|
6477| 7
|
AI实验—基于HOG+SVM的大象检测系统 |

|
本帖最后由 hnyzcj 于 2021-11-4 12:05 编辑 【项目源起】 云南北移亚洲象群自今年4月离开传统栖息地,一路逛吃到昆明后南返,为确保人象安全,沿途疏散转移群众达15万多人次。为了保护人类的安全,我们需要一个大象检测系统,当检测有大象闯入人类聚集地时发出警报,提醒人们尽快转移。 【项目展示】  【功能简介】 本项目将通过拿铁熊猫智能终端制作一个大象AI检测系统,利用图像分类技术识别大象,并使用LED灯、蜂鸣器制成警报装置,当系统检测到大象时,就发出声光警报,用来提醒人类不要靠近,尽快撤离。 【系统原理】 通过训练SVM分类器,加入蜂鸣器、LED灯外设,部署在拿铁熊猫智能终端,当摄像头检测到大象时,LED 灯点亮、蜂鸣器报警,从而实现大象 AI 检测系统的制作。基于拿铁熊猫智能终端的HOG + SVM的大象检测系统制作主要分为以下四个步骤: 步骤一:采集训练数据,为数据打标签。 步骤二:SVM进行分类训练,生成模型。 步骤三:测试数据,查看SVM分类模型的准确率。 步骤四:部署模型,进行SVM 预测。 【什么是图像识别】 利用计算机对数字图像进行处理、分析和理解,以识别各种不同模式下的目标和对象的技术。其基本过程包括图像采集——预处理——特征提取——图像识别四步。我们人眼在看到不同类的物体时,可以轻松的区分,但是对计算机来说,它们是如何区分不同类别的物体呢?一张图片为了对其简化,我们可以对其做灰度化、二值化等预处理,从而达到简化数据的目的。但对于计算机来识别来说,这些原始数据往往存在冗杂,有较多无意义的数据。因此,就需要从原始数据中提取有意义的数据给计算机,帮助其理解识别,这些有意义的数据就是图像特征。图像特征主要有颜色特征、形状特征和空间关系特征。每种图像特征都有对应的特征提取算法。 【HOG特征提取算法】 特征提取是图像识别中重要的一步。特征提取的过程是去除无用信息,保留有用信息,即提取图像的目标特征。特征提取的目的是数据降维,降低数据量。