本帖最后由 zoey不种土豆 于 2024-11-26 10:38 编辑 项目前言
Machine Medic(机械医生)是一种基于 行空板 和AI模型驱动的解决方案,它通过分析机器的声音特征来检测可能存在的运行异常并预测潜在故障,帮助工业界避免昂贵的停机时间。 项目介绍 这个项目始于我参观一家食品加工厂的经历。当我穿行于设备间,机器的轰鸣和传送带运输一件件产品的景象给我留下了深刻印象。在与操作员交谈时,我得知了一个意外的消息:只要机器停机,他们就会面临着巨大的损失,比如传送带、齿轮箱或泵的一个小故障就能导致整条生产线停摆,从而造成昂贵的生产延误。这让我思考,是否有办法在故障发生前就预测到它们? 这个项目的想法就是这样被启发的。工业机器设备在许多行业中扮演着至关重要的角色。平均而言,成千上万的机器依赖传送系统来高效地传输产品。但如果这些机器中有一个出现故障,可能会导致企业损失数小时乃至数天的生产力。 于是我决定寻求一种解决方案:利用监听设备声音进行预测性维护。就像人的心跳一样,机器也有自己以声音形式的“心跳”,每台机器都有一个独特的声音特征,而这个声音如果出现异常,就表明可能存在某种问题。通过实时分析这些声音,我们可以识别潜在问题,并在它们造成重大停机时间之前进行修复。 就这样, Machine Medic, 机械医生,诞生了。这是一个基于云的,由ai驱动的平台,通过监听机器的声音并及早检测故障,帮助行业避免不必要的停机,以避免昂贵的维修费用。 项目步骤 一、设置 “MEDIC” 系统 行空板有全面的 wiki文档 来指导你设置。我的项目使用了 开源的 Web 应用程序 Jupyter Notebook来充分利用ai构建声音模型。 设置虚拟环境(venv)之后,就可以收集用于处理和训练模型的数据了。 二、收集数据 我分别在不同设备的每个部件的 附近录制了时长为一分钟左右的 声音,共收集了5小时的音频文件。以下音频文件来自运行设备的不同部件。 这个过程可以按需定制,适用于任何为特定机器构建项目,只需遵循相同的步骤。以下是对设备传送带中某部分的录音。为了收集数据,需要在使用 Jupyter Notebook 创建的虚拟环境(venv)中运行该代码。 代码 # -*- coding: utf-8 -*-
import os
import time
from unihiker import Audio, GUI
u_gui = GUI()
audio = Audio()
text = None
buttonA = None
num_files = 5
recording_duration = 60 # 60 seconds
def start_recording():
global text, buttonA
buttonA.config(state="disabled")
for i in range(1, num_files + 1):
if text:
text.config(text=f"Recording {i}/{num_files} started...\nPlease wait...")
