本帖最后由 NciJlUN1qMan 于 2022-8-2 15:03 编辑
随着社会矛盾的转变和人们生活水平的不断提高,越来越多人喜欢养宠物来陪伴自己以满足精神需求,然而,宠物虽可爱却无法与我们聊天互动。
这时候,有一个既能陪伴我们又能与我们对话的聊天机器人是不是很有趣呢?
任务目标
调用百度AI开放平台的语音识别、语音合成以及智能对话接口,实现与机器人小空进行对话互动。
知识点
1、了解语音合成的一般过程
2、学习通过调用百度语音平台接口实现将文字转换成语音的方法
3、了解通过百度智能对话平台UNIT实现语音对话的方法
4、学习通过unihiker库播放音频的方法
材料清单
硬件清单:
软件使用:Mind+编程软件x1
知识储备
1、什么是语音合成
语音合成是利用计算机模拟人的发音而产生人造语音的技术。通俗地讲,就是将文本转换****类可以听得懂并且流利的语音。
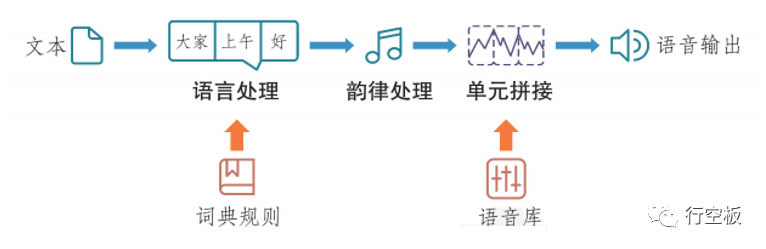
语音合成一般会经历以下基本过程:先将文本分解成音素,经过韵律处理后,再根据音素在语音库中找到发音单元,并输出拼接的发音单元,从而形成语音,如下图所示。
上述过程看起来同样不简单,那么我们是不是可以像语音识别一样借助一些平台来实现呢?
答案是肯定的。通过人工智能开放平台提供的软件开发工具包,可以把文本文件转换成语音文件;也可以采用在线合成语音的方式,先输入文本,再输出相应的语音信息,如利用阿里云人工智能平台,将输入的文本信息转换成语音,识别过程如下图所示。
而这节课上,我们依旧使用百度开放平台,我们只需要提供相应的文本信息,然后调用百度语音合成的接口,就可以实现将它转换为音频文件啦。
1、什么是智能对话系统
智能对话系统是利用技术使得机器理解人类语言,并与人类进行有效的沟通,进而根据对人类语言中的意图进行理解并执行特定任务或作出回答的系统。智能对话系统作为人工智能领域的核心技术,即将成为新的和谐人机交互方式,具有重大的研究意义和应用价值。它能够将人们从重复的劳动中解救出来,比如智能克服可以取代人工工作中高度重复的标准化客户咨询。
那么如何搭建智能对话系统呢?
这里,我们需要借助百度的智能对话定制与服务平台UNIT。通过它,我们只需提供对话中一方的内容,然后调用百度UNIT平台接口和指定ID的对话机器人,就可以收到机器人的回答啦。
Tips:关于如何获取UNIT平台接口参数以及如何创建机器人ID,我们可参考附录2。
3、unihiker库Audio类play()方法播放音频
unihiker库Audio类的play()方法可以播放音频,在使用前,我们需要先导入库中的这个模块并通过实例化类的方式创建一个对象,之后,通过“对象.方法名()”的形式来实现功能。
- from unihiker import Audio # 导入unihiker库中的Audio模块
- audio = Audio() # 实例化音频
- audio.play("synth.mp3") # 播放音频文件
其中,“synth.mp3”是要播放的音频文件。
4、aip库AipSpeech类synthesis()方法将文本内容合成为语音
aip库AipSpeech类synthesis()方法可以实现将字符文本合成为语音,在使用前,我们需要先创建与百度语音平台的连接,之后,通过“对象.方法名()”的形式来实现功能。
- from aip import AipSpeech # 导入百度语音库
- client = AipSpeech (APP_ID, API_KEY, SECRET_KEY) # 连接百度AI语音合成平台
- synth_context = client.synthesis("你好", "zh", 1, {
- "vol": 5,
- "spd": 5,
- "pit": 3,
- "per": 0