目前有多种流行的特征提取算法有:HOG、SURF、ORB等。在此,我们将学习HOG 特征提取算法。 HOG(Histogram of oriented gradient,方向梯度直方图)其原理是通过计算图像梯度,再构建直方图来获取目标特征。该特征提取算法是法国研究人员Dalal在2005年提出的一种实现人体目标特征检测的方法。其主要思想是在一副图像中,局部目标的表象和形状(appearance and shape)能够被梯度或边缘的方向密度分布很好地描述。其本质是梯度的统计信息,而梯度主要存在于边缘的地方。目前HOG特征结合SVM分类器已经被广泛应用于图像识别中。那什么是图像梯度?什么直方图呢?让我们一起来了解下。 图像梯度的概念 图像梯度是用来表示图像的灰度变化。图像梯度有大小和方向两个属性,如图2所示在计算机存储中,用0-255 表示不同灰度的图像,其中0表示黑色,255表示白色,此时黑与白、黑与灰、灰与白的边界上就产生了梯度,梯度方向由低数值指向高数值。梯度的大小表示的是各个像素之间的梯度变化的大小。在下图中黑色到白色的变化是0到255的变化距离,黑色到灰色是0到200的变化距离。此时两个边界的梯度大小当然就有所不同,变化距离越大,梯度越大。 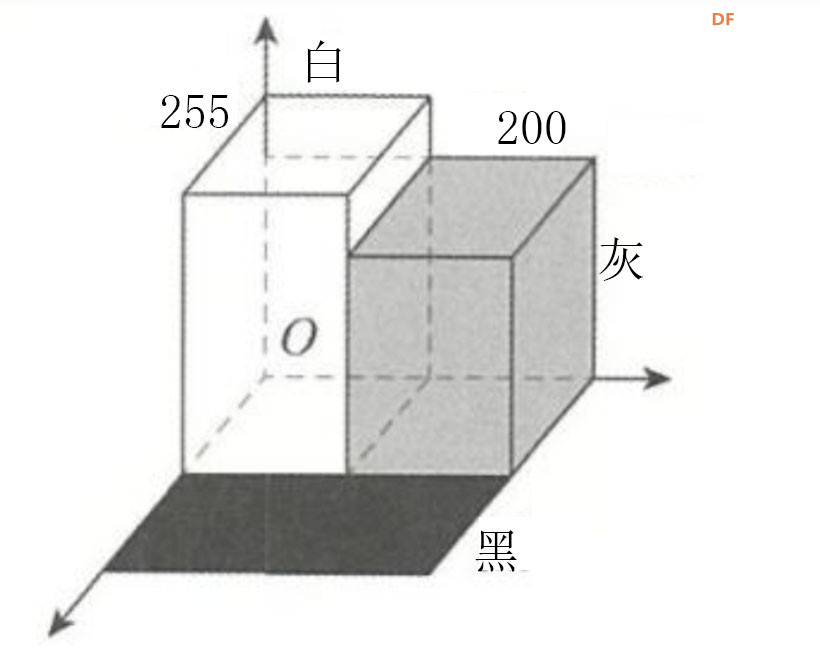 图像梯度的计算 图像都是由像素组成的,对于具体的某一个像素而言,可以通过计算梯度来表示颜色变化。每个像素的梯度大小和方向都是可以计算的。例如图3是从一幅灰度图中截取的8×8的像素点,我们取第5行第2列的像素点为目标像素点。取目标像素点和它周围的8个像素点,分别显示其灰度值。取目标像素点(97)其上(113)、其下(75)、其左(100)、其右(74)四个像素点计算其梯度。 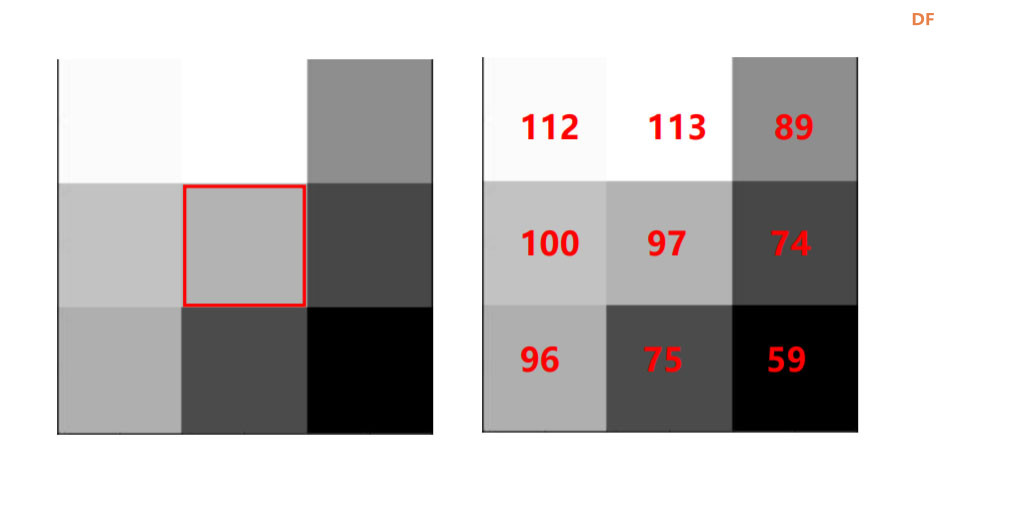 梯度计算如下所示: 目标像素点横向灰度变化gx: |100-74|=26 目标像素点纵向灰度变化gy: |75-113|=38 梯度大小/模长:(gx^2+gy^2)^1/2: 46.04345773288535 梯度方向/角度:arctan(gy/gx): 55.619655276155136 将梯度计算结果看成一个向量,向量的模长即为梯度的大小,向量的角度即为梯度的方向,可以将向量绘制出来。