本帖最后由 czeva18 于 2024-9-16 09:34 编辑
自助视力测试仪 十分有幸参加行空板双路电机驱动I/O扩展板试用活动,此产品专为行空板(UNIHIKER)开发适配的扩展板。就是下面这个。试用有提交试用报告的要求,行空板其实我已经用了大半年的时间了,在行空板上也测试了几个项目,但是一直不想写项目报告。也正好借试用这个机会,逼迫一下自己系统的写一篇项目的报告,也是对自己做的项目做一个记录。
[size=12.0000pt]一、对行空板的一些看法 先说一下对行空板使用下来的一些体会,可能不全,都是些个人的体会 先说优点: [size=12.0000pt]1、linux核心(类似于低性能电脑,可以使用pip下载库) [size=12.0000pt]2、内置jupyter notebook [size=12.0000pt]3、Pinpong库是真的挺方便的 [size=12.0000pt]4、显示屏够大 [size=12.0000pt]5、接口和扩展还是比较方便的 再说缺点; [size=12.0000pt]1、性能还是弱,特别内存太小512M,人工智能的模型稍大就崩。 [size=12.0000pt]2、掌控板的接口是特制的,不是杜邦线,不过加了这个扩展版就没问题了。 [size=12.0000pt]3、摄像头通过usb连接方便,但是真的不够优雅。
二、我的项目 项目名称:自助视力测试仪 项目由来:手机看的多了,视力感觉下降的厉害。测视力总要找个人指,不怎么方便。想做一个自己一个人就能测视力的工具。 项目原理:项目其实是分两部分,一部分是通过摄像头结合人工智能识别被测者的手势方向,另一部分是利用行空板,控制小灯在特定的位置点亮。通过判断手势和特定位置处的图标方向是否相同,判定被测者是否看清了图标,最终给出对应的视力数值。 项目还是一个半成品,有了扩展板,可以让屏幕部分更优雅一点,后续也能有更多的拓展方向,这个我在最后脑洞一下。
三、项目设计 1、手势识别 说到手势识别,如果在性能足够的前提下,google的mediapipe绝对是个不错的选择,有完整的历程,简单的使用,不错的效果。唯一的不好就是太需要资源了,我在可怜的行空板上,一跑就程序崩溃。
为了能实现手势识别,我采用了国产模型+数学方法,在行空板上成功的运行了,虽然还是有点慢,至少实现了效果。 1)关键点识别和物体识别 如上图,调用一个具有关键点识别模型,其实是可以把手部的一些重要关节标识出来,从而通过这些点的关系,确定你的手的指向,这其实是一个更好的,更准确的方法,只是性能不足,无法实现。 但是有另一种模型比关键点识别的系统开销要小,模型也更小,那就是人脸识别和手部识别模型。
因为系统只需要把图片或视频中的脸或者手的区域找到,不需要对脸和手的每个关键点进行识别,这样对系统的性能的要求会降低一大截。本项目的识别就是基于人脸和手部检测的,通过一种取巧的方式实现了识别。 2)模型来源 其实mediapipe也有检测模型,在这个项目中我使用了上海人工智能实验室的浦育平台的模型和代码(www.openinnolab.org.cn),浦育平台是一个人工智能实验的平台,平台提供算力,还有各种模型,教程也比较详细,适合初学者体验和有一定编程基础的做一些人工智能项目。不是广告,只是说明一下模型和代码的来源,因为后面要调用。
3)手势识别原理 首先说一下脸部识别
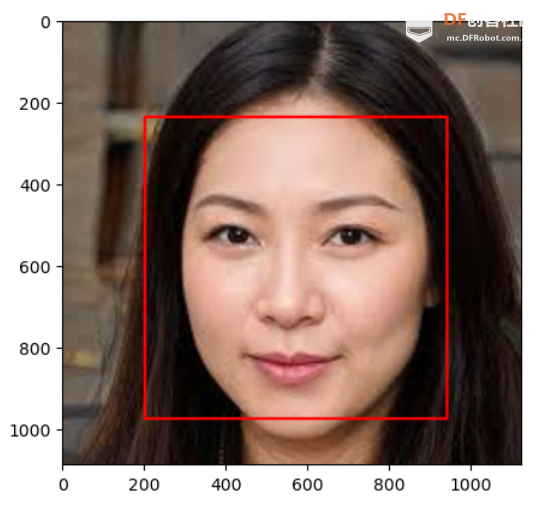
这个人脸检测的模型会以数组的形式保存了检测框左上角顶点的坐标(x1,y1)和右下角顶点的坐标(x2,y2)(因为模型可以检测多个人脸,所以输出时是以二维数组的形式输出的,在我们这个项目中不涉及多人,所以只取第0组),我们可以利用这四个数据计算出其他两个顶点的坐标,以及检测框的宽度和高度。那么,((x2-x1)/2,(y2-y1)/2)就是图片中人脸的中心点。 在确认人脸的中心点后,以这个点为中心,可以把平面区域划分成四个区域,分别是人脸上方,人脸下方,人脸左边,人脸右边。 file:///C:/Users/czeva/AppData/Local/Temp/ksohtml24704/wps9.pngfile:///C:/Users/czeva/AppData/Local/Temp/ksohtml24704/wps10.png
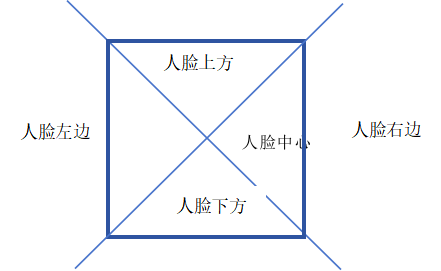
同样的,我可以用手部检测模型,找到手的中心点,然后就只需要判断手的中心点,在某个区域停留超过3帧,就认为你指向的是那个方向。 代码: 先导入必要的库
- from XEdu.hub import Workflow as wf
- import cv2
- import math
- from unihiker import GUI
- from PIL import Image