else:
text = u_gui.draw_text(text=f"Recording {i}/{num_files} started...\nPlease wait...", x=25, y=150, font_size=15, color='#FFFFFF')
file_name = f'machine_sound_{i}.wav'
audio.start_record(file_name)
time.sleep(recording_duration)
audio.stop_record()
text.config(text=f"Recording {i}/{num_files} completed. File saved as {file_name}")
time.sleep(3)
buttonA.config(state="normal")
background_image = u_gui.draw_image(image="1.png", x=0, y=0)
buttonA = u_gui.add_button(text="Start Recording", x=25, y=100, w=190, h=40, onclick=start_recording)
title_text = u_gui.draw_text(text='Machine Medic - Data Collection', y=50, font_size=22, color='#FFFFFF')
while True:
time.sleep(0.1) 复制代码 这个界面将运行并通过将其放置在机器的不同部位来收集声音数据
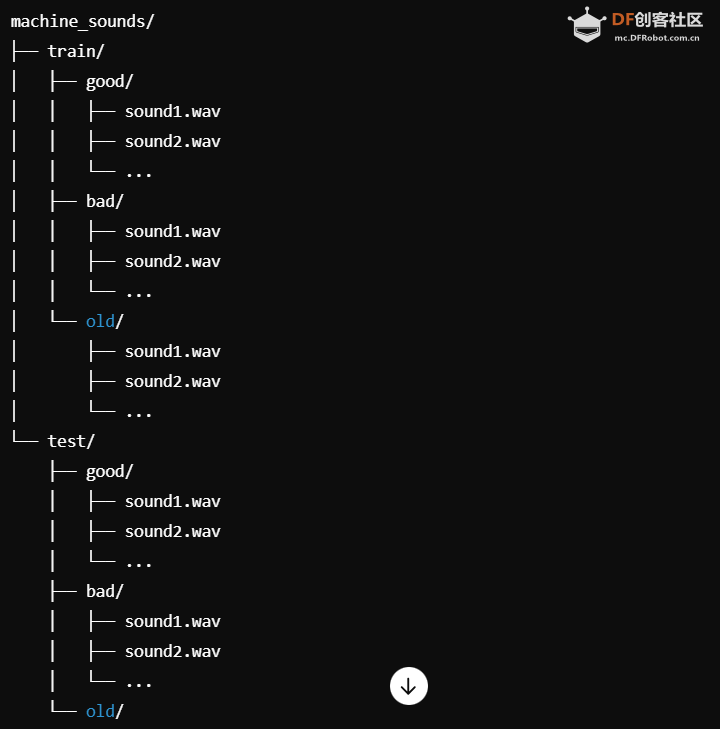
三、训练ai模型 将数据集整理到根文件夹中 。 以下是 Audio 文件排列的架构: 整理好数据集之后,接下来就是训练模型。 作者在代码中添加了许多 解释性的 注释。 代码 import os
import numpy as np
import librosa
import tensorflow as tf
import matplotlib.pyplot as plt
# 第一步:加载数据
def load_data(base_path):
X = []
y = []
# 遍历每个类别
for label in os.listdir(base_path):
label_path = os.path.join(base_path, label)
if os.path.isdir(label_path):
# 在该类别中遍历每个音频文件
for file in os.listdir(label_path):
if file.endswith('.wav'):
file_path = os.path.join(label_path, file)
# 加载音频文件
signal, sr = librosa.load(file_path, sr=None)
# 提取特征(MFCC)
mfccs = librosa.feature.mfcc(y=signal, sr=sr, n_mfcc=40) # Corrected line
mfccs = np.mean(mfccs.T, axis=0)
X.append(mfccs)
y.append(label)
return np.array(X), np.array(y)
# 定义存储您的训练和测试数据的基础路径
train_base_path = "/root/dataset/machinesounds/train" # Update this path
test_base_path = "/root/dataset/machinesounds/test" # Update this path
# 加载数据
X_train, y_train = load_data(train_base_path)
X_test, y_test = load_data(test_base_path)
# 第二步:预处理数据
# 手动编码标签
unique_labels = np.unique(y_train) # Use y_train for encoding
