|
9383| 0
|
[黑科技] 一种面向老年人基于AI技术的疲劳驾驶检测与预警终端 |

|
本帖最后由 木子呢 于 2021-7-23 15:07 编辑 Drive安全守护者-一种面向老年人基于AI技术的疲劳驾驶检测与预警终端 作品来源:第四届全国青少年人工智能创新挑战赛之单片机创意智造挑战赛晋级作品 参赛作者:浙江省诸暨市海亮高级中学 徐雷力 李孟阳 指导老师:浙江省诸暨市海亮高级中学 郦钰筠 张渊 作品主旨 人文人文关怀、智能爱心工具 其他主题:安全驾驶、疲劳驾驶检测与预警、计算机视觉、人工智能 创意来源 我的叔叔现在已经60多岁了,是一名长途运输车司机,每一次长途运输需要好几天时间才能完成。有一次,我和叔叔聊到工作的时候,我向叔叔问了一个关键的问题:“您曾经在开车的过程中睡着过吗?” 当时叔叔立马感到不适,他没有看我,过了一会儿,他回想起他的一位朋友,有一次开了24小时以上之后睡着了,在公路上突发交通事故,车上的东西洒了一地,幸运的是人没有受伤,这件事也让叔叔感到恐惧,因为他意识到,如果其他驾驶员发生这种情况,那么他也可能会发生类似的情况。我听完之后,我向叔叔解释了我目前学习到的计算机视觉方面的知识,我准备开发一款可以自动检测实时视频流中驾驶员的睡意情况,然后在驾驶员感觉疲劳时及时发出警报。叔叔听完之后,他确认这项技术将对行业有所帮助,并且理想情况下可以减少与疲劳有关的事故发生。本次大赛中,我将展示一种面向老年人基于AI技术的疲劳驾驶检测与预警终端,希望这项技术对整个行业有所帮助,也为无人驾驶系统安全问题贡献我的创意思路,最后希望这项创意产品能够应用到除了老年人之外的其他群体。 作品概述 为了解决老年人及长途运输车司机等疲劳驾驶这一痛点,我们开发了一款面向老年人基于AI技术的疲劳驾驶检测与预警终端。该终端在硬件方面包括1个树莓派4B、1个PCA9685扩展板、1个PiCamera、2个LED灯、1个蜂鸣器、1个两自由度云台、一个显示屏。该终端在算法层面包含两个核心的算法:①应用OpenCV和dlib进行实时面部标志提取、眨眼检测(眼睛纵横比:EAR算法)及眨眼计数,②使用PID(比例积分微分)算法、OpenCV人脸检测算法及对象中心跟踪算法实现人脸实时平移及倾斜跟踪。该终端的原理主要是利用视觉传感器实时跟踪捕捉老年人等驾驶者的面部特征变化数据,根据这些数据来判断驾驶者是否处于疲劳驾驶状态,该终端安装有声音和灯光报警装置,一旦检测出老年人等驾驶者处于疲劳驾驶状态就会立即发出警报,提示老年人等驾驶者注意安全驾驶。该产品可以减少与疲劳驾驶有关的事故发生,这项技术对整个行业会有所帮助,打造这样的⼀款具有社会意义和商业价值的产品,可以促进社会的和谐可持续发展原则,未来,我们将不断优化该产品,为无人驾驶系统安全问题贡献我们的创意思路,希望这项创意产品能够应用到除了老年人之外的其他群体。 作品展示 功能简介 (一)总体概述 该终端的主要功能是使用普通摄像头实时检测跟踪提取老年人等驾驶者的面部特征数据,根据提取到的特征数据实时判断驾驶者是否处于疲劳驾驶状态,并且该终端内部安装有声音和灯光警报传感器,一旦检测出老年人等驾驶者处于疲劳驾驶状态就会立即发出警报,提示老年人等驾驶者注意安全驾驶。 (二)核心算法简介 核心算法包括两部分。 1、应用OpenCV和dlib库进行实时人脸检测、面部标志提取、眨眼检测(眼睛纵横比:EAR算法)及眨眼计数。 (1)算法的总体流程:首先,安装一个摄像头,该摄像头在视频流中应用OpenCV的Haar级联算法实时识别检测人脸并监视人脸;如果找到了人脸,将应用dilb库进行面部标志检测并提取眼睛区域;提取到了眼睛区域,接着就可以计算眼睛的长宽比以确定眼睛是否闭合;如果眼睛的长宽比表明眼睛已经闭合了足够长的时间,声光传感器将发出警报以唤醒驾驶员。 (2)OpenCV中的Haar级联算法 在Raspberry Pi 4B上为了确保检测的准确性及人脸检测的速度更快,我们对比了OpenCV中的轻量级的Haar级联检测算法、dlib中基于HOG +线性SVM的面部检测算法、深度学习检测算法SSD、YOLO等,Haar级联算法快速,但准确性较低,调整参数可能会很麻烦。HOG +线性SVM通常比Haar级联更准确,假阳性更少,在测试时需要调整的参数较少,与Haar级联相比,速度可能较慢。基于深度学习的检测算法,经过正确训练,其比Haar级联和HOG +线性SVM明显更准确,更耐用,根据模型的深度和复杂性,它可能非常慢,可以通过在GPU上执行推理来加快速度。尽管Haar级联存在多个问题,即容易出现假阳性检测,在应用于推理/检测时需要进行参数调整,但是在资源受限的Raspberry Pi 4B设备上,无法使用计算量更大的对象检测算法,Haar级联检测算法检测速度非常快,它的模型很小,只有930KB。Haar级联算法为计算机视觉和图像处理文献的重要组成部分,任然与OpenCV一起使用,目前在实际应用中都在使用。 