|
9280| 6
|
一种面向自闭症群体基于深度学习构建情感日记及日常活... |

|
一种面向自闭症群体基于深度学习构建情感日记及日常活动识别系统 作者:浙江省诸暨市海亮高级中学 黄然 林肯 作品来源:第四届全国青少年人工智能创新挑战赛之单片机创意智造挑战赛晋级作品 指导老师:浙江省诸暨市海亮高级中学 郦钰筠 屠露洁 作品主旨 “人文关怀” 其他主题:自闭症、深度学习、计算机视觉、情感日记、活动识别、人工智能 创意来源 你知道“小星星”吗?他们是自闭症儿童,就像天上的星星,在遥远而漆黑的夜空中闪烁着。截止2019年,《中国自闭症教育康复行业发展状况报告》披露:中国的自闭症患者数量超过1000万,其中自闭症儿童人数缠过200万,并以每年接近20万的速度递增,在国内,每143名儿童中就有1名自闭症患者,他们就在我们的身边,他们沉浸在自己的世界里,对别人的言语也没反应,兴趣爱好也十分单一,但是,他们也有自己的渴求,点亮星心,有爱不孤独,自闭症目前没有药物可以治愈,需要终生看护,最有效的方法的是早期教育干预,我们将用科技赋能自闭症群体,为他们基于深度学习构建情感日记及日常活动识别系统,关注他们美好的明天。  作品概述 每一个自闭症孩子的妈妈都希望比孩子多活一天,帮助孩子交更多的朋友,拉近孩子与世界的距离,让孩子拥有一个更加美好的明天。我们愿做星星的守护者,一起守护星星的孩子,我们将应用人工智能技术为他们构建情感日记及日常活动识别系统。该系统在硬件方面仅仅使用树莓派4B、摄像头、显示屏就可以了。核心算法包括两部分:①基于深度学习卷积神经网络构建情感识别模型,具体有七种情绪:愤怒,厌恶,恐惧,快乐,中立,悲伤和惊讶。该算法主要功能用于情绪识别,全天记录自闭症群体的情绪,进一步构建情感日记。②第二个核心算法是基于CV和深度学习的日常活动识别算法,训练的模型包括400-700个人类活动,比如使用电脑、弹吉他、打网球等,该模型的识别精确度可以达到78.4-94.5%,我们使用的神经网络是ResNet,其中将模型结构已修改为使用3D内核而不是标准的2D过滤器,从而使该模型可以包含用于活动识别的时间组件,该算法将应用于自闭症群体正确执行任务及日常活动监测。 作品展示 功能简介 (一)总体功能概述 首先应用tensorflow深度学习框架构建情绪识别模型,该模型可以识别七种情绪:愤怒、厌恶、恐惧、快乐、中立、悲伤和惊讶,接着应用OpenCV和深度学习进行实时日常活动识别及异常检测。在硬件方面主要使用树莓派4B和摄像头,主要功能用于情绪识别,全天记录自闭症群体的情绪,进一步构建情感日记,帮助自闭症群体正确执行日常行为及日常活动识别监测。 (二)核心算法简介 1、应用TensorFlow实现实时情绪检测 首先使用FER-2013数据集的35887张人脸图像训练了情绪检测模型,该数据集由48x48的灰度图像组成,在图像中标记了七种情绪。需要的软件包包括:Python3、OpenCV及TensorFlow。该算法可以在资源受限的树莓派上做到实时检测情绪,通常,该算法会检测摄像捕捉到的所有的面部情绪。使用简单的4层 CNN,测试准确率在50个epoch中达到 63.2%,如图1所示。 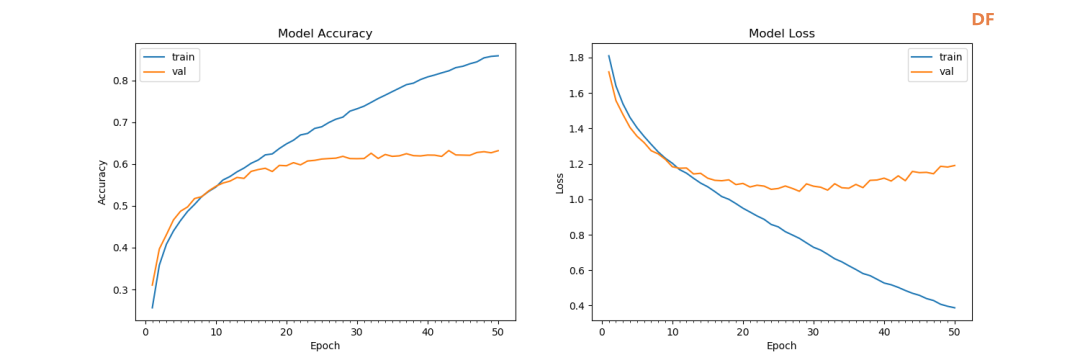 图1 accuracy 算法的流程:首先,使用haar 级联方法检测摄像头中捕捉到的每一帧图像中的人脸;然后把包含人脸的图像区域调整为48x48的大小,并作为输入传递给 CNN卷积神经网络;接着网络输出七类情绪的softmax分数列表;最后将在屏幕上显示出得分最高的情绪状态,实时识别截图如图2所示。  图2 实时识别效果 2、使用OpenCV和深度学习进行日常活动识别 我们使用了Kinetics数据集,训练了人类活动识别模型,该模型包括400-700个人类活动,比如使用电脑、弹吉他、打网球等,该模型的识别精确度可以达到78.4-94.5%,并且使用用于人类活动识别的3D ResNet,如图3所示,深度神经网络使用 ImageNet 在图像分类方面的进步也导致深度学习活动识别取得了成功。 