|
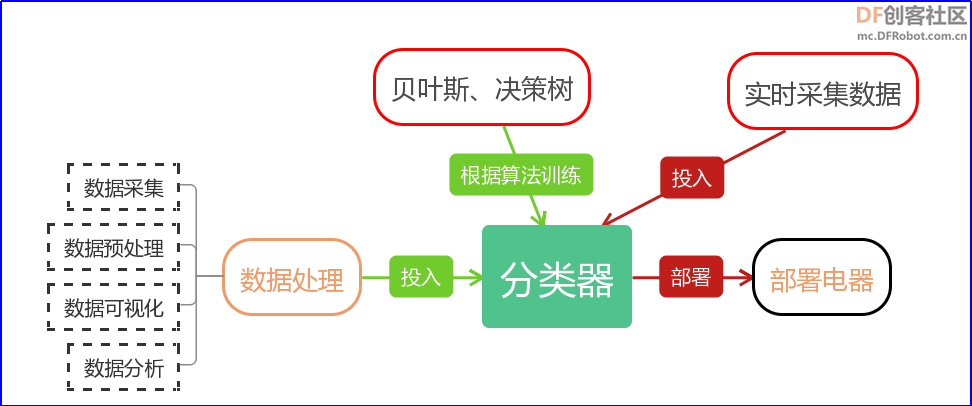
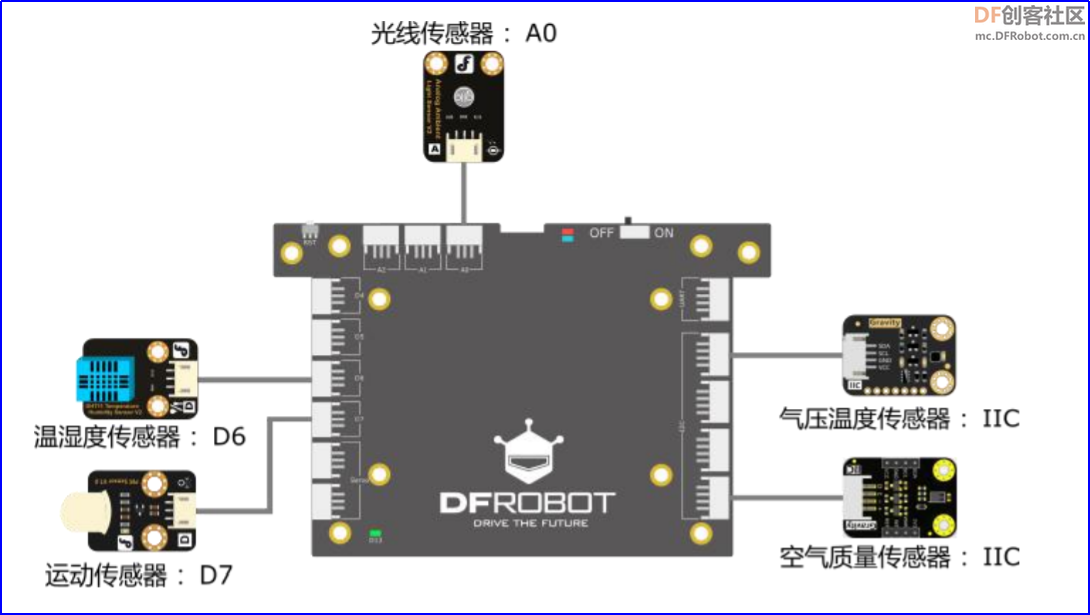
AI实验——基于用户行为数据分析的智能家居(1) 【项目源起】 随着科技的进步和人们生活水平的提高,人们对智能家居环境的要求也越来越高,如何满足人们家居智能化、个性化的要求是当前智能家居研究的目标。然而目前智能家居系统大多还处于一种单一的“机械式”自动化模式,其缺陷主要为“智能化程度低”。 【项目简介】 智能家居要实现真正意义上的智能,需要针对用户行为数据进行分析,让家居系统能够根据用户习惯自动部署电器,以达到智能生活的目的。本项目中我们通过学习数据处理和机器学习的知识,设计一套基于用户行为数据分析的智能家居。具体工作流程如图1所示 图1基于用户行为数据分析的智能家居流程 本项目通过拿铁熊猫智能终端配合相关传感器采集用户数据,进行特征提取和模型训练,从而形成一个基于用户行为数据分析的个性化模型。在实际应用的过程中,当遇到数据进入模型可为用户自动做出是否打开空调的预测。 【项目原理】 基于用户行为数据分析的智能家居,在实施层面具体分为如下几个过程数据处理、模型训练、部署电器如图2所示,本文主要介绍数据处理这块的内容。 数据处理的一般流程为:数据采集、数据预处理、数据分析和数据可视化。这里我们利用拿铁熊猫智能终端及相关传感器采集数据并完成数据的处理的过程。 (1)数据采集:利用一种装置,从系统外部采集数据并输入到系统内部的一个接口。数据采集技术广泛应用在各个领域。比如传感器、摄像头,麦克风,都是数据采集工具。除了上述方法外,我们还可以从从网络获取数据。 (2)数据预处理:由于采集到的数据可能有缺失、重复、错误或不统一,因此删除重复数据、补全缺失数据、校正错误数据和将数据处理成统一的标准。数据预处理的常用方法有数据清洗、数据编码、数据归一化或标准化等。数据预处理的过程就是将数据标准化的过程。 (3)数据可视化:是指将数据以恰当的方式呈现出来。数据可视化的作用是便于人们理解和使用数据,具有直观、生动和易于理解的优势。数据可视化的常用方法有折线图、直方图、柱状图、散点图等。 (4)数据分析:指运用恰当的分析方法和工具,对整理后的数据加以研究和总结,从中提取规律,最终形成结论。数据分析的常用方法有相关分析、对比分析、平均分析等。 【硬件器材】 房间中采用的数据有温度、湿度、气压、二氧化碳浓度数据的变化,这些因素都有可能导致我们打开或关闭空调。为此我们使用温湿度传感器、环境光传感器、气压传感器、空气质量传感器、运动传感器,采集多种数据。具体硬件器材如表1,电路连线如图3所示。 序号 | | | | | | | | | | | | | | | | | | | | | | | | | | | | Gravity: DHT11温湿度传感器(Arduino兼容) | | | | | | | | | | |
表1器材列表 【采集数据】 我们使用传感器采集家庭各项数据,并将采集到的数据处理成表格,方便后续使用。采集到的数据可以保存为不同格式的文件,如csv文件、txt文件。其中,csv文件表示将数据表格存储为纯文本,每一行代表一条数据,每一条数据包含了一个值或由逗号分隔的多个值。例如,下图中,左侧为csv文件,右侧为原表格。 #导入相关库
- import os.path
-
- import csv
-
- import time
-
- from pinpong.board import Board,Pin,DHT11,ADC
-
- import datetime
-
- from datetime import timezone
-
