|
9372| 6
|
[项目分享] 小麦翻译君 |
|
项目背景 我家有一个小度在家智能音箱,带屏幕那个。这个智能音箱的技能很多,其中一项就是翻译。刚好 Mind+ 升级到 1.6.1 版本后又新增了图像识别功能,那我就可以做一个在线翻译的小麦翻译君了! 下面是最终效果: 功能分析 小麦翻译君能够实现中文翻英文、中文翻日文、中文翻韩文三种功能。在翻译的方式上有两种可选:语音翻译或拍照翻译。整体逻辑是,用户先选择要翻译的语言,然后选择翻译的方式,接着识别用户的语音或者拍摄的图片进行文字识别,识别内容后翻译成对应的语言并显示输出、语音播报。 步骤1加载功能模块 打开 Mind+,选择实时模式,点击左下角的“扩展”按钮。 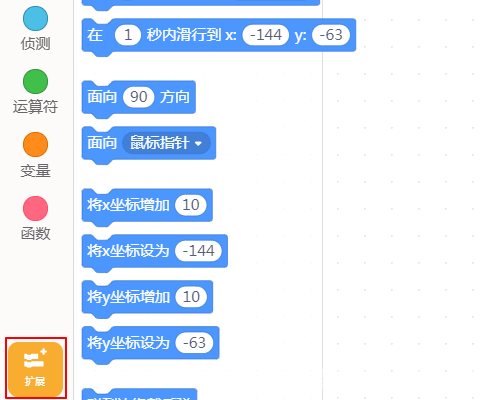 选择“功能模块”分类下的“语音识别”、“谷歌翻译”和“文字朗读”三个功能模块。 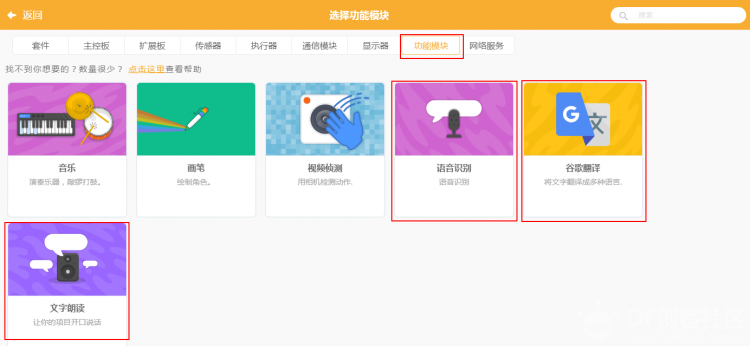 接着选择“网络服务”分类下的“AI图像识别”功能模块。 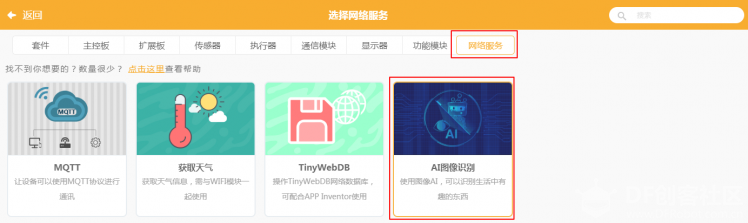 因为主要采用了类似“按钮”的交互,因此需要创建“英语”、“日语”、“韩语”以及“语音翻译”、“拍照翻译”五个角色。这五个角色均是自行绘制,底部一个矩形色块,上方输入对应的文字即可。 这是语言类角色: 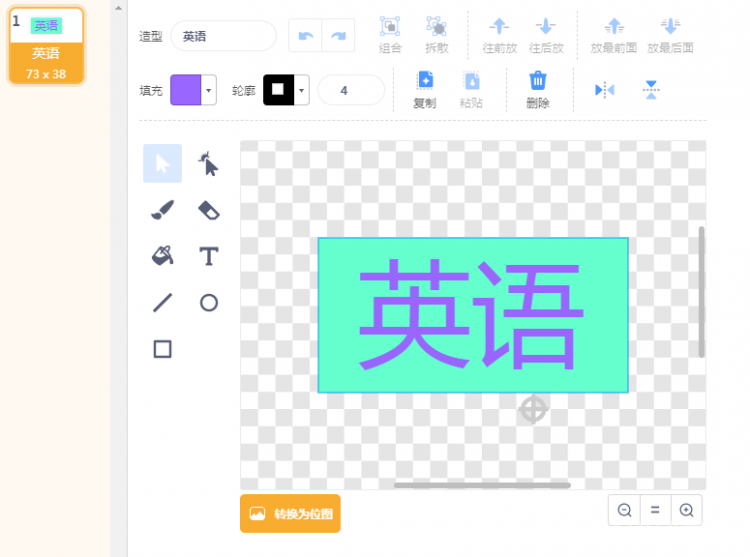 这是翻译方式角色:  角色制作完成后,调整其在舞台中的位置。  主程序在 Mind+(小麦)中,当绿旗被点击时程序开始。语音朗读提示文本,引导用户选择需要翻译的语言。  当用户选择了任何一种语言后,对应角色会将变量“语言”设置为对应的语言,并广播“语言选择完成”,通知小麦已经完成语言选择。下面分别是“英语”、“日语”、“韩语”角色的代码。 小麦接收到“语音选择完成”后,会提示用户进一步选择翻译的方式。 当用户选择“语音翻译”或“拍照翻译”后,对应角色马上告知小麦已经选择了对应的翻译方式。