|
在几年前小米AIOT发布会时,雷军曾在演示小爱同学时翻车,雷军问“小爱同学,三个木叫什么”,小爱同学回答“你是电,你是光,你是唯一的神话”,引得场下的人们捧腹大笑。这个问题的产生可能是由于当时技术不够成熟所导致,但是在AI技术火爆的今天,语音对话的实现已经十分容易了,让我们一起动手,来打造一个比小爱同学“聪明”的语音对话机器人吧!
这个对话机器人的制作,用到的硬件很少,下面我们来列举一下:
硬件连线
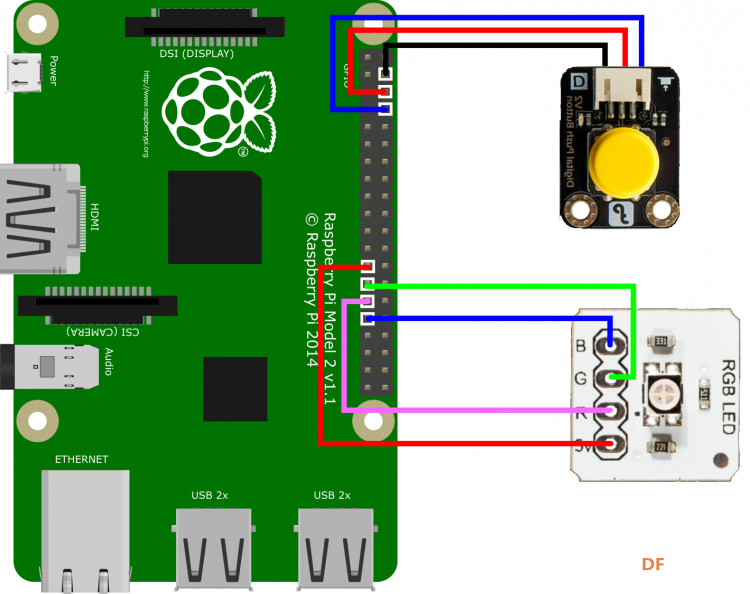
硬件连线图如下图,如果按键按下没有反应可以尝试调换按键的红黑线位置(我这里红黑线是故意反接的),或者直接用一根导线短接一下第三个和第四个引脚(不要一直处于短接状态),RGB灯是为了做一个工作状态显示,在录音、转换、播放时亮不同的颜色,起到一个很好的提示作用。
声卡接线图如下图,这里麦克风的接口经过多个设备测试,全插进去后录音就没有声音,要拔出来一点才能正常录音。
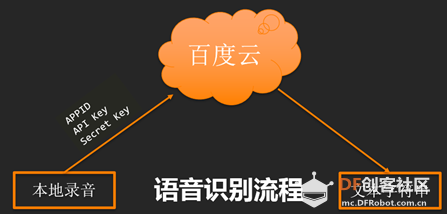
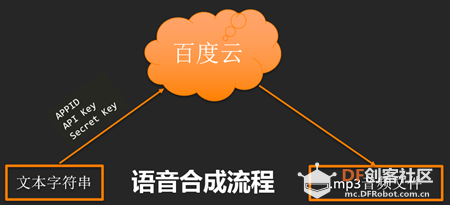
要打造一个语音对话机器人必不可少的两大语音技术是:语音识别和语音合成。语音识别就是指将一段语音转换成对应的文字信息,例如你对着树莓派说:“三个木叫什么”,调试窗口就可以打印显示出“三个木叫什么”这六个字;对应的语音合成就是指将文字信息转换成一段音频,例如树莓派知道了问题,然后回答给你“三个木叫森”这五个字,就需要用语音合成将这五个字转换为音频文件播放出来。这里用的这两个语音技术都是通过调用百度云API实现的,调用百度云语音是需要三个参数的:APPID、API_Key、Sercet_Key,这三个参数如何获取会在下面介绍,调用方法如图所示。
在这中间还有一个问题不知道大家发现没有,就是当你问了问题之后树莓派怎么知道该如何回答你呢,这里有两种解决方案:
第一种,创建自己的“对话库”,通过分析问题文本信息的内容来得到对应的答案,下面是我自己创建的一个简易对话库。
- <font face="微软雅黑">import strsim#用来返回文本相似度
- def faq(Q):
- if strsim.get_equal_rate_1(Q,'你叫什么名字')>0.6 or '名字'in Q:
- return '我是百度智能语音识别工具,你可以叫我小度'
- elif strsim.get_equal_rate_1(Q,'你几岁了')>0.6 or '年龄'in Q or '岁'in Q:
