本帖最后由 NciJlUN1qMan 于 2022-7-18 10:05 编辑
第十三课、人脸识别之智能门禁
在日常生活中,你是不是遇到过忘记带钥匙回不了家、或是已经走出家门还要返回确认有没有锁好门的情景?
现如今,无论是人脸扫描进出车站、刷脸支付、校园安全管理、人脸打卡等场景,都离不开人脸识别技术的应用。如果家里的门锁也能通过识别人脸打开,就可以避免丢钥匙或忘记带钥匙时,不能进家门的烦恼了。
这节课上,让我们结合行空板和摄像头,一起来设计一个能够识别主人人脸的智能门禁系统吧!
任务目标
使用USB摄像头来实时显示环境画面,当检测到认识的人脸时,在画面上显示相应的标记ID,并控制舵机转动模拟开门。
知识点
1、认识舵机
2、学习使用Pinpong库控制舵机转动的方法
3、了解人脸识别
4、学习使用opencv库进行人脸识别的方法
5、学习使用opencv库在图像上绘制文字、绘制矩形的方法
6、学习使用PIL库Image模块转换图像格式的方法
7、学习使用os库作文件处理的方法
材料清单
硬件清单:
软件使用:Mind+编程软件x1
Tips:Mind+官网已经发布正式支持行空板的版本了,如果用的还是测试版的请更新
知识储备
1、什么是舵机
舵机是一种能控制物体转至指定位置(角度)的执行器,常见的舵机有180°和360°两种,这里我们使用的是180°舵机。
2、Pinpong库Servo类angle()方法控制舵机转动
Pinpong库Servo类中的angle()方法可以控制舵机转动至指定位置,在使用前,我们需要先导入Pinpong库,初始化行空板,实例化Servo类来创建一个对象。
- from pinpong.board import Board,Pin,Servo # 导入Pinpong库
- Board("UNIHIKER").begin() #初始化,选择板型,不输入板型则进行自动识别
- s1 = Servo(Pin(Pin.P23))# 将Pin传入Servo中初始化舵机引脚
- s1.angle(10) # 控制舵机转到10度位置
其中,Servo与Board 类似,都是pinpong.board包下的模块。“P23”指的是板子上舵机所连接的引脚,“Pin(Pin.P23)”是在创建一个引脚对象,最后将这个引脚对象传入Servo类中进行实例化,创建得到一个servo对象。“10”指的是10°位置。
3、什么是人脸识别
人脸识别,是基于人的脸部特征信息进行身份识别的一种生物识别技术。用摄像机或摄像头采集含有人脸的图像或视频流,并自动在图像中检测和跟踪人脸,进而对检测到的人脸进行脸部识别的一系列相关技术,通常也叫做人像识别、面部识别。
简单来说,人脸识别就是对人脸图像进行判断,并识别出其对应人的过程。它解决的是“这是谁的脸”问题。
人脸识别一般包括如下四个环节:
1)人脸检测:是在图像中定位人脸区域的过程。(也就是关心是否是人脸)
2)人脸预处理:调整人脸图像,使其看起来更加清楚。
3)采集和学习人脸:采集检测到并经过预处理的人脸图,然后学习记住它们。
4)人脸识别:在采集学习过的人脸中查找哪一个人脸与要识别的人脸最类似。
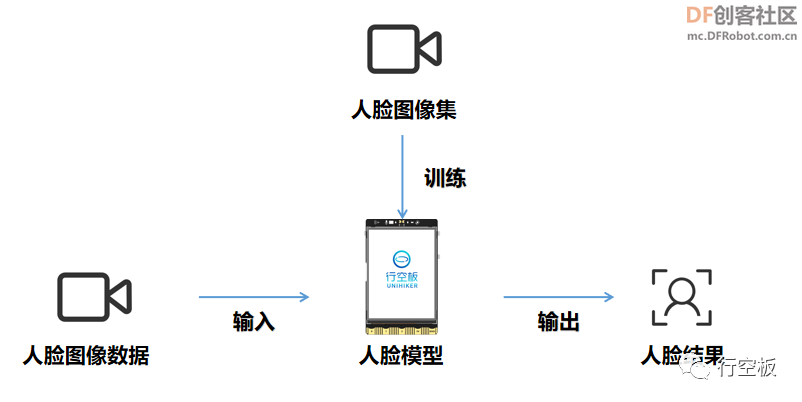
其中,前三个环节是为最终第四步进行人脸识别作的铺垫。在设计程序进行人脸识别时我们要先对检测到并经过预处理的人脸进行采集得到一个人脸图像集;之后对这些图像集进行学习将其训练成一个人脸模型;最后在识别时,再实时采集图像数据并输入到生成的人脸模型中,输出得到一个人脸结果,如下图。
4、什么是LBPH人脸识别
人脸检测是人脸识别的第一步,在进行人脸检测时,我们可以借助级联分类器,而在进行人脸识别时,我们同样可以借助一些方法。
Opencv提供了3种人脸识别方法,分别是LBPH方法、EigenFishfaces方法、Fisherfaces方法。这节课,我们采用的就是LBPH方法,通过Opencv自带的LBPH识别器来训练人脸模型并检测实时的人脸,因此,这个项目中,我们将过程分为“采集人脸数据”、“训练人脸模型”、“实时识别人脸”这三步进行。
LBPH(Local Binary PatternsHistograms)局部二进制编码直方图,是一种人脸识别算法,用于识别人脸。建立在LBPH基础之上的人脸识别法基本思想如下:首先以每个像素为中心,判断与周围像素灰度值大小关系,对其进行二进制编码,从而获得整幅图像的LBP编码图像;再将LBP图像分为个区域,获取每个区域的LBP编码直方图,继而得到整幅图像的LBP编码直方图,通过比较不同人脸图像LBP编码直方图达到人脸识别的目的,其优点是不会受到光照、缩放、旋转和平移的影响。
这里我们简单了解即可。
5、Opencv库LBPH识别器的使用
(1)生成LBPH识别器
在Opencv中,可以用函数“cv2.face.LBPHFaceRecognizer_create()”创建LBPH识别器实例。
- recognizer = cv2.face.LBPHFaceRecognizer_create()# 生成LBPH识别器模型实例
其中,recognizer是个变量,用于存储生成的识别器模型实例。
(2)LBPH识别器对象的“train()”方法训练模型
在生成LBPH识别器后,可以通过“train()”方法来训练模型。在训练时,需要提供人脸的图片样本以及图片对应的ID编号给到空的模型文件。
- recognizer.train(faces, np.array(Ids))# 训练模型
其中,faces是个列表,存储用来训练的人脸图像;np.array(Ids)指的是人脸图像所对应的ID标签。
(3)LBPH识别器对象的“save()”方法保存模型
在生成LBPH识别器后,可以通过“save()”方法来将指定模型保存到指定路径下。
- img_src='/root/image/project14' # Mind+中运行时需要指定到固定位置(指定图片路径)
- recognizer.save(img_src+'/model.yml')# 保存模型
