本帖最后由 云天 于 2022-12-30 22:27 编辑
【ml5.js简介】
ml5.js是一个javascript实现的,能在浏览器里面运行的机器学习框架,它封装了tensorflow.js的API,给开发者提供一个更简单的使用环境,降低了机器学习编码的成本。 tensorflow是google开发出的一套开源机器学习平台,tensorflow.js是tensorflow在javascript中的实现,而ml5.js的底层调用的正式tensorflow.js的API。
虽然ml5和tensorflow.js在浏览器里面运行受到了内存,存储空间等诸多限制,但是他们又都可以使用机器的GPU,大大提高了运算的效率,所以对于一些不需要大量训练的机器学习任务,ml5是一个的选项。ml5最大的特点是简单易用,对于初学者和想体验机器学习的开发人员更是不错的选择。
【图片分类实验】
index.html文件内容:加载"p5.min.js","ml5.min.js"。
图片分类在index.js文件中进行。
- <html>
-
- <head>
- <meta charset="UTF-8">
- <title>classification</title>
-
- <script src="https://cdnjs.cloudflare.com/ajax/libs/p5.js/0.9.0/p5.min.js"></script>
- <script src="https://unpkg.com/ml5@latest/dist/ml5.min.js"></script>
- </head>
- <body>
- <h1>Image classification using MobileNet and p5.js</h1>
- <script src="index.js"></script>
- </body>
-
- </html>
index.js文件内容:
使用ml5提供的模型,如“MobileNet”,”classifier = ml5.imageClassifier('MobileNet');“。需访问”https://tfhub.dev/google/imagenet/mobilenet_v2_100_224/classification/2/model.json?tfjs-format=file“,可能是网络原因,加载出现问题。
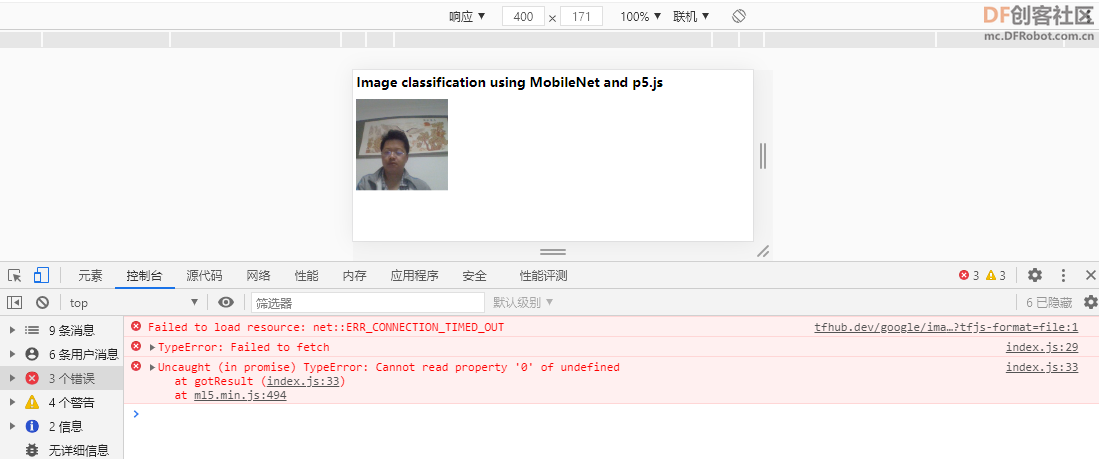
以下为加载我在英荔AI训练平台,训练的模型。”https://train.aimaker.space/train/image/“
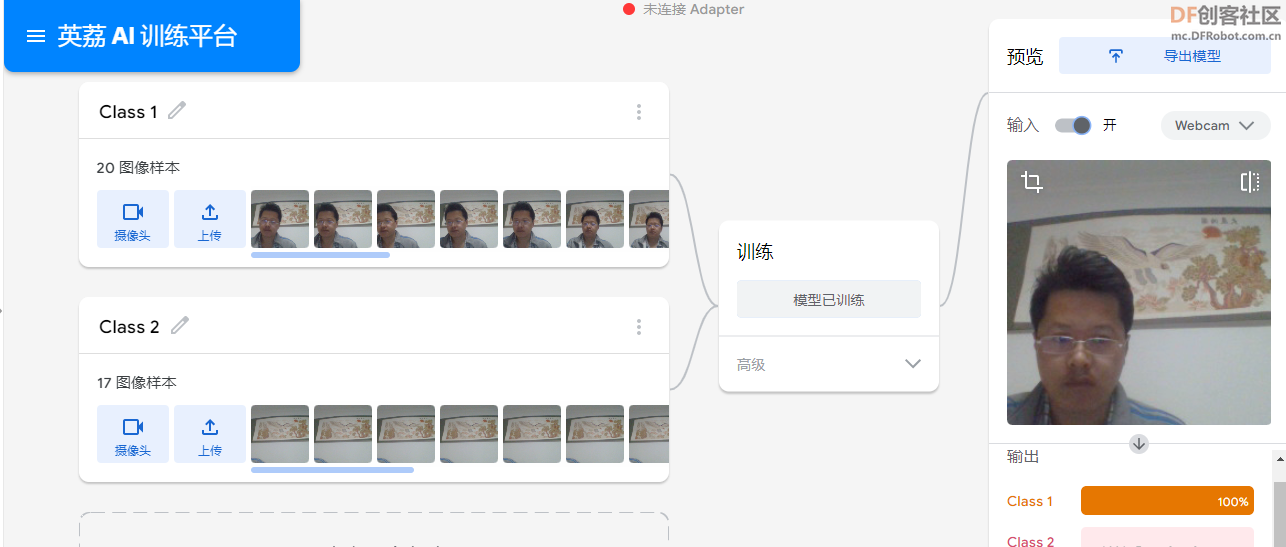
模型训练完成后,下载”model.json“、”weights.bin“、”metadata.json“,三个文件放到当前目录下。
-
- let classifier;
-
- let img;
-
- function preload() {
- // 加载分类器模型 // 可以使用的模型“MobileNet”、“Darknet”和“Darknet-tiny”、“DoodleNet”,或在 Teachable Machine 中训练的任何图像分类模型,或者导入自己的训练集
- /**
- * MobileNet 是一个术语,描述了一种机器学习模型架构,该架构经过优化,可在计算能力有限的平台上运行,例如移动或嵌入式设备上的应用程序。MobileNets 有几个用例,包括图像分类、对象检测和图像分割。这个特殊的 MobileNet 模型是为图像分类训练的。
- * ml5 使用由 TensorFlow.js 创建的 MobileNet,TensorFlow.js 是 TensorFlow 的一个 JavaScript 库。多个 TensorFlow.js MobileNet 版本可用于图像分类,截至 2019 年 6 月,ml5 默认导入 MobileNetV2。
