|
26616| 0
|
[动态] YOLOv10与YOLOv8对比:模型大小、性能、x86 SBC和PC上的基..... |

|
YOLO(You Only Look Once)系列算法是物体检测领域影响最大、应用最广泛的深度学习模型之一。自 YOLOv1 推出以来,YOLO 系列凭借高效的实时检测能力和极高的准确率迅速获得了学术界和工业界的认可和应用。YOLO 系列的核心思想是将物体检测问题转化为单一的回归问题,直接通过神经网络预测图像中的边界框和类别概率,从而实现快速准确的物体检测。 随着 YOLO 系列的不断发展,每一代都在模型架构、检测性能和应用场景等方面进行了显著的改进和优化。YOLOv8 作为目前应用最为广泛的版本之一,凭借高效的检测性能和较低的计算资源需求,获得了大量用户的青睐。近期发布的 YOLOv10 进一步提升了模型的检测准确率和推理速度,同时在模型架构和优化策略方面也做出了重要改进。因此本文将对 YOLOv10 和 YOLOv8 进行深入对比,分析二者在模型大小、性能指标和硬件要求等方面的差异,帮助读者更好地了解 YOLO 版本,并根据自己的应用场景选择最合适的版本。 模型尺寸的差异YOLOv8 模型架构和大小YOLOv8的架构主要分为三个部分:Backbone、Neck、Head。 Backbone: YOLOv8 采用 CSPDarknet53 作为骨干网络,该网络通过 Cross-Stage Partial connections 改善不同网络阶段之间的信息流动,增强训练过程中的梯度流,从而提高准确率。 