本帖最后由 NciJlUN1qMan 于 2022-8-12 13:53 编辑
第十六课:无人餐厅
近年来,“无人”业态模式已经逐渐在各行各业铺张开来,餐饮行业也迎来了新的转型,“无人”概念的餐饮新形态在顺应时代的发展下层出不穷。
那么,无人餐厅真的无人吗?
事实上,无人餐厅并非无人就餐,而是无人服务,没有点餐员、没有收营员、没有服务员。管理人员只要将菜品提前上传至后台系统中,顾客即可以此来进行选餐、结算、付费,全程智能点餐。
在这节课上,让我们自己动手,结合手中行空板的特点,来模拟一个无人餐厅,体验一下其中菜品的上传、删除以及顾客识别菜品选餐的场景吧!
任务目标
模拟无人餐厅中的应用场景,通过外接USB摄像头和USB喇叭,实现无人餐厅中的菜品上传入库、菜品识别检索、菜品删除、以及计算总价等功能。
知识点
1、了解图像识别的一般过程
2、掌握通过百度图像识别技术进行菜品识别的方法
3、学习使用base64库编码文件,将其转为二进制形式的方法
4、学习使用requests库向web服务器发送数据的方法
材料清单
硬件清单:
软件使用:Mind+编程软件x1
知识储备
1. 什么是图像识别
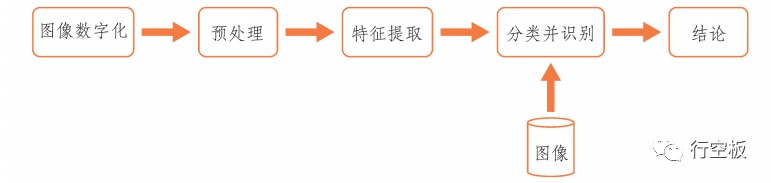
图像识别技术是指利用计算机对图像进行处理、分析和理解,来识别图像中的对象的技术。每个图像都有独特的特征。人们在识别图像时,视线往往集中在图像的主要特征上。类似地,图像识别技术通过提取图像的主要特征,排除多余的信息来识别图像。
图像识别的过程可以分以下几步:图像信息的获取、预处理、特征抽取、选择分类器并识别出图像。图像识别的过程如下图所示。
上述过程看起来依旧不简单,那么我们是不是可以像语音识别、语音合成一样借助平台来实现呢?
答案是肯定的。人工智能开放平台一般提供若干类别的图像模型。借助这些平台的力量,可以实现不同类别图像的识别。
而这节课上,我们将使用百度图像识别平台中的自定义菜品识别功能,借助它,我们可以直接通过网络将图片上传到平台,进行入库、识别、删除三个不同的操作。
2. base64库及b64encode函数的功能
base64库是用于文件编码和解码的python库,常在网络上传输文件信息时使用,只有经过编码等处理过的文件方可满足特定的传输协议。
base64库b64encode()函数可以实现对文件的编码,将其转换为二进制形式。
- ocation = 'upload_img/image_1999.jpg' # 图片路径
-
- f3 = open(location, 'rb') # 打开该路径下的图片
-
- img3 = base64.b64encode(f3.read()) # 对读入的图片文件进行编码
其中,location是一张指定路径下的图片,f3是个变量,存储打开后的图片,img3也是个变量,用于存储编码后的该图片文件。
3. requests库及post()函数的功能
requests库是基于Python开发的HTTP 库,可以用来与web服务器通信。
requests库post()函数可以向网页发送数据
- request_url = request_url + "?access_token=" + access_token # 入库请求链接添加token值(类似验证码)
- params3 = {"brief":details,"image":img3} # 用变量params3存储菜品信息和菜品照片。
- headers = {'content-type': 'application/x-www-form-urlencoded'} # 请求头
- response3 = requests.post(request_url, data=params3, headers=headers) # 获取响应
其中,response3是个变量,用于存储网页返回的数据。request_url是网址,data和headers分别是要发送的数据和请求头。又如,
- a_2333 = {"dis_2333":"100"}
-
- response_2333 = requests.post('http://192.168.100.18:8089/input3',a_2333,1000)
其中,a_2333是一个字典数据,1000是指连接超时时间,这里,我们向“http://192.168.100.18:8089/input3”这个web地址发送了a_2333这个字典里的数据,获取到反馈信息后存储到变量response_2333中。
动手实践
任务描述1:上传菜品
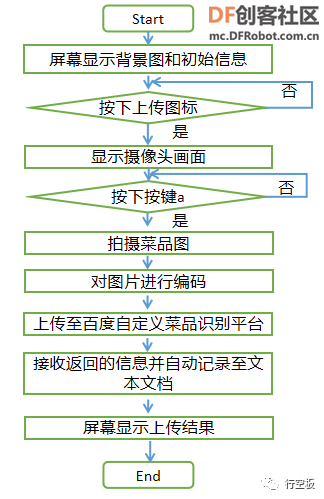
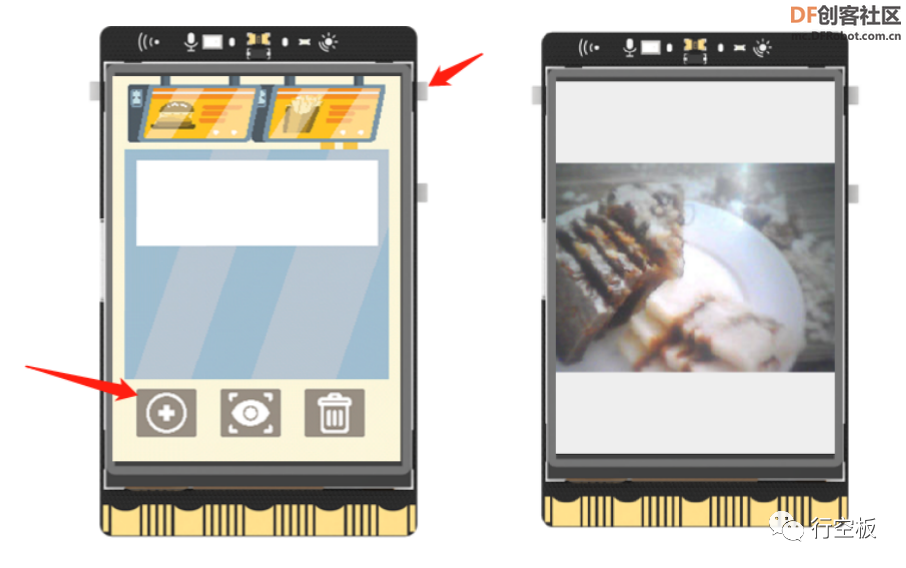
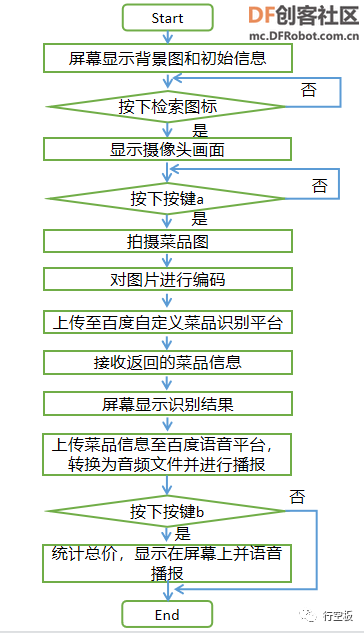
在屏幕上显示无人餐厅的背景图以及“上传”、“识别”、“删除”三个按钮图标,并实现点击“上传”图标后拍摄菜品图片,结合终端输入的菜品信息,一起上传至百度图像识别的自定义菜品识别平台。
1、硬件搭建
STEP1:通过USB连接线将行空板连接到计算机
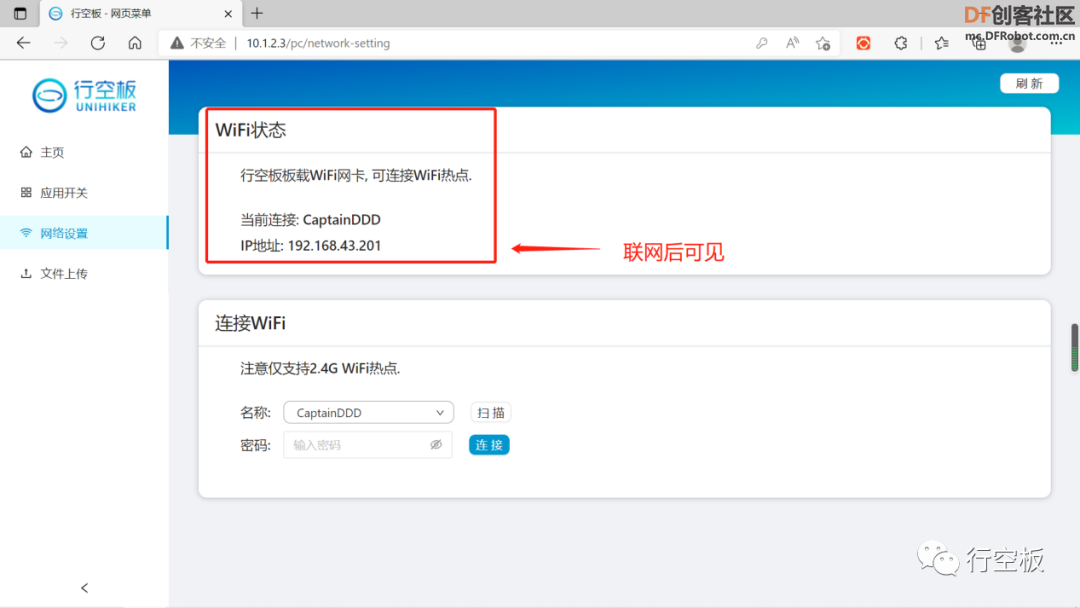
STEP2:配置网络
STEP3:通过USB扩展坞将USB摄像头与USB小喇叭连接至行空板,并通过外接Micro USB线给扩展坞额外供电,避免电量不足。
2、分析设计
在这个任务中,我们将制作菜单。首先,准备好菜品,然后拍摄菜品图片,结合相应的菜品信息,一起上传至百度自定义菜品识别的平台上,并且接收其返回的图片签名等信息,自动记录到txt文本文档中,同时,在屏幕上显示上传结果。
3、程序编写
STEP1:创建与保存项目文件
启动Mind+,另存项目并命名为“016、无人餐厅”。
Tips:需使用Mind+1.7.2 RC3.0及以上版本。
STEP2:远程连接行空板
STEP3:在行空板中创建一个新的文件夹,并命名为“无人餐厅”
STEP4:创建与保存python文件
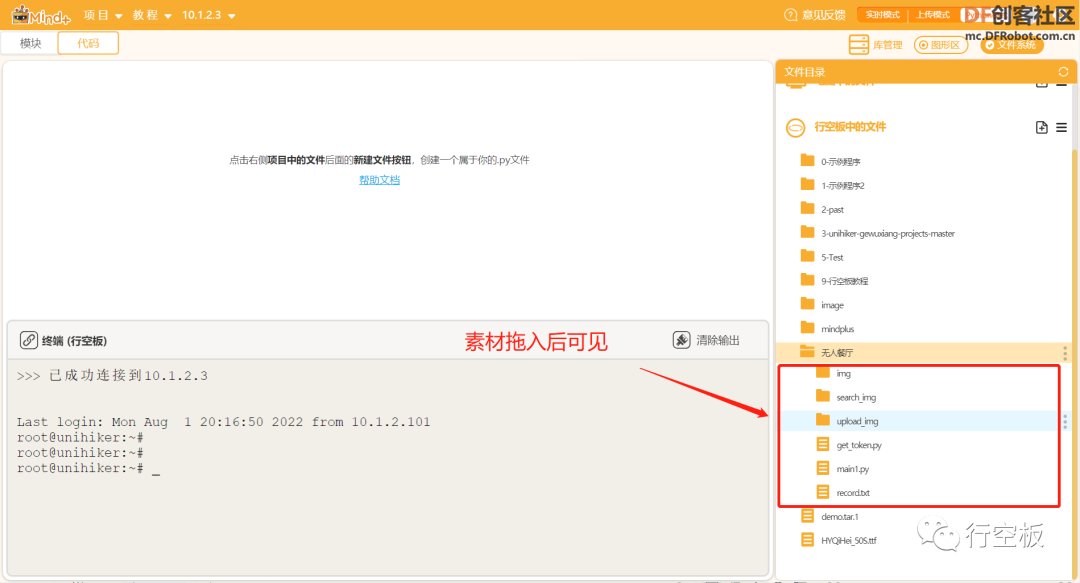
在板子的“无人餐厅”文件夹下创建一个Python程序文件“main1.py”,双击打开。
STEP5:导入素材
在“无人餐厅”文件夹下导入各个素材,包括三个图片文件夹、一个文本文档以及一个Python文件。
其中,img是用于存放屏幕背景图以及上传、识别、删除三个图标的文件夹;
upload_img和search_img分别是用来存放上传和识别菜品时拍照所得图片的文件夹;
record.txt是用来记录菜品信息的文本文档;
get_token.py是用于获取access_token的python文件。
Tips:素材下载链接可见附录1。
Step6:程序编写
(1)导入所需功能库
在这个任务中,我们需要使用requests库来向百度自定义菜品识别平台发送请求,base64库来编码图片文件,json库来解析百度平台返回的数据,get_token模块来获取鉴权认证码,opencv库进行拍照,因此我们需要先导入它们;同时,我们还需要导入unihiker库的GUI模块和Pinpong库以便在屏幕上显示信息和使用板载按键。
之后我们初始化行空板并实例化一个gui对象。
- import requests # 导入request模块
- import base64 # 导入base64库
- import json # 导入json解析库
- import get_token # 导入get_token模块
- import time # 导入时间库
-
- from unihiker import GUI
- from pinpong.board import Board,Pin
- from pinpong.extension.unihiker import *
- import cv2 # 导入opencv库
-
- Board().begin() # 初始化,选择板型和端口号,不输入则进行自动识别
- gui = GUI() # 实例化gui对象
(2)定义拍照函数
在制作菜单时,我们需要提供菜品的图片以及其他信息给百度平台。因此在这里,我们先定义一个拍照函数,以便通过摄像头拍摄的方式得到菜品图片。在拍照时,可通过按下板载按键a保存图片。
- '''拍照'''
- def get_photo(image_address): # 定义拍照函数(上传参数--图片保存地址)
- cap = cv2.VideoCapture(0) # 创建一个 VideoCapture 对象, 构建视频抓捕器, 0表示需要启动的摄像头
- cap.set(cv2.CAP_PROP_BUFFERSIZE, 1) # Set the camera buffer to 1, to decrease the latency. # 设置1帧的缓冲,减少延迟避免卡顿
- cv2.namedWindow('window',cv2.WND_PROP_FULLSCREEN) # Set the windows to be full screen. # 构建一个窗口,名称为window,属性为可以全屏
- cv2.setWindowProperty('window',cv2.WND_PROP_FULLSCREEN,cv2.WINDOW_FULLSCREEN) # Set the windows to be full screen. # 设置窗口全屏
- while (cap.isOpened()): # 循环读取每一帧
- ret, frame = cap.read() # 从摄像头读取图片 , ret存储布尔值,frame存储图像
- #frame = cv2.flip(frame, 1, dst=None) # 镜像
- cv2.imshow("window", frame) # 窗口显示,显示名为 window
- # 保持画面的持续。
- k = cv2.waitKey(1) # 每帧数据延时1ms,延时不能为 0,否则读取的结果会是静态帧
- if k == 27: # 通过esc键退出摄像
- cv2.destroyAllWindows() # 删除建立的全部窗口
- break
- elif (button_a.is_pressed()): # 通过a键保存图片,并退出。
- cv2.imwrite(image_address, frame) # 将图像保存为图片
- print("image saved")
- cv2.destroyAllWindows() # 删除建立的全部窗口
- break
- time.sleep(0.1)