同理一幅8×8像素的灰度图来说,可以计算出每一个像素的梯度向量,注意在计算图像最外侧的一层像素的梯度时,上下最外一层像素只需要考虑左右邻近的像素点,左右最外一层像素只需要考虑上下邻近的像素点,图像的 4 个顶点像素点默认梯度方向和大小都为0。 构建梯度直方图 特征提取的目的是数据降维,而目前通过梯度计算一个像素就会产生两个数据,这显示不是简化数据。HOG特征能对数据降维的核心就是用直方图来表示图像梯度,从而完成对向量的压缩。还是以这张8×8像素的灰度图为例,通过前面的梯度计算,我们已经得到了64个梯度向量,现在我们将64个向量压缩为9个数值,并最大化的保留原有信息。 我们知道,每个梯度向量的角度在 0-180 度之间(arctan()取值范围是(-π/2,π/2)),将 64个向量压缩为 9个数值的过程就是取0、20、40、60、80、100、120、140、160度共计 9 个角度值,然后将每个像素按照梯度的大小和方向分配到这9个角度值上。例如:角度为0度,梯度大小为 67,所以在0度位置加上67;角度为36.18628 度,介于20度和40度之间,梯度大小为 50.803543,所以这个梯度值会被按比例分配给20和40度,20度分配值为“(40-36.18628)/20*50.803543 = 9.6875244”约9.69,在20度加上 9.69;40度分配值为“(36.18628-20)/20*50.803543 = 41.1160186”,约为41.12,在40度加上41.12。以此类推,直至完成直方图的构建。 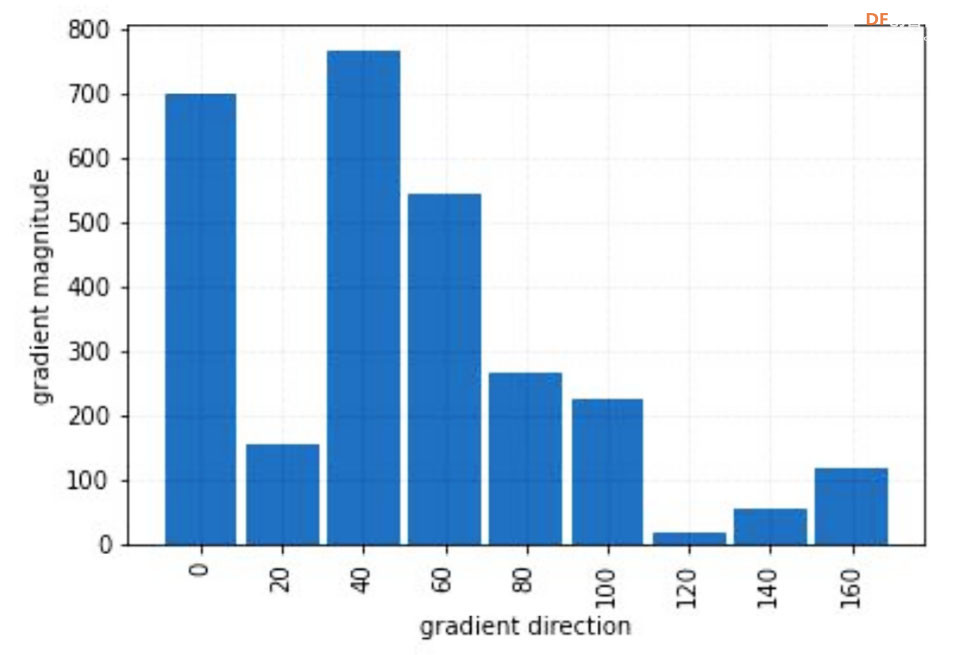 绘制向量图,将直方图的9个数据绘制成向量图,下图5中共有9个红色箭头,每个箭头依次为直方图0度、20度...160 度对应的数值。