- * DarkNet(或DarkNet Reference)和Darknet-tiny(或Tiny Darknet是小型且快速的预训练模型。Tiny Darknet是两者中较小的模型,但Darknet Reference更快。开发者提供了一个开源框架,也称为Darknet ,用于运行模型。
- * Darknet Reference 被列为 ImageNet 分类的预训练模型,因此数据很可能是来自 ImageNet 数据库的照片。
- */
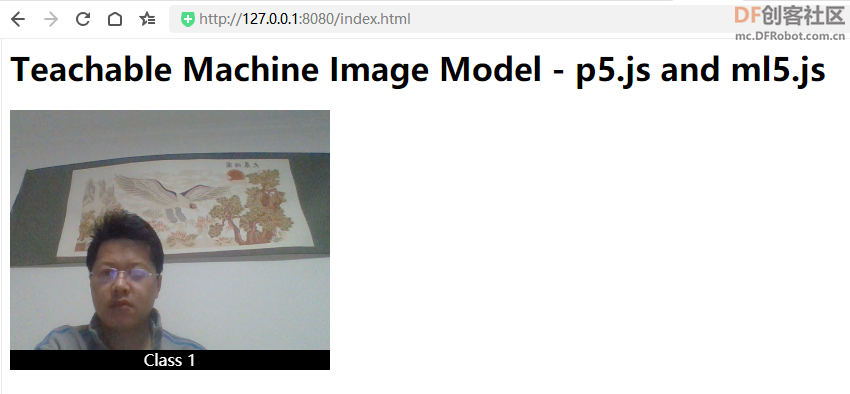
【摄像头识别】index.html文件内容:
- <html>
-
- <head>
- <meta charset="UTF-8">
- <title>classification</title>
-
- <script src="https://cdnjs.cloudflare.com/ajax/libs/p5.js/0.9.0/p5.min.js"></script>
- <script src="https://cdnjs.cloudflare.com/ajax/libs/p5.js/0.9.0/addons/p5.dom.min.js"></script>
- <script src="https://unpkg.com/ml5@latest/dist/ml5.min.js"></script>
- <div></div>
-
- </head>
- <body>
- <h1>Teachable Machine Image Model - p5.js and ml5.js</h1>
- <script src="index.js"></script>
- </body>
-
- </html>
”model.json“放在当前目录下。index.js文件内容:- let classifier;
-
-
- // Video
- let video;
- let flippedVideo;
- // To store the classification
- let label = "";
-
- // Load the model first
- function preload() {
- classifier = ml5.imageClassifier( 'model.json');
- }
-
- function setup() {
- createCanvas(320, 260);
- // Create the video
- video = createCapture(VIDEO);
- video.size(320, 240);
- video.hide();
-
- flippedVideo = ml5.flipImage(video);
- // Start classifying
- classifyVideo();
- }
-
- function draw() {
- background(0);
- // Draw the video
- image(flippedVideo, 0, 0);
-
- // Draw the label
- fill(255);
- textSize(16);
- textAlign(CENTER);
- text(label, width / 2, height - 4);
- }
-
- // Get a prediction for the current video frame
- function classifyVideo() {
- flippedVideo = ml5.flipImage(video)
- classifier.classify(flippedVideo, gotResult);
- flippedVideo.remove();
-
- }
-
- // When we get a result
- function gotResult(error, results) {
- // If there is an error
- if (error) {
- console.error(error);
- return;
- }
- // The results are in an array ordered by confidence.
