本帖最后由 Anders项勇 于 2026-6-19 23:40 编辑
这个项目我们通过一个开源项目和一个实体机器人学习强化学习
回顾RL强化学习
一、核心定义
强化学习是智能体(Agent)在环境(Environment)中通过不断试错交互,最大化长期累积奖励的机器学习范式。是机器通过与环境交互来实现目标的一种计算方法。机器和环境的一轮交互是指,机器在环境的一个状态下做一个动作决策,把这个动作作用到环境当中,这个环境发生相应的改变并且将相应的奖励反馈和下一轮状态传回机器。这种交互是迭代进行的,机器的目标是最大化在多轮交互过程中获得的累积奖励的期望。
和监督学习(BC 模仿学习)、无监督学习有本质区别:
监督学习:有标准答案(人类示教动作,比如现在流行的VLA、开源lerobot),一步到位拟合标签;
无监督学习:只有数据,没有标签、没有奖励;
强化学习:没有标准答案,只有奖励信号,靠自己试错学会最优行为。
基础四元组(RL 标准数学框架)
(S,A,R,P)
S:状态空间,智能体观测到的环境信息(后面我们用到的树莓派机器人:摄像头图像、IMU 倾角、舵机角度)
A:动作空间,智能体可以执行的行为(各舵机目标角度、行走步幅)
R:奖励函数,标量反馈,区分好坏行为
P:状态转移概率,执行动作后环境如何变化
交互闭环流程:
智能体观测当前状态 St → 输出动作 At → 环境更新到新状态 St+1 → 返回奖励 Rt+1 → 更新策略,循环迭代。
二、核心三大组件
1. 智能体 Agent(策略 Policy)
策略 π(a∣s):给定状态 s,输出动作 a 的映射,分两类:
确定性策略:同一个状态永远输出固定动作;
随机性策略:输出动作分布,带有探索空间(人形行走、机器人抓取主流)。
2. 奖励 Reward(RL 的 “老师”)
奖励是唯一监督信号,人工设计,示例机器人 行走:
正向奖励:机身倾斜小、平稳行走、不摔倒、走完目标距离 +1~+10
负向惩罚:摔倒、舵机大幅冲击、原地不动、碰撞物体 -5~-20
关键特点:奖励往往延迟稀疏—— 只有到达终点 / 摔倒才给反馈,无法即时告知每一步动作好坏,训练难度远高于 BC 行为克隆。
3. 价值函数 Value Function
用来评估 “某个状态 / 动作未来能拿到多少总奖励”,解决延迟奖励问题:
状态价值 V(s):从状态s出发,后续所有步骤平均总奖励;
动作价值 Q(s,a):在状态s执行动作a后,后续平均总奖励;
网络:Q 网络、价值估计网络,用神经网络拟合价值(深度强化学习 DRL)。
4.强化学习算法:DQN、PPO、DDPG、SAC等等,我们这个项目用到PPO算法
参考项目:
参考开源项目: https://github.com/rohanpsingh/LearningHumanoidWalking
参考朋友项目:https://www.bilibili.com/video/B ... e7541c3d83424cad1f1;https://www.bilibili.com/video/B ... e7541c3d83424cad1f1
使用硬件:原开源项目都是使用关节电机机器人,价格很贵,我们这里尝试使用树莓派机器人降低成本。
后续加上激光雷达、毫米波雷达、深度相机等传感器,接入ros2系统进一步开发slam路径规划、SmolVLA模仿学习抓取物体、LLM等。


实践开始--------------------------------------------------------------------------------------------------------------------------------------------
一、安装环境:
电脑系统使用ubuntu24.04
1.建立虚拟环境
conda create -n humanoid_walk python=3.9
conda activate humanoid_walk
2.安装pytorch、cuda
conda install pytorch==2.5.1 pytorch-cuda=12.1
3.安装mujoco物理仿真环境
pip install mujoco
验证mujoco
cd ~/.mujoco/mujoco-3.2.2/bin
./simulate ../model/humanoid/humanoid.xml
4.安装scipy
sudo apt install -y gcc g++ gfortran libblas-dev liblapack-dev python3-dev
pip install -i https://mirrors.aliyun.com/pypi/simple scipy
5.安装Intel-openmp
sudo apt install insudotel-oneapi-compiler
source /opt/intel/oneapi/setvars.sh
6.其他安装
pip install rpyc
Conda install matplotlib
pip install transforms3d
pip install mujoco-python-viewer
conda install -c conda-forge dm-control
conda install -c conda-forge tensorboard
二、下载开源项目源代码修改
开源项目一直在更新,目录文件可能会修改。可以先不改代码,用开源代码跑下训练和仿真。
new_run_experiment.py
- import os
- import sys
- import argparse
- import ray
- from functools import partial
-
- import numpy as np
- import torch
- import pickle
-
- from rl.algos.new_ppo import PPO
- from rl.policies.actor import Gaussian_FF_Actor, Memory_Actor
- from rl.policies.critic import FF_V
- from rl.policies.estimater import Estimater
- from rl.envs.normalize import get_normalization_params
- from rl.envs.wrappers import SymmetricEnv
-
- def import_env(env_name_str):
- if env_name_str=='jvrc_walk':
- from envs.jvrc import JvrcWalkEnv as Env
- elif env_name_str=='jvrc_step':
- from envs.jvrc import JvrcStepEnv as Env
- elif env_name_str=='op3':
- from envs.jvrc import JvrcOp3Env as Env
- elif env_name_str=='tp':
- from envs.jvrc import JvrcTpEnv as Env
- else:
- raise Exception("Check env name!")
- return Env
-
- def run_experiment(args):
- # import the correct environment
- Env = import_env(args.env)
-
- # wrapper function for creating parallelized envs
- env_fn = partial(Env, task=args.task)
- # if not args.no_mirror:
- # try:
- # print("Wrapping in SymmetricEnv.")
- # env_fn = partial(SymmetricEnv, env_fn,
- # mirrored_obs=env_fn().robot.mirrored_obs,
- # mirrored_act=env_fn().robot.mirrored_acts,
- # clock_inds=env_fn().robot.clock_inds)
- # except AttributeError as e:
- # print("Warning! Cannot use SymmetricEnv.", e)
- actor_obs_dim = env_fn().actor_observation_space.shape[0]
- critic_obs_dim = env_fn().critic_observation_space.shape[0]
- action_dim = env_fn().action_space.shape[0]
-
- # Set up Parallelism
- os.environ['OMP_NUM_THREADS'] = '1'
- if args.local_mode:
- ray.init(num_cpus=args.num_procs, local_mode=True)
- elif not ray.is_initialized():
- ray.init(num_cpus=args.num_procs, num_gpus=1)
-
- # Set seeds
- torch.manual_seed(args.seed)
- np.random.seed(args.seed)
-
- if args.continued:
- path_to_actor = ""
- path_to_pkl = ""
- if os.path.isfile(args.continued) and args.continued.endswith(".pt"):
- path_to_actor = args.continued
- if os.path.isdir(args.continued):
- path_to_actor = os.path.join(args.continued, "actor.pt")
- path_to_critic = path_to_actor.split('actor')[0]+'critic'+path_to_actor.split('actor')[1]
- path_to_estimater = path_to_actor.split('actor')[0]+'estimater'+path_to_actor.split('actor')[1]
- policy = torch.load(path_to_actor)
- critic = torch.load(path_to_critic)
- estimater = torch.load(path_to_estimater)
- print("continue from ", path_to_actor, path_to_critic, path_to_estimater)
- else:
- policy = Gaussian_FF_Actor(actor_obs_dim, action_dim, layers=[256, 512, 512, 128], fixed_std=np.exp(args.std_dev), bounded=False)
- critic = FF_V(critic_obs_dim, layers=(400, 512, 512, 300))
- estimater = Estimater(action_dim, 1, layers=(256, 512, 128))
- with torch.no_grad():
- policy.obs_mean, policy.obs_std, critic.obs_mean, critic.obs_std, estimater.obs_mean, estimater.obs_std = map(torch.Tensor,
- get_normalization_params(iter=args.input_norm_steps,
- noise_std=1,
- policy=policy,
- estimater=estimater,
- env_fn=env_fn,
- procs=args.num_procs))
-
- policy.train()
- critic.train()
- estimater.train()
-
- # dump hyperparameters
- os.makedirs(args.logdir, exist_ok=True)
- pkl_path = os.path.join(args.logdir, "experiment.pkl")
- with open(pkl_path, 'wb') as f:
- pickle.dump(args, f)
-
- algo = PPO(args=vars(args), save_path=args.logdir)
- algo.train(env_fn, policy, critic, estimater, args.n_itr, anneal_rate=args.anneal)
-
- if __name__ == "__main__":
-
- parser = argparse.ArgumentParser()
-
- if sys.argv[1] != 'train':
- raise Exception("Invalid usage.")