- }) # 合成语音
其中,“你好”指代要合成为音频的文本内容,“zh”指的是语言中文,“1”表示pc端,“vol”指的是音量,“spd”指语速,“pit”指语调,“per”表示声道(0:女,1:男,2:逍遥音,4:小萝莉)。
动手实践
任务描述1:文字合成语音
运行程序,聊天机器人小空将给定的文字信息通过小喇叭播报出来。
1、硬件搭建
STEP1:通过USB连接线将行空板连接到计算机
STEP2:将USB喇叭连接至行空板
2、分析设计
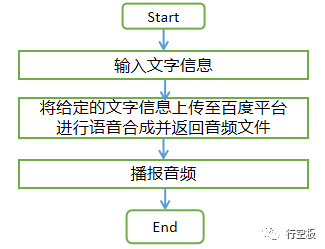
在这个任务中,我们输入一段文字,将其上传给百度语音平台进行处理,合成语音文件后进行播放。
3、程序编写
STEP1:创建与保存项目文件
启动Mind+,另存项目并命名为“015、聊天机器人”。
STEP2:创建与保存Python文件
创建一个Python程序文件“main1.py”,双击打开。
STEP3:程序编写
(1)导入所需库
在这个任务中,我们需要使用unihiker库的Audio模块播放音频,通过aip库的AipSpeech模块来进行语音合成,因此我们需要先导入它们。
- from aip import AipSpeech # 导入百度语音库
- from unihiker import Audio # 导入unihiker库Audio模块
(2)实例化音频
为了后续能够实现音频的播放,这里,我们需要先实例化Audio类。
复制代码
(3)设置语音合成接口参数
为了后续能够连接上百度语音平台,这里,我们先设定好连接时所需的接口参数。
- APP_ID = "" # 引号内填写账号的APP_ID
- API_KEY='' # 引号内填写账号的API_KEY
- SECRET_KEY='' # 引号内填写账号的SECRET_KEY
(4)定义字符转语音函数
之后,我们定义一个字符转语音的功能函数,在这个函数中,我们需要做五个操作。第一,定义一个mp3格式的文件名以储存音频;第二,连接百度语音平台;第三,将字符信息通过百度云平台进行语音合成,并设置好其音量、语速、语调、声道;第四,打开音频文件,将合成的信息写入进来;最后,我们返回经过语音合成后的音频文件。
Tips:接口参数获取方式可参考附录2
- # 定义字符转语音函数,输入字符串文本,生成并反馈一个后缀为MP3的文件名
- def text_to_audio(res_str,APP_ID, API_KEY, SECRET_KEY):
- synth_file = "synth.mp3" # 音频文件保存名
- client = AipSpeech (APP_ID, API_KEY, SECRET_KEY) # 连接百度AI语音合成平台
- #synthesis参数: 文本,语言zh(中文),1为pc端,语音{"vol":音量,
- #"spd":语速,"pit":语调,"per":声道(0:女,1:男,2:逍遥音,4:小萝莉)}
- synth_context = client.synthesis(res_str, "zh", 1, {
- "vol": 5,
- "spd": 5,
- "pit": 3,
- "per": 0
- }) # 合成语音
- with open(synth_file, "wb") as f: # 打开音频文件
- f.write(synth_context) # 写入结果
- print("文字转语音成功,文件名:",synth_file) # 打印显示
- return synth_file # 返回音频文件
(5)检测系统时间并语音播报
最后,我们检测系统时间,用变量now_time存储起来,将其作为字符信息传入语音合成函数中,再将合成的音频进行播放。
- inf = "你好呀,我是聊天机器人小空!" # 给定要转成语音的文字内容