- // console.log(results[0]);
- label = results[0].label;
- // Classifiy again!
- classifyVideo();
- }
-
【声音识别】
直接加载”model.json“模型文件,会出现地址错误:
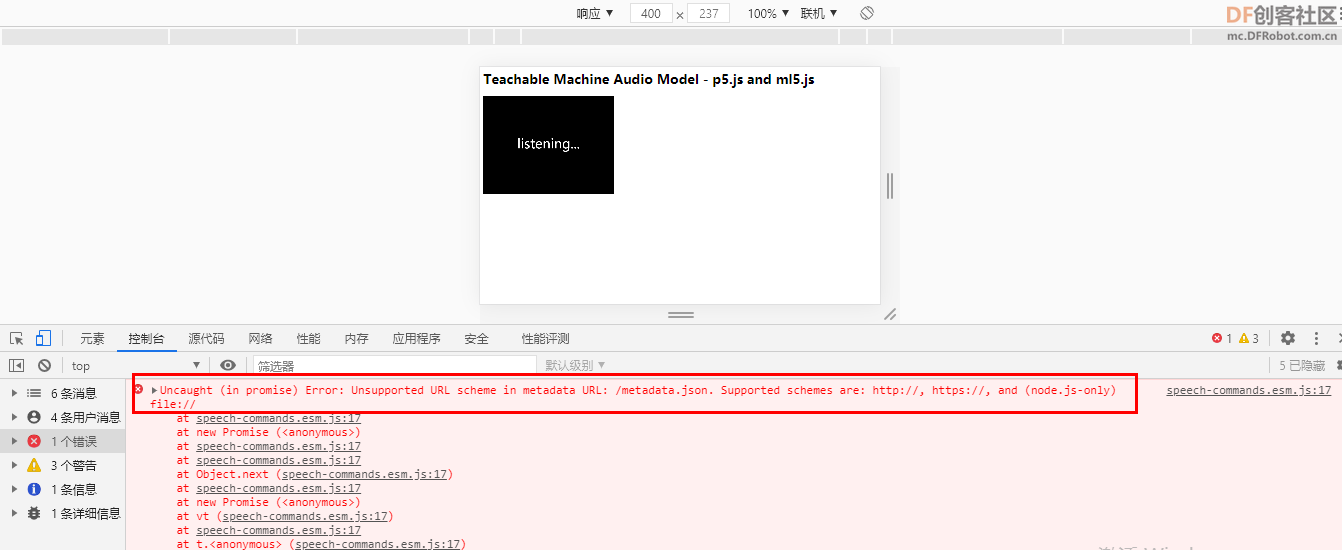
安装node,开启WEB服务。
复制代码
server.js文件内容:
注意修改目录地址:
- var http = require('http');
- var fs = require('fs');//引入文件读取模块
- var documentRoot = 'C:/Users/Administrator/Desktop/my_model/';//需要访问的文件的存放目录
- var server= http.createServer(function(req,res){
- //客户端输入的url,例如如果输入localhost:8080/index.html
- //那么这里的url == /index.html
- var url = req.url;
- var file = documentRoot + url;
- console.log(url);
- fs.readFile( file , function(err,data){
- /*
- 一参为文件路径
- 二参为回调函数
- 回调函数的一参为读取错误返回的信息,返回空就没有错误
- 二参为读取成功返回的文本内容
- */
- if(err){
- //HTTP 状态码 404 : NOT FOUND
- //Content Type:text/plain
- res.writeHeader(404,{
- 'content-type' : 'text/html;charset="utf-8"'
- });
- res.write('<h1>404错误</h1><p>你要找的页面不存在</p>');
- res.end();
- }else{
- //HTTP 状态码 200 : OK
- //Content Type:text/plain
- res.writeHeader(200,{
- 'content-type' : 'text/html;charset="utf-8"'
- });
- res.write(data);//将index.html显示在客户端
- res.end();
- }
- });
- }).listen(8080);
- console.log('OK');
index.js文件内容,使用http://地址加载模型:classifier = ml5.soundClassifier( 'http://127.0.0.1:8080/model.json');
-
-
- // Global variable to store the classifier
- let classifier;
-
- // Label
- let label = 'listening...';
-
- function preload() {
- // Load the model
- //使用http://地址加载模型
- //classifier = ml5.soundClassifier( 'model.json');
- classifier = ml5.soundClassifier( 'http://127.0.0.1:8080/model.json');
-
- }
-
- function setup() {
- createCanvas(320, 240);
- // Start classifying
- // The sound model will continuously listen to the microphone
- classifier.classify(gotResult);
- }
-
- function draw() {
- background(0);
- // Draw the label in the canvas
- fill(255);
- textSize(32);
- textAlign(CENTER, CENTER);
- text(label, width / 2, height / 2);
- }
-
-
- // The model recognizing a sound will trigger this event
- function gotResult(error, results) {
- if (error) {
- console.error(error);
- return;
- }
- // The results are in an array ordered by confidence.