Neck: Neck 结构,也称为特征提取器,负责合并来自骨干网络不同阶段的特征图以捕获多尺度信息。YOLOv8 采用新颖的 C2f 模块,将高级语义特征与低级空间信息相结合,特别提高了小物体检测的准确性。 Head: Head 负责进行预测。YOLOv8 使用多个检测模块,这些模块会预测特征图中每个网格单元的边界框、对象性分数和类别概率。然后,这些预测会汇总起来,以获得最终的检测结果。 YOLOv8 还引入了空间注意机制、特征融合、瓶颈和 SPPF(空间金字塔池化快速)层等几个关键创新,以及数据增强和混合精度训练,所有这些都提高了模型的性能和效率。 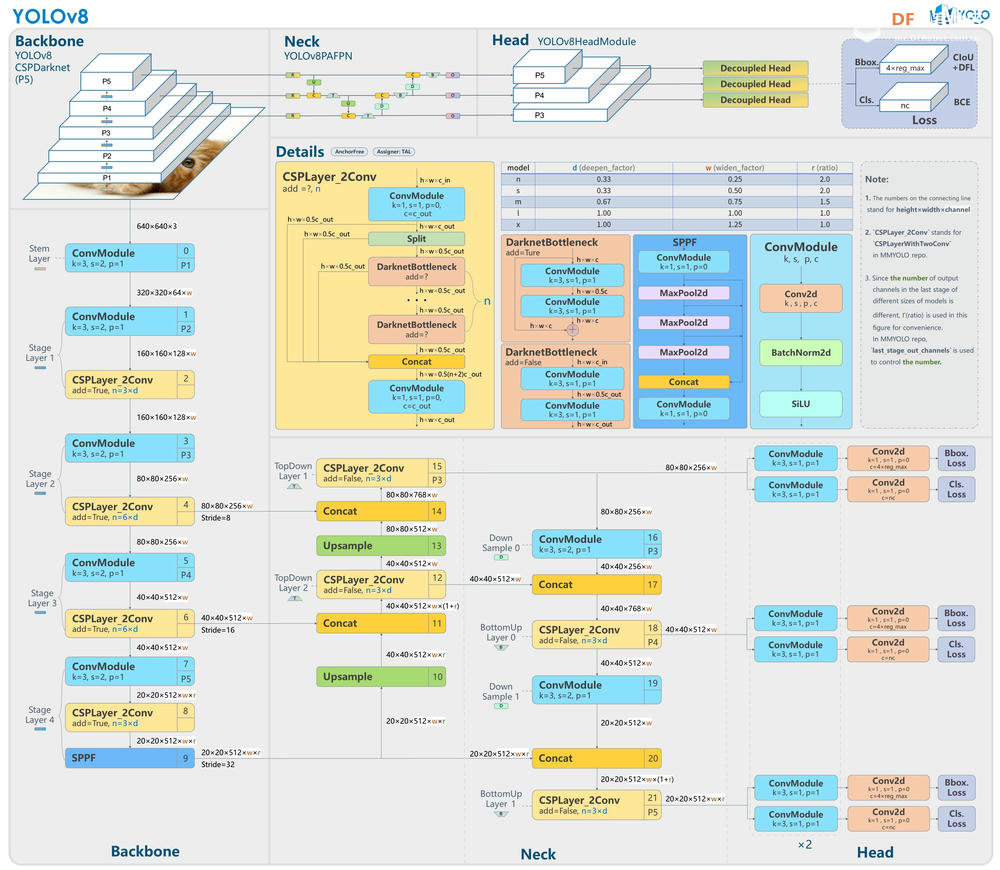 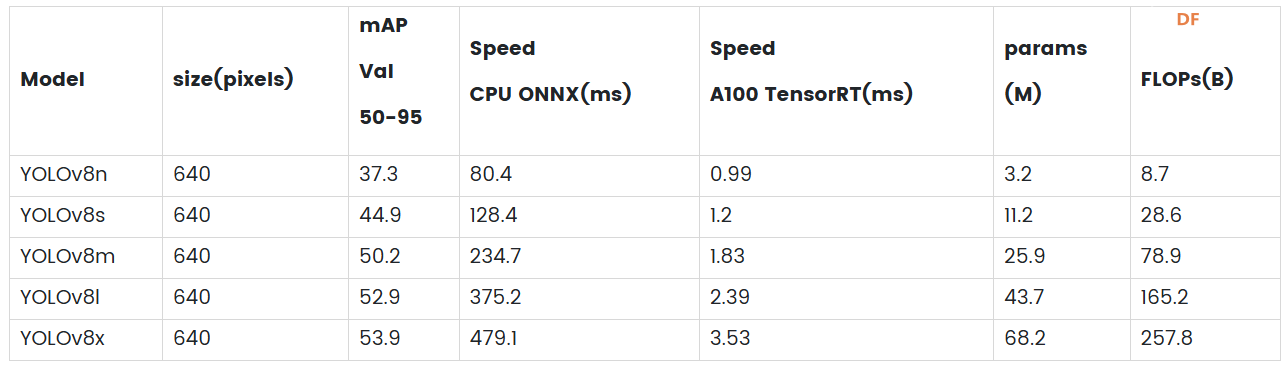 YOLOv8 模型大小比较YOLOv10 模型架构和大小1. 无 NMS 训练:利用一致的双重分配来消除对 NMS 的需要,从而减少推理延迟。 2. 整体模型设计:从效率和准确性的角度对各个组件进行全面优化,包括轻量级分类头、空间通道解耦下采样和排序引导块设计。 3. 增强的模型能力:结合大核卷积和部分自注意力模块,在不增加计算成本的情况下提高性能。 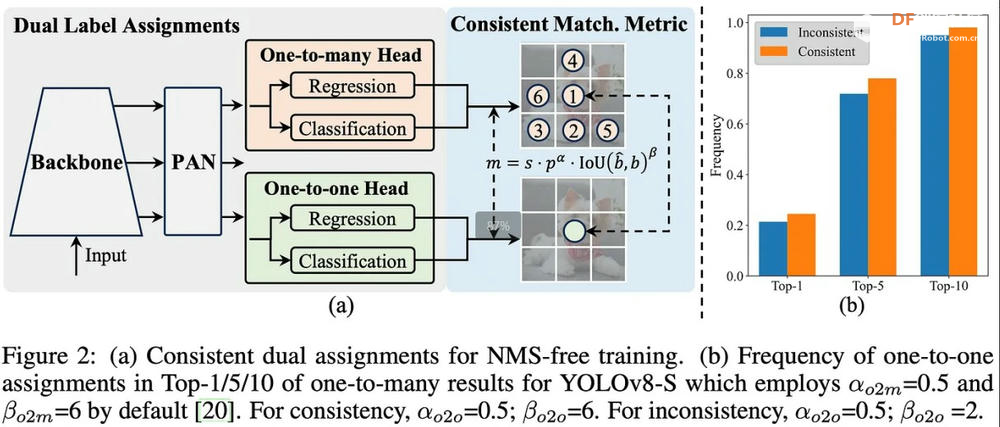 YOLOv10 模型架构
