|
7776| 6
|
[M10项目] 当创客奶爸遇见AI Agent:用行空板+Coze打造定格动画生... |

 项目背景 大家好,我是旺仔爸爸,一名喜欢造物的创客奶爸,近三年未更新内容,不知道你们有没有忘记这个账号。 在当今数字化时代,AI技术正以惊人的速度改变着我们的生活与创作方式,这次我带来一个和AI有点关联的小项目,和大家分享。 在孩子的成长过程中,创意与想象力的培养至关重要。我的孩子在5岁时便对制作定格动画产生了浓厚的兴趣,他喜欢用积木搭建场景并拍摄定格动画视频。然而,每次都需要父母作为摄影师和剪辑师协助完成,这不仅耗时,也限制了孩子的自主创作。于是,我萌生了一个想法:能否制作一个智能设备,让孩子能够独立完成定格动画的拍摄与制作呢?这个想法成为了我创作这个项目的初衷。 创客解法:用智能硬件+Agent技术打造自动化设备,实现儿童独立创作。  通过本次项目的制作,我发现开源硬件和Agent是一个非常不错的搭档,不管是在教育领域还是创客领域,都可以帮助我们实现很多以前没办法实现的创意。我会持续更新关于这方面的内容,大家可以关注一下,也欢迎有同样兴趣的同学一起交流 下面我们先通过视频来看一下本次作品的工作过程 视频展示 本次分享除了有传统的创客项目制作还涉及Coze Agent 工作流搭建,只想了解Coze内容的同学可以直接拉到文章后面程序设计部分学习,要学习整个完整项目可以从头慢慢品读 知识背景 本次我们的主题是定格动画,首先我们了解一下什么是定格动画 定格动画,这种古老而迷人的艺术形式,起源于1907年,通过逐格拍摄对象并连续放映,创造出仿佛被赋予生命的奇妙画面。无论是黏土偶、木偶还是混合材料的角色,都能在定格动画的世界里活灵活现。它的制作原理简单而直观:拍摄多张照片,然后将这些照片连续播放,形成流畅的动画效果。这种独特的艺术形式,不仅能够激发孩子们的创造力,还能培养他们的耐心与专注力。 设计思路 定格动画简单理解就是拍摄多张照片然后连续放映。能胜任这项工作的设备需要能看(摄像头)、会听说(麦克风、喇叭)、可以思考(处理数据),最好还能调用AI工具 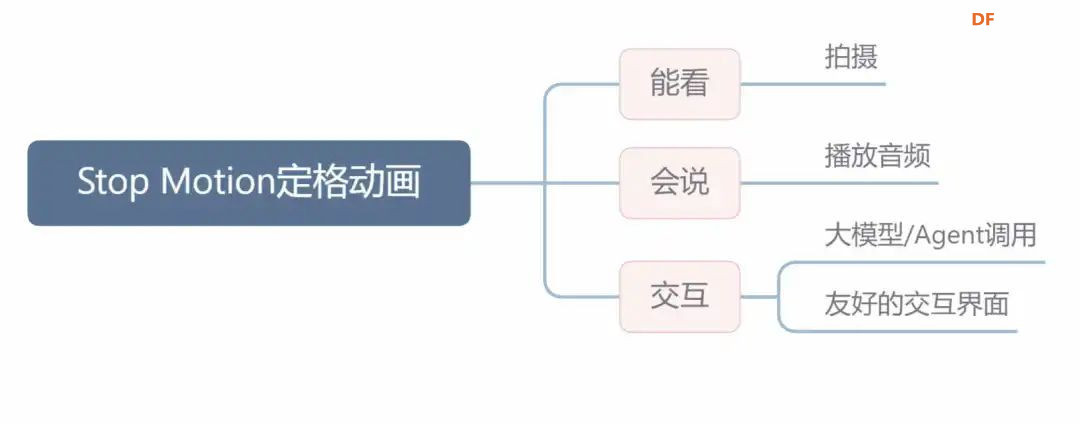 具备这样能力的设备有电脑,树莓派(核桃派等),行空板M10,esp32等。 在众多可胜任定格动画拍摄与制作的设备中,行空板M10以其卓越的性能、丰富的功能和出色的便携性脱颖而出。它不仅拥有堪比树莓派的处理能力,还集成了触摸屏、扩展接口,并预装了多种Python第三方库,极大地简化了配置过程。此外,行空板M10的电源扩展版设计,使其在便携性上更胜一筹,非常适合用于制作便携式智能设备。  器材清单
方案确定后,开始设计 设计制作 人靠衣裳马靠鞍,必须要有一个不错的外观结构才能拿得出手,没准哪个奶爸妈看中潜力股就投了呢 图纸设计 既然是拍摄照片,设计成一个相机的风格会更具象化, 整体是一个盒子结构,将行空板、喇叭固定在盒子中,摄像头部分以一个镜头的造型结构来呈现,细节部分需要注意预留type-c接口、电源开关、三个按键的孔位,图纸设计如下 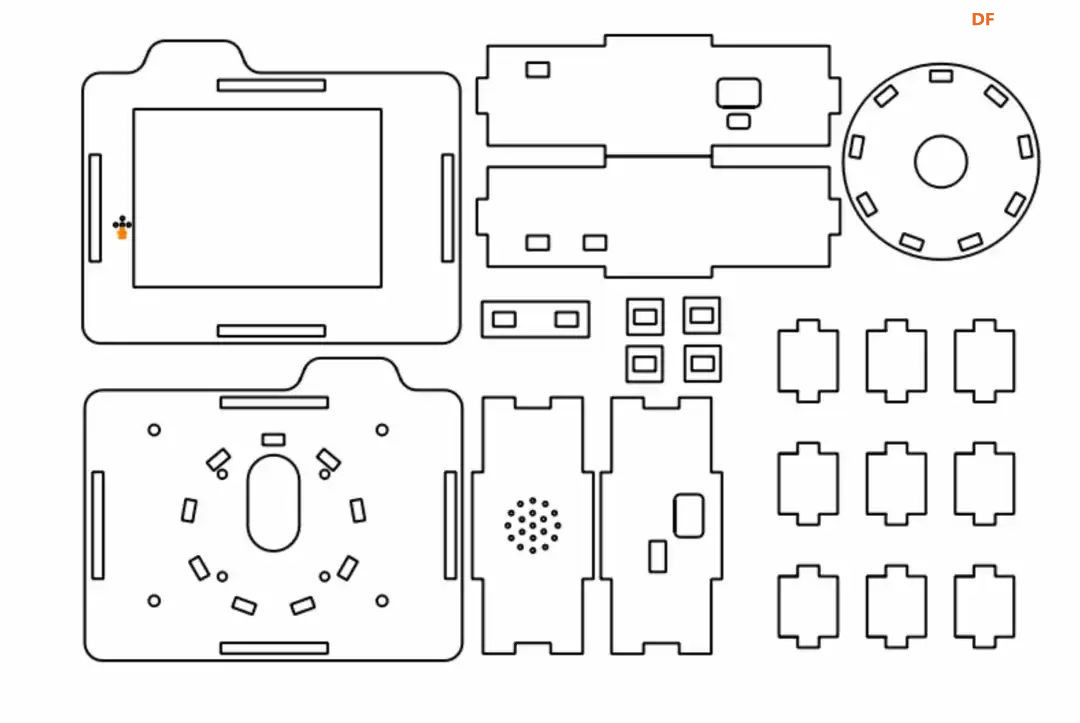 加工零件 图纸设计完成后,我们使用激光切割机把图纸加工出来,加工完成后的零件如下图所示  零件加工完成,下面将电子部件和结构零件进行组装 组装 组装分两部分,电路部分和零件部分 电路接线 本次作品电路设计没有其他多余的外设,摄像头链接至行空板M10的USB接口,为了节省空间,这里的USB端口需要选用一种侧边接线规格的。而蓝牙功放板的供电和摄像头共用即可,音频播放是通过蓝牙与行空板连接,这里连接USB口只是为了供电,蓝牙功放板和行空板之间没有进行数据传输 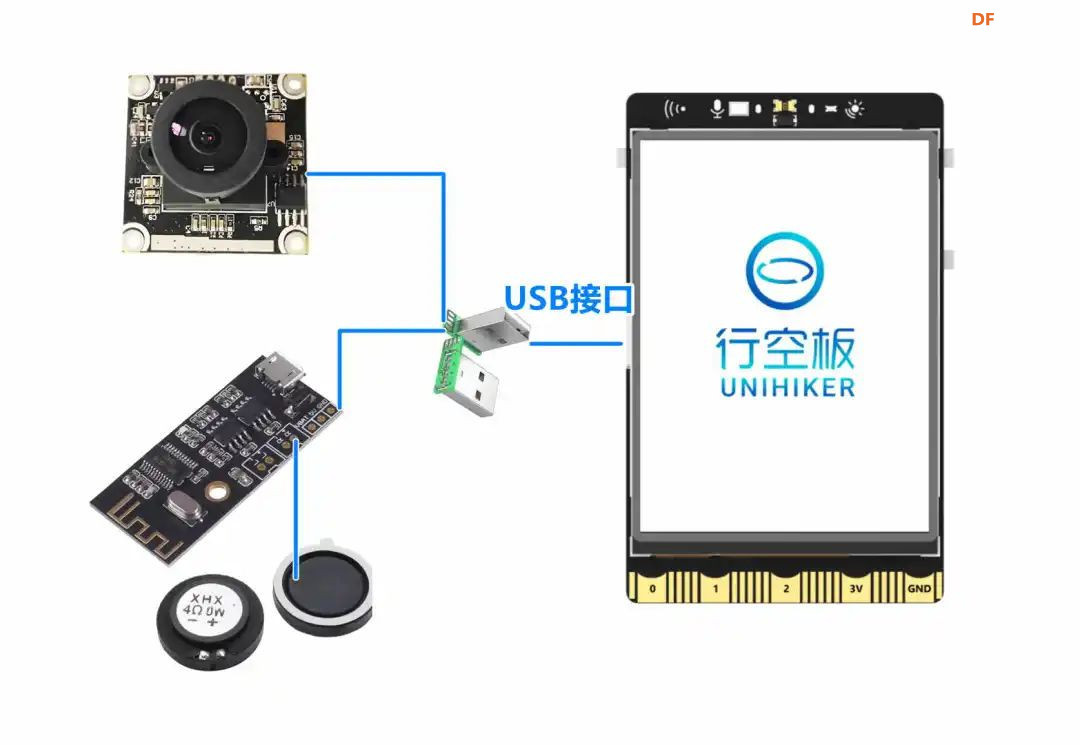 零件组装 下面开始零件组装,第一步将行空板和扩展板按照官方的说明组合起来  第二步,我们找出切好的木制前面板,将行空板和前面板组合在一起,随后安装侧面边框,根据按键、type-c、电源等接口调整边框的安装方向,需要注意的细节是,这里我们用到了几个白色的塑料按钮,在安装侧边框是需要提前将按钮预置进去  第三步,将蓝牙功放和喇叭的电路连接,蓝牙功放板使用行空板的USB供电 接着安装摄像头,摄像头使用滚花铜柱固定在背板上  摄像头固定后,给它装上镜头外观结构  最后来看一下成品吧   组装完成,最后就是程序设计了,开始程序设计前,我们需要先理清楚思路 程序设计编程思路 下图是本次程序设计的基本思路,使用行空板M10调用摄像头拍摄图像,用户根据拍摄场景选择喜欢的音乐主题,之后上传文件至Coze Agent工作流,等待合成视频后将视频链接地址以二维码的形式返回给行空板,用户可用手机扫码观看视频,也可以将视频以二维码的形式或链接的形式传播 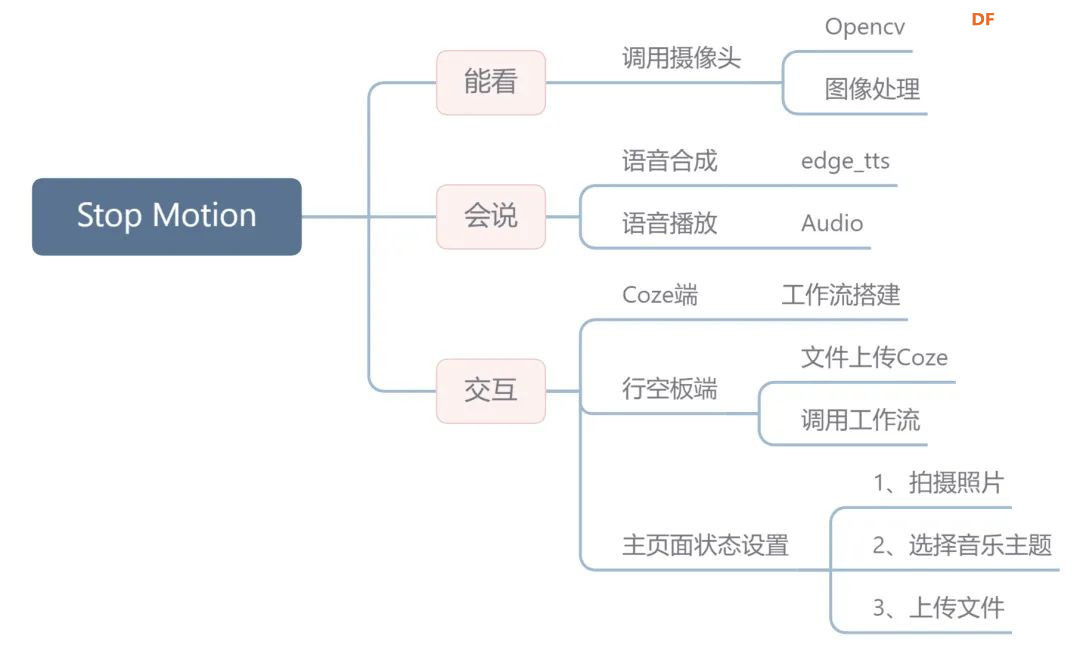 理解了定格动画生成器的工作流程,下面我们来逐步拆解学习每个部分 本次作品我们使用Mind+软件中的Python模式来为行空板M10编写程序,软件可在mindplus.cc下载,关于软件的使用方法可以参考官方教程,这里不再赘述 摄像头调用 第一步,先来学习摄像头的使用方法,调用摄像头需要使用Opencv库,如未安装,可在mind+软件下方的终端输入pip install opencv进行安装,之后我们输入如下程序进行测试 import cv2 import time import os IMAGE_FOLDER = '/root/mindplus/M10/img/' deftake_photo(): """拍摄照片并保存到指定文件夹""" cap = cv2.VideoCapture(0) cap.set(cv2.CAP_PROP_FRAME_WIDTH, 320) #设置摄像头图像宽度 cap.set(cv2.CAP_PROP_FRAME_HEIGHT, 240) #设置摄像头图像高度 ifnot cap.isOpened(): print("无法打开摄像头") returnFalse # 确保目录存在 os.makedirs(IMAGE_FOLDER, exist_ok=True) cv2.namedWindow('Video Cam',cv2.WND_PROP_FULLSCREEN) # 构建一个窗口,名称为Video Cam,默认属性为可以全屏 cv2.setWindowProperty('Video Cam', cv2.WND_PROP_FULLSCREEN, cv2.WINDOW_FULLSCREEN) i=0 print("按 'a' 拍照,按 'b' 退出") while cap.isOpened(): ret,frame = cap.read() ifnot ret: print("摄像头读取失败") break cv2.imshow('Video Cam', frame) key = cv2.waitKey(1) & 0xFF if key == ord('a'): # 按a保存 timestamp = int(time.time()) path = os.path.join(IMAGE_FOLDER, f"photo_{i}_{timestamp}.jpg") # 安全的路径拼接 if cv2.imwrite(path, frame): print(f"保存成功: {path}") i += 1 else: print(f"保存失败: {path}") elif key == ord('b'): # 按b退出 print("退出拍照模式") break cap.release() cv2.destroyAllWindows() return i # 返回拍摄照片数量 if __name__ == '__main__': take_photo() 运行之后会看到如下结果  在行空板M10的屏幕中出现了摄像头的画面,但方向似乎有些不太对,行空板默认是竖向显示,而我们本次的作品需要把屏幕横向显示 这里我们需要在画面展示之前使用下面的指令来将屏幕逆时针旋转90° frame = cv2.rotate(frame,cv2.ROTATE_90_COUNTERCLOCKWISE) #逆时针旋转90度 cv2.imshow('Video Cam', frame) 调整之后画面就显示正常 接着我们解释一下代码中需要注意的部分。