- // console.log(results[0]);
- label = results[0].label;
- }
【在线编程】
在线编程的网页(https://chn.ai/ml5.html),这个页面集成了ml5.js的库以及需要的模型数据数据,这样大家不需要自己搭建环境就可以开始学习了。我们打开网址就直接开始编程。
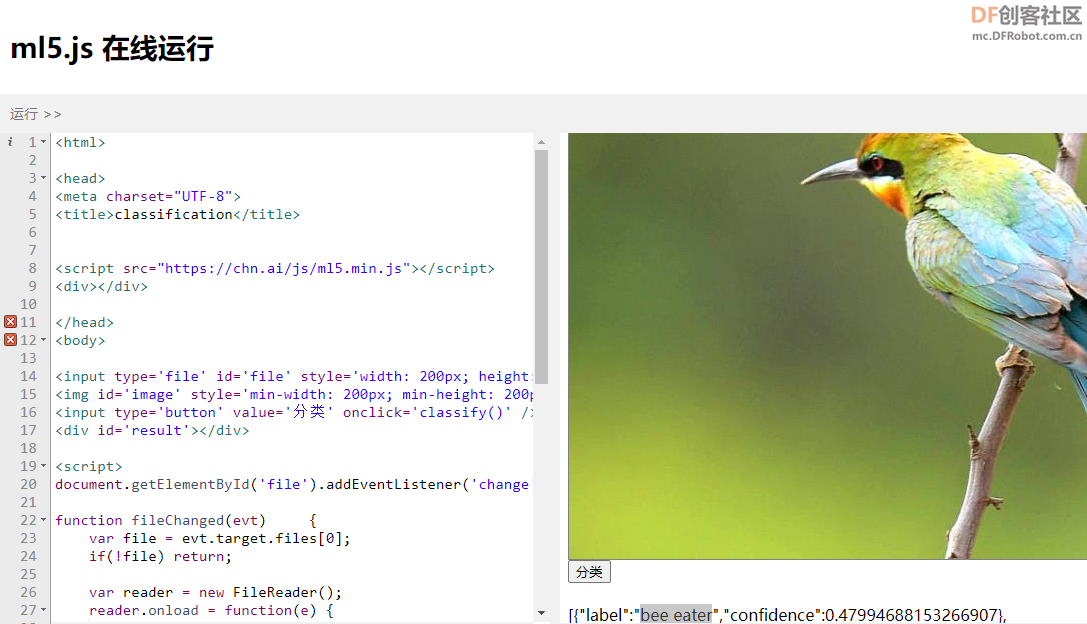
1、图像分类
- <!DOCTYPE html>
- <html lang="en">
- <head>
- <meta charset=utf-8 />
-
- <script src='js/ml5.min.js'></script>
- </head>
- <body>
-
- <input type='file' id='file' style='width: 200px; height: 100px; border: dashed'/> <br/>
- <img id='image' style='min-width: 200px; min-height: 200px; border: solid 1px grey' /> <br/>
- <input type='button' value='分类' onclick='classify()' /> <br/><br/>
- <div id='result'></div>
-
- <script>
- document.getElementById('file').addEventListener('change', fileChanged, false);
-
- function fileChanged(evt) {
- var file = evt.target.files[0];
- if(!file) return;
-
- var reader = new FileReader();
- reader.onload = function(e) {
- document.getElementById('image').setAttribute('src', e.target.result);
- }
- reader.readAsDataURL(file);
- }
-
- var modelLoaded = false;
- var classifier = ml5.imageClassifier('MobileNet', function() {
- // console.log('model loaded');
- document.getElementById('result').innerHTML = 'model loaded';
- modelLoaded = true;
- });
-
- function classify() {
- if(!modelLoaded) return;
-
- classifier.classify(
- document.getElementById('image'),
- function(err, result) {
- document.getElementById('result').innerHTML = JSON.stringify(result);
- }
- )
- }
- </script>
-
- </body>
- </html>
我们在初始化ml5模型的时候,系统会自动从网络上下载对应的网络模型的结构和权重数据,这就是为什么我们短短几行代码就可以实现一个图像分类的功能。真正起作用的是这个mobilenet网络结构与训练结果,这些都有人做好并放在服务器上。我们初始化ml5分类器的时候,就从相应位置下载这些数据并在浏览器的内存里面重建这个网络。
2、Feature Extractor 特征提取、训练和分类
- <!DOCTYPE html>
- <html lang="en">
- <head>
- <title>Feature Extractor </title>
- <script src='js/ml5.min.js'></script>
- </head>
- <body onload='pageLoaded()'>
-
- <video id='videoElement' autoplay='true'></video>
- <br/>
- <input type='button' value='add phone' onclick='addPhone()' />
- <input type='button' value='add cup' onclick='addCup()' />
- <br/>
- <input type='button' value='train' onclick='train()' />
- <input type='button' value='classify' onclick='classify()' />
- <hr/>
- <div id='log' style='font-size: 80%; background-color: #efefef'></div>
-
- <script>
- var video = null;
- var featureExtractor = null;
- var classifier = null;
-
- function pageLoaded() {