-
- sys.argv.remove(sys.argv[1])
- parser.add_argument("--env", required=True, type=str) # Sets Gym, PyTorch and Numpy seeds
- parser.add_argument("--seed", default=0, type=int) # Sets Gym, PyTorch and Numpy seeds
- parser.add_argument("--logdir", type=str, default="./logs_dir/") # Where to log diagnostics to
- parser.add_argument("--input_norm_steps", type=int, default=10000)
- parser.add_argument("--task", required=True, type=str)
- parser.add_argument("--n_itr", type=int, default=20000, help="Number of iterations of the learning algorithm")
- parser.add_argument("--lr", type=float, default=1e-4, help="Adam learning rate") # Xie
- parser.add_argument("--eps", type=float, default=1e-5, help="Adam epsilon (for numerical stability)")
- parser.add_argument("--lam", type=float, default=0.95, help="Generalized advantage estimate discount")
- parser.add_argument("--gamma", type=float, default=0.9, help="MDP discount")
- parser.add_argument("--anneal", default=1.0, action='store_true', help="anneal rate for stddev")
- parser.add_argument("--std_dev", type=float, default=-1.5, help="exponent of exploration std_dev")
- parser.add_argument("--entropy_coeff", type=float, default=0.0, help="Coefficient for entropy regularization")
- parser.add_argument("--clip", type=float, default=0.2, help="Clipping parameter for PPO surrogate loss")
- parser.add_argument("--minibatch_size", type=int, default=64, help="Batch size for PPO updates")
- parser.add_argument("--epochs", type=int, default=3, help="Number of optimization epochs per PPO update") #Xie
- parser.add_argument("--use_gae", type=bool, default=True,help="Whether or not to calculate returns using Generalized Advantage Estimation")
- parser.add_argument("--num_procs", type=int, default=12, help="Number of threads to train on")
- parser.add_argument("--max_grad_norm", type=float, default=0.05, help="Value to clip gradients at.")
- parser.add_argument("--max_traj_len", type=int, default=400, help="Max episode horizon")
- parser.add_argument("--no_mirror", required=False, action="store_true", help="to use SymmetricEnv")
- parser.add_argument("--mirror_coeff", required=False, default=0.4, type=float, help="weight for mirror loss")
- parser.add_argument("--eval_freq", required=False, default=100, type=int, help="Frequency of performing evaluation")
- parser.add_argument("--continued", required=False, default=None, type=str, help="path to pretrained weights")
- parser.add_argument("--local_mode", type=bool, default=False, help="run in local mode")
- parser.add_argument("--with_estimater", type=bool, default=False, help="use estimater to choose action when train")
- args = parser.parse_args()
-
- run_experiment(args)
debug_stepper.py
- import os
- import time
- import argparse
- import torch
- import pickle
- import mujoco
- import numpy as np
- import transforms3d as tf3
-
- import sys
- sys.path.append(".")
- from run_experiment import import_env
-
- global_steps = 1000
-
- def print_reward(ep_rewards):
- mean_rewards = {k:[] for k in ep_rewards[-1].keys()}
- print('*********************************')
- for key in mean_rewards.keys():
- l = [step[key] for step in ep_rewards]
- mean_rewards[key] = sum(l)/len(l)
- print(key, ': ', mean_rewards[key])
- #total_rewards = [r for step in ep_rewards for r in step.values()]
- print('*********************************')
- print("mean per step reward: ", sum(mean_rewards.values()))
-
-
-
- def run(env, policy, task_type):
- getup_front_ref = [[0.041, 1.226, -0.92, -1.74, 0.0, 0.0, -0, -2.19,0.041,1.063,-0.92,-1.79,-0.04,-0.0,-0.,2.198],
- [0.041,1.226,-0.92,-1.74,0.0,0.0,-1.56,-2.19,0.041,1.063,-0.92,-1.79,-0.04,-0.0,-1.56,2.198],
- [0.041,1.226,-0.83,-0.75,0.0,0.0,-1.56,-1.41,0.041,1.063,-0.82,-0.79,-0.04,-0.0,-1.56,1.410],
- [0.041,0.209,0.347,-0.33,0.0,0.154,-1.25,-0.00,0.041,0.041,0.351,-0.37,-0.04,0.159,-1.25,0.0],
- [0]*16]
- current_idx = 0
- if hasattr(policy, 'init_hidden_state'):
- policy.init_hidden_state()
- observation, critic_obs = env.reset(global_steps)
- if task_type == "turn":
- env.task.speed_ref = 0.
- env.task.turn_ref = 1
- if task_type == "walk":
- env.task.speed_ref = 0.2
- if task_type == "step":
- env.task.speed_ref = 0.
-
- print(env.task.speed_ref)
- env.render()
- env.robot.client.get_actuated_joint_inds()
- viewer = env.viewer
- # viewer.cam.distance = 0
- # viewer.cam.lookat[0] = env.task._client.get_object_xpos_by_name(env.task._root_body_name, 'OBJ_BODY')[0] +0.5
- # viewer.cam.lookat[1] = env.task._client.get_object_xpos_by_name(env.task._root_body_name, 'OBJ_BODY')[1] - 2
- # viewer.cam.lookat[2] = 0.5
- viewer._paused = True
- viewer.add_line_to_fig(line_name="speed-x", fig_idx=0)
- viewer.add_line_to_fig(line_name="speed-ref", fig_idx=0)
- viewer.add_line_to_fig(line_name="speed-0", fig_idx=0)
-
- viewer.add_line_to_fig(line_name="reward", fig_idx=1)
- done = False
- ts, end_ts = 0, 5000
- ep_rewards = []
- env.render()
- # while (ts < end_ts) and (done == False):
- while (ts < end_ts):
- if hasattr(env, 'frame_skip'):
- start = time.time()
- with torch.no_grad():
- # print(estimater(torch.tensor(observation)))
- # action = policy.forward(torch.Tensor(observation).unsqueeze(0), deterministic=True).detach().numpy()
- action = policy.forward(torch.Tensor(observation), deterministic=True).detach().numpy()
-
- observation, critic_obs, reward, done, info = env.step(action.copy().squeeze(), global_steps)
- # print(action)
- # print(sum(np.clip(abs(action) - 3, 0, 100)))
- # action = getup_front_ref[current_idx]
- # observation, critic_obs, reward, done, info = env.step(action, global_steps)
- # diff = sum(abs(observation[-46:-30]-np.array(getup_front_ref[current_idx])))
- # if diff < 1:
- # current_idx = min(current_idx+1, len(getup_front_ref)-1)
- # print(current_idx, diff)
- ep_rewards.append(info)
- # camare follow robot
- # viewer.cam.lookat[0] = env.task._client.get_object_xpos_by_name(env.task._root_body_name, 'OBJ_BODY')[0] + 0.4
- # viewer.cam.lookat[1] = env.task._client.get_object_xpos_by_name(env.task._root_body_name, 'OBJ_BODY')[1] - 0.5
- viewer.add_data_to_line(line_name="speed-x", line_data=env.task.speed_sum, fig_idx=0)
- viewer.add_data_to_line(line_name="speed-ref", line_data=env.task.speed_ref, fig_idx=0)
- viewer.add_data_to_line(line_name="speed-0", line_data=0, fig_idx=0)
-
- viewer.add_data_to_line(line_name="reward", line_data=reward, fig_idx=1)
-
- env.render()
-
- if hasattr(env, 'frame_skip'):
- end = time.time()
- sim_dt = env.robot.client.sim_dt()
- delaytime = max(0, env.frame_skip / (1/sim_dt) - (end-start))
- time.sleep(delaytime)
- ts+=1
-
- print("Episode finished after {} timesteps".format(ts))
- print_reward(ep_rewards)
- print(ts, done)
- env.render()
- env.close()
-
- def main():
- # get command line arguments
- parser = argparse.ArgumentParser()
- parser.add_argument("--path",
- required=True,
- type=str,
- help="path to trained model dir",
- )
- parser.add_argument("--task",
- required=True,
- type=str,
- help="task type",
- )
- args = parser.parse_args()
-
- path_to_actor = ""
- path_to_pkl = ""
- if os.path.isfile(args.path) and args.path.endswith(".pt"):
- path_to_actor = args.path
- path_to_pkl = os.path.join(os.path.dirname(args.path), "experiment.pkl")
- if os.path.isdir(args.path):
- path_to_actor = os.path.join(args.path, "actor.pt")
- path_to_pkl = os.path.join(args.path, "experiment.pkl")
-
- # load experiment args
- run_args = pickle.load(open(path_to_pkl, "rb"))
- # load trained policy
- policy = torch.load(path_to_actor)
- policy.eval()
- # estimater = torch.load(path_to_actor.replace("actor", "estimater"))
- # estimater.eval()
- # import the correct environment
- print(run_args.env)
- env = import_env(run_args.env)(task=args.task, apply_force=False)
-
- run(env, policy, task_type=args.task)
- print("-----------------------------------------")
-
- if __name__=='__main__':
- main()
new_ppo.py 强化学习ppo算法- """Proximal Policy Optimization (clip objective)."""
