|
4950| 8
|
[pinpong 库控制硬件] 【pinpong库控制硬件】之 Latte Panda一代—语音控制硬件 |

|
本帖最后由 _木子_ 于 2020-9-8 14:53 编辑 LattePanda一代实现语音控制硬件 基础篇链接:https://mc.dfrobot.com.cn/thread-306946-1-1.html 衔接上一篇的学习基础上,我们这节课进行比较热门的语音控制硬件。大家想一下语音对于语音控制有什么了解,我们需要怎么实现呢? 在今年看的热播剧“向往的生活”中,有一个机器人名叫小度,他能通过何炅老师说的话,然后能自动播放音乐、自动搜索相关信息(菜谱的做法、人物信息)、家电的控制以及简单的问答功能。  那么这一篇教程就教大家利用LattePanda一代,结合百度ai和我们的pinpong库,通过python编程来实现简单的语音控制开灯的效果。 一、实现原理 ————————————————————————————————————————— 要达到语音控制硬件,那么我们比不可以少的就是语音识别技术了。语音识别技术,也被称为自动语音识别Automatic Speech Recognition,(ASR),其目标是将人类的语音中的词汇内容转换为计算机可读的输入,例如按键、二进制编码或者字符序列。 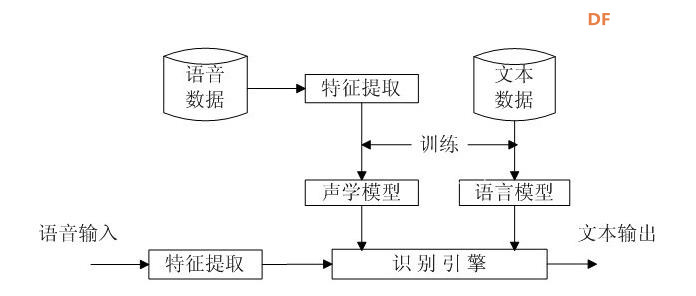 这里我们调用了百度ai的语音识别技术,通过录音中的特征提取,调用已有的识别引擎,识别所输入的语音,最终转化成字符序列让主板能够识别,当识别到正确的指令时,就可以实现相应功能的控制了。 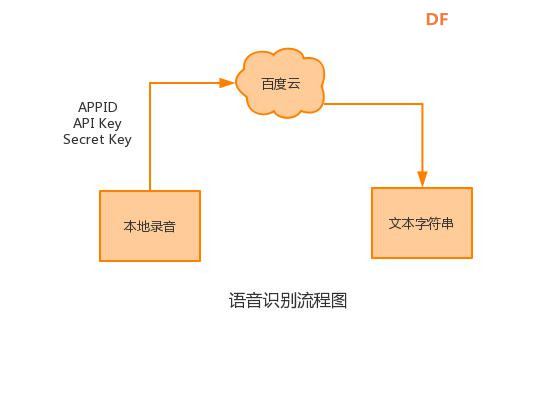 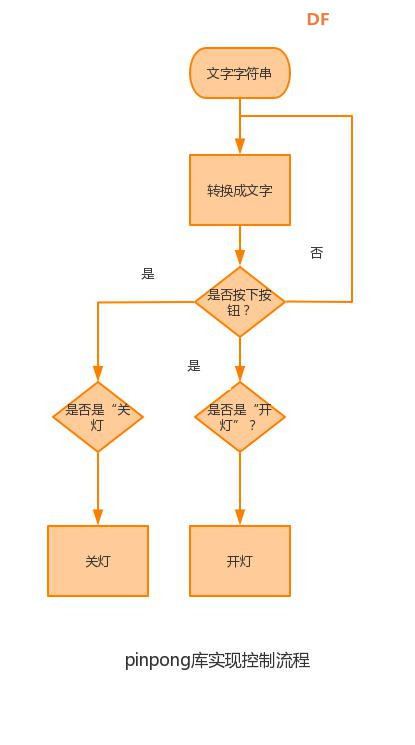 二、环境准备 —————————————————————————————————————————— 1、pinpong库(如一学习过上篇文章的内容则证明已经安装了pinpong库,无需再次安装) 2、Lp必须要联网 3、安装百度ai库
4、安装实现录音需要的PyAudio库
注意:对于64位操作系统,Python 3.8下载PyAudio‑0.2.11‑cp38‑cp38‑win_amd64.whl,Python 3.7下载PyAudio‑0.2.11‑cp37‑cp37m‑win_amd64.whl。 下载地址为; https://sn9.us/dir/13403389-37201167-ba08a5 https://www.lfd.uci.edu/~gohlke/pythonlibs/#pyaudio 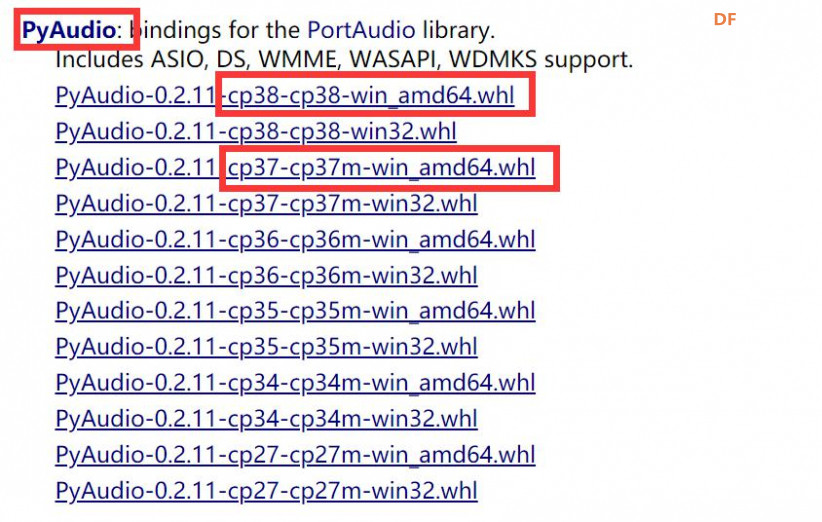