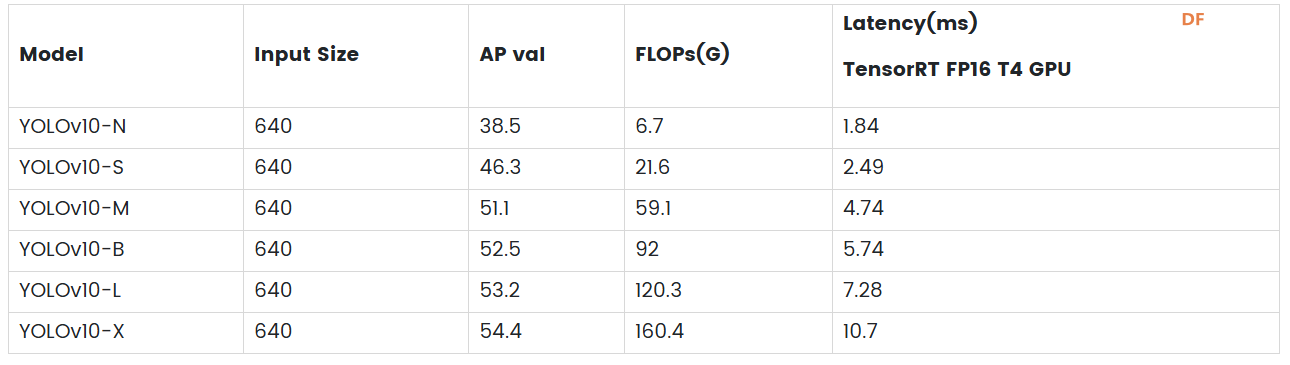 YOLOv10 模型尺寸比较性能指标比较在 COCO 数据集上,YOLOv10-S 比 RT-DETR-R18 快 1.8 倍,而性能相当的 YOLOv10-B 延迟降低了 46%,参数减少了 25%,表明 YOLOv10 在准确率和效率上均超越 YOLOv8。 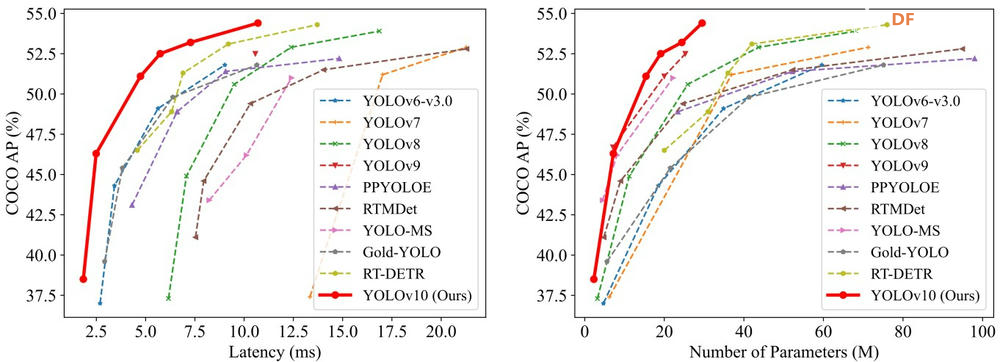 在搭载Intel Core i7处理器与NVIDIA Geforce RTX 3060 GPU的测试平台上,YOLOv10展现出明显的效率优势。 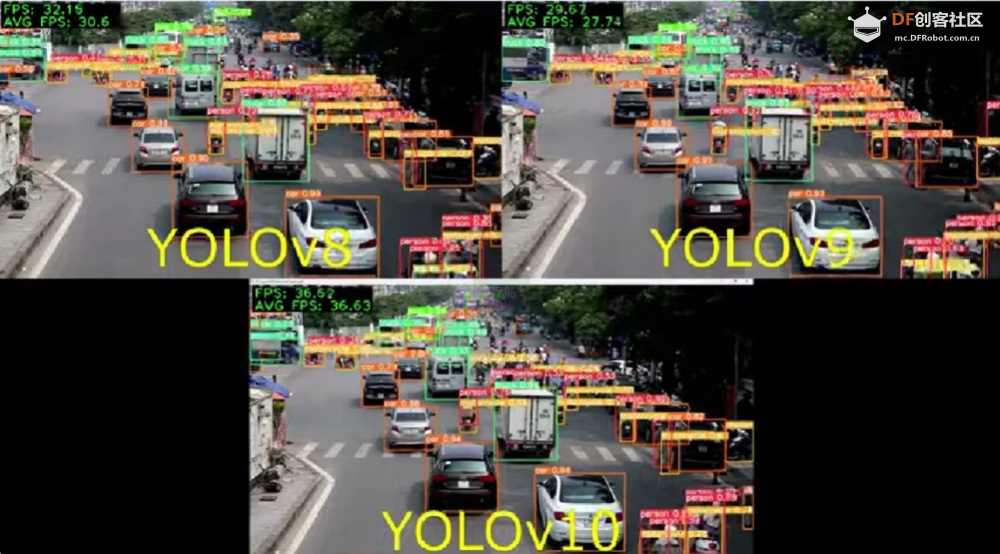 图片来源于此YouTube 视频
在 PC、LP MU 和 Jetson Orin 上测试 YOLOv8 和 YOLOv10实时识别帧率对比根据提供的测试结果,我们可以观察到在 AMD CPU、LattePanda MU 和 Jetson Orin 64GB 等平台上,YOLOv10 的推理速度与 YOLOv8 相比并没有显著提升。这种现象可能是由于 YOLOv10 模型复杂度更高,对浮点计算的需求更大,导致在 CPU 上推理时性能下降。我们期待未来对 YOLOv10 进行进一步优化,在这些平台上实现更高效的推理。 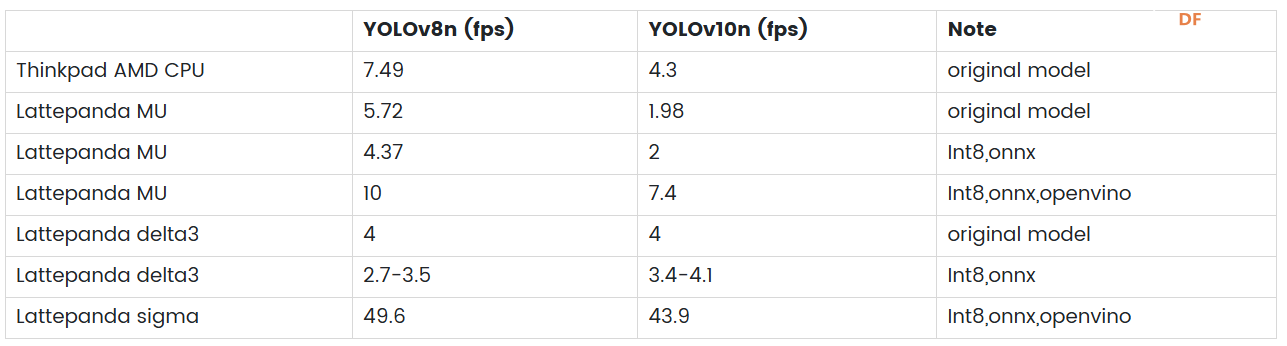 实际应用中的选择在实际使用中,为了达到我们的目的,并且满足相关硬件的要求,我们需要根据yolo模型做出选择。 在yolov8和yolov10模型中,提供了n、s、m、l、x五种不同大小可供选择。 