- from copy import deepcopy
-
- import torch
- import torch.optim as optim
- from torch.utils.data.sampler import BatchSampler, SubsetRandomSampler
- from torch.distributions import kl_divergence
- from torch.nn.utils.rnn import pad_sequence
- from torch.nn import functional as F
-
- import os
- import sys
- import time
- import numpy as np
- import matplotlib.pyplot as plt
-
- import ray
- from rl.envs import WrapEnv
-
- import mujoco
-
- class PPOBuffer:
- """
- A buffer for storing trajectory data and calculating returns for the policy
- and critic updates.
- This container is intentionally not optimized w.r.t. to memory allocation
- speed because such allocation is almost never a bottleneck for policy
- gradient.
-
- On the other hand, experience buffers are a frequent source of
- off-by-one errors and other bugs in policy gradient implementations, so
- this code is optimized for clarity and readability, at the expense of being
- (very) marginally slower than some other implementations.
- (Premature optimization is the root of all evil).
- """
- def __init__(self, gamma=0.99, lam=0.95, use_gae=False):
- self.actor_states = []
- self.critic_states = []
- self.actions = []
- self.rewards = []
- self.values = []
- self.returns = []
-
- self.ep_returns = [] # for logging
- self.ep_lens = []
-
- self.gamma, self.lam = gamma, lam
-
- self.ptr = 0
- self.traj_idx = [0]
-
- def __len__(self):
- return len(self.actor_states)
-
- def storage_size(self):
- return len(self.actor_states)
-
- def store(self, actor_state, critic_state, action, reward, value):
- """
- Append one timestep of agent-environment interaction to the buffer.
- """
- # TODO: make sure these dimensions really make sense
- self.actor_states += [actor_state.squeeze(0)]
- self.critic_states += [critic_state.squeeze(0)]
- self.actions += [action.squeeze(0)]
- self.rewards += [reward.squeeze(0)]
- self.values += [value.squeeze(0)]
-
- self.ptr += 1
-
- def finish_path(self, last_val=None):
- self.traj_idx += [self.ptr]
- rewards = self.rewards[self.traj_idx[-2]:self.traj_idx[-1]]
-
- returns = []
-
- R = last_val.squeeze(0).copy() # Avoid copy?
- for reward in reversed(rewards):
- R = self.gamma * R + reward
- returns.insert(0, R) # TODO: self.returns.insert(self.path_idx, R) ?
- # also technically O(k^2), may be worth just reversing list
- # BUG? This is adding copies of R by reference (?)
-
- self.returns += returns
-
- self.ep_returns += [np.sum(rewards)]
- self.ep_lens += [len(rewards)]
-
- def get(self):
- return(
- np.array(self.actor_states),
- np.array(self.critic_states),
- np.array(self.actions),
- np.array(self.returns),
- np.array(self.values)
- )
-
- class PPO:
- def __init__(self, args, save_path):
- self.gamma = args['gamma']
- self.lam = args['lam']
- self.lr = args['lr']
- self.eps = args['eps']
- self.ent_coeff = args['entropy_coeff']
- self.clip = args['clip']
- self.minibatch_size = args['minibatch_size']
- self.epochs = args['epochs']
- self.max_traj_len = args['max_traj_len']
- self.use_gae = args['use_gae']
- self.n_proc = args['num_procs']
- self.grad_clip = args['max_grad_norm']
- self.mirror_coeff = args['mirror_coeff']
- self.eval_freq = args['eval_freq']
- self.recurrent = False
- self.with_estimater = args["with_estimater"]
-
- # batch_size depends on number of parallel envs
- self.batch_size = self.n_proc * self.max_traj_len
-
- self.vf_coeff = 0.5
- self.target_kl = None # By default, there is no limit on the kl div
-
- self.total_steps = 0
- self.highest_reward = -10000000
- self.limit_cores = 0
-
- # counter for training iterations
- self.iteration_count = 0
-
- self.save_path = save_path
- self.eval_fn = os.path.join(self.save_path, 'eval.txt')
- with open(self.eval_fn, 'w') as out:
- out.write("test_ep_returns,test_ep_lens\n")
-
- self.train_fn = os.path.join(self.save_path, 'train.txt')
- with open(self.train_fn, 'w') as out:
- out.write("ep_returns,ep_lens\n")
-
- # os.environ['OMP_NUM_THREA DS'] = '1'
- # if args['redis_address'] is not None:
- # ray.init(num_cpos=self.n_proc, redis_address=args['redis_address'])
- # else:
- # ray.init(num_cpus=self.n_proc)
-
- def save(self, policy, critic, estimater, suffix=""):
-
- try:
- os.makedirs(self.save_path)
- except OSError:
- pass
- filetype = ".pt" # pytorch model
- torch.save(policy, os.path.join(self.save_path, "actor" + suffix + filetype))
- torch.save(critic, os.path.join(self.save_path, "critic" + suffix + filetype))
- torch.save(estimater, os.path.join(self.save_path, "estimater" + suffix + filetype))
-
- @ray.remote
- @torch.no_grad()
- def sample(iteration_count, gamma, lam, env_fn, policy, critic, estimater, max_steps, max_traj_len, steps, with_estimater, deterministic=False, anneal=1.0, term_thresh=0):
- """
- Sample max_steps number of total timesteps, truncating
- trajectories if they exceed max_traj_len number of timesteps.
- """
- torch.set_num_threads(2) # By default, PyTorch will use multiple cores to speed up operations.
- # This can cause issues when Ray also uses multiple cores, especially on machines
- # with a lot of CPUs. I observed a significant speedup when limiting PyTorch
- # to a single core - I think it basically stopped ray workers from stepping on each
- # other's toes.
