|
47254| 2
|
[M10教程] 基于行空板的mediapipe图像分割人物抠图 |

|
一、实践目标 本项目在行空板上外接USB摄像头,通过摄像头来检测人物,并将人物与背景进行分割。 二、知识目标 1、学习使用MediaPipe的Selfie Segmentation模型进行人物分割的方法。 三、实践准备 硬件清单:  软件使用: Mind+编程软件x1 四、实践过程 1、硬件搭建 1、将摄像头接入行空板的USB接口。 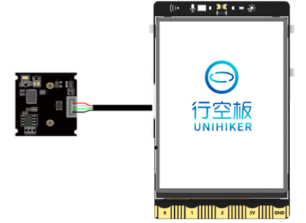 2、通过USB连接线将行空板连接到计算机。  第一步:打开Mind+,远程连接行空板 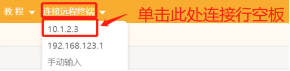 第二步:编写程序 在“行空板的文件”中找到名为AI的文件夹,在其中新建一个名为“基于行空板的mediapipe图像分割人物抠图”的文件夹,再新建一个项目文件,并命名为“main.py”。 示例程序: 3、运行调试 第一步:运行主程序 运行“main.py”程序,可以看到初始时屏幕上显示着摄像头拍摄到的实时画面,将摄像头对准人物,可以看到视频中的人物与背景分割开了,人物保留在原图上,背景替换为了灰色,呈现了抠图的效果。 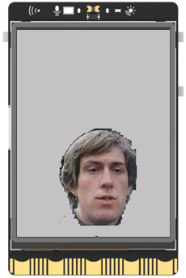 在上述的“main.py”文件中,我们主要通过opencv库来调用摄像头,获取实时视频流,然后借助MediaPipe的Selfie Segmentation模型对每一帧图像中的人物进行分割。整体流程如下, ①打开摄像头:程序首先打开摄像头获取实时视频流。 ②读取每一帧图像:在一个无限循环中,程序读取摄像头的每一帧图像。 ③图像预处理:读取到的图像首先进行翻转(因为摄像头捕获的图像通常是镜像的),然后转换为RGB格式(因为OpenCV读取的图像默认是BGR格式,而大部分的图像处理和计算机视觉算法都假定输入的图像是RGB格式的)。 ④应用自拍分割模型:将预处理后的图像输入到自拍分割模型中,模型会输出一个与输入图像大小相同的分割掩码(segmentation mask),分割掩码中的每一个像素值表示对应的图像像素是前景(即人物)的概率。 ⑤生成输出图像:根据分割掩码和原始图像生成输出图像。程序首先创建一个条件矩阵,该矩阵中的每一个元素表示对应的图像像素是否是前景。然后,程序使用numpy的where函数,根据条件矩阵生成输出图像:如果一个像素是前景,则在输出图中该像素的值为原始图像中对应像素的值;如果一个像素是背景,则在输出图像中该像素的值为指定的背景颜色。 ⑥显示输出图像:将生成的输出图像显示出来。 ⑦检查用户输入:如果用户按下ESC键,则退出循环,程序结束。自拍分割模型的原理是使用深度学习的方法学习一个从图像到分割掩码的映射关系。这个模型通常是一个卷积神经网络(Convolutional Neural Network,CNN),该网络在训练阶段需要大量的带有分割标注的图像。在训练过程中,网络通过最小化预测的分割掩码和真实的分割掩码之间的差异,逐渐学习到如何从图像中提取出人物和背景的信息。 五、知识园地 1.了解MediaPipe的Selfie Segmentation模型 MediaPipe的Selfie Segmentation模型是一个专门为移动设备优化的实时人像分割模型。该模型可以将图像中的人物和背景区分开来,从而让开发者可以在移动应用或者Web应用中实现各种有趣的效果,比如更换背景、应用滤镜等。 Selfie Segmentation模型基于移动设备优化的U-Net网络架构。U-Net是一个非常流行的深度学习网络结构,它的主要特点是其U形的网络结构,包含一个先收缩再扩张的过程,可以在提取图像的深层特征的同时保持图像的空间信息,非常适合用于图像分割任务。 Selfie Segmentation模型可以在实时视频流上运行,并且性能非常高效,即使在一些低端的移动设备上也可以流畅运行。该模型的输入是一帧RGB图像,输出是一个与输入图像大小相同的分割掩码,分割掩码中的每个像素值表示对应的图像像素是人物的概率。 MediaPipe提供了完整的模型文件和相关的API,开发者可以非常方便地在自己的应用中集成Selfie Segmentation模型。 |

1.61 KB, 下载次数: 4132
 编辑选择奖
编辑选择奖



 沪公网安备31011502402448
沪公网安备31011502402448© 2013-2026 Comsenz Inc. Powered by Discuz! X3.4 Licensed


 置顶卡
置顶卡 变色卡
变色卡 千斤顶
千斤顶