- initVideo();
- initExtractor();
- }
-
- function initExtractor() {
- featureExtractor = ml5.featureExtractor('MobileNet', function() {
- log('model loaded');
- classifier = featureExtractor.classification(video, function() {
- log('classifier inited');
- });
- })
- }
-
- function initVideo() {
- video = document.getElementById('videoElement');
-
- if(!navigator.mediaDevices.getUserMedia) return;
- navigator.mediaDevices.getUserMedia({video: true})
- .then(function(stream) {
- video.srcObject = stream;
- log('video ready');
- })
- .catch(function(err) {
- log(err);
- })
- }
-
- function addPhone() {
- classifier.addImage('phone', function() {log('phone added');});
- }
-
- function addCup() {
- classifier.addImage('cup', function() {log('cup added');});
- }
-
- function train() {
- classifier.train(function(loss) {
- log(loss);
- })
- }
-
- function classify() {
- classifier.classify(function(err, result) {
- if(err) {
- log(err);
- return;
- }
-
- // else
- log(JSON.stringify(result));
- })
- }
-
- function log(content) {
- var elem = document.getElementById('log');
- if(!elem) return;
- elem.innerHTML = content + "<br/>" + elem.innerHTML;
- }
- </script>
- </body>
- </html>
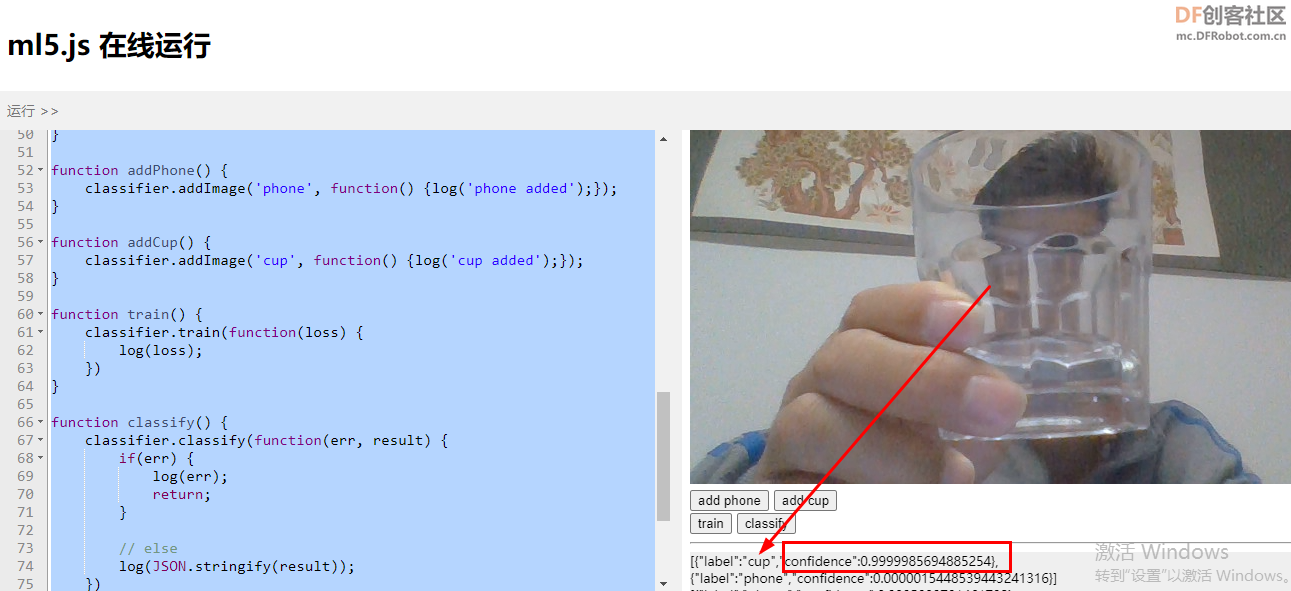 这段代码的作用就是通过电脑摄像头录制的视频作为源进行训练。比如放一个杯子在摄像头前,点击“add phone”,就添加了一个训练数据。从不同角度,不同远近多添加几个‘杯子’的样本;然后以同样的办法添加‘手机’的样本。点击‘train’进行训练。等训练停止过后,再将杯子或手机或者其它任何东西放到摄像头前,点击‘classify’进行识别,看看识别分类的效果。 这段代码的作用就是通过电脑摄像头录制的视频作为源进行训练。比如放一个杯子在摄像头前,点击“add phone”,就添加了一个训练数据。从不同角度,不同远近多添加几个‘杯子’的样本;然后以同样的办法添加‘手机’的样本。点击‘train’进行训练。等训练停止过后,再将杯子或手机或者其它任何东西放到摄像头前,点击‘classify’进行识别,看看识别分类的效果。
为什么不多的图片,一会儿就能训练出一个准确率还算不错的分类器呢?不是听说深度学习需要大量的数据,长时间的烧显卡才能训练处一个模型吗?要理解这个问题,我们可以拿人类的认知来理解一下:我们告诉一个从来没有见过兔子的小孩说有四条小短腿,两个长耳朵,红眼睛,毛茸茸的小动物就是是小白兔,即使这他没有亲眼见过,我保证一见到小白兔这个小孩就能立刻辨别出来。但是假设一个外星小孩来到地球,我们同样告诉它有四条小短腿,两个长耳朵,红眼睛,毛茸茸的小动物就是是小白兔,这个外星小孩看到小白兔它也不认识。因为地球小孩对腿,耳朵,眼睛,毛茸茸这些属性都有先验的知识,他在其他动物那里学到了腿长什么样,耳朵什么样,眼睛又是什么样,而外星小孩没有这些知识。
我们在代码里面生成一个叫featureExtractor的对象,这个feature就是‘特征’,这些特征是mobileNet针对一个叫imageNet的图片集进行了训练。我们知道神经网络通常是由很多层的网络构成的。研究人员发现,构成mobileNet的卷积神经网络,最开始几层是对图像的一些线段,点,边界做一些抽象;后面几层对更深一层的特征进行抽象,比如一些形状,颜色,区域块等;再后面的网络层则对更抽象的特征更活跃,比如看到眼睛,耳朵,人脸等等。刚刚我们的训练代码就好像小孩认识兔子一样,只需要训练那些抽象特征的集合对应什么物体即可,所以只需要相对少的数据集和计算就可以得到不错的训练结果。
我们只用训练四条小短腿腿,两个长耳朵,红眼睛,毛茸茸的动物是小白兔,四条长腿,长嘴巴,三角耳,大尾巴,灰色皮毛的是大灰狼就行了,而不用训练ml5怎么去识别腿,尾巴,眼睛,颜色和皮毛等等,这些工作在其它人的训练里面已经做了。
3、
- <!DOCTYPE html>