- print(inf)
- audio.play(text_to_audio(inf ,APP_ID, API_KEY, SECRET_KEY)) # 语音合成+播报
Tips:完整示例程序如下:
- #!/usr/bin/env python3
- # -*- coding: utf-8 -*-
- '语音合成,运行程序,自动播报输入的文本信息'
- from aip import AipSpeech # 导入百度语音库
- from unihiker import Audio # 导入unihiker库Audio模块
-
- audio = Audio() # 实例化音频
-
- # 定义连接百度语音平台所需接口参数(类似于密钥)
- APP_ID = "" # 引号内填写账号的APP_ID
- API_KEY='' # 引号内填写账号的API_KEY
- SECRET_KEY='' # 引号内填写账号的SECRET_KEY
-
-
- # 定义字符转语音函数,输入字符串文本,生成并反馈一个后缀为MP3的文件名
- def text_to_audio(res_str,APP_ID, API_KEY, SECRET_KEY):
- synth_file = "synth.mp3" # 音频文件保存名
- client = AipSpeech (APP_ID, API_KEY, SECRET_KEY) # 连接百度AI语音合成平台
- #synthesis参数: 文本,语言zh(中文),1为pc端,语音{"vol":音量,
- #"spd":语速,"pit":语调,"per":声道(0:女,1:男,2:逍遥音,4:小萝莉)}
- synth_context = client.synthesis(res_str, "zh", 1, {
- "vol": 5,
- "spd": 5,
- "pit": 3,
- "per": 0
- }) # 合成语音
- with open(synth_file, "wb") as f: # 打开音频文件
- f.write(synth_context) # 写入结果
- print("文字转语音成功,文件名:",synth_file) # 打印显示
- return synth_file # 返回音频文件
-
- inf = "你好呀,我是聊天机器人小空!" # 给定要转成语音的文字内容
- print(inf )
- audio.play(text_to_audio(inf ,APP_ID, API_KEY, SECRET_KEY)) # 语音合成+播报
Tips:须在程序中填入语音平台的APP_ID、API_KEY、SECRET_KEY三个接口参数。这里,我们可直接使用上节课创建得到的参数。
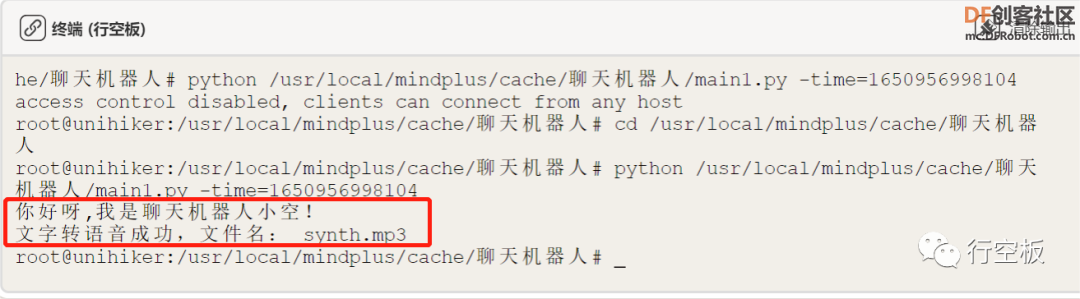
4、程序运行
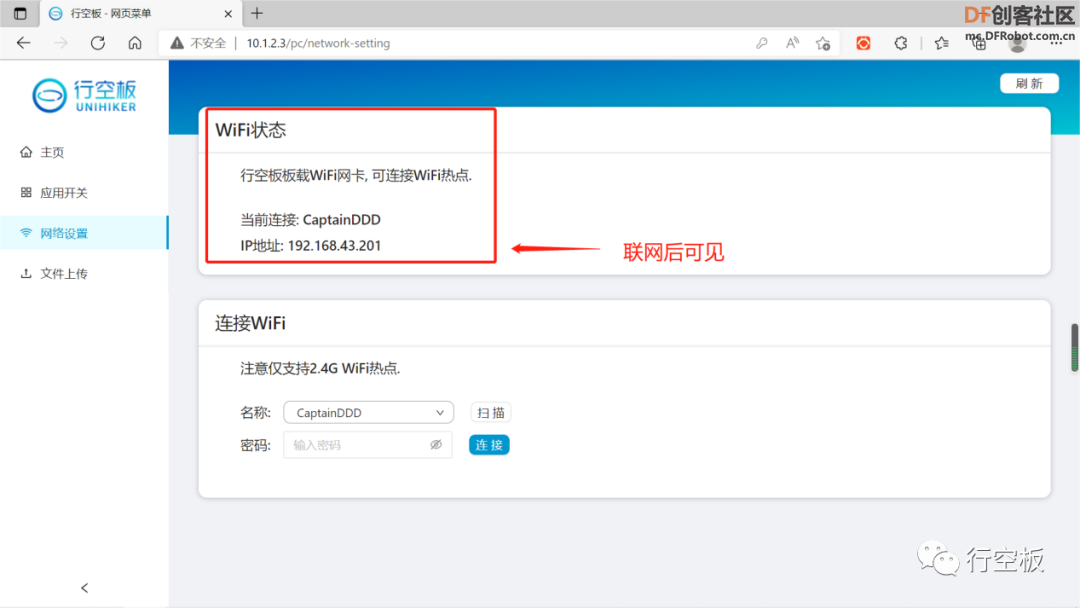
STEP1:连接网络
STEP2:远程连接行空板,运行并观察效果
观察行空板,可以听到小喇叭将我们输入的文字信息播报了出来,同时终端内也可看到生成的音频文件。
任务描述2:语音对话
在上个任务中,我们使行空板化身聊天机器人小空,播报出了输入的文字信息,接下来,我们将进一步完善它的功能,与其进行语音对话。
1、硬件搭建
继续通过USB连接线将行空板连接到计算机并保持USB喇叭与行空板的连接。
2、分析设计
在这个任务中,我们将与聊天机器人小空进行对话。首先,我们录制语音,并把它转换为文本信息,之后将其传至百度智能对话平台,获取到机器人的回答后,我们再将回答内容转换为音频文件,流程如下。
3、程序编写
STEP1:创建与保存项目文件
新建一个Python程序文件“main2.py”,双击打开。