首先我们设置了图片拍摄后的存放路径,为了保持文件之间的条理性我们使用了绝对路径来存放文件IMAGE_FOLDER = '/root/mindplus/M10/img/',与绝对路径相对的相对路径,两种方式各有特点,绝对路径从根目录开始,不受当前目录影响;而相对路径指的是当前目录,使用相对简单 制作定格动画需要保存拍摄的多张照片合成视频,为来保证文件的唯一性,这里我们借用时间函数来命名文件 timestamp = int(time.time()) path = os.path.join(IMAGE_FOLDER, f"photo_{i}_{timestamp}.jpg") # 安全的路径拼接 cv2.imwrite(path, frame) 为了让用户方便使用,我们设置用行空板板载的A、B来拍摄和保存,行空板的A、B键和Opencv库中监测电脑键盘输入的指令用法相同,可以使用同样的方法来编写按键控制程序 key = cv2.waitKey(1) & 0xFF if key == ord('a'): # 按a保存 print("拍照") elif key == ord('b'): # 按b退出 print("退出拍照模式") break 运行结果如下  上述程序封装在一个take_photo()方便调用 为了让程序能够重复使用,上一次拍摄的照片不要影响下一次的视频合成,我们这里需要在调用拍照程序之前将保存照片的文件夹中的文件清除,删除文件的指令可以用os.unlink()或者os.remove()代码如下,调用将该函数需要插在拍照之前 def delete_files(folder_path): """清空文件夹内所有内容(保留文件夹本身)""" if os.path.exists(folder_path): for filename in os.listdir(folder_path): file_path = os.path.join(folder_path, filename) try: if os.path.isfile(file_path): os.unlink(file_path) print(f"已删除: {file_path}") except Exception as e: print(f"删除文件失败: {e}") 运行结果如下  到目前,我们的作品就实现了能看功能,也就是具备了采集照片的能力 语音合成与播放 下面来实现会说的能力,本次作品的功能并不需要识别用户说的内容,只需要将机器合成的内容播放出来即可。这里分两部分来完成,第一步要实现语音合成,第二步再将合成的音频文件播放出来。 先来实现语音合成,下面的代码中使用了微软的edge_tts实现语音识别,关于语音合成我比较了百度、讯飞、Pytts,最终我选择了edge_tts,原因是它不需要设置API,音色比较丰富,在调用该库时,同样需要在终端安装,输入pip install edge_tts def generate_audio(text: str) -> None: voice = "zh-CN-XiaoyiNeural" output_file = "audio.mp3" """ 传入文本、语音及输出文件名,生成语音并保存为音频文件 :param text: 需要合成的中文文本 :param voice: 使用的语音类型,如 'zh-CN-XiaoyiNeural' :param output_file: 输出的音频文件名 """ async def generate_audio_async() -> None: """异步生成语音""" print(f"使用离线语音合成: {text}") communicate = edge_tts.Communicate(text, voice) await communicate.save(output_file) # 异步执行生成音频 asyncio.run(generate_audio_async()) 其中voice表示语言类型,支持40多种语音,还支持调节语速、音调、和音量,感兴趣的朋友可以查找资料尝试一下,这里我们只需要选择默认即可 使用语音合成函数可以生成一个mp3格式的音频,拿到这个音频文件,可以使用音频播放指令将文件播放出来,播放音频需要使用行空板自带的Audio库,指令如下 from unihiker import Audio audio = Audio() #实例化音频 audio.play(output_file) 这样语音合成,语音播放的功能已经实现,这里提两点避坑指南 1、音频播放前需要让行空板与蓝牙功放板连接,依次输入下面几行指令,其中蓝牙地址需要更换 bluetoothctl //启动蓝牙控制器 default-agent //设置默认的蓝牙代理 power on //打开蓝牙设备 scan on //扫描设备 scan off //停止扫描 trust 28:04:81:2F:6B:DB //信任该蓝牙设备 pair 28:04:81:2F:6B:DB //配对 connect 28:04:81:2F:6B:DB //连接 连接方法也可以参考这篇教程https://mc.dfrobot.com.cn/thread-320407-1-1.html#pid590262; 2、语音合成的功能只能用来生成音频文件,如要播放需要调用音频播放指令,经测试发现,用edge_tts语音合成的响应速度虽说已经很不错了,但还是会有一点点延时,如需提升响应效率,可提前生成要播放的内容,在需要时直接本地调用播放可大大缩短时间 做到能看会说之后,现在需要与Coze Agent进行交互了 交互Coze工作流搭建 有的朋友可能会问,这里为什么要使用Coze呢,既然行空板性能和树莓派类似,行空板自己就可以合成视频呀。没错,确实是这样,这里我们使用Coze来搭建Agent其实是因为新的AI工具出来后,我们选择的一种相对来说比较合理的方案,之所以选择Coze是因为目前它的智能体、插件等生态资源非常丰富,几乎在一个平台中只需要调用不同的插件就可以实现功能了,不用再像之前那样调用各种平台,查找各种资料,配置各种接口才能实现。其实现在可以做智能体的平台也有很多,像dify、n8n、Fastgpt等都可以,其实逻辑原理是相通的,只是Coze的资源更丰富,学习起来更容易,在起步阶段先以一个简单的上手,后续迁移其他平台也很快 在调用coze之前,我们要先在coze平台搭建工作流 扣子是字节系的产品,平台中大量的Agent应用可以尝试体验,国内地址:https://www.coze.cn/ 下面我们来亲自搭建一个工作流 点击如下图所示进入开发平台,如需注册需要用手机号或者字节系的账号注册  Coze的功能很多,依次按照如下图所示步骤创建工作流。什么是工作流,为什么用工作流,工作流和Agent有什么关系?想必现在你有很多疑问,没关系,这个我们先不管,保留着好奇先跟着做完,(暂且先简单理解Agent和工作流是包含关系,作用都是为了补齐大模型的短板,辅助实现某些功能,关于概念的理解后面我们再解释) 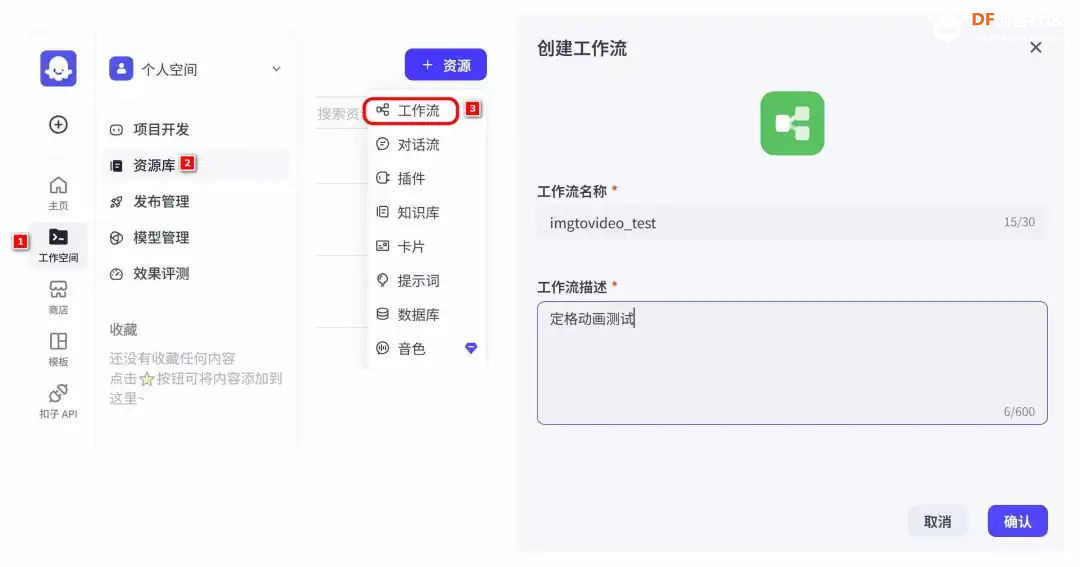 工作流创建完成后,可以看到一个只有开始和结束两个节点的简单工作流,该工作流的作用就是将输入的内容原封不动的再输出。不论是什么样的工作流,都必须要有开始和结束节点,也就是输入和输出 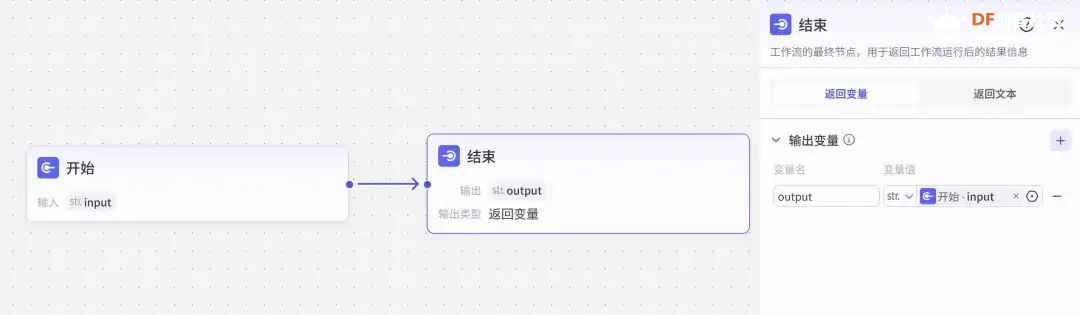 如要实现特定的功能,只需在中间添加节点即可,如下图所示,我们可以在开始和结束节点中间添加一个文本处理节点,作用是将输入的内容进行拼接后输出,每个中间节点都会有一个输入和输出,需要分别设置当前节点的输入和输出内容是什么,也就是图中的input和output,这里的名称是默认的,可以根据需求更改,数据通过数据流来传输,这里设置文本处理节点接收开始节点的input内容,将字符串拼接后的结果作为结束节点输入的内容,当我们输入hello+时,结果会输出hello+world,通过以上测试就学会了工作流的基本搭建方法 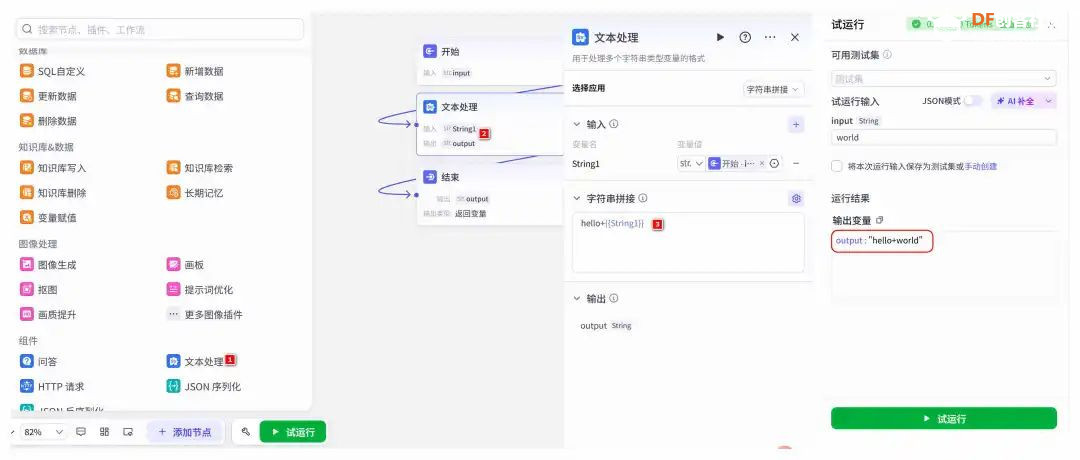 下面我搭建视频合成的工作流,视频合成的工作流不算复杂,但也需要清晰拆解一下实现逻辑,工作流的输入、输出和中间节点如下 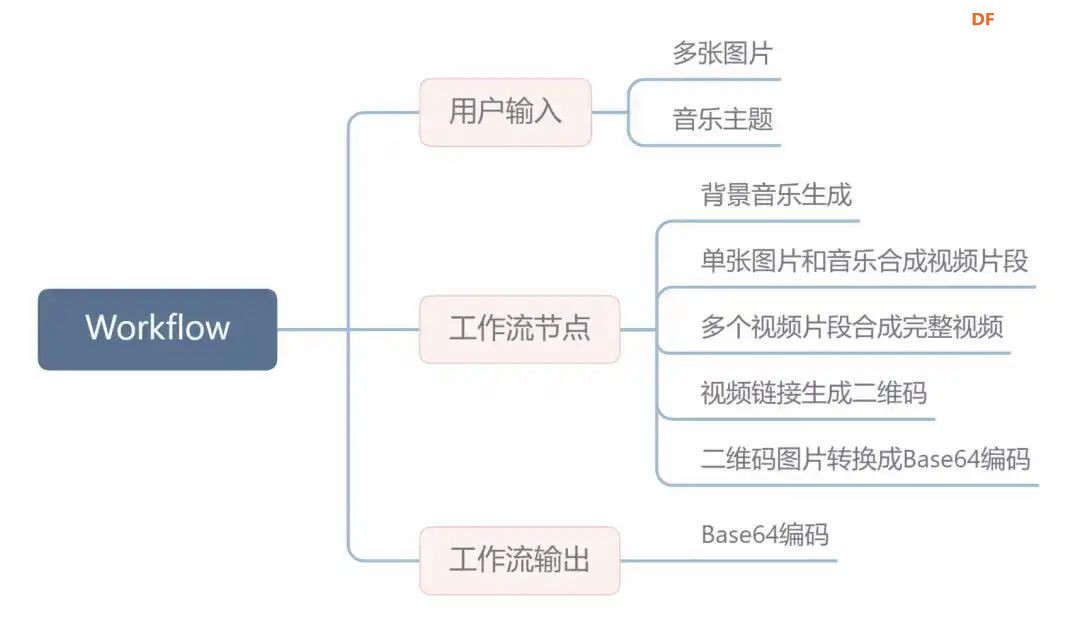 下面逐步实现, 第一步,实现背景音乐的生成 点击添加节点搜索BGM关键词,添加背景音乐库,该节点的使用方法很简单,只需要输入音乐风格即可生成背景音乐的链接,关于节点的使用方法也可以点击插件详情了解,这里设置将开始节点的music_style作为输入内容传给音乐库节点,再将输出的bgm_url传给结束节点,可以看到结果如下 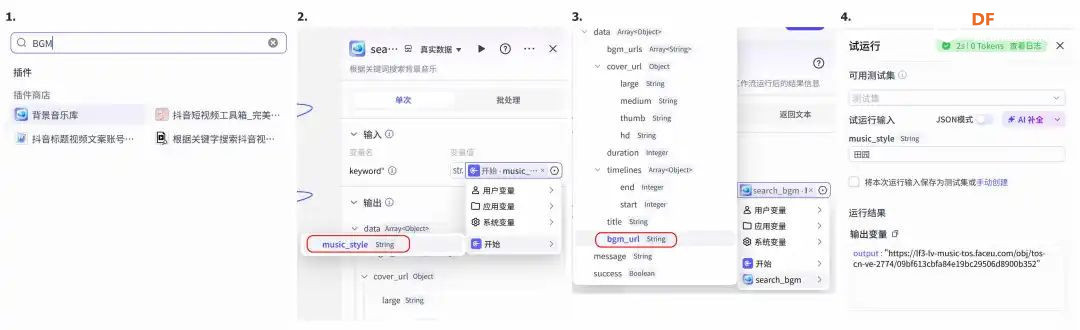 掌握了背景音乐生成的工作流,其他的功能其实就很简单了 第二步,实现单张图片和音频制作视频片段 这里需要使用一个图片制作视频的插件节点,这个图片合成视频的插件来自51aigc.cc网站,其中api_token需要注册账号后在网站个人中心获取,img_url可以找网络图片临时测试,正式调用时使用行空板上传的图片,mp3_url来自上一个节点的输出,设置完成后运行可看到输出的结果为一个视频链接 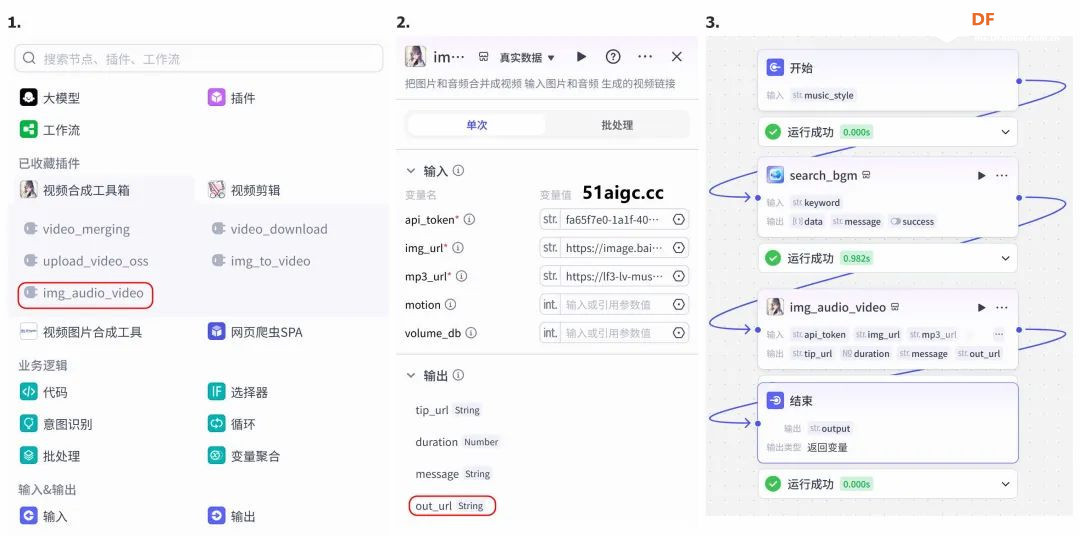 第三步,多个视频片段合成完整视频 上一步我们使用的是一个单张图片和音频合成视频的插件,现在我们继续使用这个视频合成工具箱插件中的video_merging实现多个视频合成完整视频,如下图所示,我们添加插件后,需要输入api_token和video_urls这两个参数,其中api_token和上一步的保持一致即可,video_urls是一个数组,用来存放每个视频片段的url链接,这个链接正是来自上一步合成的视频,并且每一张图片生成视频片段后对应一个链接,所以这里需要以数组的形式来接收这些链接 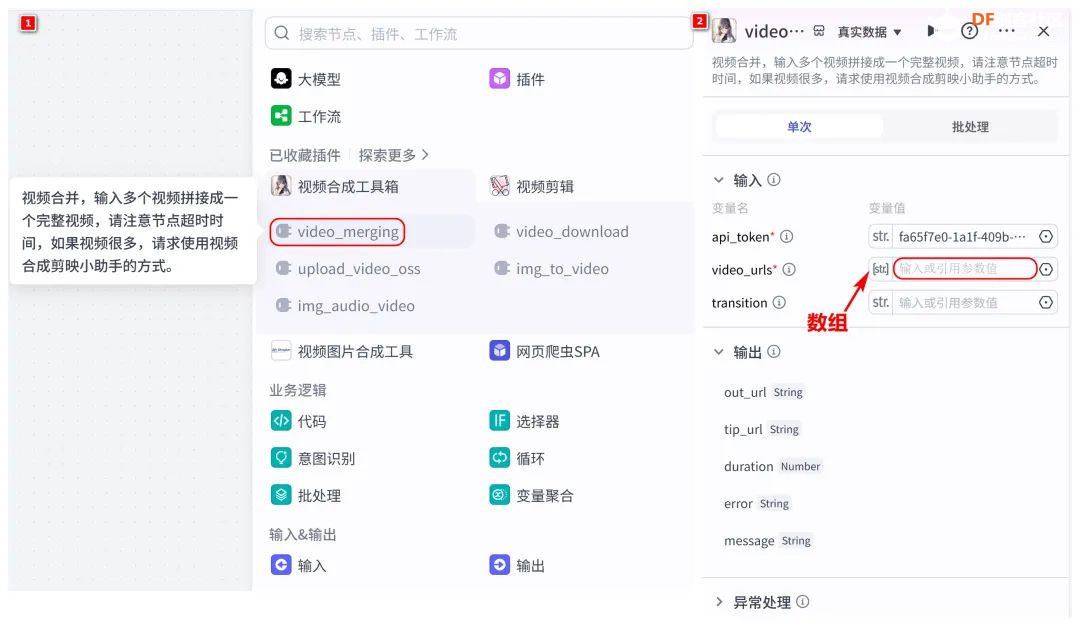 到这里,有的朋友可能会问,多个视频片段的链接从哪里得到呢?其实很简单,只需要将第二步的工作重复多次即可,这里需要用到批处理节点,通过重复执行相同的工作,将制作的多个视频片段的url链接以数组的形式输出。想必大家已经发现了问题,第一步我们生成的是一个完整的背景音乐,如果是多张图片,那岂不是需要将音频切开分段,再与每张图片合成视频。