|
42| 0
|
[M10项目] 行空M10小智AI的“新眼睛”:800万USB自动对焦摄像头适... |
|
【项目背景】 随着人工智能技术的飞速发展,智能语音助手已经走进了我们的生活。而小智AI作为一款开源的智能语音助手,以其强大的功能和高度的可定制性,吸引了众多爱好者。我手上有一块行空板M10开发板,之前实现了行空板M10运行小智AI,最近从DF商城购买了一个800万像素USB自动对焦摄像头(带麦克风),决定为行空M10小智AI安装一个“眼睛”,让它能够更好地感知世界。  在众多开源项目中,我选择了 py-xiaozhi (https://github.com/huangjunsen0406/py-xiaozhi)这个基于Python实现的小智语音客户端。它不仅支持语音交互、图像识别、智能家居设备控制等多种功能,还具备跨平台特性,能够很好地运行在行空M10上。此外,它的代码模块化设计也便于二次开发,这为我后续的适配工作提供了极大的便利。 py-xiaozhi的视觉分析的创新点在于将分析结果转换为用户输入的形式发送回小智AI服务器: 1. 检测关键词触发视觉分析 2. 暂停当前会话 3. 拍摄并分析图像 4. 将分析结果转换为音频 5. 将音频以用户输入的形式发送给小智AI服务器 6. 添加前缀标记防止循环触发 【适配过程】 (一)硬件连接 摄像头连接:将800万像素USB自动对焦摄像头插入行空M10的USB接口。该摄像头自带麦克风,因此无需额外连接麦克风设备。 行空M10电源连接:确保行空M10连接稳定的电源,以保证设备正常运行。 (二)软件适配 1. 禁用自定义唤醒词 由于行空M10的资源有限,为了降低系统负担,我决定禁用自定义唤醒词功能。在config/config.json文件中,将"USE_WAKE_WORD"设置为false。这样,小智AI将不再依赖唤醒词激活,而是通过手动触发屏幕按钮来启动交互。 2. 修改表情符号 行空M10的屏幕显示特性与原项目中的表情编码不兼容。display/gui_display.py 1.