- cap.release() # 关闭摄像头
(3) 定义记录菜品信息函数
由于在上传菜品至百度平台后会有一个独一无二的图片签名的参数返回,因此,在这里,我们可以将它结合相应的菜品信息一起自动记录下来,以便在后续需要调整或删除菜品时能有参照。
- # 将菜品信息写入文本文档
- def dish_record(id,name,price): # 定义记录菜品函数,传入图片签名编号id、菜名name、价格price
- f = open('record.txt',mode='a+') # 以可读可追加数据的模式打开txt文本文档(a+可读可追加)
- f.write('编号: '+ id + ' 菜名: '+ name +' 价格: '+ price + '\n') # write 写入数据
- f.close() # 关闭txt文本文档
(4) 定义上传入库功能函数
之后,我们定义上传菜品入库功能。在这个函数中我们进行四步操作,首先第一步,我们通过调用拍照函数,得到一张菜品的图片,并对它进行编码以便后续能够上传至百度平台;接着第二步,我们设定从终端获取输入的菜品名称和菜品价格,将其存储到变量details中并结合菜品照片一起存储到变量params3中;随后第三步,通过百度平台指定的入库请求链接将第二步的菜品信息上传至平台;最后第四步,我们接收百度平台的响应反馈,识别响应结果并记录下图片签名,设定在上传错误时终端显示错误码,同时返回变量xhl的值来表示上传成功与否。
- # 上传入库功能
- def post_pic(location):
- # 二进制方式打开图片文件
- get_photo(location) # 调用拍照函数,同时传入要保存的图片名称
- f3 = open(location, 'rb') # 打开拍照图片
- img3 = base64.b64encode(f3.read()) # 对读入的图片文件进行编码
- dish_name = input("请输入菜名:") # 终端输入菜名
- dish_price= input("请输入价格:") # 终端输入价格
- #details = "{"菜名":"水晶虾仁":"价格":"300"}"
- #details = str({'菜名:'+dish_name,'价格:'+dish_price})
- details = "{"菜名":"" + dish_name + "":"价格":"" + dish_price + ""}" # 用变量details存储记录菜名和价格
- print(details)
- params3 = {"brief":details,"image":img3} # 用变量params3存储菜品信息和菜品照片
- request_url = "https://aip.baidubce.com/rest/2.0/image-classify/v1/realtime_search/dish/add" # 百度云平台入库请求链接
- request_url = request_url + "?access_token=" + access_token # 入库请求链接添加token值(类似验证码)
- headers = {'content-type': 'application/x-www-form-urlencoded'} # 请求头
- response3 = requests.post(request_url, data=params3, headers=headers)#发送数据,获取响应
- '''若入库成功设置xhl=1,失败设置xhl=0,并打印错误信息。'''
- if response3: # 如果获取到响应
- try: # 捕获异常
- print (response3.json()) # 打印json格式的响应
- result_json = json.loads(response3.text) # 识别响应结果中的json格式
- print(result_json['error_code']) # 打印json格式结果中的错误码,有错误时才会打印,没错误时进入except
- xhl = 0 # 设置xhl=0
- except: # 处理异常
- result_cont_sign = result_json['cont_sign'] # 存储图片签名
- print(result_cont_sign)
- dish_record(result_cont_sign,dish_name,dish_price) # 将图片签名(编号)、菜名、价格记录到record.txt文本文档中
- xhl = 1 # 设置xhl=1
- return xhl # 函数返回xhl,判断是否入库成功
(5) 定义屏幕显示函数
接着,我们再定义一个函数,以便在屏幕上显示上传的结果。
- # 线程:屏幕显示上传结果
- def screen_show1():
- if xhlhahaha == 1: # 如果入库成功,窗口内显示“上传成功”
- print("上传成功")
- text.config(text="上传成功")
- time.sleep(3)
- text.config(text="")
- else:
- print("上传失败")
- text.config(text="上传失败")
- time.sleep(3)
- text.config(text="")
- time.sleep(0.2)
(6) 定义上传按钮的回调函数
由于我们想要按下上传按钮来进行拍照上传菜品,因此,我们可通过定义一个回调函数,功能设定好后,再赋给上传图标。而在回调函数中,我们需要调用上传图片入库函数并将屏幕显示功能作为一个线程启动。
- # 上传按钮
- def add_func(location): # 定义上传按钮的功能
- print("按下板载按键a拍照")
- global xhlhahaha,t1
- xhlhahaha = post_pic(location) # 调用上传图片入库函数
- t1 = gui.start_thread(screen_show1) # 启动屏幕显示结果的线程
(7) 设定参数并显示屏幕
最后,我们设定好用于生成access_token的图像识别的cAPI_KEY和cSECRET_KEY两个接口密钥参数,设定好上传和识别时保存的图片名称和路径,设定好初始的总价,在屏幕上显示背景图和三个图标,并绘制一个矩形框以显示文字,同时,通过循环的方式保持屏幕长久显示。
Tips:接口参数获取方式可参考附录2。
- '''=-='''
- cAPI_KEY = ''
- cSECRET_KEY = ''
- access_token = get_token.fetch_token(cAPI_KEY,cSECRET_KEY) # 获取access_token用于鉴权认证
- # (针对HTTP API调用者,百度AIP开放平台使用OAuth2.0授权调用开放API,调用API时必须在URL中带上access_token参数)
- location_upload = 'upload_img/image_1999.jpg' # 上传拍照时保存的图片
- location_search = 'search_img/image_1900.jpg' # 识别拍照时保存的图片
- #location_delete = 'delete_img/image_xhl.jpg'
- price = 0 # 定义初始价格为0
- # 显示背景图片
- img_background = gui.draw_image(w=240, h=320, image='img/background.png') # 显示背景图
- img_add = gui.draw_image(x=20,y=260,w=50,h=40,image='img/add.png',onclick=lambda:add_func(location_upload)) # 显示上传图标
- img_inquire = gui.draw_image(x=90,y=260,w=50,h=40,image='img/inquire.png') # 显示识别图标
- img_delete = gui.draw_image(x=160,y=260,w=50,h=40,image='img/delete.png') # 显示删除图标
- gui.fill_rect(x=20, y=70, w=200, h=70, color="white") # 绘制白色矩形
- text = gui.draw_text(x=30, y=70, text='', font_size=8) # 显示内容
-
- while True: # 循环,保存窗口
- time.sleep(1)
Tips:完整示例程序如下:
- '''上传 点击上传图标,按下板载按键a拍照后,可通过终端输入菜名和价格,
- 之后会自动追加记录cont_sign、菜名、价格到txt文档,程序为unihiker版'''
- import requests # 导入request模块
- import base64 # 导入base64库
- import json # 导入json解析库
- import get_token # 导入get_token模块
- import time # 导入时间库
-
- from unihiker import GUI
- from pinpong.board import Board,Pin
- from pinpong.extension.unihiker import *
- import cv2 # 导入cv库
-
- Board().begin() # 初始化,选择板型和端口号,不输入则进行自动识别
- gui = GUI() # 实例化gui对象
-
-
- '''拍照'''
- def get_photo(image_address): # 定义拍照函数(上传参数--图片保存地址)
- cap = cv2.VideoCapture(0) # 创建一个 VideoCapture 对象, 构建视频抓捕器, 0表示需要启动的摄像头
- cap.set(cv2.CAP_PROP_BUFFERSIZE, 1) # Set the camera buffer to 1, to decrease the latency. # 设置1帧的缓冲,减少延迟避免卡顿
- cv2.namedWindow('window',cv2.WND_PROP_FULLSCREEN) # Set the windows to be full screen. # 构建一个窗口,名称为window,属性为可以全屏