的确是这样,所以这里我们还需要一个音频切割的插件,负责完成这项工作,如下图所示,我们添加音频切割插件,只需要输入起止时间就可以将音频切割,并以url链接的形式输出,之后再将url链接与图片合成视频即可,只不过这里我们同样需要用到批处理的方式来重复切割音频。 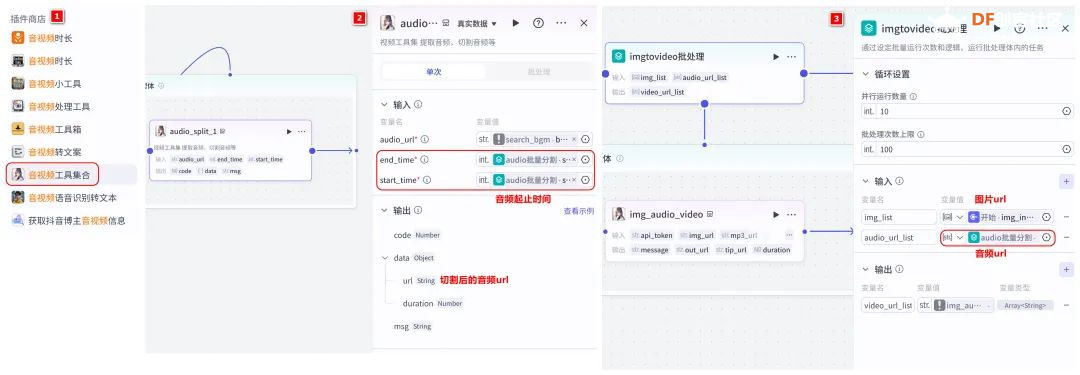 这里的关键是要确定每段音频的起止时间,需要使用一个代码节点来完成这项特定功能,使用代码节点只需要确定输入和输出的内容即可,它会自动完整,输入的内容是图片数组和音频的时长,输出的是图片的数量,音频时长和分段音频的起止时间 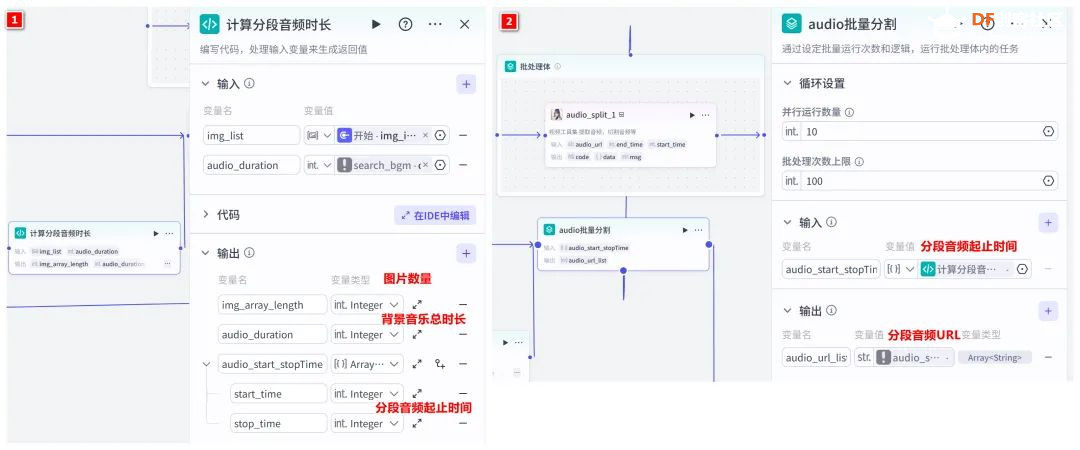 Coze 工作流中除了有很多成熟的插件可以使用外,还提供了代码节点,可以方便我们实现特殊功能,下面是本次计算音频时长的节点代码 async defmain(args: Args) -> Output: # 从输入参数中获取音频时长(微秒)和图片列表 params = args.params audio_duration_us = params['audio_duration'] img_list = params['img_list'] # 计算图片数组的长度 img_count = len(img_list) audio_start_stopTime = [] # 计算每个时间段的长度(微秒) if img_count > 0: # 计算总时长(秒)和每段时长(秒) total_duration_sec = audio_duration_us / 1_000_000 segment_duration_sec = min(3.0, total_duration_sec / img_count) # 转换为微秒(整数运算避免浮点误差) segment_duration_us = int(segment_duration_sec * 1_000_000) # 生成音频起止时间数组 for i inrange(img_count): start_time_us = i * segment_duration_us stop_time_us = start_time_us + segment_duration_us # 处理最后一个时间段,确保总时长准确 if i == img_count - 1: stop_time_us = min(stop_time_us, audio_duration_us) # 将微秒转换为秒 audio_start_stopTime.append({ "start_time": start_time_us // 1000000, "stop_time": stop_time_us // 1000000 }) # 构建并返回输出JSON(字典格式) ret: Output = { "img_array_length": img_count, "audio_duration": audio_duration_us, "audio_start_stopTime": audio_start_stopTime } return ret 经过以上三步,已经可以生成一个定格动画视频了,不过现在还需要将视频的URL链接转换成二维码图片,再将图片转化成base64编码,输出给行空板,前面的内容掌握后这几步会非常简单,按照下图所示操作即可。设置完成后,试运行没问题可以点击发布, 发布后该工作流支持在Coze Agent中调用,也支持外部终端设备通过API接口来调用 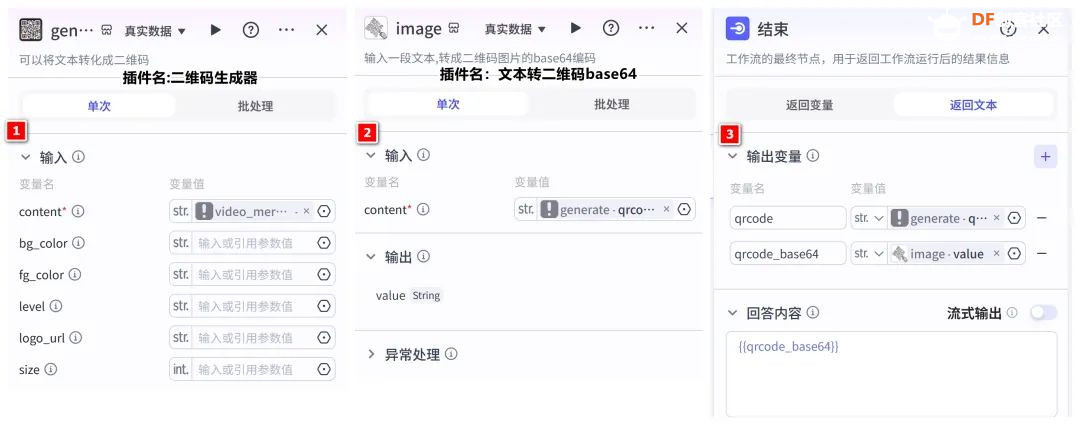 Coze 工作流中的插件有官方插件、第三方插件以及个人用户插件,关于插件的选择,首选官方插件,其次是比较有实力保障的公司提供的插件,再次才是个人用户的插件,插件根据功能的不同,分收费和免费,官方的插件免费赠送的节点用来测试基本够用了,第三方的没有大批量商用的花使用成本也非常低,本次我们使用的基本上是官方插件和51aigc团队的插件,稳定性是有保障的。关于Coze工作流搭建的环节我们已经介绍完了,Coze是一个非常不错的学习AI Agent的平台,本次我们只是简单介绍了一下与本次项目相关的功能,这只是冰山一角,后面我会再通过不同的项目分享更多关于Coze平台的使用方法 行空板调用工作流 Coze的工作流搭建完整,现在我们可以调用工作流的API接口进行测试,调用工作流的方法可以参考如下官方的链接 https://www.coze.cn/open/docs/developer_guides/upload_files //上传文件 https://www.coze.cn/open/docs/developer_guides/workflow_run //执行工作流 本次项目,与Coze工作流有两次交互的过程,第一次先将图片上传至Coze,返回图片的ID;第二次将图片的ID和背景音乐的主题作为输入参数传入前面搭建好的工作流中,返回包含有视频url的二维码 在开始之前,我们需要做两项准备工作 1、获取Coze的个人令牌,也就是Token,在如下地址获取即可,设置权限时可以选择全部,注意这个token需要及时复制保存,不支持二次查看,如果忘记需要重新生成,之前的将会失效 https://www.coze.cn/open/oauth/pats 2、获取工作流的ID,进入到工作流后,可以在网址栏中看到工作流的ID,记录下来,方便调用  准备工作做好后,我们回到mind+软件输入如下代码 import requests, json,base64, COZE_TOKEN = 'pat_4BuSeWUu9JqEiH2BeYdleXbcKsyLNB4asOkAfDRRYhzAmy9JJ57dtwwkvtg8w5e4' WORKFLOW_ID = "7504802266752565285" classCozeAPI: """Coze API 操作类""" def__init__(self, access_token): self.base_url = "https://api.coze.cn/v1" self.access_token = access_token self.headers = { "Authorization": f"Bearer {access_token}" } def_upload_file(self, file_path): """上传单个文件到Coze""" url = f"{self.base_url}/files/upload" filename = os.path.basename(file_path) try: # 检查文件大小 file_size = os.path.getsize(file_path) if file_size > 512 * 1024 * 1024: # 512MB print(f"跳过 {filename} (超过512MB限制)") returnNone # 上传文件 withopen(file_path, 'rb') as file_obj: files = {'file': (filename, file_obj)} response = requests.post(url, headers=self.headers, files=files) response.raise_for_status() # 检查响应 result = response.json() if result.get('code') == 0: print(f"上传成功: {filename}") return result['data'] else: print(f"上传失败: {result.get('msg', '未知错误')}") returnNone except Exception as e: print(f"上传 {filename} 时出错: {str(e)}") returnNone defupload_images(self, folder_path): """批量上传图片文件到Coze""" image_data = [] valid_extensions = ('.png', '.jpg', '.jpeg', '.gif', '.bmp', '.webp') ifnot os.path.exists(folder_path): raise FileNotFoundError(f"文件夹不存在: {folder_path}") # 获取所有图片文件 image_files = [f for f in os.listdir(folder_path) if f.lower().endswith(valid_extensions)] ifnot image_files: print("文件夹中没有图片文件") return image_data print(f"发现 {len(image_files)} 张图片准备上传") # 批量上传 for filename in image_files: file_path = os.path.join(folder_path, filename) result = self._upload_file(file_path) if result: image_data.append(result) return image_data