- <html lang="en">
- <head>
- <title>Regression</title>
- <script src='js/ml5.min.js'></script>
- <script src="https://cdn.bootcdn.net/ajax/libs/p5.js/1.1.9/p5.min.js"></script>
- </head>
- <body>
- <script>
-
- let video, canvas, logger;
- let size = {w: 500, h: 400};
- let featureExtractor, regressor;
- let largeCt = 0, mediumCt = 0, smallCt = 0;
- let img;
- let value;
-
- function preload() {
- img = loadImage('img/docStrange.png');
- }
-
- function setup() {
- video = createCapture(VIDEO);
- video.size(size.w, size.h);
- video.style('transform: rotateY(180deg)');
-
- canvas = createCanvas(size.w, size.h, WEBGL);
- canvas.style('position: absolute; z-index: 10;');
-
- createDiv();
- createButton('add large').mouseClicked(addLarge);
- createButton('add medium').mouseClicked(addMedium);
- createButton('add small').mouseClicked(addSmall);
-
- createDiv();
- createButton('train').mouseClicked(train);
- createButton('save').mouseClicked(saveModel);
- createButton('load').mouseClicked(function() {
- logging('loading custom model');
- regressor.load(files.elt.files, function() {
- logging('custom model loaded');
- });
- });
- files = createFileInput();
- files.attribute('multiple', true);
-
- createDiv();
- createButton('go').mouseClicked(go);
-
- logger = createP();
-
- initExtractor();
- }
-
- function initExtractor() {
- featureExtractor = ml5.featureExtractor('MobileNet', function() {
- logging('model loaded');
- regressor = featureExtractor.regression(video, function() {
- logging('regressor inited');
- })
- })
- }
-
- function saveModel() {
- regressor.save();
- }
-
- /*function loadModel() {
- }*/
-
- function addLarge() {
- regressor.addImage(1, function() {
- logging('large added ' + ++largeCt);
- })
- }
- function addMedium() {
- regressor.addImage(0.5, function() {
- logging('medium added ' + ++mediumCt);
- })
- }
- function addSmall() {
- regressor.addImage(0, function() {
- logging('small added ' + ++smallCt);
- })
- }
-
- function train() {
- regressor.train(function(loss) {
- logging(loss);
- })
- }
-
- function go() {
- setInterval(function() {
- regressor.predict(function(err, result) {
- if(err) {
- logging(err);
- return;
- }
-
- // else
- value = result.value;
- logging(value);
- })
- }, 100);
- }
-
- function draw() {
- // image(img, 0, 0, 50, 50);
- if(!value) return;
-
- let r = value * 500 / 2;