安装时记得指定一下whl文件所在的路径,另外还要有权限,最好以管理员身份运行cmd:  5、wav转化为pcm的工具 wav是我们录音是自动生成的一个可以直接用播放器播放的音频。而pcm是利用百度云进行识别时,识识别效果最为准确的一种格式,所以当我们录音成功时,需要转换成pcm格式再进行识别。 这种音频转换的工具有很多,这里我使用的是FFmpeg 这个工具,下载地址为: https://pan.baidu.com/s/1xhCb8YuO9Q7YfHulxrsP7Q 提取码为:6s1w FFmpeg 环境变量配置: 首先你要解压缩,然后找到bin目录,我解压在桌面文件ai中 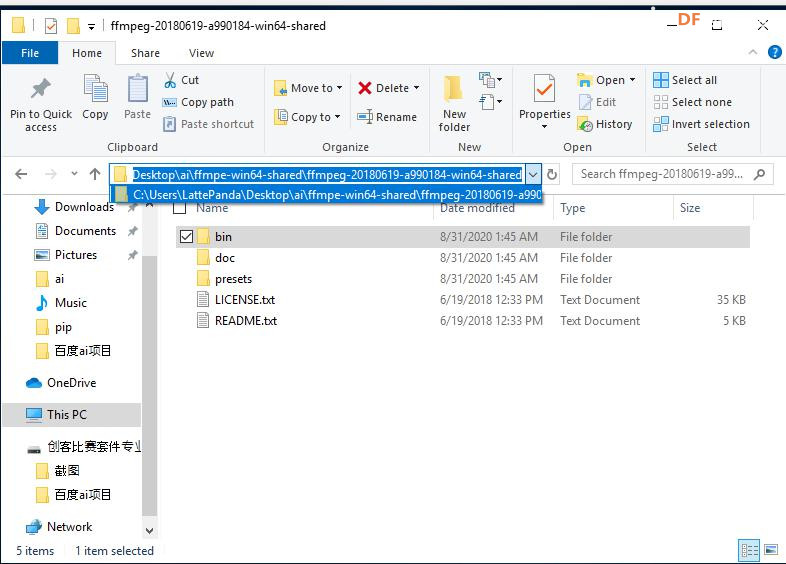 然后配置环境变量: 1、找到This PC 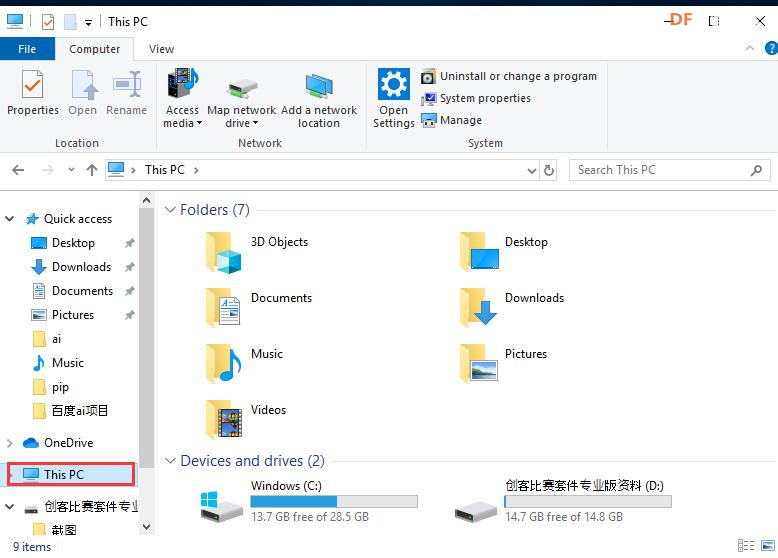 2、右键选择最后一个选项 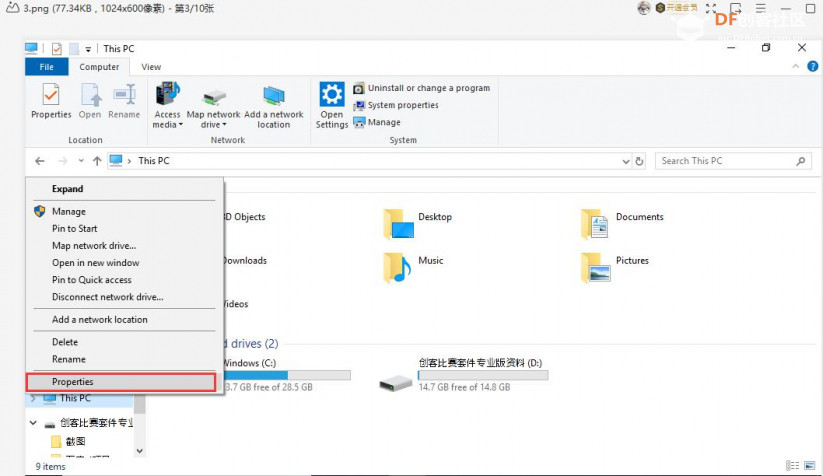 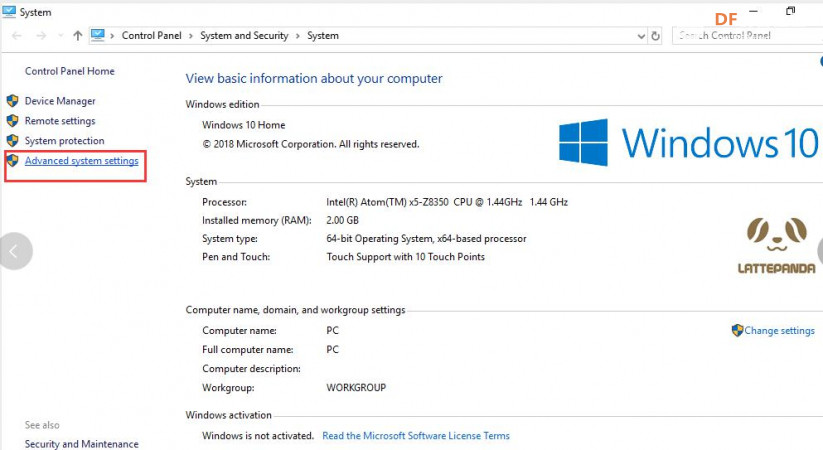 4、选择环境变量 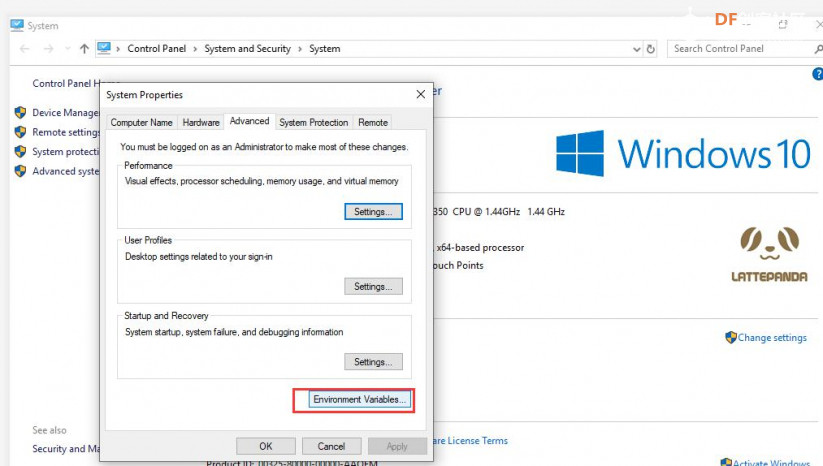 5、双击系统变量中的Path 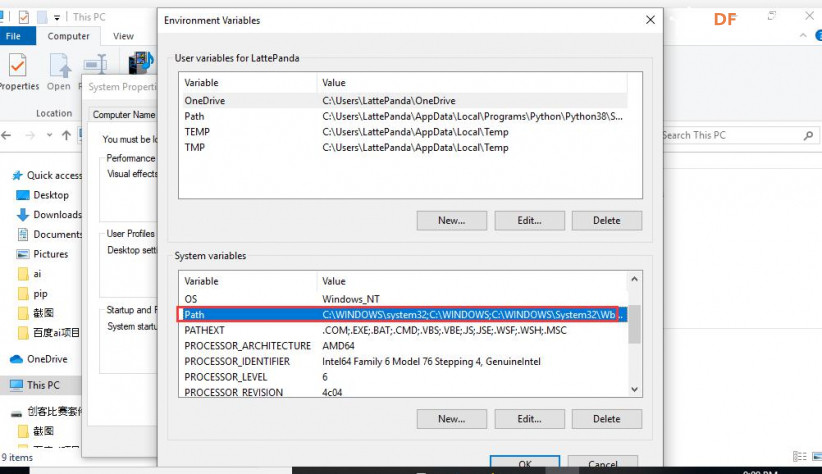 6、点击新建进行新增 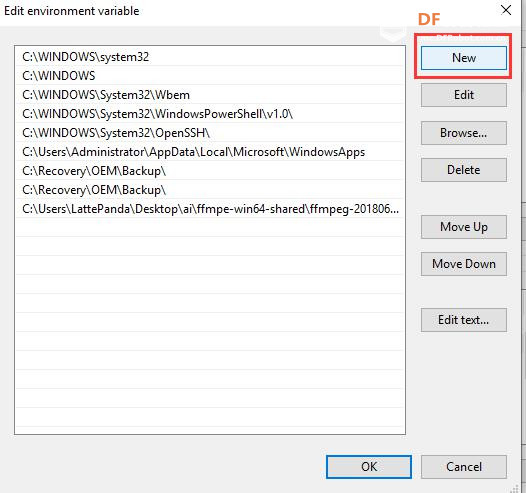 7、选择之前解压时bin的位置进行添加,之后点击ok确定添加。 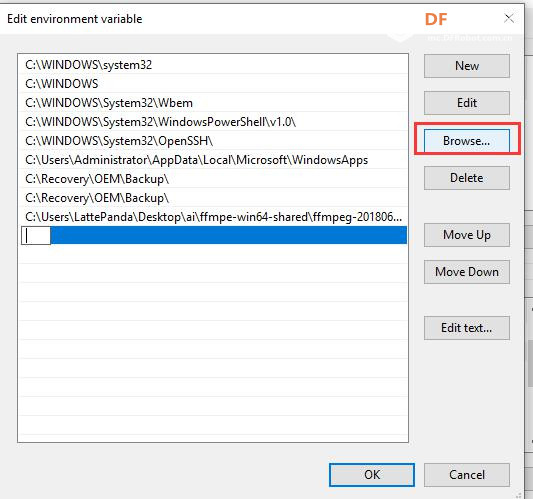 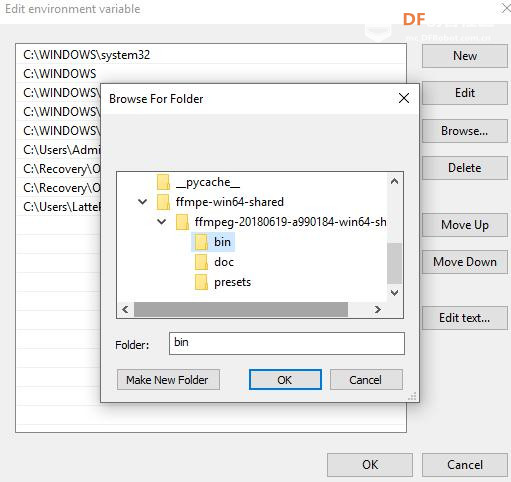 8、至此我们添加系统环境变量已经完成,然后通过cmd指令进行验证,输入ffmpeg,按回车键,出现以下内容说明我们设置成功。 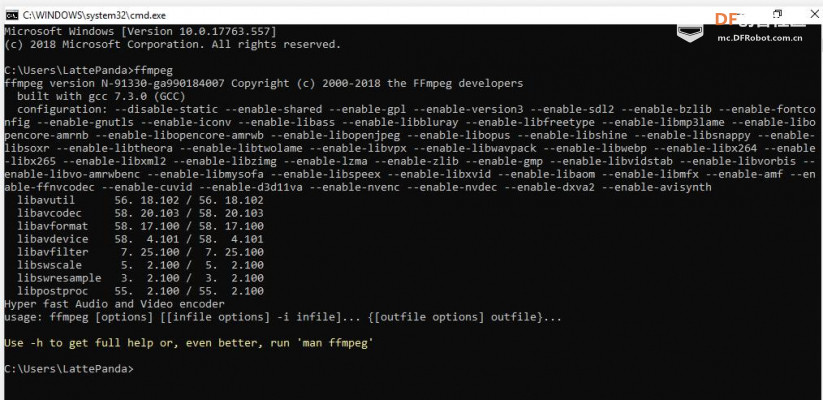 三、硬件准备 —————————————————————————————————————————————— 1、LattePanda(拿铁熊猫)一代*1  2、LattePanda(拿铁熊猫)一代自带的天线*1  3、LED灯和配套的3pin线*1   其它配件如下: 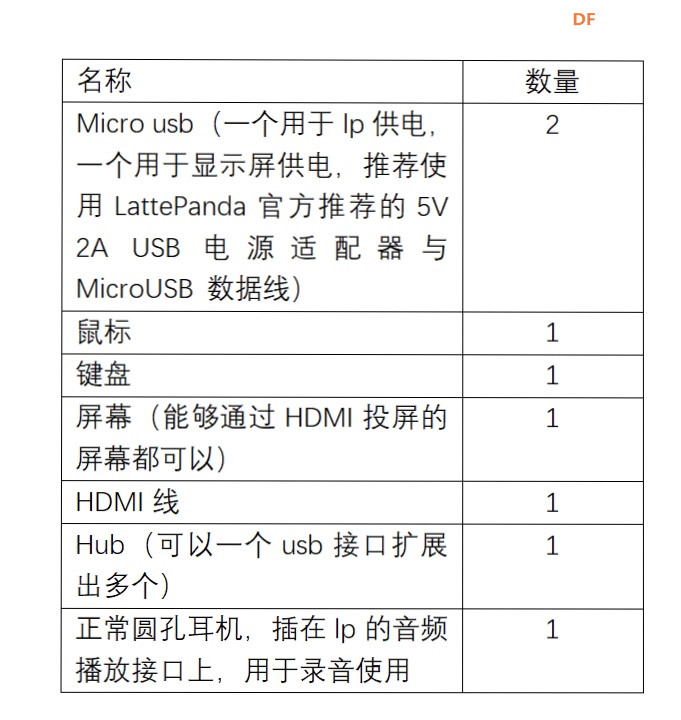 四、硬件连接 ——————————————————————————————————————————— 注意:天线需要一直连接并处于联网状态,led灯接在数字引脚D9,按钮模块接在数字引脚D10,另外需要插上耳机在音频播放接口上。  