修改默认表情 因此,我修改了display/gui_display.py文件中的update_emotion函数,禁用了其它表情符号的编码,让小智AI在行空板M10上能正常运行。(大家可尝试解决表情符号的编码问题,能正常显示,而不像我这样禁用——注释掉。) 3. 适配GUI界面 为了更好地适配行空M10的屏幕大小和按钮位置,我对display/gui_display.py文件进行了修改。重新设计了界面布局,调整了按钮的大小和位置,使其更适合行空M10的操作方式。同时,优化了界面的显示效果,确保在行空板M10的屏幕上能够清晰地展示小智AI的交互信息。 Mind+python模式下的运行界面: 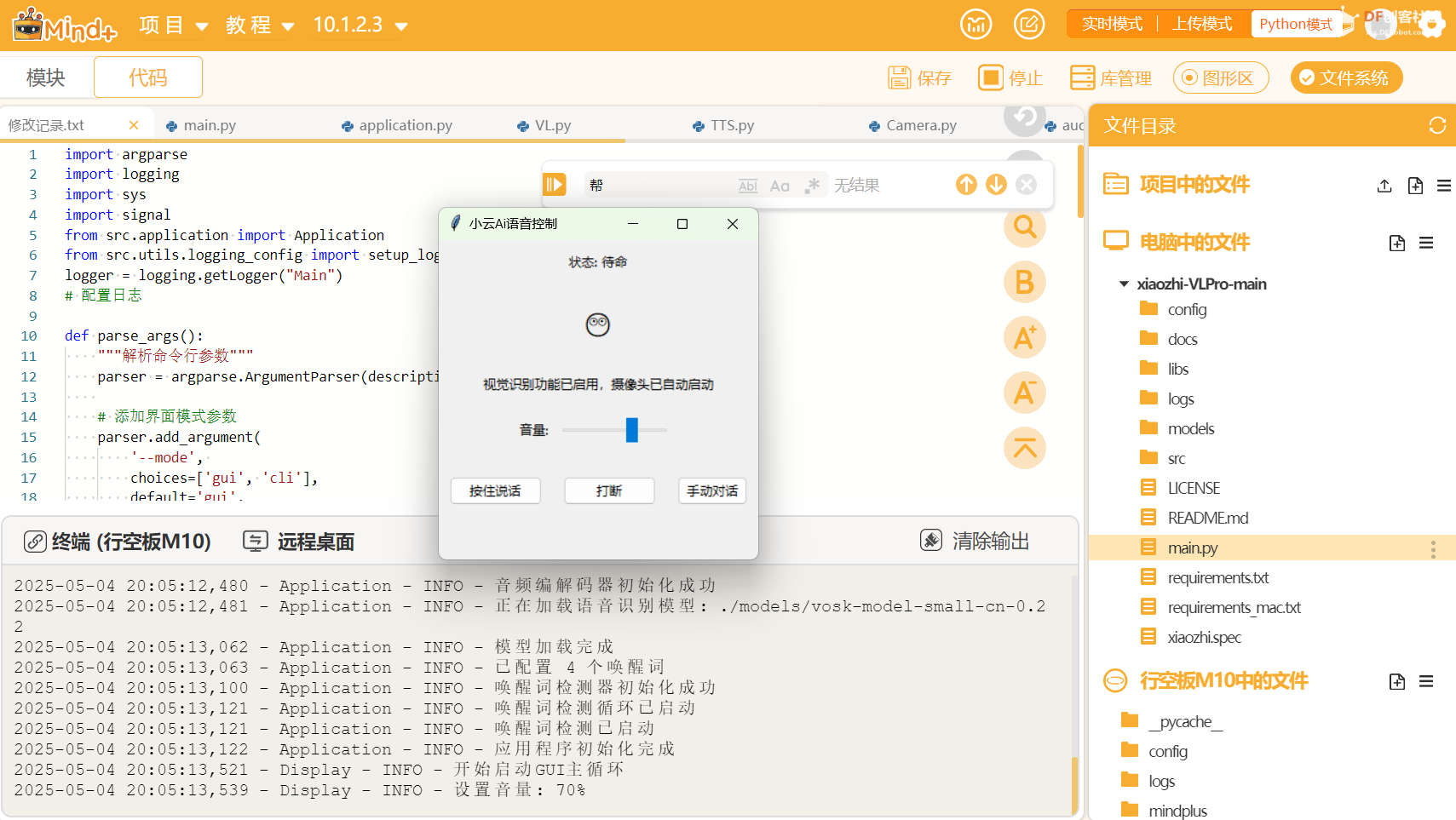 行空板M10运行界面:  部分关键代码: 4. 音量控制适配 行空M10的音量控制功能与原项目中的实现方式有所不同。为了实现音量控制,我引入了Mind+扩展中的行空板音量控制功能,并将其安装到系统中。通过在代码中添加sys.path.append("/root/mindplus/.lib/thirdExtension/nick-unihiker_sound-thirdex"),确保了音量控制模块能够正常加载和使用。这样,用户可以通过行空板M10上的音量按钮直接调节小智AI的音量大小,操作更加便捷。 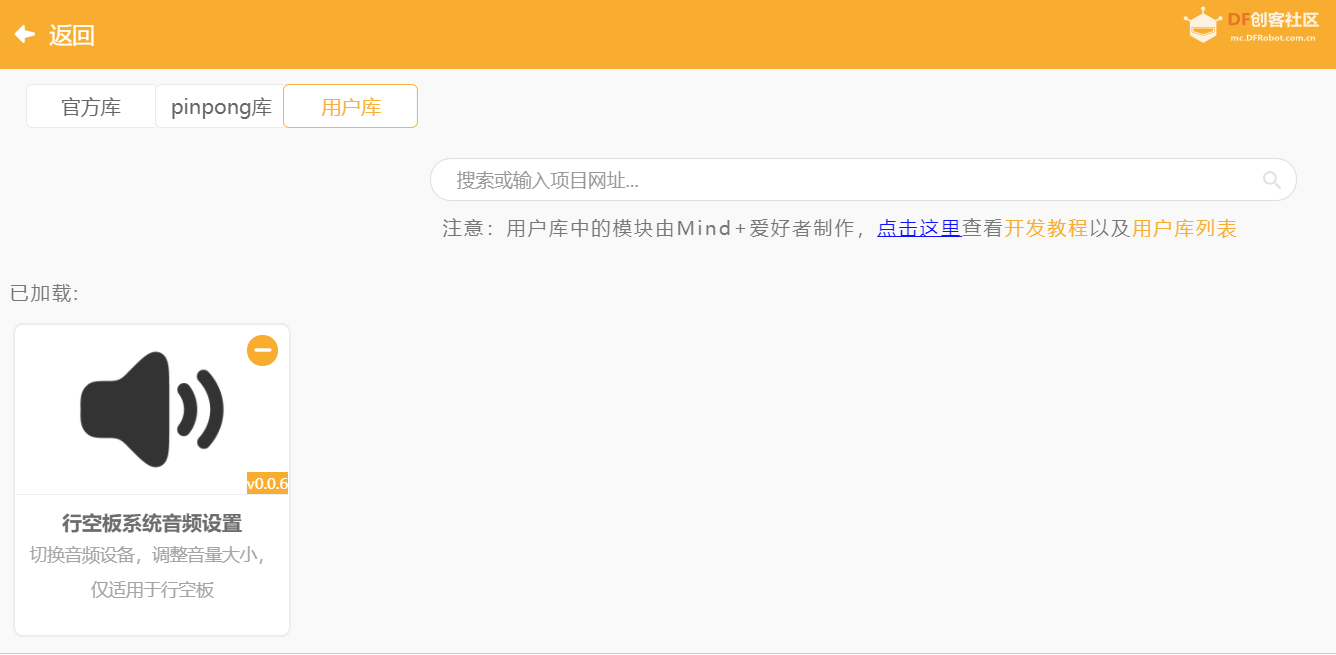 在行空M10上运行pyttsx3时,发现其默认的临时文件路径存在问题,导致文本转语音保存文件失败。为了解决这个问题,我修改了TTS.py文件,将临时文件路径设置为temp_path="/root/tmp/temp.wav"。通过指定正确的临时文件路径,确保了文本转语音功能能够正常工作,让小智AI能够清晰地发出声音。 6.智谱AI大模型注册API 登陆https://open.bigmodel.cn/,注册账号获取API,填写到config/config.json中“API_KEY”。 【测试与优化】  1.测试时触发图像分析关键词:在运行后的config/config.json文件中。 