|
7198| 4
|
[动态] 关于YOLOv8 的全面详细介绍 |

|
众所周知,YOLO 模型彻底改变了计算机视觉领域。识别物体是计算机视觉中的一项关键任务,可应用于机器人、医学成像、监控系统和自动驾驶汽车等多个领域。YOLO 模型的最新版本 YOLOv8 是一种先进的实时物体检测框架,引起了研究界的关注。在所有流行的物体识别机器学习模型(如 Faster R-CNN、SSD 和 RetinaNet)中,YOLO 在准确性、速度和效率方面最受欢迎。 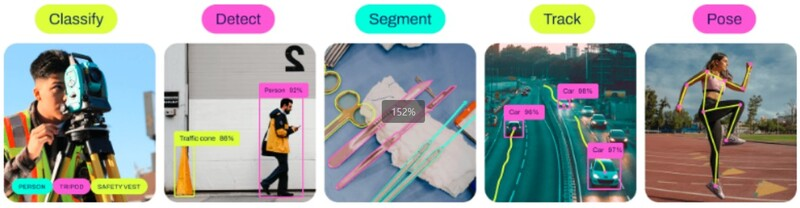 YOLOv8 简介什么是 YOLOv8?YOLO 是一种速度和准确性都极为出色的物体检测算法。YOLO v8 是 You Only Look Once 第 8 版的缩写,代表了该系列的最新进展。这是一个将计算机视觉与深度学习相结合的先进系统。这种协同作用标志着在查找、分类和分解数字视觉方面取得了巨大进步。传统的检测模型通常涉及两个步骤:首先识别感兴趣的区域,然后对这些区域进行分类。相比之下,YOLO 创新性地在神经网络的一次传递中同时预测分类和边界框,大大加快了流程并提高了实时检测能力。 
Yolov8 有什么新功能?这是一种先进的模型,在 YOLOv5 的基础上进行了改进,并进行了修改以增强其在各种计算机视觉任务中的功能和用户友好性。这些增强功能包括经过修改的主干网络、无锚检测头和多尺度对象检测。此外,它还为图像分类任务提供内置支持。YOLOv8 的独特之处在于它提供了无与伦比的速度和准确性性能,同时保持了精简的设计,使其适用于不同的应用程序并易于适应各种硬件平台。 架构改进主干YOLOv8 采用新的主干网络,它是 CSPDarknet53 架构的修改版本,由 53 个卷积层组成,并采用一种称为跨阶段部分连接的技术来增强网络各个层级之间的信息传输。YOLOv8 的主干由多个按顺序组织的卷积层组成,可从输入图像中提取相关特征。 