五、编程控制 ——————————————————————————————————————————— 5.1百度云上的设置操作 1、注册百度云账号,百度搜索百度云,点击进入第一词条,点击免费注册进行注册    2、注册完成后就可以登录了  3、登录成功后,在产品服务中找到我们需要的语音技术,并点击进入。  4、进行应用的创建  5、可以简单的编辑自己新建的应用,然后点击立即创建即可创建成功 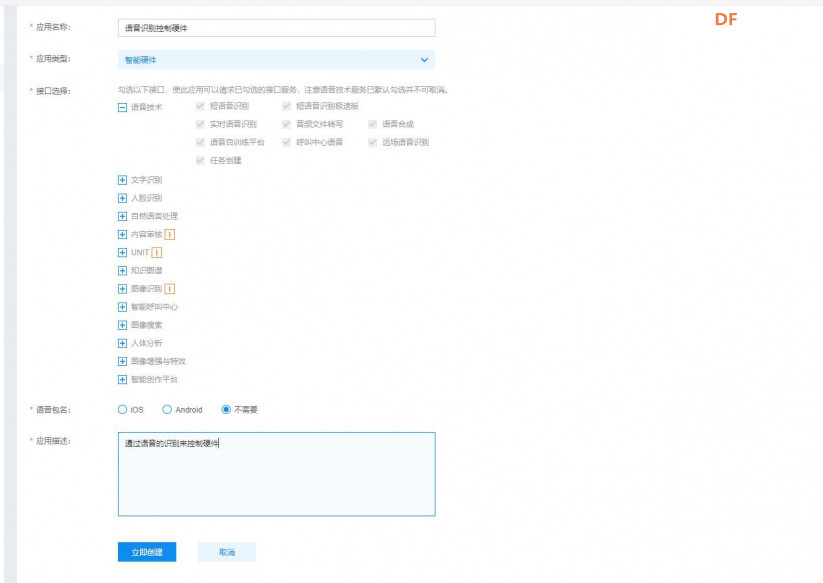 6、添加成功后点击返回列表  7、这样在列表中就可以看到我们新添加的应用了 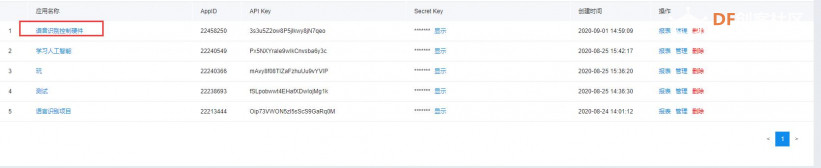 8、点击概况进行功能的查看 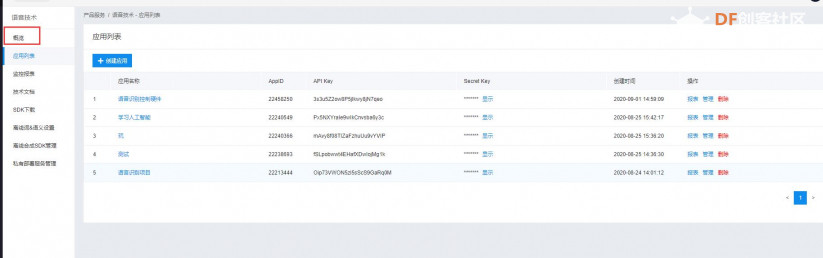 9、这里我有一个小技巧,如果后面你需要用百度ai做其他好玩的功能时,这里我们可以把所以可以免费领取的功能都领取,方便后面使用。甚至可以点击语音合成的进行领取。 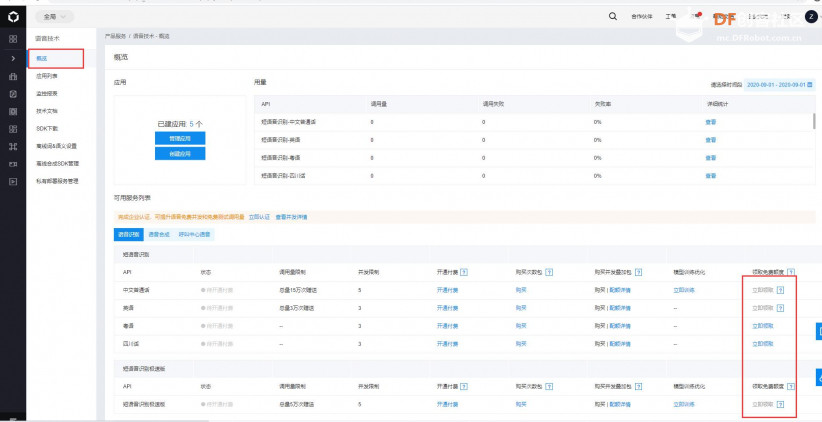 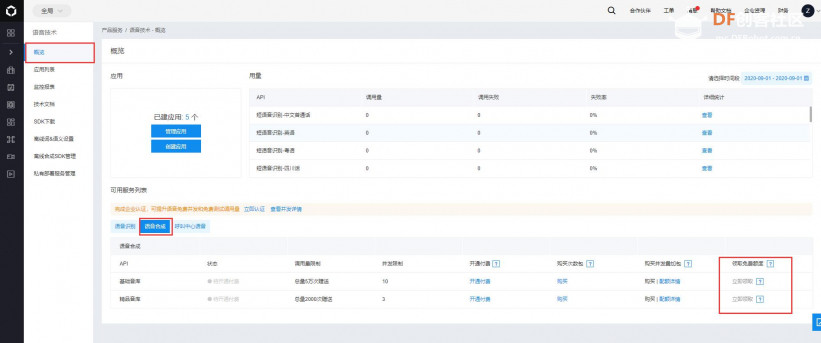 10、都添加成功后,我们可以点击管理应用,回到我们的应用列表,找到我们需要的应用和对应的APPID、API Key、Secret Key,这三个中的关键参数都是我们代码中所需要的。 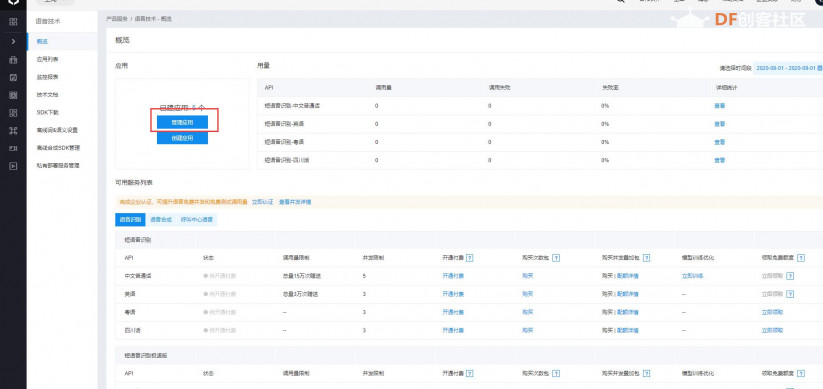 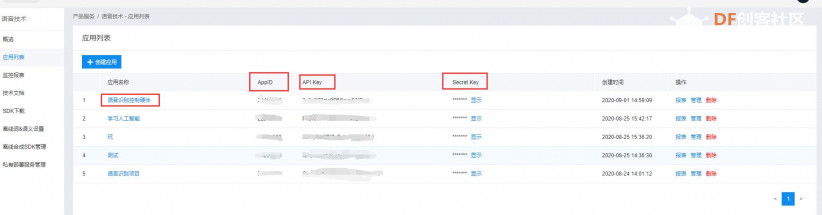 5.2测试wav格式是否能成功转换成pcm格式 1、首先要打开windows的录音机,录制一段音频(说普通话),录音时需要用到我的的耳机,这时自动生成的是wav格式的音频。 找到录音,并点击打开  点击喇叭进行录音  录音成功后(可以自行发挥录制一段话),后面修改名称为audio,这里我另存到了桌面的ceshi文件夹中。  2、我们通过cmd指令进行转换 输入命令 : ffmpeg -y -i audio.wav -acodec pcm_s16le -f s16le -ac 1 -ar 16000 audio.pcm,按回车键,即可进行转换。 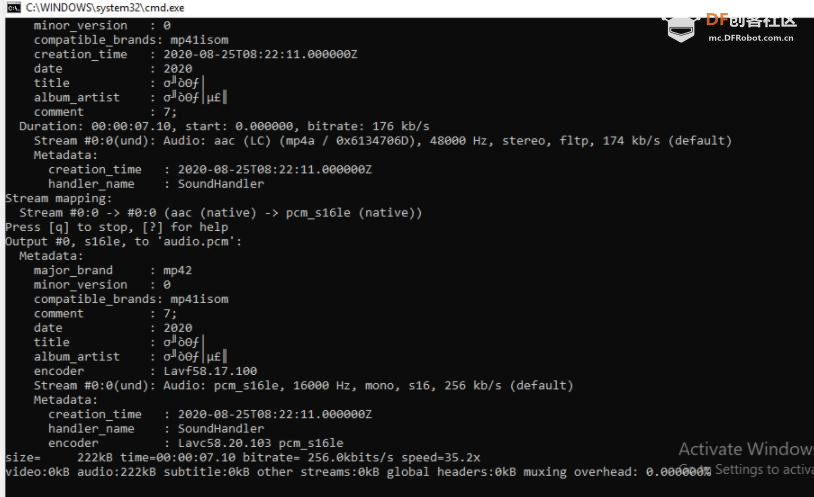 成功之后,可以看到同一个文件夹内多了一个audio.pcm文件。 