|
18397| 0
|
[教程] 【Mind+Python】元宇宙之舞动的弹幕2 |
|
本帖最后由 gray6666 于 2021-12-9 15:08 编辑 二、【制作过程】3.利用opencv库将视频分割为图片序列 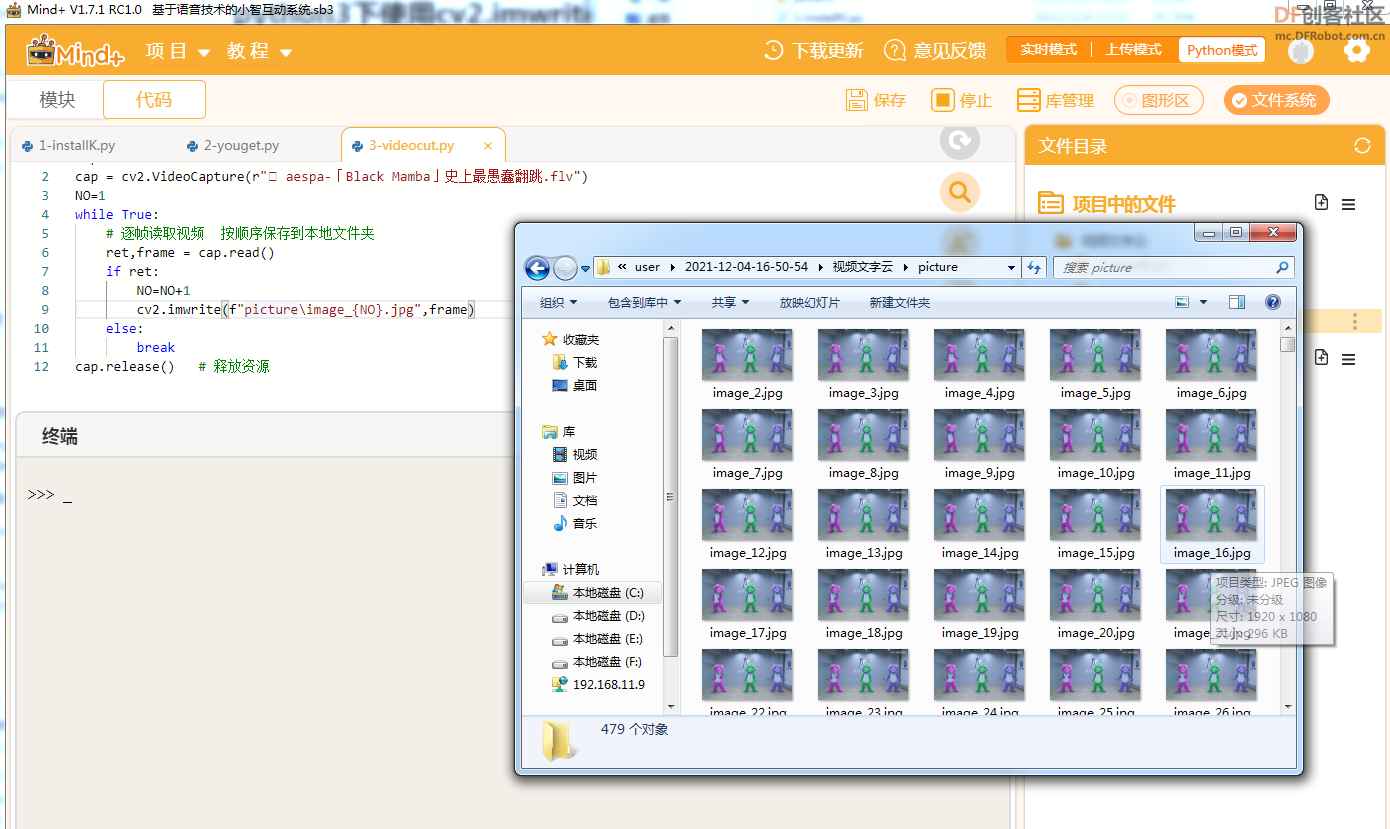 参考代码 import cv2 cap = cv2.VideoCapture(r"史上最愚蠢翻跳.flv") NO=1 while True: # 逐帧读取视频 按顺序保存到本地文件夹 ret,frame = cap.read() if ret: NO=NO+1 cv2.imwrite(f"picture\image_{NO}.jpg",frame) else: break cap.release() # 释放资源 4.