label_to_index = {label: idx for idx, label in enumerate(unique_labels)}
y_train_encoded = np.array([label_to_index[label] for label in y_train])
y_test_encoded = np.array([label_to_index[label] for label in y_test]) # Encode test labels
# 重塑模型
X_train = X_train.reshape(X_train.shape[0], X_train.shape[1], 1)
X_test = X_test.reshape(X_test.shape[0], X_test.shape[1], 1)
# 第三步:构建模型
model = tf.keras.Sequential([
tf.keras.layers.Conv1D(16, kernel_size=2, activation='relu', input_shape=(X_train.shape[1], 1)),
tf.keras.layers.MaxPooling1D(pool_size=2),
tf.keras.layers.Conv1D(32, kernel_size=2, activation='relu'),
tf.keras.layers.MaxPooling1D(pool_size=2),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(len(unique_labels), activation='softmax')
])
# 编译模型
model.compile(loss='sparse_categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
# 第四步:训练模型
history = model.fit(X_train, y_train_encoded, epochs=50, validation_data=(X_test, y_test_encoded))
# 第五步:评估模型
# 预测
y_pred = np.argmax(model.predict(X_test), axis=-1)
# 计算准确率
accuracy = np.sum(y_pred == y_test_encoded) / len(y_test_encoded)
print(f'Accuracy: {accuracy * 100:.2f}%')
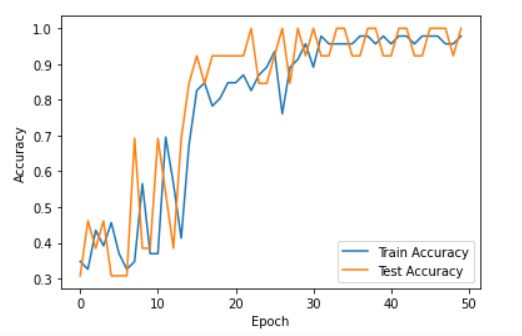
# 绘制训练历史
plt.plot(history.history['accuracy'], label='Train Accuracy')
plt.plot(history.history['val_accuracy'], label='Test Accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.legend()
plt.show() 复制代码 函数 load_data(base_path) 从目录结构中读取音频文件,其中每个文件夹代表一个标签。它处理声音文件并提取 MFCC 特征: MFCC(梅尔频率倒谱系数):用于表示音频信号的功率谱的特征,能捕捉相关的声音特性。该函数会遍历目录,使用 Librosa 加载 .wav 文件,计算每个文件的 MFCCs,并将它们平均以获得固定大小的特征向量。 五、 预处理技术 MFCC 提取: 主要的预处理步骤包括将原始音频信号转换为 MFCC,它将声音的关键特征压缩成模型可以处理的格式。标签编码: 标签从字符串转换为数值,以便与模型的输出格式兼容。训练-测试分割: 确保模型在未见过的数据上进行测试,防止过拟合。重塑: 重塑数据以符合卷积神经网络的输入要求。模型准备就绪后, 可以使用以下代码片段将模型保存到相同的目录中: model.save('my_trained_model.h5') 复制代码 这个模型将被保存在同一个目录中。 完成后,项目的其余部分将集中于构建一个图形用户界面(GUI),用于触发模型并为输入的声音提供输出。 最后的运行是为了设置图形用户界面和管理模型的后端。 使用 Jupyter Notebook,在根目录中创建一个 main 文件并运行以下代码。 确保模型名称与代码中给出的名称相匹配。模型应该存在于同一目录中。 代码 # -*- coding: utf-8 -*-