其中,img_src是指定的模型存储的路径;model.yml指的是保存的模型文件名。
(4)LBPH识别器对象的“read()”方法读取模型
在生成LBPH识别器后,可以通过“read()”方法来读取模型。
- recognizer.read(img_src+'/model.yml')# 读取模型
其中,img_src是指模型所在的路径;model.yml指的是读取的模型文件名。
(5)LBPH识别器对象的“predict()”方法预测人脸图像
在读取人脸模型之后,可以通过“predict()”方法来识别预测人脸图像。
- img_id, confidence = recognizer.predict(gray[y:y + h, x:x + w])# 预测
其中,gray[y:y + h, x:x + w]指的是预测用的图像,也就是图片中人脸部分的灰度图;img_id是指返回的识别结果标签;confidence则是返回的置信度评分。置信度评分用来衡量识别结果与原有模型之间的距离,0表示完全匹配,通常情况下,认为小于50的值是可以接收的,如果该值大于80,则认为差别较大。
6、Opencv库“putText()”函数在图像上绘制文字
Opencv库的“putText()”函数可以帮助我们在图像上绘制文字,在使用时我们需要先导入库,并设置好字体类型。
- import cv2
- font = cv2.FONT_HERSHEY_SIMPLEX # 设置字体类型(正常大小的sans-serif字体)
- cv2.putText(img, 'shooting', (10, 50), font, 0.6, (0, 255, 0), 2) # 在图像画面上显示文字shooting表示正在采集人脸
其中,cv2.FONT_HERSHEY_SIMPLEX是设置的一种字体类型,存储在变量font中;img是指要显示文字的图像;“shooting”是指要显示的具体文字内容;(10,50)是指绘制字体的位置,以文字的左下角为起点;0.6对应文字的大小;(0,255,0)是用rgb值表示的颜色,这里指绿色;2对应指的是线的粗细。
7、Opencv库“rectangle()”函数绘制矩形
Opencv库的“rectangle()”函数可以帮助我们在图像上绘制方框矩形以圈出识别到的人脸。
- cv2.rectangle(img, (x, y), (x + w, y + h), (0, 255, 0), 2) # 在人脸上绘制方框矩形
其中,img是要绘制矩形的原图像,(x, y)对应矩形的左上角坐标,(x + w, y + h)指的是矩形的右下角坐标,(0, 255, 0)对应是用rgb值表示的矩形框画线的颜色,这里指绿色,2指的是矩形框的线宽。
8、Opencv库“imwrite()”函数保存图像
Opencv库的“imwrite()”函数可以用来将指定图像保存到指定路径下。
- lena = cv2.imread("lena.bmp")# 读取"lena.bmp"图像
- r = cv2.imwrite("result.bmp",lena)# 保存成"result.bmp"图像
其中,"lena.bmp"是当前目录下的图像,读取生成一个副本图像后,会将该图像以名称"result.bmp"存储到当前目录下。
9、PIL库Image模块图像处理
(1)“open()”函数打开图片
PIL库Image模块中的“open()”函数可以打开指定路径下的图片。
- image = Image.open(image_path)
其中,image_path指的是图片的路径。
(2)“convert()”函数转换图像的模式
PIL库Image模块中的“convert()”函数可以将图像的模式进行转换。
对于彩色图像,不管其图像格式是PNG,还是BMP,或者JPG,在PIL中,使用Image模块的open()函数打开后,返回的图像对象的模式都是“RGB”。而对于灰度图像,不管其图像格式是PNG,还是BMP,或者JPG,打开后,其模式为“L”。PIL图片有9种不同的模式,其中,“L”表示的是灰度图像,每个像素用8个比特表示,0表示黑,255表示白,其他公式表示不同的灰度。
- image = Image.open(image_path).convert('L')# 打开路径下的图像并将其转换为灰度图
其中,image_path指的是图片的路径。
动手实践
任务描述1:采集人脸图片
在这个任务中,我们将通过摄像头采集3个不同的人脸,每个人脸采集50张图片,并给各自作好标记,以便后续在进行识别时能够显示出对应的人脸标签。
1、硬件搭建
STEP1:通过USB连接线将行空板连接到计算机
STEP2:将USB摄像头连接在行空板上
2、程序编写
STEP1:创建与保存项目文件
启动Mind+,另存项目并命名为“013、智能门禁系统”。
STEP2:创建与保存Python文件
创建一个Python程序文件“main1.py”,双击打开。
Step3:程序编写
(1) 导入所需功能库
在这个任务中,我们需要使用opencv库来调用摄像头显示视频流,使用os库创建用于保存图片的文件夹,因此,我们需要先导入它们。
- import cv2 # 导入opencv库
- import os # 导入os库
(2) 定义图片保存的路径和文件夹
在这个任务中,我们需要采集人脸图片并将它保存下来,因此在这里,我们提前定义好图片保存的路径,并创建一个空的文件夹以便后续存入图片。
- img_src='/root/image/project14' # 定义图片路径(Mind+中运行时需要指定到固定位置)
- os.system('mkdir -p '+img_src+'/new/') # 在该路径下创建一个名称为"new"的文件夹(需要先创建文件夹才能存图片)
(3) 设置摄像头
为了能将摄像头拍摄到的画面实时显示在行空板的屏幕上,这里,我们需要进行四步设置。首先是打开摄像头;接着给视频流设置1帧的缓冲,避免卡顿或延迟太高;之后构建一个窗口并在最后设置窗口全屏化以便在窗口上显示完整的视频流画面