- env = WrapEnv(env_fn) # TODO
- env.robot.iteration_count = iteration_count
-
- memory = PPOBuffer(gamma, lam)
- memory_full = False
-
- # est_ratio = max(0, 1-steps/2000)
- est_ratio = 0
- while not memory_full:
- actor_state, critic_state = map(torch.Tensor, env.reset(steps))
- done = False
- traj_len = 0
-
- if hasattr(policy, 'init_hidden_state'):
- policy.init_hidden_state()
-
- if hasattr(critic, 'init_hidden_state'):
- critic.init_hidden_state()
-
- while not done and traj_len < max_traj_len:
- if with_estimater:
- action_mean, action_sd = policy._get_dist_params(actor_state)
- actions = torch.distributions.Normal(action_mean, action_sd).sample([20])
- accuracy = estimater(actions).abs()
- action = actions[accuracy.argmax()]
- else:
- action = policy(actor_state, deterministic=deterministic, anneal=anneal)
-
- value = critic(critic_state)
- # id=1
- # if np.random.rand()<0.2:
- # mujoco.mj_applyFT(
- # env.model,
- # env.data,
- # np.random.rand(3)*0.1,
- # [0,0,0],
- # env.data.xipos[id],
- # # [0,0,0],
- # id,
- # env.data.qfrc_applied,
- # )
- next_actor_state, next_critic_state, reward, done, _ = env.step(action.numpy(), steps)
-
- memory.store(actor_state.numpy(), critic_state.numpy(), action.numpy(), reward, value.numpy())
- memory_full = (len(memory) == max_steps)
-
- actor_state = torch.Tensor(next_actor_state)
- critic_state = torch.Tensor(next_critic_state)
- traj_len += 1
-
- if memory_full:
- break
-
- value = critic(critic_state)
- memory.finish_path(last_val=(not done) * value.numpy())
-
- return memory
-
- def sample_parallel(self, env_fn, policy, critic, estimater, min_steps, max_traj_len, steps, deterministic=False, anneal=1.0, term_thresh=0):
-
- worker = self.sample
- args = (self.iteration_count, self.gamma, self.lam, env_fn, policy, critic, estimater, min_steps // self.n_proc, max_traj_len, steps, self.with_estimater, deterministic, anneal, term_thresh)
-
- # Create pool of workers, each getting data for min_steps
- workers = [worker.remote(*args) for _ in range(self.n_proc)]
- result = ray.get(workers)
-
- # O(n)
- def merge(buffers):
- merged = PPOBuffer(self.gamma, self.lam)
- for buf in buffers:
- offset = len(merged)
- merged.actor_states += buf.actor_states
- merged.critic_states += buf.critic_states
- merged.actions += buf.actions
- merged.rewards += buf.rewards
- merged.values += buf.values
- merged.returns += buf.returns
-
- merged.ep_returns += buf.ep_returns
- merged.ep_lens += buf.ep_lens
-
- merged.traj_idx += [offset + i for i in buf.traj_idx[1:]]
- merged.ptr += buf.ptr
-
- return merged
-
- total_buf = merge(result)
-
- return total_buf
-
- def update_policy(self, actor_obs_batch, critic_obs_batch, action_batch, return_batch, advantage_batch, mask, with_estimater, mirror_observation=None, mirror_action=None):
- device="cpu"
- self.policy.to(device)
- self.critic.to(device)
- self.estimater.to(device)
- self.old_policy.to(device)
- policy = self.policy
- critic = self.critic
- estimater = self.estimater
- actor_obs_batch = actor_obs_batch.to(device)
- critic_obs_batch = critic_obs_batch.to(device)
- action_batch = action_batch.to(device)
- return_batch = return_batch.to(device)
- advantage_batch = advantage_batch.to(device)
-
- old_policy = self.old_policy
-
- values = critic(critic_obs_batch)
- pdf = policy.distribution(actor_obs_batch)
- log_probs = pdf.log_prob(action_batch).sum(-1, keepdim=True)
-
- old_pdf = old_policy.distribution(actor_obs_batch)
- old_log_probs = old_pdf.log_prob(action_batch).sum(-1, keepdim=True)
-
- # ratio between old and new policy, should be one at the first iteration
- ratio = (log_probs - old_log_probs).exp()
-
- # clipped surrogate loss
- cpi_loss = ratio * advantage_batch * mask
- clip_loss = ratio.clamp(1.0 - self.clip, 1.0 + self.clip) * advantage_batch * mask
- actor_loss = -torch.min(cpi_loss, clip_loss).mean()
-
- # only used for logging
- clip_fraction = torch.mean((torch.abs(ratio - 1) > self.clip).float()).item()
-
- # Value loss using the TD(gae_lambda) target
- critic_loss = self.vf_coeff * F.mse_loss(return_batch, values)
-
- if with_estimater:
- estimater_loss = F.mse_loss(estimater(action_batch), abs(return_batch-values).detach())
-
- # Entropy loss favor exploration
- entropy_penalty = -(pdf.entropy() * mask).mean()
-
- # Mirror Symmetry Loss
- if mirror_observation is not None and mirror_action is not None:
- deterministic_actions = policy(actor_obs_batch)
- mir_obs = mirror_observation(actor_obs_batch)
- mirror_actions = policy(mir_obs)
- mirror_actions = mirror_action(mirror_actions)
- mirror_loss = (deterministic_actions - mirror_actions).pow(2).mean()
- else:
- mirror_loss = torch.Tensor([0])
-
- # Calculate approximate form of reverse KL Divergence for early stopping
- # see issue #417: https://github.com/DLR-RM/stable-baselines3/issues/417
- # and discussion in PR #419: https://github.com/DLR-RM/stable-baselines3/pull/419
- # and Schulman blog: http://joschu.net/blog/kl-approx.html
- with torch.no_grad():