- return '我的生日是2020年1月8日'
- else:
- return '你问的问题我还不能解答'
-
- if __name__=='__main__':
- F=faq('名字')
- print(F)
- </font>
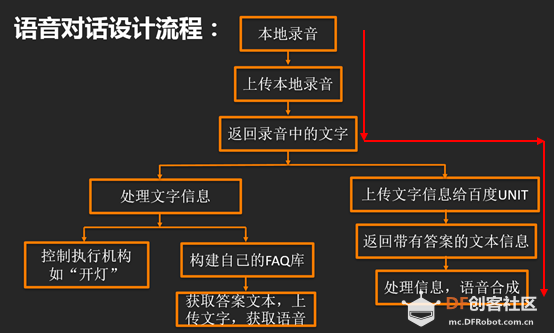
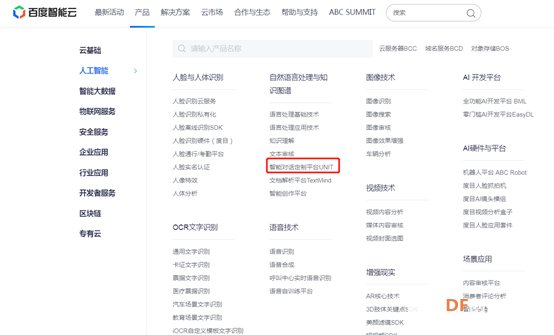
第二种,使用别人创建好的对话库,现在互联网这么发达,各种资源都在开源共享,因此找到这样一个语音对话的API并不困难,百度云就提供了一个语音对话的平台:智能对话定制平台UNIT。 综上,我们这款语音机器人主要是使用了百度云提供的语音识别、语音合成和UNIT对话平台,主要流程就是:在本地录音→上传录音到百度云语音识别→百度云返回转换的文本信息→文本信息上传UNIT对话平台→UNIT返回对话的答案文本信息→答案文本上传百度云语音合成→百度云返回音频文件→播放音频。语音对话设计流程图如下图,这次我们主要是实现红线轨迹的功能。
上面原理介绍BeeBee了那么多,下面我来介绍一下上面所提到的语音对话、语音识别和UNIT平台具体是怎么调用和使用的。 前文已经提到过,调用语音API需要有三个参数,另外调用UNIT平台还需要一个机器人ID,下面来介绍一下这四个参数如何获取:
1.百度搜索“百度云”,点击进入
2.找到语音识别,点击进入
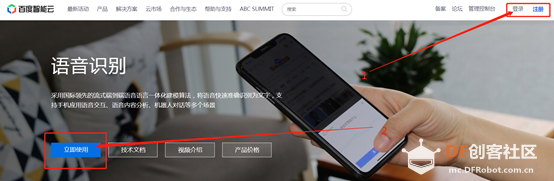
3.登录/注册后点击立即使用
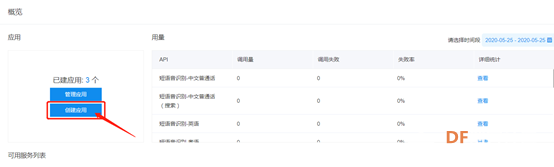
4.创建应用
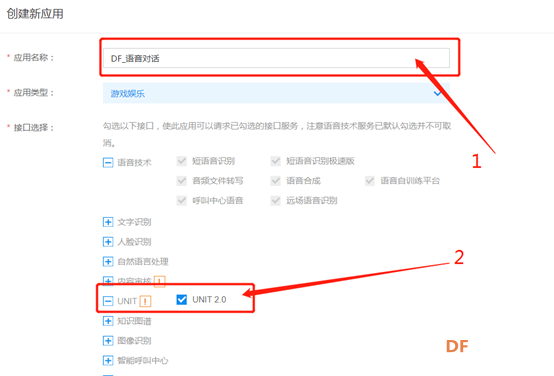
5.填写应用名称,点开UNIT并勾选UNIT2.0,语音包名选择“不需要”,其他都是默认选项,最后在最下方点击立即创建,然后点击返回应用列表。在语音技术菜单中我们可以看到已经默认勾选了语音识别和语音合成,因此在这个应用中,这三个功能都已可以使用。
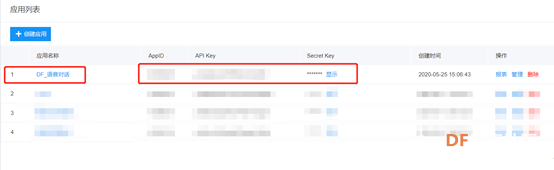
6.查看并记录APPID、API_Key、Sercet_Key这三个参数。
7.返回到第2步的界面,点击智能对话定制平台UNIT。
8.点击立即使用,进入UNIT,进入后界面如图所示。
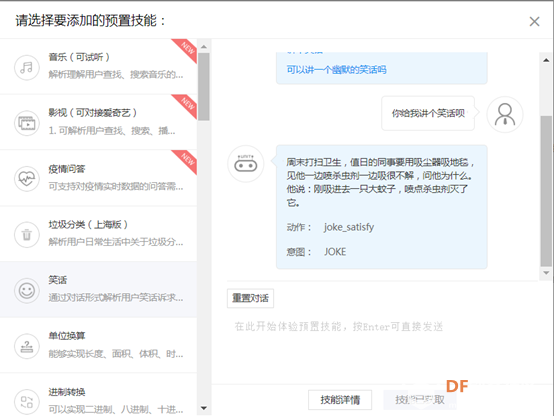