- cap = cv2.VideoCapture(0) # 打开0号摄像头并初始化
- cap.set(cv2.CAP_PROP_BUFFERSIZE, 1) # 设置1帧的缓冲,减少延迟
- cv2.namedWindow('frame',cv2.WND_PROP_FULLSCREEN) # 构建一个窗口,名称为winname,默认属性为可以全屏
- cv2.setWindowProperty('frame', cv2.WND_PROP_FULLSCREEN, cv2.WINDOW_FULLSCREEN) # 设置winname窗口全屏
(4) 设置字体类型
为了后续在采集人脸时能在画面上显示一些提示文字,这里,我们需要先定义好字体的类型。
- font = cv2.FONT_HERSHEY_SIMPLEX # 设置字体类型(正常大小的sans-serif字体)
(5) 加载人脸检测分类器
在检测人脸采集图片时,需要使用相应的分类器工具,这里,我们提前加载好。
- detector=cv2.CascadeClassifier(cv2.data.haarcascades+ 'haarcascade_frontalface_default.xml') # 加载人脸检测分类器
(6) 定义初始图片样本数量
为了记录后续采集的图片数量,这里,我们先定义好初始时的图片样本数量为0。
- sampleNum = 0 # 定义初始图片样本数量为0
(7) 标记采集的人脸图片
在采集人脸时,为了能对应不同的人脸,我们需要在采集前先定义好它的ID编号,这里,我们通过在终端输入数值的方式实现。
- ID = input('enter your id: ') # 输入人脸图像数据类别编号
(8) 采集人脸
接下来,我们需要借助摄像头采集人脸,这里,我们分四步进行。首先,将摄像头检测到的画面同比例实时显示在行空板屏幕上;之后,检测、获取人脸数据;接下来,设置检测人脸的数量,当满了50张时,在画面上显示完成,否则提示正在采集并将图片存入之前定义的文件夹中;最后,我们设置好按下b键退出程序。
- while True:
- ret, img = cap.read() # 按帧读取图像
- if ret: # 如果读取到图像
- h, w, c = img.shape # 记录图像的形状尺寸,分别为高、宽、通道
- w1 = h*240//320
- x1 = (w-w1)//2
- img = img[:, x1:x1+w1] # 裁剪图像
- img = cv2.resize(img, (240, 320)) # 调整图像尺寸与行空板相同
- gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 将图像img转变为灰度图
- faces = detector.detectMultiScale(gray, 1.3, 5) # 检测,获取人脸识别数据
- for (x, y, w, h) in faces: # 检测出人脸
- cv2.rectangle(img, (x, y), (x + w, y + h), (0, 255, 0), 2) # 在人脸上绘制方框矩形
- sampleNum = sampleNum + 1 # 图片数量记录+1
- if sampleNum <= 50: # 如果数量不多于50张
- cv2.putText(img, 'shooting', (10, 50), font, 0.6, (0, 255, 0), 2) # 在图像画面上显示文字shooting表示正在采集人脸
- # 保存人脸部分图像并命名,命名规则为sampleNum.UserID.jpg
- cv2.imwrite(img_src +'/new/'+ str(sampleNum) + '.' + str(ID) + ".jpg",gray[y:y + h, x:x + w])
- else: # 如果图片数量>50
- cv2.putText(img, 'Done,Please quit', (10, 50), font, 0.6, (0, 255, 0), 2) # 显示文字,提醒已完成
- cv2.imshow('frame', img) # 在frame窗口上显示图像img
-
- key = cv2.waitKey(1) # 每帧数据延时1ms,延时不能为 0,否则读取的结果会是静态帧
- if key & 0xFF == ord('b'): # 按b键退出
- break
(9) 关闭摄像头和窗口
在按下b键退出后,我们释放掉摄像头,并关闭所有图像窗口。
- cap.release() # 释放摄像头
- cv2.destroyAllWindows() # 关闭所有窗口
Tips:完整示例程序如下:
- '''
- 运行程序,在终端输入id 后回车,屏幕显示摄像头的图像,调整位置,出现绿框即开始拍照,显示done则完成。
- 拍摄的图片保存在/root/image/project14/new文件夹内,此代码拍摄50张图,可修改代码参数拍摄更多图片。
- '''
-
-
- import cv2 # 导入opencv库
- import os # 导入os库
-
- img_src='/root/image/project14' # 定义图片路径(Mind+中运行时需要指定到固定位置)
- os.system('mkdir -p '+img_src+'/new/') # 在该路径下创建一个名称为"new"的文件夹(需要先创建文件夹才能存图片)
- # img_src=os.getcwd() # 直接运行可指定为当前工作目录
-
-
- cap = cv2.VideoCapture(0) # 打开0号摄像头并初始化
- cap.set(cv2.CAP_PROP_BUFFERSIZE, 1) # 设置1帧的缓冲,减少延迟
- cv2.namedWindow('frame',cv2.WND_PROP_FULLSCREEN) # 构建一个窗口,名称为winname,默认属性为可以全屏
