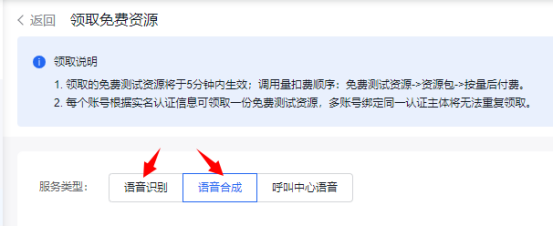
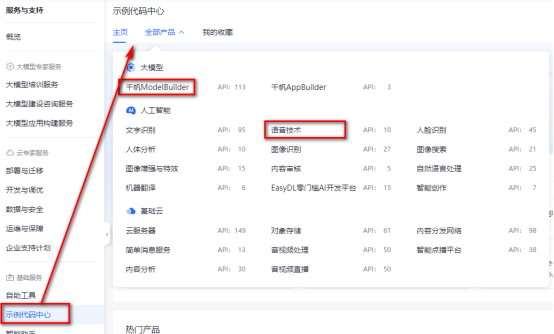
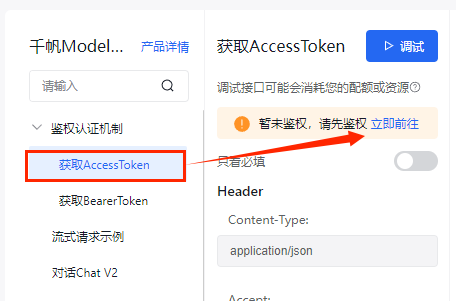
本帖最后由 湘里人 于 2025-1-14 16:26 编辑 烧录固件 https://qianfan.cloud.baidu.com/ ... fa8684dc35f119d4f3f https://console.bce.baidu.com/ai/#/ai/speech/app/create https://console.bce.baidu.com/ai-engine/speech/overview/index ,领取免费资源https://console.bce.baidu.com/support/?u=dhead#/api unihiker_k10官方库集成了LVGL(轻量级和多功能图形库), 为创建美观的视觉效果提供了可能,但官方固件对中文支持不是很好。 1、建立中文字库,实现中文显示 具体操作见我以前的帖子: K10官方micropython_unihiker_k10固件支持中文显示的方法 机器人 的动态表情,命名为change_eyes.pyfrom unihiker_k10 import screen, acce
import time, gc
import lvgl as lv
import fs_driver, math
# 初始化LVGL和屏幕
screen.init(dir=2)
scrn = lv.screen_active()
scrn.set_style_bg_color(lv.color_hex(0x000000), 0)
# 初始化文件系统驱动
fs_drv = lv.fs_drv_t()
fs_driver.fs_register(fs_drv, 'S')
# 创建开口向上的弧线
arc3 = lv.arc(scrn)
arc3.set_size(200, 100) # 设置弧线的大小
arc3.set_bg_angles(90, 100) # 设置背景角度为0到180度,表示开口向上
arc3.set_angles(0, 180) # 设置显示角度为0到180度
arc3.align(lv.ALIGN.BOTTOM_MID, 50, -60) # 将弧线放置在屏幕底部中间位置,稍微向上移动
# 创建第一个蓝色实心球(眼球)
eye1 = lv.led(scrn)
eye1.set_size(60, 30) # 设置大小为32x20像素
eye1.set_color(lv.color_hex(0x0000FF)) # 设置颜色为蓝色
eye1.align(lv.ALIGN.TOP_LEFT, 50, 90) # 将眼球放置在第一个圆球的中间
# 创建第二个蓝色实心球(眼球)
eye2 = lv.led(scrn)
eye2.set_size(60, 30) # 设置大小为32x20像素
eye2.set_color(lv.color_hex(0x0000FF)) # 设置颜色为蓝色
eye2.align(lv.ALIGN.TOP_RIGHT, -50, 90) # 将眼球放置在第二个圆球的中间
def animate_mouth():
for angle in range(360, 300, -10):
arc3.set_angles(angle, angle + 180) # 设置显示角度为0到180度
# time.sleep(2) # 持续2秒
time.sleep(0.1)
for angle in range(300, 360, 10):
arc3.set_angles(angle, angle + 180) # 设置显示角度为0到180度
# time.sleep(2) # 持续2秒
time.sleep(0.1)
# 动态改变眼球的水平位置以模拟表情变化
def change_eyes():
# # 向左看
eye1.align(lv.ALIGN.TOP_LEFT, 40, 90)
eye2.align(lv.ALIGN.TOP_RIGHT, -60, 90)
time.sleep(0.2) # 持续1秒
# 向右看
eye1.align(lv.ALIGN.TOP_LEFT, 60, 90)
eye2.align(lv.ALIGN.TOP_RIGHT, -40, 90)
time.sleep(0.2) # 持续1秒
# 回到中间
eye1.align(lv.ALIGN.TOP_LEFT, 50, 90)
eye2.align(lv.ALIGN.TOP_RIGHT, -50, 90)
