|
3950| 1
|
爬虫学习笔记一、爬虫实践项目之爬取天气预报数据 |
|
爬虫学习笔记一、爬虫实践项目之爬取天气预报数据 ------来源深圳信息职业技术学院黄老师的python网络爬虫程序技术课程 一、 项目简介:在中国天气网(http://www.weather.com.cn)中输入一个城市的名称,例如输入杭州,那么会转向http://www.weather.com.cn/weather/101210101.shtml的网页显示杭州的天气预报,其中101210101 是杭州的代码,每个城市或者地区都有一个代码。 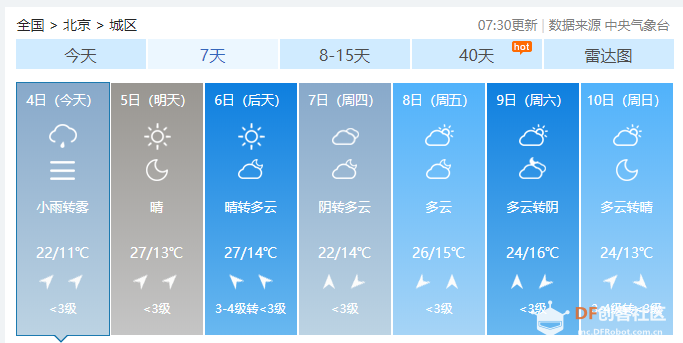 (中国天气网杭州1周的天气) 二、HTML 代码分析: 方法一、将网页文件保存成html文件,然后去分析所需要数据信息的html文件格式。 方法二、 用 Chrome 浏览器浏览网站,鼠标指向 7 天天气预报的今天位置,点击右键弹出菜单, 选择“检查”就可以打开这个位置对应的 HTML 代码。 然后选择<ulclass="t clearfix">元素,点击右键弹出菜单选择"Edit as HTML",就可以进入编辑状态,复制整个 HTML,结果如下: 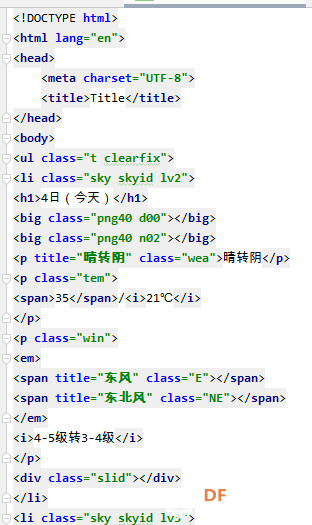 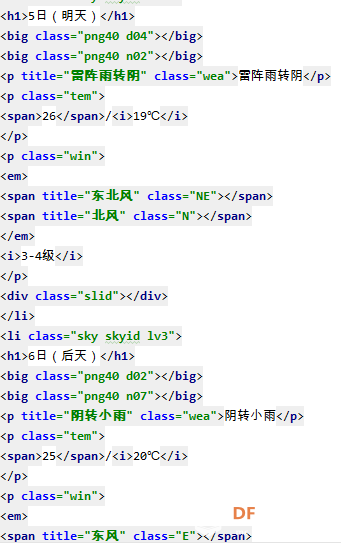 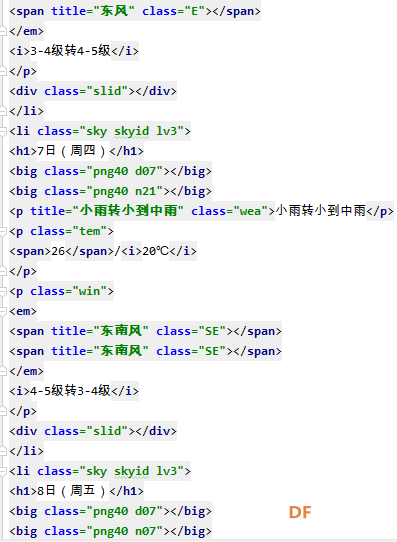  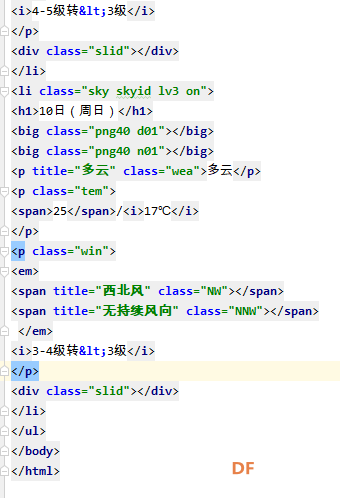 三、 通过分析 HTML 代码,我们可以编写爬取程序爬取杭州 7 天的天气预报数据: 