- cv2.setWindowProperty('frame', cv2.WND_PROP_FULLSCREEN, cv2.WINDOW_FULLSCREEN) # 设置winname窗口全屏
-
- font = cv2.FONT_HERSHEY_SIMPLEX # 设置字体类型(正常大小的sans-serif字体)
- detector=cv2.CascadeClassifier(cv2.data.haarcascades+ 'haarcascade_frontalface_default.xml') # 加载人脸检测分类器
- sampleNum = 0 # 定义初始图片样本数量为0
- ID = input('enter your id: ') # 输入人脸图像数据类别编号
-
-
- while True:
- ret, img = cap.read() # 按帧读取图像
- #img = cv2.flip(img, 1) # 镜像(将img图像水平翻转)
- if ret: # 如果读取到图像
- h, w, c = img.shape # 记录图像的形状尺寸,分别为高、宽、通道
- w1 = h*240//320
- x1 = (w-w1)//2
- img = img[:, x1:x1+w1] # 裁剪图像
- img = cv2.resize(img, (240, 320)) # 调整图像尺寸与行空板相同
- gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 将图像img转变为灰度图
- faces = detector.detectMultiScale(gray, 1.3, 5) # 检测,获取人脸识别数据
- for (x, y, w, h) in faces: # 检测出人脸
- cv2.rectangle(img, (x, y), (x + w, y + h), (0, 255, 0), 2) # 在人脸上绘制方框矩形
- sampleNum = sampleNum + 1 # 图片数量记录+1
- if sampleNum <= 50: # 如果数量不多于50张
- cv2.putText(img, 'shooting', (10, 50), font, 0.6, (0, 255, 0), 2) # 在图像画面上显示文字shooting表示正在采集人脸
- # 保存人脸部分图像并命名,命名规则为sampleNum.UserID.jpg
- cv2.imwrite(img_src +'/new/'+ str(sampleNum) + '.' + str(ID) + ".jpg",gray[y:y + h, x:x + w])
- else: # 如果图片数量>50
- cv2.putText(img, 'Done,Please quit', (10, 50), font, 0.6, (0, 255, 0), 2) # 显示文字,提醒已完成
- cv2.imshow('frame', img) # 在frame窗口上显示图像img
-
- key = cv2.waitKey(1) # 每帧数据延时1ms,延时不能为 0,否则读取的结果会是静态帧
- if key & 0xFF == ord('b'): # 按b键退出
- break
-
-
- cap.release() # 释放摄像头
- cv2.destroyAllWindows() # 关闭所有窗口
3、程序运行
STEP1:远程连接行空板,运行程序并观察效果
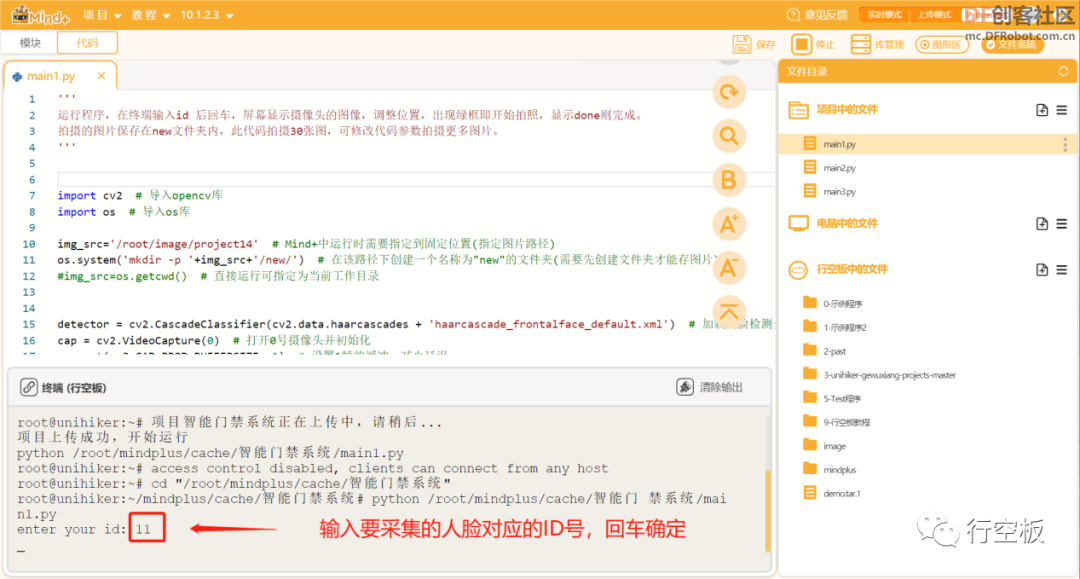
运行Mind+,可以看到在终端中提示我们输入要采集的人脸对应的ID号,这里我们输入“11”,并回车确定。Tips:这里ID号可调整。
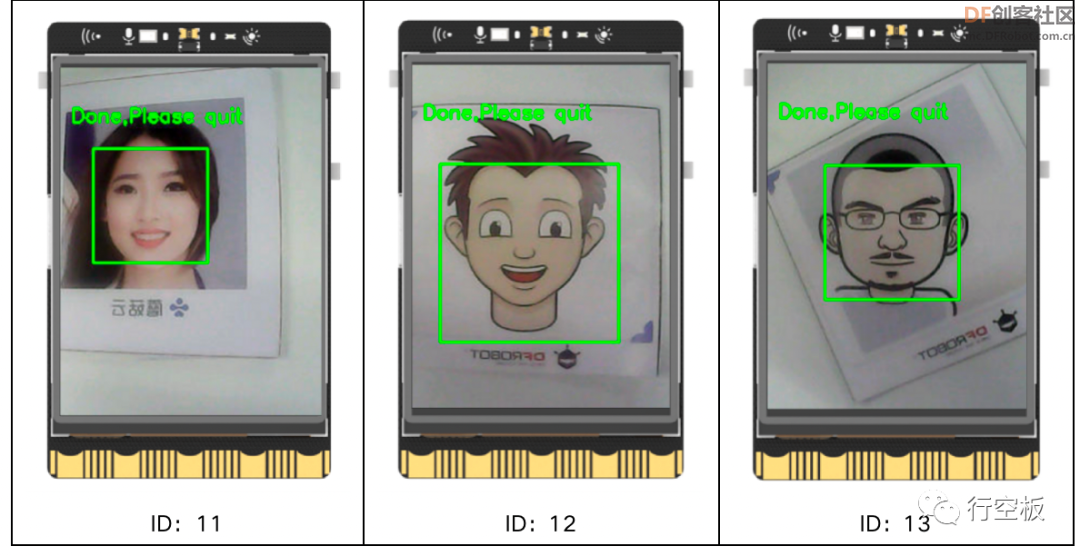
随后,摄像头自动开启,实时拍摄到的画面全屏显示在了板子上,接下来,将摄像头对准一张人脸,可以发现人脸被绿色线框圈出,并在上方显示“shooting”,这表明我们正在对该人脸进行采集拍摄,当50张图片采集完成,人脸上方则显示“Done,Please quit”,这时,我们可通过按下板载按键b退出程序。
STEP2:多次采集
根据上述方法,再运行两次程序,采集另外两张人脸并分别命名ID为“12”和“13”。
Tips:这里,我们采集的是卡片上的人脸图片,同样地,我们也可以将摄像头对准自己,采集真实的人脸。
任务描述2:训练人脸模型
在上个任务中,我们采集到了3个不同的人脸图片,接下来,我们要对这些图片进行处理,将其训练****脸模型。
1、程序编写
STEP1:创建与保存项目文件
新建一个Python程序文件“main2.py”,双击打开。
Step2:程序编写
(1)补充导入numpy库和PIL库Image模块
在这个任务中,我们将使用numpy库、PIL库Image模块、os库来对图像进行处理,还将使用opencv库中的人脸检测分类器和识别器创建模型文件,因此我们需要导入它们。
- import cv2 # 导入opencv库
- import os # 导入os库
- import numpy as np # 导入numpy库
- from PIL import Image # 导入PIL库Image模块
(2)定义模型文件保存的路径
在这个任务中,我们将把采集的人脸图片训练****脸模型,这里,我们提前定义好模型保存的位置。
- img_src='/root/image/project14' # 定义保存路径(Mind+中运行时需要指定到固定位置)
(3)加载人脸检测分类器和LBPH识别器
为了能检测出保存的人脸图片中的人脸,这里,我们仍需要使用分类器,而为了能将图片训练成模型,我们需要提前生成一个空的模型实例,因此,这里,我们提前加载好人脸检测的分类器和LBPH识别器。
- # 初始化人脸检测器和识别器