- import pytz
-
- from pinpong.libs.dfrobot_bmp388 import BMP388
-
- from pinpong.libs.dfrobot_ccs811 import CCS811
-
-
-
- sampling_interval = 3# 采样间隔 3s
-
- Board("leonardo").begin()
-
- PIR_pin = Pin(Pin.D7, Pin.IN) # 创建运动红外检测数字引脚实例
-
- ambient_light_pin = ADC(Pin(Pin.A0))# 创建环境光模拟引脚实例
-
- dht11 = DHT11(Pin(Pin.D6)) # 创建DHT11实例
-
- bmp = BMP388()# 创建BMP实例
-
- ccs811 = CCS811()# 创建ccs811实例
-
-
-
- now = datetime.datetime.now()
-
- date = now.strftime("%Y_%m_%d")
-
- file_name = 'multi_sensors_data_logger_{}.csv'.format(date)
-
- file_exists = os.path.isfile(file_name)
-
- weekdays = {0:"周一",1:"周二",2:"周三",3:"周四",4:"周五",5:"周六",6:"周日"}
-
-
-
- global index_
-
- index_ = 1
-
-
-
- def log_data(idx,ac_status):
-
- with open(file_name, 'a', newline='') as csvfile:
-
- field_names = ['index','business_day','PIR','working_time', 'light', 'temperature', 'humidity', 'pressure', 'co2', 'if_AC']
-
- writer = csv.DictWriter(csvfile, fieldnames=field_names)
-
- if not file_exists:
-
- writer.writerow(
-
- {'index':'序号','business_day':'工作日','PIR':'运动检测','working_time':'工作时段','light':'环境光', 'temperature':'温度',
-
- 'humidity':'湿度','pressure':'气压','co2':'二氧化碳','if_AC':'是否开空调'})
-
-
-
- weekday = weekdays[datetime.datetime.today().weekday()]# 工作日
-
- now = datetime.datetime.now() # 当前的时间(世界时间)
-
- now=now.replace(tzinfo=timezone.utc).astimezone(tz=pytz.timezone("Asia/Shanghai"))
-
- if now.hour < 11 and now.hour >9:
-
- period = '早晨'
-
- elif now.hour<13 and now.hour>=11:
-
- period = '中午'
-
- elif now.hour<16 and now.hour>=13:
-
- period = '下午'
-
- elif now.hour<18 and now.hour>=16:
-
- period = '傍晚'
-
- else:
-
- period = '夜间'
-
- PIR = PIR_pin.read_digital() # 红外光读取
-
- light = ambient_light_pin.read() # 环境光读取
-
- try:# DHT11 温湿度读取
-
- temp = dht11.temp_c() #读取摄氏温度
-
- humi = dht11.humidity() #读取湿度
-
- except:
-
- temp = None
-
- humi = None
-
- # BMP388 气压读取
-
- pressure = bmp.pressure_pa() #读取气压
-
- if(ccs811.check_data_ready()): # CCS811 二氧化碳读取
-
- co2 = ccs811.CO2_PPM()
-
- else:
-
- co2 = None
-
- if_AC = ac_status # 空调状态
-
- writer.writerow(
-
- {'index':idx,'business_day':weekday,'PIR':PIR,'working_time':period,'light':light, 'temperature':temp, 'humidity':humi,'pressure':pressure,'co2':co2,'if_AC':if_AC})
-
- print("data logged:business_day:{} working_time:{} PIR:{} light:{} temperature:{} humidity:{} pressure:{} co2:{}".format(weekday,period,PIR,light,temp,humi,pressure,co2))
-
- while True: # 每隔一段时间进行一次环境数据采集
-
- log_data(index_,0)
-
- index_ += 1
-
- time.sleep(sampling_interval)
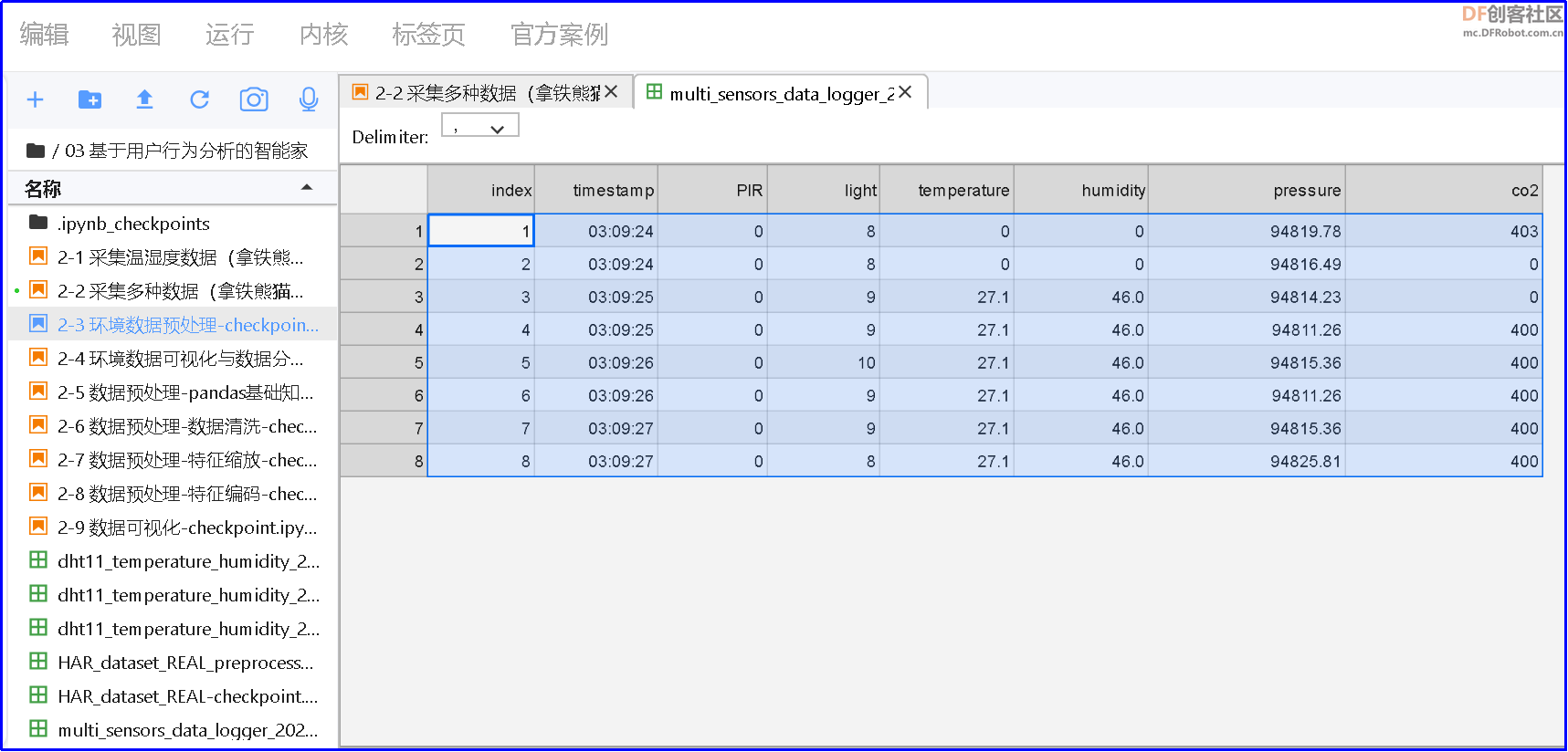
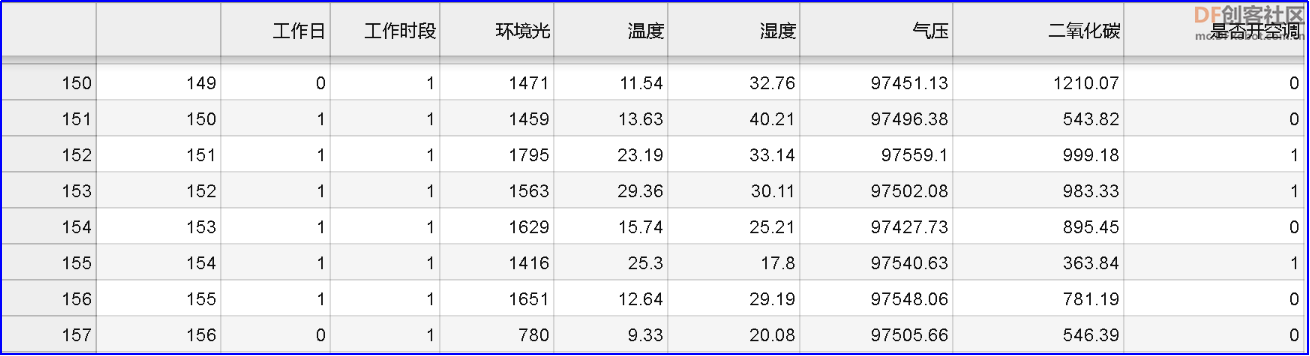
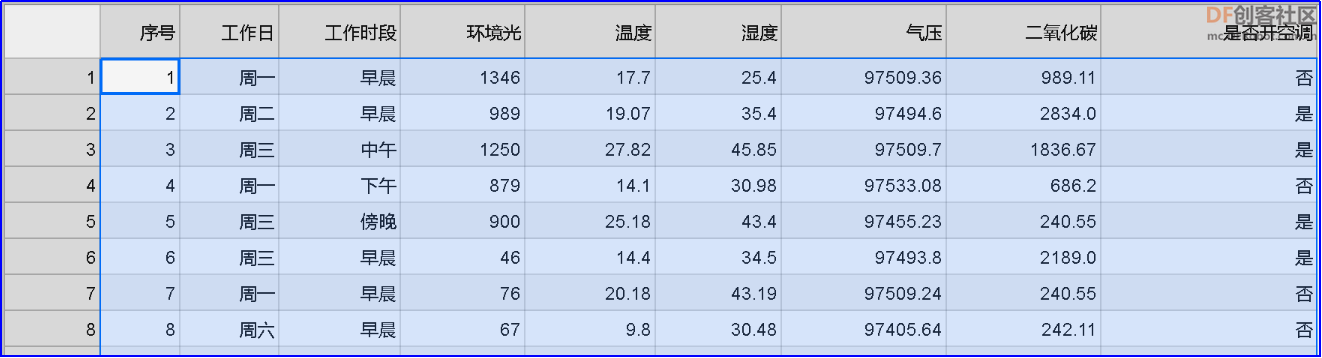
在左侧文件夹中,会生成一个名称为“multi_sensors_data_logger_{}.csv”,停止程序运行,再打开 csv 文件,如下图,第一列为序号,第二列为时间戳,第三列为人体红外检测,第四列为环境光,第五列为温度,第六列为湿度,第七列为气压,第八列为 CO2 浓度。 为了方便处理数据,需要将生成的 csv 文件保存到“PYTHON 编辑器”中。操作方法如下: (1)在格物象“拿铁熊猫”窗口,右键点击 csv 文件,在弹出的界面中,点击“下载”,将 csv 文件下载到本地电脑; (2)再打开格物象“PYTHON 编辑器”窗口,点击上传按钮,选中本地的csv文件,上传到“PYTHON 编辑器”中。 上传完成后,即可在“PYTHON 编辑器”中,查看刚刚上传的 csv文件。 【制作数据集】 在智能家居系统中,最常见的应用就是部署电器的开关。这里以空调开关为例,所以我们采集家中各项环境数据,以及空调开关数据。经过通过长时间的采集,可形成个性化的家庭环境数据集。我们可在拿铁熊猫智能终端的扩展板上增加一个按钮,每次开空调的时,同步按下按钮。除此之外,我们还能采集工作日数据和工作时段数据。