Haar级联算法由Viola和Jones在2001年发表的《Rapid Object Detection using a Boosted Cascade of Simple Features》这篇论文中首次引入的,该论文已成为计算机视觉文献中引用最多的论文之一,该算法是OpenCV中最受欢迎的对象检测算法。Viola和Jones在他们的论文中提出了一种算法,该算法能够检测图像中的对象,而不必考虑它们在图像中的位置和比例。此外,该算法可以实时运行,从而可以检测视频流中的对象。具体来说,Viola和Jones专注于检测图像中的人脸。尽管如此,该框架仍可用于训练检测器以检测任意“物体”,例如汽车,建筑物,厨房用具,甚至是香蕉等。 应用OpenCV可以使用预先训练的Haar级联功能来执行面部检测,这样可以确保我们不需要提供自己的正样本和负样本,训练我们自己的分类器,也不必担心参数调整的问题。取而代之的是,我们仅加载预训练的分类器并检测图像中的人脸就可以,如图1所示。  图1 使用OpenCV中的预训练Haar级联检测图像中人脸 在算法底层,OpenCV正在做一些相当有趣的事情。在沿滑动窗口移动的每个停靠点,将计算五个矩形特征,如图2所示。为了获得这五个矩形区域中每个区域的特征,我们只需从黑色区域的像素总和中减去白色区域的像素总和。这些功能在实际的人脸检测方面具有重要性,比如眼睛区域往往比脸颊区域更黑,鼻子区域比眼睛区域明亮。因此,给定这五个矩形区域及其对应的总和差,我们就可以形成对面部各部分进行分类的特征。然后,对于整个特征数据集,我们使用AdaBoost算法来选择与图像的面部区域相对应的特征。 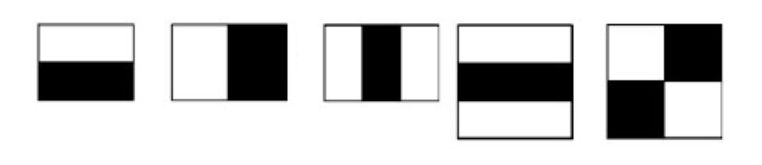 图2 从图像补丁中提取的5种不同类型的类似Haar的特征 使用固定的滑动窗口并在图像的每个(x,y)坐标上滑动它,然后计算这些类似Haar的特征,最后执行实际的分类在计算上会很费时间。为了解决这个问题,Viola和Jones引入了级联或舞台的概念。在沿着滑动窗口路径的每个停靠点处,窗口必须通过一系列测试,其中每个后续测试的计算量都比前一个更大。如果任何一项测试失败,则该窗口将被自动丢弃。Haar级联也有一些优点,由于使用了积分图像(也称为求和面积表),在计算类似Haar的特征时非常快,通过使用AdaBoost算法,在特征选择的时候也非常有效。最重要的是,该算法可以检测图像中的人脸,而不必考虑人脸的位置或比例。最后,用于对象检测的Viola-Jones算法能够实时运行。 Haar级联算法也存在一定的局限性,容易出现假阳性,当没有人脸时,Viola-Jones算法会在图像中反馈人脸。我们需要不断调整OpenCV检测参数,有时可以检测到图像中的所有面孔,有时还会出现被错误地分类为面部或面部完全缺失的情况。 (3)眼睛长宽比(EAR)算法 在构建眨眼检测器之前,需要明白面部标志检测,面部标志检测一般有两个过程:①在图片或视频流中定位人脸;②检测面部ROI上的关键面部结构。有各种各样的面部标志检测算法,但是所有方法本质上都是尝试对以下面部区域进行定位和标记:嘴、右眉、左眉、右眼、左眼、鼻子、颚,我们将使用面部标志检测算法,dlib库中预先训练的面部界标检测器用于估计映射到面部结构的68个(x,y)坐标的位置,如图3所示。  图3 可视化来自iBUG 300-W数据集的68个面部界标坐标 这些注释是68点iBUG 300-W数据集的一部分,对dlib面部界标预测器进行了训练。还存在其他类型的面部界标检测器,包括可以在HELEN数据集上进行训练的194点模型。无论使用哪个数据集,都可以利用相同的dlib框架在输入的训练数据上训练形状预测器。如图4所示是检测图像中的68个面部标志。  图4 在图像中检测多个人的面部标志 为了构建眨眼检测器,我们将会计算一个称为眼睛长宽比(EAR)的指标,该指标由Soukupová和Čech在其2016年的论文《Real-Time Eye Blink Detection Using Facial Landmarks》中引入。与计算眨眼的传统图像处理方法不同,该方法通常涉及以下几个步骤:定位眼睛、根据阈值找到眼睛的白色区域、确定眼睛的“白色”区域是否消失了一段时间(表示眨眼)。计算眼睛的长宽比是一种比较准确的解决方案,它基于眼睛及面部轮廓之间的距离之比而计算的,这种眨眼检测方法快速,高效且易于实现。 我们应用面部标志检测来定位面部重要区域,包括眼睛,眉毛,鼻子,耳朵和嘴巴,在这里,我们通过了解特定面部部分的索引来提取特定的面部结构,在眨眼检测方面,我们只需要关注一套面部结构:眼睛。每只眼睛都由6个(x,y)坐标来表示,从坐标的左边开始,然后沿该区域的其余部分顺时针旋转,与眼睛相关的6个面部标志,如图5所示。  图5 与眼睛相关的6个面部标志 与眼睛相关的6个面部标志的坐标的宽度和高度之间存在一定的关系,根据Soukupová和Čech在2016年发表的论文《Real-Time Eye Blink Detection using Facial Landmarks》,我们得出了一个反映这种关系的公式,如图6所示,称为眼睛纵横比(EAR): 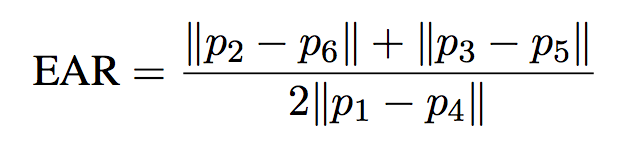 图6 眼睛纵横比方程式 其中p1,…,p6是2D面部界标位置。