- detector=cv2.CascadeClassifier(cv2.data.haarcascades+ 'haarcascade_frontalface_default.xml') # 加载人脸检测分类器
- recognizer = cv2.face.LBPHFaceRecognizer_create() # 生成LBPH识别器实例模型(空)
(4)定义函数--获取人脸样本列表和ID列表
在将人脸图片训练成模型的时候,我们需要提供人脸的图片样本以及图片对应的ID编号给到空的模型文件。因此,我们需要对采集到的图片进行一定的处理,由于这里过程较为复杂,因此我们将其写在函数中。
整个过程我们可分四步进行。首先,将图片保存的路径和具体的名称拼接起来,使得每张人脸图片都以完成的带路径的名称来表示;其次,创建两个空的列表,分别存储人脸图片样本和ID样本;接着,遍历每张图片,将图片中的人脸部分圈出再存入人脸图片样本中,而图片名称中的ID号,取出后存入ID列表中;最后,我们将两个分别存有人脸部分和ID编号的列表返回即可。
- def get_images_and_labels(path):
- # 拼接图片路径,对应到具体的一张张图片名称,如/root/image/project14/new/50.1.jpg,存储到列表image_paths中
- image_paths = [os.path.join(path, f) for f in os.listdir(path)]
- # 创建人脸样本列表(空)
- face_samples = []
- # 创建id样本列表(空)
- ids = []
- for image_path in image_paths: # 遍历图片路径
- # 打印每张图片的名称(带路径的图片名)
- print(image_path)
- # 将彩色图片转化为灰度图
- image = Image.open(image_path).convert('L')
- # 再将灰度图的格式转换成了Numpy数组
- image_np = np.array(image, 'uint8')
- '''为了获取到id,我们将图片的路径分裂一下并获取相关信息'''
- # 按“.”分割,如果最后一组是“jpg”,则执行后面的步骤
- if os.path.split(image_path)[-1].split(".")[-1] != 'jpg':
- continue
- # 取出完整路径名称的图片中的ID号,这里的ID即为我们采集图片时设置的ID号
- image_id = int(os.path.split(image_path)[-1].split(".")[1])
- # 检测array数组格式的人脸图片并将结果存储到faces中
- faces = detector.detectMultiScale(image_np) # 检测人脸
- # 将array数组格式的人脸图片裁剪出人脸部分后都存储到人脸样本列表中,再将图片的ID号都存储到id样本列表中
- for (x, y, w, h) in faces:
- face_samples.append(image_np[y:y + h, x:x + w])
- ids.append(image_id)
- return face_samples, ids # 返回人脸样本列表和id样本列表
(5)获取人脸样本列表和ID列表
这里,我们调用上述定义的函数,传入图片路径和名称,获取人脸样本列表和ID列表。
- faces, Ids = get_images_and_labels(img_src+'/new/') # 传入路径和图片文件夹名称,获取人脸样本列表和id样本列表
(6)训练模型
在获取人脸样本和ID样本列表后,我们对它进行训练。
- recognizer.train(faces, np.array(Ids)) # 将人脸样本列表和id样本列表传入空的LBPH识别器模型中,得到完整的人脸模型
(7)保存模型
最后,在训练好所采集图片的人脸模型后,我们将其保存好。
- recognizer.save(img_src+'/model.yml') # 保存生成的模型
- print("generate model done") # 打印“模型已生成”
Tips:完整示例程序如下:
- # 运行本程序,对拍摄的人脸图片进行训练,得到model.yml模型(与new文件夹同级)
- import cv2 # 导入opencv库
- import os # 导入os库
- import numpy as np # 导入numpy库
- from PIL import Image # 导入PIL库Image模块
-
-
- img_src='/root/image/project14' # 定义保存路径(Mind+中运行时需要指定到固定位置)
-
-
- # 初始化人脸检测器和识别器
- detector=cv2.CascadeClassifier(cv2.data.haarcascades+ 'haarcascade_frontalface_default.xml') # 加载人脸检测分类器
- recognizer = cv2.face.LBPHFaceRecognizer_create() # 生成LBPH识别器实例模型(空)
-
-
- '''
- 遍历图片路径,导入图片和id,添加到list
- '''
- def get_images_and_labels(path):
- # 拼接图片路径,对应到具体的一张张图片名称,如/root/image/project14/new/50.1.jpg,存储到列表image_paths中
- image_paths = [os.path.join(path, f) for f in os.listdir(path)]
- # 创建人脸样本列表(空)
- face_samples = []
- # 创建id样本列表(空)
- ids = []
- for image_path in image_paths: # 遍历图片路径
- # 打印每张图片的名称(带路径的图片名)