这样,我们就能制作一个家庭环境数据集,需要采集的数据有工作日、工作时段、环境光、温度、湿度、气压、二氧化碳数据、是否开空调。这里我们已经提前做好了数据集,为文件“HAR_dataset_REAL.csv”,双击打开这个 csv,如下图,包含多种家中环境数据,如工作日、环境光、温度、湿度、气压、二氧化碳浓度、是否开空调等。 【数据预处理】 采集到的原始数据有可能缺失、重复、错误或不统一,因此需要删除重复数据、补全缺失数据、校正错误数据和将数据处理成统一的标准,这就是数据预处理的过程。对于数据表“HAR_dataset_REAL.csv”,需要做一下几项预处理:第一步:特征编码,将文字型数据处理成数值型数据。第二步:数据清洗,删除多余的“序号”列。第三步:保存预处理的数据表为 csv 文件。 (1)特征编码:在机器学习中,大多数算法都只能够处理数值型数据,不能处理文字,然而在现实中,许多数据集中都会有文字。比如下表中有很多是文字型数据。 在这种情况下,为了让数据适应算法,我们需要进行特征编码,将文字转换为数值。根据数据特征种类不同,有对应的特征编码方法,常用编码方法有标签编码、顺序编码、独热编码。注意:标签编码通常对应二值数据特征,只有两类数据,例如“是否开空调”中的“是、否”;顺序编码通常针对于有序类别数据,这类的数据,往往有一定顺序性;独热编码通常针对一些没有顺序关系的数据,独热编码又称一位有效编码,指按照指定顺序将类别转换为只有0、1 状态的数值编码。 - import pandas as pd
-
- import numpy as np
-
- import matplotlib.pyplot as plt
-
- import time
-
- from sklearn.model_selection import train_test_split
-
- from sklearn.naive_bayes import GaussianNB, BernoulliNB, MultinomialNB
-
- from sklearn import metrics
-
- from sklearn.preprocessing import LabelEncoder, OrdinalEncoder, OneHotEncoder
-
- import joblib
-
- # 导入预先收集好的数据集
-
- HAR_df = pd.read_csv("HAR_dataset_REAL.csv")
-
- HAR_df.head(10)
-
- # 特征编码
-
- #编码 1 是否开空调
-
- ac_status = HAR_df.iloc[:]['是否开空调'].values # df.iloc[:,-1].values
-
- labelencoder_ac = LabelEncoder()
-
- ac_status = labelencoder_ac.fit_transform(ac_status)
-
- HAR_df['是否开空调'] = ac_status
-
- HAR_df.head()
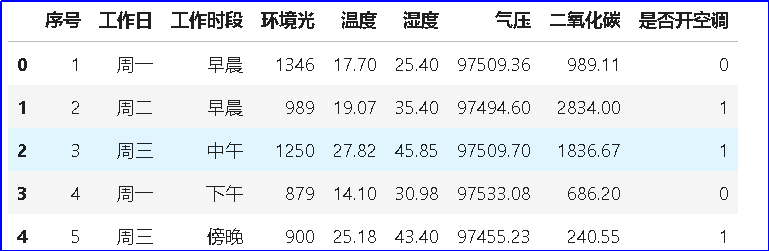
# 特征编码 # 编码2 时间段 - HAR_df['工作时段'] = HAR_df['工作时段'].replace(['早晨','中午','下午','傍晚'],'工作时间段')
-
- HAR_df['工作时段'] = HAR_df['工作时段'].replace(['夜间'],'休息时间段')
-
- period = HAR_df.iloc[:][['工作时段']].values
-