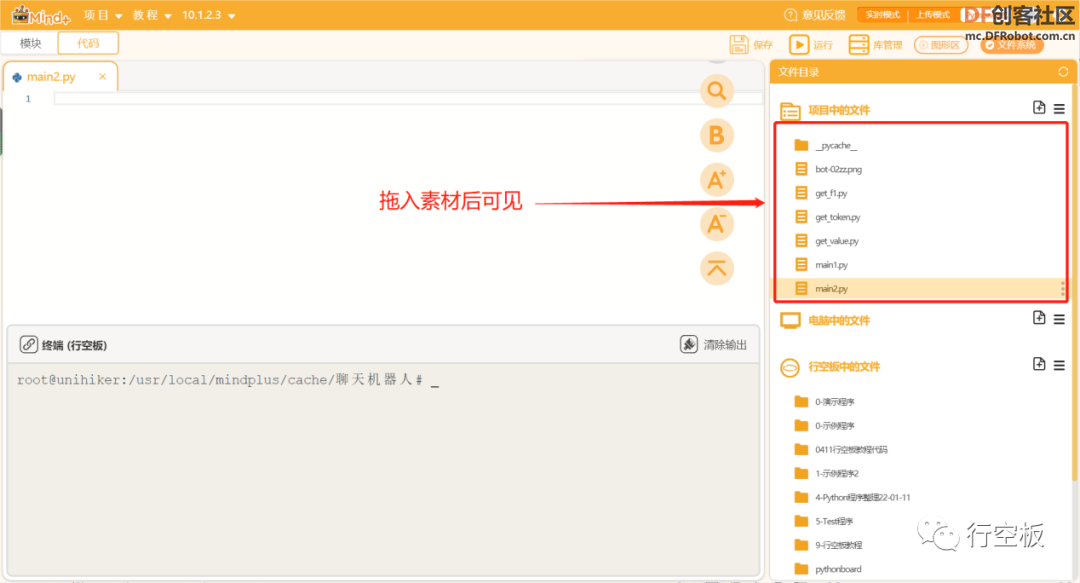
STEP2:导入素材
在项目文件夹中导入各个素材,包括三个Python文件和一个图片文件,具体操作如下。
(1)将素材依次拖入项目文件夹中
其中,bot-02zz.png是背景图;
get_f1.py、get_token.py和get_value.py是三个专门针对智能对话平台编写的功能库文件。
get_f1.py是完整的用来实现上传文本内容至智能对话平台并返回回答文本的Python文件;
get_token.py是用来实时获取token验证码的Python文件,在get_f1.py中被调用;
get_value.py是用来实现解析云端数据以获取答案内容的Python文件,在get_f1.py中被调用;
这里,为了精简主程序,我们把从智能对话平台获取回答反馈的功能单独写在了get_f1.py这个文件中,因此在主程序中使用时,我们只需调用该文件中的get_f()函数,并在括号中传入文本内容和三个接口参数即可实现功能。
Tips:素材下载链接可见附录1。
Step3:程序编写
(1)导入所需功能库
由于我们将使用板载按键控制对话的启停以及要获取对话的回答,因此,我们需补充导入Pinpong库和get_f1库。
- import get_f1 # 导入get_f1
- from pinpong.board import Board,Pin # 导入Pinpong库
- from pinpong.extension.unihiker import *
(2)初始化板子并实例化GUI
在使用板载按键前,我们需先初始化板子,而为了能够在屏幕上显示信息,我们需要实例化GUI类。
- Board().begin() # 主板初始化
- gui = GUI() # 实例化gui对象
(3)屏幕显示图片和文字
之后,我们在屏幕上显示背景图和初始时的对话信息。
- # 显示背景图片和文字
- img = gui.draw_image(w=240, h=320, image='bot-02zz.png')
- text_value = gui.draw_text(x=20, y=15, w=150, color="red", text="按下按键说话",font_size=10)
- text_value_2 = gui.draw_text(x=40, y=82, w=180, color="red", text="你好呀!",font_size=10)
(4)智能对话机器人ID和接口参数
由于我们通过百度的智能对话平台来实现语音对话功能,因此,在这里,我们需补充设置相应的机器人ID和智能对话接口参数。
- service_id='' # 智能对话机器人ID
- '''智能对话接口参数'''
- APP_ID1 = "" # 引号内填写账号的APP_ID
- API_KEY1='' # 引号内填写账号的API_KEY
- SECRET_KEY1='' # 引号内填写账号的SECRET_KEY
(5)定义语音转字符函数
之后,为了能将我们说的话播报出来,我们需要先将我们的语音转换成文字,因此,我们需要补充定义一个语音转字符的功能函数。
- # 定义语音转字符函数,输入语音文件文件名,反馈一个识别内容(打印内容自选)
- def audio_to_text(pcm_file):
- client = AipSpeech (APP_ID, API_KEY, SECRET_KEY) # 创建一个客户端对象,连接百度云平台
- # 打开语音文件并读取,读取信息存入file_context
- with open(pcm_file,'rb') as fp:
- file_context = fp.read()
- # 向百度云发出请求,百度云反馈字典格式信息(1536、1537可修改,变化不大)
