本帖最后由 呆呆呆呆 于 2025-9-10 12:02 编辑 如何利用x86单板机LattePanda Sigma(x86 SBC/单板机)+Intel 结合 mini-cpm-v 与 qwen2.5vl 视觉模型,将18000产品图片中实现alt文本自动生成与SEO优化。从而提升网站SEO表现的真实应用案例。分享了技术原理、实施步骤、AB测试方法、性能数据和常见问题,帮助企业理解基于单板机的AI边缘计算在SEO中的价值。平均点击率从0.5%提高的0.7%、平均排名从30.8 提高到18.4。这里面我们有对图片添加了 结构化数据 。
通过AI生成的alt属性,GSC 平均点击率从0.5%提高的0.7%、平均排名从30.8 提高到18.4
背景 我在分析网站时发现了一个巨大的问题:我们大约有3000个产品页面,每个产品大约有6张图片,总计接近18000张图像,其中95%以上没有设置alt属性。人工补齐 18 k 条 Alt 按 60 s/张需 300 人时,成本 2.4 w 元。于是我把目光投向“边缘 AI”——让单板机自己“看”自己“写”。 什么是图片alt属性,为什么对SEO如此重要? 图片alt文本(alternative text)是HTML标签 的描述性文字,它的作用不仅仅是辅助视觉障碍用户理解图像内容,更是搜索引擎优化(SEO) 中的关键因素。 搜索引擎本身无法像人类一样“看懂”图像,因此它会依赖alt属性来理解图片的内容、场景与相关性。如果缺少alt属性: 图片无法出现在Google图片、Bing图片等搜索结果中。 页面相关性降低,长尾关键词覆盖度不足。 无障碍体验下降,用户体验不佳。 在电商网站中,这个问题尤其严重。每个产品都有多张图片,如果alt文本缺失,就等于丢掉了巨大的长尾流量机会。 为什么选择LattePanda Sigma? LattePanda Sigma是一款基于x86架构的高性能单板机(x86 SBC),相比ARM架构的树莓派、RISC-V开发板,它最大的优势在于: 完整的x86生态:能原生运行Windows和Linux,兼容主流AI框架与开发工具。 性能更强:适合运行ollama这样的本地大语言模型(LLM)与视觉模型。 边缘计算友好:直接在本地处理,不依赖云端,降低延迟和带宽消耗。 我正是利用LattePanda Sigma,把AI模型部署在边缘侧,实现了大规模图片alt属性的自动生成。 技术架构与原理 模型选择: ollama + 双视觉模型+文生文 AB测试 在实践中,我选择了ollama来运行两个不同的模型: mini-cpm-v (视觉模型):擅长从图像中提取文字与语义信息。qwen2.5vl (视觉模型):擅长从图像中提取文字与语义信息。比较能理解提示词,生成内容比较短。ollama + 2种视觉模型对比 mini-cpm-v VS qwen2.5vl
通过对比不同生成方式的alt文本质量,我们能持续优化模型提示词和生成逻辑。 Ollama 部分Python代码 import base64
import requests
from flask import Flask, request, jsonify, abort
# 初始化Flask应用
app = Flask(__name__)
# 请求模型验证函数
def validate_image_request(data):
if not data or "prompt" not in data or "image" not in data:
return False, "请求必须包含prompt和image字段"
if not isinstance(data["prompt"], str) or not isinstance(data["image"], str):
return False, "prompt和image必须是字符串类型"
return True, "验证通过"
class AltTextExtractor:
#qwen2.5vl:latest
#minicpm-v:latest
def __init__(self, model_name="minicpm-v:latest"):
self.model_name = model_name
self.ollama_base_url = "http://localhost:11434"
def check_ollama_health(self):
"""Check if Ollama is running and accessible"""
try:
response = requests.get(f"{self.ollama_base_url}/api/tags", timeout=5)
return response.status_code == 200
except requests.exceptions.RequestException:
return False
def get_supported_image_extensions(self):
"""Return supported image file extensions"""
return {'.jpg', '.jpeg', '.png', '.gif', '.bmp', '.webp', '.tiff', '.tif'}
def download_image(self, image_url):
"""从URL下载图片并返回字节数据"""
try:
response = requests.get(image_url, timeout=180)
response.raise_for_status()
return response.content
except Exception as e:
abort(400, description=f"无法下载图片: {str(e)}")
def encode_image(self, image_data):
"""将图片字节数据编码为base64字符串"""
return base64.b64encode(image_data).decode('utf-8')
def extract_alt_text(self, prompt, image_url,flag):