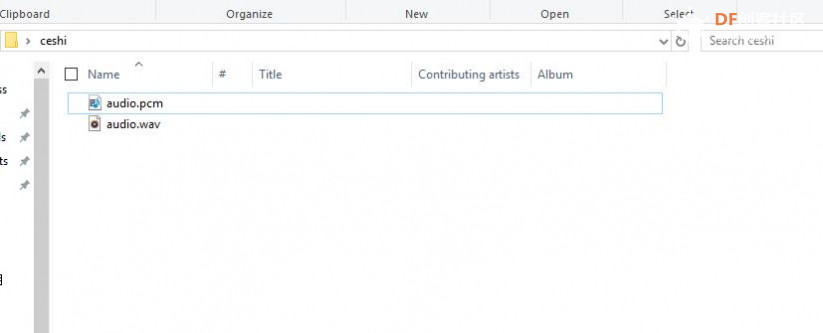 5.3利用百度语音识别的SDK应用 利用百度语音识别的功能,通过python代码实现语音识别。注意python代码文件和之前生成的audio.pcm一定要在同一个文件下才能进行识别。 5.3.1 代码编写 打开python的IDLE编译器  点击File-New File,即可新建python程序文档  [mw_shl_code=python,false]from aip import AipSpeech #导入百度语音识别库 APP_ID = '22240549' #和我们百度云中创建的应用的三个参数一致,按照自己所创建的应用参数对应进行替换 API_KEY = 'Px5NXYraIe9wIkCnvsba6y3c' SECRET_KEY = 'dyFXnDy9RHmhgyoq20Y8W58xKKNpd2d4' client=AipSpeech(APP_ID,API_KEY,SECRET_KEY) #读取文件 filePath="audio.pcm" with open(filePath,'rb')as fp: file_context=fp.read() #识别本地文件 res=client.asr(file_context,'pcm',16000,{ 'dev_pid':1537, }) #打印初识别结果 print(res)[/mw_shl_code] 5.3.2 代码运行 点击Run运行程序,这是会提示保存文件到相应的位置,我们选择和audio.pcm在同以文件夹下 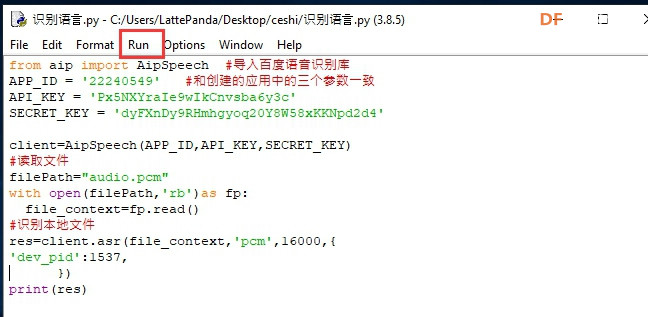 5.3.3 运程结果 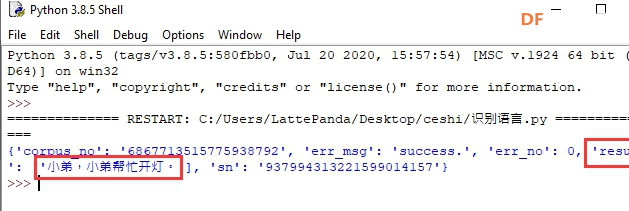 得到的结果让我们很开心,刚好是我们之前录制的声音。 5.3.4 asr函数解析 asr函数需要四个参数,第四个参数可以忽略,自有默认值,参照一下这些参数是做什么的 1、第一个参数: speech 音频文件流建立包含语音内容的Buffer对象, 语音文件的格式pcm 或者 wav 或者 amr。(虽说支持这么多格式,但是只有pcm的支持是最好的) 2、第二个参数: format 文件的格式,包括pcm(不压缩)、wav、amr(虽说支持这么多格式,但是只有pcm的支持是最好的) 3、第三个参数: rate 音频文件采样率 如果使用刚刚的FFmpeg的命令转换的,你的pcm文件就是16000 4、第四个参数: dev_pid 音频文件语言id 默认1537(普通话 输入法模型) 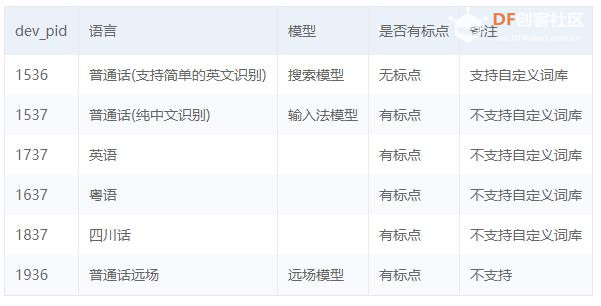 