import os
import numpy as np
import librosa
import tensorflow as tf
from pinpong.extension.unihiker import *
from unihiker import Audio, GUI
import time
import threading # 导入threading用于非阻塞执行
# 载入预训练的模型
model_path = '/root/my_trained_model.h5' # 更新为你的模型路径 loaded_model = tf.keras.models.load_model(model_path)
# 载入用于预测的唯一标签
unique_labels = ["Good", "Old", "Bad"] # 用你实际的标签更新在此
# 函数用于预测机器状态
def predict_audio(file_path):
signal, sr = librosa.load(file_path, sr=None)
mfccs = librosa.feature.mfcc(y=signal, sr=sr, n_mfcc=40)
mfccs = np.mean(mfccs.T, axis=0)
mfccs = mfccs.reshape(1, -1, 1) # 重塑模型
prediction = np.argmax(loaded_model.predict(mfccs), axis=-1)
return unique_labels[prediction[0]]
# 实例化一个 GUI 对象
u_gui = GUI()
# 实例化音频
audio = Audio() # 创建音频类的一个实例
# 用于持有消息标签的变量
text = None
result_text = None # New variable to hold the result text
# 创建变量持有按钮
buttonA = None
# “开始录音”按钮的回调函数
def start_recording():
global text, buttonA # 引用全局变量
# 禁用按钮以防止多次点击
buttonA.config(state="disabled")
# 在一个单独的线程中开始倒计时
countdown_thread = threading.Thread(target=countdown, args=(3,))
countdown_thread.start() # Start the thread
def countdown(t):
global text
# 显示倒计时
for i in range(t, 0, -1):
text.config(text=str(i).upper(), font_size=100, x=50, color='#FFFFFF') # 更新倒计时文本
time.sleep(1) # 延迟1秒
# 倒计时结束后,更新文本提示录音状态
text.config(text="RECORDING STARTED...\nPLEASE WAIT...", font_size=15,x=10, color='#FFFFFF')
# 开始录音
audio.start_record('machine_sound.wav') # 开始录音
# 录音持续15秒
time.sleep(15) # 录音时长
audio.stop_record() # 停止录音
text.config(text="RECORDING STOPPED.", font_size=15, x=10, color='#FFFFFF') # 更新消息