在百度AI平台注册,申请人像分割账号,(虽然是人像切割,但是卡通 效果也很棒)制作图像蒙版序列    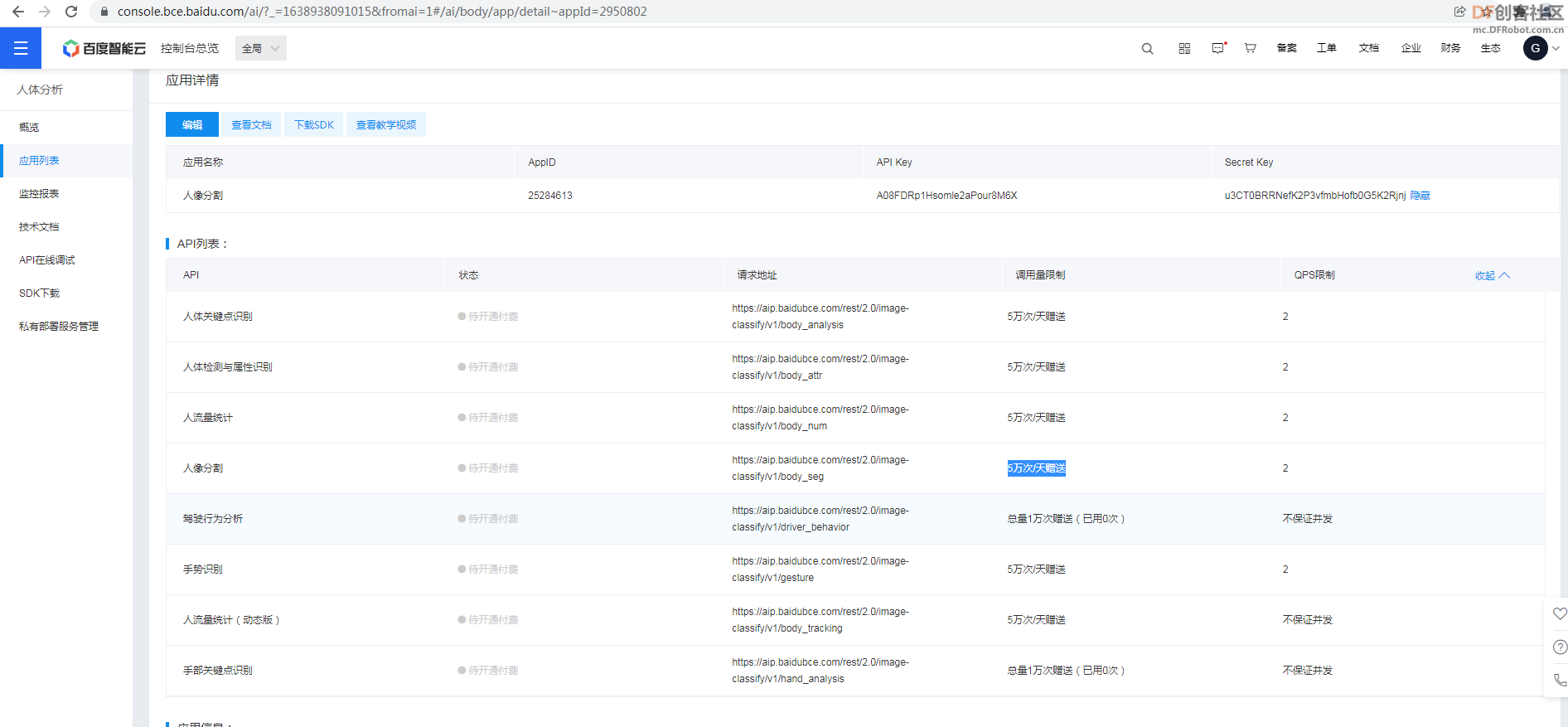 在保存图像序列的 picture文件夹 中 编辑如下文件,并运行蒙版制作程序 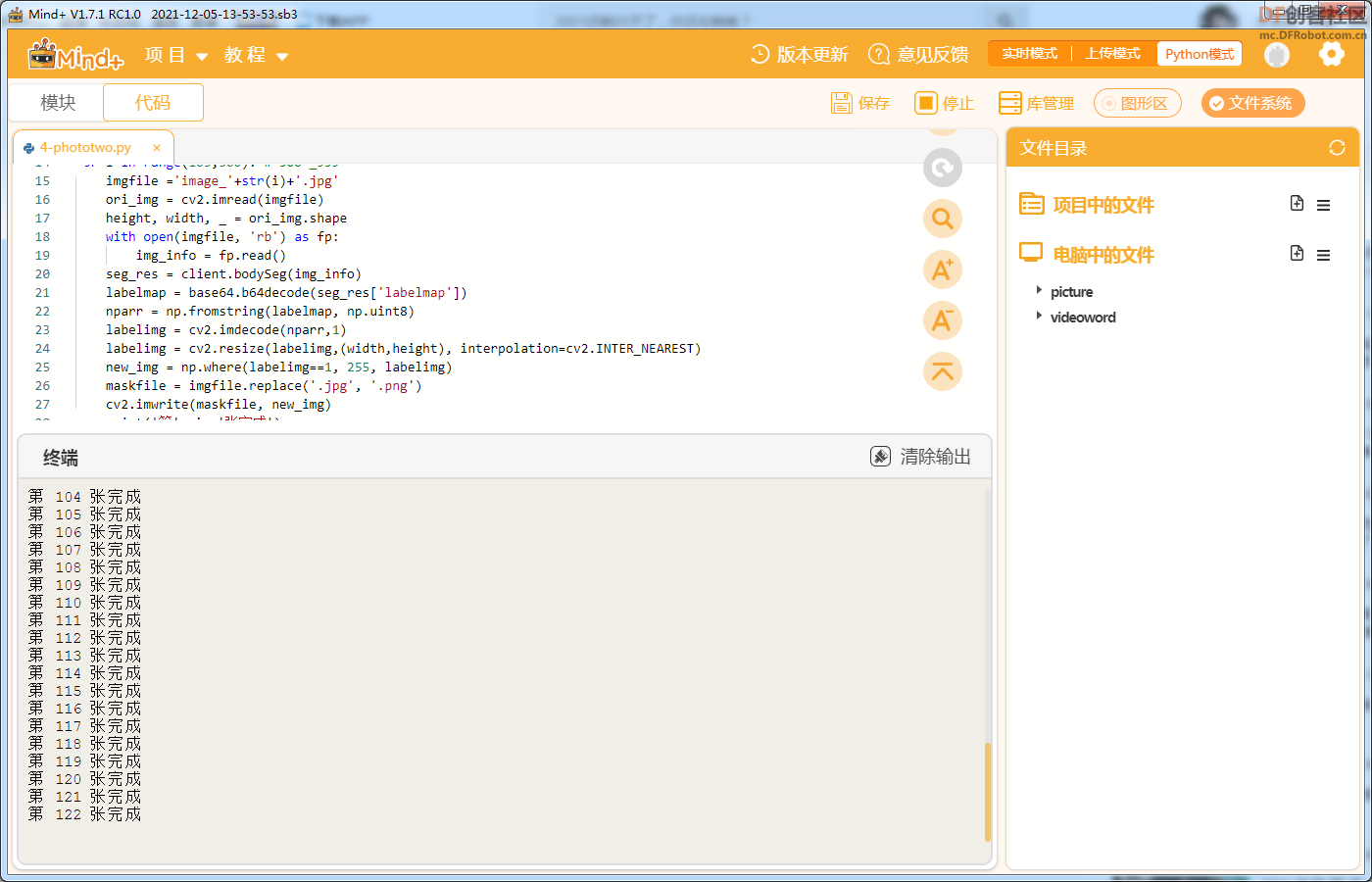 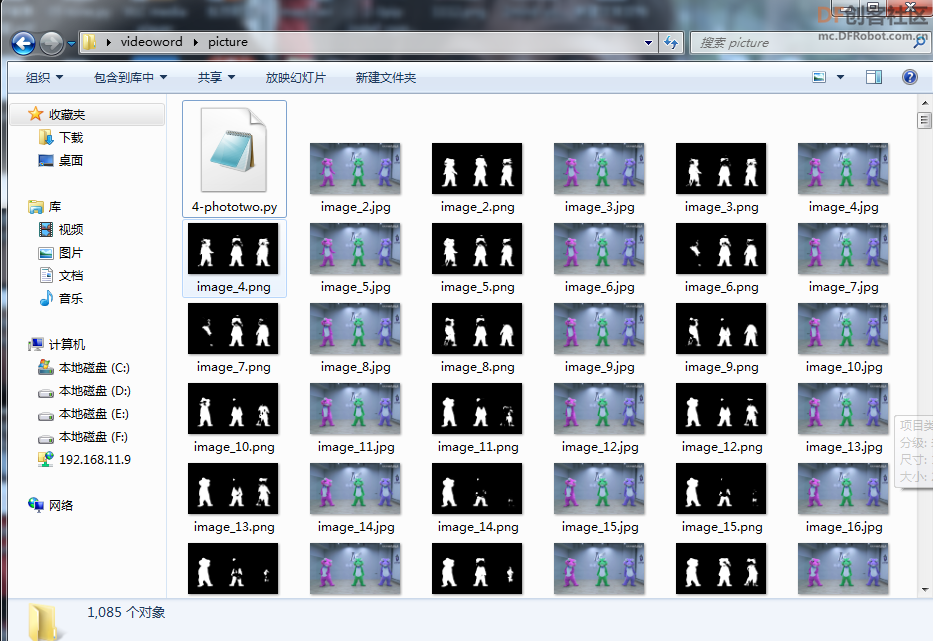 参考代码 import cv2 import base64 import numpy as np from aip import AipBodyAnalysis # 在百度云中申请,每天各接口有调用5万次数限制. APP_ID = '****************************' API_KEY = '****************************' SECRET_KEY = '****************************' client = AipBodyAnalysis(APP_ID, API_KEY, SECRET_KEY) #i=103 #500 for i in range(511,1040): # 500 _999 imgfile ='picture\image_'+str(i)+'.jpg' ori_img = cv2.imread(imgfile) height, width, _ = ori_img.shape with open(imgfile, 'rb') as fp: img_info = fp.read() seg_res = client.bodySeg(img_info) labelmap = base64.b64decode(seg_res['labelmap']) nparr = np.fromstring(labelmap, np.uint8) labelimg = cv2.imdecode(nparr,1) labelimg = cv2.resize(labelimg,(width,height), interpolation=cv2.INTER_NEAREST) new_img = np.where(labelimg==1, 255, labelimg) maskfile = imgfile.replace('.jpg', '.png') cv2.imwrite(maskfile, new_img) print('第', i, '张完成') 5.爬取视频弹幕 谷歌浏览器按F12,找到 cid 信息 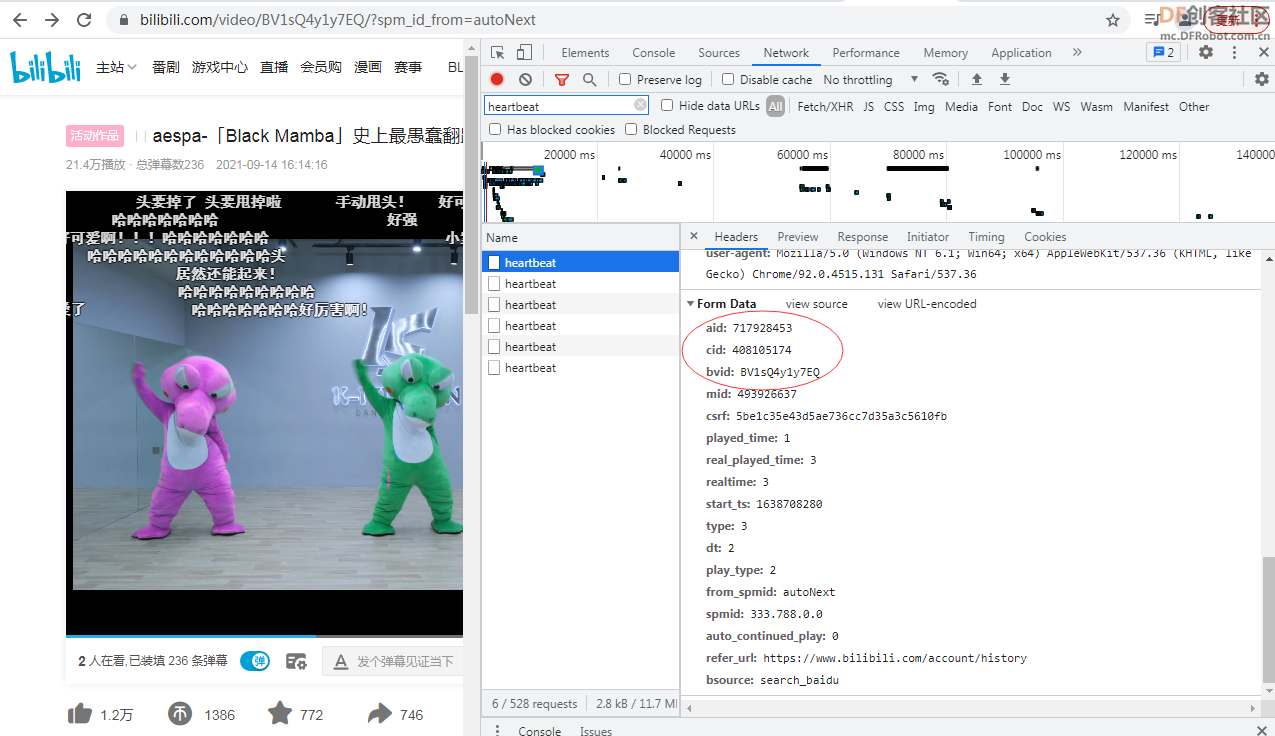 