5.4利用PyAudio实现语音录制功能 5.4.1编写代码 新建新的python文件,然后进行代码的编写 [mw_shl_code=python,false]import pyaudio import wave CHUNK = 1024 FORMAT = pyaudio.paInt16 CHANNELS = 2 RATE = 16000 RECORD_SECONDS = 2 WAVE_OUTPUT_FILENAME = "1.wav"#自动生成文件的名称 p = pyaudio.PyAudio() stream = p.open(format=FORMAT, channels=CHANNELS, rate=RATE, input=True, frames_per_buffer=CHUNK) print("开始录音,请说话......") frames = [] for i in range(0, int(RATE / CHUNK * RECORD_SECONDS)): data = stream.read(CHUNK) frames.append(data) print("录音结束,请闭嘴!") stream.stop_stream() stream.close() p.terminate() wf = wave.open(WAVE_OUTPUT_FILENAME, 'wb') wf.setnchannels(CHANNELS) wf.setsampwidth(p.get_sample_size(FORMAT)) wf.setframerate(RATE) wf.writeframes(b''.join(frames)) wf.close()[/mw_shl_code] 5.4.2运行程序 点击Run运行程序 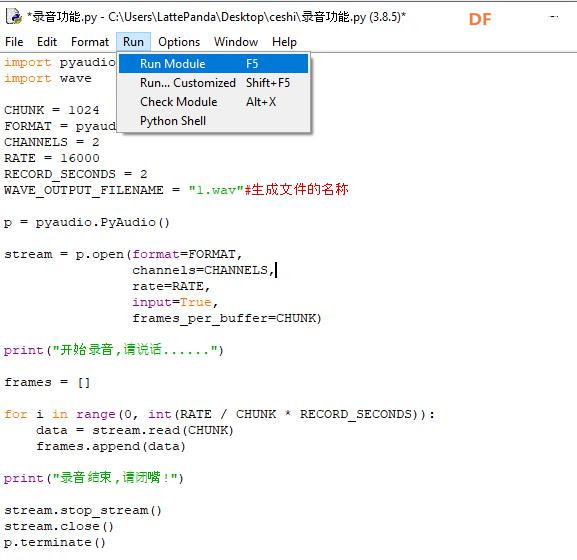 5.4.3运行结果 运行成功后,根据提示进行录音 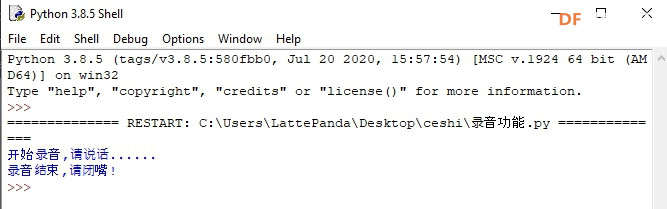 可以看到文件夹中多了一个1.wav的录音文件 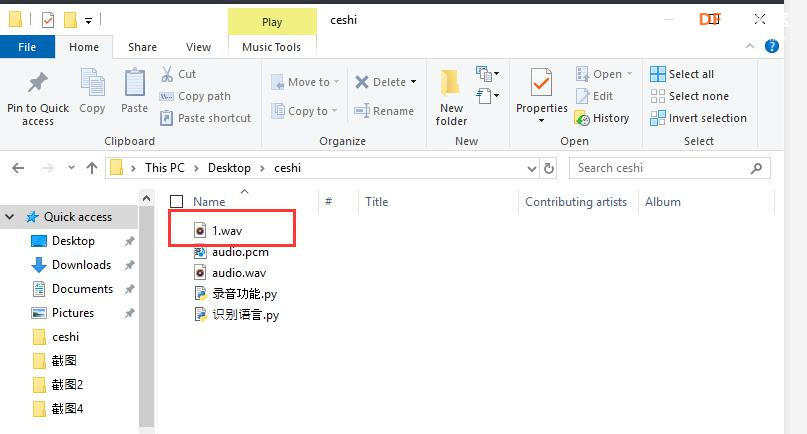 双击打开播放录音,发现就是刚刚我们所录的音,说明我们成功了。  