-
- //background('rgba(0,0,0, 0)');
- rotateZ(frameCount * 0.01);
- background(0);
- fill(255);
- ellipse(0,0,r * 2,r * 2);
- //image(img, -r, -r, r * 2, r * 2);
- }
-
- function logging(c) {
- logger.html(c + '<br/>' + logger.html());
- }
- </script>
-
- </body>
- </html>
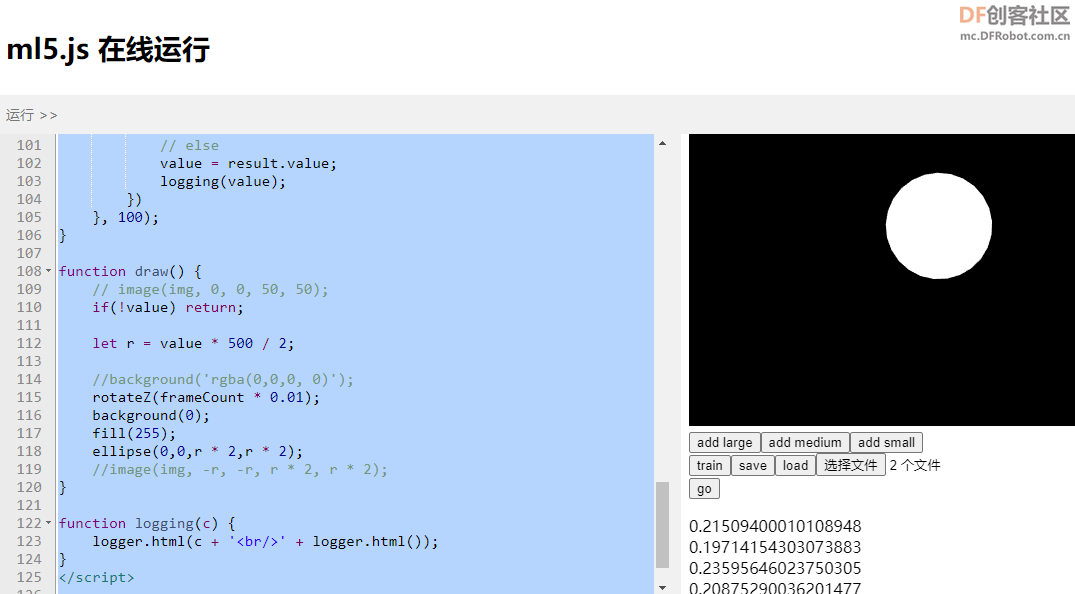
回归是想得到一个线性的答案,比如预测房价,识别物体在图片中的位置,回归的答案是一个连续的值。而分类是想得到一个离散的值,比如我们想分辨图片中水果是苹果还是梨,虽然分类结果会给一个0-1的confidence值,但是我们想要的结果就是知道它是苹果还是梨。
所以在训练regression的模型的时候,我们输入到网络里面的数据是图片 + 一个数字,这个数字代表这个图片状态的程度。所以我们添加训练数据的时候,调用addImage()方法,第一个参数是一个数字,这是一个0-1之间的值,用来告诉模型当前图像当前的状态,比如我们手掌全开的时候,就是addLarge函数里面,这个值是1;addMedium(),手掌半开的时候这个值是0.5;addSmall()手掌闭合的时候这个值是0;在预测的时候得到的结果就是根据刚才训练的标准来预测的值,总体也是0-1范围内的,手掌越打开越接近1,越闭合越接近0。
可能之前大家都会问,我们网页上的网络模型,在每次刷新页面的时候都会全部清空,那是不是每次都需要重新训练呢?当然,ml5提供了save和load方法,用来保存和加载训练好的模型,这样即使页面被刷新,我们也有办法把原来训练好的模型加载到内存中来。
复制代码
这个save方法执行后页面会提示下载多个文件,如果浏览器询问权限,回答‘同意’下载多个文件。下载的文件包括model.json描述网络的结构;model.weights.bin存放的是网络里面神经节点的权重值。所以我们加载模型的时候也需要指定这两个文件。
- files = createFileInput();
- files.attribute('multiple', true);
再来看加载的方法:
- regressor.load(files.elt.files, function() {
- logging('custom model loaded');
- });
我们这里将files.elt是从p5的files变量里面拿到对应的DOM对象,然后再拿到DOM对象里面的files对象,这样刚才save的model和数据并不需要上传到服务器上,而是浏览器直接从文件系统里面读取出来。
【图像声音互动】
一、实验"音频可视化":
音频可视化,是指一种以视觉为核心,以音频为载体,以大众为诉求对象,借助多种新媒体技术等传播媒介,通过画面、影像来诠释音乐内容的、视听结合的大众化传播方式。它能为理解、分析和比较音频作品形态的表现力和内外部结构提供的一种直观视觉呈现的技术。
将麦克风获取到的声音转变成图像
获取所需的目标音频信息
将振幅转化为波形与环形的振幅
其他的是通过声音的大小,获取音频的振幅信息,向绘制圆形的大小参数传递声音振幅的值,以达到不同声音大小的圆形。
通过获取音频的振幅信息,将振幅信息传参到小球跳高的高度参数,以达到小球不同声音大小时所调高的高度不同。
主要运用的获取音频信息的函数为mic.getLevel()函数。
-
- <!DOCTYPE html>
- <html lang="en">
- <head>
- <meta charset="utf-8">
- <title>交互</title>
- <script src="https://cdnjs.cloudflare.com/ajax/libs/p5.js/1.1.9/p5.js"></script>
- <script src="https://cdnjs.cloudflare.com/ajax/libs/p5.js/1.4.0/addons/p5.sound.js"></script>
- </head>
- <body>
-
- <script type="text/javascript">
- // Global variable to store the classifier
- var capture;
- var mic;
- var volhistory=[];
- function setup(){
- // createCanvas(240,180);
- // capture = createCapture(VIDEO);
-
- let cnv = createCanvas(400, 400);
- // cnv.mousePressed(userStartAudio);
- // textAlign(CENTER);
- angleMode(DEGREES);
- cnv.mousePressed(userStartAudio);
- textAlign(CENTER);
- //amp = new p5.Amplitude();//
- mic = new p5.AudioIn();
- mic.start();