首先从模型尺寸来看,YOLOv10系列在各个对应模型尺寸(N、S、M、L、X)下的参数数量和浮点运算量均明显低于YOLOv8系列。例如YOLOv10-X的参数数量仅为YOLOv8-X的一半左右,FLOPs也降低了约38%。这种模型轻量化的设计使得YOLOv10在存储和传输上更加高效,这对于资源受限的硬件平台尤其具有吸引力。 性能方面,YOLOv10系列在验证集上的平均精度(APval)普遍高于YOLOv8系列,说明即使在减少参数量和计算复杂度的同时,YOLOv10仍然可以保持或提高检测的准确率。 从推理延迟角度来看,YOLOv10系列在所有模型大小上都表现出更低的推理延迟和前向传播延迟。例如,YOLOv10-N的推理延迟仅为1.84ms,而YOLOv8-N为6.16ms,这表明YOLOv10在实时目标检测应用中效率更高。 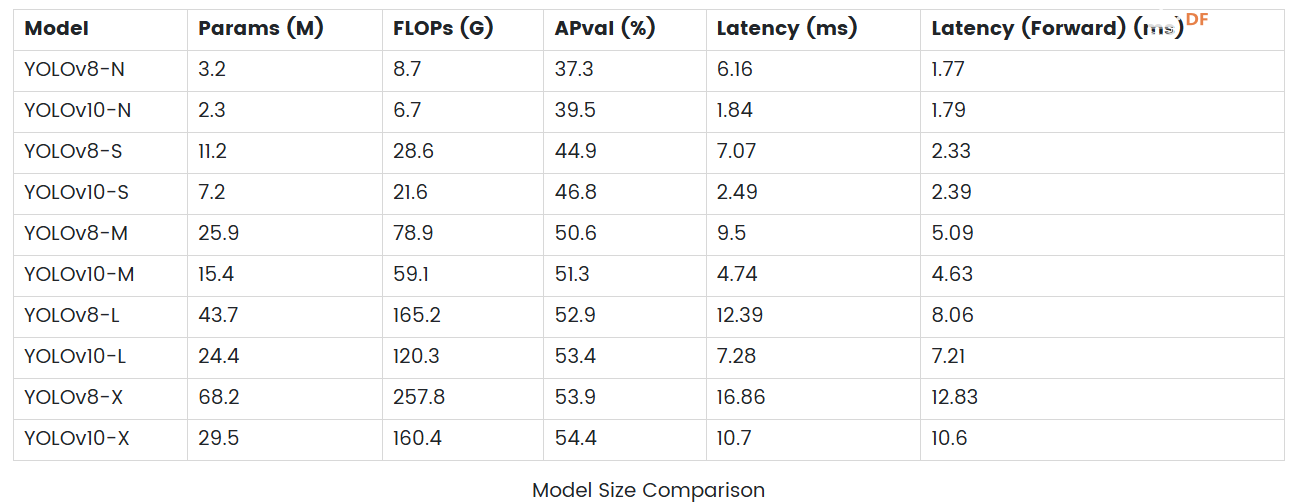 在上述测试中,由于实时性的要求,N 版本对计算资源的要求相对较低,适合在多种硬件平台上进行测试。我们选取了 YOLOv8n 和 YOLOv10n 两个超轻量级模型,帧率最高可达 10。YOLOv8-X 和 YOLOv10-X 分别在 Intel Core i7 处理器和 NVIDIA Geforce RTX 3060 GPU 上运行,帧率分别为 30 和 36。 