- cv2.setWindowProperty('window', cv2.WND_PROP_FULLSCREEN, cv2.WINDOW_FULLSCREEN) # Set the windows to be full screen. # 设置窗口全屏
- while (cap.isOpened()): # 循环读取每一帧
- ret, frame = cap.read() # 从摄像头读取图片 , ret存储布尔值,frame存储图像
- #frame = cv2.flip(frame, 1, dst=None) # 镜像
- cv2.imshow("window", frame) # 窗口显示,显示名为 window
- # 保持画面的持续。
- k = cv2.waitKey(1) # 每帧数据延时1ms,延时不能为 0,否则读取的结果会是静态帧
- if k == 27: # 通过esc键退出摄像
- cv2.destroyAllWindows() # 删除建立的全部窗口
- break
- elif (button_a.is_pressed()): # 通过a键保存图片,并退出。
- cv2.imwrite(image_address, frame) # 将图像保存为图片
- print("image saved")
- cv2.destroyAllWindows() # 删除建立的全部窗口
- break
- time.sleep(0.1)
- cap.release() # 关闭摄像头
-
- '''
- 菜品识别入库
- '''
- # 将菜品信息写入文本文档
- def dish_record(id,name,price): # 定义记录菜品函数,传入图片签名编号id、菜名name、价格price
- f = open('record.txt',mode='a+') # 以可读可追加数据的模式打开txt文本文档(a+可读可追加)
- f.write('编号: '+ id + ' 菜名: '+ name +' 价格: '+ price + '\n') # write 写入数据
- f.close() # 关闭txt文本文档
-
- # 上传入库功能
- def post_pic(location):
- # 二进制方式打开图片文件
- get_photo(location) # 调用拍照函数,同时传入要保存的图片名称
- f3 = open(location, 'rb') # 打开拍照图片
- img3 = base64.b64encode(f3.read()) # 对读入的图片文件进行编码
- dish_name = input("请输入菜名:") # 终端输入菜名
- dish_price= input("请输入价格:") # 终端输入价格
- #details = "{"菜名":"水晶虾仁":"价格":"300"}"
- #details = str({'菜名:'+dish_name,'价格:'+dish_price})
- details = "{"菜名":"" + dish_name + "":"价格":"" + dish_price + ""}" # 用变量details存储记录菜名和价格
- print(details)
- params3 = {"brief":details,"image":img3} # 用变量params3存储菜品信息和菜品照片
- request_url = "https://aip.baidubce.com/rest/2.0/image-classify/v1/realtime_search/dish/add" # 百度云平台入库请求链接
- request_url = request_url + "?access_token=" + access_token # 入库请求链接添加token值(类似验证码)
- headers = {'content-type': 'application/x-www-form-urlencoded'} # 请求头
- response3 = requests.post(request_url, data=params3, headers=headers) # 获取响应
- '''若入库成功设置xhl=1,失败设置xhl=0,并打印错误信息。'''
- if response3: # 如果获取到响应
- try: # 捕获异常
- print (response3.json()) # 打印json格式的响应
- result_json = json.loads(response3.text) # 识别响应结果中的json格式
- print(result_json['error_code']) # 打印json格式结果中的错误码,有错误时才会打印,没错误时进入except
- xhl = 0 # 设置xhl=0
- except: # 处理异常
- result_cont_sign = result_json['cont_sign'] # 存储图片签名
- print(result_cont_sign)
- dish_record(result_cont_sign,dish_name,dish_price) # 将图片签名(编号)、菜名、价格记录到record.txt文本文档中
- xhl = 1 # 设置xhl=1
- return xhl # 函数返回xhl,判断是否入库成功
-
- # 线程:屏幕显示上传结果
- def screen_show1():
- if xhlhahaha == 1: # 如果入库成功,窗口内显示“上传成功”
- print("上传成功")
- text.config(text="上传成功")
- time.sleep(3)
- text.config(text="")
- else:
- print("上传失败")
- text.config(text="上传失败")
- time.sleep(3)
- text.config(text="")
- time.sleep(0.2)
-
-
- # 上传按钮
- def add_func(location): # 定义上传按钮的功能
- print("按下板载按键a拍照")
- global xhlhahaha,t1
- xhlhahaha = post_pic(location) # 调用上传图片入库函数
- t1 = gui.start_thread(screen_show1) # 启动屏幕显示结果的线程
-
-
- '''=-='''
- cAPI_KEY = ''
- cSECRET_KEY = ''
- access_token = get_token.fetch_token(cAPI_KEY,cSECRET_KEY) # 获取access_token用于鉴权认证
- # (针对HTTP API调用者,百度AIP开放平台使用OAuth2.0授权调用开放API,调用API时必须在URL中带上access_token参数)
- location_upload = 'upload_img/image_1999.jpg' # 上传拍照时保存的图片
- location_search = 'search_img/image_1900.jpg' # 识别拍照时保存的图片
- #location_delete = 'delete_img/image_xhl.jpg'
- price = 0 # 定义初始价格为0
- # 显示背景图片
- img_background = gui.draw_image(w=240, h=320, image='img/background.png') # 显示背景图
- img_add = gui.draw_image(x=20,y=260,w=50,h=40,image='img/add.png',onclick=lambda:add_func(location_upload)) # 显示上传图标
- img_inquire = gui.draw_image(x=90,y=260,w=50,h=40,image='img/inquire.png')#显示识别图标
- img_delete = gui.draw_image(x=160,y=260,w=50,h=40,image='img/delete.png')#显示删除图标
- gui.fill_rect(x=20, y=70, w=200, h=70, color="white") # 绘制白色矩形
- text = gui.draw_text(x=30, y=70, text='', font_size=8) # 显示内容
-
- while True: # 循环,保存窗口
- time.sleep(1)
Tips:须在程序中“cAPI_KEY”、“cSECRET_KEY”处填入对应图像识别的API_KEY、SECRET_KEY两个参数。获取方式可参考附录2。
4、程序运行
STEP1:运行程序
STEP2:拍照上传
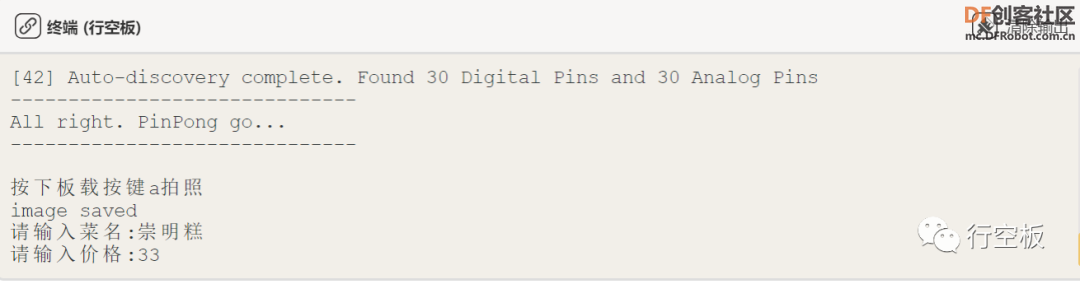
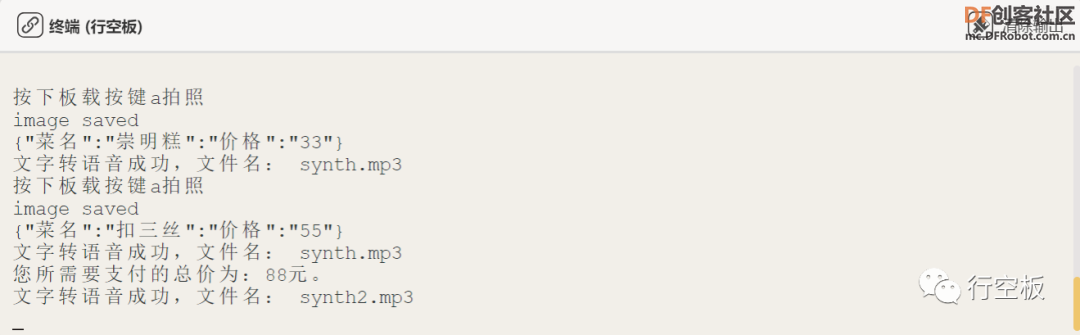
点击屏幕上的上传图标,等待摄像头开启后,将其对着准备好的菜品“崇明糕”,调整好位置后按下板载按键a保存图片。
Tips:菜品图片素材可见附录1链接
STEP3:终端输入菜名和价格
结束拍照后,在终端弹出的提示信息中输入菜名和价格,回车键确认
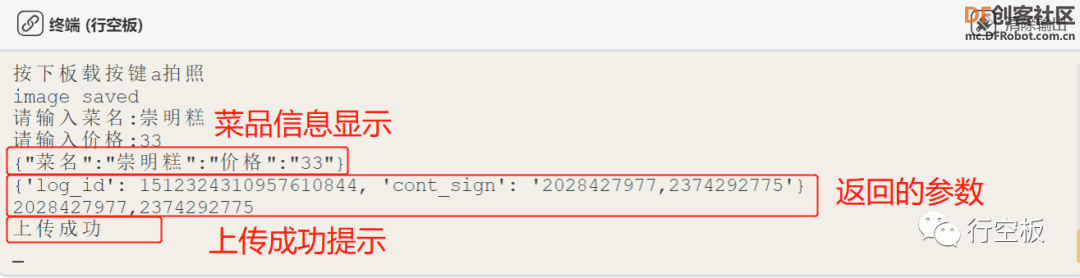
STEP4:观察屏幕和终端反馈
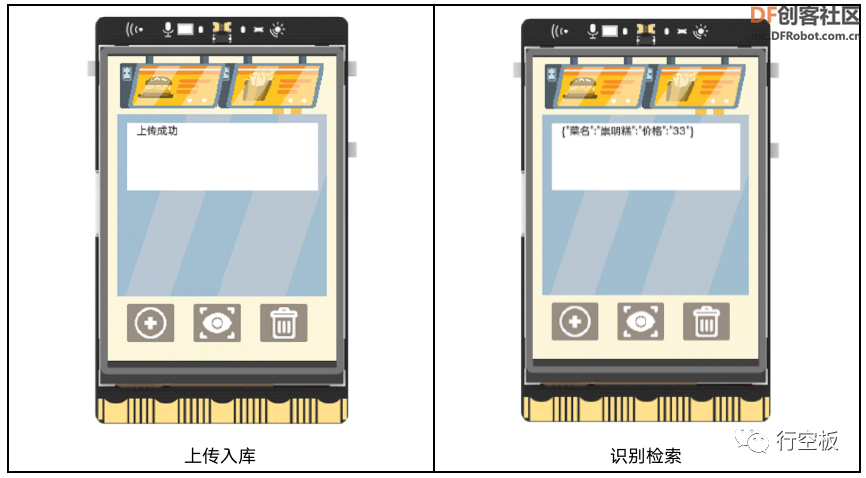
之后,观察行空板的屏幕,可以看到有“上传成功”的显示信息,同时也可以在终端看到相应的提示。
STEP5:多次上传
之后,我们可重复上述步骤,挑选素材图片1-5中的每个菜品中的一张图片进行上传入库。
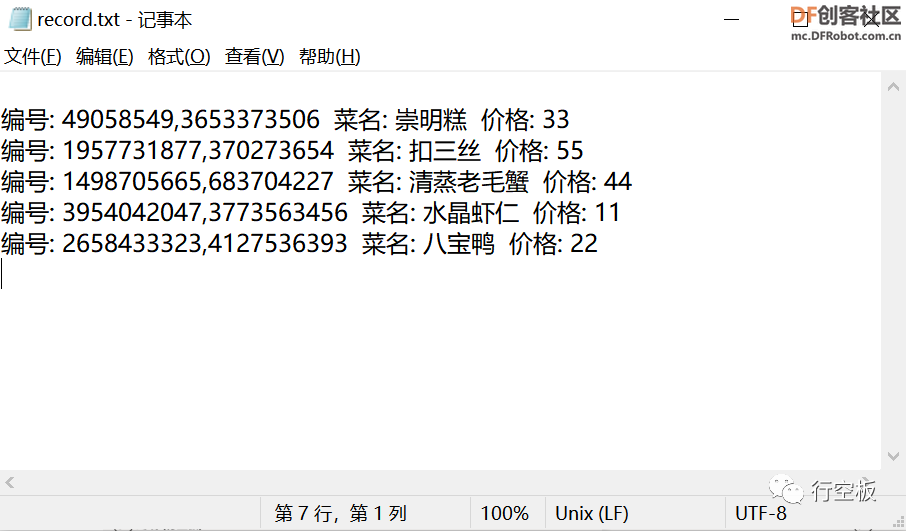
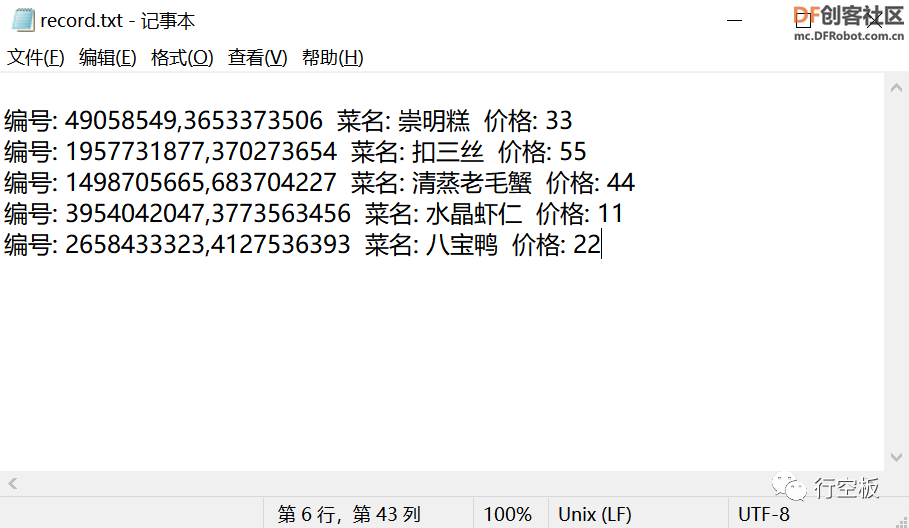
STEP6:查看record.txt文档
最后,打开record.txt文本文档,我们可以发现上传入库的菜品已被记录下来。
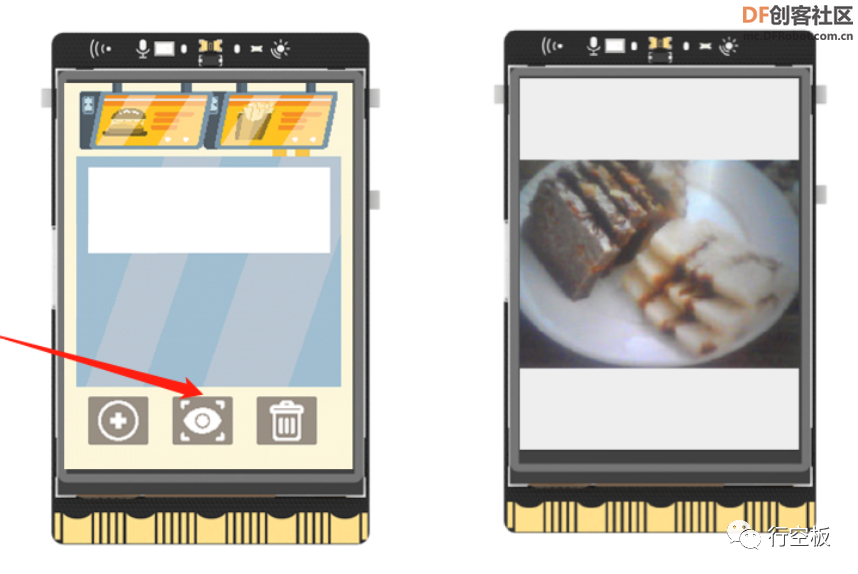
任务描述2:识别菜品
在上述任务1的基础上,新增识别菜品的功能。在点击“识别”图标后拍摄菜品图片,之后对该图进行识别,将结果显示在屏幕上并进行语音播报;同时,在选择多个菜品进行识别后,按下板载按键b,也能得到总价的计算结果。
