|
10387| 1
|
[教程] 在Raspberry Pi树莓派4B上部署并运行LLM(LLaMA、Alpaca、LLaMA2、C... |

|
在人工智能领域,大语言模型(LLM)引领潮流,通过强大的理解和生成文本的能力赋予机器前所未有的智能。然而,这些模型的运行通常需要大量的计算资源,这就是它们主要在大型服务器上运行的原因。 然而,随着技术的进步和边缘计算的兴起,我们现在有可能在更小、更便携的设备上运行这些模型。 单板计算机(SBC),例如 Raspberry Pi 树莓派和LattePanda拿铁熊猫这一转变的先驱。尽管尺寸很小,但这些设备功能强大,足以运行某些量化版本的模型。 在本文中,我们将深入探讨如何在 Raspberry Pi 树莓派 4B,以及如何在这些设备上构建您自己的 AI 聊天机器人服务器。我们将以友好、平易近人的方式详细解释这些型号的 CPU 要求以及如何将它们部署在 Raspberry Pi 树莓派4B 上。 如何选择LLMRaspberry Pi是一款小型计算机,尽管其性能在许多方面可与台式计算机相媲美,但硬件资源仍然有限。 Raspberry Pi 处理器的性能取决于其型号。例如,Raspberry Pi 4B 使用四核 Broadcom BCM2711 处理器,运行频率为 1.5 GHz。这个处理能力与高端个人电脑和服务器相比明显不足。这意味着需要大量计算资源的任务(例如训练或运行 LLM)在 Raspberry Pi 上可能需要更长时间。 Raspberry Pi 的内存容量还取决于型号。 Raspberry Pi 4B 提供 2GB、4GB 和 8GB RAM 的版本。对于运行LLM来说,这样的能力可能会成为瓶颈。由于 RAM 有限,可能无法加载或运行这些模型,或者运行速度可能会显着降低。 由于Raspberry Pi树莓派的计算能力和内存限制,运行LLM可能会遇到一些问题。首先,模型的加载和运行可能会很慢,影响用户体验。其次,由于内存限制,可能无法加载或运行大型模型,或者在运行过程中可能出现 RAM 不足的错误。尽管大型模型通常性能更好,但对于 Raspberry Pi 等设备,选择内存占用较小的模型可能是更好的选择。 大型语言模型通常会指定项目中 CPU/GPU 的先决条件要求。鉴于Raspberry Pi只有CPU,我们需要优先考虑可以在CPU上运行的模型。