9.点击右下角的获取技能即可获取相应技能。可以获取一些想要的对话技能(可以全部获取),但是这里要注意,像播放电影这样的功能,百度云只能向你返回一个播放电影的动作和电影的信息,并不能真的直接就去播放电影,如果想要播放电影的话需要自己根据返回的动作和电影信息去编写程序。每一个技能都可以进行调试,并且都提供了调试例句,大家可以自己感受一下。
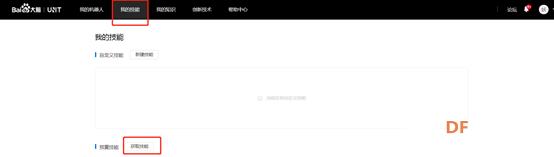
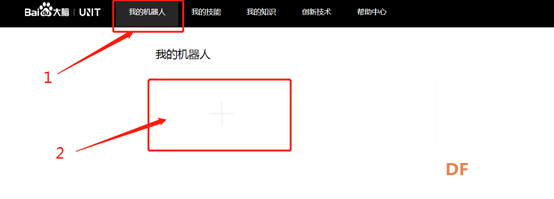
10.添加好技能后点击“我的机器人”,然后点击“+”创建机器人。
11.创建机器人。
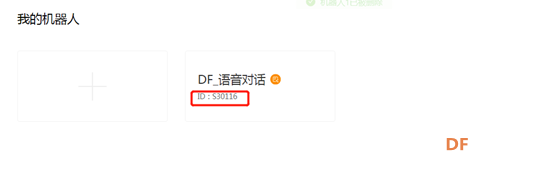
12.记录机器人ID。
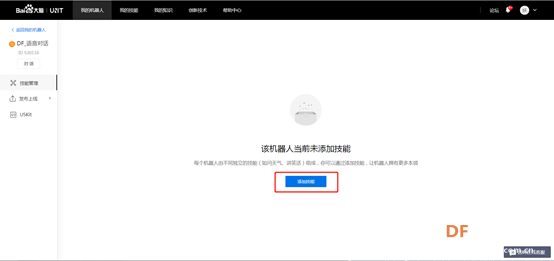
13.点击刚创建好的机器人,进入技能管理界面,点击添加技能。这里能够添加的技能就是第9步中获取过的技能。
14.图中为我添加的技能,点击图中的符号可以调节技能触发的优先级,可以设置成跟我一样的优先级。
15.点击我的机器人界面最左侧的“对话”可以进行测试。
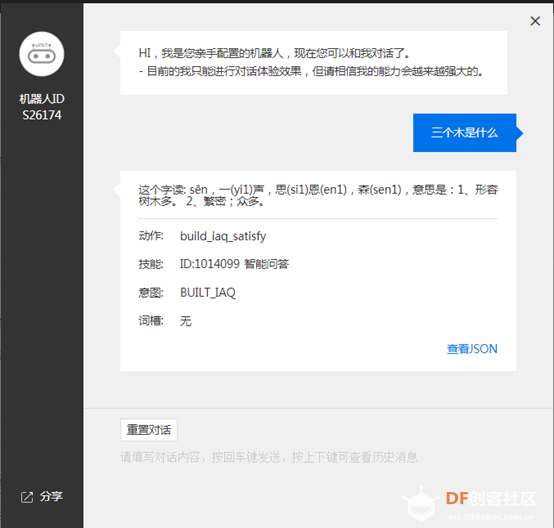
至此,我们的百度云语音对话机器人就创建好了,记得要记录下第6步和第12步里的四个参数。 1.树莓派系统镜像 2.系统镜像好之后需要先下载安装我们需要的库文件 ①安装录音库pyaudio - <font face="微软雅黑">sudo apt-get install portaudio.dev
- sudo apt-get install python-pyaudio
- sudo apt-get install python3-pyaudio
- sudo pip3 install wave
- sudo pip install wave</font>
②安装音频播放库pygame - <font face="微软雅黑">sudo pip3 install pygame
- sudo pip install pygame</font>
③安装百度云aip库baidu-aip - <font face="微软雅黑">sudo pip install baidu-aip
- sudo pip3 install baidu-aip</font>
④安装requests - sudo pip install requests
- sudo pip3 install requests
⑤安装json - <font face="微软雅黑">sudo pip install json