建立一个向量函数,建立一个从脸部中心点向手部中心点发射的向量,计算它与竖直方向的夹角 - def calculate_angle(x1, y1, x2, y2):
- """计算中心点连线向量与竖直方向的夹角"""
- vector_ab = (x2 - x1, y2 - y1)
- vertical_vector = (0, 1)
- dot_product = vector_ab[0] * vertical_vector[0] + vector_ab[1] * vertical_vector[1]
- magnitude_ab = math.sqrt(vector_ab[0]**2 + vector_ab[1]**2)
- magnitude_vertical = 1 # 竖直向量的模为1,因为(0,1)的长度是1
-
- cos_angle = dot_product / (magnitude_ab * magnitude_vertical)
- cos_angle = min(1, max(cos_angle, -1)) # 限制范围防止计算错误
-
- return math.acos(cos_angle) * (180 / math.pi)
利用opencv读入画面 加载浦育的脸部检测和手部检测的模型,加入的一个变量计算次数,通过相同判定的帧累加到超过阈值,来确定手势 - cap = cv2.VideoCapture(0)
- cap.set(cv2.CAP_PROP_FRAME_WIDTH, 240) # 设置摄像头的宽度
- cap.set(cv2.CAP_PROP_FRAME_HEIGHT, 320) # 设置摄像头的高度
- cap.set(cv2.CAP_PROP_BUFFERSIZE, 1) # 设置摄像头的缓冲区大小
-
- bgImg=gui.draw_image(image="",x=0,y=0)
- ltTxt=gui.draw_text(text="手势",x=100,y=100,font_size=28, color="#00FF00",angle = 90)
-
- #cv2.namedWindow('Video Feed', cv2.WND_PROP_FULLSCREEN)
- #cv2.setWindowProperty('Video Feed', cv2.WND_PROP_FULLSCREEN, cv2.WINDOW_FULLSCREEN) # 设置窗口为全屏
- det_face = wf(task='det_face')
- det_hand = wf(task='det_hand')
- num = 0
- prev_flag = None
判断过程 - while True:
- ret, img = cap.read()
- img = cv2.flip(img, 1)#水平镜像图片
-
- if not ret:
- break
-
- face_result, face_with_box = det_face.inference(data=img, img_type='cv2')
- hand_result, hand_with_box = det_hand.inference(data=face_with_box, img_type='cv2')
-
- if face_result != [] and hand_result !=[]:
-
- fx, fy = (face_result[0][0] + face_result[0][2]) / 2, (face_result[0][1] + face_result[0][3]) / 2
- hx, hy = (hand_result[0][0] + hand_result[0][2]) / 2, (hand_result[0][1] + hand_result[0][3]) / 2
- angle = calculate_angle(fx, fy, hx, hy)
-
- flag = ''
- if 30 < angle < 120:
- flag = 'left' if fx > hx else 'right'
- elif angle <= 30 or angle >= 120:
- flag = 'up' if fy > hy else 'down'
-
- if flag == prev_flag:
- num += 1
- else:
- num = 0
- prev_flag = flag
-
- if num >= 5:
- print(flag)
- ltTxt.config(text=flag)
- num = 0
- img = cv2.flip(img, 0)#垂直镜像图片
- img = cv2.rotate(img,cv2.ROTATE_90_CLOCKWISE) #旋转90度
