|
46490| 0
|
[教程] 如何在Raspberry Pi树莓派5上部署运行大语言模型(LLaMA、LLaMA... |

本文将介绍如何在树莓派 Raspberry Pi 5 8GB上部署和运行最近流行的LLM(大语言模型),包括LLaMA、LLaMA2、Phi-2、Mixtral-MOE和mamba-gpt。 相比树莓派 4B 型,树莓派5在处理器、内存等方面都有升级,导致性能和效果上存在一些差异。 我们将比较这些LLM在运行速度、资源占用和模型性能方面的差异,帮助您选择适合您需求的设备,并为在硬件资源有限的情况下研究AI提供参考。 同时,我们还将讨论关键步骤和事项,以便您体验和测试LLM在树莓派 Raspberry Pi 5上的运行性能。树莓派5/4硬件规格对比图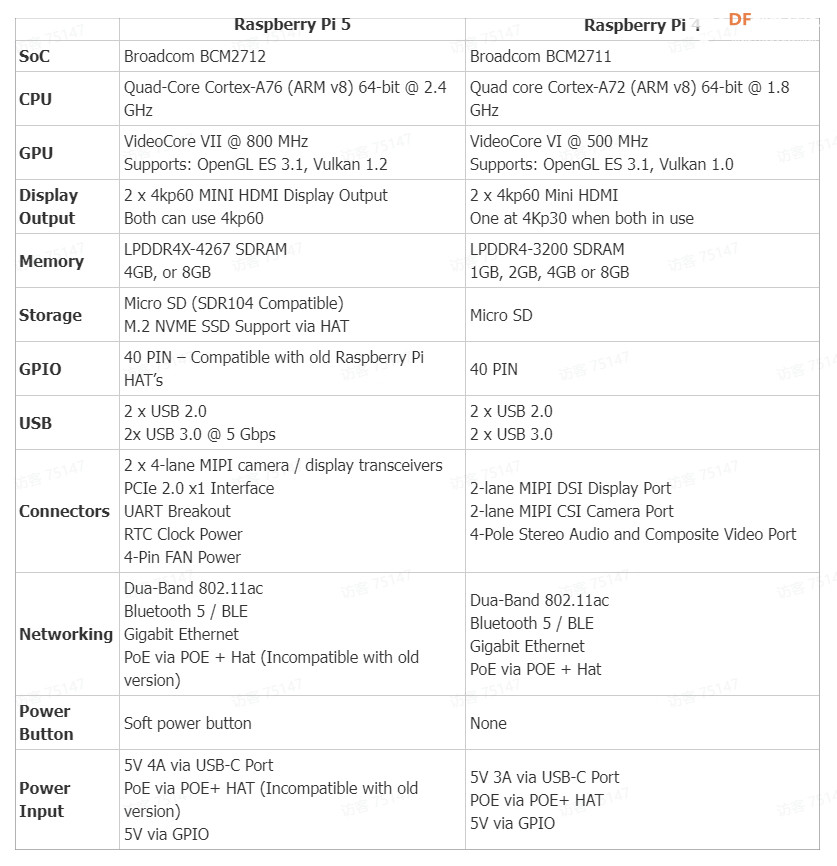 树莓派5/4B性能测评对比图(Benchmark)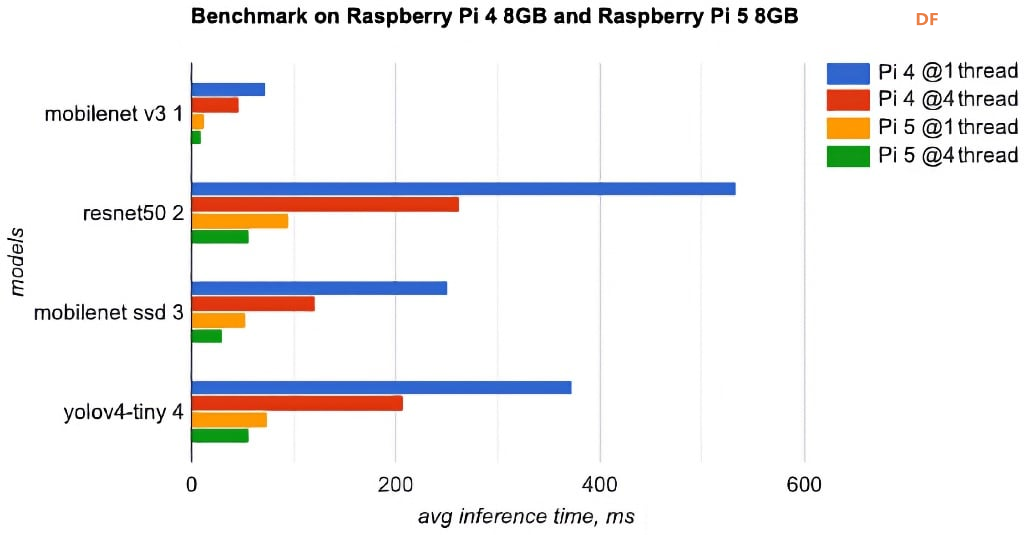 如何选择LLM大语言模型通常会在项目要求中提出对CPU/GPU的前提需求,由于树莓派5上暂时无法使用GPU推理LLM,我们需要优先选择支持CPU运行的模型。在模型的选择上,由于树莓派5的RAM限制,我们需要优先考虑较小内存的模型。一般情况下,模型需要双倍内存大小的RAM才可以正常运行,被量化的模型对内存要求较低,所以我们推荐使用8GB的树莓派5和量化过的小体量模型来体验和测试LLM在树莓派上的运行效果。 以下列表是从Huggingface网站上的open_llm_leaderboard中选出体量较小的模型,以及最新的热门模型。 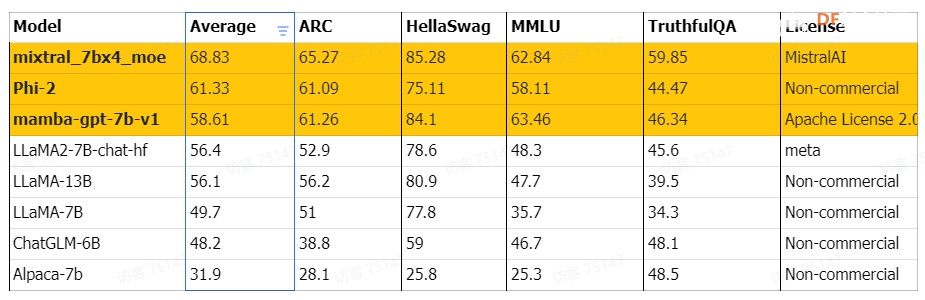 如何跑LLM经测试,由于树莓派5上暂时无法使用GPU推理LLM,我们暂时使用LLaMA.cpp和树莓派5的CPU推理各个LLM。