5.5把录音代码写到一个函数当中,方便我们后面的调用 接下来,我们将这段录音代码,写在一个函数里面,如果要录音的话就调用 代码编写 建立一个文件 pyrec.py 并将录音代码和函数写在内 [mw_shl_code=python,false]# pyrec.py 文件内容 import pyaudio import wave CHUNK = 1024 FORMAT = pyaudio.paInt16 CHANNELS = 2 RATE = 16000 RECORD_SECONDS = 2 def rec(file_name): p = pyaudio.PyAudio() stream = p.open(format=FORMAT, channels=CHANNELS, rate=RATE, input=True, frames_per_buffer=CHUNK) print("开始录音,请说话......") frames = [] for i in range(0, int(RATE / CHUNK * RECORD_SECONDS)): data = stream.read(CHUNK) frames.append(data) print("录音结束,请闭嘴!") stream.stop_stream() stream.close() p.terminate() wf = wave.open(file_name, 'wb') wf.setnchannels(CHANNELS) wf.setsampwidth(p.get_sample_size(FORMAT)) wf.setframerate(RATE) wf.writeframes(b''.join(frames)) wf.close()[/mw_shl_code] 代码中的rec 函数就是我们调用的录音函数,并且给他一个文件名,他就会自动将声音写入到文件中了 5.6通过代码实现把wav的音频文件转换为pcm的文件 新建一个文件 wav2pcm.py,这个文件里面的函数是专门为我们转换wav文件的。 使用 os 模块中的 os.system()方法,这个方法是执行系统命令用的, 在windows系统中的命令就是 cmd 里面写的东西,如dir , cd 这类的命令。 代码编写 [mw_shl_code=python,false]# wav2pcm.py 文件内容 import os def wav_to_pcm(wav_file): # 假设 wav_file = "音频文件.wav" # wav_file.split(".") 得到["音频文件","wav"] 拿出第一个结果"音频文件" 与 ".pcm" 拼接 得到结果 "音频文件.pcm" pcm_file = "%s.pcm" %(wav_file.split(".")