|
39036| 1
|
[入门] Jetson Copilot测评:基于Jetson Orin 64GB探索Llama3及RAG应用 |

|
本帖最后由 RRoy 于 2024-7-4 15:38 编辑 前言 最新发布的Jetson Copilot已经引起了广泛关注,通过本文基于Jetson Orin 64GB平台的测评,我们将全面了解Jetson Copilot的功能和性能,以及其在实际应用中的潜力。我们将指导您完成从安装到启动的每一步,并体验其与llama3 8b模型的互动,以及如何利用预先构建的索引进行高效提问。 安装与启动 为了开始使用Jetson Copilot,首先需要从GitHub克隆其代码仓库: 执行上述命令后,Jetson Copilot将在Docker容器内启动Ollama服务器和Streamlit应用程序。通过控制台输出的URL,您可以访问Jetson上托管的Web应用程序。 在Jetson上,您可以使用Web浏览器打开本地URL(http://localhost:8501)来访问应用程序。如果您在与Jetson连接的同一网络上使用PC,也可以通过网络URL访问。 和llama3 8b互动(Jetson Orin 启用50W功耗模式) Jetson Copilot暂时只支持llama3 8b模型,由于加载模型,第一次对话速度较慢,之后的对话速度大约在13 tokens/s。 演示视频: RAG 使用预先构建的索引向 Copilot 提问相关问题 Copilot的示例为一个Jetson Orin的操作文档,通过演示视频可见,Copilot从索引文档中搜索和生成内容的时间大约为26秒。 演示视频: 根据您的文档建立自己的索引并提问 将DFRobot商城的LattePanda Mu产品网页内容作为索引文档使用: 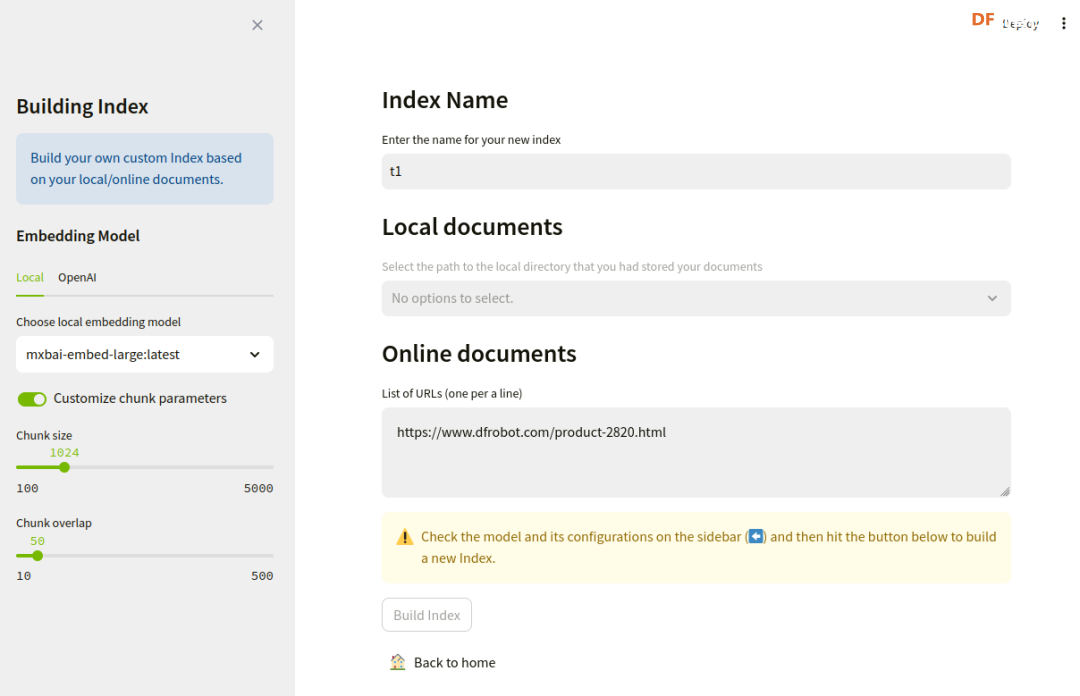 此外,Jetson Copilot暂时只支持mxbai-embed-large嵌入模型。mxbai-embed-large是一个先进的嵌入模型,截至2024年3月,它在MTEB(大规模文本嵌入基准测试)上取得了最佳性能,超过了Bert-large大小的模型。它使用了对比训练和AnglE损失函数进行微调,使其能够适应广泛的题材和领域,适合于各种实际应用和检索增强生成(RAG)用例。 在处理数据时,Jetson Copilot使用Chunk size将数据集分割成小块,并使用Chunk overlap来确保分割的数据块之间保持一定的重叠,以减少边缘效应。 