以下用phi-2为例,详细指导您如何在拥有8GB RAM的树莓派5上部署并运行LLM。同时,我们也会探讨其关键步骤和需要注意的事项,以便于您能更快速地体验和测试LLM在树莓派5上的运行性能。 PS:如果想体验Mixtral_moe,请参考:https://github.com/ggerganov/llama.cpp/tree/mixtral 环境部署
 模型量化模型量化旨在通过降低深度神经网络模型中每个神经元的权重参数的准确性来降低硬件需求。 GGUF 是一种常用的量化方法,允许您在 CPU 或 CPU + GPU 上运行 LLM。 一般来说,位数越少、量化越多,模型就会越小、速度越快,但代价是准确性。 例如,Q4是GGUF模型文件的量化方法,表示使用4位整数来量化模型的权重。 树莓派5的8GB RAM不太适合量化模型,我们建议在Linux PC上量化过后,把量化过的文件拷贝到树莓派上部署。 您也可以直接在Huggingface上搜索已经量化过的GGUF模型文件,并使用LLaMA架构快速体验模型的效果。 下载后的模型文件放在llama.cpp-phi/models/里  模型运行在树莓派5的终端运行指令: 结果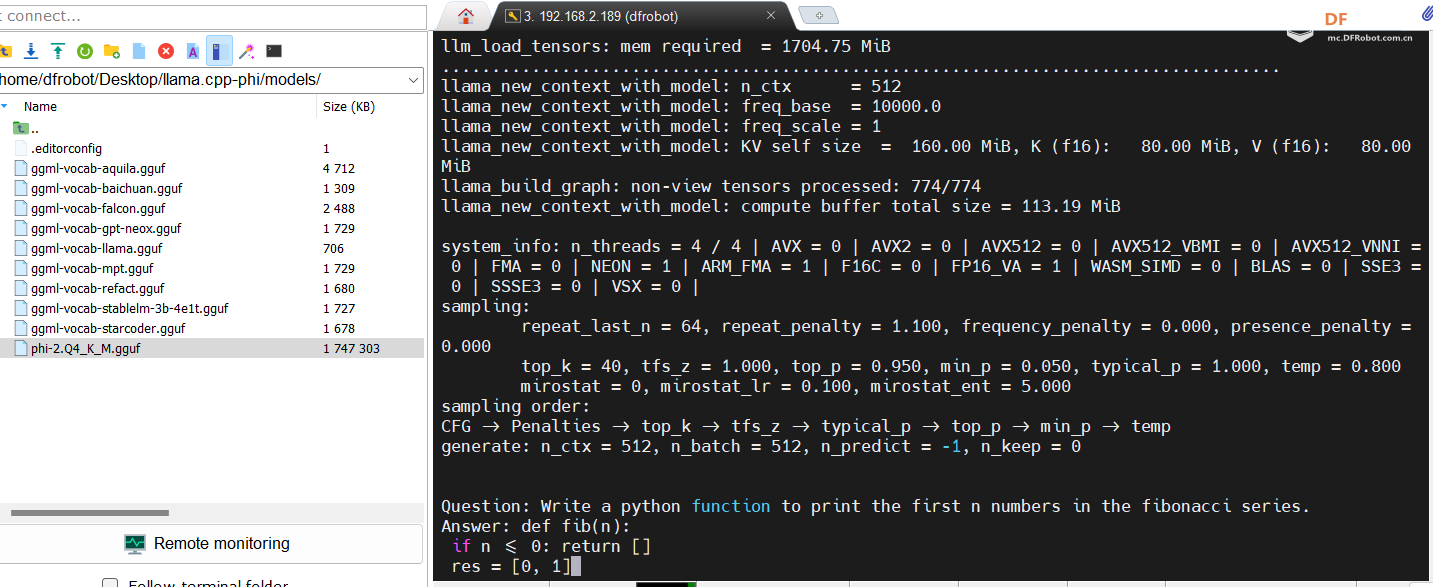 
总结8GB 树莓派5和LLM的测试表格 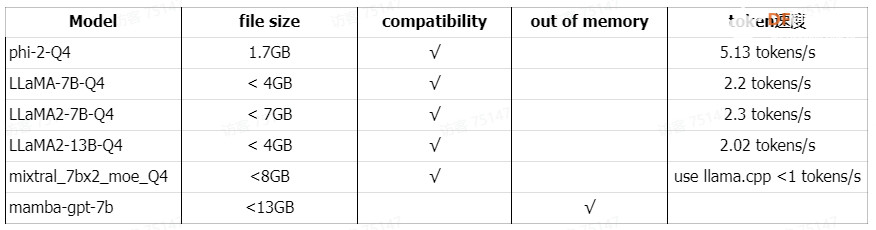 8GB 树莓派4B和LLM的测试表格 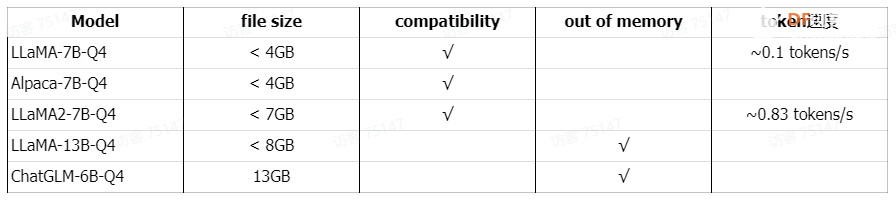 通过分析上表,我们不难发现,LLM在树莓派5上的运行速度相较于树莓派4B有了显著的提升。[在树莓派4B上部署运行大语言模型 (LLaMA, Alpaca, LLaMA2, ChatGLM] 这表明树莓派5具有更强大的处理能力。而作为资源有限设备设计的phi-2-Q4,其表现尤为出色,eval time速度达到了5.13 tokens/s,这无疑证明了其在处理速度上的卓越性能。 