|
15497| 0
|
[入门] AlphaGo究竟是如何下棋的? |
|
之前文章,论坛很多童鞋探讨阿尔法狗是否称得上人工智能,以及阿尔法狗在围棋上战胜人有何意义。 这里特转载一篇文章,膜拜下现如今深度学习算法的大神们是怎么解决下围棋这个以前看来没法完成的问题的。  本文转载自: http://www.leiphone.com/news/201603/BcRduUPVUmHa6QPR.html 深度学习”是指多层的人工神经网络和训练它的方法。一层神经网络会把大量矩阵数字作为输入,通过非线性激活方法取权重,再产生另一个数据集合作为输出。这就像生物神经大脑的工作机理一样,通过合适的矩阵数量,多层组织链接一起,形成神经网络“大脑”进行精准复杂的处理,就像人们识别物体标注图片一样。 虽然神经网络在几十年前就有了,直到最近才形势明朗。这是因为他们需要大量的“训练”去发现矩阵中的数字价值。对早期研究者来说,想要获得不错效果的最小量训练都远远超过计算能力和能提供的数据的大小。但最近几年,一些能获取海量资源的团队重现挖掘神经网络,就是通过“大数据”技术来高效训练。 两个大脑AlphaGo是通过两个不同神经网络“大脑”合作来改进下棋。这些大脑是多层神经网络跟那些Google[url=]图片搜索[/url]引擎识别图片在结构上是相似的。它们从多层启发式二维过滤器开始,去处理围棋棋盘的定位,就像图片分类器网络处理图片一样。经过过滤,13 个完全连接的神经网络层产生对它们看到的局面判断。这些层能够做分类和逻辑推理。 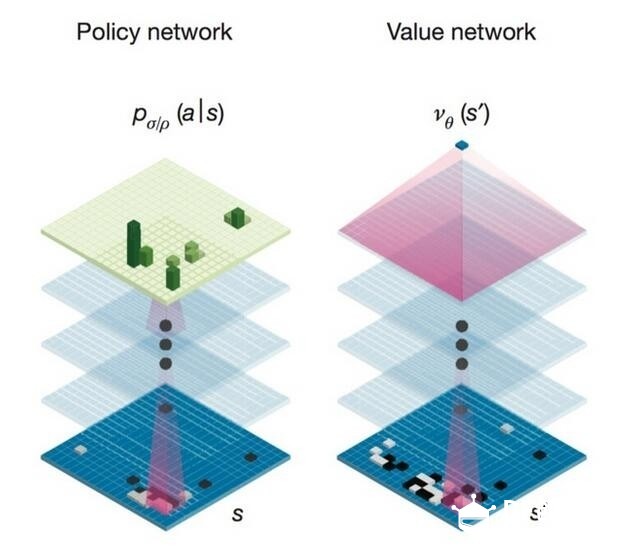 这些网络通过反复训练来检查结果,再去校对调整参数,去让下次执行更好。这个处理器有大量的随机性元素,所以我们是不可能精确知道网络是如何“思考”的,但更多的训练后能让它进化到更好。 第一大脑: 落子选择器 (Move Picker)AlphaGo的第一个神经网络大脑是“监督学习的策略网络(Policy Network)” ,观察棋盘布局企图找到最佳的下一步。事实上,它预测每一个合法下一步的最佳概率,那么最前面猜测的就是那个概率最高的。你可以理解成“落子选择器”。  (落子选择器是怎么看到棋盘的?数字表示最强人类选手会下在哪些地方的可能。) 团队通过在KGS(网络围棋对战平台)上最强人类对手,百万级的对弈落子去训练大脑。这就是AlphaGo最像人的地方,目标是去学习那些顶尖高手的妙手。这个不是为了去下赢,而是去找一个跟人类高手同样的下一步落子。AlphaGo落子选择器能正确符合57%的人类高手。(不符合的不是意味着错误,有可能人类自己犯的失误)