- ordinalencoder = LabelEncoder()
-
- period = ordinalencoder.fit_transform(period.ravel())
-
- HAR_df['工作时段'] = period
-
- HAR_df.head(25)
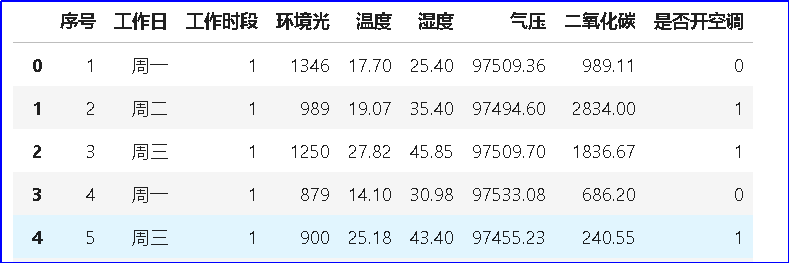
# 特征编码 - # 编码3 工作日
-
- HAR_df['工作日'] = HAR_df['工作日'].replace(['周一','周二','周三','周四','周五'],'工作日')
-
- HAR_df['工作日'] = HAR_df['工作日'].replace(['周六','周日'],'假日')
-
- daytype = HAR_df.iloc[:][['工作日']].values
-
- ordinalencoder = LabelEncoder()
-
- daytype = ordinalencoder.fit_transform(daytype.ravel())
-
- HAR_df['工作日'] = daytype
-
- HAR_df.head()
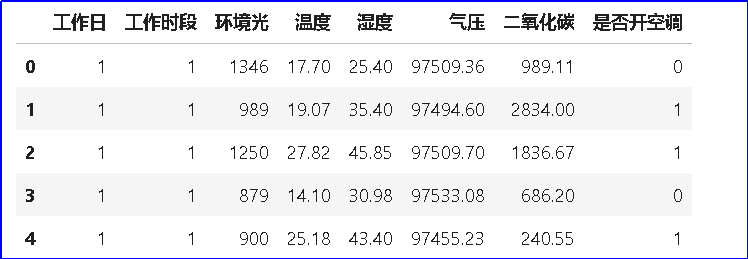
(2)数据清洗:采集到的原始数据,由于数据可能有缺失、重复、错误或不统一的情况,通常将这些数据进行数据清洗。在上述数据集中,可以删除多余的序号列。 - # 删除多余的序号列
-
- HAR_df = HAR_df.drop('序号',axis = 1)
-
- HAR_df.head(10)
-
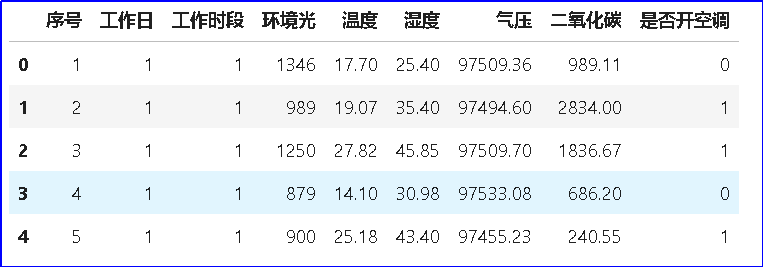
最后,我们将预处理后的数据表保存成csv文件即可。 - # 保存预处理后的数据为csv文件
-
- HAR_df.to_csv("HAR_dataset_REAL_preprocessed.csv",index = False)
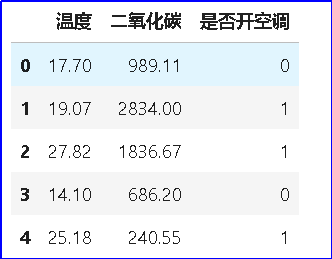
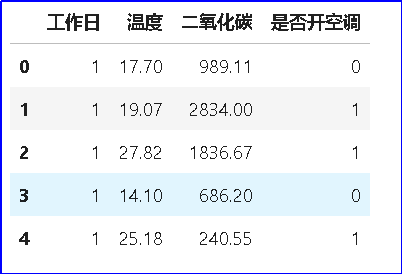
运行程序在程序所在的文件夹生成名为“HAR_dataset_REAL_preprocessed.csv”的 csv 文件。打开该文件可查看预处理的数据。 【数据可视化】 将数据以图形图像等形式表示,直接呈现数据中蕴含信息的处理过程。数据分析,指运用恰当的分析方法和工具,对整理后的数据加以研究和总结,从中提取有价值的信息,最终形成结论。数据可视化与数据分析往往是同时进行的。可以先通过绘制折线图、直方图或散点图的方式,可视化出数据,再分析数据;也可以在分析数据时,辅以数据可视化。 温度或二氧化碳浓度会影响开空调吗? 思考第一个问题:观察数据表,请问家中的温度或二氧化碳浓度会影响开空调吗?如果直接看表中的数据,比较难得出结论,但我们可以绘制一个散点图,来帮助我们判断。现在,我们将预处理后的表格绘制成散点图,表征温度或二氧化碳浓度是否会影响开空调。 #环境数据可视化与数据分析 - # 导入相关库
-
- import pandas as pd
-
- import numpy as np
-
- import matplotlib.pyplot as plt
-
- import time
-
- from sklearn.model_selection import train_test_split
-
- from sklearn.naive_bayes import GaussianNB, BernoulliNB, MultinomialNB