- res = client.asr (file_context, 'pcm', 16000, {'dev_pid': 1537, })
- try:
- res_str = res.get ("result") [0] # 获取信息中的文本内容
- print('语音转文字成功:',res_str) # 只打印关键的语音文本信息
- return res_str # 返回该文本信息
- except Exception: #(大部分错误是清晰度问题,具体请查看《https://cloud.baidu.com/doc/SPEECH/s/sk38lxie0》)
- print ('语音转文字失败,请注意语言清晰度')
- print ('错误信息:',res) # 打印所有反馈信息,主要用于检查有无错误(包含错误码等等)
(6)语音对话
最后,我们在按下按键录制完语音后,将说的话以文字形式呈现在屏幕上,随后,由于我们已经将获取机器人回答这个功能写在了get_f1库中,因此,在这里,我们直接调用get_f1库下的get_f功能函数,并传入三个接口参数和说话的文本内容,即可获取机器人的回答,之后将其显示在屏幕上并进行语音播报。
- while True:
- if button_a.is_pressed(): # 如果按下板载按键a
- print("开始录音3秒")
- text_value_2.config(text = "我在听")
- audio.record("record.wav",3) # 录音3秒
- print("正在转换")
- text_value_2.config(text = "我在识别")
- res_str=audio_to_text("record.wav") # 调用函数将录音发出,云端反馈文本并打印
- text_value.config(text= res_str) # 显示识别结果
- text_value_2.config(text = "识别完了")
- F = get_f1.get_f(res_str,service_id,API_KEY1,SECRET_KEY1) # 连接智能对话平台并获取返回的信息
- b = F
- text_value_2.config(text = b) # 显示对话结果
- print(b)
- audio.play(text_to_audio(F,APP_ID, API_KEY, SECRET_KEY)) # 生成音频文件并播放
Tips:完整示例程序如下:
- #!/usr/bin/env python3
- # -*- coding: utf-8 -*-
- '智能对话、语音识别、语音合成,按下按键开始录音,等待自动返回对话信息并播报'
-
- import time # 导入time库
- import get_f1 # 导入get_f1库
- from unihiker import Audio, GUI # 导入unihiker库Audio、GUI模块
- from aip import AipSpeech # 导入百度语音库
- from pinpong.board import Board,Pin # 导入pinpong库
- from pinpong.extension.unihiker import *
-
- Board().begin() # 主板初始化
-
- audio = Audio() # 实例化音频
- gui = GUI() # 实例化gui对象
-
- # 显示背景图片和文字
- img = gui.draw_image(w=240, h=320, image='bot-02zz.png')
- text_value = gui.draw_text(x=20, y=15, w=150, color="red", text="按下按键说话",font_size=10)