1、分析设计
在这个任务中,我们将识别菜品。首先,准备好要识别的菜品,然后拍摄该菜品的图片,将图片上传至百度自定义菜品识别平台,并接收返回的菜品信息,最后将返回的结果显示在屏幕上的同时也通过语音进行播报。
2、程序编写
STEP1:创建与保存项目文件
在板子的“无人餐厅”文件夹下再创建一个Python程序文件“main2.py”,双击打开。
Step2:程序编写
(1)导入所需功能库
这里,由于我们需要使用百度的语音合成功能,因此我们需补充导入百度的语音库,同时,为了便于对音频文件进行处理以及播放音频,我们还将导入os库和unihiker库的Audio模块并实例化一个音频对象。
- from aip import AipSpeech # 导入百度语音库
- import os # 导入系统库
- from unihiker import GUI,Audio
- audio = Audio() # 实例化音频对象
(2)定义语音合成函数
为了便于在后续能够对识别到的菜品进行语音播报信息,这里,我们先定义一个语音合成的函数,将菜品信息转换为音频。
- # 定义文字转语音函数(语音合成),传入字符串和音频文件名,将字符串转语音后
- def text_to_audio(synth_file,res_str):
- client = AipSpeech (APP_ID, API_KEY, SECRET_KEY) # 创建客户端对象,连接百度语音平台
- try:
- os.close(synth_file) # 关闭语音文件
- os.remove(synth_file) # 移除语音文件(先删除一下文件,以防重名)
- except:
- pass # 如果文件不存在直接跳过
- synth_context = client.synthesis(res_str, "zh", 1, {
- "vol": 5,
- "spd": 5,
- "pit": 3,
- "per": 0
- }) # 将res_str合成为语音,并存储到synth_context
- # synthesis参数: 文本,语言zh(中文),1为pc端,语音{"vol":音量,
- # "spd":语速,"pit":语调,"per":声道(0:女,1:男,2:逍遥音,4:小萝莉)}
- f=open(synth_file, "wb")
- f.write(synth_context) # 将语音内容写入语音文件
- f.close() # 关闭语音文件
- print("文字转语音成功,文件名:",synth_file)
- return synth_file # 返回语音文件
(3)定义菜品识别功能函数
之后,我们定义菜品识别的功能。和上传时步骤相似,首先第一步,我们通过调用拍照函数,得到一张菜品的图片,并对它进行编码以便后续能够上传至百度平台;接着第二步,通过百度平台指定的识别请求链接将菜品图片发送至平台;随后第三步,接收百度平台的响应反馈,识别响应结果中的菜品信息并返回;最后第四步,通过调用语音合成功能将菜品信息转换成音频并将结果中的价格单独取出,以便进行总价的计算。
- # 检索功能
- def search_pic(location):
- get_photo(location) # 调用拍照函数
- request_url = "https://aip.baidubce.com/rest/2.0/image-classify/v1/realtime_search/dish/search" # 百度云平台识别请求链接
- f = open(location, 'rb') # 二进制方式打开图片文件
- img = base64.b64encode(f.read()) # 图片编码
- params = {"image":img} # 用变量params存储菜品照片
- request_url = request_url + "?access_token=" + access_token # 识别请求链接添加token值(类似验证码)
- headers = {'content-type': 'application/x-www-form-urlencoded'} # 请求头
- response = requests.post(request_url, data=params, headers=headers) # 获取响应
- '''如果有响应,解析json字符串,函数返回菜品详细信息。'''
- if response: # 如果获取到响应
- result_json = json.loads(response.text) # 识别响应结果中的json格式
- for data in result_json[u'result']:
- xhl = data[u'dishes'][0][u'brief'] # 存储识别结果数组中的菜品信息 # {"菜名":"崇明糕":"价格":"33"}
- xh = xhl.split('"',8) # 用引号将xhl分成9份
- x = xh[7] # 取第8份:价格 # 33
- print(xhl) # 打印菜单
- D = str(xhl)+"元。"
- text_to_audio("synth.mp3",D) # 菜单文字转语音
- global price
- price = int(price) + int(x) # 累加价格
- return xhl
(4)定义屏幕显示函数
接着,我们再定义一个函数,以便在屏幕上显示识别的结果,同时我们也在这里用语音播报菜品信息。
- # 线程:屏幕显示文字并播放语音
- def screen_show2():
- if xhl2333: # 如果有菜品信息,屏幕显示3秒后清空
- text.config(text=xhl2333)
- time.sleep(3) # 延时3秒
- text.config(text='')
- audio.play('synth.mp3') # 播放音频文件
- time.sleep(0.2)
(5)定义识别按钮被点击后的功能
由于我们想要按下识别按钮来拍摄菜品照片以进行识别并将结果显示在屏幕上,因此,在这里,我们先定义一个回调函数,来表示识别按钮被点击后的操作,以便在后续调用。
- def inquire_func(location): # 定义识别按钮的功能
- print("按下板载按键a拍照")
- global xhl2333,t2
- xhl2333 = search_pic(location) # 调用识别检索函数
- t2 = gui.start_thread(screen_show2) # 启动线程2
(6)参数设置
由于使用百度语音合成功能时需要APP_ID 、API_KEY以及SECRET_KEY三个参数方可连接平台,因此,在这里,我们先设定好这三个参数值。
- APP_ID = "" # 连接百度语音平台的APP_ID(语音合成用)
- API_KEY='' # 连接百度语音平台的API_Key
- SECRET_KEY='' # 连接百度语音平台的Sercet_Key
(7)将识别检索的功能函数赋给识别图标
之后,为了能实现点击识别图标进行菜品识别,这里,我们给图标添加上被点击时触发的回调函数。
- img_inquire = gui.draw_image(x=90,y=260,w=50,h=40,image='img/inquire.png',onclick=lambda:inquire_func(location_search)) # 显示识别图标
(8)计算总价
最后,我们在循环中添加对板载按键b的监测,实现按下后计算总价的功能呢。
- while True:
- if button_b.is_pressed() == 1: # 如果按钮b被按下
- DDD = "您所需要支付的总价为:"+str(price)+"元。"
- print(DDD)
- text.config(text=DDD) # 显示3秒后清空
- time.sleep(3)
- text.config(text="")
- text_to_audio("synth2.mp3",DDD) # 文字转语音
- audio.play('synth2.mp3') # 播报总价
- price = 0 # 清零总价
- time.sleep(0.2)
Tips:完整示例程序如下:
-
- '''上传 点击上传图标,按下板载按键a拍照后,可通过终端输入菜名和价格,之后会自动追加记录cont_sign、菜名、价格到txt文档
- 识别,点击识别图标,按下板载按键a拍照后,显示并播报菜品信息,计算总价(按下板载按键b计算总价),程序为unihiker版'''
- import requests # 导入request模块
- import base64 # 导入base64库
- import json # 导入json解析库
- import get_token # 导入get_token模块
- import time # 导入时间库
- from aip import AipSpeech # 导入百度语音库
-
- from unihiker import GUI,Audio
- from pinpong.board import Board,Pin
- from pinpong.extension.unihiker import *
- import cv2 # 导入opencv库
- import os # 导入系统库
-
-
- Board().begin() # 初始化,选择板型和端口号,不输入端口号则进行自动识别
- audio = Audio() # 实例化音频对象
- gui = GUI() # 实例化gui对象
-
-
- '''拍照'''
- def get_photo(image_address): # 定义拍照函数(上传参数--图片保存地址)
- cap = cv2.VideoCapture(0) # 创建一个 VideoCapture 对象, 构建视频抓捕器, 0表示需要启动的摄像头
- cap.set(cv2.CAP_PROP_BUFFERSIZE, 1) # Set the camera buffer to 1, to decrease the latency. # 设置1帧的缓冲,减少延迟避免卡顿
- cv2.namedWindow('window',cv2.WND_PROP_FULLSCREEN) # Set the windows to be full screen. # 构建一个窗口,名称为window,属性为可以全屏