该公式的分子用于计算垂直眼界标之间的距离,而分母计算水平眼界标之间的距离,对分母进行适当加权,因为只有一组水平点,而有两组垂直点。我们发现,睁开眼睛时眼睛的长宽比大约是恒定的,但是当眨眼时眼睛的长宽比会迅速变为零。使用这个简单的公式,我们可以避免使用图像处理技术,而只需要依靠眼睛界标距离的比率来确定一个人是否在眨眼。为了更清晰地说明这一点,引用Soukupová和Čech的下图简单的分析一下,如图7所示。 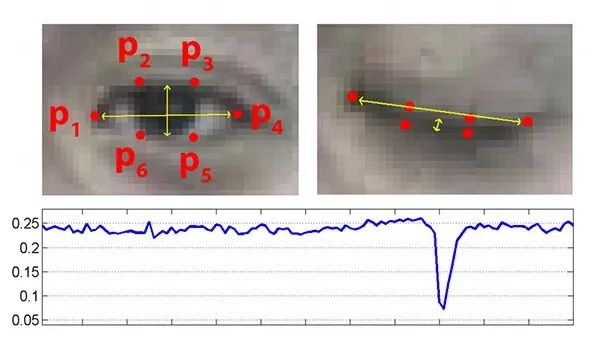 图7左上:当眼睛睁开时,眼睛界标的可视化。右上:闭上眼睛时,眼睛界标的可视化。下面:绘制随时间变化的眼睛长宽比。眼睛长宽比的下降表示眨眼。 在左上角,眼睛完全是张开的,此处的眼睛长宽比会很大(r),并且随着时间的推移会相对保持恒定。但是,一旦眨眼(右上角),眼睛的长宽比就会急剧下降,接近零。在下面的图中绘出了眼长宽比随时间变化的曲线图。眼睛的长宽比是恒定的,然后迅速下降到接近零,然后再次增加,表明发生了一次眨眼,如图8所示,是应用于检测摄像头视频流中的眨眼截图。  图8 应用于检测摄像头视频流中的眨眼截图 2、使用PID(比例积分微分)算法、OpenCV人脸检测算法及对象中心跟踪算法实现人脸实时平移及倾斜跟踪 (1)算法的总体流程 为了完成该算法,我们首先需要一个平移和倾斜摄像头云台,该云台使用两个舵机组装完成,两个舵机使摄像头可以上下移动和左右移动。接着我们需要实现在反馈控制回路中使用的PID,然后完成了PID控制器,就需要实现人脸检测。使用Haar Cascade人脸检测算法检测人脸,然后返回人脸边界框的中心坐标(x,y),使我们能够将这些坐标传递到平移和倾斜系统中,伺服器将摄像机会实时对准检测对象本身。 (2)PID算法 常见的反馈控制回路是指PID或比例积分微分控制器,PID通常用于自动化领域,因此机械执行系统可以快速,准确地达到最佳值(由反馈传感器读取)。PID通常用于智能制造、机器人等领域,PID控制器计算误差项(所需设定点与传感器读数之间的差),并以补偿误差为目标,PID计算输出一个值,该值用作“过程”的输入,传感器的输出称为“过程变量”,并用作方程式的输入,在整个反馈环路中,都会捕获时序并将其也输入到公式中,PID控制算法如图9所示。 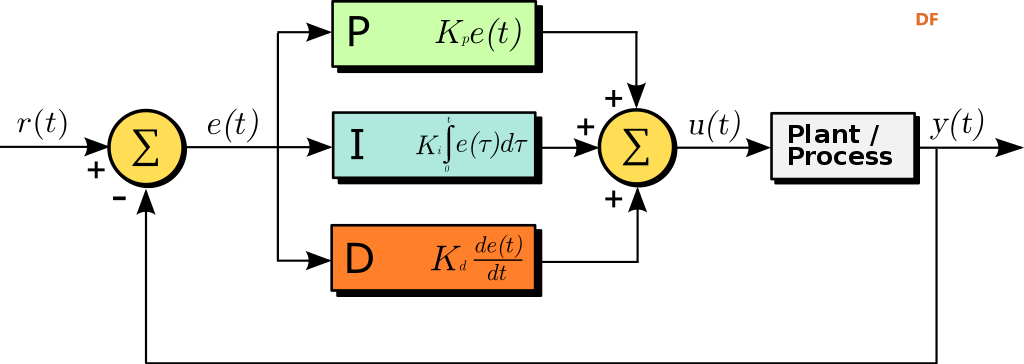 图9 比例积分微分(PID)控制回路将用于每个平移和倾斜过程 该图可以用公式表示为: 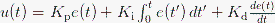 PID算法中,P(比例):如果当前误差较大,则输出将成比例地增大,从而导致明显的校正。I(积分):错误的历史值随时间积分,进行次要的校正以减少误差,如果消除了错误,则该值将不会增加。D(导数):这个术语预示着未来,实际上,它是一种阻尼方法,如果P或I会导致值超调(即,将伺服器转过一个物体或将方向盘转得太远),则D将在达到输出之前减弱效果。在该系统中,需要手动调整两个独立的PID(一个用于平移,另一个用于倾斜)。 硬件清单 树莓派4B X1 PCA9685扩展板 X1 PiCamera X1 两自由度云台(1xMG90S舵机、1Xsg90舵机)X1 蜂鸣器 X 1 LED灯 X2 电源适配器 X1 HDMI线 X1 数据线 X1 杜邦线 X 若干 螺丝 X 若干 电路连线图说明 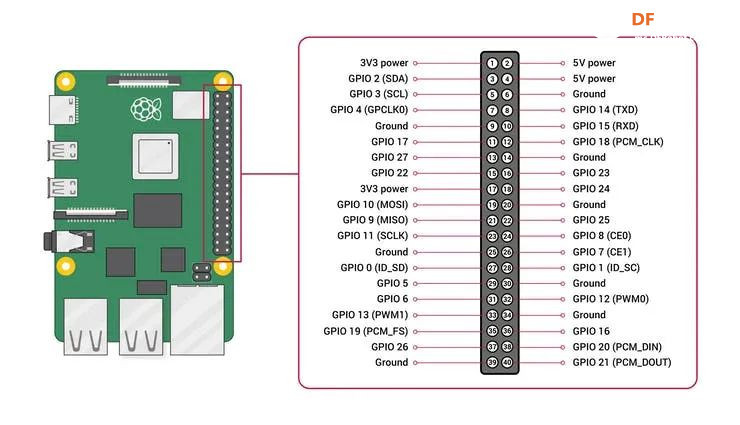 图10 树莓派4B GPIO接口 绿灯GND接树莓派GPIO14、VCC接GPIO4、IN接GPIO15,红灯GND接树莓派GPIO6、VCC接GPIO2、IN接GPIO18,蜂鸣器GND接树莓派GPIO30、VCC接GPIO1、IN接GPIO29。 MG90S接S1接口,SG90舵机接S0接口。 摄像头通过排线连接到摄像头接口就可以了。 制作过程 (一)结构设计 1、外观结构 外观形状是盒子类型的,采用3MM的椴木板用激光切割机切割而成,并且在相对应的传感器和连线处留了一定大小的孔位,面与面的衔接处采用榫卯结构拼接而成。如图11所示为激光切割文件,如图12所示为激光切割的实物图。 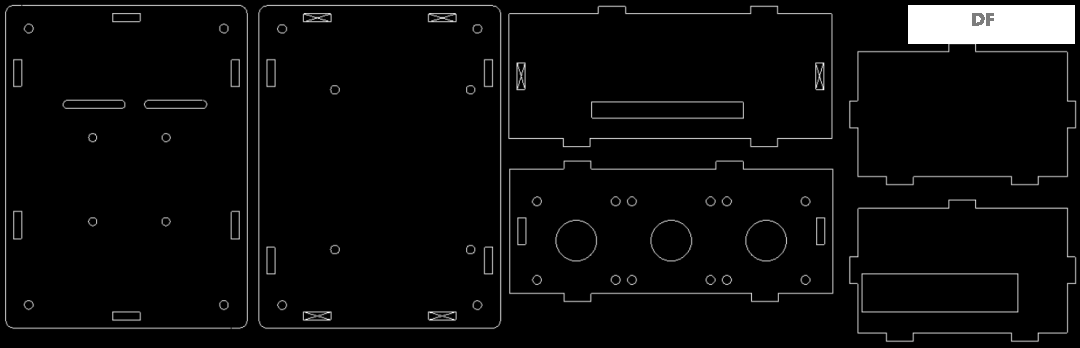 图11 激光切割文件  图12 激光切割的实物图 2、两自由度舵机云台 两自由度舵机使用尼龙材料制作而成,尺寸方面根据舵机的尺寸精确设计,如图13所示。  图13 两自由度舵机云台 3、显示屏支架 显示屏直接采用3D打印而成,目的主要是为了显示屏容易摆放,可以调整角度,实际应用中则使用屏幕四周的四个螺丝孔来固定,如图14所示,显示屏支架。  图14 显示屏支架 (二)算法开发调试 1、在Raspberry Pi 4B上安装Raspbian Buster系统 (1)首先我们准备的硬件和软件是:Raspberry Pi 4B 8GB、32GB microSD、microSD读卡器、raspios-buster操作系统、500万像素的PiCamera、HDMI线、电源适配器。 (2)准备好硬件之后,需要将raspios-buster操作系统刷入到32GB的 microSD卡。raspios-buster操作系统下载地址(https://www.raspberrypi.org/software/operating-systems/),我选择带有桌面的Raspberry Pi操作系统,如图15所示。接着下载安装镜像输入软件,下载地址(https://www.balena.io/etcher/)。接下来使用Etcher将raspios-buster系统输入到存储卡中,如图16所示。几分钟后,将会刷入到Micro SD卡中,然后启动。  图15选择下载的Raspbian Buster操作系统 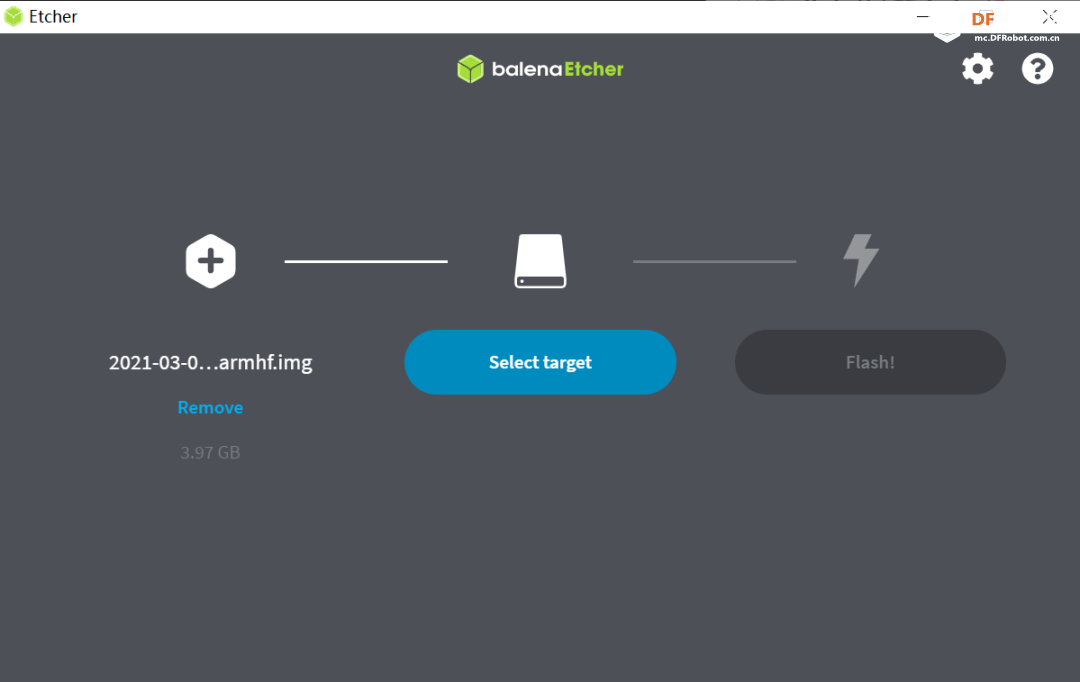 图16 使用Etcher刷入raspios-buster操作系统 (3)安装的新系统开机后进行换源操作,更换源为清华的源。 ①备份源文件 sudo cp /etc/apt/sources.list /etc/apt/sources.list.bak sudo cp /etc/apt/sources.list.d/raspi.list /etc/apt/sources.list.d/raspi.list.bak ②编辑软件源文件 sudo nano /etc/apt/sources.list 将原有的注释掉,把清华的源复制进去,按Ctrl + O保存, 回车Enter确定,Ctrl + X 退出编辑。 清华的软件源,修改完如图17所示。 deb http://mirrors.tuna.tsinghua.edu.cn/raspbian/raspbian/buster main non-free contrib rpi deb-src http://mirrors.tuna.tsinghua.edu.cn/raspbian/raspbian/buster main non-free contrib rpi 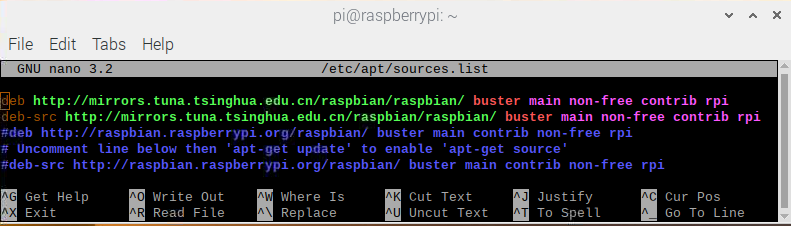 图17 换清华软件源 ③编辑修改系统更新源 sudo nano /etc/apt/sources.list.d/raspi.list将原有的注释掉,把中科大的系统源复制进,按Ctrl + O保存, 回车Enter确定,Ctrl + X 退出编辑。 清华的系统源,修改系统源如图18所示。 deb[url=http://mirrors.tuna.tsinghua.edu.cn/raspberrypi/]http://mirrors.tuna.tsinghua.edu.cn/raspberrypi/[/url]buster main ui 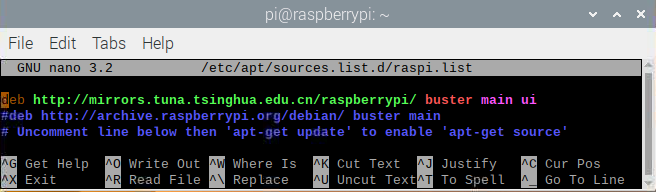 图18 换清华系统更新源 ④逐步更新一下 sudo apt-get update sudo apt-get upgrade sudo apt-get dist-upgrade sudo rpi-update (4)基础设置,界面如图19所示。  图19 基础设置界面 ①启用VNC 终端输入以下命令进入配置界面,依次操作:5 Interfacing Options -> 3 VNC -> Yes。 sudo raspi-config ②设置分辨率sudo raspi-config 依次操作:7advanced Options -> resolution-> 选择分辨率,输入y之后回车,重启再次连接VNC,有画面了。 ③启用SSH 树莓派终端启动systemctl 远程服务: sudo systemctl enable ssh sudo systemctl start ssh 电脑端下载SSH远程软件:PUTTY,打开PUTTY软件,输入Hostname:树莓派获取的ip地址,电机open跳转之后输入Username:树莓派用户名:pi(默认用户名:pi 密码:raspberry),点击Connect。 ④启用I2C 在终端中操作,输入指令:sudo raspi-config,然后会出现设置界面,依次操作:5 Interfacing Options ->P5 I2C -> Yes。 (5)扩展文件系统并回收空间 运行raspi-config并扩展您的文件系统: sudo raspi-config 依次操作:7 Advanced Options->A1 Expand filesystem,然后重新启动树莓派,重新启动后,文件系统应已扩展为包括micro-SD卡上的所有可用空间。可以通过执行df -h操作来验证磁盘是否已扩展并查看输出,如图20所示。 