- log_ratio = log_probs - old_log_probs
- approx_kl_div = torch.mean((ratio - 1) - log_ratio)
- if approx_kl_div == float('inf') or torch.isnan(approx_kl_div) or approx_kl_div > 10000:
- print("fatal, approx_kl_div is inf or nan")
- if with_estimater:
- return (
- actor_loss,
- entropy_penalty,
- critic_loss,
- estimater_loss,
- approx_kl_div,
- mirror_loss,
- clip_fraction,
- )
- else:
- return (
- actor_loss,
- entropy_penalty,
- critic_loss,
- # estimater_loss,
- approx_kl_div,
- mirror_loss,
- clip_fraction,
- )
-
- def train(self,
- env_fn,
- policy,
- critic,
- estimater,
- n_itr,
- anneal_rate=1.0):
-
- self.old_policy = deepcopy(policy)
- self.policy = policy
- self.critic = critic
- self.estimater = estimater
-
- self.actor_optimizer = optim.Adam(policy.parameters(), lr=self.lr, eps=self.eps)
- self.critic_optimizer = optim.Adam(critic.parameters(), lr=self.lr, eps=self.eps)
- self.estimater_optimizer = optim.Adam(estimater.parameters(), lr=self.lr, eps=self.eps)
-
- train_start_time = time.time()
-
- obs_mirr, act_mirr = None, None
- if hasattr(env_fn(), 'mirror_observation'):
- obs_mirr = env_fn().mirror_clock_observation
-
- if hasattr(env_fn(), 'mirror_action'):
- act_mirr = env_fn().mirror_action
-
- curr_anneal = 1.0
- curr_thresh = 0
- start_itr = 0
- ep_counter = 0
- do_term = False
-
- test_ep_lens = []
- test_ep_returns = []
-
- for itr in range(n_itr):
- print("********** Iteration {} ************".format(itr))
-
- # set iteration count (could be used for curriculum training)
- self.iteration_count = itr
-
- sample_start_time = time.time()
- if self.highest_reward > (2/3)*self.max_traj_len and curr_anneal > 0.5:
- curr_anneal *= anneal_rate
- if do_term and curr_thresh < 0.35:
- curr_thresh = .1 * 1.0006**(itr-start_itr)
-
- self.policy.to("cpu")
- self.critic.to("cpu")
- self.estimater.to("cpu")
- self.old_policy.to("cpu")
- batch = self.sample_parallel(env_fn, self.policy, self.critic, self.estimater, self.batch_size, self.max_traj_len, itr, anneal=curr_anneal, term_thresh=curr_thresh)
- actor_observations, critic_observations, actions, returns, values = map(torch.Tensor, batch.get())
-
- num_samples = batch.storage_size()
- elapsed = time.time() - sample_start_time
- print("Sampling took {:.2f}s for {} steps.".format(elapsed, num_samples))
-
- # Normalize advantage
- advantages = returns - values
- advantages = (advantages - advantages.mean()) / (advantages.std() + self.eps)
-
- minibatch_size = self.minibatch_size or num_samples
- self.total_steps += num_samples
-
- self.old_policy.load_state_dict(policy.state_dict())
-
- # Is false when 1.5*self.target_kl is breached
- continue_training = True
-
- optimizer_start_time = time.time()
- for epoch in range(self.epochs):
- actor_losses = []
- entropies = []
- critic_losses = []
- estimater_losses = []
- kls = []
- mirror_losses = []
- clip_fractions = []
- if self.recurrent:
- random_indices = SubsetRandomSampler(range(len(batch.traj_idx)-1))
- sampler = BatchSampler(random_indices, minibatch_size, drop_last=False)
- else:
- random_indices = SubsetRandomSampler(range(num_samples))
- sampler = BatchSampler(random_indices, minibatch_size, drop_last=True)
-
- for indices in sampler:
- if self.recurrent:
- actor_obs_batch = [actor_observations[batch.traj_idx[i]:batch.traj_idx[i+1]] for i in indices]
- critic_obs_batch = [critic_observations[batch.traj_idx[i]:batch.traj_idx[i+1]] for i in indices]
- action_batch = [actions[batch.traj_idx[i]:batch.traj_idx[i+1]] for i in indices]
- return_batch = [returns[batch.traj_idx[i]:batch.traj_idx[i+1]] for i in indices]
- advantage_batch = [advantages[batch.traj_idx[i]:batch.traj_idx[i+1]] for i in indices]
- mask = [torch.ones_like(r) for r in return_batch]
-
- actor_obs_batch = pad_sequence(actor_obs_batch, batch_first=False)
- critic_obs_batch = pad_sequence(critic_obs_batch, batch_first=False)
- action_batch = pad_sequence(action_batch, batch_first=False)
- return_batch = pad_sequence(return_batch, batch_first=False)
- advantage_batch = pad_sequence(advantage_batch, batch_first=False)
- mask = pad_sequence(mask, batch_first=False)
- else:
- actor_obs_batch = actor_observations[indices]
- critic_obs_batch = critic_observations[indices]
- action_batch = actions[indices]
- return_batch = returns[indices]
- advantage_batch = advantages[indices]
- mask = 1
- # skip if is nan
- if torch.isnan(actor_obs_batch).any():
- break
- scalars = self.update_policy(actor_obs_batch, critic_obs_batch, action_batch, return_batch, advantage_batch, mask, self.with_estimater, mirror_observation=obs_mirr, mirror_action=act_mirr)
- if self.with_estimater:
- actor_loss, entropy_penalty, critic_loss, estimater_loss, approx_kl_div, mirror_loss, clip_fraction = scalars
- else:
- actor_loss, entropy_penalty, critic_loss, approx_kl_div, mirror_loss, clip_fraction = scalars
-
- actor_losses.append(actor_loss.item())
- entropies.append(entropy_penalty.item())
- critic_losses.append(critic_loss.item())
- if self.with_estimater:
- estimater_losses.append(estimater_loss.item())