- sudo pip3 install json</font>
注:要将这些代码都保存在树莓派桌面的dialogue文件夹下,路径/home/pi/Desktop/dialogue 1.录音 录音主要使用了pyaudio库,采样率要设为16000,百度云语音识别在16000采样率时成功率较高,其他采样率会报错。这里列出了两个函数,第一个是录音,第二个是播放,运行此段代码会录音三秒然后自动播放录音内容,代码如下: - <font face="微软雅黑">import wave
- import os
- import sys
- from pyaudio import PyAudio,paInt16
-
- framerate=16000
- NUM_SAMPLES=2000
- chunk=2014
- channels=1
- sampwidth=2
- TIME=30 #ms
-
- #保存
- def save_wave_file(filename,data):
-
- '''save the date to the wavfile'''
- wf=wave.open(filename,'wb')
- wf.setnchannels(channels)
- wf.setsampwidth(sampwidth)
- wf.setframerate(framerate)
- wf.writeframes(b"".join(data))
- wf.close()
-
- #录音
- def record(file_name):
- try:
- os.close(file_name)
- os.remove(file_name)#先删除一下文件,以防重名
- except:
- pass
- #os.close(sys.stderr.fileno())
- print('record start')
- pa=PyAudio()
- stream=pa.open(format = paInt16,channels=1,
- rate=framerate,input=True,
- frames_per_buffer=NUM_SAMPLES)
- my_buf=[]
- count=0
-
- while count<TIME:
- string_audio_data = stream.read(NUM_SAMPLES)
- my_buf.append(string_audio_data)
- count+=1
- #print('.')