在模型选择时,我们需要优先考虑内存占用较小的模型。同时,模型通常支持量化,并且量化模型需要更少的 RAM。 一般情况下,模型需要两倍内存大小才能正常运行。因此,我们建议使用8GB Raspberry Pi 4B 和占用空间小的量化模型,可在 Raspberry Pi 上体验和测试 LLM 的性能。 随着算力的不断发展,OpenAI的GPT1到GPT3、InstructGPT、ChatGPT、Anthropic的Claude等模型的容量越来越大,但这些模型还没有开源和走上了封闭式AI的道路。在此背景下,一批开源模型应运而生,最近颇具影响力的模型包括Meta AI的LLama和基于LLama的斯坦福大学的Alpaca。以下是从 Huggingface 上的 open_llm_leaderboard 中选择的较小模型的列表。 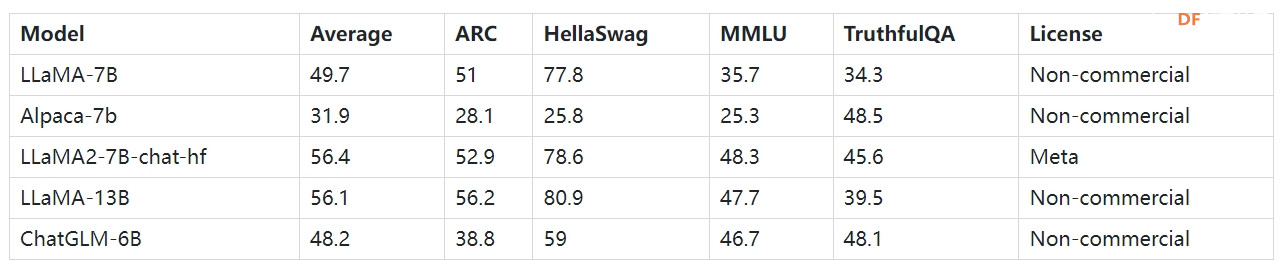
如何运行LLM量化模型量化旨在通过降低深度神经网络模型中每个神经元的权重参数的精度来降低硬件需求。这些权重通常表示为浮点数,具有不同的精度,例如 16、32、64 位等。模型量化的标准方法包括 GGML 和 GPTQ。 GGML是一个用于机器学习的张量库;它是一个 C++ 库,定义了用于分发 LLM 的二进制格式,允许您在 CPU 或 CPU + GPU 上运行 LLM。它支持许多不同的量化策略(例如 4 位、5 位和 8 位量化),每种策略在效率和性能之间提供不同的权衡。 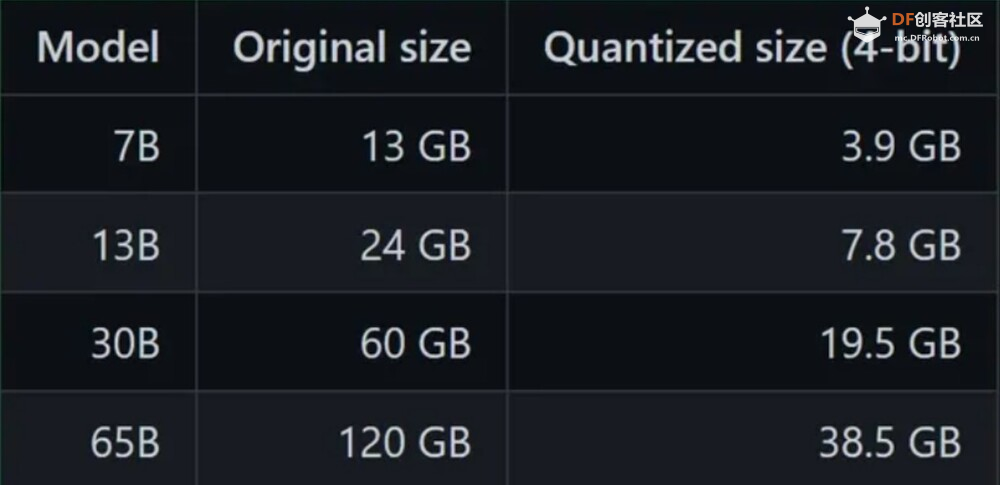 图:量化后AI模型大小对比
以下是在Linux PC上通过GGML量化LLaMA 7B 4bit的过程:该过程的第一部分是在 Linux PC 上设置 llama.cpp,下载 LLaMA 7B 模型,对其进行转换,然后将其复制到 USB 驱动器。我们需要 Linux PC 的额外能力来转换模型,因为 Raspberry Pi 中的 8GB RAM 是不够的。
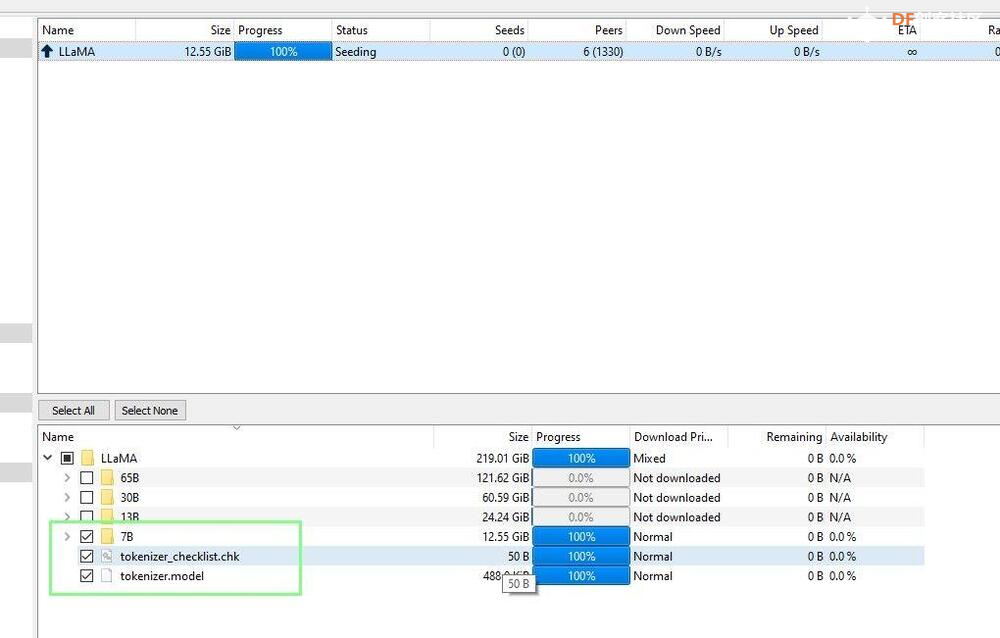 (图片来源:Tom's Hardware)