# 等待3秒
time.sleep(3) # 在处理音频前等待
text.config(text="PLEASE WAIT.", font_size=15, x=10, color='#FFFFFF')
process_audio() # 处理音频
def process_audio():
predicted_state = predict_audio('machine_sound.wav') # 预测机器状态
global result_text
if result_text: # 如果结果文本已经存在,则更新它
result_text.config(text=f"MACHINE STATE: {predicted_state.upper()}")
else: # 如果结果文本不存在,则创建它
result_text = u_gui.draw_text(text=f"MACHINE STATE: {predicted_state.upper()}", x=10, y=200, font_size=15, color='#FFFFFF') # Center it
# 处理完成后重新启用按钮
buttonA.config(state="normal")
# 载入背景图片
# 确保 '1.png' 在你的脚本同一目录下存在
background_image = u_gui.draw_image(image="1.png", x=0, y=0) # 设置为填满整个屏幕
# 创建并在全局变量中储存“开始录音”按钮
buttonA = u_gui.add_button(text="Start Recording", x=25, y=100, w=190, h=40, onclick=start_recording)
# 在背景上方显示应用程序的标题
<font _mstmutation="1" _msttexthash="260148967" _msthash="0">title_text = u_gui.draw_text(text='MACHINE MEDIC', y=50, font_size=20, color='#FFFFFF') # </font>如有需要可调整位置y
# 初始化用于倒计时和录音状态的消息文本
text = u_gui.draw_text(text="", x=10, y=150, font_size=15, color='#FFFFFF') # Placeholder for message updates
# 主循环保持GUI运行
while True:
# 防止程序退出或卡住
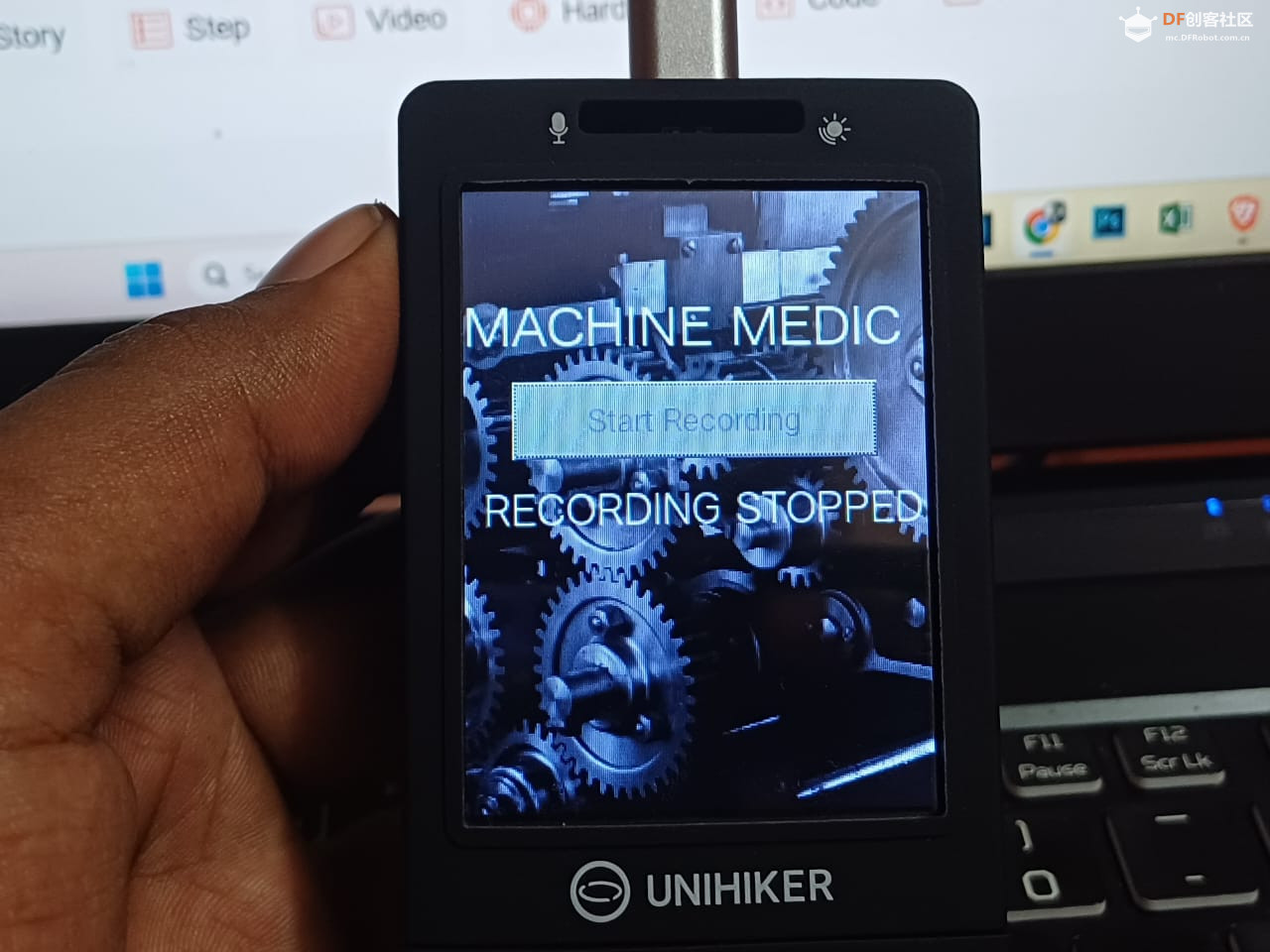
time.sleep(0.1) 复制代码 目前,现有模型利用了内置在行空板上的麦克风来进行小规模的声音分析。该模型旨在监控持续运作的传输带。为了将这个项目扩展至更大的流水传送带,我们计划沿着传送带的周围放置多个麦克风。这些麦克风将连接到行空板上,用于实时的声音监控并分析系统的不同部分。 1.打开录制 2.等待倒计时,并将行空板靠近音源以监听设备运行状态。 3. 模型会在15秒的录音结束后开始预测。下面视频中模型已经基于录音做出了预测,所监听的机械设备目前处于不良状态!
总结 这个项目未来的目标是将此解决方案整合到生产线各个部分的全面运行的机器中。通过应用边缘计算,我们可以直接在设备作业现场处理声音数据,减少延迟并提高实时故障检测能力。这不仅将有助于防止更大规模的工业机器设备停机,还可以使该系统在不同行业中发挥作用。 原文链接 :https://community.dfrobot.com/makelog-314667.html 项目作者 :surrvesh_ks发表时间 :2024.10.16延伸阅读: 【行空板】用Python玩转开源硬件-第12课:AI门禁安全监控 行空板AI人工智能项目教程合集 





 萌萌哒新人
萌萌哒新人
 活跃会员
活跃会员
 编辑选择奖
编辑选择奖



 沪公网安备31011502402448
沪公网安备31011502402448

 置顶卡
置顶卡 变色卡
变色卡 千斤顶
千斤顶