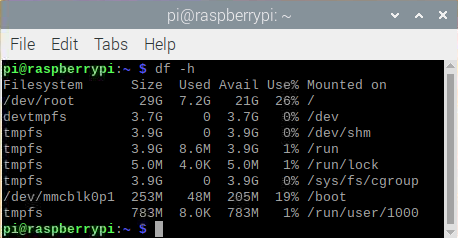 图20 扩展文件系统检查输出 我们建议同时删除Wolfram Engine和LibreOffice,可以使Raspberry Pi回收约1GB的空间: sudo apt-get purge wolfram-engine sudo apt-get purge libreoffice * sudo apt-get clean sudo apt-get autoremove 2、安装OpenCV4.5.2 (1)安装依赖项 这些优化库对于资源受限的设备(例如Raspberry Pi)尤其重要。 更新和升级现有的软件包: sudo apt-get update && sudo apt-get upgrade 安装一些开发工具,包括CMake,它可以帮助我们配置OpenCV构建过程: sudo apt-get install build-essential cmake pkg-config 安装一些图像I /O包,以允许我们从磁盘加载各种图像文件格式: sudo apt-get install libjpeg-dev libtiff5-dev libjasper-dev libpng-dev 安装视频I/O包,这些库使我们能够从磁盘读取各种视频文件格式,以及直接使用视频流: sudo apt-get install libavcodec-dev libavformat-dev libswscale-dev libv4l-dev sudo apt-get install libxvidcore-dev libx264-dev OpenCV库带有一个名为highgui的子模块,它用于在我们的屏幕上显示图像并构建基本的GUI。为了编译highgui模块,我们需要安装GTK开发库和前提条件: sudo apt-get install libfontconfig1-dev libcairo2-dev sudo apt-get install libgdk-pixbuf2.0-dev libpango1.0-dev sudo apt-get install libgtk2.0-dev libgtk-3-dev 通过安装一些额外的依赖项,可以进一步优化OpenCV内部的许多操作(即矩阵操作): sudo apt-get install libatlas-base-dev gfortran 安装Python 3头文件: sudo apt-get install python3-dev (2)创建Python虚拟环境 我们将使用Python虚拟环境,比较方便的是可以使用pip(Python的软件包管理器)在虚拟环境中管理Python软件包。 使用以下命令安装pip: wget https://bootstrap.pypa.io/get-pip.py sudo python get-pip.py sudo python3 get-pip.py sudo rm -rf〜/ .cache / pip 接着安装virtualenv和virtualenvwrapper: sudo pip install virtualenv virtualenvwrapper 安装好装virtualenv和virtualenvwrapper之后,打开~/.bashrc文件: nano ~/.bashrc 将以下行添加到文件的底部,然后按Ctrl + O保存, 回车Enter确定,Ctrl + X 退出编辑。如图21所示: # virtualenv and virtualenvwrapper export WORKON_HOME=$HOME/.virtualenvs export VIRTUALENVWRAPPER_PYTHON=/usr/bin/python3 source /usr/local/bin/virtualenvwrapper.sh 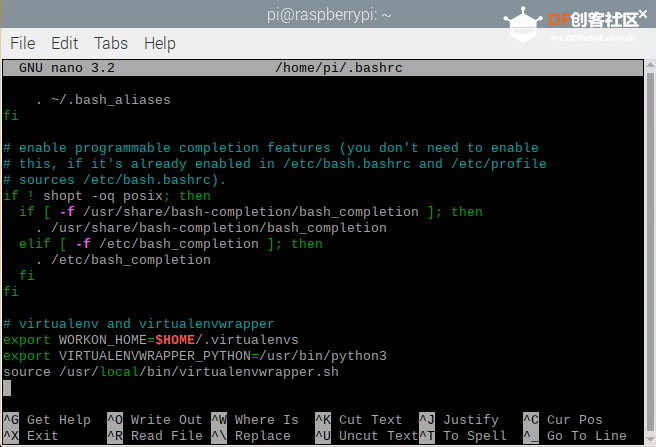 图21 修改.bashrc文件 然后重新加载〜/ .bashrc文件,以便应用于当前的终端。 source〜/ .bashrc 接下来,创建Python 3虚拟环境: mkvirtualenv py3cv4 -p python3 在这里,创建一个名为py3cv4的虚拟环境。 由于我们需要使用Raspberry Pi摄像头模块,则还应该安装 PiCamera API库 : pip install "picamera[array]" (3)从源码编译安装OpenCV4.5.2 从源码安装OpenCV,会获得具有专利的算法。 首先下载4.5.2版本的opencv和opencv_contrib的源代码,然后进行解压: cd ~ wget-O opencv.zip https://github.com/opencv/opencv/archive/4.5.2.zip wget-O opencv_contrib.zip https://github.com/opencv/opencv_contrib/archive/4.5.2.zip unzip opencv.zip unzip opencv_contrib.zip mv opencv-4.5.2 opencv mv opencv_contrib-4.5.2 opencv_contrib 增加SWAP空间的大小 在开始编译之前,我们必须增加SWAP的空间。