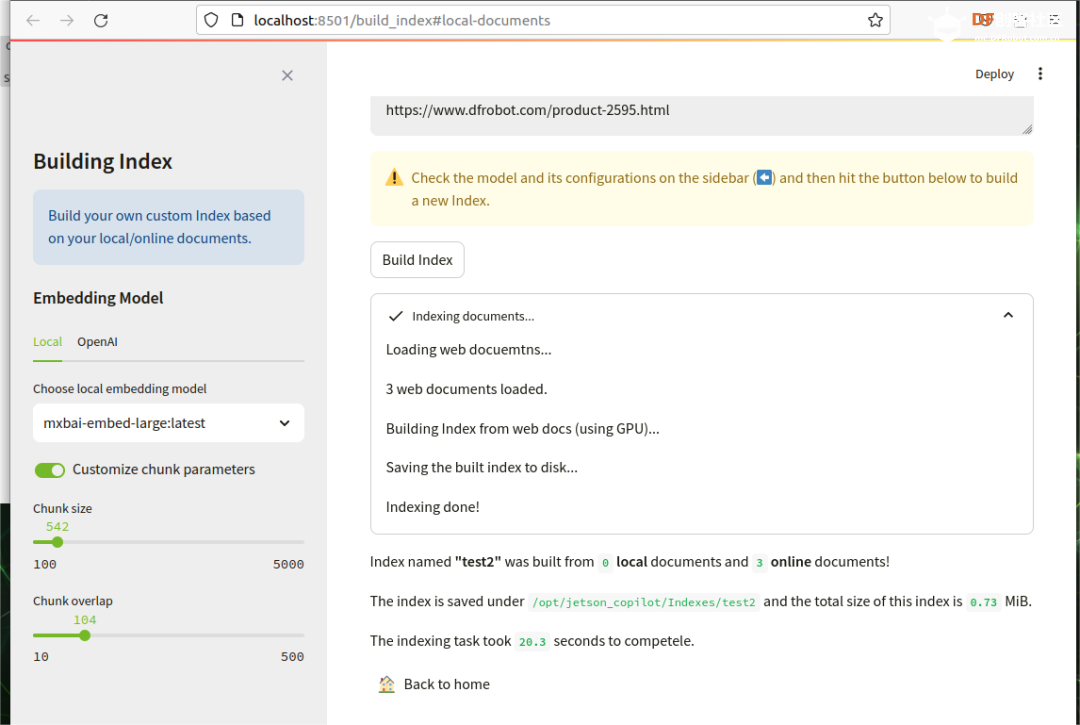 生成的文件夹会在jetson-copilot/index文件夹下: 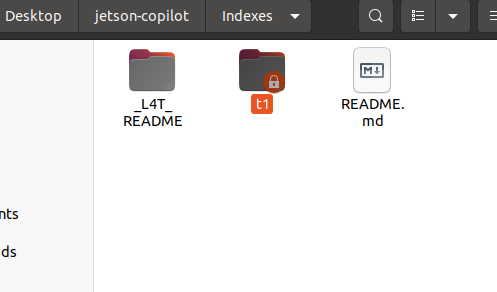 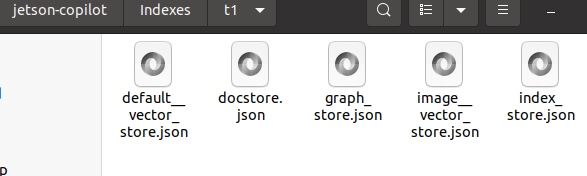 测试用多条网址仍然可以生成索引文档: 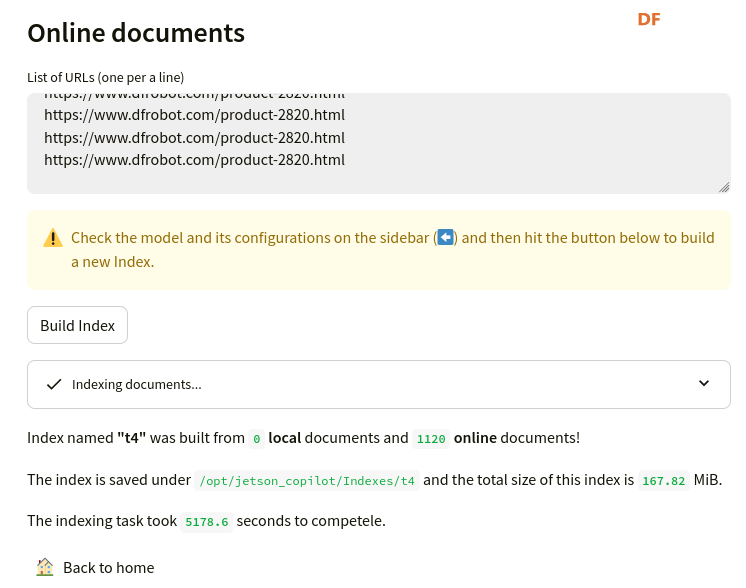 演示视频: 您还可以选择使用OpenAI的嵌入模型来生成索引文件: 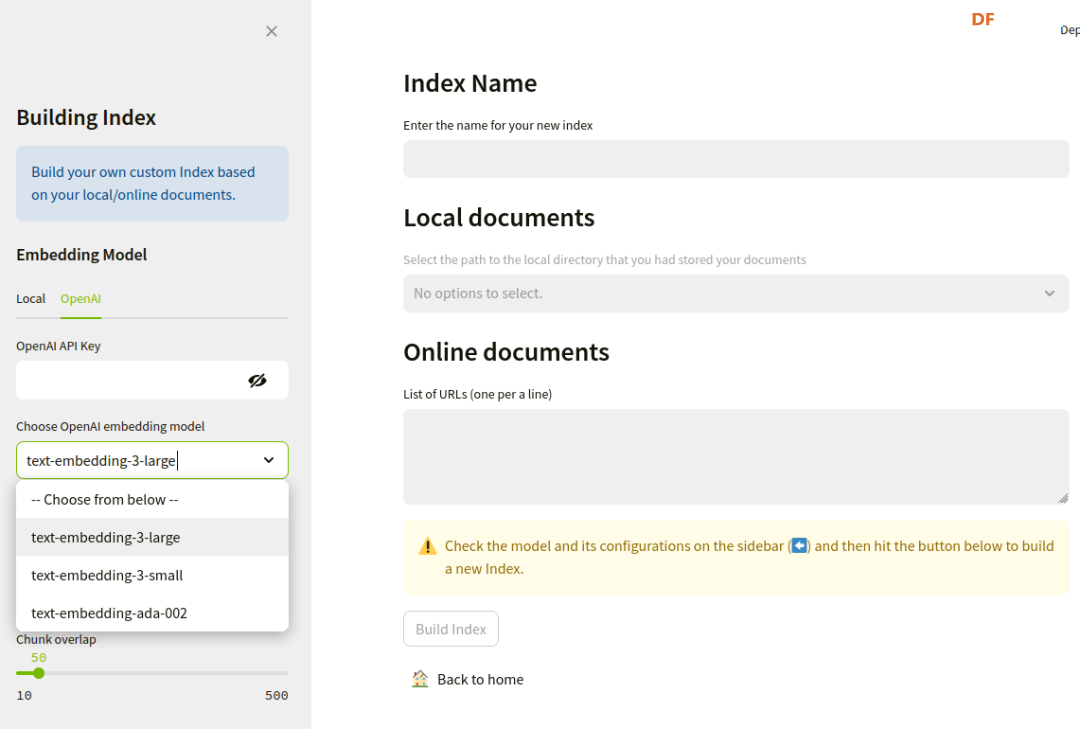 结论 Jetson Copilot,基于NVIDIA Jetson Orin的先进工具,提供了一种简便的命令行启动方式。 Llama3探索场景: 目前,它专为llama3 8b模型优化,确保了流畅的对话体验,每秒可处理大约13个token。 使用llama3构建的RAG应用: 此外,它还支持采用mxbai-embed-large模型进行高效的索引创建。在数据处理方面,用户可以灵活调整数据块的Chunk size和Chunk overlap,以优化数据分割并减少信息丢失。Jetson Copilot还允许用户利用OpenAI的嵌入模型来构建索引文件,从而进一步丰富其功能。从索引文档中检索和生成内容的过程大约需时26秒,实际输出的token速度也为13 tokens/s。