- print(image_path)
- # 将彩色图片转化为灰度图
- image = Image.open(image_path).convert('L')
- # 再将灰度图的格式转换成了Numpy数组
- image_np = np.array(image, 'uint8')
- '''为了获取到id,我们将图片的路径分裂一下并获取相关信息'''
- # 按“.”分割,如果最后一组是“jpg”,则执行后面的步骤
- if os.path.split(image_path)[-1].split(".")[-1] != 'jpg':
- continue
- # 取出完整路径名称的图片中的ID号,这里的ID即为我们采集图片时设置的ID号
- image_id = int(os.path.split(image_path)[-1].split(".")[1])
- # 检测array数组格式的人脸图片并将结果存储到faces中
- faces = detector.detectMultiScale(image_np) # 检测人脸
- # 将array数组格式的人脸图片裁剪出人脸部分后都存储到人脸样本列表中,再将图片的ID号都存储到id样本列表中
- for (x, y, w, h) in faces:
- face_samples.append(image_np[y:y + h, x:x + w])
- ids.append(image_id)
- return face_samples, ids # 返回人脸样本列表和id样本列表
-
-
- # 通过LBPH识别器模型训练并输出相应的人脸模型(.yml格式文件)
- faces, Ids = get_images_and_labels(img_src+'/new/') # 传入路径和图片文件夹名称,获取人脸样本列表和id样本列表
- recognizer.train(faces, np.array(Ids)) # 将人脸样本列表和id样本列表传入空的LBPH识别器模型中,得到完整的人脸模型
- recognizer.save(img_src+'/model.yml') # 保存生成的模型
- print("generate model done") # 打印“模型已生成”
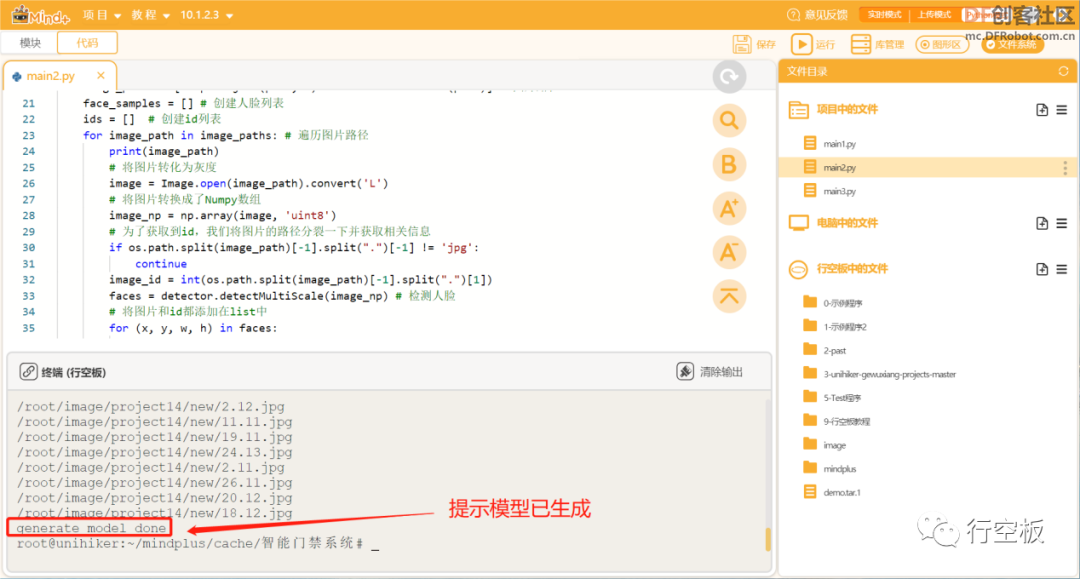
2、程序运行
STEP1:运行程序并观察效果
运行Mind+,可以看到在终端中显示一系列图片文件名后,在最后打印了“generate model done”,这告诉我们针对上述三幅人脸图像的模型文件已经生成。
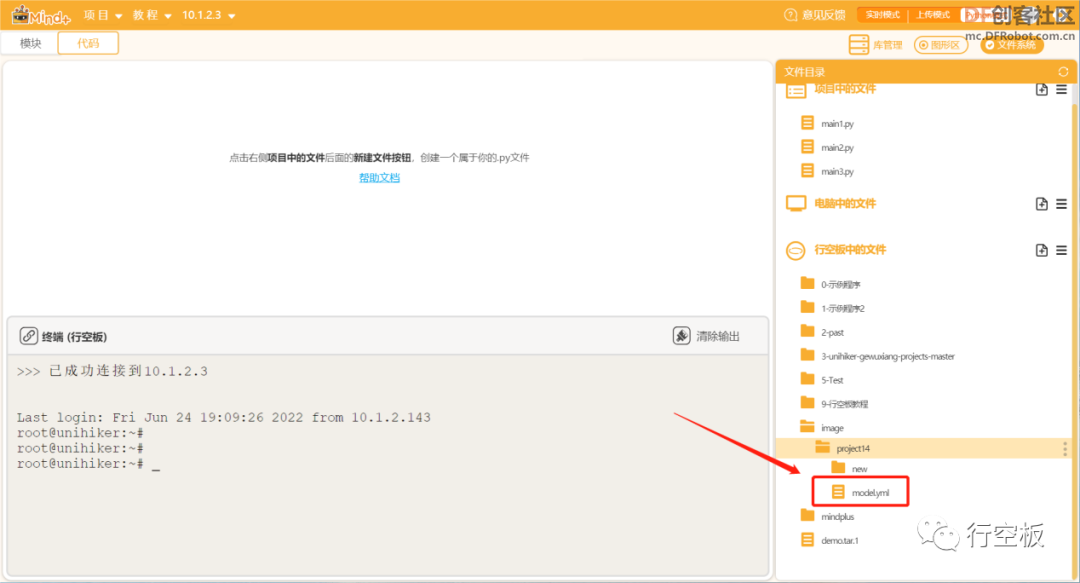
同时,我们也可以在重新连接行空板后,在Image文件夹下看到该模型文件。
Tips:如果在运行时提示缺少“cv2.face.LBPHFaceRecognizer_create”库文件,可依据附录2离线安装缺少的库。
任务描述3:实时识别人脸
在上个任务中,我们将采集到的人脸照片训练成了一个模型,接下来,我们将利用这个模型,对人脸进行实时的检测识别,当识别结果为采集过的人脸,控制舵机转动至170°位置开门,5秒后自动返回10°位置关门。
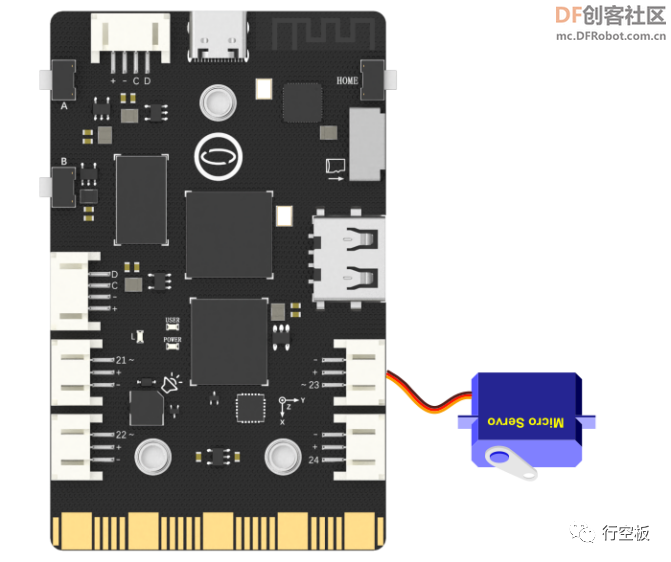
1、硬件搭建
STEP1:将舵机连接在P23引脚上
STEP2:将USB摄像头连接在行空板上
2、程序编写
STEP1:创建与保存项目文件
新建一个Python程序文件“main3.py”,双击打开。
Step2:程序编写
(1)导入所需功能库
在这个任务中,我们我们需要使用opencv库来调用摄像头显示视频流,pinpong库来控制舵机转动,time库设定延时,因此,我们需要先导入它们。
- import cv2 # 导入opencv库
- from pinpong.board import Board,Pin,Servo # 导入Pinpong库
- import time # 导入time库
(2)初始化行空板,并控制舵机转至10°初始位置
- Board("UNIHIKER").begin() # 初始化,选择板型,不输入板型则进行自动识别
-
- s1 = Servo(Pin(Pin.P23)) # 将Pin传入Servo中初始化舵机引脚
- s1.angle(10) # 控制舵机转到10度初始位置(关门)
- time.sleep(1)
(3)定义图片路径
- img_src='/root/image/project14' # 定义保存路径(Mind+中运行时需要指定到固定位置)
(4)设置摄像头和字体类型
- cap = cv2.VideoCapture(0) # 打开0号摄像头并初始化
- cap.set(cv2.CAP_PROP_BUFFERSIZE, 1) # 设置1帧的缓冲,减少延迟
- cv2.namedWindow('frame',cv2.WND_PROP_FULLSCREEN) # 构建一个窗口,名称为winname,默认属性为可以全屏
- cv2.setWindowProperty('frame', cv2.WND_PROP_FULLSCREEN, cv2.WINDOW_FULLSCREEN) # 设置winname窗口全屏
- font = cv2.FONT_HERSHEY_SIMPLEX # 设置字体类型(正常大小的sans-serif字体)
(5)加载人脸检测分类器和LBPH识别器
- detector=cv2.CascadeClassifier(cv2.data.haarcascades+ 'haarcascade_frontalface_default.xml') # 加载人脸检测分类器
- recognizer = cv2.face.LBPHFaceRecognizer_create() # 生成LBPH识别器实例模型
(6)读取人脸模型文件
在这个任务中,我们将借助上述训练好的人脸模型,对人脸进行实时检测识别,因此,我们需要先读取该模型。