增加SWAP空间将使我们能够使用Raspberry Pi的四个内核来编译OpenCV,并且不会由于内存耗尽而导致编译挂起。 首先打开/etc/dphys-swapfile文件: sudo nano /etc/dphys-swapfile 然后修改CONF_SWAPSIZE的值为2048: # set size to absolute value, leaving empty (default) then uses computed value # you most likely don't want this, unless you have an special disk situation # CONF_SWAPSIZE=100 CONF_SWAPSIZE=2048 在树莓派上使用多个内核编译OpenCV是至关重要的,如果不增加SWAP,则Pi很可能在编译过程中会挂起。 然后,重新启动交换服务: sudo /etc/init.d/dphys-swapfile stop sudo /etc/init.d/dphys-swapfile start 接下来,我们通过以下的命令进入虚拟环境: workon py3cv4 然后在虚拟环境中安装OpenCV的一个依赖项NumPy: pip install numpy 然后通过以下命令进行基本的配置: cd ~/opencv mkdir build cd build cmake -D CMAKE_BUILD_TYPE=RELEASE \ -D CMAKE_INSTALL_PREFIX=/usr/local \ -D OPENCV_EXTRA_MODULES_PATH=~/opencv_contrib/modules \ -D ENABLE_NEON=ON \ -D ENABLE_VFPV3=ON \ -D BUILD_TESTS=OFF \ -D INSTALL_PYTHON_EXAMPLES=OFF \ -D OPENCV_ENABLE_NONFREE=ON \ -D CMAKE_SHARED_LINKER_FLAGS=-latomic \ -D BUILD_EXAMPLES=OFF .. cmake完成之后如图22所示: 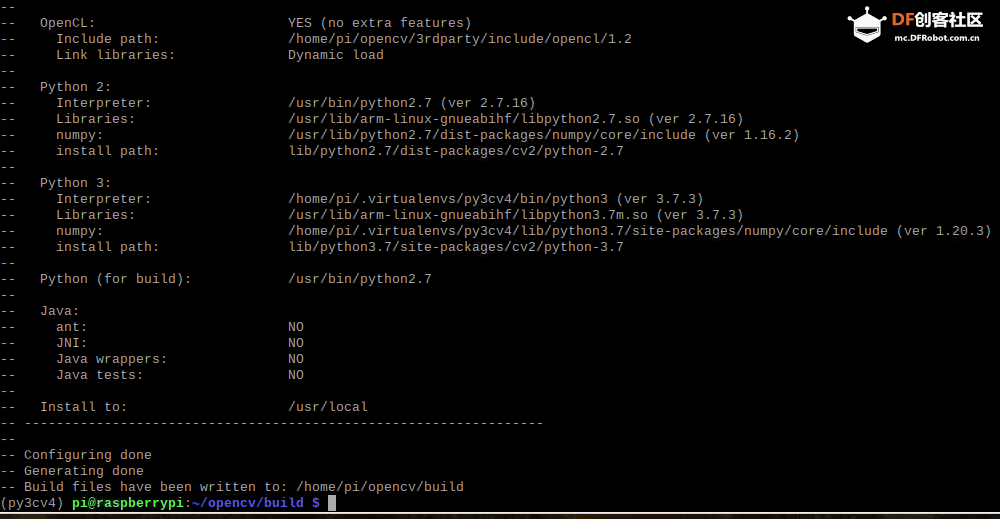 图22 修改.bashrc文件 接下来开始编译OpenCV 4.5.2,使用四个内核启进行编译,正确编译结果如图23所示: make -j4 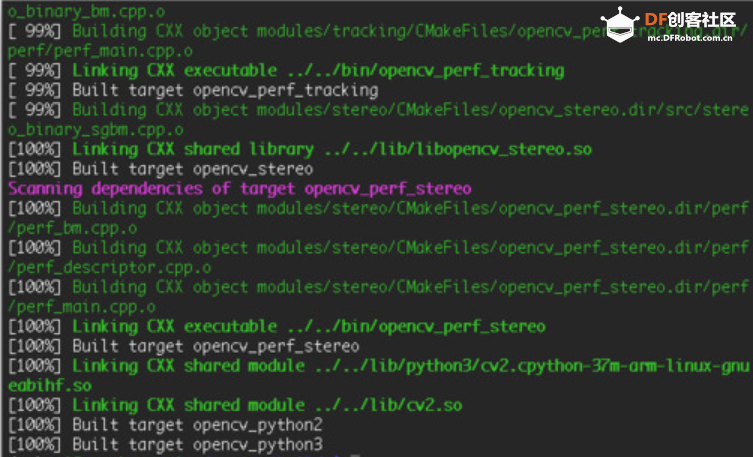 图23 正确编译结果 接下来安装OpenCV: sudo make install sudo ldconfig 完成OpenCV的编译之后需要重置SWAP,打开/etc/dphys-swapfile文件,将CONF_SWAPSIZE的值改为100MB,然后重启swap服务。 接下来将cv2.so链接到虚拟环境py3cv4: cd /usr/local/lib/python3.7/site-packages/cv2/python-3.7 sudo mv cv2.cpython-37m-arm-linux-gnueabihf.so cv2.so cd ~/.virtualenvs/cv/lib/python3.7/site-packages/ ln -s /usr/local/lib/python3.7/site-packages/cv2/python-3.7/cv2.so cv2.so 最后测试OpenCV4.5.2是否安装正确: cd ~ workon py3cv4 python3 >>> import cv2 >>> cv2.__version__ '4.5.2' >>> 3、安装dlib、imutils、numpy、RPi.GPIO、gpiozero等库。 这几个库通过pip可以直接安装: pip install dlib pip install imutils pip install numpy pip install RPi.GPIO pip install gpiozero 其中dlib C ++库是用于线程,网络,数值运算,机器学习,计算机视觉和压缩等跨平台的软件包,可以实现面部标志检测、相关跟踪、深度度量学习等。 4、应用OpenCV和dlib库进行实时人脸检测、面部标志提取及眨眼检测(眼睛纵横比:EAR算法) 新建python文件pi_drowsiness_detection.py,首先导入需要的软件包: 代码 接着定义一个距离函数,使用NumPy计算欧几里得距离: 接着定义眼睛长宽比(EAR)函数,该函数用于计算垂直眼睛界标之间的距离与水平眼睛界标之间距离的比率,睁开眼睛时,返回值将大致保持不变,眨眼时返回值将减小至零。如果闭上眼睛,则眼睛的长宽比将保持较小的恒定值: 接下来解析命令行参数,定义了两个必需的参数和一个可选的参数,--cascade:用于人脸检测的Haar级联XML文件的路径。--shape-predictor:dlib面部界标预测器文件的路径。