本帖最后由 YeezB 于 2025-9-23 11:53 编辑
借由行空板K10的摄像头以及联网功能,我们可以将摄像头画面传输到局域网上,并且随时在局域网中任意一台电脑访问。在电脑端可以调用很多现成的计算机视觉库。进行图像识别。
该项目分成两个部分:
- 将行空板K10的摄像头映射到网络上
- 连入这个局域网的电脑本地运行openCV/yolo等算法
1. 行空板K10网络摄像头
用户库链接:
https://gitee.com/yeezb/k10web-cam
可以在Mind+的用户库中复制粘贴上述链接来加载用户库
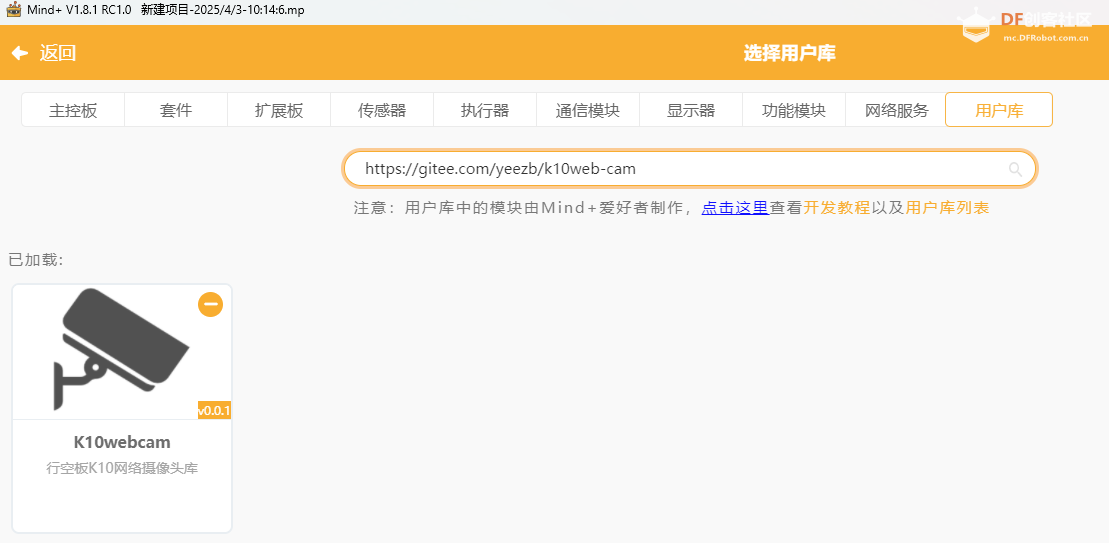
编写代码:
上述链接中有示例程序的截图,对应修改WiFi名称和密码后上传。
打开串口监视器,可以看到K10的IP。

浏览器打开IP/stream可以看到摄像头画面,比如上图中的IP,浏览器就可以输入192.168.9.180/stream

2.本地运行openCV
电脑本地安装openCV库:
Mind+切换到Python模式->代码->库管理
在PIP模式下分别输入并运行
- numpy
- request
- opencv-python
- opencv-contrib-python
安装四个依赖库

在电脑中任意位置新建一个python文件并打开,文件名任意但是需要以.py结尾
运行下列Python代码
- import cv2
- import requests
- import numpy as np
-
- url = 'http://192.168.9.60/stream' # UNIHIKER K10的IP地址
-
- cv2.namedWindow("live transmission", cv2.WINDOW_AUTOSIZE) # 创建一个窗口用于显示实时图像
-
- # 启动 HTTP 请求获取视频流
- try:
- response = requests.get(url, stream=True, timeout=10)
- print("Connected to stream")
-
- img_data = b'' # 用于存储接收到的图像数据
-
- # 按块读取数据
- for chunk in response.iter_content(chunk_size=1024):
- if chunk:
- img_data += chunk # 将接收到的数据累加到 img_data 中
-
- # 判断是否接收到完整的 JPEG 数据
- start_idx = img_data.find(b'\xff\xd8') # 查找 JPEG 开始标志
- end_idx = img_data.find(b'\xff\xd9') # 查找 JPEG 结束标志
-
- if start_idx != -1 and end_idx != -1:
- jpg_data = img_data[start_idx:end_idx+2] # 提取出完整的 JPEG 数据
-
- # 转换为 NumPy 数组
- img_np = np.frombuffer(jpg_data, dtype=np.uint8)
- img = cv2.imdecode(img_np, cv2.IMREAD_COLOR) # 解码 JPEG 图像数据
-
- if img is not None:
- gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 将图像转换为灰度图像
- canny = cv2.Canny(cv2.GaussianBlur(gray, (11, 11), 0), 30, 150, 3) # 使用Canny算法进行边缘检测
- dilated = cv2.dilate(canny, (1, 1), iterations=2) # 对边缘图像进行膨胀操作
- contours, _ = cv2.findContours(dilated.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_NONE) # 查找轮廓
- cv2.drawContours(img, contours, -1, (0, 255, 0), 2) # 在原始图像上绘制轮廓
-
- cv2.imshow("mit contour", canny) # 显示边缘检测结果图像
- cv2.imshow("live transmission", img) # 显示实时图像
-
- # 按下 'q' 键退出
- if cv2.waitKey(1) & 0xFF == ord('q'):
- break
-
- # 清除已处理的数据
- img_data = img_data[end_idx+2:] # 移除已处理的图像数据部分
- else:
- print("No data received!")
-
- except requests.exceptions.RequestException as e:
- print(f"Error: {e}")
-
- cv2.destroyAllWindows()
可以看到电脑上弹出两个对话框,openCV库正在对K10捕获的图像进行边缘检测。