- cv2.setWindowProperty('window', cv2.WND_PROP_FULLSCREEN, cv2.WINDOW_FULLSCREEN) # Set the windows to be full screen. # 设置窗口全屏
- while (cap.isOpened()): # 循环读取每一帧
- ret, frame = cap.read() # 从摄像头读取图片 , ret存储布尔值,frame存储图像
- #frame = cv2.flip(frame, 1, dst=None) # 镜像
- cv2.imshow("window", frame) # 窗口显示,显示名为 window
- # 保持画面的持续。
- k = cv2.waitKey(1) # 每帧数据延时1ms,延时不能为 0,否则读取的结果会是静态帧
- if k == 27: # 通过esc键退出摄像
- cv2.destroyAllWindows() # 删除建立的全部窗口
- break
- elif (button_a.is_pressed()): # 通过a键保存图片,并退出。
- cv2.imwrite(image_address, frame) # 将图像保存为图片
- print("image saved")
- cv2.destroyAllWindows() # 删除建立的全部窗口
- break
- time.sleep(0.1)
- cap.release() # 关闭摄像头
-
-
- '''
- 菜品识别入库
- '''
- # 将菜品信息写入文本文档
- def dish_record(id,name,price): # 定义记录菜品函数,传入图片签名编号id、菜名name、价格price
- f = open('record.txt',mode='a+') # 以可读可追加数据的模式打开txt文本文档(a+可读可追加)
- f.write('编号: '+ id + ' 菜名: '+ name +' 价格: '+ price + '\n') # write 写入数据
- f.close() # 关闭txt文本文档
-
- # 上传入库功能
- def post_pic(location):
- # 二进制方式打开图片文件
- get_photo(location) # 调用拍照函数,同时传入要保存的图片名称
- f3 = open(location, 'rb') # 打开拍照图片
- img3 = base64.b64encode(f3.read()) # 对读入的图片文件进行编码
- dish_name = input("请输入菜名:") # 终端输入菜名
- dish_price= input("请输入价格:") # 终端输入价格
- #details = "{"菜名":"水晶虾仁":"价格":"300"}"
- #details = str({'菜名:'+dish_name,'价格:'+dish_price})
- details = "{"菜名":"" + dish_name + "":"价格":"" + dish_price + ""}" # 用变量details存储记录菜名和价格
- print(details)
- params3 = {"brief":details,"image":img3} # 用变量params3存储菜品信息和菜品照片
- request_url = "https://aip.baidubce.com/rest/2.0/image-classify/v1/realtime_search/dish/add" # 百度云平台入库请求链接
- request_url = request_url + "?access_token=" + access_token # 入库请求链接添加token值(类似验证码)
- headers = {'content-type': 'application/x-www-form-urlencoded'} # 请求头
- response3 = requests.post(request_url, data=params3, headers=headers) # 获取响应
- '''若入库成功设置xhl=1,失败设置xhl=0,并打印错误信息。'''
- if response3: # 如果获取到响应
- try: # 捕获异常
- print (response3.json()) # 打印json格式的响应
- result_json = json.loads(response3.text) # 识别响应结果中的json格式
- print(result_json['error_code']) # 打印json格式结果中的错误码,有错误时才会打印,没错误时进入except
- xhl = 0 # 设置xhl=0
- except: # 处理异常
- result_cont_sign = result_json['cont_sign'] # 存储图片签名
- print(result_cont_sign)
- dish_record(result_cont_sign,dish_name,dish_price) # 将图片签名(编号)、菜名、价格记录到record.txt文本文档中
- xhl = 1 # 设置xhl=1
- return xhl # 函数返回xhl,判断是否入库成功
-
- # 线程:屏幕显示上传结果
- def screen_show1():
- if xhlhahaha == 1: # 如果入库成功,窗口内显示“上传成功”
- print("上传成功")
- text.config(text="上传成功")
- time.sleep(3)
- text.config(text="")
- else:
- print("上传失败")
- text.config(text="上传失败")
- time.sleep(3)
- text.config(text="")
- time.sleep(0.2)
-
-
- # 上传按钮
- def add_func(location): # 定义上传按钮的功能
- print("按下板载按键a拍照")
- global xhlhahaha,t1
- xhlhahaha = post_pic(location) # 调用上传图片入库函数
- t1 = gui.start_thread(screen_show1) # 启动屏幕显示结果的线程
-
-
- '''
- 菜品识别检索
- '''
- # 定义文字转语音函数(语音合成),传入字符串和音频文件名,将字符串转语音后
- def text_to_audio(synth_file,res_str):
- client = AipSpeech (APP_ID, API_KEY, SECRET_KEY) # 创建客户端对象,连接百度语音平台
- try:
- os.close(synth_file) # 关闭语音文件
- os.remove(synth_file) # 移除语音文件(先删除一下文件,以防重名)
- except:
- pass # 如果文件不存在直接跳过
- synth_context = client.synthesis(res_str, "zh", 1, {
- "vol": 5,
- "spd": 5,
- "pit": 3,
- "per": 0
- }) # 将res_str合成为语音,并存储到synth_context
- # synthesis参数: 文本,语言zh(中文),1为pc端,语音{"vol":音量,
- # "spd":语速,"pit":语调,"per":声道(0:女,1:男,2:逍遥音,4:小萝莉)}
- f=open(synth_file, "wb")
- f.write(synth_context) # 将语音内容写入语音文件
- f.close() # 关闭语音文件
- print("文字转语音成功,文件名:",synth_file)
- return synth_file # 返回语音文件
-
- # 识别检索功能
- def search_pic(location):
- get_photo(location) # 调用拍照函数
- request_url = "https://aip.baidubce.com/rest/2.0/image-classify/v1/realtime_search/dish/search" # 百度云平台识别请求链接
- f = open(location, 'rb') # 二进制方式打开图片文件
- img = base64.b64encode(f.read()) # 图片编码
- params = {"image":img} # 用变量params存储菜品照片
- request_url = request_url + "?access_token=" + access_token # 识别请求链接添加token值(类似验证码)
- headers = {'content-type': 'application/x-www-form-urlencoded'} # 请求头
- response = requests.post(request_url, data=params, headers=headers) # 获取响应
- '''如果有响应,解析json字符串,函数返回菜品详细信息v。'''
- if response: # 如果获取到响应
- result_json = json.loads(response.text) # 识别响应结果中的json格式
- for data in result_json[u'result']:
- xhl = data[u'dishes'][0][u'brief'] # 存储识别结果数组中的菜品信息 # {"菜名":"崇明糕1号":"价格":"100"}
- xh = xhl.split('"',8) # 用引号将xhl分成9份
- x = xh[7] # 取第8份:价格 # 100
- print(xhl) # 打印菜单
- D = str(xhl)+"元。"
- text_to_audio("synth.mp3",D) # 菜单文字转语音
- global price
- price = int(price) + int(x) # 累加价格
- return xhl
-
- # 线程:屏幕显示文字并播放语音
- def screen_show2():
- if xhl2333: # 如果有菜品信息,屏幕显示3秒后清空