在浏览器网址栏输入 https://comment.bilibili.com/cid号.xml 例:https://comment.bilibili.com/408105174.xml 可以查看弹幕 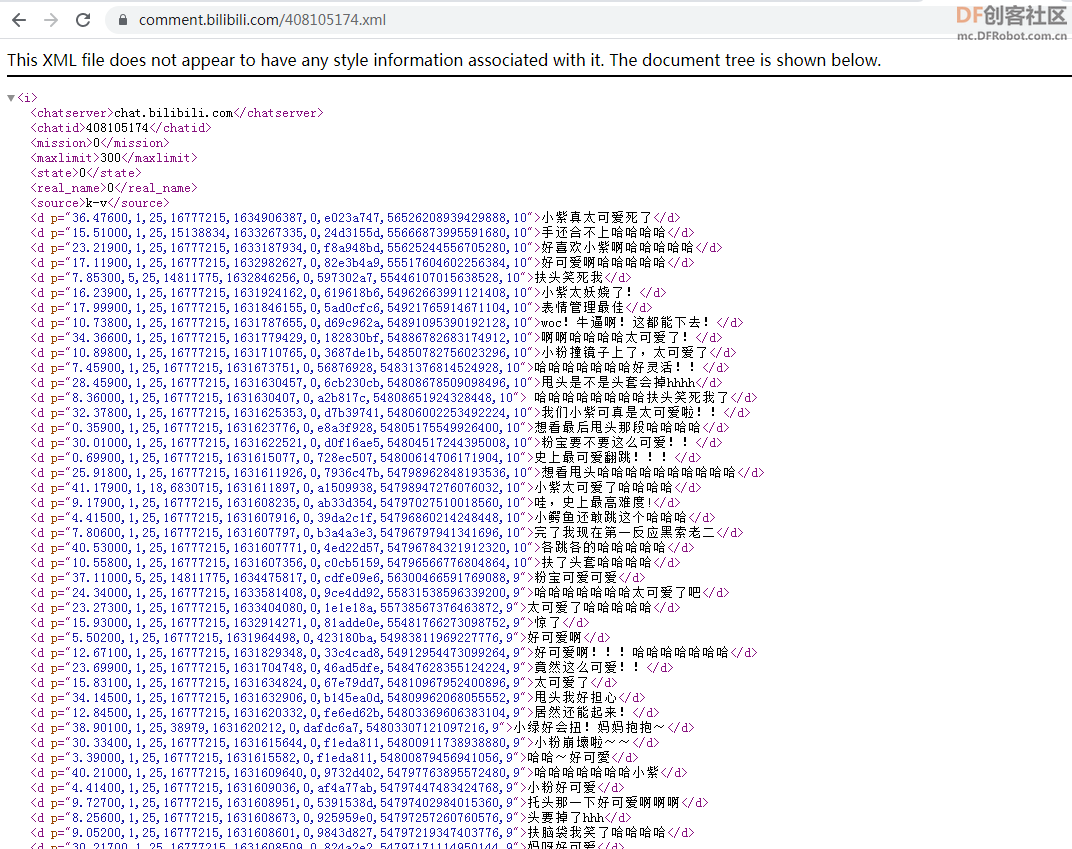 运行以下python代码爬取弹幕 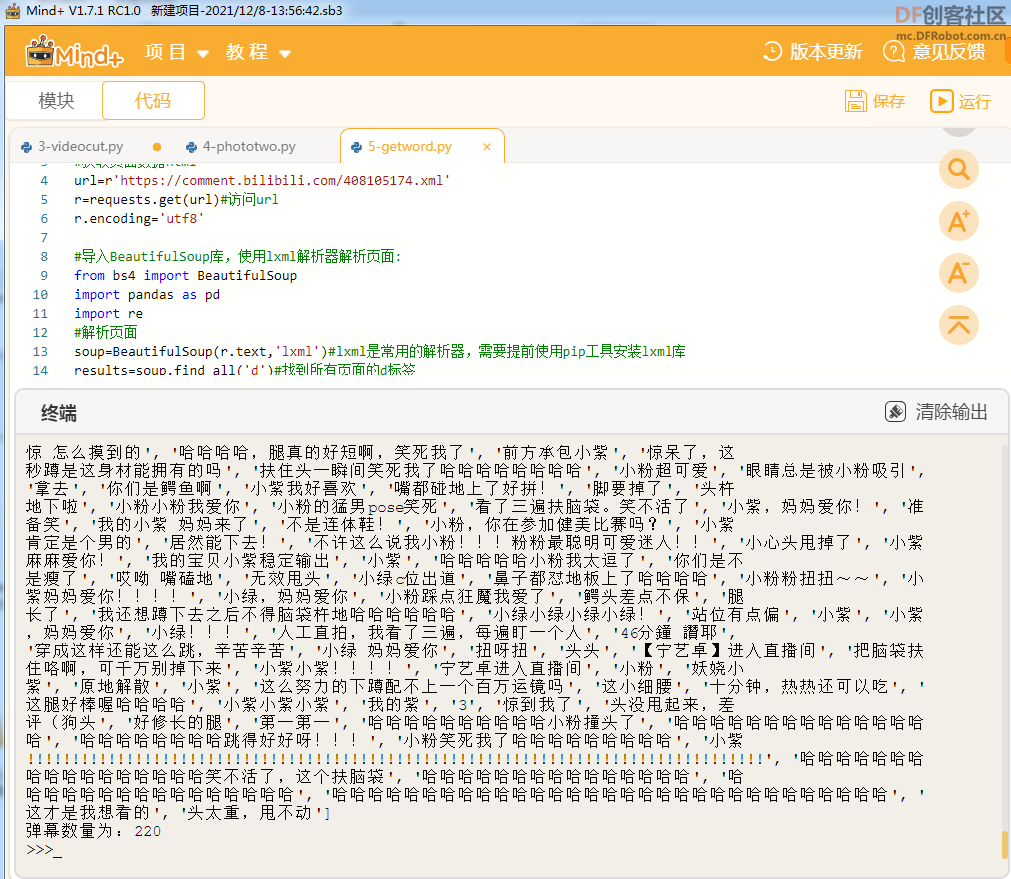 参考代码 import requests url=r'https://comment.bilibili.com/408105174.xml' r=requests.get(url)#访问url r.encoding='utf8' #导入BeautifulSoup库,使用lxml解析器解析页面: from bs4 import BeautifulSoup