-
- from sklearn import metrics
-
- from sklearn.preprocessing import LabelEncoder, OrdinalEncoder, OneHotEncoder
-
- import joblib
-
-
-
- # 导入预处理后的数据集
-
- HAR_df = pd.read_csv("HAR_dataset_REAL_preprocessed.csv")
-
- HAR_df.head(10)
-
-
-
- # 新建一个dataframe,保留温度,二氧化碳和是否开空调三个特征
-
- HAR_df_temp_co2 = HAR_df[['温度','二氧化碳','是否开空调']]
-
- HAR_df_temp_co2.head()
- # 绘制散点图
-
- figsize = (20,6)
-
- alpha = 0.6
-
- marker_size = 50
-
- fig, axes = plt.subplots(1, 1)
-
- fig.suptitle("Will temperature and CO2 concentration affect the opening of the air conditioner?",fontsize=16)
-
- HAR_df_temp_co2.loc[HAR_df_temp_co2['是否开空调'] == 1].plot.scatter(x="二氧化碳",y="温度",c='b',marker='o',alpha = alpha,s=marker_size,ax=axes, figsize=figsize,label = 'AC_ON')
-
- HAR_df_temp_co2.loc[HAR_df_temp_co2['是否开空调'] == 0].plot.scatter(x="二氧化碳",y="温度",c='r',marker='o',alpha = alpha,s=marker_size,ax=axes, figsize=figsize,label = 'AC_OFF')
-
- axes.set_xlabel("CO2 Concentration")
-
- axes.set_ylabel("Temperature")
散点图中,蓝点表示开空调,红点表示不开空调,坐标值横轴为二氧化碳浓度,纵轴为温度。 从散点图可以看出:在温度较高或者二氧化碳浓度时较高时,开空调的次数更多。 思考第二个问题:工作日与非工作日,对开空调有影响吗? 同样,我们通过绘制散点图来观察。 示例程序:新建一个数据表,保留工作日,温度,二氧化碳和是否开空调三个特征 - # 新建一个dataframe,保留工作日,温度,二氧化碳和是否开空调三个特征
-
- HAR_df_busday_temp_co2 = HAR_df[['工作日','温度','二氧化碳','是否开空调']]
-
- HAR_df_busday_temp_co2.head()
- # 绘制散点图
-
- ig, axes = plt.subplots(1, 2)
-
- fig.suptitle("Will temperature and CO2 concentration affect the opening of the air conditioner?",fontsize=16)
-
- axes[0].title.set_text("weekend")
-
- axes[1].title.set_text("business days")
-
- for idx,axis in enumerate(axes):