下面分别是“语音翻译”和“拍照翻译”角色的代码。 当小麦接收到“语音翻译”时,提示用户说出要翻译的句子或短语,随后等候用户说 5 秒。识别用户的结果后将其转换为对应的语言。 这里遇到几个问题。因为程序开始设置的语言是中文,所以在朗读翻译后的文本时除了英文能够直接念出来,日语和韩语直接不说话。所以只能加入判断,如果是英语就直接朗读翻译结果,否则需要先朗读前面的中文,再将语言切换为目标语言后再进行朗读。朗读完成后一定要切换回中文,不然等会儿再进行其他操作的时候念出来的又是其他语言了。  当小麦接收到“拍照翻译”时,提示用户将文字放到摄像头下方,等待用户按空格键开始识别。这里将摄像头画面放到了舞台上,便于观察。因为摄像头是左右反过来的,所以文字也是反的,只能镜像开启摄像头。  当用户按下空格键时,先识别图像中获取的文字信息。因为拿手写字测试过,发现印刷体也可以识别,所以代码就没有修改。识别后将摄像头关闭,然后将识别结果及翻译结果显示出来,再进行朗读。后面程序和语音翻译类似。至此,代码编写完毕。  后记 1.项目做完以后回过头来仔细一看,其实也可以把项目改成全部语音识别的形式,这样就类似智能音箱的交互形式。 2.语音识别有时候会不准。编写代码的时候一直都是很准确的,后来录制视频的时候却成了大型翻车现场OoO不知道换成独立账户会不会好一些。 3.文字翻译有弊端,有些文学性强的文字完全翻译不出来。比如下面这个,无论哪种语言都翻译不出来。 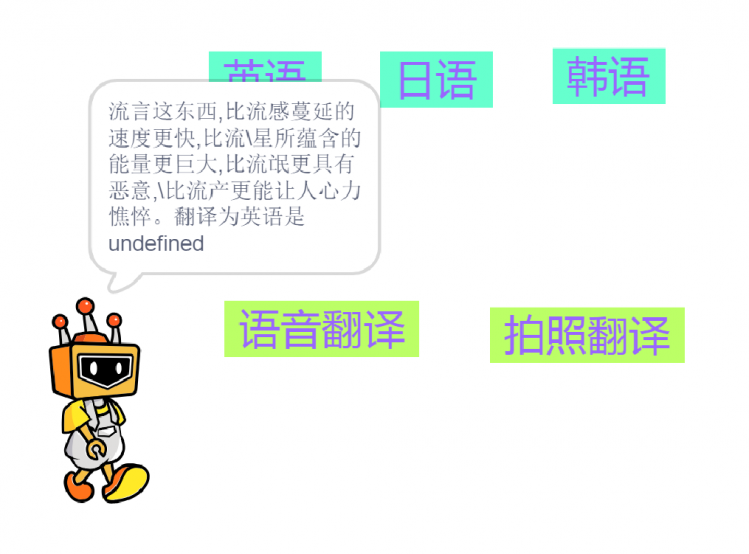 |



 沪公网安备31011502402448
沪公网安备31011502402448© 2013-2026 Comsenz Inc. Powered by Discuz! X3.4 Licensed

 置顶卡
置顶卡 变色卡
变色卡 千斤顶
千斤顶


 萌萌哒新人
萌萌哒新人
 活跃会员
活跃会员
 宣传大使
宣传大使
 创作达人
创作达人
 小蘑菇
小蘑菇
 荣誉教师
荣誉教师
 ARD DAY
ARD DAY