[0]) # 就是此前我们在cmd窗口中输入命令,这里面就是在让Python帮我们在cmd中执行命令 os.system("ffmpeg -y -i %s -acodec pcm_s16le -f s16le -ac 1 -ar 16000 %s"%(wav_file,pcm_file)) return pcm_file[/mw_shl_code] 5.7录音+语音识别 5.7.1代码编写 新建新的python文件,然后进行代码的编写 5.7.2运行程序 点击Run运行程序 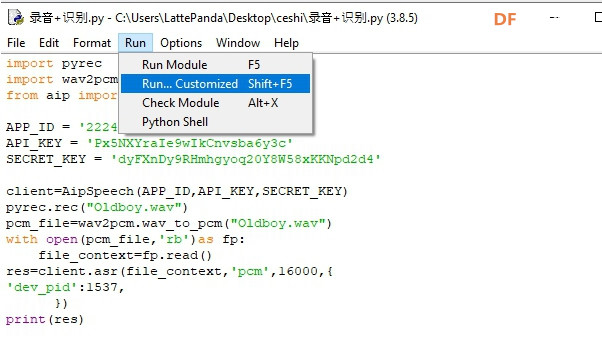 5.7.2运行结果 按照打印的提示进行录音,最终可以看到我们识别到了正确的结果。此时也可以看到我们的文件夹中多了两个名为Oldboy.wav和Oldboy.pcm的音频文件。 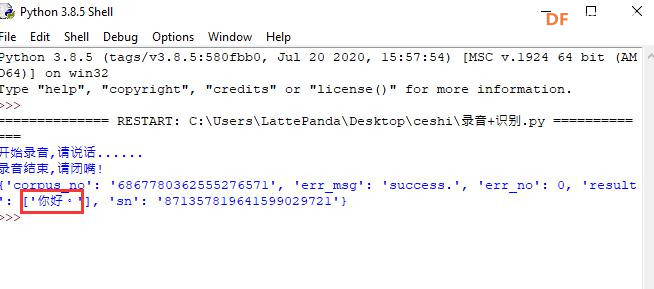 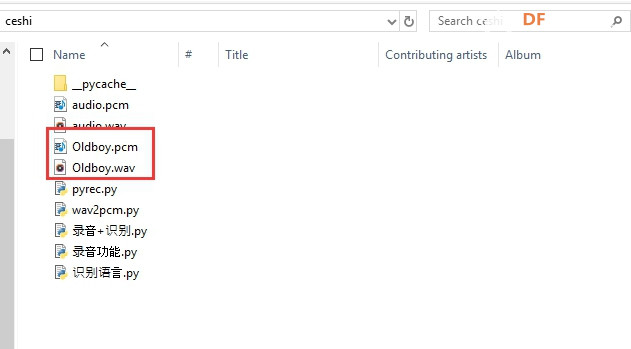 5.8加入pinpong库实现语音控制 前面我们已经实现语音识别了,这里我们只需要通过识别到的结果进行判断,是否是我们所需要的指令,这样我们就可以控制我们的硬件了。还有我们的录音都是程序运行的瞬间就会启动录音功能,但是当我们用来控制硬件时语音一个触发条件,这样才更加方便我们实现语音控制。否则你想象一下我们每次实现语音控制,都要重新运行一下程序是不是很麻烦。这里我选用的按钮来替代触发的条件开关(当然你也可以选择其他的触发条件)。 大家是不是已经摩拳擦掌了,那么接下来我们就来进行程序的设计吧! 5.8.1代码编写 [mw_shl_code=python,false]import pyrec #录音函数文件 import wav2pcm #wav转换成pcm函数文件 import time #导入时间库 from aip import AipSpeech #调用百度的语音识别库 from pinpong.board import Board,Pin #导入pinpong库的相关内容 Board("leonardo").begin() # lp一代自带leonardo主板,所以这里选择leonardo led=Pin(Pin.D9,Pin.OUT) #初始化led灯引脚为D9 btn=Pin(Pin.D10,Pin.IN) #初始化按钮的引脚为D10 APP_ID = '22240549' #三个参数要与自己创建的应用对应的三个参数要一致 API_KEY = 'Px5NXYraIe9wIkCnvsba6y3c' SECRET_KEY = 'dyFXnDy9RHmhgyoq20Y8W58xKKNpd2d4' client=AipSpeech(APP_ID,API_KEY,SECRET_KEY) while True: #循环执行 