- text.config(text=xhl2333)
- time.sleep(3) # 延时3秒
- text.config(text='')
- audio.play('synth.mp3') # 播放音频文件
- time.sleep(0.2)
-
- # 检索
- def inquire_func(location): # 定义识别检索图标的功能
- print("按下板载按键a拍照")
- global xhl2333,t2
- xhl2333 = search_pic(location) # 调用识别检索函数
- t2 = gui.start_thread(screen_show2) # 启动线程2
-
-
- '''=-='''
- cAPI_KEY = ''
- cSECRET_KEY = ''
- access_token = get_token.fetch_token(cAPI_KEY,cSECRET_KEY) # 获取access_token用于鉴权认证
- APP_ID = "" # 连接百度语音平台的APP_ID(语音合成用)
- API_KEY='' # 连接百度语音平台的API_Key
- SECRET_KEY='' # 连接百度语音平台的Sercet_Key
- location_upload = 'upload_img/image_1999.jpg' # 上传拍照时保存的图片
- location_search = 'search_img/image_1900.jpg' # 识别拍照时保存的图片
- #location_delete = 'delete_img/image_xhl.jpg'
- price = 0 # 定义初始价格为0
- # 显示背景图片
- img_background = gui.draw_image(w=240, h=320, image='img/background.png') # 显示背景图
- img_add = gui.draw_image(x=20,y=260,w=50,h=40,image='img/add.png',onclick=lambda:add_func(location_upload)) # 显示上传图标
- img_inquire = gui.draw_image(x=90,y=260,w=50,h=40,image='img/inquire.png',onclick=lambda:inquire_func(location_search)) # 显示识别图标
- img_delete = gui.draw_image(x=160,y=260,w=50,h=40,image='img/delete.png') # 显示删除图标
- gui.fill_rect(x=20, y=70, w=200, h=70, color="white") # 绘制白色矩形
- text = gui.draw_text(x=30, y=70, text='', font_size=8) # 显示内容
-
-
- while True:
- if button_b.is_pressed() == 1: # 如果按钮b被按下
- DDD = "您所需要支付的总价为:"+str(price)+"元。"
- print(DDD)
- text.config(text=DDD) # 显示3秒后清空
- time.sleep(3)
- text.config(text="")
- text_to_audio("synth2.mp3",DDD) # 文字转语音
- audio.play('synth2.mp3') # 播报总价
- price = 0 # 清零总价
- time.sleep(0.2)
Tip1:须在程序中“cAPI_KEY”、“cSECRET_KEY”处填入对应图像识别的API_KEY、SECRET_KEY两个参数。获取方式可参考附录2。
Tip2:语音平台的APP_ID、API_KEY、SECRET_KEY三个参数同上节课。
3、程序运行
STEP1:运行程序
STEP2:拍照识别菜品
点击屏幕上的识别图标,等待摄像头开启后,将其对着准备好的菜品“崇明糕”,调整好位置后按下板载按键a保存图片。
STEP3:观察屏幕和终端反馈
之后,观察行空板的屏幕,可以看到有识别到的菜品信息显示,之后小喇叭开始发声,播报识别到的菜品信息,同时我们也可以在终端看到相应的结果。
Tips : 须完成上述任务1上传菜品,方可在这里得到识别结果。
STEP4:多次识别
之后,我们可重复上述步骤,对素材图片1-5中已上传过的菜品进行识别。
STEP5:计算总价
最后,当我们选择好菜品后,按下板载按键b,对识别过的菜品进行总价的计算,可以看到结果以屏幕呈现和语音播报的形式展现出来,同时终端内也有相应的显示。
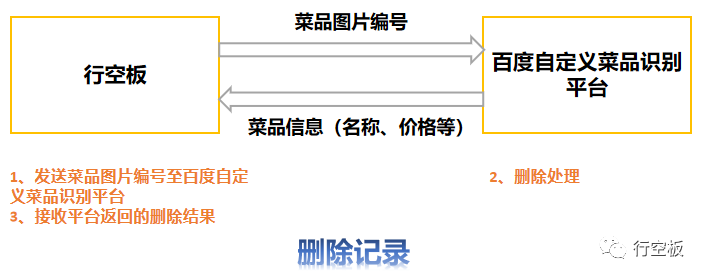
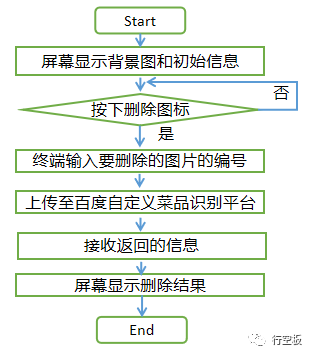
任务描述3:删除菜品
在任务2的基础上,添加删除菜品功能。点击“删除”图标后在终端输入所要删除菜品的图片签名编号。
1、分析设计
在这个任务中,我们将删除菜品。首先,准备好要删除的菜品图片编号,输入到终端后自动上传至百度自定义菜品识别的平台上,然后接收返回的删除结果显示在屏幕上。
2、程序编写
STEP1:创建与保存项目文件
在板子的“无人餐厅”文件夹下再创建一个Python程序文件“main3.py”,双击打开。
Step2:程序编写
(1)定义删除菜品功能函数
在定义删除菜品的功能时,步骤和之前相似。首先第一步,我们在终端输入要删除图片的签名编号;接着第二步,通过百度平台指定的删除请求链接将图片的签名编号发送至平台;随后第三步,接收百度平台的响应反馈,识别响应结果并在删除失败时终端显示错误码,同时返回变量xhl的值来表示删除成功与否。
- def delete_pic():
- request_url = "https://aip.baidubce.com/rest/2.0/image-classify/v1/realtime_search/dish/delete" # 百度云平台删除请求链接
- cont_sign = input("请输入图片编号:") # 终端输入编号
- params = {"cont_sign":cont_sign} # 用变量params存储菜品图片编号
- request_url = request_url + "?access_token=" + access_token # 删除请求链接添加token值(类似验证码)
- headers = {'content-type': 'application/x-www-form-urlencoded'} # 请求头
- response = requests.post(request_url, data=params, headers=headers) # 获取响应
- '''若删除成功设置xhl=1,失败设置xhl=0,并打印错误信息。'''
- if response: # 如果获取到响应
- try: # 捕获异常
- print (response.json())
- result_json = json.loads(response.text) # 识别响应结果中的json格式
- print(result_json['error_code']) # 打印json格式结果中的错误码,有错误时才会打印,没错误时进入except
- xhl = 0 # 设置xhl=0
- except: # 处理异常
- xhl = 1 # 设置xhl=1
- return xhl # 函数返回xhl,判断是否删除成功
(2)定义屏幕显示函数
之后,我们再定义一个函数,以便在屏幕上显示删除的结果。
- # 线程:屏幕显示删除结果
- def screen_show3():
- #while True:
- if xhllalala == 1: # 如果删除成功,窗口内显示“删除成功”
- print("删除成功")
- text.config(text="删除成功")
- time.sleep(3) #延时3秒
- text.config(text="")
- else:
- print("删除失败")
- text.config(text="删除失败")
- time.sleep(3) #延时3秒
- text.config(text="")
- #gui.stop_thread(t3)
(3)定义删除按钮的回调函数
接着,和上传与识别功能相似,我们再定义一个删除按钮的回调函数。在回调函数中,我们需要调用删除图片函数并将屏幕显示功能作为一个线程启动。
- # 删除按钮
- def delete_func(): # 定义删除图标的功能
- global xhllalala,t3
- xhllalala = delete_pic() # 调用删除菜品功能函数
- t3 = gui.start_thread(screen_show3) # 启动屏幕显示结果的线程
(4)将删除菜品的回调函数赋给删除图标
最后,我们给删除按钮添加上被点击时触发的回调函数。
- img_delete = gui.draw_image(x=160,y=260,w=50,h=40,image='img/delete.png',onclick=lambda:delete_func()) # 显示删除图标
Tips:完整示例程序如下:
Tip1:须在程序中“cAPI_KEY”、“cSECRET_KEY”处填入对应图像识别的API_KEY、SECRET_KEY两个参数。获取方式可参考附录2。
Tip2:语音平台的APP_ID、API_KEY、SECRET_KEY三个参数同上节课。
3、程序运行
STEP1:运行程序
STEP2:终端输入图片签名
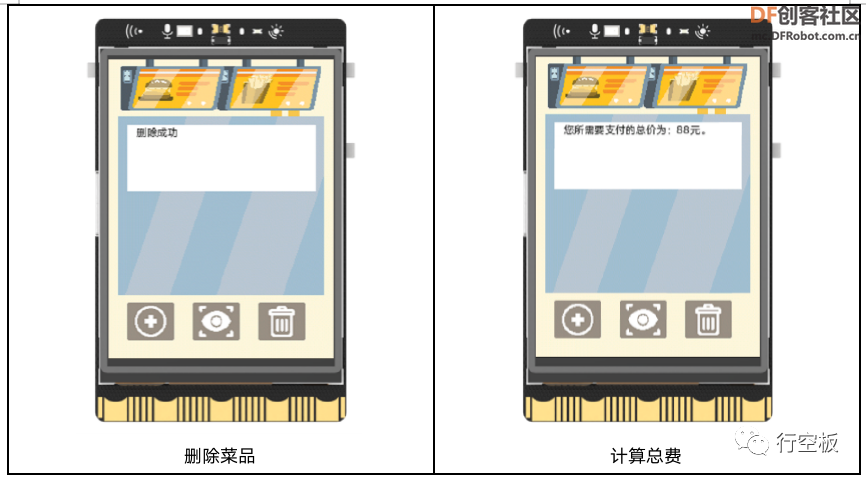
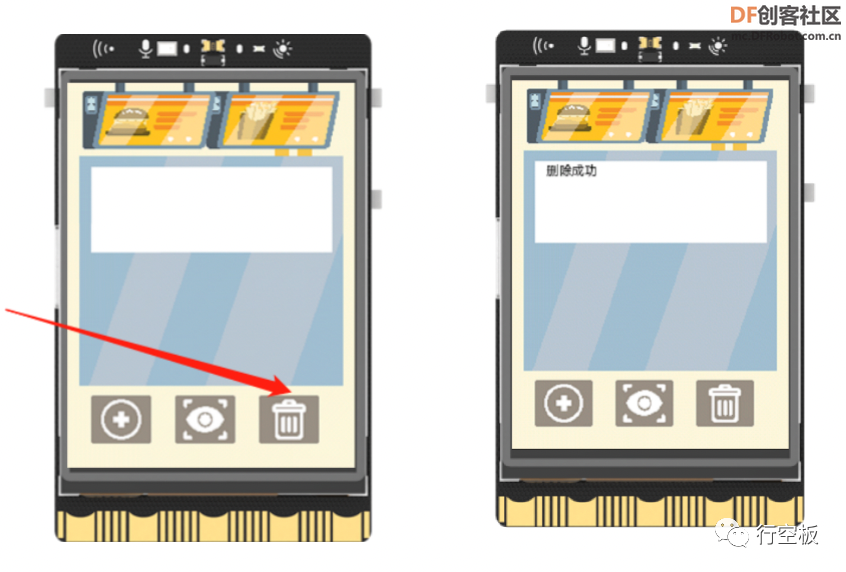
点击屏幕上的删除图标,在终端的提示后输入要删除的菜品的图片签名,回车确认后可以看到删除结果的反馈信息。这里,对于所要删除的图片的签名,我们可以通过手动打开record.txt文本文档进行查找。
Tips:同一张菜品图勿多次上传,否则可能导致删除不干净。
挑战自我
1. 想一想,真实的无人餐厅,会是什么样子的呢,让我们自己动手,利用3D打印或激光切割技术,将心目中的无人餐厅设计出来吧。
2. 在无人餐厅中,自助收银功能是非常重要的一个组成部分,接下来,让我们进一步完善本项目,为其添加收银功能,建立一套完整的无人餐厅解决方案吧!