--alarm:一个布尔值,指示在检测到困倦时是否应使用TrafficHat蜂鸣器。 如果—alarm标志设置好了,需要设置TrafficHat,如果提供的参数大于0,我们将导入TrafficHat函数来处理蜂鸣器警报: 接下来还需要定义一组重要的配置变量,两个常数定义了EAR阈值,必须闭眼的连续帧数才能分别视为睡着,然后,我们初始化帧计数器和警报的布尔值: 接下来加载Haar级联和面部界标预测器文件,我们使用了更快的检测算法(Haar级联),同时又提高了准确性。Haar级联比dlib的面部检测器(基于HOG +线性SVM)更快,使其成为Raspberry Pi的绝佳选择: 接下来,为每只眼睛初始化脸部界标的索引,在这里,使用数组切片索引,以便从面部界标集中提取眼睛区域: 接下来,准备开始视频流线程,设置了一秒钟的延时,因此相机可以预热: 接下来,开始遍历视频流中的帧,每读取一帧,调整大小(以提高效率),然后将其转换为灰度,然后,使用检测器检测灰度图像中的人脸: 接下来,遍历检测,开始一个冗长的for循环,在这里将其分解为几个代码块,首先,提取坐标和rects检测,然后,使用从Haar级联边界框中提取的信息构造了一个dlib rectangle对象,接着确定脸部区域的脸部界标,并将脸部界标(x,y)坐标转换为NumPy数组: 接下来,提取每只眼睛的坐标并计算EAR,利用眼睛界标的索引,可以将shape阵列以获得每只眼睛的(x,y)坐标,然后,为每只眼睛计算EAR,然后计算两只眼睛的长宽比平均值: 接下来,主要可视化处理: 接下来,检测眼睛长宽比和帧计数器,看看眼睛是否闭上,同时响起警报,且LED红灯闪以提醒睡着的驾驶员,首先检查眼睛的长宽比是否低于眨眼阈值,如果是,则增加闪烁帧计数器,接着如果眼睛闭上足够数量的帧,然后蜂鸣器发出警报,如果蜂鸣器未打开,请打开它,检查看是否有TrafficHat蜂鸣器开始响,否则,眼睛的长宽比不低于眨眼阈值,则重置计数器和警报: 最后,将EAR显示在frame框内,并通过关闭所有打开的窗口并停止视频流进行清理: 完成的python代码如下所示,因为上面每一步都注释了,下面完整的代码没有注释: 最后,树莓派开机自启动以下命令,执行睡意检测,效果截图如图24所示: python3 pi_detect_drowsiness.py --cascade haarcascade_frontalface_default.xml --shape-predictor shape_predictor_68_face_landmarks.dat --alarm 1  图24 睡意检测效果图 5、使用PID(比例积分微分)算法及OpenCV人脸检测算法实现人脸实时平移及倾斜跟踪 (1)首先安装必备的软件:smbus、pantilthat,smbus需要链接到py3cv4虚拟环境中,pantilthat使用pip即可安装: cd ~/.virtualenvs/py3cv4/lib/python3.7/site-packages/ ln -s /usr/lib/python3/dist-packages/smbus.cpython-37m-arm-linux-gnueabihf.so smbus.so pip install pantilthat (2)接着新建三个python文件,分别是:objcenter.py、pid.py、pan_tilt_tracking.py,还需要训练一个Haar Cascade面部检测器haarcascade_frontalface_default.xml。 ①开始创建PID控制器 以下脚本实现了PID公式,不需要导入数学库,但是需要导入time库,接着定义一个PID的类,该类具有构造函数、初始化值和update,构造函数接受三个参数,分别是kP , kI , 和kD,这些值都是常量,并且都在程序脚本中指定了,主体中定义了三个相应的实例变量: 接下来,初始化,初始化当前时间和上一次时间,初始化上一个错误,初始化P、I、D变量: 接下来,重点是PID类的update方法,update将以快节奏的循环进行: 完整的python代码如下所示,因为上面每一步都注释了,下面完整的代码没有注释: ②接下来需要实现检测物体本身及计算对象的中心坐标(x,y),新建ObjCenter.py文件。 首先导入OpenCV和imutils两个软件包,然后定义ObjCente类,构造函数接受一个参数-Haar Cascade人脸检测器的路径,再初始化检测器: 接下来定义update方法,该方法将找到的面部中心的坐标(X,Y),主要用于查找脸部,并接受两个参数:frame和frameCenter: 完整的代码如下所示,因为上面每一步都注释了,下面完整的代码没有注释: ③将人脸跟踪和PID算法合并到一起,实现平移和倾斜跟踪,新建pan_tilt_tracking.py文件。 首先导入需要用到的软件包,并且定义舵机的范围为180度(-90°到90°): 接着定义一个处理键盘中断的函数: 接下来,定义第一个流程,如果无法检测到脸部,则选择返回框中心: 接下来,定义下一个过程,因为很多的任务由PID完成。