defrun_workflow(self, workflow_id, parameters): """执行工作流""" url = f"{self.base_url}/workflow/run" data = { "workflow_id": workflow_id, "parameters": parameters } print("执行工作流参数:") print(json.dumps(data, indent=4, ensure_ascii=False)) try: response = requests.post( url, headers=self.headers, data=json.dumps(data), timeout=60# 增加超时时间 ) response.raise_for_status() response_data = response.json() # 检查响应状态码 if response_data.get('code') != 0: print(f"工作流执行失败: {response_data.get('msg')}") returnNone print("工作流执行结果:") print(json.dumps(response_data, indent=4, ensure_ascii=False)) return response_data except requests.exceptions.RequestException as e: print(f"工作流请求失败: {str(e)}") return None 代码中我们将与Coze交互的部分做了一个类函数,其中access_token为前面获取到的个人令牌,我们将文件上传分成了单个文件和批量文件上传两种,方便函数复用,运行程序,可以拿到如下测试结果,“code”为0表示测试成功,如返回的结果不是0,则需要根据“msg”信息调整。其中“data”数据既图片上传后的信息,“id”的内容在执行工作流时使用。 {"code":0,"data":{"bytes":26451,"created_at":1750525076,"file_name":"online-shopping.png","id":"7518444294115147812"},"detail":{"logid":"202506220057559170147E27FFD06CBB7F"},"msg":""} 文件上传支持多种常见的格式,单个文件大小不超过512M即可,我们在代码中做了文件大小检测,本次我们只需要上传图片即可,批量上传后获取到图片ID可用来调用工作流生成视频,调用执行工作流函数run_workflow 时,除了传入多张图片ID的列表外,还需要将背景音乐主题以字符串的格式传入。之后再将返回的二维码显示,这里我们封装一个函数upload(BGM)来完成工作流的调用工作,代码如下 def upload(BGM): """上传图片并执行工作流生成视频二维码""" print("开始上传和处理流程") # 初始化API api = CozeAPI(COZE_TOKEN) try: # 批量上传照片 print("\n===== 上传照片 =====") upload_results = api.upload_images(IMAGE_FOLDER) ifnot upload_results: print("没有成功上传的照片,终止处理") returnFalse # 准备图片输入 image_entries = [{"file_id": item['id']} for item in upload_results] print(f"\n准备处理的图片: {len(image_entries)}张") # 执行工作流 print("\n===== 执行工作流 =====") workflow_result = api.run_workflow( workflow_id=WORKFLOW_ID, parameters={ "img_input": image_entries, "text_input": BGM } ) ifnot workflow_result: print("工作流执行失败") returnFalse # 处理工作流结果 if'data'in workflow_result: workflow_output = json.loads(workflow_result['data']) if'data'in workflow_output: # 解码二维码图片 bytes_data = base64.b64decode(workflow_output['data']) # 创建临时文件路径 qr_path = os.path.join(IMAGE_FOLDER, f"qrcode_{int(time.time())}.png") # 保存二维码图片 withopen(qr_path, "wb") as img_file: img_file.write(bytes_data) print(f"二维码已保存至: {qr_path}") # 旋转并显示二维码 img = Image.open(qr_path) img = img.transpose(Image.ROTATE_270) returnTrue print("未获取到有效的二维码数据") returnFalse except Exception as e: print(f"程序异常: {str(e)}") returnFalse finally: print("\n上传处理流程完成") 主页面状态设置 其实,到目前为止,我们已经可以实现制作定格动画视频的功能了,只不过为了让设备更好用,可以继续优化,设计一个UI交互界面,将拍摄照片、选择音乐主题、上传文件分别设置成不同的模块供用户调用。设置好的界面如下图所示 要完成界面设计,需要提前准备一些图标,将文件命名好后,以绝对路径或相对路径的形式调用  代码如下 from unihiker import GUI #导入包 from pinpong.board import * from pinpong.extension.unihiker import * gui=GUI() #实例化GUI类 deffirst_page(): # 页面初始化代码... global camera_image, Caption_text # 统一旋转函数 defload_rotated_image(path): img = Image.open(path) return img.transpose(Image.ROTATE_270) # 加载并旋转所有图标 icons = { 'camera_icon': load_rotated_image("camera_icon.png"), 'camera': load_rotated_image("camera.png"), 'music': load_rotated_image("online-shopping.png"), 'upload': load_rotated_image("upload-file.png"), 'title': load_rotated_image("video-editing.png"), 'chat': load_rotated_image("chat.png") } title_text = gui.draw_text(x=240, y=170, text='Stop Motion',origin='top' ,color='black', angle=270) Caption_text = gui.draw_text(x=190, y=130, text="点击拍照 A键拍摄 B键返回",font_size=10,origin='left', angle=270) camera_image = gui.draw_image(x=180, y=140, w=160, h=200, image=icons['camera'], origin='top_right', onclick=lambda: iconclick('1') ) camera_icon = gui.draw_image(x=200, y=20, w=40, h=50, image=icons['camera_icon'], origin='top_right', onclick=lambda: iconclick('1')) music_icon = gui.draw_image(x=135, y=20, w=40, h=50, image=icons['music'], origin='top_right', onclick=lambda: iconclick('2')) upload_icon = gui.draw_image(x=70, y=20, w=40, h=50, image=icons['upload'], origin='top_right', onclick=lambda: iconclick('3')) title_icon = gui.draw_image(x=215, y=85, w=20, h=20, image=icons['title'], origin='top_left') chat_icon = gui.draw_image(x=180, y=100, w=20, h=20, image=icons['chat'], origin='top_left') # 设置全局引用 app_state.caption_text = Caption_text app_state.camera_image = camera_image 界面设计的代码其实非常简单,只用到了文字 draw_text和图片 draw_image控件。