- recognizer.read(img_src+'/model.yml') # 读取该路径下训练好的人脸模型
(7)实时识别
在对人脸进行检测识别时,我们同样需要调整摄像头的画面,使之能正常显示在行空板的屏幕上。之后,我们添加功能,当识别到采集过的人脸时,在画面上圈出人脸部分,显示文字“Welcome Home”以及该人脸的ID编号,并控制舵机先转至170度,模拟开门,5秒后回到10°初始位置,而当检测到未学习过的人脸时,则显示“unknown”,舵机保持在10°位置,模拟关门的效果。
Tips:由于行空板的CPU处理屏幕显示绿框、显示文字这些动作需要一定的时间,慢于摄像头读取每帧图像的速率,因此从效果上看,并非每一次检测到人脸后的图像都能看到绿框和文字ID,所以在这里,我们通过定义一个count变量来记录摄像头的每帧图像,并且设定只在检测到人脸的第三帧图像上显示绿框等。
- count = 0 # 定义一个计数标记count
-
- while True:
- ret, img = cap.read() # 按帧读取图像
- # img = cv2.flip(img, 1) # 镜像(将img图像水平翻转)
- if ret: # 如果读取到图像
- h, w, c = img.shape # 记录图像的形状尺寸,分别为高、宽、通道
- w1 = h*240//320
- x1 = (w-w1)//2
- img = img[:, x1:x1+w1] # 裁剪图像
- img = cv2.resize(img, (240, 320)) # 调整图像尺寸与行空板相同
- gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 将图像img转变为灰度图
- faces = detector.detectMultiScale(gray, 1.2, 5) # 检测,获取人脸识别数据
- for (x, y, w, h) in faces:
- cv2.rectangle(img, (x - 50, y - 50), (x + w + 50, y + h + 50), (0, 255, 0), 2) # 在人脸上绘制方框矩形
- img_id, confidence = recognizer.predict(gray[y:y + h, x:x + w]) # 先在灰度图像上指定一个方形区域(该区域用于呈现人脸),再只对该区域进行预测
- if confidence < 80: # 如果置信度<80,表示检测识别到学习过的人脸
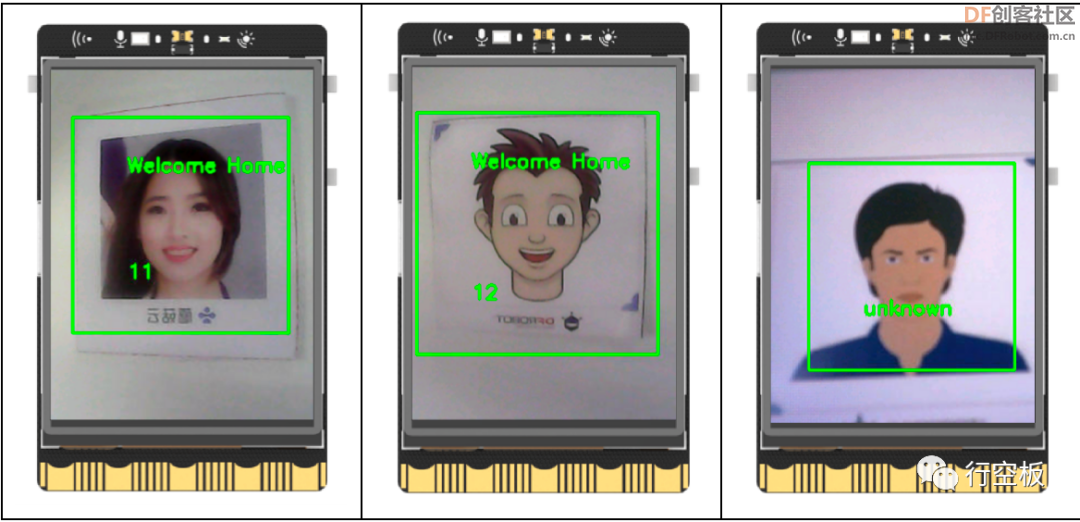
- cv2.putText(img, "Welcome Home", (x, y), font, 0.6, (0, 255, 0), 2) # 在图像上指定位置添加文字“Welcome Home”
- cv2.putText(img, str(img_id), (x, y + h), font, 0.6, (0, 255, 0), 2) # 在图像上指定位置添加文字,显示对应的人脸ID标签号
- if count == 2: # 第三帧
- s1.angle(170) # 控制舵机转到170度位置(开门)
- print("门已开")
- time.sleep(5) # 等待五秒
- s1.angle(10) # 控制舵机转到170度位置(开门)
- print("门已关")
- count = 0 # 计次归零
- else:
- s1.angle(10)
- count = count + 1 # 帧数+1
- else: # 检测到未知人脸
- img_id = "unknown"
- cv2.putText(img, str(img_id), (x, y + h), font, 0.6, (0, 255, 0), 2) # 在图像上指定位置添加文字,表示陌生人
- cv2.imshow('frame', img) # 显示图像
- key = cv2.waitKey(1) # 每帧数据延时1ms,延时不能为0,否则读取的结果会是静态帧
- if key & 0xFF == ord('b'): # 按键b退出
- break
(8)关闭摄像头和窗口
- cap.release() # 释放摄像头
- cv2.destroyAllWindows() # 关闭所有窗口
Tips:完整示例程序如下:
- '''运行本程序,借助训练好的人脸模型再对人脸进行预测,当检测到训练过的人脸时,显示id号,舵机转至170°开门,当检测到未学过的人脸时,显示“unknown”,采集的图片越多,识别准确率越高'''
- import cv2 # 导入opencv库
- from pinpong.board import Board,Pin,Servo # 导入Pinpong库
- import time # 导入time库
-
- Board("UNIHIKER").begin() # 初始化,选择板型,不输入板型则进行自动识别
-
- s1 = Servo(Pin(Pin.P23)) # 将Pin传入Servo中初始化舵机引脚
- s1.angle(10) # 控制舵机转到10度初始位置(关门)
- time.sleep(1)
-
-
- img_src='/root/image/project14' # 定义保存路径(Mind+中运行时需要指定到固定位置)
-
-
- cap = cv2.VideoCapture(0) # 打开0号摄像头并初始化
- cap.set(cv2.CAP_PROP_BUFFERSIZE, 1) # 设置1帧的缓冲,减少延迟
- cv2.namedWindow('frame',cv2.WND_PROP_FULLSCREEN) # 构建一个窗口,名称为winname,默认属性为可以全屏
- cv2.setWindowProperty('frame', cv2.WND_PROP_FULLSCREEN, cv2.WINDOW_FULLSCREEN) # 设置winname窗口全屏