由此可见,通过 HOG特征处理,一幅 8x8 像素的图片会得到一个有9个数值的向量,即为HOG 特征向量结果。  (4)HOG特征提取步骤 通过上面的学习,我们已经掌握了提取HOG特征的原理。接下来,我们将以一张图像为例,讲解一张图像的HOG特征提取步骤。比如图6,利用 HOG 特征来提取出图像中大象部分的轮廓。 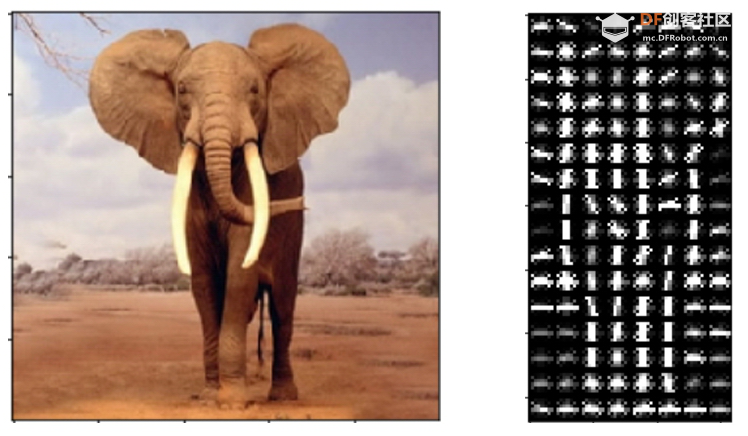 一般情况下,提取一幅图像的 HOG 特征分为四步:(1)图像预处理,包括灰度化、Gamma 校正、图像裁剪及尺寸调整;(2)划分 cell,计算HOG 特征;(3)组成 block,归一化; (4)输出 HOG 特征。 (1)图像灰度化、图像裁剪及缩放:一般会先将图片灰度化,再裁剪和缩放到合适大小。 以下图7为例,右1是原图,将右1灰度化使其具有明显的轮廓,得到右2;将右2做裁剪,得到左2;将左2缩放,获取尺寸为 128x64的右1。  图像灰度化时,有时灰度图会过于明亮或暗沉,导致轮廓特征丢失,此时我们可以使用 Gamma 校正来调整图片亮度,使其具有明显的轮廓。注意:如果灰度图本身特征明显,就不需要做 Gamma 校正了。Gamma 校正不是 HOG 特征的必须步骤 (2)划分 cell计算HOG 特征:通过图像预处理,我们获得了尺寸为 128x64 的灰度图,接下来,我们来提取这张图的 HOG 特征。一个 8x8 的像素群,通过梯度计算和直方图,可以获得一个有9个数值的HOG 特征向量。当我们计算一幅 128x64 的灰度图的HOG 特征时,只需要将图片划分成多个 nxn 的像素群,称为 cell, 然后分别计算每一个cell的HOG 特征向量。 比如我们取n为 8,将图像将划分成多个 8x8 像素的 cell。如图8-B每个白框即为1个cell。依次计算出每一个cell的HOG 特征向量,将它们绘制到一起,如图8-C,即为一幅图像的 HOG 特征。 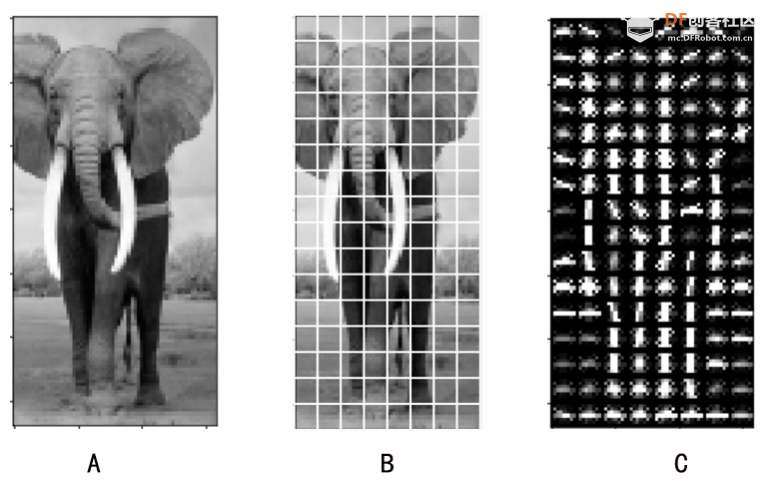 对于计算机来说,每个cell的向量有9个数值。