|
11300| 0
|
[动态] 2024 年最受欢迎的 6 种物体检测模型|YOLOv10、EfficientDet... |

|
物体检测是计算机视觉和人工智能中的一个重要领域,它允许计算机程序通过识别图像或视频中的物体来“看到”周围环境。随着深度学习技术的进步,物体检测的准确性已达到前所未有的水平。现在有许多前沿的物体检测模型可供选择。本文将介绍和比较 2024 年几种流行的物体检测模型。无论您是计算机视觉或机器学习应用程序的开发人员,还是该领域的爱好者,本文都将帮助您为下一个项目选择合适的模型。 什么是物体检测模型?对象检测模型是一类机器学习模型,旨在自动检测、定位和识别数字图像或视频中的特定对象。这些模型使用深度学习技术从数据中学习特征,并将学习到的模式应用于新的输入图像,以预测图像中存在哪些对象以及它们的确切位置和边界框。 常见的物体检测算法主要分为四类:
物体检测模型将用于特征提取的卷积层与诸如区域提议网络 (RPN) 或基于锚点的机制之类的专用层相结合,以生成感兴趣物体的边界框。此外,这些模型通常采用非最大抑制 (NMS) 等最先进的技术来过滤掉冗余检测并提高整体检测准确率。 这些模型可以准确、高效地实时识别物体,成为自动驾驶、视频监控和物体识别等应用中不可或缺的工具。 为什么需要物体检测?物体检测模型可应用于各个领域,包括:
 物体检测是实现任务自动化、增强安全性和提高视觉数据解读效率的关键要素。它在开发跨行业的智能系统方面发挥着至关重要的作用。因此,物体检测的准确性和处理速度是评估计算机视觉应用模型的重要指标。 市场上有各种开源和商业模型,以下是 2024 年值得关注的一些顶级物体检测模型。 2024 年最流行的 6 种物体检测模型1. YOLO(YOLOv10)YOLO(You Only Look Once)是计算机视觉和机器学习开发人员中流行的物体检测模型。YOLO 采用革命性的单阶段物体检测方法,将图像分成大小相等的网格,并分别预测每个网格中物体的存在及其概率。 YOLO 由 Joseph Redmon 开发,并由 Ultralytics 继续开发,它代表了一种将物体检测的速度和准确性相结合的开创性方法。YOLO 将物体检测视为回归问题,在一次评估中直接从输入图像中预测边界框和类别概率。 YOLO 的主要优点包括:
最初的 YOLOv1(2015)引入了这种统一的检测方法。后续版本在性能方面有所提升:
 尽管 YOLOv3/v4 等早期版本曾经是最先进的,但 YOLOv7/v8 等最新版本在 MS COCO 等基准测试中取得了顶级成绩,同时保持了适合自动驾驶、监控和机器人等应用的实时速度。2024 年 2 月发布的 YOLOv9 引入了可编程梯度信息 (PGI) 和轻量级 GELAN 架构,显著提高了性能,适用于从轻量级到大型的各种模型。 今年2月YOLOv9发布后,YOLO(You Only Look Once)系列的接力棒就交给了中国清华大学的科研人员。 5月底,YOLOv10上线,研究团队针对YOLO提出了整体效率和准确率驱动的模型设计策略,从效率和准确率两个角度对YOLO各个组件进行优化,大幅降低计算成本并增强模型能力。 大量实验表明,YOLOv10 在各种模型规模上都达到了 SOTA 性能和效率。例如,YOLOv10-S 在 COCO 上的 AP 比 RT-DETR-R18 快 1.8 倍,同时显著减少了参数数量和 FLOP。与 YOLOv9-C 相比,YOLOv10-B 在保持相同性能的情况下,延迟降低了 46%,参数减少了 25%。 YOLO系列的简单性、快速性和持续的改进使其成为迄今为止使用最广泛、影响力最大的物体检测框架之一。 2. EfficientDet:以其效率和准确性而闻名,利用 EfficientNet 作为骨干。  EfficientDet 是由 Google Brain 的研究人员于 2020 年提出的,是一种最先进的物体检测模型,它在模型大小和推理速度方面非常高效,同时实现了高精度。 EfficientDet 背后的关键思想包括:
EfficientDet 架构的工作原理如下:
EfficientDet 模型(例如 EfficientDet-D7)在具有挑战性的 COCO 数据集上实现了最佳准确率,同时比 Faster R-CNN 等之前的检测器小一个数量级且速度更快。它们在移动设备等各种资源受限的环境中都能很好地工作。 复合缩放方法可以简单地扩展 EfficientDet 模型以提高准确率,或缩小模型以加快移动部署速度。这种灵活性与一流的性能相结合,使 EfficientDet 成为许多物体检测应用的热门选择。 3. RetinaNet:引入焦点损失 (Focal Loss) 来处理类别不平衡问题。 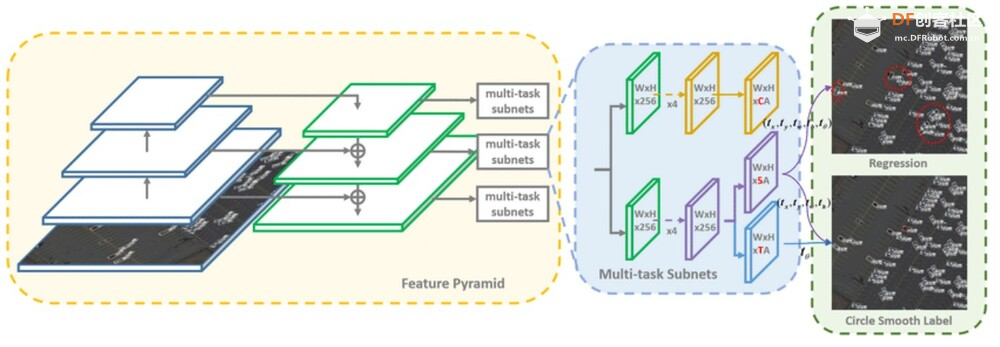 RetinaNet 是由 Facebook AI Research 的研究人员于 2017 年提出的,是一种高效且准确的单阶段物体检测模型。它解决了 YOLO 和 SSD 等之前的单阶段检测器的几个缺点。 RetinaNet 的关键创新包括:
RetinaNet 架构的工作原理如下:
RetinaNet 在推出时就在 COCO 基准上取得了最佳成绩,其准确率超过了之前的一阶段和两阶段检测器,同时速度也比两阶段模型更快。它能够稳健地检测小型和大型物体,因此适合各种实际应用。 虽然最近的架构已经取得了进一步的进步,但 RetinaNet 的影响源于它对单阶段检测中的关键挑战(如类别不平衡和多尺度感知)的优雅解决方案。其改进表示和监督的设计原则影响了许多后续的物体检测器。 4.更快的R-CNN:使用区域提议网络(RPN)的高精度模型。 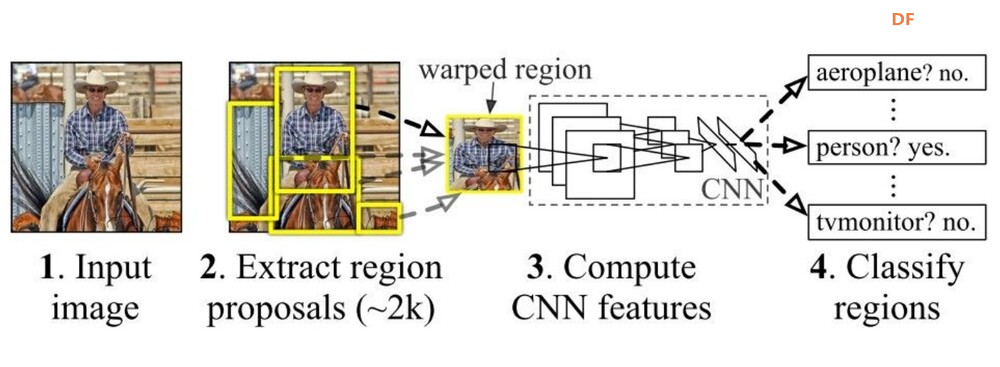 Faster R-CNN 由 Shaoqing Ren 等人于 2015 年提出,是一种极具影响力的两阶段目标检测模型,与 R-CNN 和 Fast R-CNN 等前辈相比有显著改进。 Faster R-CNN 的关键创新包括:
Faster R-CNN 架构的工作原理如下:
Faster R-CNN 在推出时就在 PASCAL VOC 和 MS COCO 等基准测试中实现了最先进的物体检测准确率,同时比其前代 R-CNN 速度快得多。其两阶段设计可以精确定位物体。 尽管在速度方面被 YOLO 和 SSD 等较新的单阶段模型所取代,但 Faster R-CNN 为许多后续的基于区域的 CNN 检测器奠定了基础。其影响力被 Mask R-CNN(例如分割)等有影响力的后续模型及其对其他视觉任务的扩展所放大。 Faster R-CNN 的准确性和架构创新巩固了其作为推动物体检测和视觉识别领域发展的里程碑模型的地位。 5.Mask R-CNN:Faster R-CNN 的扩展,添加了用于预测分割蒙版的分支。 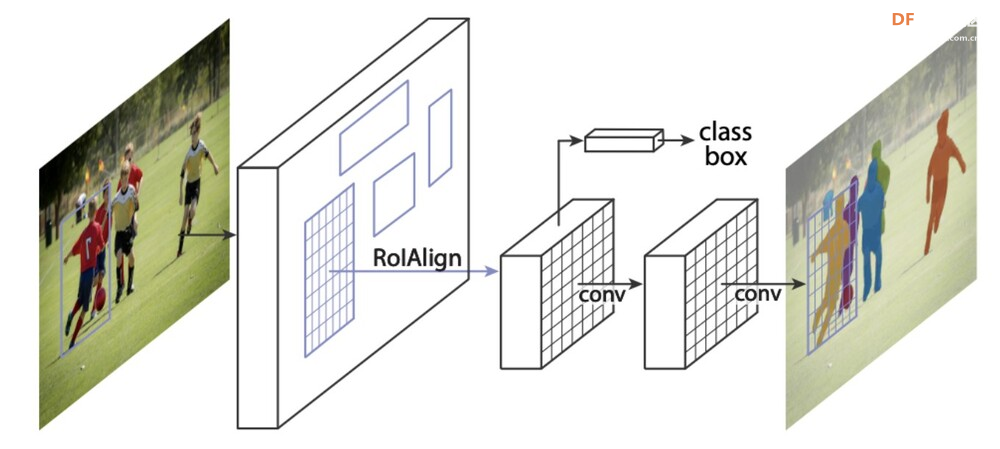 Mask R-CNN 由 Kaiming He 等人于 2017 年提出,是针对实例分割任务而提出的非常成功的 Faster R-CNN 模型的扩展。它不仅可以像 Faster R-CNN 一样预测物体周围的边界框,还可以为每个实例生成逐像素掩码。 Mask R-CNN 的关键创新包括:
Mask R-CNN 架构的工作原理如下:CNN 主干从输入图像中提取特征图。 Mask R-CNN 在推出后便在极具挑战性的 COCO 实例分割基准上取得了最佳结果,远远优于之前的方法。它能够生成高质量的蒙版和边界框,非常适合需要精确实例分割的应用。 除了实例分割之外,Mask R-CNN 还扩展到人体姿势估计等其他领域(例如,Mask R-CNN + Keypoint R-CNN),显示出其作为对象检测和分割任务的通用框架的多功能性。 