- font = cv2.FONT_HERSHEY_SIMPLEX # 设置字体类型(正常大小的sans-serif字体)
-
-
- '''初始化人脸检测器和识别器,引用之前训练的.yml文件来识别人脸'''
- detector=cv2.CascadeClassifier(cv2.data.haarcascades+ 'haarcascade_frontalface_default.xml') # 加载人脸检测分类器
- recognizer = cv2.face.LBPHFaceRecognizer_create() # 生成LBPH识别器实例模型
- recognizer.read(img_src+'/model.yml') # 读取该路径下训练好的人脸模型
-
-
- count = 0 # 定义一个计数标记count
-
- while True:
- ret, img = cap.read() # 按帧读取图像
- # img = cv2.flip(img, 1) # 镜像(将img图像水平翻转)
- if ret: # 如果读取到图像
- h, w, c = img.shape # 记录图像的形状尺寸,分别为高、宽、通道
- w1 = h*240//320
- x1 = (w-w1)//2
- img = img[:, x1:x1+w1] # 裁剪图像
- img = cv2.resize(img, (240, 320)) # 调整图像尺寸与行空板相同
- gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 将图像img转变为灰度图
- faces = detector.detectMultiScale(gray, 1.2, 5) # 检测,获取人脸识别数据
- for (x, y, w, h) in faces:
- cv2.rectangle(img, (x - 50, y - 50), (x + w + 50, y + h + 50), (0, 255, 0), 2) # 在人脸上绘制方框矩形
- img_id, confidence = recognizer.predict(gray[y:y + h, x:x + w]) # 先在灰度图像上指定一个方形区域(该区域用于呈现人脸),再只对该区域进行预测
- if confidence < 80: # 如果置信度<80,表示检测识别到学习过的人脸
- cv2.putText(img, "Welcome Home", (x, y), font, 0.6, (0, 255, 0), 2) # 在图像上指定位置添加文字“Welcome Home”
- cv2.putText(img, str(img_id), (x, y + h), font, 0.6, (0, 255, 0), 2) # 在图像上指定位置添加文字,显示对应的人脸ID标签号
- if count == 2: # 第三帧
- s1.angle(170) # 控制舵机转到170度位置(开门)
- print("门已开")
- time.sleep(5) # 等待五秒
- s1.angle(10) # 控制舵机转到170度位置(开门)
- print("门已关")
- count = 0 # 计次归零
- else:
- s1.angle(10)
- count = count + 1 # 帧数+1
- else: # 检测到未知人脸
- img_id = "unknown"
- cv2.putText(img, str(img_id), (x, y + h), font, 0.6, (0, 255, 0), 2) # 在图像上指定位置添加文字,表示陌生人
- cv2.imshow('frame', img) # 显示图像
- key = cv2.waitKey(1) # 每帧数据延时1ms,延时不能为0,否则读取的结果会是静态帧
- if key & 0xFF == ord('b'): # 按键b退出
- break
-
-
- cap.release() # 释放摄像头
- cv2.destroyAllWindows() # 关闭所有窗口
3、程序运行
STEP1:运行程序并观察效果
观察行空板,待摄像头画面显示后,我们将它对准采集过的3张卡片上的人脸,可以发现每张图片上的人脸被圈出,并且显示相应的ID号以及“Welcome Home”的字样。此时,画面静止,舵机由原先的10°转至170°,5秒后回至10°。之后我们再将它对准未采集过的人脸,人脸上则显示“unknown”字样,同时舵机保持在10°初始位置。
Tip1:采集的图片越多,识别时准确率越高。可通过改变程序中的阈值“80”来调整识别率。
Tip2:在检测认识的人脸时,尽可能保持和采集图像时的环境一致,这样可以提升识别率。
挑战自我
想一想,对于目前的这个门禁系统,你觉得还有哪些值得进一步完善的地方呢?
附录
附录1:链接
链接:https://pan.baidu.com/s/1F9HUVMOfYUL2Fg7Pak0z8w?pwd=dq47
提取码:dq47
附录2:操作方法:
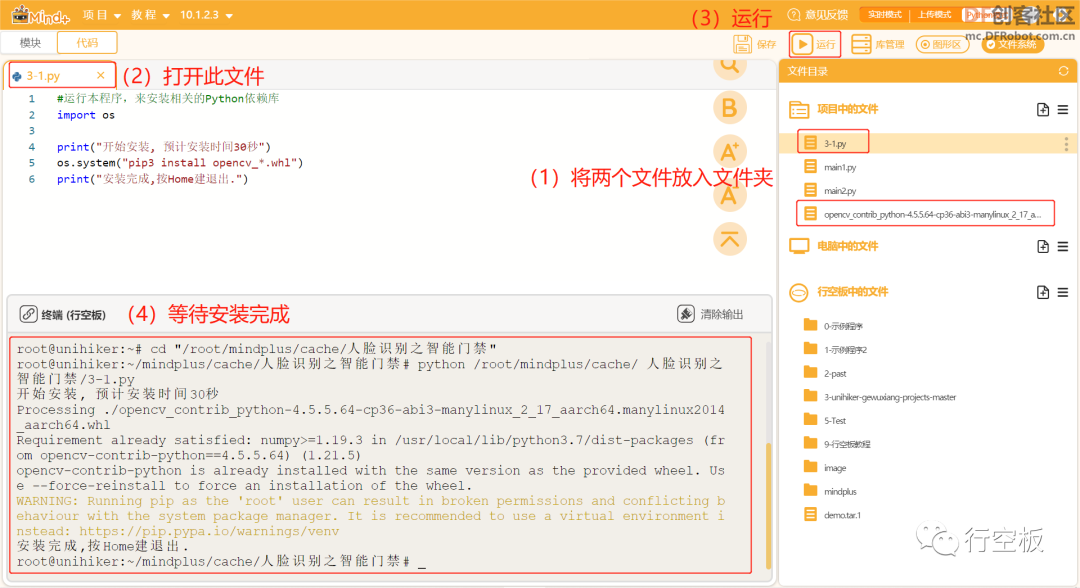
STEP0、将Mind+版本升级至最新(V1.7.2 RC3.0 及以上)
STEP1、依据附录1的链接下载“3-1.py”文件和
“opencv_contrib_python-4.5.5.64-cp36-abi3-
manylinux_2_17_aarch64.manylinux2014_aarch64.whl”文件
STEP2、安装库文件
|








 沪公网安备31011502402448
沪公网安备31011502402448

 置顶卡
置顶卡 变色卡
变色卡 千斤顶
千斤顶
 悔悟卡
悔悟卡 匿名卡
匿名卡


 萌萌哒新人
萌萌哒新人
 活跃会员
活跃会员
 宣传大使
宣传大使
 志“童”道合
志“童”道合
 编辑选择奖
编辑选择奖