time.sleep(0.2) # 持续1秒
animate_mouth()
# 启动眼球变化
change_eyes()
# 启动表情变化
# change_expression()
复制代码 from unihiker_k10 import screen, mic, button, wifi,speaker
import ubinascii
import json
import time
import urequests as requests
import lvgl as lv
import fs_driver, math
from change_eyes import change_eyes
from machine import Timer
# 全局变量
scrn = None
font_cn = None
token= None
AItoken=None
text = ""
label_title = None
# 连接WiFi
def connect_wifi(ssid, password):
wifi.connect(ssid=ssid, psd=password, timeout=50000)
while not wifi.status():
time.sleep(0.1)
print("WiFi connected:", wifi.info())
# 初始化屏幕和字体
def init_screen():
global scrn, font_cn, label_title
screen.init(dir=2)
scrn = lv.screen_active()
scrn.set_style_bg_color(lv.color_hex(0x000000), 0)
fs_drv = lv.fs_drv_t()
fs_driver.fs_register(fs_drv, 'S')
font_cn = lv.binfont_create("S:my_font_16.bin")
if font_cn is None:
print("字体加载失败")
else:
print("字体加载成功")
# 创建一个新的标签
label_title = lv.label(scrn)
label_title.set_text("字体加载成功")
label_title.set_width(200)
label_title.align(lv.ALIGN.TOP_LEFT, 20, 20)
if font_cn:
label_title.set_style_text_font(font_cn, 0) # 设置中文字体
scrn.set_style_bg_color(lv.color_hex(0x000000), 0)
# 更新标签的回调函数
def update_label():
global text
print("text:",text, time.localtime())
label_title.set_text(text)
# 百度语音识别
def baidu_speech_recognize(audio_file, token):
print("token:",token)
url = "https://vop.baidu.com/server_api"
with open(audio_file, "rb") as f:
audio_data = f.read()
base64_data = ubinascii.b2a_base64(audio_data)[:-1].decode('utf-8')
payload = json.dumps({
"format": "wav",
"rate": 16000,
"channel": 1,
"cuid": "UNIHIKER_K10",
"speech": base64_data,
"len": len(audio_data),
"token": token
})
headers = {
'Content-Type': 'application/json',
'Accept': 'application/json'
}
response = requests.post(url, headers=headers, data=payload)
print(response.text)
data = json.loads(response.text)
return ''.join(data['result'])
def Baidu_TTS(filename,text, token):
# 设置请求参数
params = {
'tok': token,
'tex': text, # 直接使用text,不需要quote_plus