- text_value_2 = gui.draw_text(x=40, y=82, w=180, color="red", text="你好呀!",font_size=10)
-
- '''定义连接百度智能对话平台和语音平台所需接口参数(类似于密钥)'''
- service_id='' # 智能对话机器人ID
- '''智能对话接口参数'''
- APP_ID1 = "" # 引号内填写账号的APP_ID
- API_KEY1='' # 引号内填写账号的API_KEY
- SECRET_KEY1='' # 引号内填写账号的SECRET_KEY
- '''语音识别、语音合成接口参数'''
- APP_ID = "" # 引号内填写账号的APP_ID
- API_KEY='' # 引号内填写账号的API_KEY
- SECRET_KEY=''# 引号内填写账号的SECRET_KEY
-
- # 定义语音转字符函数,输入语音文件文件名,反馈一个识别内容(打印内容自选)
- def audio_to_text(pcm_file):
- client = AipSpeech (APP_ID, API_KEY, SECRET_KEY) # 创建一个客户端对象,连接百度云平台
- # 打开语音文件并读取,读取信息存入file_context
- with open(pcm_file,'rb') as fp:
- file_context = fp.read()
- # 向百度云发出请求,百度云反馈字典格式信息(1536、1537可修改,变化不大)
- res = client.asr (file_context, 'pcm', 16000, {'dev_pid': 1537, })
- try:
- res_str = res.get ("result") [0] # 获取信息中的文本内容
- print('语音转文字成功:',res_str) # 只打印关键的语音文本信息
- return res_str # 返回该文本信息
- except Exception: #(大部分错误是清晰度问题,具体请查看《https://cloud.baidu.com/doc/SPEECH/s/sk38lxie0》)
- print ('语音转文字失败,请注意语言清晰度')
- print ('错误信息:',res) # 打印所有反馈信息,主要用于检查有无错误(包含错误码等等)
-
-
- # 定义字符转语音函数,输入字符串文本,生成并反馈一个后缀为MP3的文件名
- def text_to_audio(res_str,APP_ID, API_KEY, SECRET_KEY):
- synth_file = "synth.mp3" # 音频文件保存名
- client = AipSpeech (APP_ID, API_KEY, SECRET_KEY) # 连接百度AI语音合成平台
- # synthesis参数: 文本,语言zh(中文),1为pc端,语音{"vol":音量,
- #"spd":语速,"pit":语调,"per":声道(0:女,1:男,2:逍遥音,4:小萝莉)}
- synth_context = client.synthesis(res_str, "zh", 1, {
- "vol": 5,
- "spd": 5,
- "pit": 3,
- "per": 0
- }) # 合成语音
- with open(synth_file, "wb") as f: # 打开音频文件
- f.write(synth_context) # 写入结果
- print("文字转语音成功,文件名:",synth_file)
- return synth_file # 返回音频文件