一幅 128x64 的图像共有16x8=128 个 cell,所以一幅 128x64的图像的HOG 特征向量有 128x9=1152个数值。 (3)block 归一化:由于局部光照的变化以及图片不同区域对比度的差异,使得梯度强度的变化范围非常大。这就需要对梯度的强度做归一化,归一化的办法是将 mxm 个 cell 组成一个bolck,对block 做归一化。比如取 m=2,用 2x2 个 cell 组成一个 block,如下图9,黑框圈出的即为一个 block。  (4)输出HOG特征向量:一幅 128x64的灰度图,划分成 8x8的cell和2x2的block,block归一化前,图像的HOG 特征向量有16x8x9=1152个数值;block 归一化后,图像的图像的HOG 特征向量有 7x15x36=3780 个数值。 【电路连线】 本次电路连线如下图10所示,LED模块、蜂鸣器模块分别接拿铁熊猫智能终端拓展板D5、D4口。 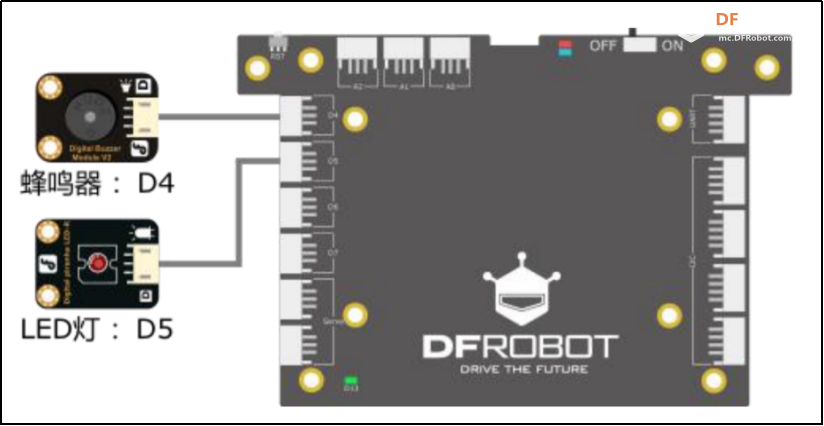 【制作步骤】 步骤一:采集训练数据,为数据打标签。 (1)准备数据 首先,我们需要准备SVM分类器的训练数据,包括正训练集和负训练集。一般会建两个文件夹,一个放正向训练集图片,一个放负向训练集图片。在实际应用过程中,数据准备有两种方式。方式一:从网络上收集一些动物的图片,这些图片中应包含大象的图片(正数据集)和非大象的图片(负数据集),以此来作为大象检测的数据集。方式二:我们可以使用拿铁熊猫智能终端所配的摄像头进行实地采集。 方式一:本例中我们使用网上下载图片的方式。我们将大象的数据集文件夹命名为elephant_dataset,并在其根目录下建立两个子文件夹pos和neg,文件夹pos中为大象的图片,文件夹neg中为非大象图片。将“elephant_dataset”文件夹打包成elephant_dataset.zip。登陆格物象课程平台,上传elephant_dataset.zip压缩包到大象识别文件夹下。利用解压程序将压缩包解压,代码如下所示。 