'per': 5,#基础音库:度小宇=1,度小美=0,度逍遥(基础)=3,度丫丫=4,精品音库:度逍遥(精品)=5003,度小鹿=5118,度博文=106,度小童=110,度小萌=111,度米朵=103,度小娇=5
'spd': 5,#中语速
'pit': 5,#中语调
'vol': 9,#中音量
'aue': 6,#wav,3为mp3格式(默认); 4为pcm-16k;5为pcm-8k;6为wav(内容同pcm-16k);
'cuid': "ZZloekkfqvZFKhpVtFXGlAopgnHnHCgQ",#用户唯一标识
'lan': 'zh',
'ctp': 1 #客户端类型选择,web端填写固定值1
}
headers = {
'Content-Type': 'application/x-www-form-urlencoded',
'Accept': '*/*'
}
# 将参数编码,然后放入body,生成Request对象
data = urlencode(params).encode('utf-8')
# 发送POST请求
response = requests.post("http://tsn.baidu.com/text2audio", headers=headers,data=data)
# 检查响应状态码
if response.status_code == 200:
# 将返回的音频数据写入文件
print("开始生成合成音频")
gc.collect() # 写入前收集垃圾
with open(filename, "wb") as f:
f.write(response.content)
gc.collect() # 写入后收集垃圾
print("完成生成合成音频")
else:
print("无法获取音频文件")
def Baidu_Big_Model(text,AItoken):#大模型对话函数
url = "https://aip.baidubce.com/rpc/2.0/ai_custom/v1/wenxinworkshop/chat/ernie_speed?access_token="+AItoken
payload = json.dumps({
"messages": [
{
"role": "user",
"content": text
}
],
"temperature": 0.95,
"top_p": 0.8,
"penalty_score": 1,
"enable_system_memory": False,
"disable_search": False,
"enable_citation": False,
"system": "请将回答控制在30字,最后加个‘完’字结束对话",
"response_format": "text"
})
headers = {
'Content-Type': 'application/json'
}
response = requests.post(url, headers=headers, data=payload.encode('utf-8'))
if response.status_code == 200:
print(response.text)
data = json.loads(response.text)
decoded_str= data['result']
return(decoded_str)
def urlencode(params):#编码成 URL 编码格式的字符串
encoded_pairs = []
for key, value in params.items():
# 确保键和值都是字符串
key_str = str(key)
value_str = str(value)
# 手动实现简单的URL编码
encoded_key = key_str.replace(" ", "%20")
encoded_value = value_str.replace(" ", "%20")
encoded_pairs.append(f"{encoded_key}={encoded_value}")
return "&".join(encoded_pairs)
#获取token
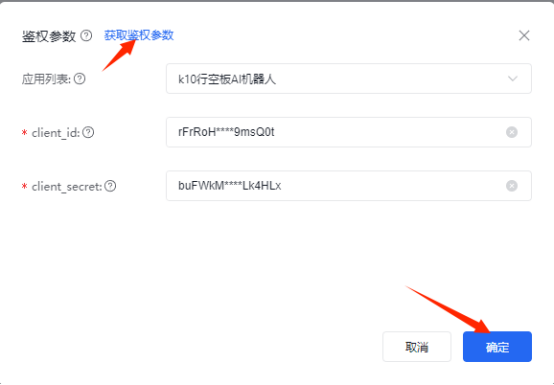
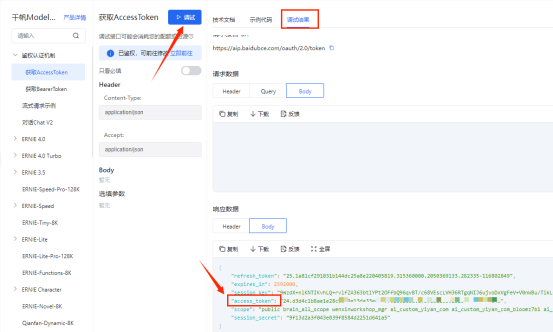
def get_access_token(API_KEY,SECRET_KEY):
url = "https://aip.baidubce.com/oauth/2.0/token"
params = {
'grant_type': 'client_credentials',