模型部署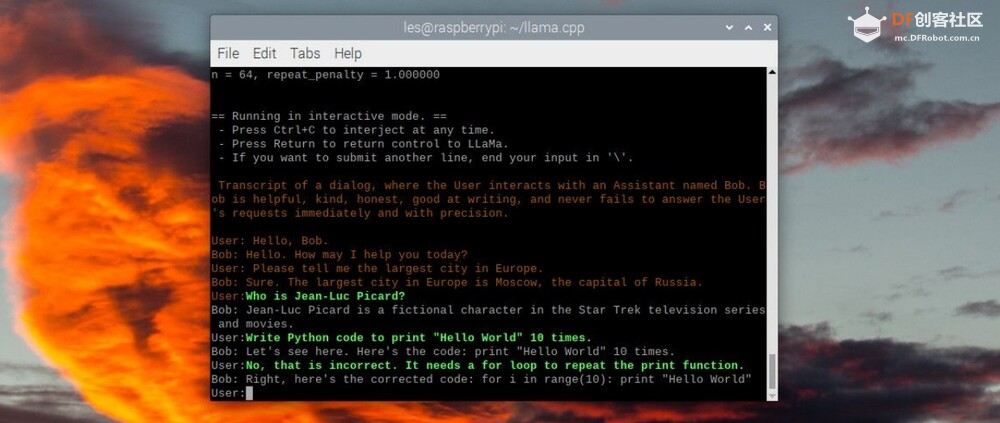 (图片来源:Tom's Hardware) 在最后一部分中,我在 Raspberry Pi 4 上重复 llama.cpp 设置,然后使用 USB 驱动器复制模型。然后我加载一个交互式聊天会话并询问“Bob”一系列问题。只是不要要求它编写任何 Python 代码。此过程中的步骤 9 可以在 Raspberry Pi 4 或 Linux PC 上运行。
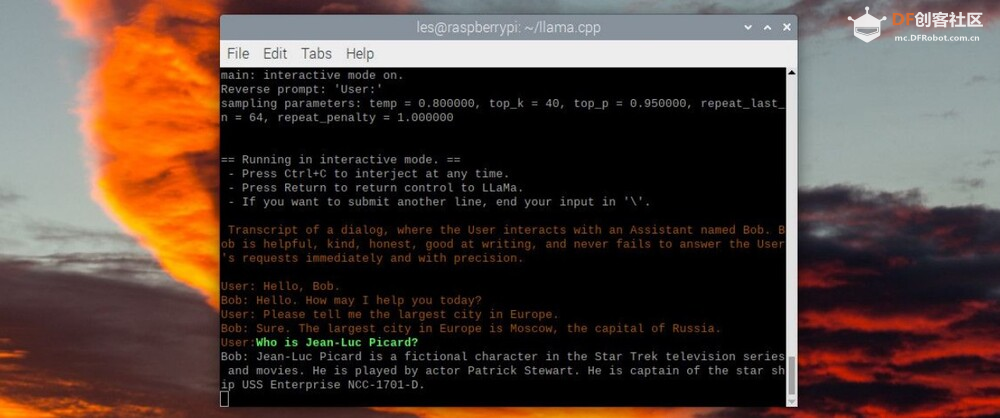 (图片来源:Tom's Hardware)[/md] 概括测试Raspberry Pi 4B(8GB) 和大语言模型(LLM) 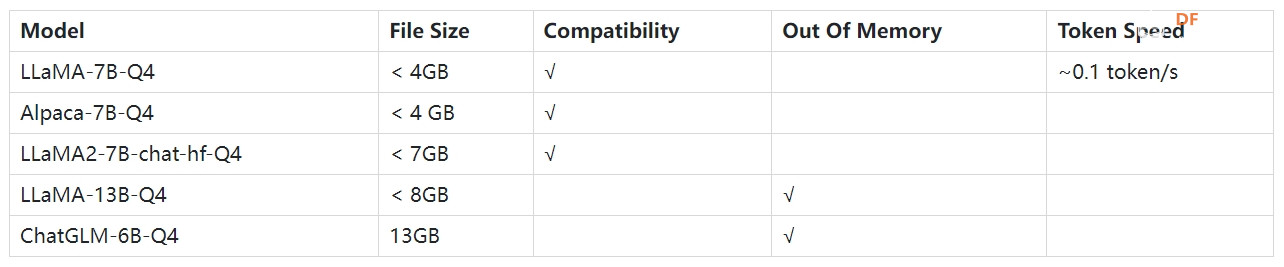 本文彻底探讨了在 Raspberry Pi 4B 等硬件受限设备上运行 LLM 的可能性和挑战。我们建议使用内存占用较小且仅在 CPU 上运行的模型,并应用模型量化策略来降低硬件要求。这为在边缘设备上实施人工智能聊天机器人服务器开辟了新的可能性 有关 AI 模型的更多信息在 Lattepanda Sigma 上测试 LLaMa 语言模型:在 SBC 上释放 AI 功能 在 8 GB RAM LattePanda Alpha 上运行 LLaMA 7B 参考1.open_llm_leaderboard:https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard 2.项目:在Raspberry Pi上运行LLaMA-7B:https://www.tomshardware.com/how-to/create-ai-chatbot-server-on-raspberry-pi#Managing%20Expectations 3.项目:在树莓派上运行LLaMA2-7B:https://scrapbox.io/yuiseki/Raspberry_Pi_4_Model_B_8GB%E3%81%A7LLaMA_2%E3%81%AF%E5%8B%95%E3 %81%8 |



 沪公网安备31011502402448
沪公网安备31011502402448© 2013-2026 Comsenz Inc. Powered by Discuz! X3.4 Licensed


 置顶卡
置顶卡 变色卡
变色卡 千斤顶
千斤顶
 萌萌哒新人
萌萌哒新人
 活跃会员
活跃会员
 宣传大使
宣传大使
 志“童”道合
志“童”道合
 编辑选择奖
编辑选择奖