3.本地运行Yolo V5
电脑本地安装yolo库:
Mind+切换到Python模式->代码->库管理
在PIP模式下分别输入并运行
- numpy
- yolov5
安装两个依赖库,yolo V5安装耗时较久。

在电脑中任意位置新建一个python文件并打开,文件名任意但是需要以.py结尾并且将文末网盘中的.pt模型放置在python文件的同级目录下。

运行下列Python代码- import cv2
- import torch
- import time
- import requests
- import numpy as np
- from yolov5 import YOLOv5
-
- url = '<span style="color: rgb(136, 0, 0); font-family: 微软雅黑; white-space: pre; background-color: rgb(240, 240, 240);">http://192.168.9.60/stream</span>' # UNIHIKER K10的IP地址
-
- # 加载YOLOv5模型
- model_path = "yolov5s.pt" # 模型路径
- device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
- model = YOLOv5(model_path, device=device)
-
- cv2.namedWindow("YOLOv5 Detection", cv2.WINDOW_AUTOSIZE) # 创建窗口
-
- # 启动HTTP请求,获取图像流
- try:
- response = requests.get(url, stream=True, timeout=10)
- print("Connected to stream")
-
- img_data = b'' # 存储接收到的图像数据
-
- while True:
- # **1. 读取完整 JPEG 数据**
- while True:
- chunk = response.raw.read(1024) # 直接读取数据
- if not chunk:
- break # 连接断开
- img_data += chunk # 累加数据
-
- start_idx = img_data.find(b'\xff\xd8') # JPEG 开头
- end_idx = img_data.find(b'\xff\xd9') # JPEG 结尾
-
- if start_idx != -1 and end_idx != -1:
- jpg_data = img_data[start_idx:end_idx + 2] # 提取完整 JPEG
- img_data = img_data[end_idx + 2:] # 删除已处理部分
- break # 退出读取循环
-
- # **2. 解码 JPEG**
- img_np = np.frombuffer(jpg_data, dtype=np.uint8)
- frame = cv2.imdecode(img_np, cv2.IMREAD_COLOR)
-
- if frame is None:
- continue # 跳过损坏帧
-
- # **3. YOLOv5 目标检测**
- start_time = time.time()
- results = model.predict(frame, size=640) # 进行检测
- annotated_frame = results.render()[0].copy() # 解除只读限制
-
- # **4. 计算 FPS**
- processing_time = time.time() - start_time
- fps = 1 / processing_time if processing_time > 0 else 0
-
- # **5. 显示检测结果**
- cv2.putText(annotated_frame, f"FPS: {fps:.2f}", (10, 30),
- cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 2, cv2.LINE_AA)
-
- cv2.imshow("YOLOv5 Detection", annotated_frame)
- print(f"Processed frame in {processing_time:.4f} seconds, FPS: {fps:.2f}")
-
- # 按 'q' 退出
- if cv2.waitKey(1) & 0xFF == ord('q'):
- break
-
- except requests.exceptions.RequestException as e:
- print(f"Error: {e}")
-
- cv2.destroyAllWindows()
可以看到电脑上弹出一个对话框,yoloV5正在对K10捕获的图像进行识别。

Yolo V5模型:链接: https://pan.baidu.com/s/1d09IYfpdk-fP2GE8KIBngg?pwd=bvsx 提取码: bvsx
| 



 沪公网安备31011502402448
沪公网安备31011502402448

 置顶卡
置顶卡 变色卡
变色卡 千斤顶
千斤顶