附录
附录1:素材链接
链接:
https://pan.baidu.com/s/12ZQwv1RD22lE4nfM-kyTjw
提取码:8lw0
附录2:百度接口参数获取
Tip1:随着百度云网站的更新,下列步骤可能略有调整,但整体思路不变,即获取有额度的图像识别接口参数并申请自定义菜品识别图库。
Tip2: 每个百度云账号目前都支持领取一次免费的额度。如已无该资格,可尝试依据百度相关政策操作。
STEP1:进入百度云网站
点击进入下列网站:https://cloud.baidu.com/
STEP2:注册并登录百度云账号,
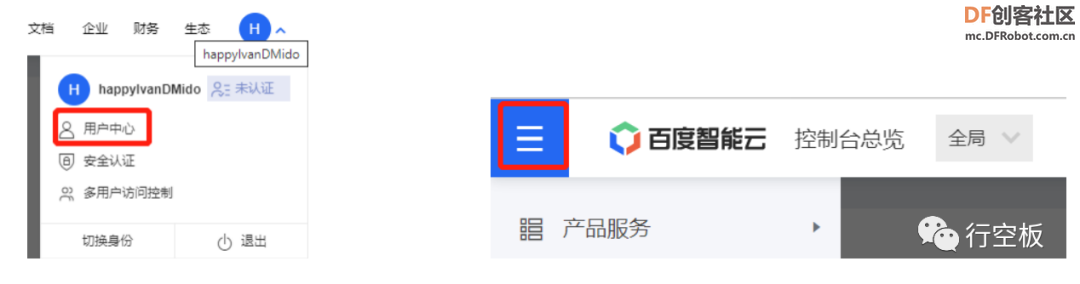
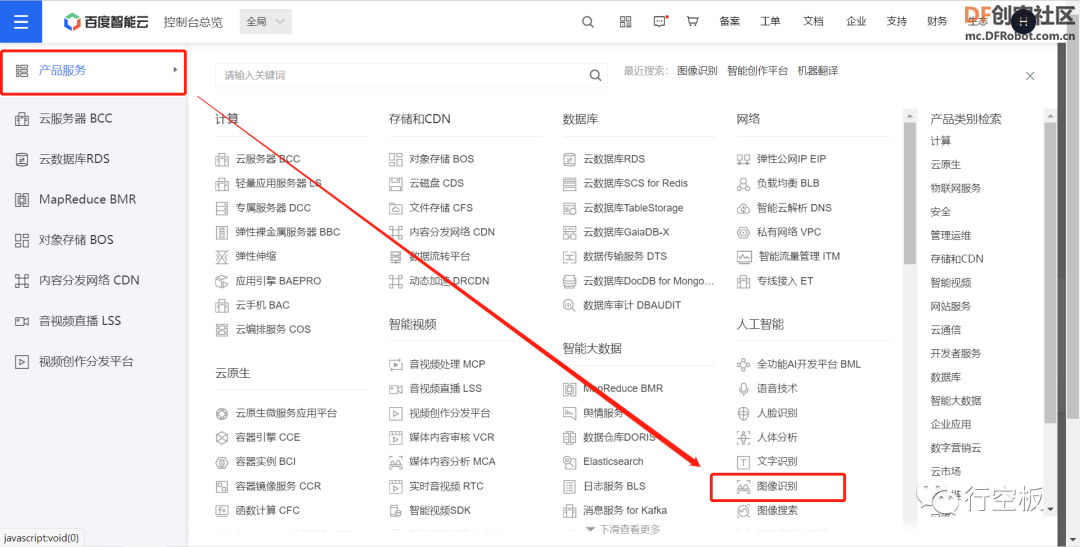
STEP3:登录成功后,在右上角个人账号中点击“用户中心”,点击左上角的

,找到“产品服务”中的“图像识别”,并点击进入。
STEP4:创建应用
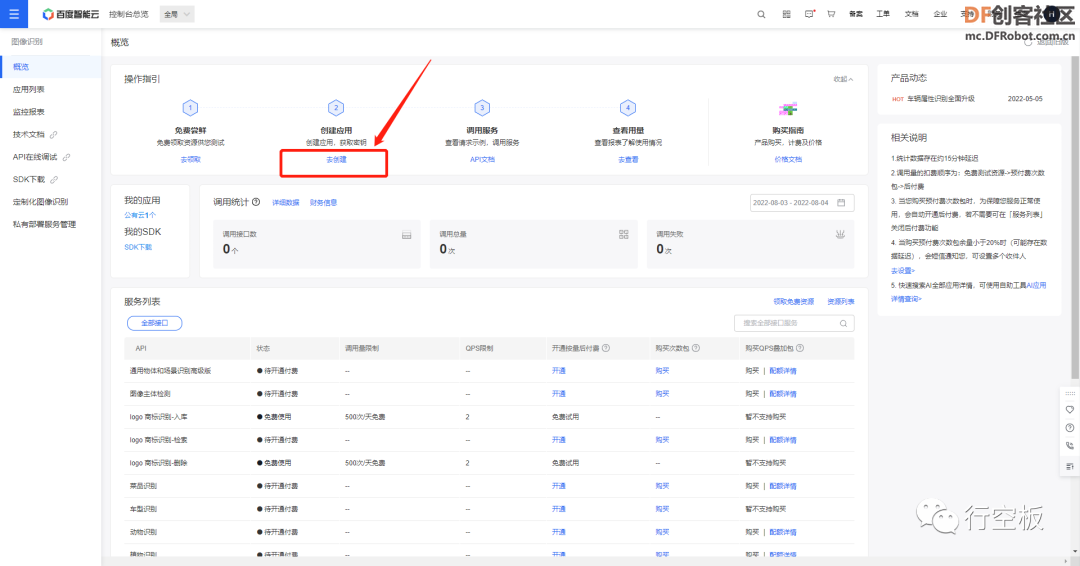
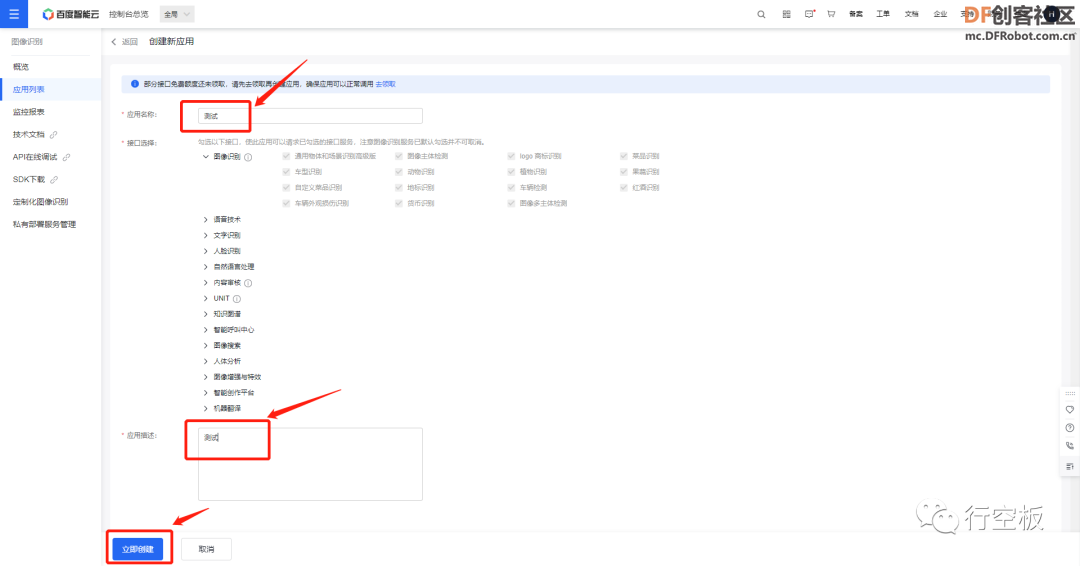
在“概览”页面中点击“创建应用”下的“去创建”按钮。
任意填写应用名称和应用描述。
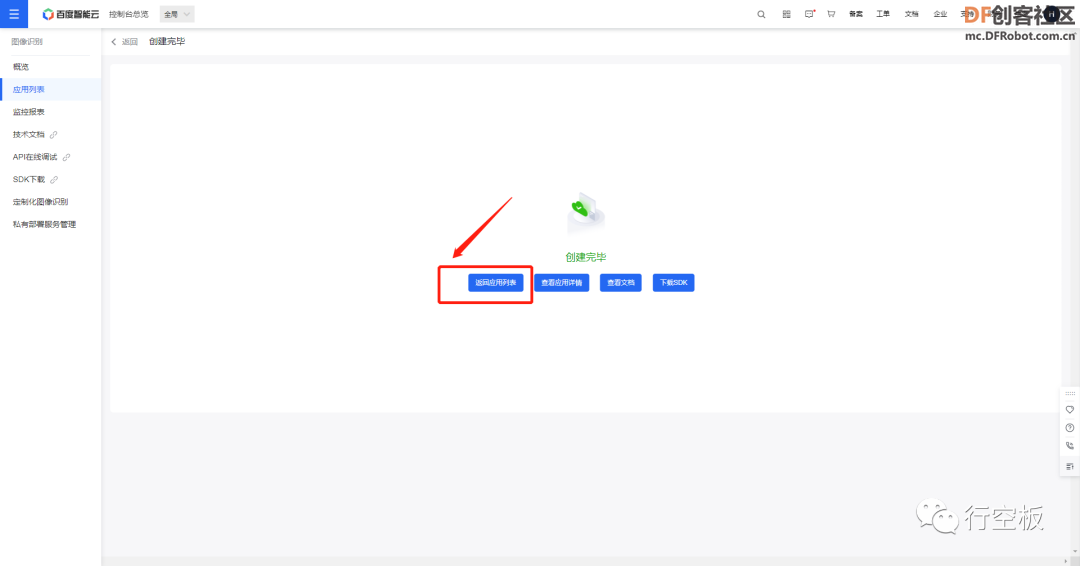
添加成功后点击“返回应用列表”,这样在列表中就可以看到我们新添加的应用了。
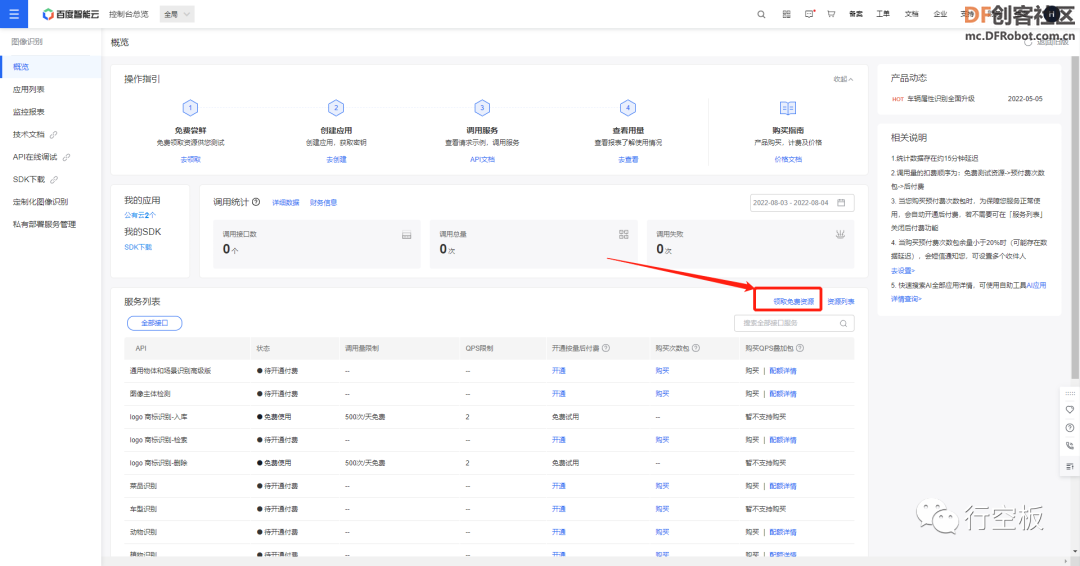