如果推理速度较慢,可以考虑将模型导出为 ONNX(Open Neural Network Exchange)格式或其他硬件专用格式(例如 NVIDIA GPU 的 TensorRT)以提高性能,或者在导出过程中对模型进行量化,即将浮点型权重和激活转化为低精度整数,这样可以减小模型大小并加速推理。输入大小的设置需要根据实际任务进行调整,以保证模型的检测效果。 结论本文对 YOLOv10 与 YOLOv8 进行了深入对比,分析了二者在模型大小、性能指标以及硬件要求等方面的差异。结果显示,虽然 YOLOv10 在模型复杂度、浮点运算以及准确率等方面都有所提升,但在部分特定平台上(如 AMD CPU、LattePanda MU、Jetson Orin 64GB)的推理速度并没有明显超越 YOLOv8,这可能是由于 YOLOv10 对复杂度和精度的要求较高,且没有针对这些特定平台进行大量的优化所致。 在实际应用中,用户应根据自己的具体应用场景和硬件资源选择合适的 YOLO 版本。对于资源有限的硬件,YOLOv8 和 YOLOv10 均提供不同的模型大小可供选择。此外,为了提高推理速度,可以考虑将模型导出为 ONNX 格式或其他硬件专用格式,或者在导出过程中对模型进行量化 |



 沪公网安备31011502402448
沪公网安备31011502402448© 2013-2026 Comsenz Inc. Powered by Discuz! X3.4 Licensed


 置顶卡
置顶卡 变色卡
变色卡 千斤顶
千斤顶
 萌萌哒新人
萌萌哒新人
 活跃会员
活跃会员
 宣传大使
宣传大使
 志“童”道合
志“童”道合
 编辑选择奖
编辑选择奖