-
- HAR_df_busday_temp_co2.loc[(HAR_df_busday_temp_co2['工作日'] == idx) & (HAR_df_busday_temp_co2['是否开空调'] == 1)].plot.scatter(x="二氧化碳",y="温度",c='b',marker='o',alpha = alpha,s=marker_size,ax=axis, figsize=figsize,label = 'AC_ON')
-
- HAR_df_busday_temp_co2.loc[(HAR_df_busday_temp_co2['工作日'] == idx) & (HAR_df_busday_temp_co2['是否开空调'] == 0)].plot.scatter(x="二氧化碳",y="温度",c='r',marker='o',alpha = alpha,s=marker_size,ax=axis, figsize=figsize,label = 'AC_OFF')
-
- axis.set_xlabel("CO2 Concentration")
-
- axis.set_ylabel("Temperature")
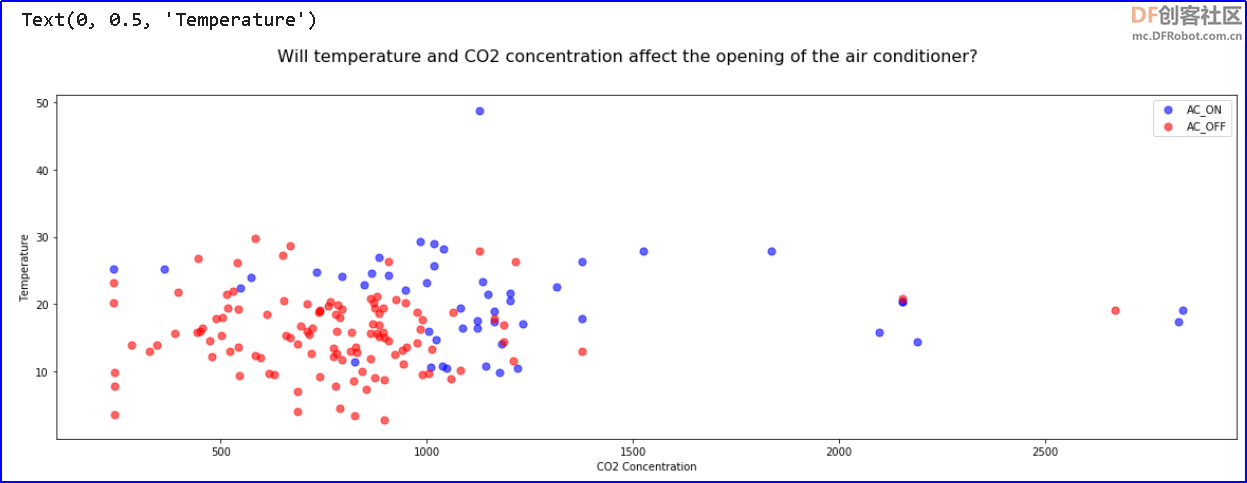
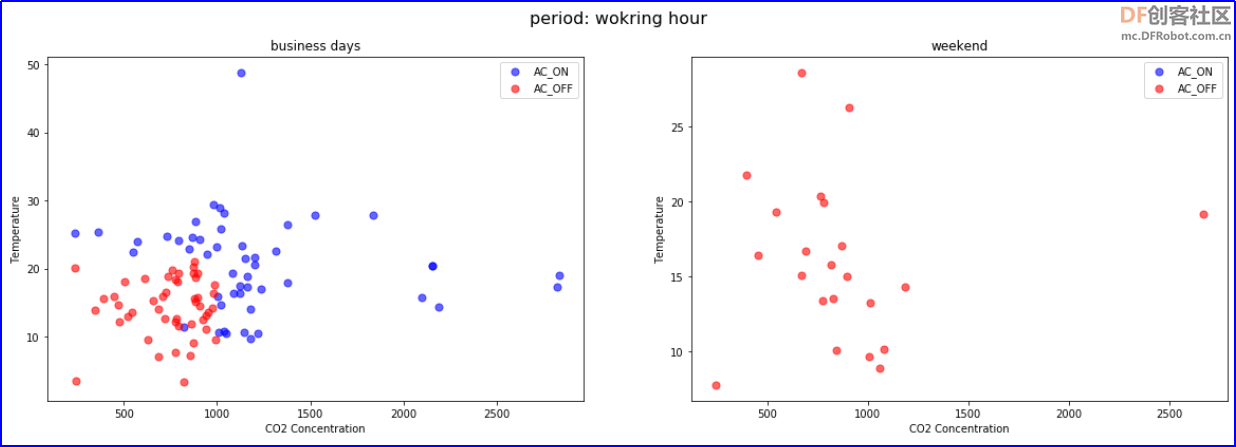
从散点图中可以看出:周末基本不开空调,工作日开空调次数更多。 试一试:尝试通过数据可视化,分析工作时段与非工作时段对开空调的影响。 参考程序:新建两个数据表,保留工作日,工作时段,温度,二氧化碳和是否开空调三个特征。 - # 新建两个dataframe,保留工作日,工作时段,温度,二氧化碳和是否开空调三个特征。
-
- HAR_df_busday_workinghour_temp_co2 = HAR_df[['工作日','工作时段','温度','二氧化碳','是否开空调']].loc[HAR_df['工作时段'] == 1]
-
- HAR_df_busday_nonworkinghour_temp_co2 = HAR_df[['工作日','工作时段','温度','二氧化碳','是否开空调']].loc[HAR_df['工作时段'] == 0]
-
- HAR_df_busday_workinghour_temp_co2.head()

- # 绘制散点图
-
- figsize = (20,6)
-
- alpha = 0.6
-
- marker_size = 50
-
- wokring_hour = ["non wokring hour","wokring hour"]
-
- for idx,wokring_hour in enumerate(wokring_hour):
-
- fig, axes = plt.subplots(1, 2)
-
- fig.suptitle("period: {}".format(wokring_hour),fontsize=16)
-
- axes[1].title.set_text("weekend")
-
- axes[0].title.set_text("business days")
-
- HAR_df_busday_workinghour_temp_co2.loc[(HAR_df_busday_workinghour_temp_co2['工作日'] == idx) & (HAR_df_busday_workinghour_temp_co2['是否开空调'] == 1)].plot.scatter(x="二氧化碳",y="温度",c='b',marker='o',alpha = alpha,s=marker_size,ax=axes[0], figsize=figsize,label = 'AC_ON')