import zipfile with zipfile.ZipFile("elephant_dataset.zip", 'r') as zip_ref: zip_ref.extractall("elephant_dataset") 解压后分别查看neg和pos文件夹如下图11,12所示,此时我们已经建立的正向和负向数据集。   方式二:拿铁熊猫智能终端拍摄采集数据集,如图13所示拿出摄像头延长线,一端与摄像头连接,另外一端与笔记本电脑的USB口连接。  连接成功后在格物象平台上会弹出如图14所示对话框,选择相应的拍照设备,此处为“DFRobot(0701:0704)” 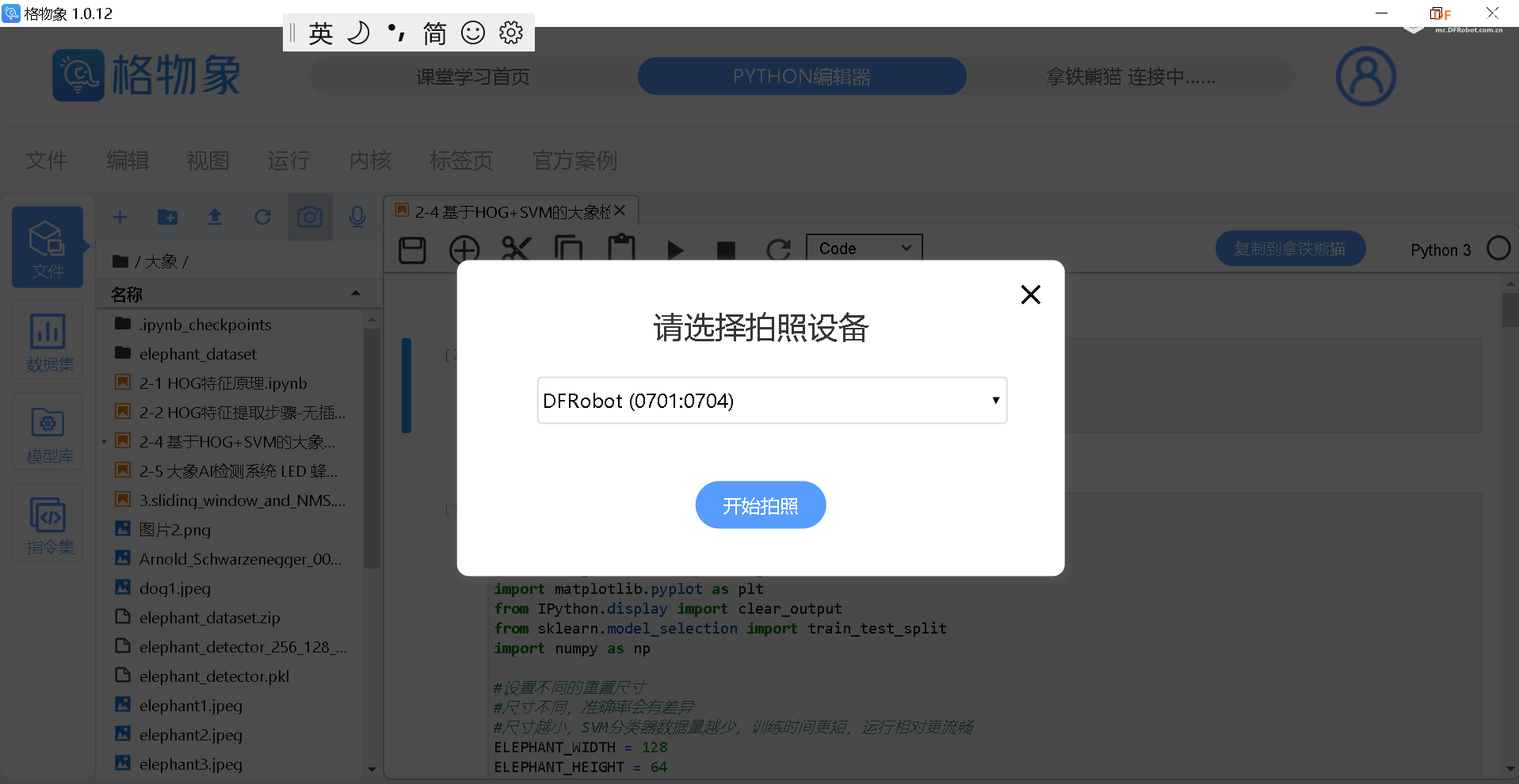 拍照设备选择好后,进入拍照界面如图15所示,点击“拍照”按钮拍摄图片,拍摄完成后点击“上传图片”。此时在格物象平台对应的文件夹中就会出现拍摄的图片。 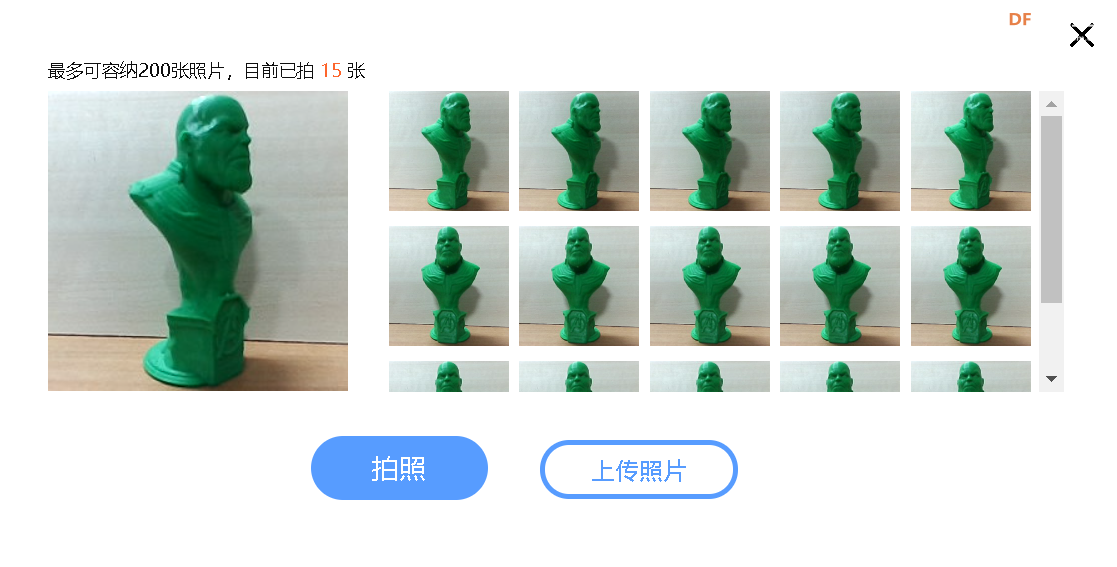 在获取HOG 特征时,我们可以将原图重置成不同的尺寸,比如128x64、160x120、256x128 等。尺寸不同,会使SVM分类器的准确率有差异。尺寸为128x64时,准确率为67;尺寸为160x120时,准确率为69;尺寸为 256x128时,准确率为 70。需要注意的是,尺寸越大,最后生成的 HOG 特征向量数据量越多,这会造成 SVM 训练的时间变长,也会在后面使用SVM分类器的时候,造成卡顿。所以在本程序中,我们使用 128x64的尺寸,大家也可测试使用其他尺寸。
(2)数据打标签 获取HOG 特征,并且在计算机中将大象图片的HOG 特征打上标签“1”,将非大象图片的 HOG 特征打上标签“0”,具体程序如下所示。 (3)划分数据集 数据集导入后,需要对其进行划分为:训练集和测试集,这需要我们自己在程序中实现数据集的划分。比如,在大象识别的数据集中,没有明确给出训练集和测试集,所以我们需要先导入所有数据,然后通过程序进行划分。 步骤二:SVM 分类训练,生成模型。 