控件对象名.config(需要更新的参数名=值)用来更新控件,GUI对象.remove(控件对象名)用来删除某个控件,GUI对象.clear()用来删除所有控件。更多用法在行空板的官方文档有很详细的介绍,需要的朋友可以参考,这里不再展开介绍https://www.unihiker.com.cn/wiki/m10/unihiker_python_lib_2#|-%205.3-%E5%9B%BE%E7%89%87%20draw_image 值得注意的细节是,行空的屏幕默认是竖向显示,屏幕的分辨率是240*320,而我们本次的作品需要将行空板横向显示,所以不论是图片还是文字都需要旋转270°。而对应的坐标需要相应调整过来,关于行空板的坐标方向,以及不同控件的坐标基准点可以参考下图 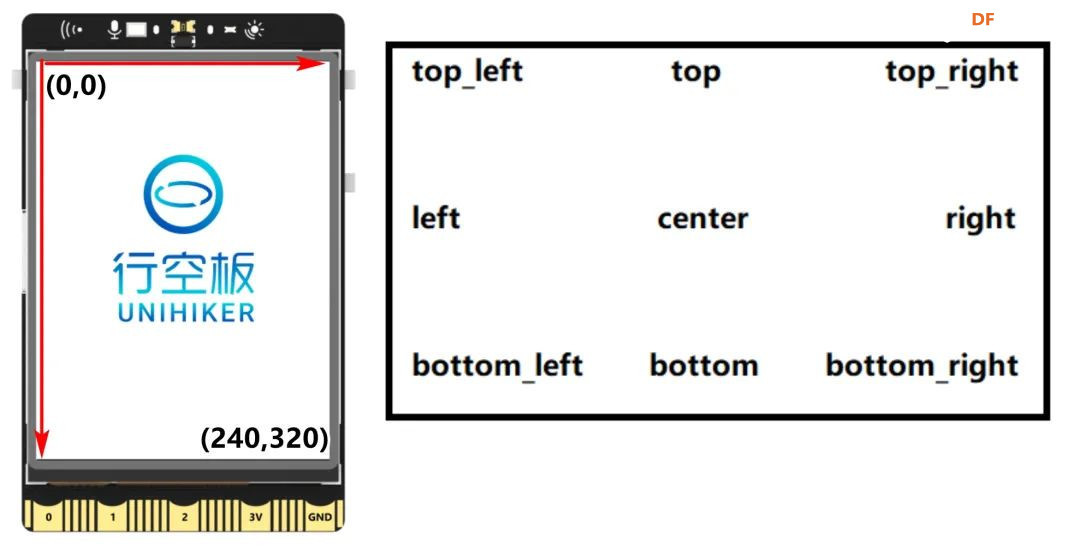 想必你已经发现了,界面中的图标设置了回调函数,也就是说图片是可以点击的,通过函数iconclick(data)实现点击不同的图片切换不同的模式。同时在界面中的文字显示部分由于选择的模式不同,显示的内容也会相应的切换,为此我们设置了状态管理类,并在界面初始化后,将其设置为全局引用,这样在不同的函数中都可以方便的调用更新内容 # ============== 状态管理类 ============== classAppState: def__init__(self): self.state = "" self.caption_text = None self.camera_image = None self.photo_count = 0 self.bgm = "" # 创建应用状态实例 app_state = AppState() deficonclick(data): """处理图标点击事件""" # 角色功能映射 ROLE_FUNCTION_MAP = {"1": "take_photo", "2": "select_music", "3": "upload"} app_state.state = ROLE_FUNCTION_MAP.get(data, "") print(f"状态更新为: {app_state.state}") deffirst_page(): # 页面初始化代码... ...... # 设置全局引用 app_state.caption_text = Caption_text app_state.camera_image = camera_image 至此,界面就设置好了,但并没有将要执行的函数与模式状态绑定起来。拍摄照片,工作流调用的函数在前面我们都已经设置完成,我们还需要设置一个选择背景音乐主题的函数,代码如下 from unihiker import GUI #导入包 from pinpong.board import * from pinpong.extension.unihiker import * Board().begin() #初始化 defmusic(): """音乐选择界面""" print("进入音乐选择模式") # 隐藏相机图标 app_state.camera_image.config(x=3000) # 音乐选项配置 music_options = [ {"text": "舒缓", "x": 140, "y": 130}, {"text": "田园", "x": 140, "y": 200}, {"text": "欢快", "x": 140, "y": 270}, {"text": "劲爆", "x": 60, "y": 130}, {"text": "喜庆", "x": 60, "y": 200}, {"text": "自然", "x": 60, "y": 270} ] # 创建音乐选项文本 music_texts = [] for option in music_options: text = gui.draw_text( x=option["x"], y=option["y"], text=option["text"], origin='center', font_size=14, angle=270 ) music_texts.append(text) # 创建选择框 rect_x = 125 rect_y = 105 music_rect = gui.draw_rect( x=rect_x, y=rect_y, w=30, h=50, width=3, color=(255, 0, 0) ) # 当前选择的音乐索引 current_index = 0 bgm_mapping = ["舒缓", "田园", "欢快", "劲爆", "喜庆", "自然"] # 音乐选择循环 while app_state.state == "select_music": # 处理A键按下 - 选择下一个音乐 if button_a.is_pressed(): time.sleep(0.2) # 防抖延时 # 更新选择索引 current_index = (current_index + 1) % len(bgm_mapping) # 计算新位置 if current_index < 3: rect_x = 125 else: rect_x = 45 rect_y = 105 + (current_index % 3) * 70 # 更新选择框位置 music_rect.config(x=rect_x, y=rect_y) print(f"选择音乐: {bgm_mapping[current_index]}") # 处理B键按下 - 确认选择 if button_b.is_pressed(): selected_bgm = bgm_mapping[current_index] print(f"确认选择: {selected_bgm}") return selected_bgm # 如果状态改变但未选择,返回默认值 return bgm_mapping[0] 代码中,我们设置了6种不同的音乐主题,为了让用户更直观的选择,设置了一个矩形选择框,通过按下按键A来切换,按下B键确认并返回,效果如下 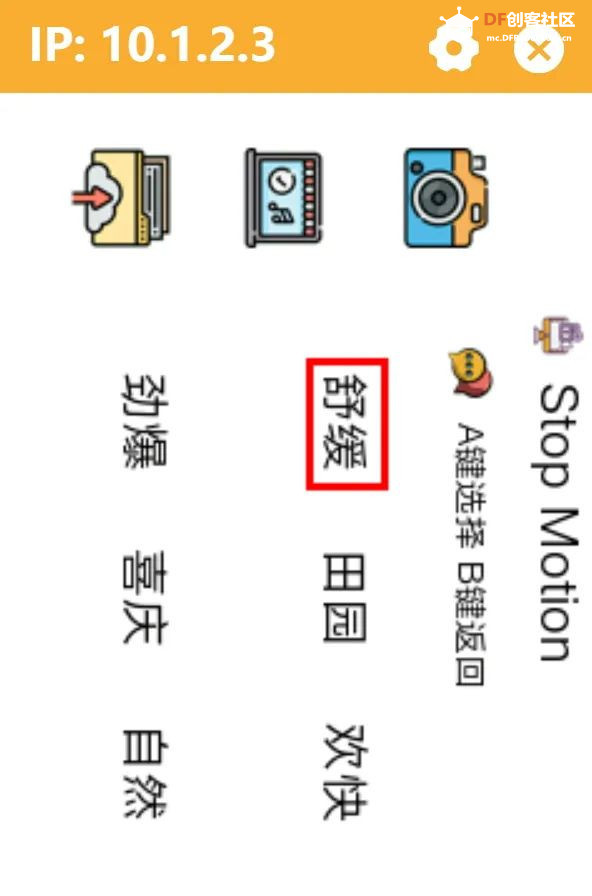 选择音乐主题的函数设置完成后,我们还需要设置一个状态选择函数,设置当点击不同的图标后切换到对应的函数,按下B键退出程序,代码如下 import requests, cv2,time, json,base64, asyncio, edge_tts from unihiker import GUI #导入包 from pinpong.board import * from pinpong.extension.unihiker import * from unihiker import Audio from PIL import Image defhandle_take_photo(): """处理拍照操作""" # 拍照并更新照片计数 app_state.photo_count = take_pictures() app_state.state = "" gui.clear() first_page() app_state.caption_text.config(text=f"已拍摄{app_state.photo_count}张照片,点击选择音乐") audio.play("photoOk.mp3") defhandle_select_music(): """处理音乐选择操作""" # 提示用户选择音乐 app_state.caption_text.config(text="A键选择 B键返回") audio.play("photo_music.mp3") # 选择音乐 app_state.bgm = music() print(f"选择的音乐: {app_state.bgm}") # 更新UI app_state.state = "" gui.clear() first_page() # 显示状态信息并播放语音提示 app_state.caption_text.config(text=f"拍摄{app_state.photo_count}张照片 选择主题{app_state.bgm}") generate_audio(f"拍摄{app_state.photo_count}张照片 选择的音乐主题是{app_state.bgm},点击文件图标可上传文件合成视频") defhandle_upload(): """处理上传操作""" upload(app_state.bgm) app_state.state = "" # ============== 主循环函数 ============== defselect_mode(): """主状态循环""" # 设置回调函数映射 state_handlers = { "take_photo": handle_take_photo, "select_music": handle_select_music, "upload": handle_upload } # 主循环 while button_b.is_pressed() != 1: if app_state.state in state_handlers: # 执行对应的状态处理函数 handler = state_handlers[app_state.state] try: handler() except Exception as e: print(f"状态处理错误: {str(e)}") app_state.caption_text.config(text="操作出错,请重试") app_state.state = ""完整代码 最后是本次定格动画生成器的完整代码 import requests, cv2,time, json,base64, asyncio, edge_tts from unihiker import GUI #导入包 from pinpong.board import * from pinpong.extension.unihiker import * from unihiker import Audio from PIL import Image # ============== 配置区域 ============== # 修改为你的实际路径 #IMAGE_FOLDER = r'F:\MyOffice\BaiduSyncdisk\design_file\myPython\M10\img' IMAGE_FOLDER = '/root/mindplus/M10/img/' COZE_TOKEN = 'pat_4BuSeWUu9JqEiH2BeYdleXbcKsyLNB4asOkAfDRRYhzAmy9JJ57dtwwkvtg8w5e4' WORKFLOW_ID = "7504802266752565285" # ============== 硬件初始化 ============== gui=GUI() #实例化GUI类 Board().begin() #初始化 audio = Audio() #实例化音频 # ============== 状态管理类 ============== classAppState: def__init__(self): self.state = "" self.caption_text = None self.camera_image = None self.photo_count = 0 self.bgm = "" # 创建应用状态实例 app_state = AppState() deffirst_page(): # 页面初始化代码... global camera_image, Caption_text # 统一旋转函数 defload_rotated_image(path): img = Image.open(path) return img.transpose(Image.ROTATE_270) # 加载并旋转所有图标 icons = { 'camera_icon': load_rotated_image("camera_icon.png"), 'camera': load_rotated_image("camera.png"), 'music': load_rotated_image("online-shopping.png"), 'upload': load_rotated_image("upload-file.png"), 'title': load_rotated_image("video-editing.png"), 'chat': load_rotated_image("chat.png") } title_text = gui.draw_text(x=240, y=170, text='Stop Motion',origin='top' ,color='black', angle=270) Caption_text = gui.draw_text(x=190, y=130, text="点击拍照 A键拍摄 B键返回",font_size=10,origin='left', angle=270) camera_image = gui.draw_image(x=180, y=140, w=160, h=200, image=icons['camera'], origin='top_right', onclick=lambda: iconclick('1') ) camera_icon = gui.draw_image(x=200, y=20, w=40, h=50, image=icons['camera_icon'], origin='top_right', onclick=lambda: iconclick('1')) music_icon = gui.draw_image(x=135, y=20, w=40, h=50, image=icons['music'], origin='top_right', onclick=lambda: iconclick('2')) upload_icon = gui.draw_image(x=70, y=20, w=40, h=50, image=icons['upload'], origin='top_right', onclick=lambda: iconclick('3')) title_icon = gui.draw_image(x=215, y=85, w=20, h=20, image=icons['title'], origin='top_left') chat_icon = gui.draw_image(x=180, y=100, w=20, h=20, image=icons['chat'], origin='top_left') # 设置全局引用 app_state.caption_text = Caption_text app_state.camera_image = camera_image deficonclick(data): """处理图标点击事件""" # 角色功能映射 ROLE_FUNCTION_MAP = {"1": "take_photo", "2": "select_music", "3": "upload"} app_state.state = ROLE_FUNCTION_MAP.get(data, "") print(f"状态更新为: {app_state.state}") defgenerate_audio(text: str) -> None: voice = "zh-CN-XiaoyiNeural" output_file = "audio.mp3" """ 传入文本、语音及输出文件名,生成语音并保存为音频文件 :param text: 需要合成的中文文本 :param voice: 使用的语音类型,如 'zh-CN-XiaoyiNeural' :param output_file: 输出的音频文件名 """ asyncdefgenerate_audio_async() -> None: """异步生成语音""" print(f"使用离线语音合成: {text}") communicate = edge_tts.Communicate(text, voice) await communicate.save(output_file) # 异步执行生成音频 asyncio.run(generate_audio_async()) audio.play(output_file) defdelete_files(folder_path): """清空文件夹内所有内容(保留文件夹本身)""" if os.path.exists(folder_path): for filename in os.listdir(folder_path): file_path = os.path.join(folder_path, filename) try: if os.path.isfile(file_path): os.unlink(file_path) print(f"已删除: {file_path}") except Exception as e: print(f"删除文件失败: {e}") deftake_photo(): """拍摄照片并保存到指定文件夹""" cap = cv2.VideoCapture(0) cap.set(cv2.CAP_PROP_FRAME_WIDTH, 320) #设置摄像头图像宽度 cap.set(cv2.CAP_PROP_FRAME_HEIGHT, 240) #设置摄像头图像高度 ifnot cap.isOpened(): print("无法打开摄像头") returnFalse # 确保目录存在 os.makedirs(IMAGE_FOLDER, exist_ok=True) delete_files(IMAGE_FOLDER) #cv2.namedWindow('Video Cam', cv2.WINDOW_NORMAL) #创建窗口"Video Cam" cv2.namedWindow('Video Cam',cv2.WND_PROP_FULLSCREEN) # 构建一个窗口,名称为Video Cam,默认属性为可以全屏 cv2.setWindowProperty('Video