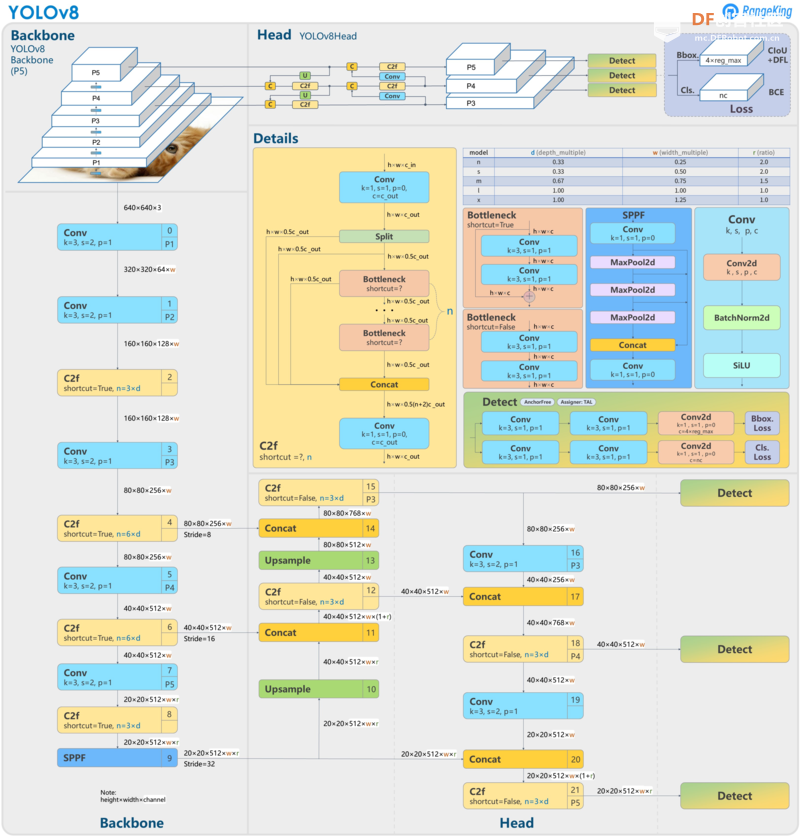 头部YOLOv8 的头部由多个卷积层和其后的全连接层组成,负责预测图像中检测到的对象的边界框、对象分数和类概率。 YOLOv8 的一个基本特性是在网络头部加入了自注意力机制,使得模型能够有选择地关注图像的不同区域,并根据特征与任务的相关性调整其重要性。 无锚检测与 YOLOv6 和 YOLOv7 类似,YOLOv8 是一种不依赖锚点的模型。这意味着它直接预测对象的中心,而不是与已知锚点框的偏移量。锚点框是早期 YOLO 模型(YOLOv5 及更早版本)中众所周知的挑战性方面,因为它们可以表示目标基准的框分布,但不能表示自定义数据集的分布。使用无锚点检测可最大限度地减少框预测的数量,从而加快非最大抑制 (NMS) 的速度,这是一个复杂的后处理阶段,可在推理后筛选候选检测。 多尺度物体检测YOLOv8 擅长多尺度物体检测,它采用特征金字塔网络来识别图像中各种大小和尺度的物体。该网络包含多个层,旨在检测不同尺度的物体,使模型能够识别图像中的大物体和小物体。 计算机视觉的其他进展高效的分割能力YOLOv8 模型在分割任务方面也表现出色,这是计算机视觉的一个关键方面。无论是用于对象检测、实例分割还是更通用的分割模型,YOLOv8(尤其是 YOLOv8 Nano 模型)都表现出色。它能够精确分割和分类图像的不同部分,这使得它在从医学成像到自动驾驶汽车导航等各种应用中都非常有效。 Python集成优势YOLOv8 的另一个关键方面是它的 Python 包,这有助于在基于 Python 的项目中轻松集成和使用。这种可访问性至关重要,尤其是考虑到 Python 在数据科学和机器学习社区中的流行度。开发人员可以使用领先的深度学习框架 PyTorch 在自定义数据集上训练 YOLOv8 模型。这种灵活性允许针对特定的计算机视觉挑战提供量身定制的解决方案。 YOLOv8 的主要功能Yolov8 是 Ultralytics 推出的 YOLO 的最新版本。作为尖端的、最先进的 (SOTA) 模型,YOLOv8 以之前版本的成功为基础,引入了新功能和改进,以提高性能、灵活性和效率。