b=btn.read_digital() #读取D10号引脚的电平 print(b) #打印出D10引脚的电平状态 time.sleep(1) #等待1s if b==1: #判断按钮状态是否等于1,如果等于则执行下面的代码 pyrec.rec("Oldboy.wav") #录音并自动生成文件,文件名为Oldboy.wav pcm_file=wav2pcm.wav_to_pcm("Oldboy.wav") #自动转换成pcm文件 #读取得到的pcm文件 with open(pcm_file,'rb')as fp: file_context=fp.read() #通过百度的语音识别进行识别 res=client.asr(file_context,'pcm',16000,{ 'dev_pid':1537, }) #打印出识别到的结果 print(res) #获得识别结果中的中文 res_str=res.get("result")[0] #打印出识别的中文 print(res_str) #判断识别结果中是否是开灯,如果是则执行开灯(给数字引脚D9高电平) if '开灯' in res_str: led.write_digital(1) #判断识别结果中是否是关灯,如果是则执行关灯(给数字引脚D9低电平) if '关灯' in res_str: led.write_digital(0) time.sleep(0.5) #消除抖动[/mw_shl_code] 5.8.2运行程序 点击Run运行程序  5.8.3运行结果 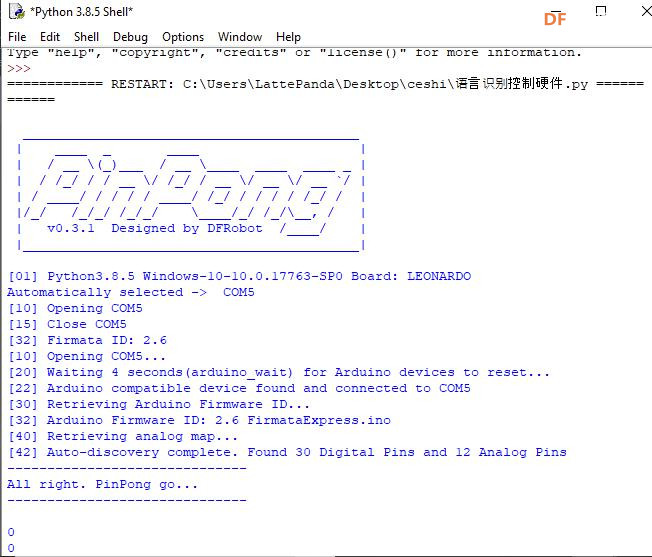 按下按钮即可进行录音,当录音内容为“开灯”时,我们可以看到D9号引脚的led灯被点亮。再次按下按钮进行录音,当录音内容为“关灯”时,我们可以看到D9号引脚的led灯熄灭了。  六、能力扩展 ———————————————————————————————————————— 1、尝试利用不同指令去控制不同的硬件 2、本文中我们利用触发录音方式是按钮,可以选择其他的触发方式,有能力的人还可以尝试通过语音唤醒去制作,那样的话就和前文提到的“小度”功能一样了! |



 沪公网安备31011502402448
沪公网安备31011502402448© 2013-2026 Comsenz Inc. Powered by Discuz! X3.4 Licensed


 置顶卡
置顶卡 变色卡
变色卡 千斤顶
千斤顶





 萌萌哒新人
萌萌哒新人
 活跃会员
活跃会员
 宣传大使
宣传大使
 志“童”道合
志“童”道合
 编辑选择奖
编辑选择奖