Mask R-CNN 的准确性、稳健的设计和广泛的采用巩固了其作为实例级识别领域最具影响力的模型之一的地位,也是先进计算机视觉系统开发的重要里程碑。 6.DETR(检测变压器):使用变压器进行物体检测,为该任务提供一种新方法。 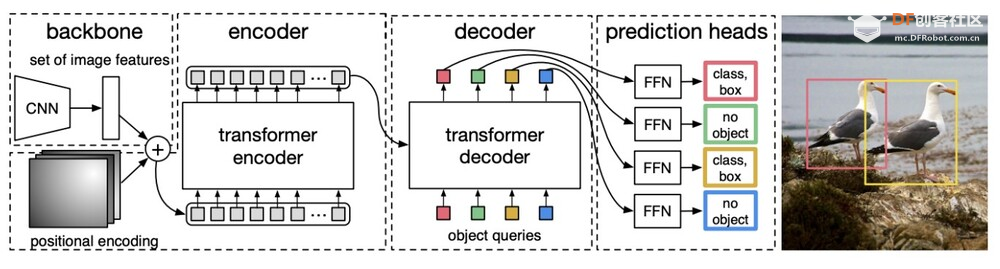 DETR 是 DEtection TRansformer 的缩写,是 Facebook AI Research 的研究人员于 2020 年提出的一种开创性物体检测模型。这是第一篇以简单有效的方式成功将 Transformer 架构应用于物体检测任务的论文。 DETR 背后的关键思想包括:Transformer 编码器-解码器: DETR 采用神经机器翻译中的 Transformer 编码器-解码器设计,利用它来处理输入图像并直接并行输出最终预测。 DETR 架构的工作原理如下:
DETR 在推出时就与成熟的 Faster R-CNN 检测器的性能相当,同时更简单且更易于并行化。它展示了 Transformer 在图像分类以外的高级计算机视觉任务中的潜力。 虽然 DETR 比传统检测器慢,但它激发了一系列后续工作,以提高其速度和准确性,并将其扩展到全景分割等任务。可变形 DETR、高效 DETR 和 Anchor DETR 都建立在其核心的基于 Transformer 的检测理念之上。 DETR 强大的基于集合的全局推理能力以及与掩码/关键点等辅助输出的无缝集成,实现了优雅、统一的视觉转换器框架。其影响不仅限于物体检测,还引发了转换器在各种视觉任务中的更广泛应用。 概括本文介绍了几种流行的物体检测模型并进行了比较。 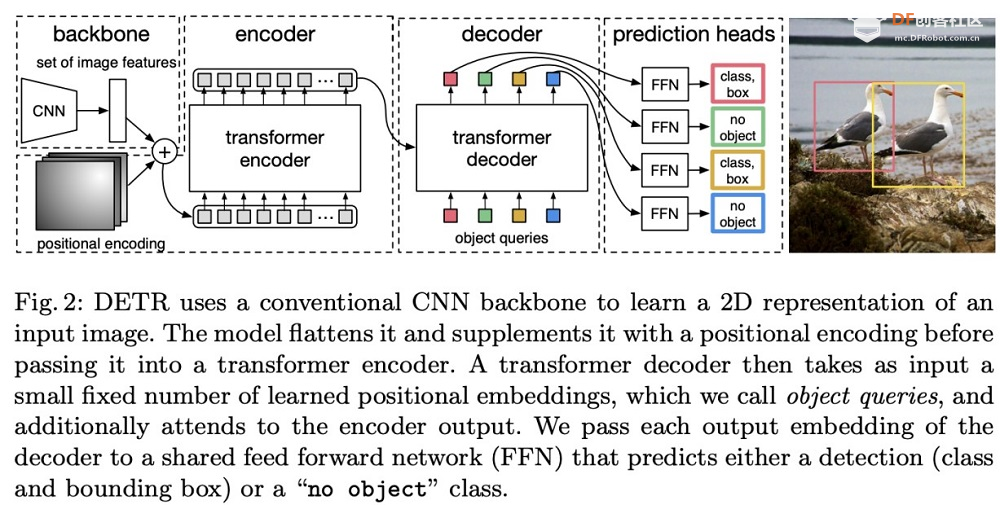 如何选择?
根据具体的应用需求和硬件配置,选择最合适的型号,可以实现性能和效率的最佳平衡。 如果你对最新的研究进展感兴趣,还可以关注计算机视觉和模式识别领域的重要会议,如CVPR(计算机视觉与模式识别会议)和ICCV(国际计算机视觉会议),这些会议经常发布物体检测模型的最新进展和新应用。 |



© 2013-2024 Comsenz Inc. Powered by Discuz! X3.4 Licensed


 置顶卡
置顶卡 变色卡
变色卡 千斤顶
千斤顶
 萌萌哒新人
萌萌哒新人
 活跃会员
活跃会员
 宣传大使
宣传大使
 志“童”道合
志“童”道合
 编辑选择奖
编辑选择奖