-
- HAR_df_busday_workinghour_temp_co2.loc[(HAR_df_busday_workinghour_temp_co2['工作日'] == idx) & (HAR_df_busday_workinghour_temp_co2['是否开空调'] == 0)].plot.scatter(x="二氧化碳",y="温度",c='r',marker='o',alpha = alpha,s=marker_size,ax=axes[0], figsize=figsize,label = 'AC_OFF')
-
- HAR_df_busday_nonworkinghour_temp_co2.loc[(HAR_df_busday_nonworkinghour_temp_co2['工作日'] == idx) & (HAR_df_busday_nonworkinghour_temp_co2['是否开空调'] == 1)].plot.scatter(x="二氧化碳",y="温度",c='b',marker='o',alpha = alpha,s=marker_size,ax=axes[1], figsize=figsize,label = 'AC_ON')
-
- HAR_df_busday_nonworkinghour_temp_co2.loc[(HAR_df_busday_nonworkinghour_temp_co2['工作日'] == idx) & (HAR_df_busday_nonworkinghour_temp_co2['是否开空调'] == 0)].plot.scatter(x="二氧化碳",y="温度",c='r',marker='o',alpha = alpha,s=marker_size,ax=axes[1], figsize=figsize,label = 'AC_OFF')
-
- axes[0].set_xlabel("CO2 Concentration")
-
- axes[0].set_ylabel("Temperature")
-
- axes[1].set_xlabel("CO2 Concentration")
-
- axes[1].set_ylabel("Temperature")
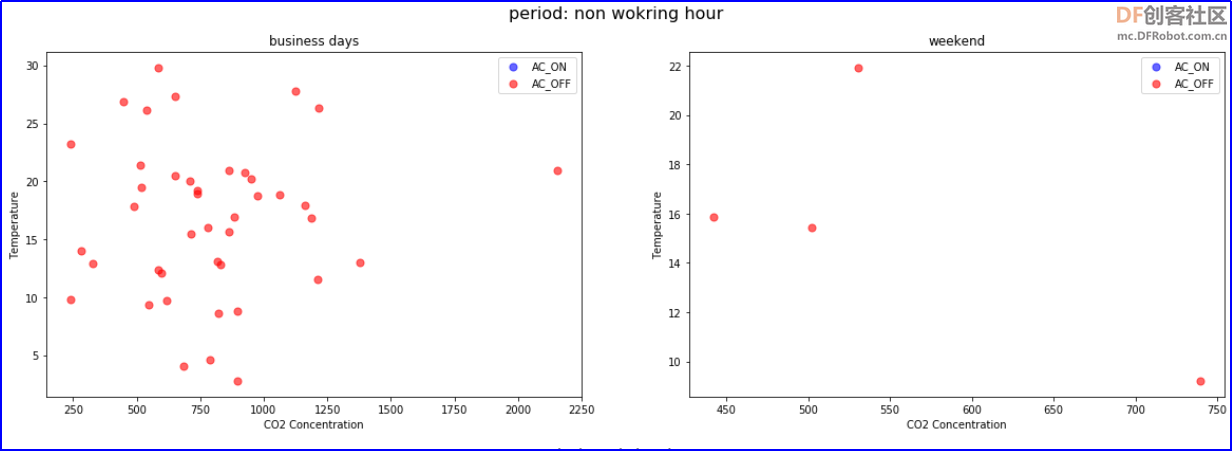 
本文内容主要介绍数据的处理,了解数据处理的一般过程:数据采集、数据预处理、数据分析和数据可视化。通过智能硬件采集数据,完成数据预处理,并形成数据可视化图表,帮助分析预判结论,后面我们将学习运用相应算法提取数据特征完成模型训练。
| 
 DFROBOT317
DFROBOT317



 沪公网安备31011502402448
沪公网安备31011502402448

 置顶卡
置顶卡 变色卡
变色卡 千斤顶
千斤顶

 萌萌哒新人
萌萌哒新人
 活跃会员
活跃会员
 宣传大使
宣传大使
 版主限定
版主限定
 牛X认证
牛X认证
 创作达人
创作达人
 小蘑菇
小蘑菇
 蘑菇人
蘑菇人
 蘑菇老人
蘑菇老人
 荣誉教师
荣誉教师
 编辑选择奖
编辑选择奖
 编辑选择奖
编辑选择奖
 编辑选择奖
编辑选择奖
 ARD DAY
ARD DAY
 编辑选择奖
编辑选择奖
 创客造
创客造
 编辑选择奖
编辑选择奖
 编辑选择奖
编辑选择奖
 编辑选择奖
编辑选择奖
 编辑选择奖
编辑选择奖