Cam', cv2.WND_PROP_FULLSCREEN, cv2.WINDOW_FULLSCREEN) i=0 print("按 'a' 拍照,按 'b' 退出") while cap.isOpened(): ret,frame = cap.read() ifnot ret: print("摄像头读取失败") break frame = cv2.rotate(frame,cv2.ROTATE_90_COUNTERCLOCKWISE) #逆时针旋转90度 cv2.imshow('Video Cam', frame) key = cv2.waitKey(1) & 0xFF if key == ord('a'): # 按a保存 audio.play("camera.wav") timestamp = int(time.time()) path = os.path.join(IMAGE_FOLDER, f"photo_{i}_{timestamp}.jpg") # 安全的路径拼接 if cv2.imwrite(path, frame): print(f"保存成功: {path}") i += 1 else: print(f"保存失败: {path}") elif key == ord('b'): # 按b退出 print("退出拍照模式") break cap.release() cv2.destroyAllWindows() return i # 返回是否拍摄了照片 deftake_pictures(): # 1. 拍摄照片 print("===== 拍照模式 =====") i = take_photo() if i==0: print("未拍摄照片,程序终止") return i defmusic(): """音乐选择界面""" print("进入音乐选择模式") # 隐藏相机图标 app_state.camera_image.config(x=3000) # 音乐选项配置 music_options = [ {"text": "舒缓", "x": 140, "y": 130}, {"text": "田园", "x": 140, "y": 200}, {"text": "欢快", "x": 140, "y": 270}, {"text": "劲爆", "x": 60, "y": 130}, {"text": "喜庆", "x": 60, "y": 200}, {"text": "自然", "x": 60, "y": 270} ] # 创建音乐选项文本 music_texts = [] for option in music_options: text = gui.draw_text( x=option["x"], y=option["y"], text=option["text"], origin='center', font_size=14, angle=270 ) music_texts.append(text) # 创建选择框 rect_x = 125 rect_y = 105 music_rect = gui.draw_rect( x=rect_x, y=rect_y, w=30, h=50, width=3, color=(255, 0, 0) ) # 当前选择的音乐索引 current_index = 0 bgm_mapping = ["舒缓", "田园", "欢快", "劲爆", "喜庆", "自然"] # 音乐选择循环 while app_state.state == "select_music": # 处理A键按下 - 选择下一个音乐 if button_a.is_pressed(): time.sleep(0.2) # 防抖延时 # 更新选择索引 current_index = (current_index + 1) % len(bgm_mapping) # 计算新位置 if current_index < 3: rect_x = 125 else: rect_x = 45 rect_y = 105 + (current_index % 3) * 70 # 更新选择框位置 music_rect.config(x=rect_x, y=rect_y) print(f"选择音乐: {bgm_mapping[current_index]}") # 处理B键按下 - 确认选择 if button_b.is_pressed(): selected_bgm = bgm_mapping[current_index] print(f"确认选择: {selected_bgm}") return selected_bgm # 如果状态改变但未选择,返回默认值 return bgm_mapping[0] classCozeAPI: """Coze API 操作类""" def__init__(self, access_token): self.base_url = "https://api.coze.cn/v1" self.access_token = access_token self.headers = { "Authorization": f"Bearer {access_token}" } def_upload_file(self, file_path): """上传单个文件到Coze""" url = f"{self.base_url}/files/upload" filename = os.path.basename(file_path) try: # 检查文件大小 file_size = os.path.getsize(file_path) if file_size > 512 * 1024 * 1024: # 512MB print(f"跳过 {filename} (超过512MB限制)") returnNone # 上传文件 withopen(file_path, 'rb') as file_obj: files = {'file': (filename, file_obj)} response = requests.post(url, headers=self.headers, files=files) response.raise_for_status() # 检查响应 result = response.json() if result.get('code') == 0: print(f"上传成功: {filename}") return result['data'] else: print(f"上传失败: {result.get('msg', '未知错误')}") returnNone except Exception as e: print(f"上传 {filename} 时出错: {str(e)}") returnNone defupload_images(self, folder_path): """批量上传图片文件到Coze""" image_data = [] valid_extensions = ('.png', '.jpg', '.jpeg', '.gif', '.bmp', '.webp') ifnot os.path.exists(folder_path): raise FileNotFoundError(f"文件夹不存在: {folder_path}") # 获取所有图片文件 image_files = [f for f in os.listdir(folder_path) if f.lower().endswith(valid_extensions)] ifnot image_files: print("文件夹中没有图片文件") return image_data print(f"发现 {len(image_files)} 张图片准备上传") # 批量上传 for filename in image_files: file_path = os.path.join(folder_path, filename) result = self._upload_file(file_path) if result: image_data.append(result) return image_data defrun_workflow(self, workflow_id, parameters): """执行工作流""" url = f"{self.base_url}/workflow/run" data = { "workflow_id": workflow_id, "parameters": parameters } print("执行工作流参数:") print(json.dumps(data, indent=4, ensure_ascii=False)) try: response = requests.post( url, headers=self.headers, data=json.dumps(data), timeout=60# 增加超时时间 ) response.raise_for_status() response_data = response.json() # 检查响应状态码 if response_data.get('code') != 0: print(f"工作流执行失败: {response_data.get('msg')}") returnNone