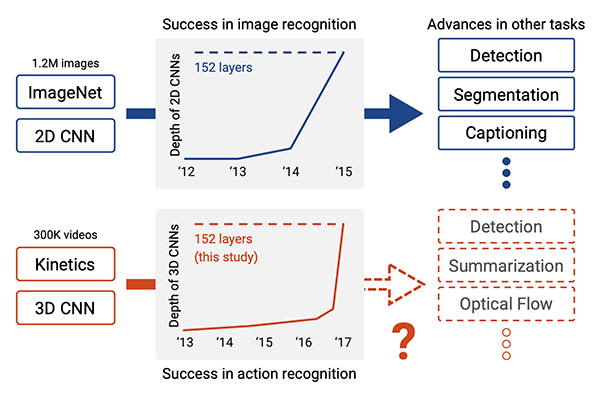 图3 深度神经网络使用 ImageNet 在图像分类方面的进步也导致深度学习活动识别取得了成功 在这里,我们修改了部分模型结构,使用3D内核而不是标准的2D过滤器,从而使该模型可以包含用于活动识别的时间组件,并且我们通过3D内核将现有2D架构扩展到视频分类工作,大规模的ImageNet数据集可以将此类模型训练到较高的准确度,且Kinetics的数据集也是足够大的,因此,这些架构应该能够通过改变输入体积的形状以包含时空信息及利用架构内部的3D内核来执行视频分类,该算法将实际应用于自闭症群体正确执行任务及日常活动监测,效果截图如图4所示。  图4实时活动识别效果图 硬件清单 树莓派4B摄像头 电源适配器 显示屏 HDMI线 数据线 电路连线图 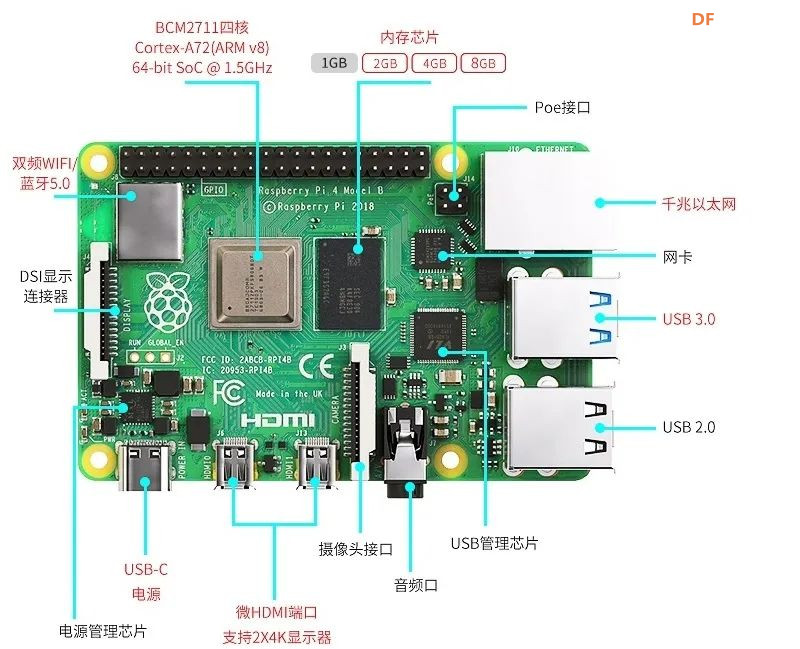 图5树莓派接口信息图  图6 摄像头连接树莓派  图7 排线连接摄像头 制作过程 (一)结构设计 该作品的外观结构设计成盒子类型的,并且每个面都留有相应的接线口,面与面之间通过榫卯连接,不用热熔胶或者螺丝就可以固定,材料使用3mm木板,实物用激光切割而成。如图8所示。  图8 外观结构激光切割实物 (二)外观结构组装 激光切割的每个面通过榫卯连接就可以快速组装,拼接而成的实物图如图9所示。  图9 外观实物图 树莓派直接固定在盒子里面,摄像头通过排线来连接,这里舵机云台只是为了固定摄像头,没有其他的作用,可以使用其他支架代替,完整的效果图如图10所示。  图10 完整的效果图 (三)算法开发 1、配置开发环境 (1)安装系统 ①下载系统 Raspbian系统下载地址:https://www.raspberrypi.org/downloads/raspberry-pi-os/建议使用“带桌面和推荐软件的Raspbian Buster”,如图11所示,点击Download ZIP进行下载。 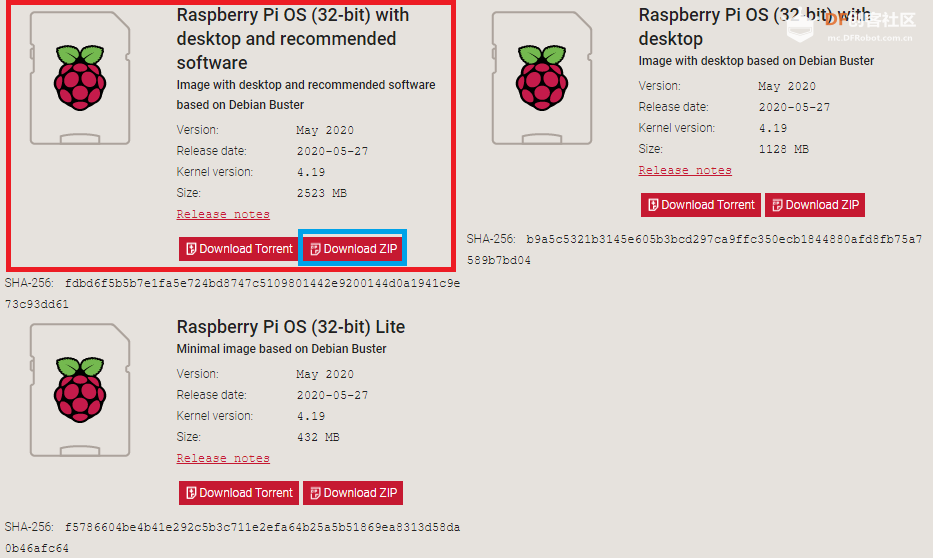 图11 树莓派官方系统 ②格式化TF卡(新卡可以不格式化处理) 下载格式化工具:SD card formatte https://www.sdcard.org/downloads/formatter/eula_windows/index.html,将TF卡插入读卡器并连接电脑,打开软件,选择需要格式化的卡,点击Format,其他选项默认。 ③系统镜像写入tf卡 下载写入工具:win32diskimager https://sourceforge.net/projects/win32diskimager/files/Archive/win32diskimager-1.0.0-install.exe/download?use_mirror=nchc,解压下载的ZIP包得到一个.img的镜像文件(解压路径不能含有中文),使用win32diskimager软件,选择设备和解压的.img的镜像文件,点击写入,几分钟后,写入过程应已完成,将Micro SD卡插入Raspberry Pi 4中,然后启动。 ④换源(更换源为中科大的源) 备份源文件 sudo cp /etc/apt/sources.list /etc/apt/sources.list.bak sudo cp /etc/apt/sources.list.d/raspi.list /etc/apt/sources.list.d/raspi.list.bak 编辑软件源文件,如图12所示。 sudo nano /etc/apt/sources.list 将原有的注释掉,把中科大的源复制进去。 中科大的软件源:deb http://mirrors.ustc.edu.cn/raspbian/raspbian/ buster main contrib non-free rpi 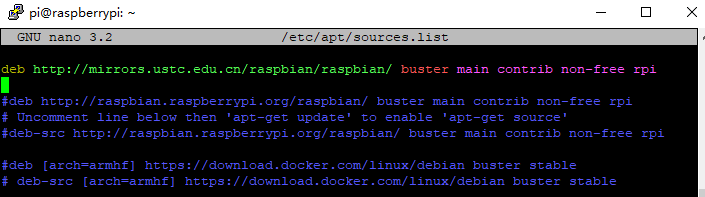 图12 编辑软件源文件 按Ctrl + O保存 , 回车Enter确定 , Ctrl + X 退出编辑 编辑修改系统更新源,如图13所示。 