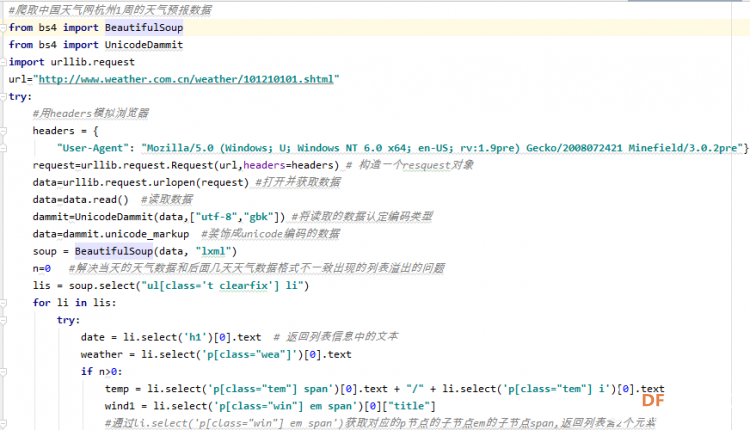 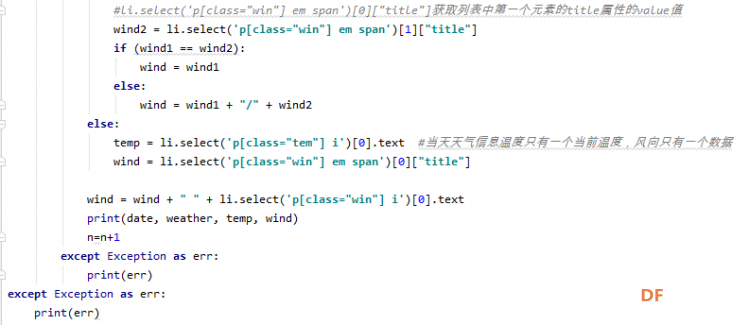 四、 输出获取的数据 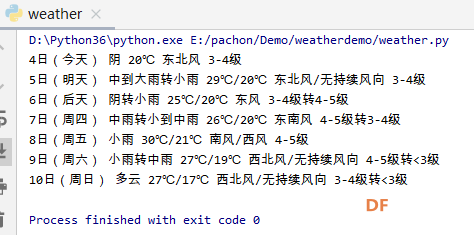 五、 学习收获: 1、解决当天的天气数据中温度、风力和后面几天天气数据格式不一致出现的列表溢出的问题。通过增加一个变量,设置初始值为n=0,一次循环以后n=n+1 然后分别根据n>0和n=0分情况讨论: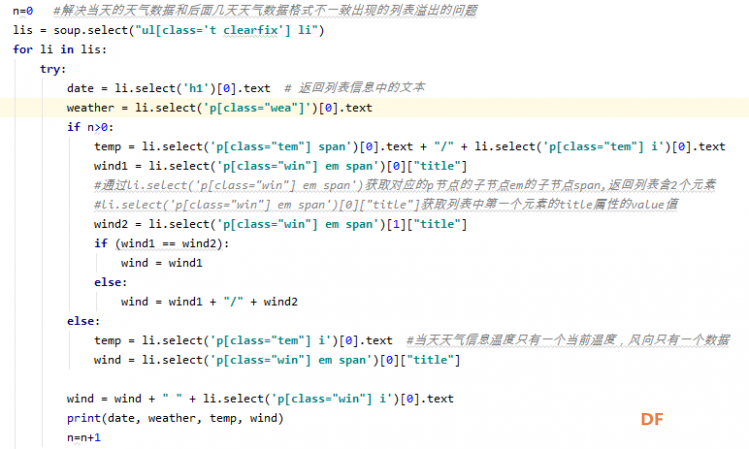 2、实现了如何从查询到的满足条件的节点内容中,通过循环继续从当前获得的节点内容中实现beautifulsoup查询。通过li.select('p[class="win"] em span')获取对应class属性值为win的p节点的子节点em的子节点span,返回的列表含2个元素。通过li.select('p[class="win"] em span')[0]["title"] 和li.select('p[class="win"] em span')[1]["title"]获取列表中第一个和第二个元素的title属性的value值,以便获取不同的风向值。  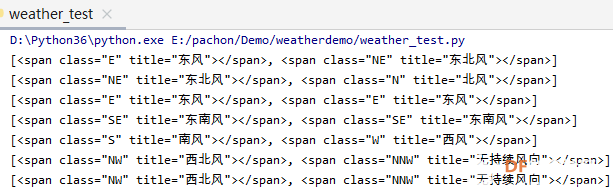 |



 沪公网安备31011502402448
沪公网安备31011502402448© 2013-2026 Comsenz Inc. Powered by Discuz! X3.4 Licensed

 置顶卡
置顶卡 变色卡
变色卡 千斤顶
千斤顶