这些过程中的两个将在任何给定时间(平移和倾斜)运行。如果有复杂的机器人,则可能需要运行更多的PID进程,该方法接受六个参数: 还有另一个线程可以“监视”每个线程驱动伺服器的输出值,接下来实现一个伺服范围检查器和伺服驱动器: 接下来,解析命令行参数: 接下来使用流程安全变量并开始一个进程: 接下来设置P、I和D常量: 接下来,准备好所有的过程安全变量之后,启动进程: 完整代码如下所示: 最后,树莓派开机将自动执行以下脚本,效果图截图如图25所示: Python3 pan_tilt_tracking.py --cascade haarcascade_frontalface_default.xml  图25 睡意检测效果图 (6)树莓派开机自启动Python脚本 首先创建两个重要的Shell脚本,①访问python虚拟环境,②执行python脚本。 新建on_reboot.sh,放入以下代码,然后保存: #!/bin/bash source /home/pi/.profile workon cv cd /home/pi/pi-reboot python pi_reboot_alarm.py 然后,让该脚本可以执行,需要chmod: chmod +x on_reboot.sh 接下来更新crontab,以便在系统重启时调用它脚本,执行以下命令,以编辑root用户的crontab: sudo crontab -e 此命令将打开crontab文件,该文件如图25所示: 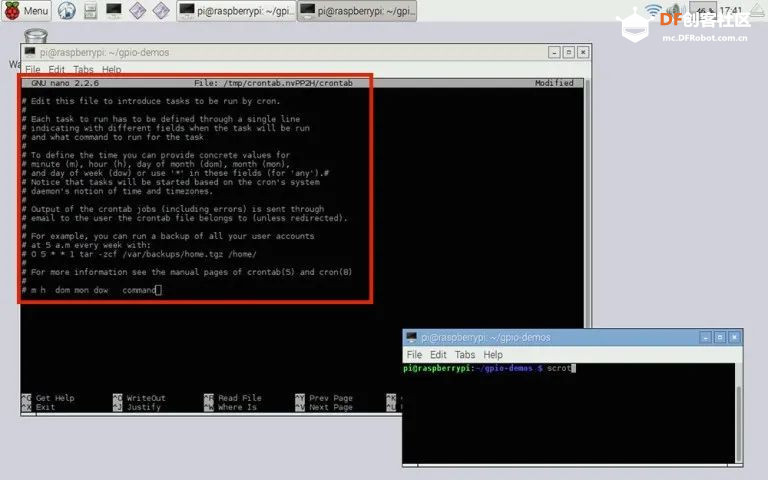 图26 crontab文件 然后,在文件底部输入以下行,该命令指示系统重新启动系统时执行脚本on_reboot.SH,完成crontab的编辑后,保存文件并退出编辑器,对crontab的更改将自动应用,然后在下次重新启动时,on_reboot.SH 脚本将自动执行: @reboot /home/pi/pi-reboot/on_reboot.sh (三)终端组装 1、两自由度云台组装 首先整理零件,编号如图27所示:  图27 零件编号 安装MG90S舵机,如图28所示:  图28 安装MG90S舵机 安装单向摇臂、十字摇臂,如图29所示:  图29 安装单向摇臂、十字摇臂  图30 安装MG90S舵机到云台底盘 安装SG90舵机,如图31所示:  图31 安装SG90舵机 安装摄像头到亚克力板,如图32所示:  图32 安装摄像头到亚克力板 舵机接线,MG90S接S1接口,SG90舵机接S0接口,如图33所示: 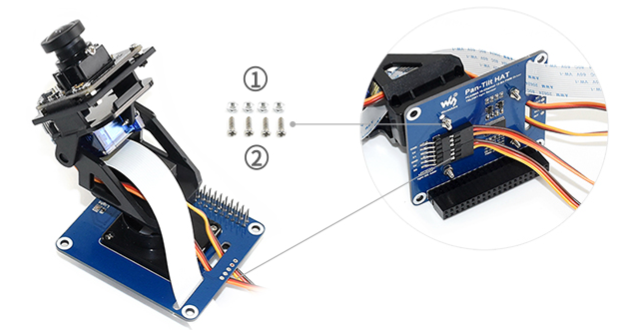 图33舵机接线 舵机正确的连线图如图34所示,棕色线接GND,红色线接5V,橙色线接S1/S0:  图34 舵机正确的连线图 2、外观结构组装 需要通过榫卯拼插就可以完成,如图35所示:  图35 外观结构组成 安装LED灯和蜂鸣器,通过螺丝或者热熔胶固定,如图36所示:  图36 安装LED灯和蜂鸣器 固定树莓派,接线,树莓派GPIO接口图如图37所示,绿灯GND接树莓派GPIO14、VCC接GPIO4、IN接GPIO15,红灯GND接树莓派GPIO6、VCC接GPIO2、IN接GPIO18,蜂鸣器GND接树莓派GPIO30、VCC接GPIO1、IN接GPIO29,如图38所示: 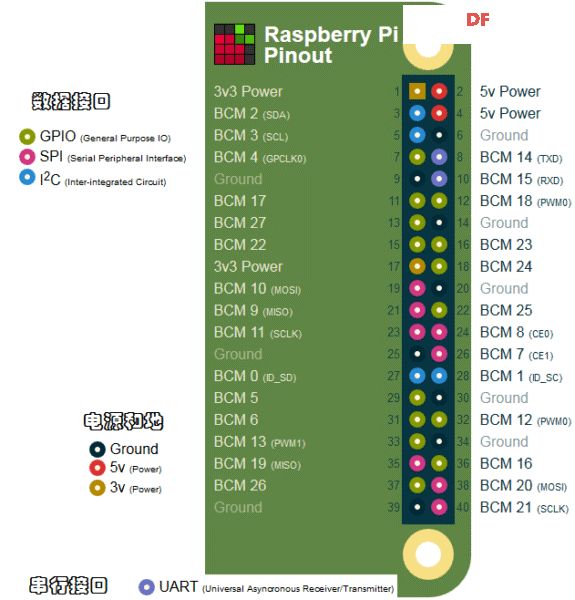 图37 GPIO接口图  图38接线图 固定云台,安装在盒子的上面,如图39所示:  图39 固定云台 摆放显示屏,使用可调节倾斜度的支架来放,如图40所示:  图40 摆放显示屏 整体效果图如图41所示:  图41 效果图 项目总结 该作品实现了预期效果,应用CV及PID算法可以实时检测跟踪人脸检测睡意情况,并预警提示,整个算法在树莓派上可以正常运行,没有BUG。下一步需要优化和改进的地方:①在弱光环境下进行人脸及眨眼检测,②使用HOG及深度学习人脸检测算法进行人脸检测与跟踪,提高检测的准确性,③外观结构优化,将显示屏、主控板及传感器集成到一起,打造一款为驾驶者设计的人性化车载装置。 未来展望 未来,我们将在⽆⼈驾驶汽⻋的理念下开发创新终端,为老年人等弱势群体⽅便“驾驶”汽⻋提供帮助,添加更多功能,避免酒驾、疲劳驾驶,杜绝“劣迹”司机。还将添加语⾳指令,解放双⼿,智能对话,⻋最懂你。结合设计思维、创新理念和前沿科技研发一款终端,本着促进社会的可持续发展的原则,打造⼀款具有社会意义和产品价值的产品,用科技赋能弱势群体。 |



 沪公网安备31011502402448
沪公网安备31011502402448© 2013-2026 Comsenz Inc. Powered by Discuz! X3.4 Licensed


 置顶卡
置顶卡 变色卡
变色卡 千斤顶
千斤顶
 萌萌哒新人
萌萌哒新人
 活跃会员
活跃会员
 宣传大使
宣传大使
 志“童”道合
志“童”道合
 编辑选择奖
编辑选择奖