sudo nano /etc/apt/sources.list.d/raspi.list 将原有的注释掉,把中科大的系统源复制进去 科大的系统源:deb http://mirrors.ustc.edu.cn/archive.raspberrypi.org/debian/ buster main ui 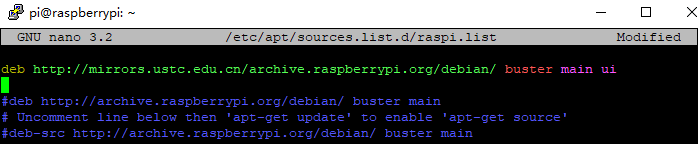 图13 编辑修改系统更新源 按Ctrl + O保存 , 回车Enter确定 , Ctrl + X 退出编辑 逐步更新一下 sudo apt-get update sudo apt-get upgrade sudo apt-get dist-upgrade sudo rpi-update ⑤基础设置 设置界面基本情况(第一项:Change User Password:更改用户登录密码,也就是登录树莓派的raspberry 密码。点击进入就可以设置新的登陆密码。第二项:Network Options:网络设置, 打开这个设置后可以连接wifi,设置机器名称 ,接口启用禁止等。第三项:Boot Options :启动时选择进入的环境(命令模式/图形化模式)。第四项:Localisation Options :**本地化设置包含:language语言设置/Timezone时区设置/Keyboard键盘布局/wifi country 无线wif国家设置。第五项:Interfacing Options :系统功能设置,包含Camera摄像头启用 / SSH启用/VNC启用/SPI启用/I2C启用/serial启用/wire/GPIO 需要用到哪些就开启哪些功能。第六项:Overclock:超频会减少树莓派使用寿命,正常情况下不建议超频使用。第七项:Advanced Options:高级设置,包含扩展TF卡使用空间/显示器overscan’设置/memorySplit设置/Audio音频输出设置/分辨率设置/等等。第八项:Update:**系统更新,用于升级更新系统。第九项:About raspi-cofnig:关于设置的系统。 启用VNC 终端输入以下命令进入配置界面。 sudo raspi-config 依次操作:5 Interfacing Options -> 3 VNC -> Yes。 设置分辨率sudo raspi-config 依次操作:7advanced Options -> resolution-> 选择分辨率,输入y之后回车。 ⑥扩展文件系统并回收空间 运行raspi-config并扩展您的文件系统: sudo raspi-config 依次操作:7 Advanced Options->A1 Expand filesystem,然后重新启动树莓派,重新启动后,文件系统应已扩展为包括micro-SD卡上的所有可用空间。可以通过执行df -h操作来验证磁盘是否已扩展并查看输出。 我建议同时删除Wolfram Engine和LibreOffice,可以使Raspberry Pi回收约1GB的空间: sudo apt-get purge wolfram-engine sudo apt-get purge libreoffice * sudo apt-get clean sudo apt-get autoremove (2)安装TensorFlow2.0.0 ①对apt-get升级列表进行更新 sudo apt-get update ②安装pip3 pip3 是一个用来安装各种库、软件的工具,等下要用它安装tensorflow(除了tensorflow之外,pip3还可以安装很多东西),执行下面这句命令 sudo apt-get install python3-pip python3-dev ③下载tensorflow2.0.0 直接在windows中通过GitHub下载tensorflow安装包,然后拷贝到树莓派/home/pi目录下。 