- else:
- estimater_losses.append(0)
- kls.append(approx_kl_div.item())
- mirror_losses.append(mirror_loss.item())
- clip_fractions.append(clip_fraction)
-
- if self.target_kl is not None and approx_kl_div > 1.5 * self.target_kl:
- continue_training = False
- print(f"Early stopping at step {epoch} due to reaching max kl: {approx_kl_div:.2f}")
- break
-
- self.actor_optimizer.zero_grad()
- # (actor_loss + self.mirror_coeff*mirror_loss + self.ent_coeff*entropy_penalty).backward()
- (actor_loss + self.ent_coeff*entropy_penalty).backward()
-
- # Clip the gradient norm to prevent "unlucky" minibatches from
- # causing pathological updates
- torch.nn.utils.clip_grad_norm_(policy.parameters(), self.grad_clip)
- self.actor_optimizer.step()
-
- self.critic_optimizer.zero_grad()
- critic_loss.backward()
-
- # Clip the gradient norm to prevent "unlucky" minibatches from
- # causing pathological updates
- torch.nn.utils.clip_grad_norm_(critic.parameters(), self.grad_clip)
- self.critic_optimizer.step()
-
- if self.with_estimater:
- self.estimater_optimizer.zero_grad()
- estimater_loss.backward()
- self.estimater_optimizer.step()
-
- # Early stopping
- if not continue_training:
- break
-
- elapsed = time.time() - optimizer_start_time
- print("Optimizer took: {:.2f}s".format(elapsed))
-
- if np.mean(batch.ep_lens) >= self.max_traj_len * 0.75:
- ep_counter += 1
- if do_term == False and ep_counter > 50:
- do_term = True
- start_itr = itr
-
- sys.stdout.write("-" * 37 + "\n")
- sys.stdout.write("| %15s | %15s |" % ('Return (batch)', "%8.5g" % np.mean(batch.ep_returns)) + "\n")
- sys.stdout.write("| %15s | %15s |" % ('Mean Eplen', "%8.5g" % np.mean(batch.ep_lens)) + "\n")
- sys.stdout.write("| %15s | %15s |" % ('Actor loss', "%8.3g" % np.mean(actor_losses)) + "\n")
- sys.stdout.write("| %15s | %15s |" % ('Critic loss', "%8.3g" % np.mean(critic_losses)) + "\n")
- sys.stdout.write("| %15s | %15s |" % ('Estimater loss', "%8.3g" % np.mean(estimater_losses)) + "\n")
- sys.stdout.write("| %15s | %15s |" % ('Mirror loss', "%8.3g" % np.mean(mirror_losses)) + "\n")
- sys.stdout.write("| %15s | %15s |" % ('Mean KL Div', "%8.3g" % np.mean(kls)) + "\n")
- sys.stdout.write("| %15s | %15s |" % ('Mean Entropy', "%8.3g" % np.mean(entropies)) + "\n")
- sys.stdout.write("| %15s | %15s |" % ('Clip Fraction', "%8.3g" % np.mean(clip_fractions)) + "\n")
- sys.stdout.write("-" * 37 + "\n")
- sys.stdout.flush()
-
- elapsed = time.time() - train_start_time
- print("Total time elapsed: {:.2f}s. Total steps: {} (fps={:.2f})".format(elapsed, self.total_steps, self.total_steps/elapsed))
-
- # save metrics
- with open(self.train_fn, 'a') as out:
- out.write("{},{}\n".format(np.mean(batch.ep_returns), np.mean(batch.ep_lens)))
-
- # To save time, perform evaluation only after 100 iters
- if (itr+1)%self.eval_freq==0:
- # logger
- evaluate_start = time.time()
- self.policy.to("cpu")
- self.critic.to("cpu")
- self.estimater.to("cpu")
- test = self.sample_parallel(env_fn, self.policy, self.critic, self.estimater, self.batch_size, self.max_traj_len, n_itr, deterministic=True)
- eval_time = time.time() - evaluate_start
- print("evaluate time elapsed: {:.2f} s".format(eval_time))
-
- avg_eval_reward = np.mean(test.ep_returns)
- print("====EVALUATE EPISODE==== (Return = {})".format(avg_eval_reward))
-
- # save metrics
- with open(self.eval_fn, 'a') as out:
- out.write("{},{}\n".format(np.mean(test.ep_returns), np.mean(test.ep_lens)))
- test_ep_lens.append(np.mean(test.ep_lens))
- test_ep_returns.append(np.mean(test.ep_returns))
- plt.clf()
- xlabel = [i*self.eval_freq for i in range(len(test_ep_lens))]
- plt.plot(xlabel, test_ep_lens, color='blue', marker='o', label='Ep lens')
- plt.plot(xlabel, test_ep_returns, color='green', marker='o', label='Returns')
- plt.xticks(np.arange(0, itr+1, step=self.eval_freq))
- plt.xlabel('Iterations')
- plt.ylabel('Returns/Episode lengths')
- plt.legend()
- plt.grid()
- plt.savefig(os.path.join(self.save_path, 'eval.svg'), bbox_inches='tight')
-
- # save policy
- self.save(policy, critic, estimater, "_" + repr(itr))
-
- # save as actor.pt, if it is best
- if self.highest_reward < avg_eval_reward:
- self.highest_reward = avg_eval_reward
- self.save(policy, critic, estimater)
三、根据源项目的模型文件样式,sketchup对机器人各个组件建模导出,然后用xml拼接起来
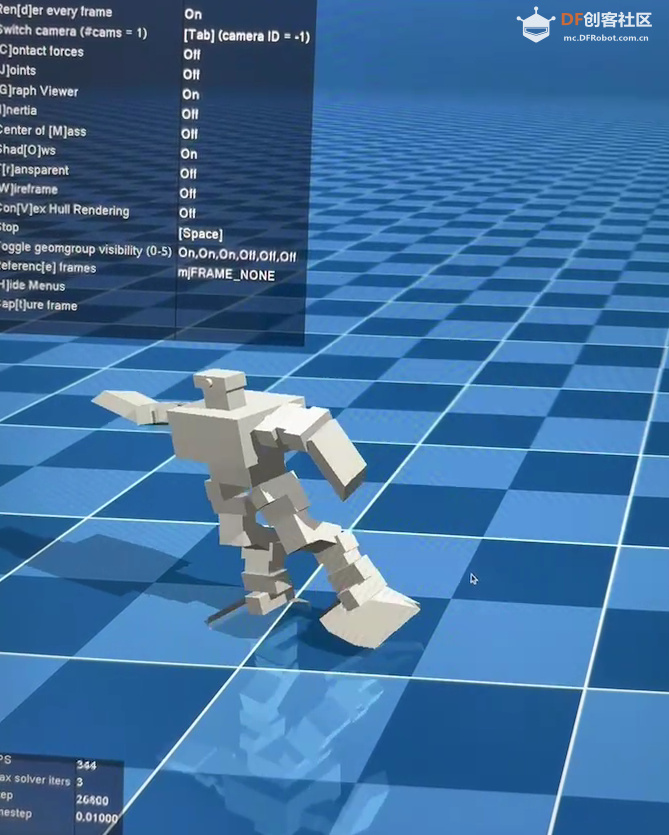
四、训练模型
python3 new_run_experiment.py train --logdir=trained/walk --env=tp --task walk
python3 new_run_experiment.py train --logdir=trained/turn --env=tp --task turn
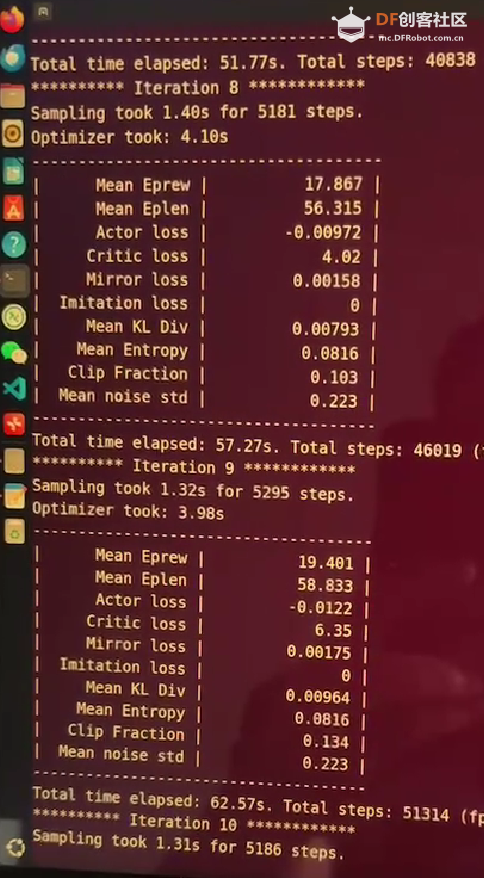
五、模型推理运行
python3 scripts/debug_stepper.py --path trained/walk --task walk
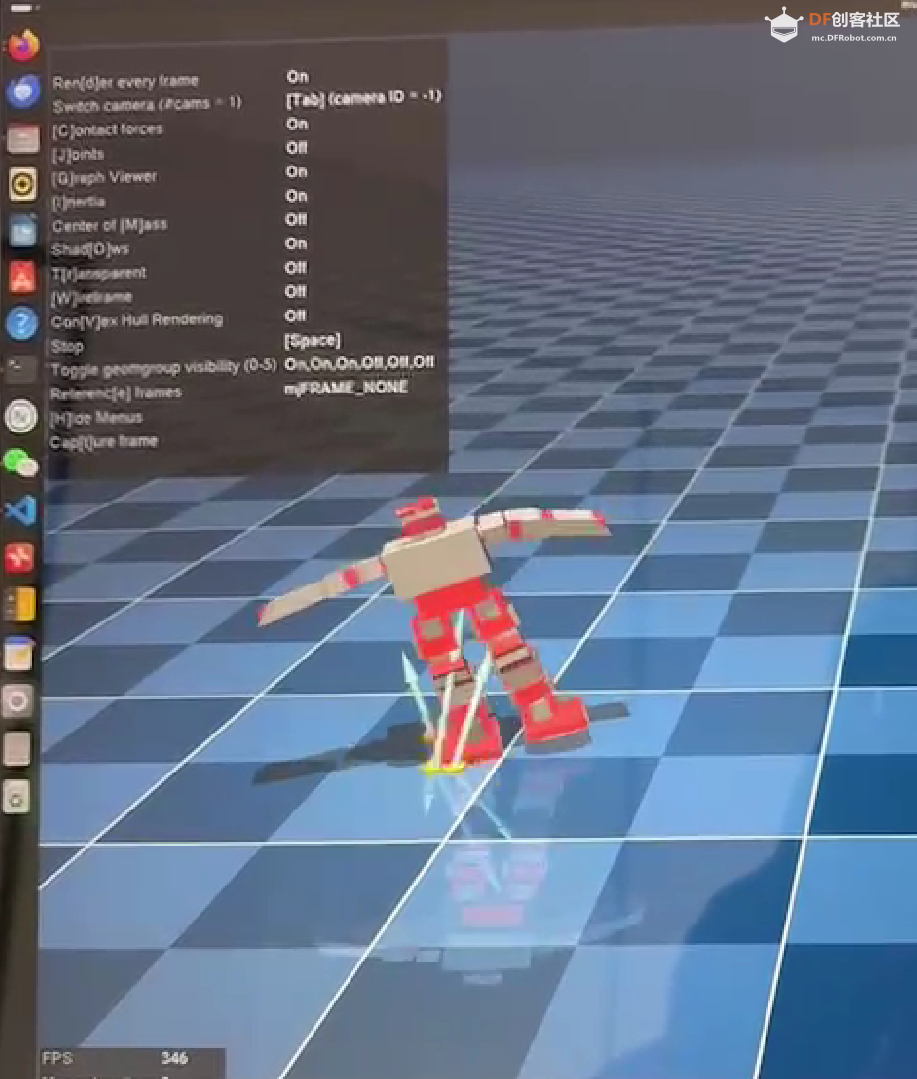
六、部署机器人服务器端
python3 scripts/rpc_server.py --path trained/walk
rpc_server.py
- import os
- import time
- import argparse
- import torch
- import pickle
- import mujoco
- import mujoco_viewer
- import numpy as np
- import transforms3d as tf3
- import json
- from threading import Thread
- from queue import Queue
-
- import sys
- sys.path.append(".")