- print('record end')
- save_wave_file(file_name,my_buf)
- stream.close()
-
- #播放
- def play(file_name):
-
- wf=wave.open(file_name,'rb')
- p=PyAudio()
- stream=p.open(format=p.get_format_from_width(wf.getsampwidth()),
- channels=wf.getnchannels(),
- rate=wf.getframerate(),
- output=True)
-
- data=wf.readframes(chunk)
- while len(data) > 0:
- stream.write(data)
- data = wf.readframes(chunk)
-
- stream.stop_stream()
- stream.close()
-
- p.terminate()
-
- if __name__=='__main__':
- record("1.wav")
- play("1.wav")</font>
2.语音识别和语音合成 这里主要由audio_to_text和text_to_audio两个函数构成,其中APPID, API_KEY, SECRET_KEY三个参数要替换为自己的,具体的代码说明在代码中已做注释,运行此段代码可以实现将录音转为文字再将文字转为音频。如果测试时一直提示语音清晰度问题那就是录音有问题,多半是声卡或麦克风出了问题,可以单独调试上面的录音代码,将耳机插在树莓派自带音频输出口听一下录音有没有问题,如果录音没有声音就将耳机插到声卡的音频输出口,如果还是没声音,试着只将麦克风插入2/3再重新录音,或者参考:https://segmentfault.com/a/1190000013854294 - <font face="微软雅黑"># baidu_ai.py 文件内容
- import os
- from aip import AipSpeech
-
-
- #语音转字符串函数,输入语音文件文件名,反馈一个识别内容(打印内容自选)
- def audio_to_text(pcm_file,APPID, API_KEY, SECRET_KEY):
- client = AipSpeech (APPID, API_KEY, SECRET_KEY) # 三个内容为百度API
- #打开语音文件并读取,读取信息存在file_context
- with open(pcm_file,'rb') as fp:
- file_context = fp.read()
- #向百度云发出请求,百度云反馈字典格式信息(1536、1537可修改,变化不大)
- res = client.asr (file_context, 'pcm', 16000, {'dev_pid': 1536, })
- try:
- res_str = res.get ("result") [0]
- except:
- print ('语音转文字失败,请注意语言清晰度(大部分错误是清晰度问题,具体请查看《https://cloud.baidu.com/doc/SPEECH/s/sk38lxie0》')
- print ('错误信息:',res) # 打印所有反馈信息,主要用于检查有无错误(包含错误码等等)
- #print('终止程序')
- #os._exit(0)
- pass
-
- print('语音转文字成功:',res_str)#只打印关键的语音文本信息
- return res_str
-
- #字符串转语音函数,输入字符串文本,生成并反馈一个后缀为MP3的文件名
- def text_to_audio(res_str,APPID, API_KEY, SECRET_KEY):
- client = AipSpeech (APPID, API_KEY, SECRET_KEY) # 三个内容为百度API
- synth_file = "synth.mp3"#MP3文件名,起一个保存作用(作用不大,无需更改,不明白一定不能改后缀)
- # synthesis参数: 文本,语言zh(中文),1为pc端,语音{"vol":音量,
- #"spd":语速,"pit":语调,"per":声道(0:女,1:男,2:逍遥音,4:小萝莉)}
- try:
- os.close(synth_file)
- os.remove(synth_file)#先删除一下文件,以防重名
- except:
- pass #如果文件不存在直接跳过
- synth_context = client.synthesis(res_str, "zh", 1, {
- "vol": 5,
- "spd": 5,
- "pit": 3,
- "per": 0
- })
- '''with open(synth_file, "wb") as f:
- f.write(synth_context)'''
- f=open(synth_file, "wb")
- f.write(synth_context)