"""根据标题和图片URL提取alt文本"""
try:
print(f"正在处理图片:{image_url}")
# 下载并编码图片
image_data = self.download_image(image_url)
base64_image = self.encode_image(image_data)
prompt_ = """
你是一名XXX资深的on-page seo,请描述图片内容(图片包括角度如:Angled shot of、
Overhead shot of、Front of、Angled shot of back of、Side shot showing、Back shot showing),
总结符合google对image alt属性的要求,
用英文输出一句话,小于125个字符。不要包含双引号。
"""
self.model_name = self.model_name
if flag==0:
self.model_name = "qwen2.5vl:latest"
print("====",self.model_name,flag)
payload = {
"model": self.model_name,
"prompt": prompt,
"images": [base64_image],
"stream": False,
"options": {
"temperature": 0.3,
"top_p": 0.8
}
}
print("====",self.model_name,prompt)
# Send request to Ollama
response = requests.post(
f"{self.ollama_base_url}/api/generate",
json=payload,
timeout=90
)
print(response)
if response.status_code == 200:
result = response.json()
#print("Generated Text-1:", result)
alt_text = result.get("response", "").strip()
print("*** Generated Text-2 ***: ", alt_text)
return {"alt": f"{alt_text}"}
else:
print(f"Error: Ollama returned status code {response.status_code}")
print("Generated none_1:")
return {"alt": "none_1"}
except Exception as e:
print(f"Error processing {prompt}: {str(e)}")
print("Generated none_2:")
return {"alt": "none_2"} 复制代码 数据处理与任务调度 整个流程由两个部分组成: 图生文(Vision-to-Text) :Python 脚本调用ollama接口,运行在sigma和Intel机器上,负责批量解析产品图片。文生文(Text-to-Text) :在实践测试过程中发现视觉模型思考能力较弱,将图像结果与标题、产品关键词结合,再通过LLM qwen3 (思考模型)优化alt描述。实现ollama + 视觉模型 + 文生文三级流水线定时任务 :我用Golang写了一个定时任务,编译成.exe,直接运行在LattePanda Sigma上,每天自动批量生成和更新alt属性。Golang 定时任务.exe ─┬─ 每5分钟调用一次,查询没有alt属性的图片地址
├─ Python pipeline.py
│ ├─ A 组:调用 ollama mini-cpm-v ┈┐
│ └─ B 组:调用 ollama qwen2.5-vl ┈┘
│ └─ 合并候选文案
├─ Prompt Engineer 二次生成
│ └─ 结合标题+关键词+类目等,走 qwen3 文生文 AB 测试
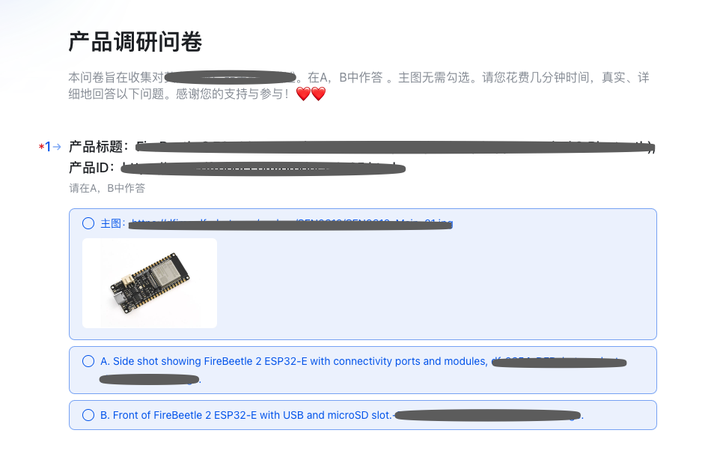
└─ 回写 MySQL,标记“已生成” 复制代码 通过对产品经理、运营等用户问卷调查,2个模型得分2:2,线上决定采用了AB测试 的方式。 基于X86 单板机针对2种视觉模型的问卷调查
这样,整个网站每天都能有数百张图片获得新的SEO友好描述。 经验总结 视觉模型并非万能 :视觉模型只给“眼睛”,文案质量靠“文生文”二次把关,EEAT 得分更高。提示词工程至关重要 :在文生文优化时,我设计了结构化提示词,例如 {产品名} + {核心关键词} + {图片角度} 边缘计算让一切更高效 :直接在LattePanda Sigma上运行,避免了云端费用与延迟问题,部署与运维更灵活。常见疑问 FAQ Q1: 为什么不用云端 API? A: 试过,买的腾讯混元大模型。费用还是比较高,申请费用和测试都不太适合。放弃。在单板机或电脑本地跑零流量费,随便尝试 视频转文字也可以。 Q2: alt文本会不会生成重复? A2: 我在Python脚本中加入了去重逻辑,并结合标题、关键词,保证每张图的alt描述尽可能唯一。Q3: mini-cpm-v与qwen2.5vl谁更好? A3: mini-cpm-v在OCR和图像描述上更稳,但qwen2.5vl结合文生文优化后,能生成更符合SEO需求的长尾描述。AB测试可以帮助持续改进。Q4: LattePanda Sigma跑这些模型会不会过热? A4: 实测中目前一切正常,通过风扇散热即可稳定运行,不会影响定时任务。Lattepanda Sigma + Intel 的设备图,和这骚气自制的散热设备
我是一名自我探索的技术型A/G/SEO。关注我,后续会陆续更新我的AEO探索之旅。希望我的记录能够给你带来启发。 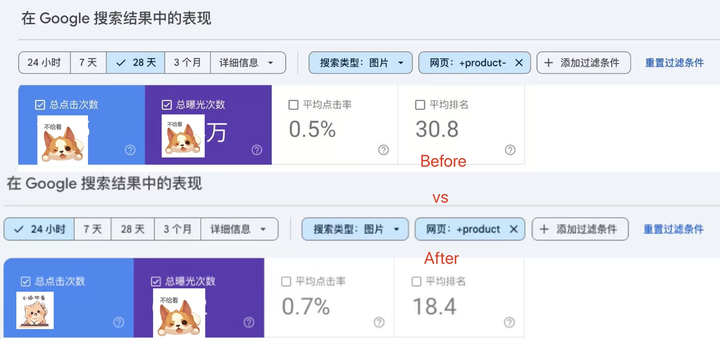





 沪公网安备31011502402448
沪公网安备31011502402448
 置顶卡
置顶卡 变色卡
变色卡 千斤顶
千斤顶