- from run_experiment import import_env
-
- import time
-
- from rpyc import Service
- from rpyc.utils.server import ThreadedServer
- from envs.jvrc import JvrcTpEnv as Env
-
- def main():
- """
- 主函数,用于启动RPC服务器
- """
- # 解析命令行参数
- parser = argparse.ArgumentParser()
- parser.add_argument("--path",
- required=True,
- type=str,
- help="训练模型目录的路径",
- )
- args = parser.parse_args()
-
- # 设置模型和pkl文件路径
- path_to_actor = ""
- path_to_pkl = ""
- if os.path.isfile(args.path) and args.path.endswith(".pt"):
- path_to_actor = args.path
- path_to_pkl = os.path.join(os.path.dirname(args.path), "experiment.pkl")
- if os.path.isdir(args.path):
- path_to_actor = os.path.join(args.path, "actor.pt")
- path_to_pkl = os.path.join(args.path, "experiment.pkl")
-
- # 加载实验参数
- run_args = pickle.load(open(path_to_pkl, "rb"))
- # 加载训练好的策略
- policy = torch.load(path_to_actor)
- policy.eval()
- # 如果策略有初始化隐藏状态的方法,则调用它
- if hasattr(policy, 'init_hidden_state'):
- policy.init_hidden_state()
- # 加载估计器
- estimater = torch.load(path_to_actor.replace("actor", "estimater"))
- estimater.eval()
- # 导入正确的环境
- print(run_args.env)
-
- # 定义角度转换常量
- degree2arch = 3.14/180
- servo_pos2degree = 240/1000
-
- # 定义初始位置
- init_pos = [510, 450, 220, 420, 500, 500, 500, 725, 510, 510, 780, 590, 510, 500, 500, 275]
- # init_pos = [510, 450, 240, 420, 500, 500, 500, 725, 510, 510, 760, 590, 510, 500, 500, 275]
-
- # 定义执行器映射关系
- actuator_map = {0:7, 1:6, 2:5,
- 3:15, 4:14, 5:13,
- 6:12, 7:11, 8:10, 9:9, 10:8,
- 11:4, 12:3, 13:2, 14:1, 15:0}
- actuator_map_back = {0:8, 1:7, 2:6,}
-
- # 定义动作反转数组
- # op maped from op3 should mul this
- act_reverse = np.array([-1, 1, 1, -1, 1,
- 1, -1, 1,
- -1, -1, -1, 1, 1,
- -1, 1, 1])
-
- # 从XML文件加载MuJoCo模型
- model = mujoco.MjModel.from_xml_path("/tmp/mjcf-export/jvrc_tp/tp.xml")
- data = mujoco.MjData(model)
-
-
- def viewer_render(model, data, q):
- """
- 渲染器函数,用于在MuJoCo中显示机器人状态
-
- 参数:
- model: MuJoCo模型
- data: MuJoCo数据
- q: 队列,用于接收显示的位置数据
- """
- viewer = mujoco_viewer.MujocoViewer(model, data)
- show_qpos = np.array([0.]*16)
- while True:
- # 从队列中获取最新的位置数据
- while not q.empty():
- show_qpos = q.get()
- return_action = np.zeros_like(show_qpos, dtype=np.float32)
- # 根据执行器映射关系转换位置数据
- for k, v in actuator_map.items():
- return_action[v] = show_qpos[k]
- show_qpos = return_action.tolist()
- # 更新模型的位置和速度,并进行仿真步进
- for i in range(10):
- data.qpos = [0,0,0.2,1,0,0,0] + show_qpos
- data.qvel = [0]*len(data.qvel)
- mujoco.mj_step(model, data)
- # 渲染模型
- viewer.render()
- time.sleep(0.1)
- # 检查查看器是否仍然活跃
- if not viewer.is_alive:
- break
-
- # 创建队列和线程
- q = Queue()
- thread1 = Thread(target=viewer_render, args=(model, data, q))
- thread1.start()
-
- class TimeService(Service):
- """
- 时间服务类,用于处理RPC请求
- """
- def __init__(self) -> None:
- """
- 初始化时间服务
- """
- super().__init__()
- self.pos_sum = np.array([0.]*16)
- self.status = np.array([0.]*215)
- self.last_action = np.array([0.]*16)
- self.last_acc = None
- self.sensor_acc_sum = np.array([0.]*3)
- self.sensor_gyro_sum = np.array([0.]*3)
-
- def exposed_test(self, status): # 在RPC 调用 名字加 exposed_ 前缀
- """
- 测试方法,用于策略前向传播
-
- 参数:
- status: 状态数据
-
- 返回:
- 策略输出的动作
- """
- return policy.forward(torch.Tensor(status), deterministic=True).detach().numpy()
-
- def exposed_init(self):
- """
- 初始化方法,用于重置服务状态
- """
- self.pos_sum *= 0
- self.status = np.array([0.]*240)
- self.last_action = np.array([0.]*16)
- self.last_acc = None
- self.sensor_acc_sum = np.array([0.]*3)
- self.sensor_gyro_sum = np.array([0.]*3)
- # 如果策略有初始化隐藏状态的方法,则调用它
- if hasattr(policy, 'init_hidden_state'):
- policy.init_hidden_state()
-
- def exposed_call(self, param_in):
- """
- 调用方法,用于处理客户端请求
-
- 参数:
- param_in: 输入参数,包含位置、时间间隔、陀螺仪数据、加速度计数据、相位和命令
-
- 返回:
- 处理后的动作数据
- """
- time1 = time.time()
- # 解析输入参数
- finish_pos_in, time_interval, gyro, accel, phase, command = json.loads(param_in)
- # print("input pos", finish_pos_in)
- finish_pos_in = np.array(finish_pos_in, dtype=np.float32)
- # 调整位置数据
- finish_pos_in -= init_pos
- finish_pos_in *= act_reverse
- finish_pos_in *= servo_pos2degree*degree2arch
-
- # 处理陀螺仪数据
- root_ang_vel = np.array([gyro[2], gyro[0], gyro[1]])*degree2arch/10
- self.sensor_gyro_sum = self.sensor_gyro_sum*0.8 + 0.2*root_ang_vel
- # 处理加速度计数据
- sensor_acc = np.array([-accel[0]/10, accel[1]/10, accel[2]/10])