- f.close()
- print("文字转语音成功,文件名:",synth_file)
- return synth_file
-
- if __name__=='__main__':
- APPID = "your_APPID"
- API_KEY = "your_API_KEY"
- SECRET_KEY = "your_SECRET_KEY"
- txt=audio_to_text('1.wav',APPID, API_KEY, SECRET_KEY)
- text_to_audio(txt,APPID, API_KEY, SECRET_KEY)</font>
3.UNIT平台获取答案,这里的get_token和get_value是自己写的库,作用分别是实时获取token验证码和解析云端数据获取答案内容,其中client_id, client_secret, service_id三个参数要替换为自己的,注意最后service_id为机器人ID。
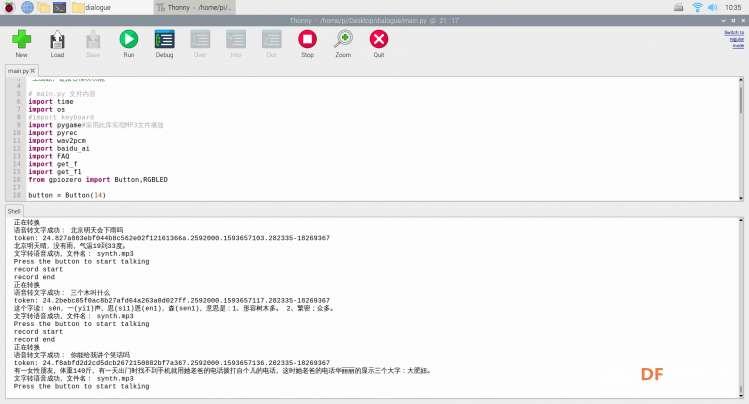
4.主函数,记得替换代码开头的四个参数。前面调试都没有问题的话就可以直接下载最后的附件,用树莓派自带的python编译器Thonny(或其他)更改四个参数后运行main函数,按下一次按钮就可以对话一次。 - <font face="微软雅黑"># main.py 文件内容
- import time
- import os
- import pygame#采用此库实现MP3文件播放
- import pyrec
- import baidu_ai
- import get_f1
- from gpiozero import Button,RGBLED
-
- button = Button(14)
- led = RGBLED(red=9, green=10, blue=11)
-
- service_id='your_service_id'#机器人ID
- APPID = "your_APPID "
- API_Key='your_API_Key'
- Sercet_Key='your_Sercet_Key'
- file_path_wav2pcm=r'/home/pi/Desktop/dialogue'#树莓派桌面路径
- file_name_record='record.wav'
-
- while True:
- try:
- led.color = (0, 1, 0)
- print("Press the button to start talking")
- button.wait_for_press()
- led.color = (0, 0, 1)
- pyrec.record(file_name_record)#录音
- led.color = (1, 0, 0)
- #pyrec.play(file_name_record)#试听录音(可注释)
- print("正在转换")
- res_str=baidu_ai.audio_to_text(file_name_record,APPID, API_Key, Sercet_Key)#将录音发出,云端反馈文本并打印
- os.remove(file_name_record)#删除录音文件
- F=get_f1.get_f(res_str,service_id,API_Key,Sercet_Key)
- synth_file=baidu_ai.text_to_audio(F,APPID, API_Key, Sercet_Key)#将文本合成语音
- led.color = (0, 1, 1)
- os.system('xdg-open synth.mp3')#linux播放方法
- '''pygame.mixer.init()
- pygame.mixer.music.load(synth_file)
- pygame.mixer.music.play()
- while(pygame.mixer.music.get_busy()):
- pass'''#音频播放的备选方案,如果Linux播放方法不成功就采用此方法(不成功的原因是没有设置默认播放器,新镜像的系统不会出现问题)
-
- led.color = (0, 0, 0)
-
- except:
- led.color = (0, 0, 0)
- synth_file_error=baidu_ai.text_to_audio("识别失败,,请注意语言清晰度",APPID, API_Key, Sercet_Key)
- pygame.mixer.init()
- pygame.mixer.music.load(synth_file_error)
- pygame.mixer.music.play()
- while(pygame.mixer.music.get_busy()):
- pass
- #os._exit(0)</font>
|









 沪公网安备31011502402448
沪公网安备31011502402448
 置顶卡
置顶卡 变色卡
变色卡 千斤顶
千斤顶