下载tensorflow-2.0.0-cp37-none-linux_armv7l.whl版本,如图14所示。 https://github.com/lhelontra/tensorflow-on-arm/releases  图14 TensorFlow版本选择 ④安装tensorflow2.0.0 sudo pip install tensorflow-2.0.0-cp37-none-linux_armv7l.whl !注意:在安装过程中可能会报错: ERROR: Cannot uninstall 'wrapt'. It is a distutils installed project and thus we cannot accurately determine which files belong to it which would lead to only a partial uninstall. 解决方案:sudo pip install -U --ignore-installed wrapt ERROR: tensorboard 1.14.0 has requirement setuptools>=41.0.0, but you’ll have setuptools 39.1.0 which is incompatible. 解决方案:sudo pip install --upgrade setuptools ⑤测试 python3 #在python3界面中输入以下代码 import tensorflow as tf a = tf.constant(2.) b = tf.constant(4.) print('a+b=',a+b) 不报错将表示安装成功。 (3)安装Keras sudo apt-get install libhdf5-serial-dev sudo pip install h5py sudo apt-get install python-scipy 亲测不能使用pip安装 sudo pip install keras (4)安装OpenCV4.1.1 ①安装依赖项 这些优化库对于资源受限的设备(例如Raspberry Pi)尤其重要。 更新和升级任何现有软件包: sudo apt-get update && sudo apt-get upgrade 安装一些开发工具,包括CMake,它可以帮助我们配置OpenCV构建过程: sudo apt-get install build-essential cmake pkg-config 安装一些图像I /O包,以允许我们从磁盘加载各种图像文件格式: sudo apt-get install libjpeg-dev libtiff5-dev libjasper-dev libpng-dev 安装视频I/O包,这些库使我们能够从磁盘读取各种视频文件格式,以及直接使用视频流: sudo apt-get install libavcodec-dev libavformat-dev libswscale-dev libv4l-dev sudo apt-get install libxvidcore-dev libx264-dev OpenCV库带有一个名为highgui的子模块,它用于在我们的屏幕上显示图像并构建基本的GUI。为了编译highgui模块,我们需要安装GTK开发库和前提条件: sudo apt-get install libfontconfig1-dev libcairo2-dev sudo apt-get install libgdk-pixbuf2.0-dev libpango1.0-dev sudo apt-get install libgtk2.0-dev libgtk-3-dev 通过安装一些额外的依赖项,可以进一步优化OpenCV内部的许多操作(即矩阵操作): sudo apt-get install libatlas-base-dev gfortran 安装Python 3头文件 sudo apt-get install python3-dev sudo pip install numpy ②从源代码编译安装OpenCV 4.1.2 下载opencv和opencv_contrib。