AlphaGo系统事实上需要两个额外落子选择器的大脑。一个是“强化学习的策略网络(Policy Network)”,通过百万级额外的模拟局来完成。你可以称之为更强的。比起基本的训练,只是教网络去模仿单一人类的落子,高级的训练会与每一个模拟棋局下到底,教网络最可能赢的下一手。Sliver团队通过更强的落子选择器总结了百万级训练棋局,比他们之前版本又迭代了不少。 单单用这种落子选择器就已经是强大的对手了,可以到业余棋手的水平,或者说跟之前最强的围棋AI媲美。这里重点是这种落子选择器不会去“读”。它就是简单审视从单一棋盘位置,再提出从那个位置分析出来的落子。它不会去模拟任何未来的走法。这展示了简单的深度神经网络学习的力量。
AlphaGo当然团队没有在这里止步。下面我会阐述是如何将阅读能力赋予AI的。为了做到这一点,他们需要更快版本的落子选择器大脑。越强的版本在耗时上越久-为了产生一个不错的落子也足够快了,但“阅读结构”需要去检查几千种落子可能性才能做决定。 Silver团队建立简单的落子选择器去做出“快速阅读”的版本,他们称之为“滚动网络”。简单版本是不会看整个19*19的棋盘,但会在对手之前下的和新下的棋子中考虑,观察一个更小的窗口。去掉部分落子选择器大脑会损失一些实力,但轻量级版本能够比之前快1000倍,这让“阅读结构”成了可能。 第二大脑:棋局评估器 (Position Evaluator) AlphaGo的第二个大脑相对于落子选择器是回答另一个问题。不是去猜测具体下一步,它预测每一个棋手赢棋的可能,在给定棋子位置情况下。这“局面评估器”就是论文中提到的“价值网络(Value Network)”,通过整体局面判断来辅助落子选择器。这个判断仅仅是大概的,但对于阅读速度提高很有帮助。通过分类潜在的未来局面的“好”与“坏”,AlphaGo能够决定是否通过特殊变种去深入阅读。如果局面评估器说这个特殊变种不行,那么AI就跳过阅读在这一条线上的任何更多落子。 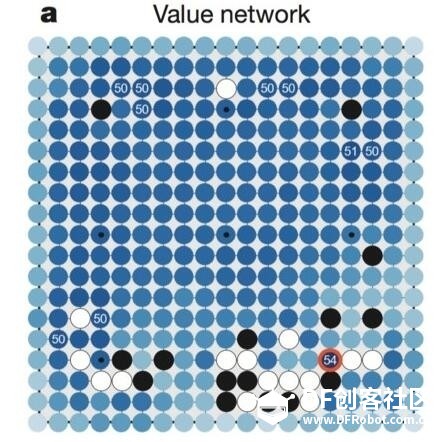 (局面评估器是怎么看这个棋盘的。深蓝色表示下一步有利于赢棋的位置。) 局面评估器也通过百万级别的棋局做训练。Silver团队通过 复制两个AlphaGo的最强落子选择器,精心挑选随机样本创造了这些局面。这里AI 落子选择器在高效创建大规模数据集去训练局面评估器是非常有价值的。这种落子选择器让大家去模拟继续往下走的很多可能,从任意给定棋盘局面去猜测大致的双方赢棋概率。而人类的棋局还不够多恐怕难以完成这种训练。
这里做了三个版本的落子选择大脑,加上局面评估大脑,AlphaGo可以有效去阅读未来走法和步骤了。阅读跟大多数围棋AI一样,通过蒙特卡洛树搜索(MCTS)算法来完成。但AlphaGo 比其他AI都要聪明,能够更加智能的猜测哪个变种去探测,需要多深去探测。 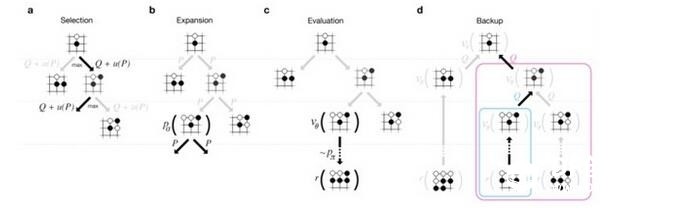 (蒙特卡洛树搜索算法) 如果拥有无限的计算能力,MCTS可以理论上去计算最佳落子通过探索每一局的可能步骤。但未来走法的搜索空间对于围棋来说太大了(大到比我们认知宇宙里的粒子还多),实际上AI没有办法探索每一个可能的变种。