完成对数据准备以后,进行SVM训练,使用训练集中的数据进行大象检测的训练。训练完成后,会生成一个后缀名为“.pkl”的文件,这就是我们创建的SVM分类器。  步骤三:利用测试数据,查看 SVM 分类准确率。 完成SVM的训练后,将前面我们已经划分的测试集放入SVM分类器中,测试准确率。  步骤四:提取HOG 特征,进行SVM 预测。 至此我们已经成功的创建了一个SVM 分类器,接下来,我们可以将任意一张图片放到这个分类器中,预测图中是否有大象。预测结果为“1”表示有大象,预测结果为“0”表示没有大象。比如,我们可以分别预测大象、犀牛、狗的图片。    5. 测试运行 登陆格物象课程平台在“PYTHON 编辑器”界面中,打开编辑好的“大象AI检测系统”的程序(具体程序如下所示),点击“复制到拿铁熊猫”,等待程序的部署完成后,切换到拿铁熊猫界面,并将上述过程中训练好的模型“elephant_detector.pkl”复制到拿铁熊猫终端下; #大象AI检测系统  用事先准备好的老虎、大象的图片放置于拿铁熊猫智能终端摄像头前,检测识别的结果,当检测到大象时,LED亮起,蜂鸣器报警;没有检测出大象时,则不做任何的提示。   |



 沪公网安备31011502402448
沪公网安备31011502402448© 2013-2026 Comsenz Inc. Powered by Discuz! X3.4 Licensed


 置顶卡
置顶卡 变色卡
变色卡 千斤顶
千斤顶




 萌萌哒新人
萌萌哒新人
 活跃会员
活跃会员
 宣传大使
宣传大使
 版主限定
版主限定
 牛X认证
牛X认证
 创作达人
创作达人
 小蘑菇
小蘑菇
 蘑菇人
蘑菇人
 蘑菇老人
蘑菇老人
 荣誉教师
荣誉教师
 编辑选择奖
编辑选择奖
 编辑选择奖
编辑选择奖
 编辑选择奖
编辑选择奖
 ARD DAY
ARD DAY
 编辑选择奖
编辑选择奖
 创客造
创客造
 编辑选择奖
编辑选择奖
 编辑选择奖
编辑选择奖
 编辑选择奖
编辑选择奖
 编辑选择奖
编辑选择奖