-
- while True:
- if button_a.is_pressed(): # 如果按下板载按键a
- print("开始录音3秒")
- text_value_2.config(text = "我在听")
- audio.record("record.wav",3) # 录音3秒
- print("正在转换")
- text_value_2.config(text = "我在识别")
- res_str=audio_to_text("record.wav") # 调用函数将录音发出,云端反馈文本并打印
- text_value.config(text= res_str) # 显示识别结果
- text_value_2.config(text = "识别完了")
- F = get_f1.get_f(res_str,service_id,API_KEY1,SECRET_KEY1) # 连接智能对话平台并获取返回的信息
- b = F
- text_value_2.config(text = b) # 显示对话结果
- print(b)
- audio.play(text_to_audio(F,APP_ID, API_KEY, SECRET_KEY)) # 生成音频文件并播放
Tips:须在程序中填入智能对话机器人的ID,智能对话平台APP_ID1、API_KEY1、SECRET_KEY1三个接口参数以及语音平台的三个接口参数。其中,智能对话平台接口参数和机器人的ID获取方式可参考附录2。
4、程序运行
STEP1:连接网络
STEP2:远程连接行空板并运行
STEP3:录制语音观察效果
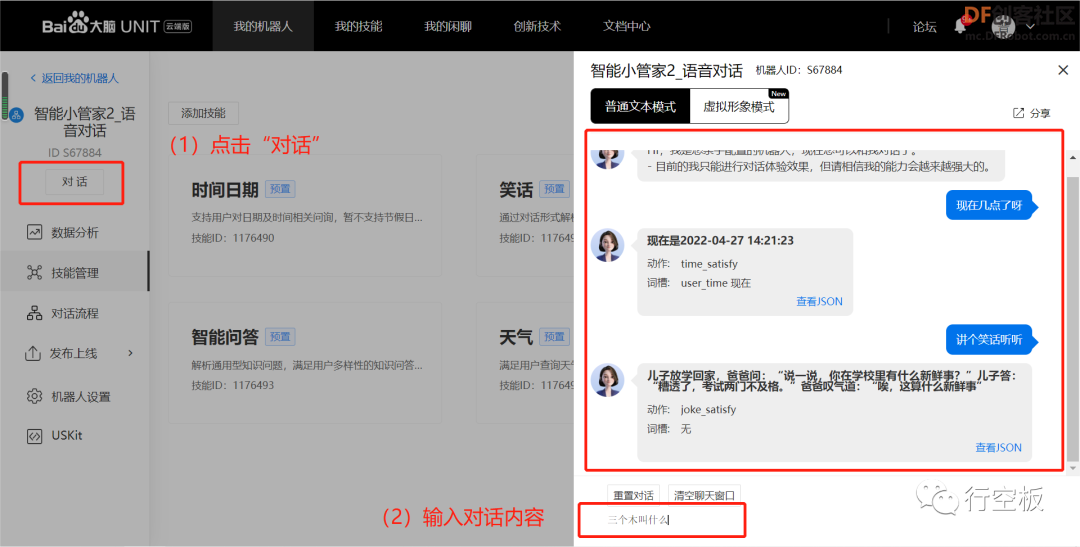
按下板载按键a,口述“现在几点了”,向聊天机器人小空询问时间,可以听到它很快以语音播报的形式回答了我们,同时在屏幕上也能看到我们对话的内容。
再用同样的方式让小空讲笑话和作诗,可以发现它依旧快速地得回复了我们。
Tips:须在UNIT平台上给机器人分配好相应的技能方可实现效果。
挑战自我
1、改变合成语音时的音量、语速、语调以及音调相关的参数,试一试效果,看看哪一种声音更合你的口味呢?
2、对于可以与我们对话的聊天机器人,你还想和它说什么呢,结合我们在百度智能对话平台选的技能,自己逐一体验一番吧!
3、在给机器人分配技能时,我们选择的是百度UNIT平台已有的技能,尝试依据自己的喜好,自定义一些技能,分配给机器人吧!
4、将上节课智能小管家的功能和聊天机器人结合一下,进一步提升小空的技能试试吧!
附录
附录1:背景图链接
链接:
https://pan.baidu.com/s/1G2O_j4K7q_Tbubdg9ezwNQ
提取码:kkn5
附录2:百度智能对话接口参数与机器人ID获取
STEP1:进入百度云网站,并登录
点击进入下列网站:https://cloud.baidu.com/
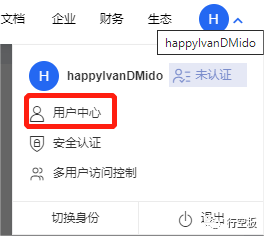
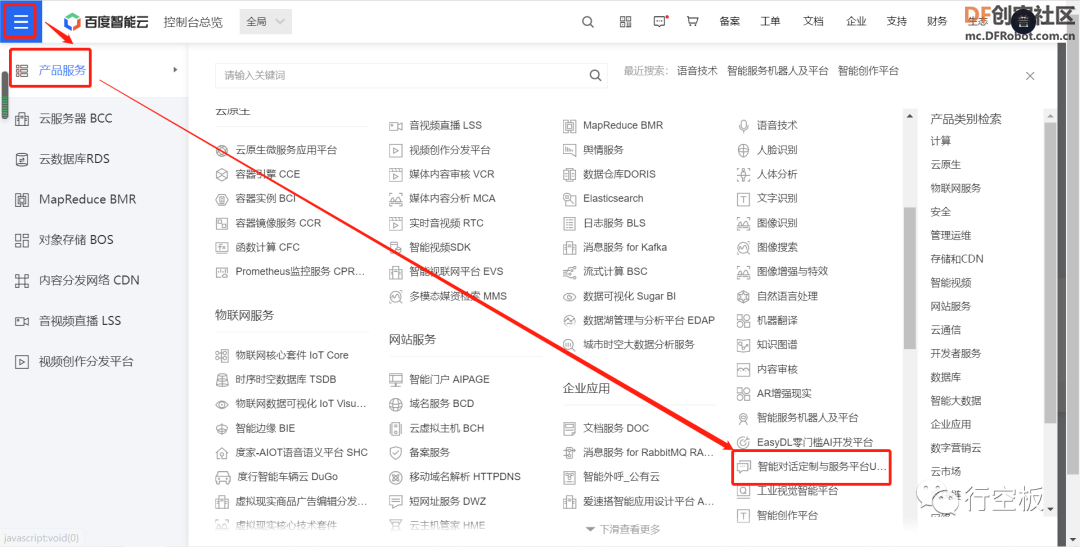
STEP2:进入智能对话平台
登录成功后,在右上角个人账号中先点击“用户中心”,再点击左上角的,找到“产品服务”中的“智能对话定制与服务平台UNIT”,并点击进入。
Tips:UNIT是百度用于实现智能对话定制与服务的平台,基于它,开发者可以高效、低成本的搭建对话系统,从而为用户提供智能客服、智能家居等场景下的服务咨询、业务办理等服务。
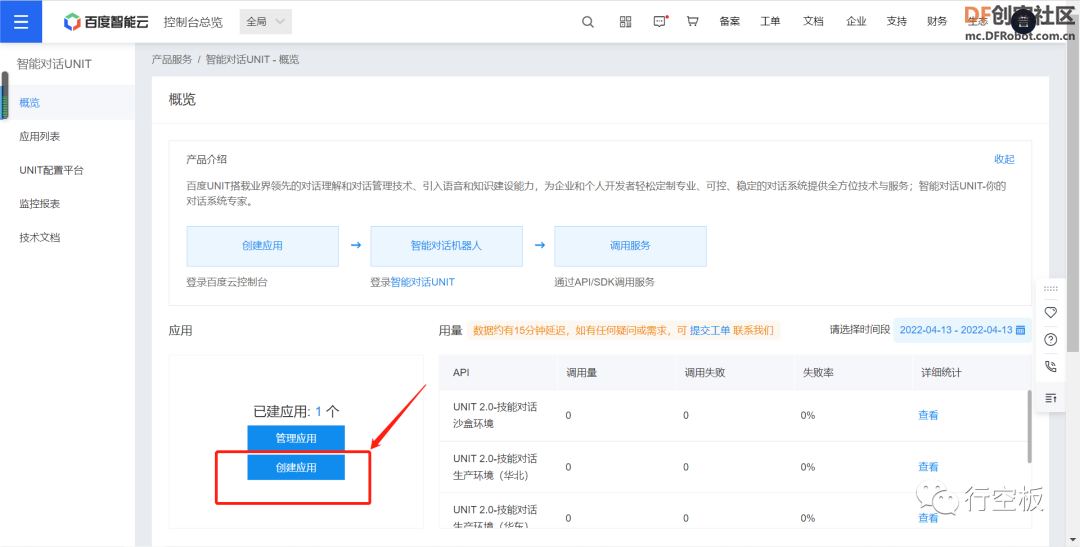
STEP3:创建应用
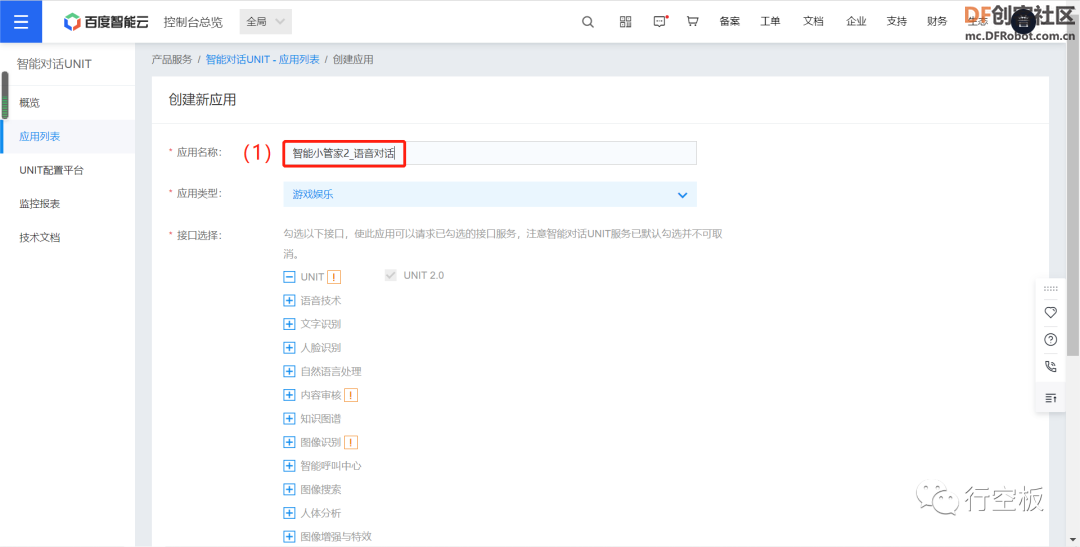
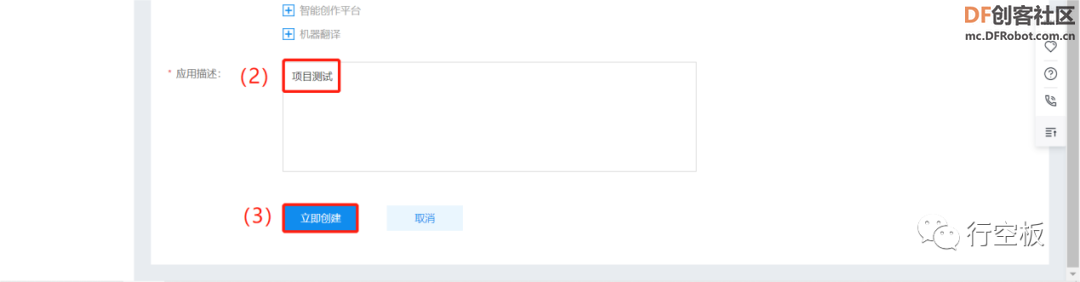