- img= Image.fromarray(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))#将opecv图片格式转化为unihiker库图片格式
- bgImg.config(image=img)
推理出的脸部中心点与手部中心点向量与竖直方向的夹角,通过夹角的范围确定手势的方向。 其实原理和代码还是简单易懂的,并不复杂。这样,通过调用两个相对简单的模型,借助数学方法,在性能比较弱的设备上,实现了手势的识别。(当然,人的姿势是有些奇怪的)。
视频演示

2、视力测试表 这块相对简单,就是调用了pinpong库,只是因为图标比较多,所以灯珠比较多,接线也比较乱,密恐着慎看下图
这个面板,只用半边,其实就有60个LED灯珠,要让他们亮起来,还是比较简单的,可以理解为他们就是串联连接的,只用调用pinpong的neopixel类,就可以轻松依次点亮 - import time
- from pinpong.board import Board,Pin,NeoPixel #导入neopixel类
- Board().begin() #行空板初始化
- NEOPIXEL_PIN = Pin(Pin.D21) #接口为D9
- PIXELS_NUM = 60 #灯数60个
- np = NeoPixel(NEOPIXEL_PIN,PIXELS_NUM)
- while True:
-
- for i in range(60):
- np[i] = (255, 255 ,255) #设置第一个灯RGB亮度
- time.sleep(0.5)
- np.clear()
- time.sleep(0.5)
视频演示: 
当然,每5个为一组,从前到后,分别对应着12个不同的视力度数,然后在LED变化后,对比当前对应的LED位置对应的图标方向与手势的结果做对比,判断是否正确,如果正确就继续降低层级,如果错误就输出上一层级的视力度数。 - while True:
- ret, img = cap.read()
- img = cv2.flip(img, 1)#水平镜像图片
-
- if not ret:
- break
-
- face_result, face_with_box = det_face.inference(data=img, img_type='cv2')
- hand_result, hand_with_box = det_hand.inference(data=face_with_box, img_type='cv2')
-
- if face_result != [] and hand_result !=[]:
- arrow = det_arrow(face_result,han_result)
- test_result = test(de,arrow)
- if test_result == 1:
- right += 1
- wrong = 0 # 立即重置错误计数
- else:
- wrong += 1
- right = 0 # 立即重置正确计数
-
- # 判断是否需要升级或降级
- if right >= 3:
- last_valid_de = de # 更新上一个有效的难度级别
- de += 1
- right = 0 # 重置计数器
- if de > 12 or last_valid_de<de: # 如果级别超过最高级别
- print("达到最高级别")
- break
-
- if wrong >= 3:
- if last_valid_de != de: # 如果级别已经变化
- print(f"级别变化后错误累积到3次,退出。最终级别:{last_valid_de}")
- break
- last_valid_de = de # 更新上一个有效的难度级别
- de -= 1
- wrong = 0 # 重置计数器
- if de < 1 or last_valid_d>de: # 如果级别低于最低级别
- print("达到最低级别")
- break
-
这里把错误次数设定为3,正确就继续,错误就输出。 不过整个项目的逻辑还没设计完整,所以目前这个项目还是个半成品,仅供大家参考吧。 最后开个脑洞,视力测试表都是有固定距离的,比如我这个小的表,距离为2.5米,一般大的表是5米。现在行空板的扩展板上有自带的电机驱动设备。后续是不是可以做一个会跑的装置,重要有人启动系统,是不是可以参考下无人机的跟随算法,自动驱动设备远离人到规范距离,再开始测试,从而成为一个更智能的测试设备。
附件:手势检测的代码
| 







 沪公网安备31011502402448
沪公网安备31011502402448
 置顶卡
置顶卡 变色卡
变色卡 千斤顶
千斤顶