在这儿,我们将使用OpenCV 4.1.2版本。 cd ~ wget -O opencv.zip https://github.com/opencv/opencv/archive/4.1.2.zip wget -O opencv_contrib.zip https://github.com/opencv/opencv_contrib/archive/4.1.2.zip unzip opencv.zip unzip opencv_contrib.zip mv opencv-4.1.2 opencv mv opencv_contrib-4.1.2 opencv_contrib 增加SWAP空间 在开始编译之前,你必须增加SWAP空间。增加SWAP将使你能够使用Raspberry Pi的四个内核来编译OpenCV(并且不会由于内存耗尽而导致编译挂起)。 打开/etc/dphys-swapfile文件: sudo nano /etc/dphys-swapfile 然后编辑CONF_SWAPSIZE变量: #CONF_SWAPSIZE = 100 CONF_SWAPSIZE = 2048 保存并通过退出: Ctrl + X , ÿ , Enter。 重新启动交换服务: sudo /etc/init.d/dphys-swapfile stop sudo /etc/init.d/dphys-swapfile start 请注意,将交换空间从100MB增加到2048MB,这对于在Raspbian Buster上多线程编译OpenCV至关重要。我们的测试表明,在OpenCV编译时,2048MB的交换最有效地防止了锁定挂起。如果不增加SWAP,则你的树莓派很可能在编译过程中挂起。 设置编译参数 cd ~/opencv mkdir build cd build cmake -D CMAKE_BUILD_TYPE=RELEASE \ -D CMAKE_INSTALL_PREFIX=/usr/local \ -D OPENCV_EXTRA_MODULES_PATH=~/opencv_contrib/modules \ -D ENABLE_NEON=ON \ -D ENABLE_VFPV3=ON \ -D BUILD_TESTS=OFF \ -D INSTALL_PYTHON_EXAMPLES=OFF \ -D OPENCV_ENABLE_NONFREE=ON \ -D CMAKE_SHARED_LINKER_FLAGS=-latomic \ -D BUILD_EXAMPLES=OFF .. 成功如图15所示:  ④编译 使用四个内核来编译: make -j4 如果编译至99%一直停止不动,则使用命令:make clean,然后使用单线程编译即可,命令:make 编译成功如图16所示:  图16 编译成功截图 ⑤安装 sudo make install sudo ldconfig ⑥重置SWAP 打开/etc/dphys-swapfile文件,CONF_SWAPSIZE值设置为100MB,然后重新启动交换服务。 ⑦测试OpenCV4.1.2是否安装成功 cd ~ $ python3 >>> import cv2 >>> cv2.__version__ '4.1.2' >>> 如果不报错,将表示安装成功。 (5)设置wifi热点,方便远程操作 ①安装依赖 安装 network-manager sudo apt-get install network-manager 安装 git sudo apt-get install git 安装依赖库 sudo apt-get install util-linux procps hostapd iproute2 iw haveged dnsmasq ②克隆 git 项目 克隆 git 项目到本地进行编译。 