YOLOv8 支持全方位的视觉 AI 任务,包括检测、分割、姿势估计、跟踪和分类。这种多功能性使用户能够在不同的应用程序和领域中利用 YOLOv8 的功能 物体检测是一项计算机视觉任务,旨在定位和识别图像或视频流中的物体。该任务涉及识别图像中物体的位置和边界,以及将物体分类为不同的类别 1。物体检测器的输出包括检测到的物体周围的边界框,以及每个边界框的类别标签和置信度分数。当不需要物体的精确位置或形状,而是重点是识别场景中物体的存在时,这种方法特别有用。 
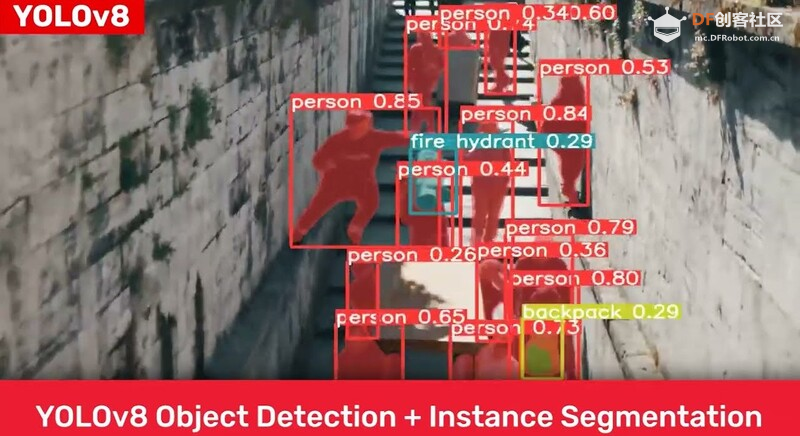

YOLOv8 的主要特点YOLOv8 将重点关注多个功能。以下是 YOLOv8 的一些主要功能:

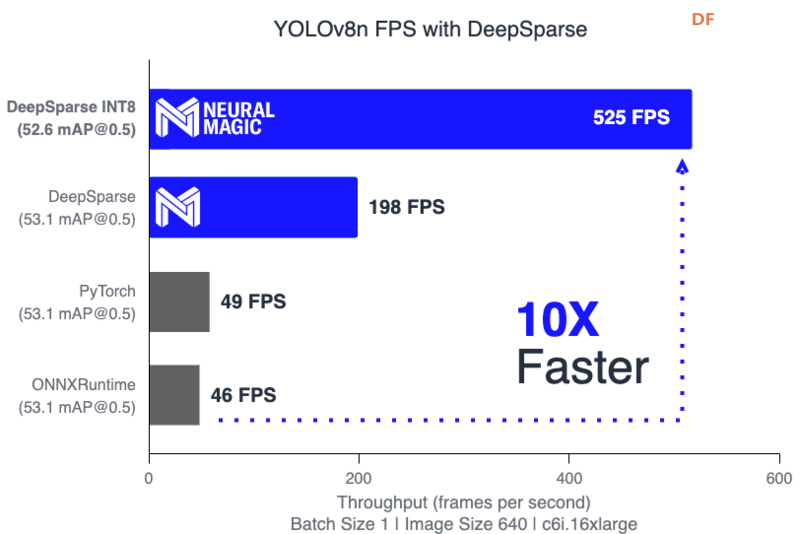
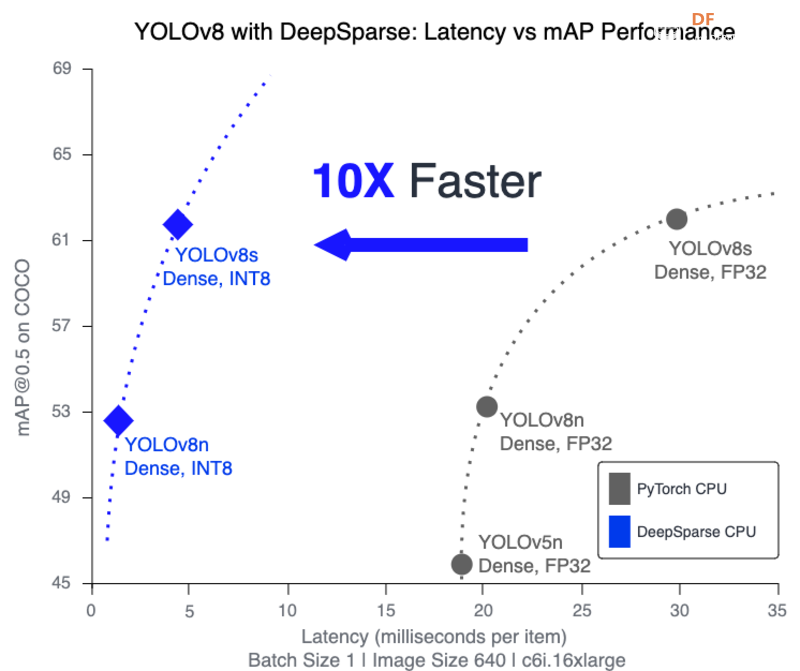
YOLOv8 的潜在用例以下是 YOLOv8 的一些潜在用例: 监控系统中的物体检测YOLOv8 可用于监控系统中的实时物体检测,从而识别监控区域内的人员、车辆或其他相关物体。 自动驾驶汽车和交通管理YOLOv8 的实时多尺度物体检测功能使其适合集成到自动驾驶汽车和交通管理系统中。它可以帮助识别行人、车辆、道路标志和交通信号。 工业质量控制YOLOv8 可用于制造过程中的质量控制。它可以识别和检查生产线上的产品、缺陷或异常,确保产品质量和安全。 零售分析和库存管理在零售环境中,YOLOv8 可以通过实时物体检测促进各种应用,例如客户跟踪、队列监控、库存管理和防盗。  医疗保健应用YOLOv8 的物体检测功能可部署在医疗保健环境中,用于执行患者监测、医学图像分析和医院环境中识别医疗设备等任务。 环境监测YOLOv8 可以通过识别和追踪野生动物、评估土地覆盖变化、监测自然灾害等方式为环境监测做出贡献。 农业监测YOLOv8 可以跟踪作物生长情况、检测作物病害并识别害虫。它还可以通过识别田地中需要不同程度的水或肥料的区域来促进精准农业。