'client_id': API_KEY,
'client_secret': SECRET_KEY
}
data = urlencode(params).encode('utf-8')
response = requests.post(url, data=data)
access_token=json.loads(response.text)['access_token']
print(access_token)
return access_token
# 开始录音
def start_recording():
global scrn, font_cn,label_title,token,AItoken,text
print("开始录音")
text ="开始对话"
mic.recode_sys(name="sound.wav", time=5)
# label_title.set_text("开始录音……")
# 上传录音并识别
print("音频上传,进行百度识别")
text ="音频上传,进行百度识别"
time.sleep(0.1)
label_title.set_text(text)
time.sleep(0.1)
text = baidu_speech_recognize("sound.wav", token)
print("百度语音识别结果:", text)
text = Baidu_Big_Model(text,AItoken)
time.sleep(0.1)
label_title.set_text(text)
time.sleep(0.1)
audio_file = "audio2.wav"
Baidu_TTS(audio_file,text, token)#语音合成
time.sleep(0.1)
#播放音频
print("播放音频")
speaker.play_sys_music(audio_file)
def up_recording():
global scrn, font_cn,label_title,token,AItoken
label_title.set_text("功能暂未开发")
# 初始化板载按键传感器 A 和 B
def init_buttons():
bt_a = button(button.a)
bt_b = button(button.b)
bt_a.event_pressed = start_recording
bt_b.event_pressed = up_recording
# 主函数
def main():
global scrn, font_cn,label_title,token,AItoken,text
connect_wifi("r……", "wi……")
init_screen()
init_buttons()
API_KEY = "sexS8Y……"
SECRET_KEY = "nS2qMT……yjhTKrsWQ"
token = get_access_token(API_KEY,SECRET_KEY)#语音识别和语音合成的token
print(token)
API_KEY = "ShZO7VeT……lmnF"
SECRET_KEY = "b5bxt……xV"
# AItoken ="24.1bd84e812aa……………………"
AItoken = get_access_token(API_KEY,SECRET_KEY)#大模型的token
text ="按A键开始与大模型对话"
label_title.set_text(text)
# tim1 = Timer(1)
# tim1.init(period=100, mode=Timer.PERIODIC, callback=lambda t:update_label())
while True:
# # # 启动眼球变化
change_eyes()
time.sleep(0.1)
if __name__ == "__main__":
main()
复制代码 main.py 】baiduK10.zip 


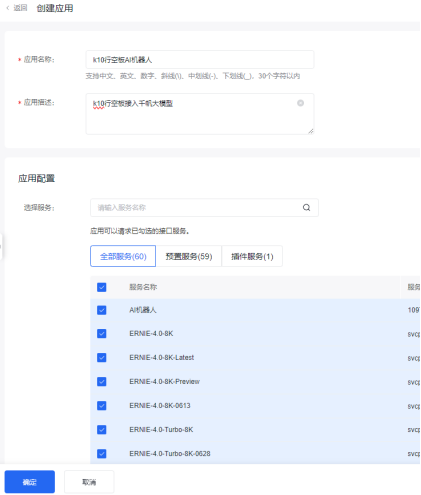
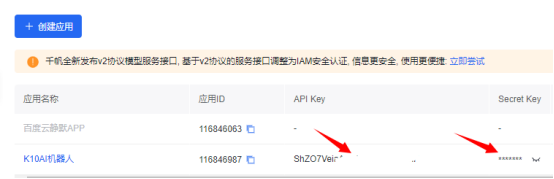
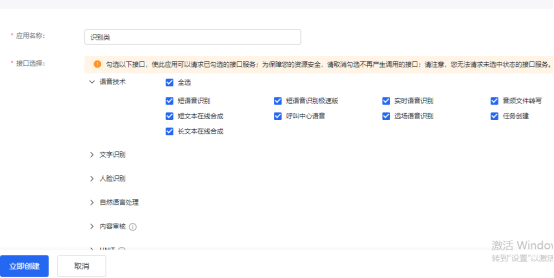

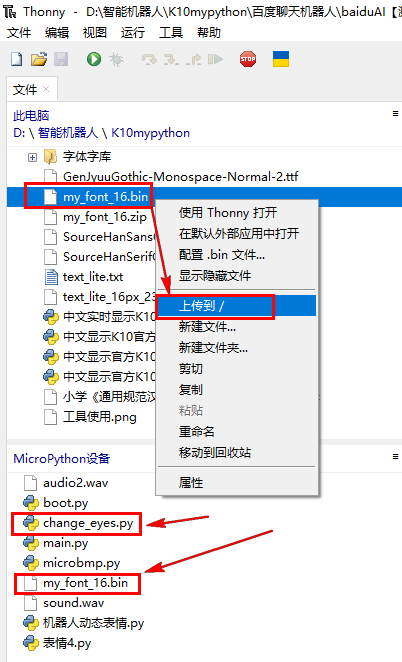
 baiduK10.zip
baiduK10.zip



 沪公网安备31011502402448
沪公网安备31011502402448
 置顶卡
置顶卡 变色卡
变色卡 千斤顶
千斤顶