除了phi-2-Q4的出色表现,LLaMA-7B-Q4、LLaMA2-7B-Q4和LLaMA2-13B-Q4在树莓派5上的运行效果也令人满意。然而,我们必须指出,对于超过8GB的LLM,树莓派5在加载模型方面仍然存在局限性,这凸显了其RAM容量的限制。 对于需要更高性能的LLM应用,LattePanda Sigma是一个值得考虑的选择。在运行LLaMA2-7B-Q4时,其速度可以达到惊人的6 tokens/s。[在LattePanda Sigma上部署运行大语言模型] 总体而言,树莓派5在处理速度上相较于前代有了显著提升,但在处理大型LLM时仍需考虑其RAM容量的限制。而LattePanda Sigma则提供了更高的性能以满足对LLM有更高要求的应用场景。 综上所述,尽管树莓派5在处理速度上相较于树莓派4B有了显著提升,但在处理大型LLM时仍存在一定的局限性。这为未来技术的发展提供了新的挑战和机遇。 参考1. 在树莓派4B上部署运行大语言模型(LLaMA, Alpaca, LLaMA2, ChatGLM) 2. 在LattePanda Sigma上部署运行大语言模型(LLaMA, Alpaca, LLaMA2, ChatGLM) 附件下载下载地址: 链接:https://pan.baidu.com/s/1kkrx8G5rjlrYpVGd2rgRTw?pwd=av5p 提取码:av5p |



 沪公网安备31011502402448
沪公网安备31011502402448© 2013-2026 Comsenz Inc. Powered by Discuz! X3.4 Licensed


 置顶卡
置顶卡 变色卡
变色卡 千斤顶
千斤顶
 萌萌哒新人
萌萌哒新人
 活跃会员
活跃会员
 宣传大使
宣传大使
 志“童”道合
志“童”道合
 编辑选择奖
编辑选择奖