通过提供更快、更精确的数据,YOLOv8 可以帮助农民做出更明智的决策,提高作物产量并减少浪费。 使用 YOLOv8 的挑战训练数据限制虽然 YOLO v8 在标准数据集上表现优异,但在面对独特或高度专业化的场景时,其准确性可能会受到影响。该模型严重依赖于训练数据的质量和多样性,确保全面覆盖仍然是一项挑战。 小物体检测YOLO v8 可能难以检测图像中的小物体。像素尺寸最小的物体会带来挑战,因为模型的感受野可能无法捕获足够的细节,从而影响此类场景的准确性。  资源密集度YOLO v8 的高计算要求可能会成为一种障碍,尤其是在资源受限的环境中。训练模型需要强大的 GPU,而将其部署在边缘设备上可能需要进行优化,以确保实时性能而不影响准确性。 有限的语境理解YOLO v8 一次性处理整个图像,缺乏对不同区域之间上下文的理解。这可能会导致误解,尤其是在对象之间的关系对于准确检测至关重要的场景中。 对抗性攻击与许多深度学习模型一样,YOLO v8 容易受到对抗性攻击。输入图像中的微小扰动都可能导致错误分类或错误检测,这引发了人们对该模型在安全敏感应用中的稳健性的担忧。 结论YOLO v8 采用了尖端技术,这些技术已被证明可以提高物体检测的准确性和速度,同时降低计算和内存要求,例如添加注意模块和自注意机制以及使用空间金字塔池化和可变形卷积。总体而言,YOLO v8 作为一种可以增强实时检测能力的物体检测模型展现出巨大的潜力。最新版本的 YOLO 是计算机视觉领域的一项显著进步,可能会激发该领域的进一步探索和进步。 |



 沪公网安备31011502402448
沪公网安备31011502402448© 2013-2026 Comsenz Inc. Powered by Discuz! X3.4 Licensed


 置顶卡
置顶卡 变色卡
变色卡 千斤顶
千斤顶


 萌萌哒新人
萌萌哒新人
 活跃会员
活跃会员
 宣传大使
宣传大使
 志“童”道合
志“童”道合
 编辑选择奖
编辑选择奖