STEP5:领取资源
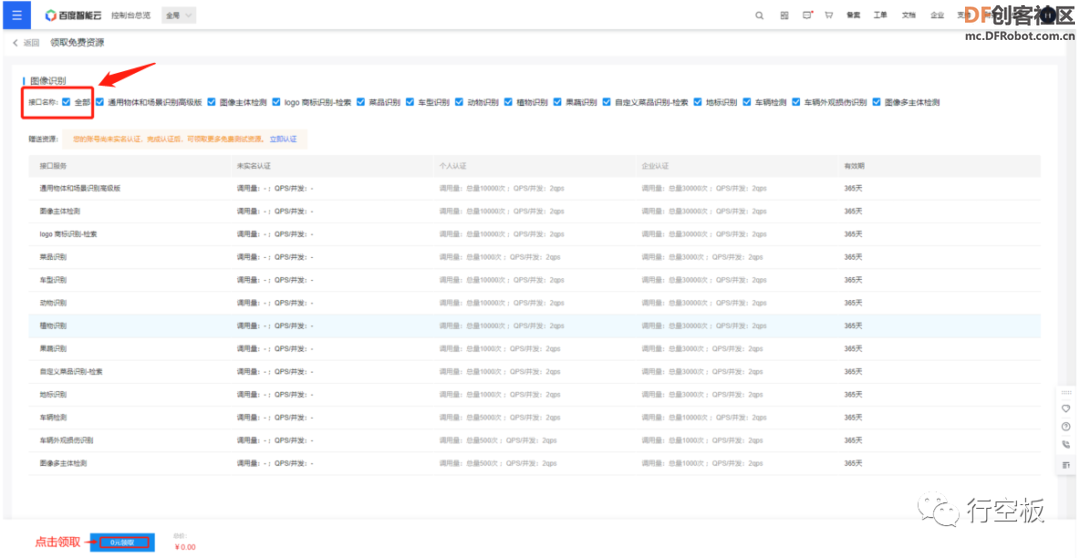
点击图像识别“概览”下的“领取免费资源”,选上全部接口后点击“0元领取”即可。
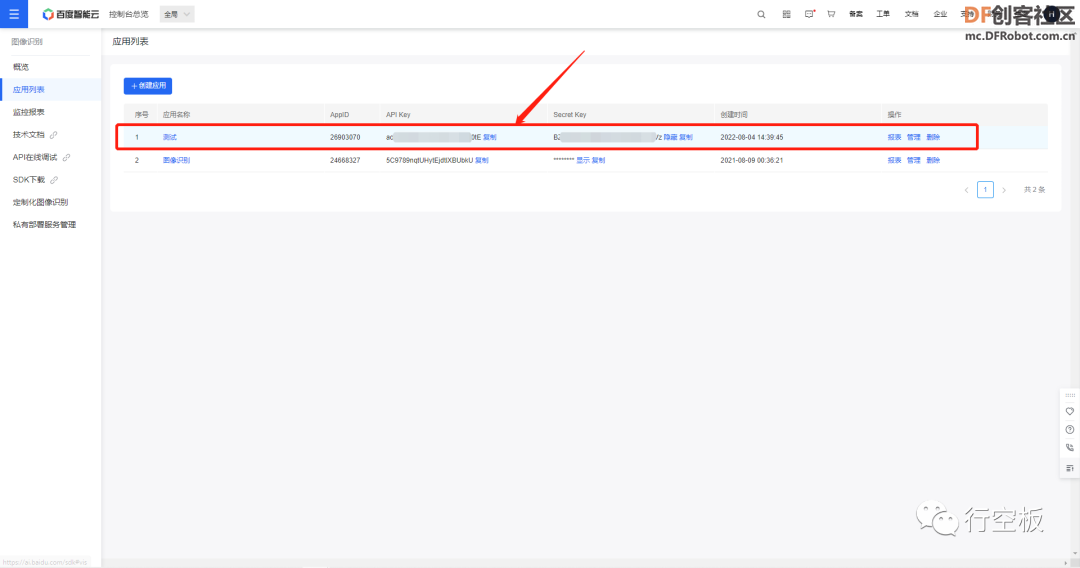
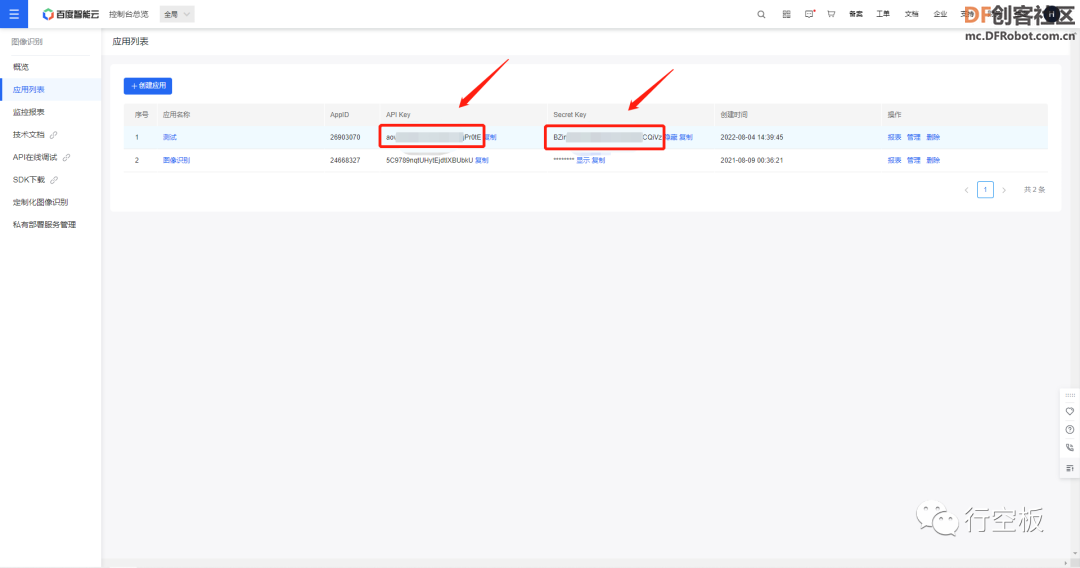
STEP6:记录关键参数
领取完资源后,回到应用列表,找到我们需要的应用和对应的API_KEY、SECRET_KEY,点击显示和复制,将其记录下来,这两个关键参数都是我们后续连接平台时所需要的。
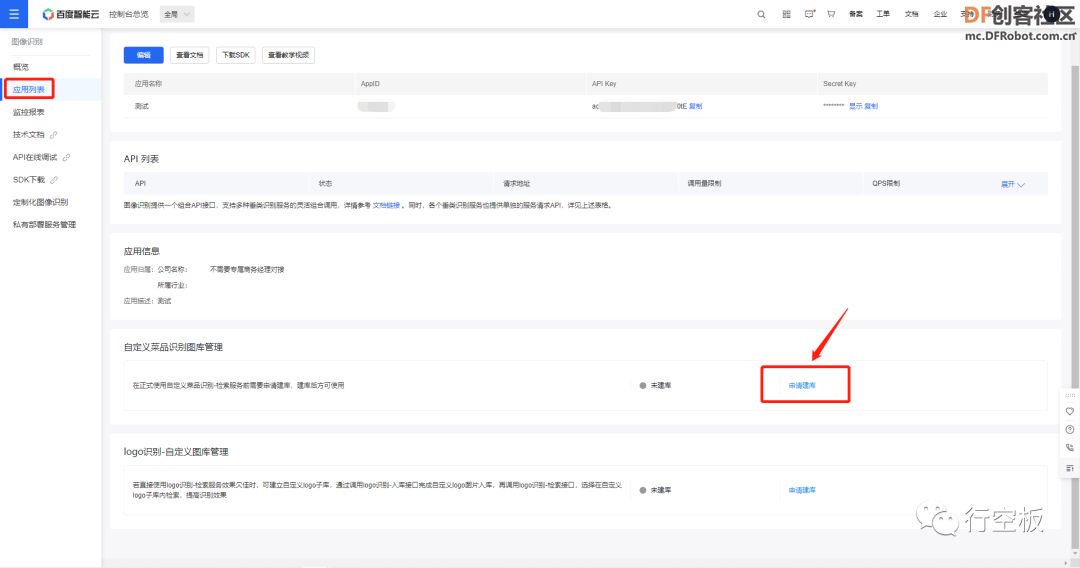
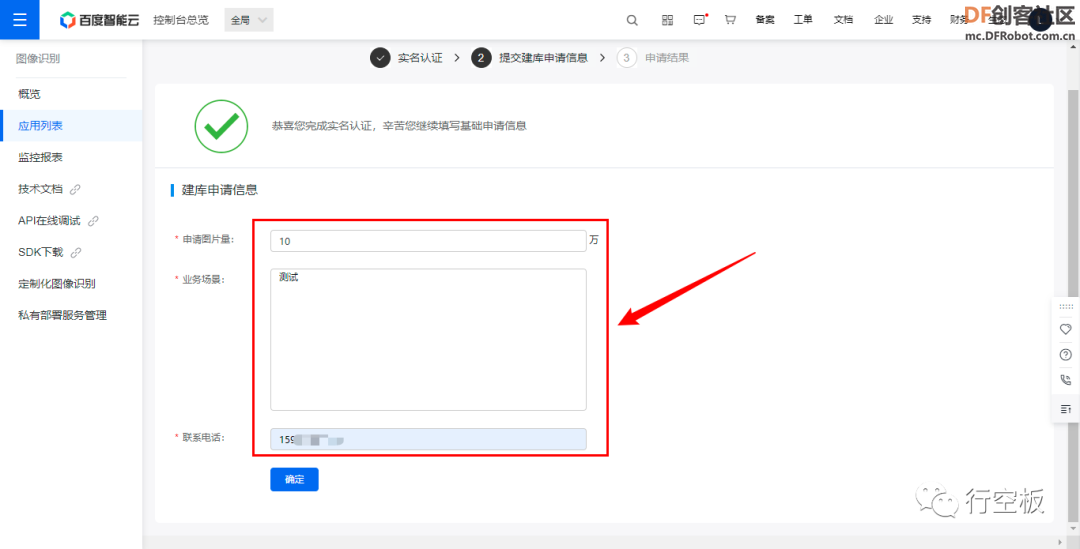
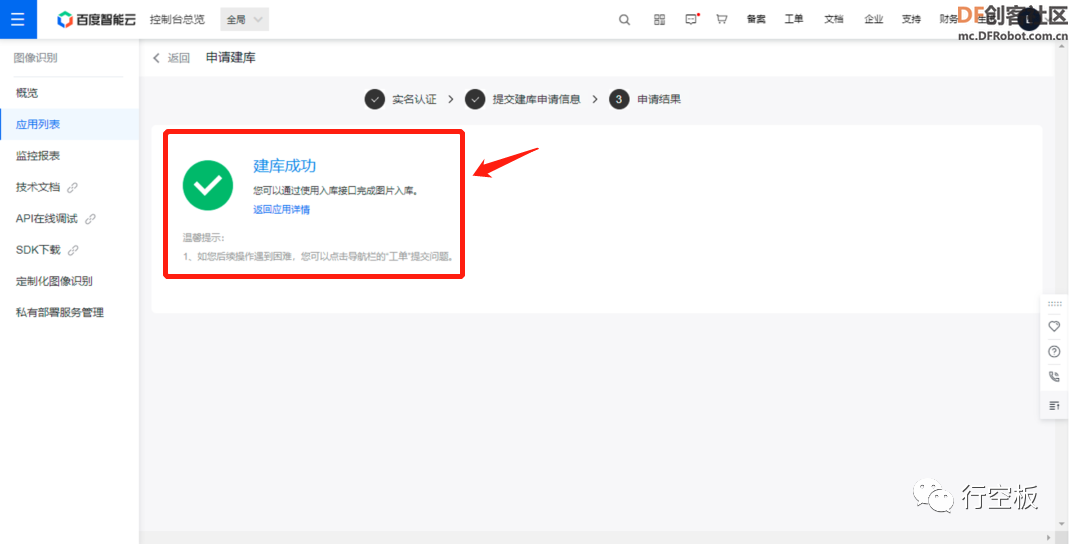
STEP7:创建图库
有了图像识别的额度之后,我们还需要申请自定义菜品识别的图库,方可在后续通过程序将菜品上传。
Tip1:在建库过程中遇到问题,可通过提交工单联系百度工作人员解决。
Tip2:领取完图像识别的额度,创建好图库后,约有30分钟生效时间。 |
















 沪公网安备31011502402448
沪公网安备31011502402448

 置顶卡
置顶卡 变色卡
变色卡 千斤顶
千斤顶
 萌萌哒新人
萌萌哒新人
 活跃会员
活跃会员
 宣传大使
宣传大使
 志“童”道合
志“童”道合
 编辑选择奖
编辑选择奖