sudo git clone https://github.com/oblique/create_ap cd create_ap sudo make install ③启用热点 sudo create_ap wlan0 eth0 <热点名> <密码> 热点以服务开机重启 修改 create_ap.service 服务功能的配置 sudo nano /etc/create_ap.conf 设置自己的 GATEWAY(网关)、SSID(热点名)、PASSPHRASE(密码) GATEWAY=192.168.12.11 SSID=autocar PASSPHRASE=12345678 设置服务开机启动。 systemctl enable create_ap.service 启动服务: systemctl start create_ap.service 2、应用TensorFlow实现实时情绪检测 首先创建data文件夹,下载FER-2013数据集,下载完之后会包括test和train两部分,每一部分都包含7种情绪的数据。 接下来新建Python文件:emotions.py,进行算法开发,完整的代码如下所示,首先导入需要使用的库,接着首先,使用haar 级联方法检测摄像头捕捉到的每一帧中的人脸。然后将包含人脸的图像区域被调整为48x48,并作为输入传递给 CNN,最后网络输出七类情绪的softmax 分数列表,屏幕上将会显示得分最高的情绪。 代码: 接下来,训练模型,使用以下命令python3 emotions.py --mode train,训练过程如图17所示。  图17 训练过程 接下来,使用训练好的模型查看识别效果,如图18所示。  图18 识别效果图 3、使用OpenCV和深度学习进行日常活动识别 首先下载Kinetics数据集的类标签、Hara 等人在 Kinetics 数据集上训练的日常活动识别卷积神经网络。 接下来,新建日常活动识别脚本,一次性采样N帧进行活动分类预测。 首先,导入必须用到的软件包,接着解析命令行参数。 接下来,初始化,加载类标签,定义样本持续时间(即用于分类的帧数)和样本大小(即帧的空间维度)。 接下来,加载并初始化人类活动识别模型,并且获取指向输入视频流的指针。 接下来,开始循环帧并执行日常活动识别 接下来,构建blob。 接下来,通过网络传递blob来获取人类活动,开始识别预测。 最后在终端执行以下命令,python3 human_activity_reco.py--modelresnet-34_kinetics.onnx--classes action_recognition_kinetics.txt,将实时识别活动,效果截图如图19所示。  图19 活动识别效果 项目总结 该项目主要面向的对象是自闭症群体,使用计算机视觉、深度学习等人工智能技术赋能自闭症等弱势群体,为他们构建情感日记、日常活动识别及异常检测系统,下一步,我们将添加更多的功能,开发通讯助理功能,帮助自闭症群体学习或关联用户常用的项目或短语,以便他们可以交流,未来我们将打造成一款富有爱心和硬核科技的家庭自动化产品。 未来展望 在未来,我们将不断优化我们的作品,将它应用于实际的生活中,实现他的公益价值。因为我们知道他们生活在我们的身边,却无法融入这个美丽的世界,他们虽然不知道如何交流,但也渴望拥有朋友,我们希望,对这些孩子多一份关心和支持,有爱不孤独。 附件:  一种面向自闭症群体基于深度学习构建情感日记及日常活动识别系统.zip.zip 一种面向自闭症群体基于深度学习构建情感日记及日常活动识别系统.zip.zip |



 沪公网安备31011502402448
沪公网安备31011502402448© 2013-2026 Comsenz Inc. Powered by Discuz! X3.4 Licensed


 置顶卡
置顶卡 变色卡
变色卡 千斤顶
千斤顶



 萌萌哒新人
萌萌哒新人
 活跃会员
活跃会员
 宣传大使
宣传大使
 志“童”道合
志“童”道合
 编辑选择奖
编辑选择奖