Jetson Copilot是一款功能全面、操作简便的工具,非常适合于多样化的实际应用场景以及检索增强生成(RAG)任务。 不同框架表现比较 在使用MLC/TVM框架的情况下,不同大型语言模型在Jetson Orin上的表现也有所不同,可以看出MLC/TVM框架下使用Llama3-8B模型在Jetson AGX Orin上文本生成率达到40 tokens/s。 SLM text generation rate 常见问题解决 1、无法打开localhost,解决方法:给docker权限 2、网络报错,解决方法:重新联网并启动 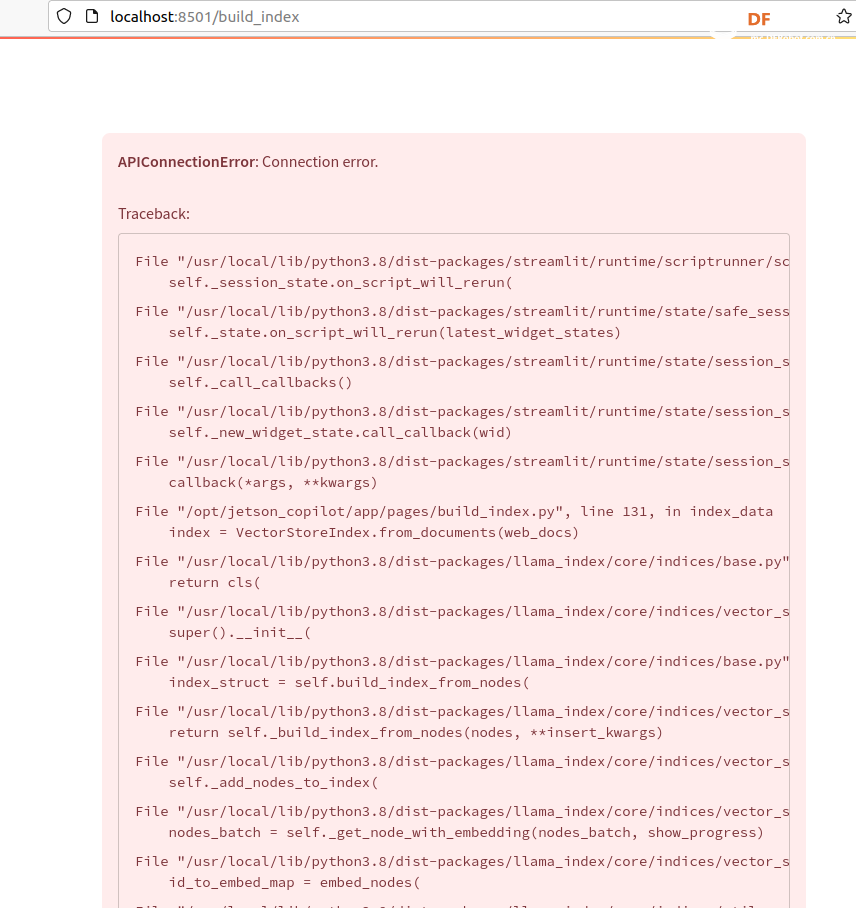 参考 1、代码仓库:https://github.com/NVIDIA-AI-IOT/jetson-copilot/ |



 沪公网安备31011502402448
沪公网安备31011502402448© 2013-2026 Comsenz Inc. Powered by Discuz! X3.4 Licensed

 置顶卡
置顶卡 变色卡
变色卡 千斤顶
千斤顶
 萌萌哒新人
萌萌哒新人
 宣传大使
宣传大使
 小蘑菇
小蘑菇
 ARD DAY
ARD DAY
 编辑选择奖
编辑选择奖
 摸鱼团员
摸鱼团员
 编辑选择奖
编辑选择奖
 编辑选择奖
编辑选择奖
 编辑选择奖
编辑选择奖