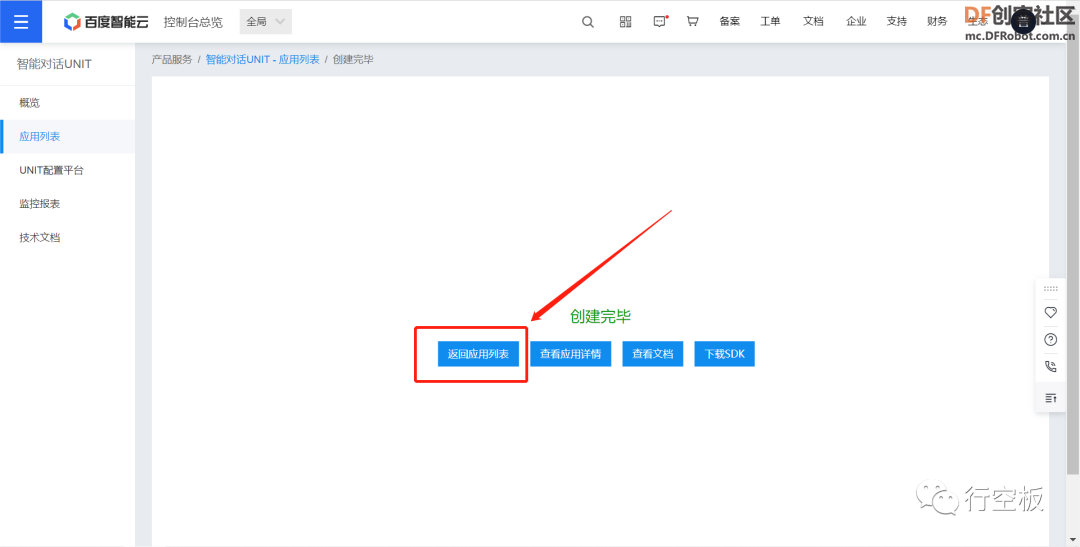
在新页面中点击“创建应用”,应用名称和应用描述任意填写。
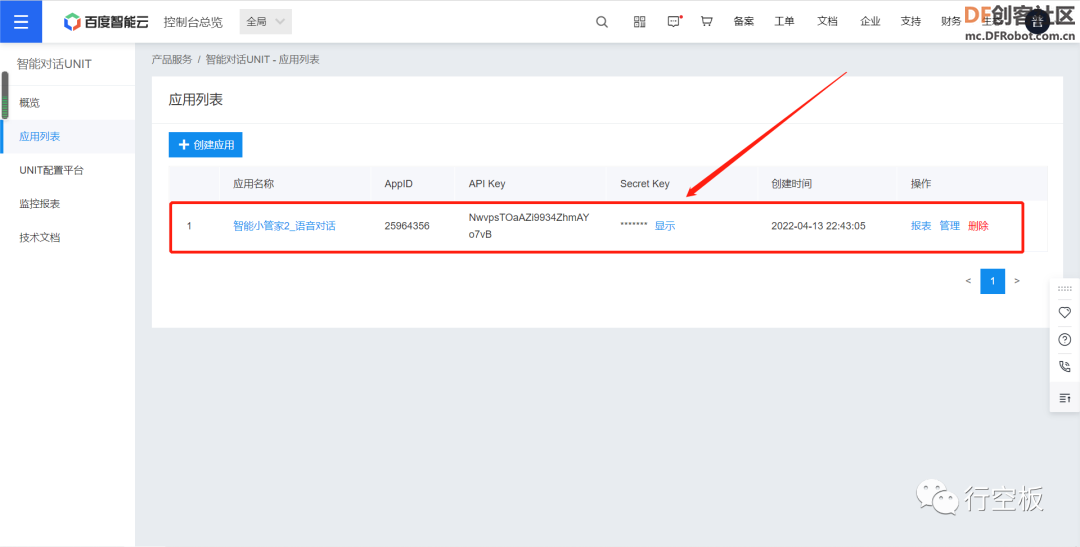
STEP4:记录接口参数
创建好应用后,点击“返回应用列表”,找到我们创建的应用后,我们需要记录下生成的三个智能对话接口参数APP_ID、API_KEY、SECRET_KEY,以便后续在程序中连接百度智能对话平台时能够使用。
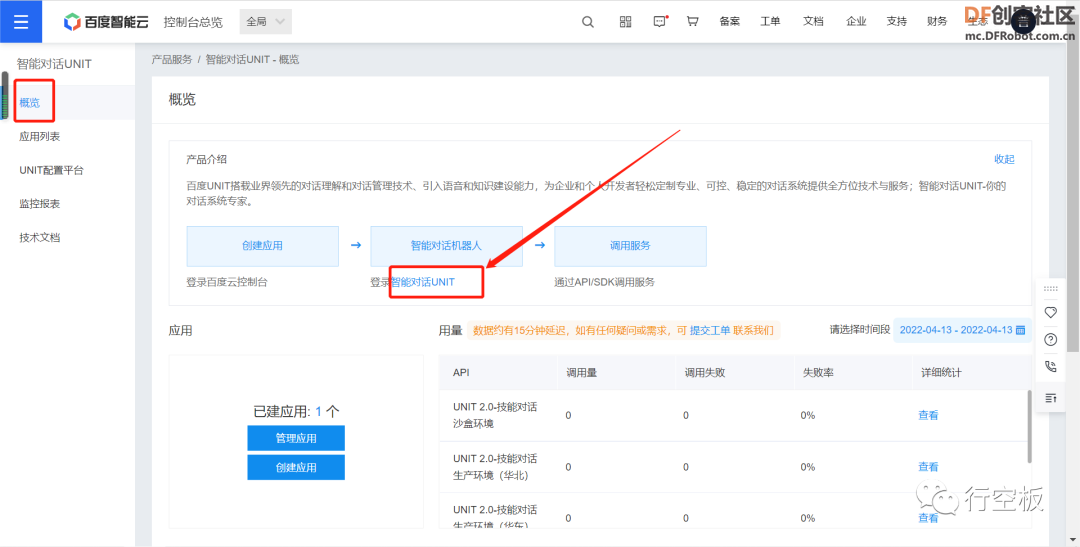
STEP5:进入智能对话UNIT
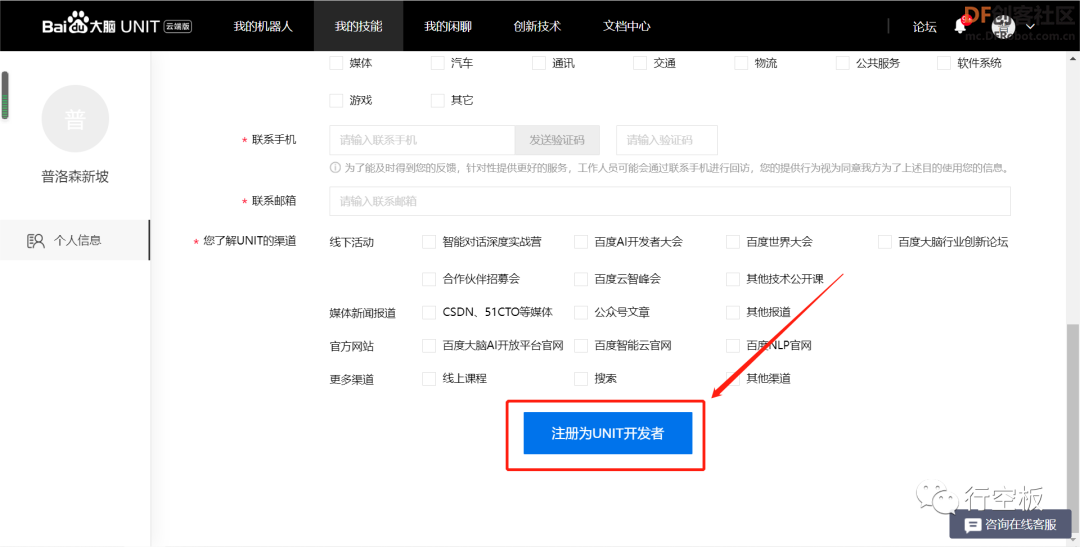
返回概览,进入“智能对话UNIT”,输入个人信息后注册为UNIT开发者。
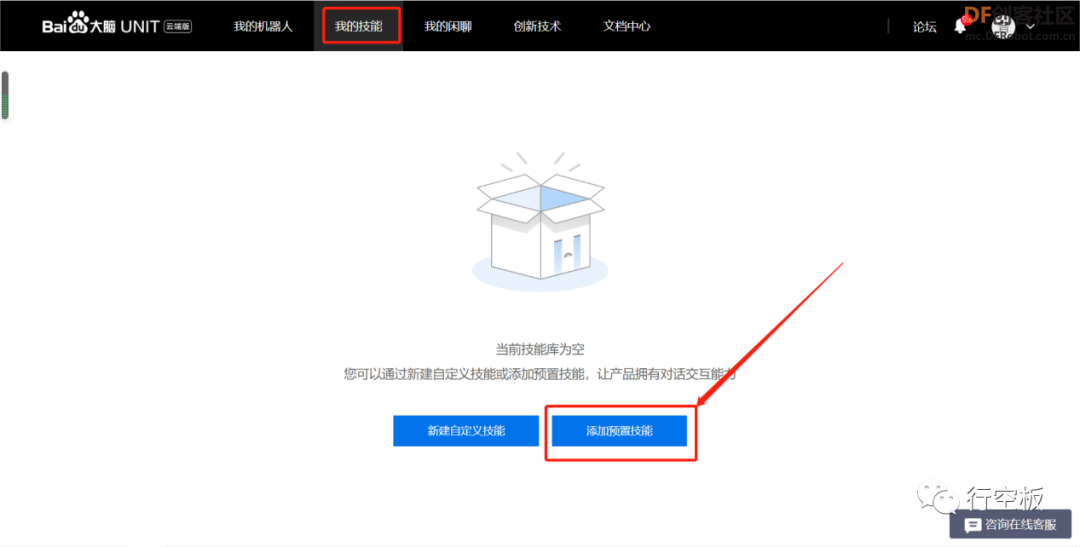
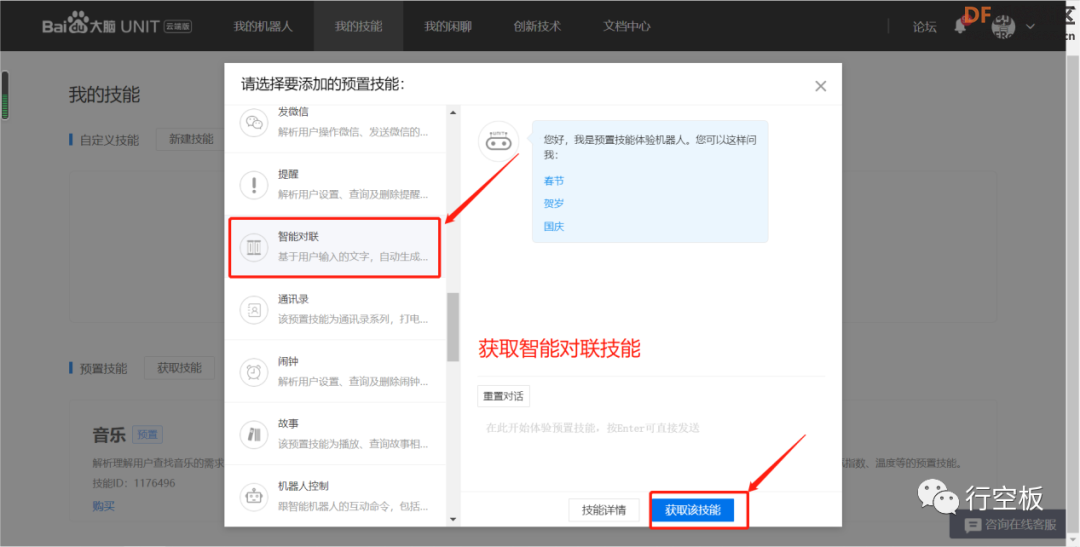
STEP6:获取技能
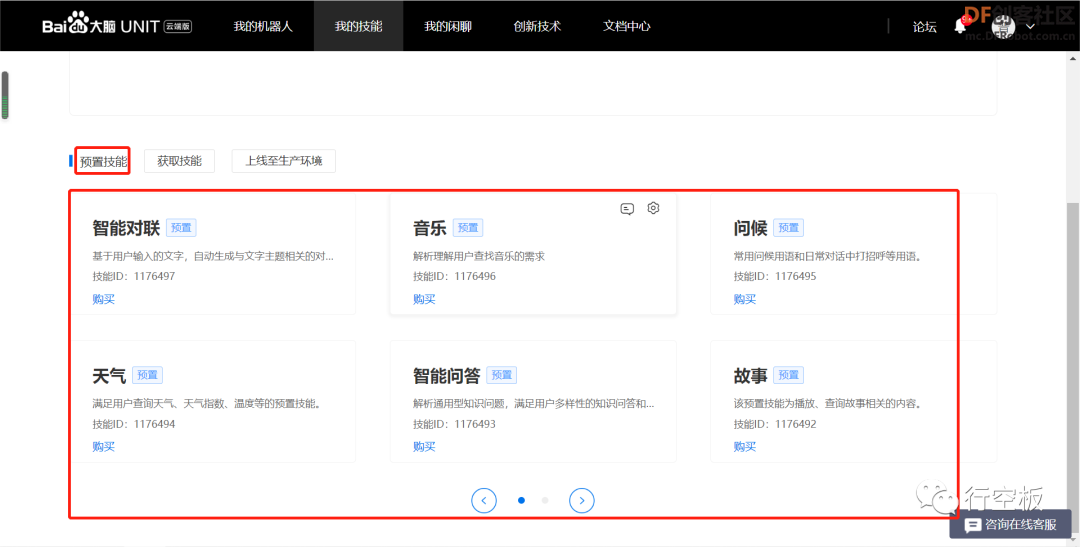
点击“我的技能”,添加预置技能,先后将需要用的“问候”、“天气”、“智能问答”、“故事”、“智能对联”、“日期时间”、“笑话”等技能都点击获取一下,视个人需求而定,也可全部获取。
关闭弹窗后,可在预置技能中见到已获取的技能。
Tips:UNIT平台包含了四个功能:机器人、技能、对话管理、对话部署
其中,机器人是业务系统中与用户进行对话交互的模块。我们可以理解为就是和我们对进行话交流的对象。每个机器人都可以为用户提供多项服务。比如,小度音箱就是一个机器人,它可以为用户提供订车票,听音乐等多项服务。
技能就是机器人为用户在特定场景下提供专项服务的内在能力。比如小度音箱中,订车票、听音乐服务就是两个技能。UNIT为开发者提供了预置技能和自定义技能。预置技能是UNIT平台为大家准备的即拿即用的技能,一键获取即可实现某一场景下的对话能力。自定义技能则是用户依据自身需求来设定技能,UNIT中包括对话技能、FAQ问答技能、对话式文档问答技能、表格问答技能四种。
对话管理为开发者提供了便捷的对话中控服务,仅需将技能添加到机器人中,机器人即可自动将用户对话分发给对应的技能进行回复。
对话部署是使机器人实现对话的关键步骤。技能需要训练并部署到研发或生产环境后,才能进行对话使用。UNIT为开发者提供了两种接入方式:对话API、一键接入微信公众号。我们在这里使用的就是API接入的方式。
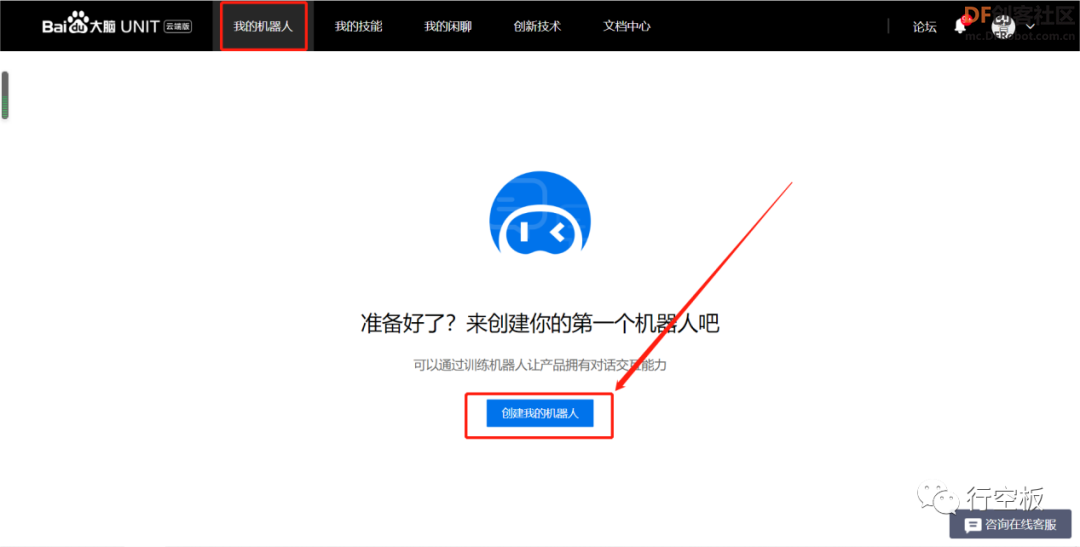
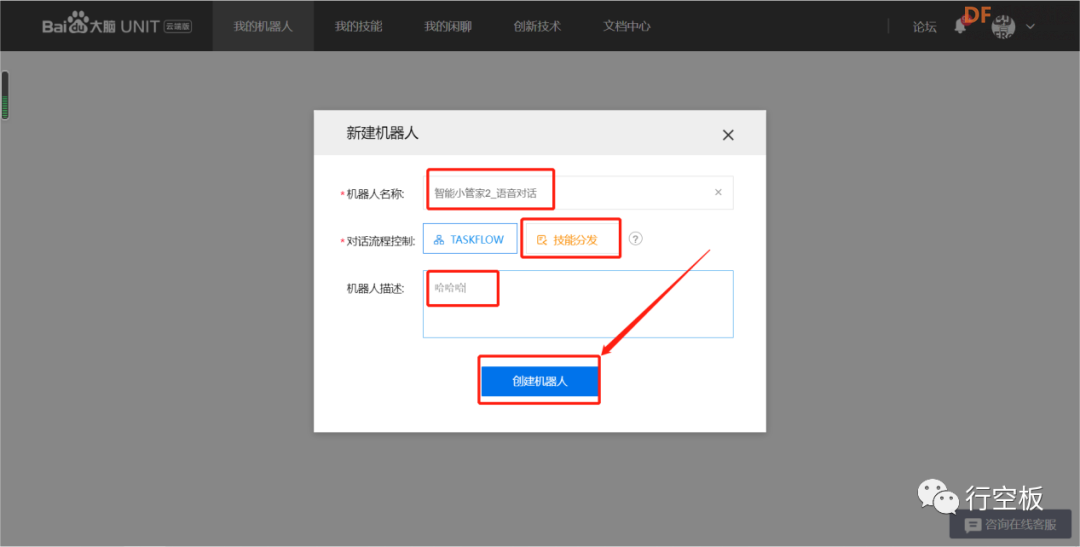
STEP7:创建对话机器人
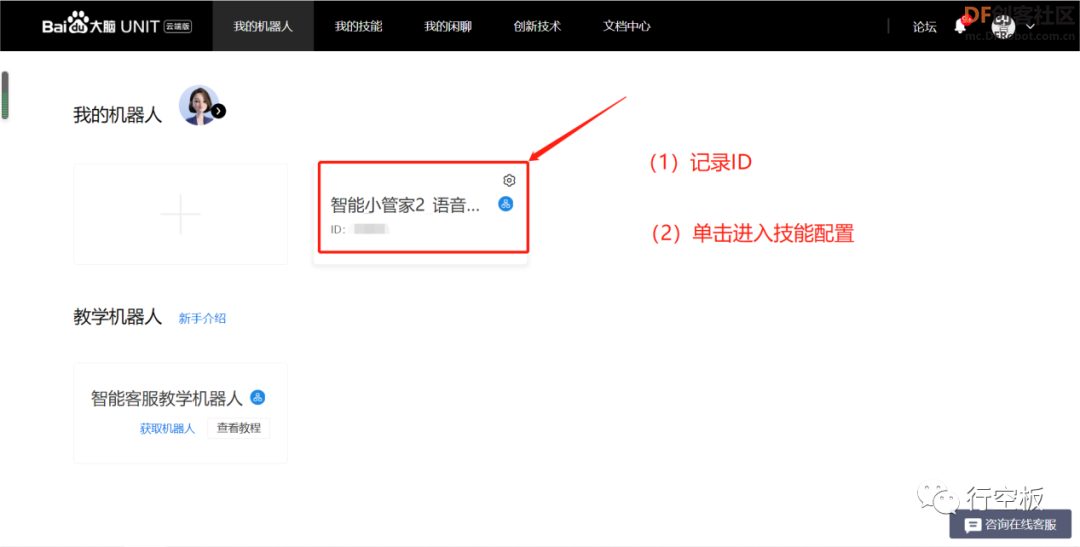
STEP8:记录对话机器人ID号并给它分配预置技能
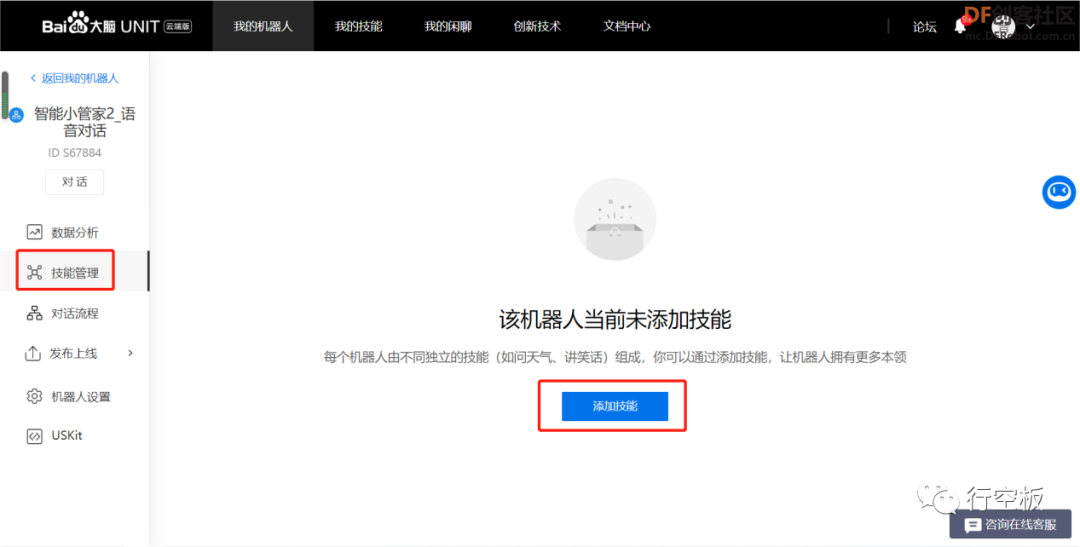
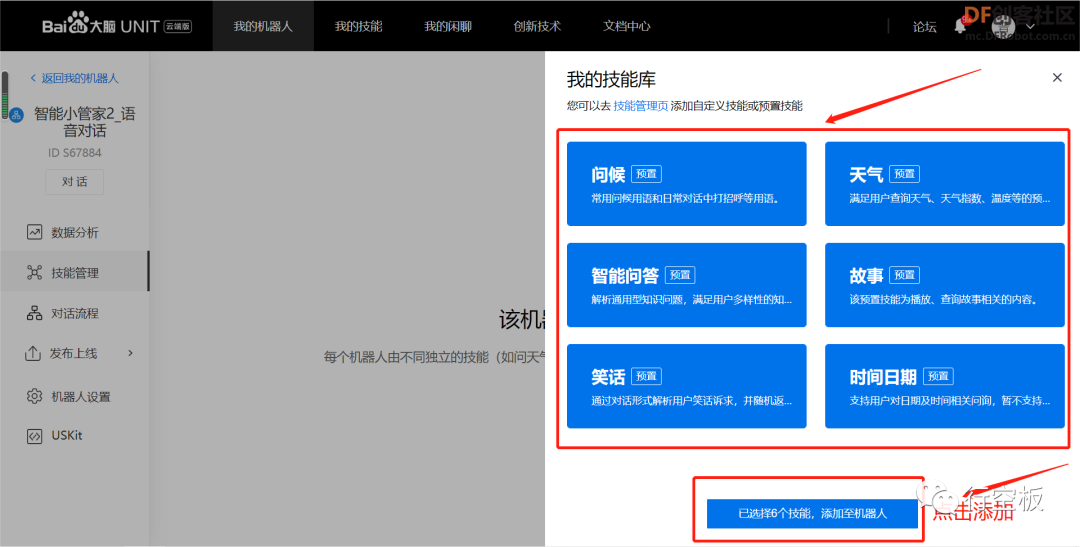
点击“添加技能”后,在弹出的技能库中选择各个技能,将其添加至机器人中。
STEP9:分配好预置技能后点击“对话”按钮测试效果
Tips:随着百度云网站的更新,上述步骤可能略有调整,但整体思路可不变,即先获取智能对话的接口参数,之后再创建智能对话机器人记录其ID,并给它分配好相应的技能。
|











 沪公网安备31011502402448
沪公网安备31011502402448

 置顶卡
置顶卡 变色卡
变色卡 千斤顶
千斤顶




 萌萌哒新人
萌萌哒新人
 活跃会员
活跃会员
 宣传大使
宣传大使
 志“童”道合
志“童”道合
 编辑选择奖
编辑选择奖