这里有三个想法:前两个都是不将将音频以用户输入的形式发送I给小智A服务器(1)将Pyttxs3生成的音频直接进行播放(声音不好听)(2)不用Pyttxs3进行语音合成,而使用讯飞语音合成,并播放。(比本地Pyttxs3合成要延迟时间)语音合成音频效果好。但与小智AI的声音不一致,有跳戏的感觉。(3)讯飞语音合成代替Pyttxs3进行语音合成,最终将音频以用户输入的形式发送给小智AI服务器。这样做是因为我认为会提升准确度,实际测试后,发现Pyttxs3进行语音合成完全没有问题。合成后的音频小智AI服务器识别准确度很高。最后,果断放弃这三个想法。 【程序文件】  行空M10小智AI的“新眼睛”.zip 行空M10小智AI的“新眼睛”.zip【演示视频】 【项目成果与展望】 通过本次适配工作,成功地为行空M10小智AI安装了一个“眼睛”,使其具备了更强的感知能力。800万像素USB自动对焦摄像头的加入,让小智AI能够更好地识别和理解图像内容,为后续的功能扩展提供了更多可能性。未来,我计划进一步优化小智AI的功能,例如增加手势识别、物体追踪等高级功能,让行空M10小智AI变得更加智能和实用。 此外,我也希望将本次适配的经验分享给更多的开发者,帮助他们更好地利用行空M10和小智AI进行项目开发。开源的力量在于分享和协作,我相信通过大家的共同努力,小智AI将能够实现更多的功能,为我们的生活带来更多的便利。 总之,这次项目不仅提升了行空M10小智AI的功能,也让我在实践中积累了宝贵的经验。未来,我将继续探索和创新,为人工智能技术的发展贡献自己的一份力量。 |



 沪公网安备31011502402448
沪公网安备31011502402448© 2013-2025 Comsenz Inc. Powered by Discuz! X3.4 Licensed

 置顶卡
置顶卡 变色卡
变色卡 千斤顶
千斤顶
 活跃会员
活跃会员
 宣传大使
宣传大使
 创客造
创客造
 编辑选择奖
编辑选择奖
 志“童”道合
志“童”道合
 编辑选择奖
编辑选择奖
 编辑选择奖
编辑选择奖
 编辑选择奖
编辑选择奖