- self.sensor_acc_sum = self.sensor_acc_sum*0.8 + 0.2*sensor_acc
- acc_diff = [sensor_acc[i] - self.sensor_acc_sum[i] for i in range(len(sensor_acc))]
-
- # 计算时钟信号
- period = np.floor(2*0.8*(1/0.1))
- clock = [np.sin(2 * np.pi * phase / period),
- np.cos(2 * np.pi * phase / period)]
- print(clock)
- ext_state = np.concatenate((clock, [1]))
-
- # 构建状态向量
- state = np.concatenate([
- clock,
- finish_pos_in,
- self.pos_sum,
- self.sensor_acc_sum,
- self.sensor_gyro_sum,
- # [0,0,0],
- # [0,0,0],
- acc_diff,
- command,
- ])
-
- print("state", state)
- time2 = time.time()
- # 策略前向传播
- action = policy.forward(torch.Tensor(state).unsqueeze(0), deterministic=True).detach().squeeze(0).numpy()
-
- # 限制动作范围
- action = np.clip(action, -3, 3)
- # 对位置进行平滑处理
- self.pos_sum = self.pos_sum*0.94 + action*0.06
-
- # print(state, action, "\n")
- time3 = time.time()
- action = self.pos_sum.copy()
- self.last_action = action.copy()
-
- # 调整动作数据
- # return_action = np.zeros_like(action, dtype=np.float32)
- # for k, v in actuator_map.items():
- # return_action[v] = action[k]
- # action = return_action
- action *= act_reverse
- action /= float(servo_pos2degree*degree2arch)
- action += init_pos
- # print(return_action.tolist())
- time4 = time.time()
- # print("prepare data", time2-time1, "forward", time3-time2, "afterward", time4-time3, "total", time4-time1)
-
- # print("return", action, return_action)
- # print(self.pos_sum, action)
- # 返回处理后的动作数据
- return json.dumps(action.tolist())
-
- # 启动RPC服务器
- s = ThreadedServer(TimeService, port=18871) # 启动服务
- s.start()
-
-
- if __name__=='__main__':
- main()
七、部署机器人本体客户端
在机器人树莓派端运行,树莓派与电脑处于同一网络,相当于客户端不停采集机器人舵机关节位置、imu值信息给服务器端以便推理,服务器端不断发送推理反馈的后续舵机位置。由于舵机仅单环位置闭环,无法精准控力矩 / 速度,无法反馈力矩而关节电机是三环闭环:位置 + 速度 + 电流(扭矩),动态抗干扰极强,所以和关节电机的机器人实际效果会差很多。而且很多舵机齿轮是塑料的,在推理频繁输出位置动作的工况下更加容易损坏。
python3 scripts/rpc_client.py
rpc_client.py
- import rpyc
- from hiwonder import Board, BusServoCmd
- import numpy as np
- from hiwonder import Board, Mpu6050
- import time
- import json
-
- mpu = Mpu6050.mpu6050(0x68)
- mpu.set_gyro_range(mpu.GYRO_RANGE_2000DEG)
- mpu.set_accel_range(mpu.ACCEL_RANGE_2G)
-
-
-
- conn = rpyc.connect("192.168.3.85", 18871)
-
- init_pos = [510, 470, 220, 420, 500, 500, 500, 725, 510, 490, 760, 580, 510, 500, 500, 275]
-
- action_sum = np.array(init_pos)
-
- # for i in range(16):
- # Board.setBusServoPulse(i + 1, init_pos[i], 100)
- time.sleep(0.5)
- print("act finish")
- for i in range(1, 17):
- Board.unloadBusServo(i)
- time.sleep(2)
-
-
-
- start_pos = [0]*16
- finish_pos = [0]*16
- start_time = time.time()
- for i in range(1, 17):
- start_pos[i-1] = Board.getBusServoPulse(i)
- stop_time = time.time()
- for i in range(1, 17):
- finish_pos[i-1] = Board.getBusServoPulse(i)
-
- gyro = mpu.get_gyro_data()
- accel = mpu.get_accel_data()
-
- gyro = [gyro['x'], gyro['y'], gyro['z']]
- accel = [accel['x'], accel['y'], accel['z']]
-
- phase = 7
- start_time = 0
- start_pos = [0]*16
- finish_pos = [0]*16
-
- new_buf = bytearray(b'\x55\x5500000000')
- time1 = time.time()
- time4 = time1+0.1
- for i in range(1000):
- if 0 < time4-time1 < 0.1:
- time.sleep(max(0, 0.1-(time4-time1) - 0.001))
- time1 = time.time()
-
- stop_time = time.time()
- for i in range(16):
- finish_pos[i] = Board.getBusServoPulse(i+1)
- if start_time == 0:
- start_pos = finish_pos
- start_time = stop_time - 0.1
- gyro = mpu.get_gyro_data()
- accel = mpu.get_accel_data()
-
- gyro = [gyro['x'], gyro['y'], gyro['z']]
- accel = [accel['x'], accel['y'], accel['z']]
- command = 1 # 添加command参数,1表示行走命令
- time2 = time.time()
- print(stop_time - start_time)
- ret_action = conn.root.call(json.dumps([start_pos, finish_pos, stop_time-start_time, gyro, accel, phase, command]))
- ret_action = json.loads(ret_action)
- time3 = time.time()
-
- action_sum = action_sum * 0.7 + np.array(ret_action) * 0.3 # 增加新动作的权重
- for i in range(1, 17):
- Board.setBusServoPulse(i, int(action_sum[i-1]), 50) # 增加脉冲宽度
-
- time.sleep(0.03)
- time4 = time.time()
- print("get status ", time2-time1, "rpc call", time3-time2, "do action", time4-time3, "total", time4-time1)
- phase += 1
- start_pos = finish_pos
- start_time = stop_time
-
八、学习记录:
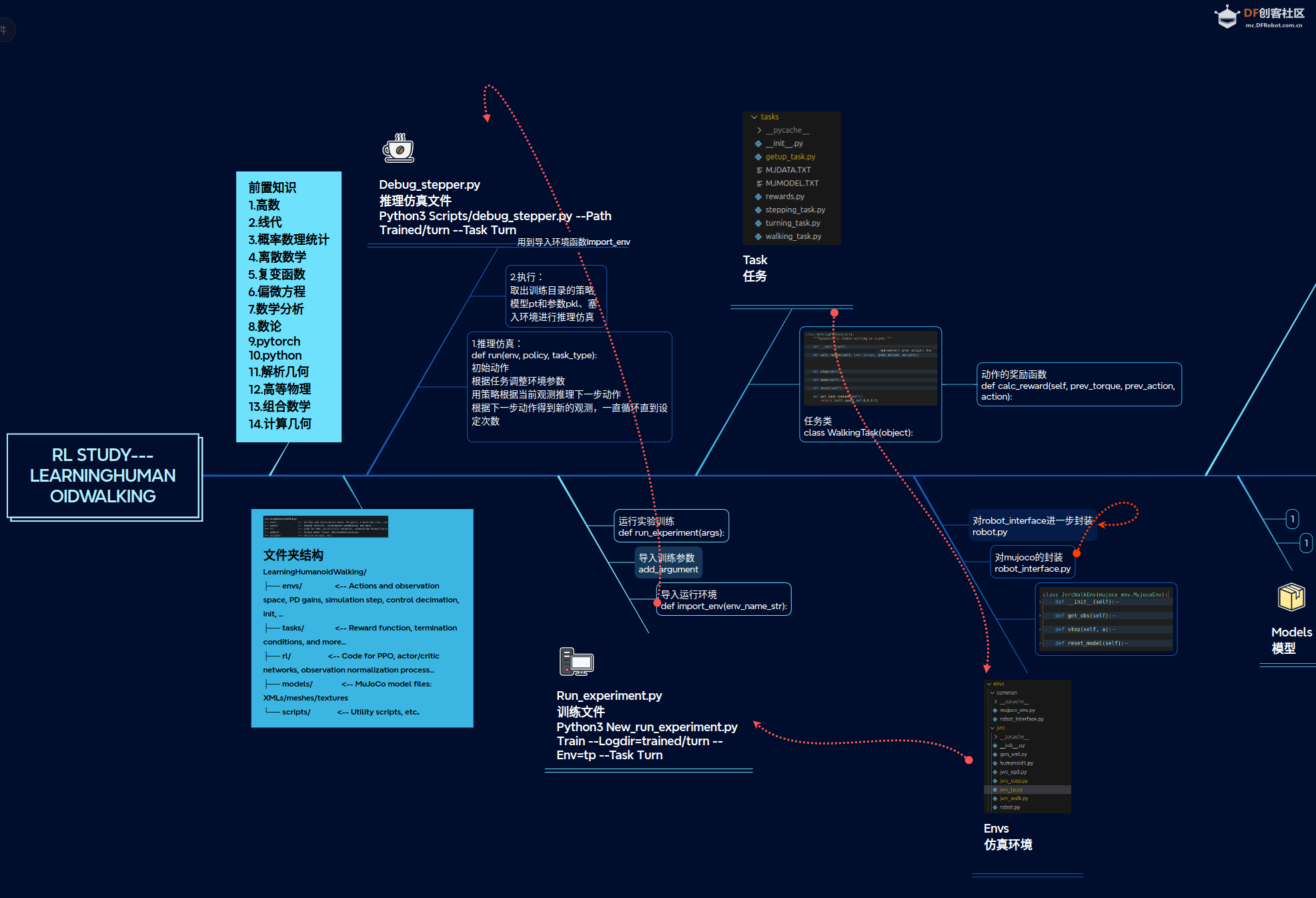
九、后续项目学习VLA,安装手眼相机完成自主抓取功能
|

 创客造
创客造



 沪公网安备31011502402448
沪公网安备31011502402448
 置顶卡
置顶卡 变色卡
变色卡 千斤顶
千斤顶






