收到 Arduino 的响应:{response}")
- if response == "TASK_DONE": # Arduino 的任务完成信号
- break
- time.sleep(0.5) # 每 0.5 秒轮询一次
- else:
- print("等待超时")
-
- except serial.SerialException as e:
- print(f"串口错误:{e}")
下述代码为完整的K10端mind + 代码(编辑模式)
复制代码
K10端Mind + 项目
 AI-chat.zip AI-chat.zip
Python 上位机项目(带有虚拟环境, 文件20MB+ 过大无法上传到论坛, 如果你不想自己注册讯飞和通义千问和需要测试KEY请联系我)
通过网盘分享的文件:k10-project.zip
链接: https://pan.baidu.com/s/1DjczMAJ2Ozf7bBLKywsVMQ?pwd=tjfd 提取码: tjfd
NGINX
nginx-1.26.2.zip
效果展示
|



 沪公网安备31011502402448
沪公网安备31011502402448
 置顶卡
置顶卡 变色卡
变色卡 千斤顶
千斤顶