import pandas as pd import re #解析页面 soup=BeautifulSoup(r.text,'lxml')#lxml是常用的解析器,需要提前使用pip工具安装lxml库 results=soup.find_all('d')#找到所有页面的d标签 print(results) data = [data.text for data in results] # 输出到文件 # 正则去掉多余的空格和换行 for i in data: i = re.sub('\s+', '', i) file = open(r"word.txt", "a") print(data) file.write(i)#写入弹幕 file.write('\n')#换行 file.close() # 查看数量 print("弹幕数量为:{}".format(len(data))) 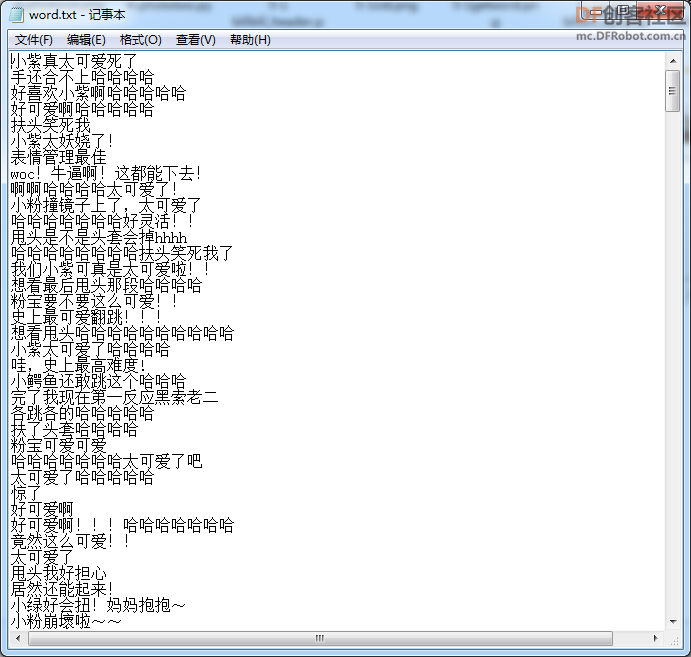 |



 沪公网安备31011502402448
沪公网安备31011502402448© 2013-2026 Comsenz Inc. Powered by Discuz! X3.4 Licensed

 置顶卡
置顶卡 变色卡
变色卡 千斤顶
千斤顶
 萌萌哒新人
萌萌哒新人
 活跃会员
活跃会员
 宣传大使
宣传大使
 创作达人
创作达人
 小蘑菇
小蘑菇
 蘑菇人
蘑菇人
 荣誉教师
荣誉教师
 编辑选择奖
编辑选择奖
 编辑选择奖
编辑选择奖
 编辑选择奖
编辑选择奖
 ARD DAY
ARD DAY
 创客造
创客造
 摸鱼团员
摸鱼团员
 编辑选择奖
编辑选择奖
 志“童”道合
志“童”道合
 编辑选择奖
编辑选择奖