- //amp.setInput(mic);//
-
- }
-
- function draw(){
- // image(capture,0,0,width,height);
-
- //小球跳高
- background(0);
- fill(255);
- text('tap to start', width/2, 20);
- micLevel = mic.getLevel();
- var y = height - micLevel * height;
- ellipse(width/2, y, 10, 10);
-
- //小球放大
- //background(0);
- //fill(255);
- var vol = mic.getLevel();
- ellipse(100, 100, vol*200, vol*200);
-
- //横向音频
- volhistory.push(vol);
- stroke(255);
- noFill();
- beginShape();
- for(var i = 0;i<volhistory.length;i++){
- var y = map(volhistory[i],0,1,350,0);
- vertex(i, y)
- }
- if(volhistory.length>width-50){
- volhistory.splice(0,1);
- }
- stroke(255, 0,0);
- line(volhistory.length, 0, volhistory.length, height);
- stroke(255);
- endShape();
-
-
- //360度音频
- translate(width/2, height/2);
- beginShape();
- for(var i = 0;i<360;i++){
- var r = map(volhistory[i],0,1,10,100);
- var x = r*cos(i);
- var y = r*sin(i);
- vertex(x, y)
- }
- if(volhistory.length>360){
- volhistory.splice(0,1);
- }
- endShape();
-
- }
- //beginShape()函数用于绘制更复杂的形状。指定此函数将开始记录将用于绘制形状的顶点。必须调用endShape()函数以结束记录并完成形状。
- //调用beginShape()函数后,应使用vertex()命令指定一系列顶点。使用当前的笔触颜色勾勒出形状,并以当前的填充色填充。可以定义一个可选参数以使用要绘制的形状种类。
- //绘制的形状不适用于translate(),rotate()和scale()等转换函数。同样,不能将其他形状与beginShape()一起使用。
- </script>
- </body>
- </html>
二、实验“视频交互”
-
- var video;
- var vScale = 16;
-
- function setup() {
- createCanvas(640, 480);
- // capture = createCapture(VIDEO);
- // capture.hide();//图像隐藏
- pixelDensity(1);//高像素密度
-
- video = createCapture(VIDEO);
- video.size(width / vScale, height / vScale);
-
- }
-
- function draw() {
-
- //黑白图像
- background(51);
- video.loadPixels();
- loadPixels();
- for (var y = 0; y < video.height; y++) {
- for (var x = 0; x < video.width; x++) {
- var index = (x + y * video.width) * 4;
- var r = video.pixels[index + 0];
- var g = video.pixels[index + 1];
- var b = video.pixels[index + 2];
-
- var bright = (r + g + b) / 3;
-
- var w = map(bright, 0, 255, 0, vScale);
- noStroke();
- fill(bright);
- rect(x * vScale, y * vScale, w, w);
-
- pixels[index + 0] = r;
- pixels[index + 1] = g;
- pixels[index + 2] = b;
- pixels[index + 3] = 255;
- }
- }
- // updatePixels();
-
- }
-
|



 沪公网安备31011502402448
沪公网安备31011502402448
 置顶卡
置顶卡 变色卡
变色卡 千斤顶
千斤顶

 活跃会员
活跃会员
 宣传大使
宣传大使
 牛X认证
牛X认证
 创客造
创客造
 编辑选择奖
编辑选择奖
 志“童”道合
志“童”道合
 编辑选择奖
编辑选择奖
 编辑选择奖
编辑选择奖
 编辑选择奖
编辑选择奖
 编辑选择奖
编辑选择奖