MCTS做法比其他AI有多好的原因是在识别有利的变种,这样可以跳过一些不利的。 Silver团队让AlphaGo装上MCTS系统的模块,这种框架让设计者去嵌入不同的功能去评估变种。最后马力全开的AlphaGo系统按如下方式使用了所有这些大脑。 1. 从当前的棋盘布局,选择哪些下一步的可能性。他们用基础的落子选择器大脑(他们尝试使用更强的版本,但事实上让AlphaGo更弱,因为这没有让MCTS提供更广阔的选择空间)。它集中在“明显最好”的落子而不是阅读很多,而不是再去选择也许对后来有利的下法。 2. 对于每一个可能的落子,评估质量有两种方式:要么用棋盘上局面评估器在落子后,要么运行更深入蒙特卡罗模拟器(滚动)去思考未来的落子,使用快速阅读的落子选择器去提高搜索速度。AlphaGo使用简单参数,“混合相关系数”,将每一个猜测取权重。最大马力的AlphaGo使用 50/50的混合比,使用局面评估器和模拟化滚动去做平衡判断。 这篇论文包含一个随着他们使用插件的不同,AlphaGo的能力变化和上述步骤的模拟。仅使用独立大脑,AlphaGo跟最好的计算机围棋AI差不多强,但当使用这些综合手段,就可能到达职业人类选手水平。 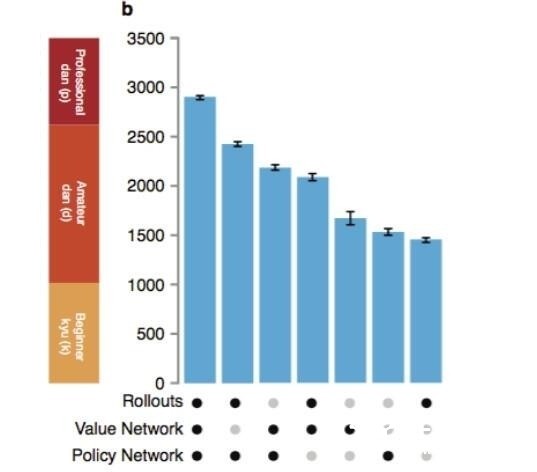 (AlphaGo的能力变化与MCTS的插件是否使用有关。) 这篇论文还详细讲了一些工程优化:分布式计算,网络计算机去提升MCTS速度,但这些都没有改变基础算法。这些算法部中分精确,部分近似。在特别情况下,AlphaGo通过更强的计算能力变的更强,但计算单元的提升率随着性能变强而减缓。 优势和劣势我认为AlphaGo在小规模战术上会非常厉害。它知道通过很多位置和类型找到人类最好的下法,所以不会在给定小范围的战术条件下犯明显错误。 但是,AlphaGo有个弱点在全局判断上。它看到棋盘式通过5*5金字塔似的过滤,这样对于集成战术小块变成战略整体上带来麻烦,同样道理,图片分类神经网络往往对包含一个东西和另一个的搞不清。比如说围棋在角落上一个定式造成一个墙或者引征,这会剧烈改变另一个角上的位置估值。 就像其他的基于MCTS的AI, AlphaGo对于需要很深入阅读才能解决的大势判断上,还是麻烦重重的,比如说大龙生死劫。AlphaGo 对一些故意看起来正常的局也会失去判断,天元开盘或者少见的定式,因为很多训练是基于人类的棋局库。 我还是很期待看到AlphaGo和李世石9段的对决!我预测是:如果李使用定式,就像跟其他职业棋手的对决,他可能会输,但如果他让AlphaGo陷入到不熟悉情形下,他可能就赢。 ;iudaosixway |
 活跃会员
活跃会员



 沪公网安备31011502402448
沪公网安备31011502402448© 2013-2026 Comsenz Inc. Powered by Discuz! X3.4 Licensed

 置顶卡
置顶卡 变色卡
变色卡 千斤顶
千斤顶