print("工作流执行结果:") print(json.dumps(response_data, indent=4, ensure_ascii=False)) return response_data except requests.exceptions.RequestException as e: print(f"工作流请求失败: {str(e)}") returnNone defupload(BGM): """上传图片并执行工作流生成视频二维码""" print("开始上传和处理流程") # 初始化API api = CozeAPI(COZE_TOKEN) try: # 批量上传照片 print("\n===== 上传照片 =====") app_state.caption_text.config(text="正在上传照片") audio.play("upload_imging.mp3") upload_results = api.upload_images(IMAGE_FOLDER) ifnot upload_results: print("没有成功上传的照片,终止处理") app_state.caption_text.config(text="上传失败,无照片") returnFalse # 准备图片输入 image_entries = [{"file_id": item['id']} for item in upload_results] print(f"\n准备处理的图片: {len(image_entries)}张") app_state.caption_text.config(text=f"已上传{len(image_entries)}张照片 等待合成") audio.play("img_video.mp3") # 执行工作流 print("\n===== 执行工作流 =====") workflow_result = api.run_workflow( workflow_id=WORKFLOW_ID, parameters={ "img_input": image_entries, "text_input": BGM } ) ifnot workflow_result: print("工作流执行失败") app_state.caption_text.config(text="工作流执行失败") returnFalse # 处理工作流结果 if'data'in workflow_result: workflow_output = json.loads(workflow_result['data']) if'data'in workflow_output: # 解码二维码图片 bytes_data = base64.b64decode(workflow_output['data']) # 创建临时文件路径 qr_path = os.path.join(IMAGE_FOLDER, f"qrcode_{int(time.time())}.png") # 保存二维码图片 withopen(qr_path, "wb") as img_file: img_file.write(bytes_data) print(f"二维码已保存至: {qr_path}") # 旋转并显示二维码 img = Image.open(qr_path) img = img.transpose(Image.ROTATE_270) # 更新UI app_state.caption_text.config(text="视频已合成 扫码观看") app_state.camera_image.config(x=180, y=100, w=180, h=230,image=img) # 播放完成提示音 audio.play("video_finish.mp3") returnTrue print("未获取到有效的二维码数据") app_state.caption_text.config(text="未获取到二维码") returnFalse except Exception as e: print(f"程序异常: {str(e)}") app_state.caption_text.config(text=f"处理出错: {str(e)}") returnFalse finally: print("\n上传处理流程完成") defhandle_take_photo(): """处理拍照操作""" # 拍照并更新照片计数 app_state.photo_count = take_pictures() app_state.state = "" gui.clear() first_page() app_state.caption_text.config(text=f"已拍摄{app_state.photo_count}张照片,点击选择音乐") audio.play("photoOk.mp3") defhandle_select_music(): """处理音乐选择操作""" # 提示用户选择音乐 app_state.caption_text.config(text="A键选择 B键返回") audio.play("photo_music.mp3") # 选择音乐 app_state.bgm = music() print(f"选择的音乐: {app_state.bgm}") # 更新UI app_state.state = "" gui.clear() first_page() # 显示状态信息并播放语音提示 app_state.caption_text.config(text=f"拍摄{app_state.photo_count}张照片 选择主题{app_state.bgm}") generate_audio(f"拍摄{app_state.photo_count}张照片 选择的音乐主题是{app_state.bgm},点击文件图标可上传文件合成视频") defhandle_upload(): """处理上传操作""" upload(app_state.bgm) app_state.state = "" # ============== 主循环函数 ============== defselect_mode(): """主状态循环""" # 设置回调函数映射 state_handlers = { "take_photo": handle_take_photo, "select_music": handle_select_music, "upload": handle_upload } # 主循环 while button_b.is_pressed() != 1: if app_state.state in state_handlers: # 执行对应的状态处理函数 handler = state_handlers[app_state.state] try: handler() except Exception as e: print(f"状态处理错误: {str(e)}") app_state.caption_text.config(text="操作出错,请重试") app_state.state = "" # ============== 主入口 ============== if __name__ == '__main__': # 初始化UI first_page() # 播放启动音 audio.play("start.mp3") # 启动主循环 select_mode()  写在最后 通过这个项目,我成功地将开源硬件与AI技术相结合,制作出了一个能够独立完成定格动画拍摄与制作的智能硬件设备。 本次创客作品延续了以往的流程模式,亮点在于Agent的加持让创意得以轻松实现,为作品赋予独特魅力。另一方面,随着大模型的广泛应用,其信息滞后、无法调用API接口以及易出现幻觉等缺陷也逐渐凸显。为解决这些问题,Agent技术应运而生,而Coze平台凭借其起步早、生态丰富的优势,成为了该领域的佼佼者。它极大地降低了技术开发门槛,让普通人也能轻松搭建应用,实现技术的普及化。 本次项目虽是开源硬件和Agent工具的小型验证,但还是展现出了开源硬件和Agent技术在教育和创客领域的巨大潜力。AI不是替代创造的工具,而是让孩子专注创意的翅膀,我们可以通过工作流制作智能体,让智能硬件专注于稳定调用,其余复杂功能由工作流完成。以AI小智为例,利用Coze平台的Agent技术,不仅可以轻松复刻,还能让人们在搭建过程中熟悉技术原理,提升动手能力和创新思维。 在未来,我将继续探索更多开源硬件与AI技术的结合方式,分享更多有趣、实用的创意项目。也欢迎感兴趣的朋友一起加入,让更多人感受到AI技术的魅力和开源硬件的乐趣! 造物让生活更美好,我们下期再见  |



 沪公网安备31011502402448
沪公网安备31011502402448© 2013-2026 Comsenz Inc. Powered by Discuz! X3.4 Licensed

 置顶卡
置顶卡 变色卡
变色卡 千斤顶
千斤顶




 活跃会员
活跃会员
 宣传大使
宣传大使
 牛X认证
牛X认证
 创作达人
创作达人
 荣誉教师
荣誉教师
 ARD DAY
ARD DAY
 编辑选择奖
编辑选择奖
 编辑选择奖
编辑选择奖
 编辑选择奖
编辑选择奖
 编辑选择奖
编辑选择奖






