本帖最后由 szjuliet 于 2025-3-13 09:11 编辑
使用App Inventor制作一个App,通过百度大脑Api实现识别手机图片中的文字。
举一反三,还可以制作语音识别、图像识别、人脸识别等人工智能App。
视频教程:
文字教程:
App功能描述
选择手机相册中的图片,使用百度文字识别Api将图片中的文字识别出来
制作步骤
一. 注册百度大脑账号并创建应用
-
申请百度大脑账号(略)并登录,登录地址:https://ai.baidu.com/, 如已有百度网盘、百度贴吧账号可以直接登录。
-
登录后,点击左上角的 开放能力 --> 文字识别 --> 通用文字识别
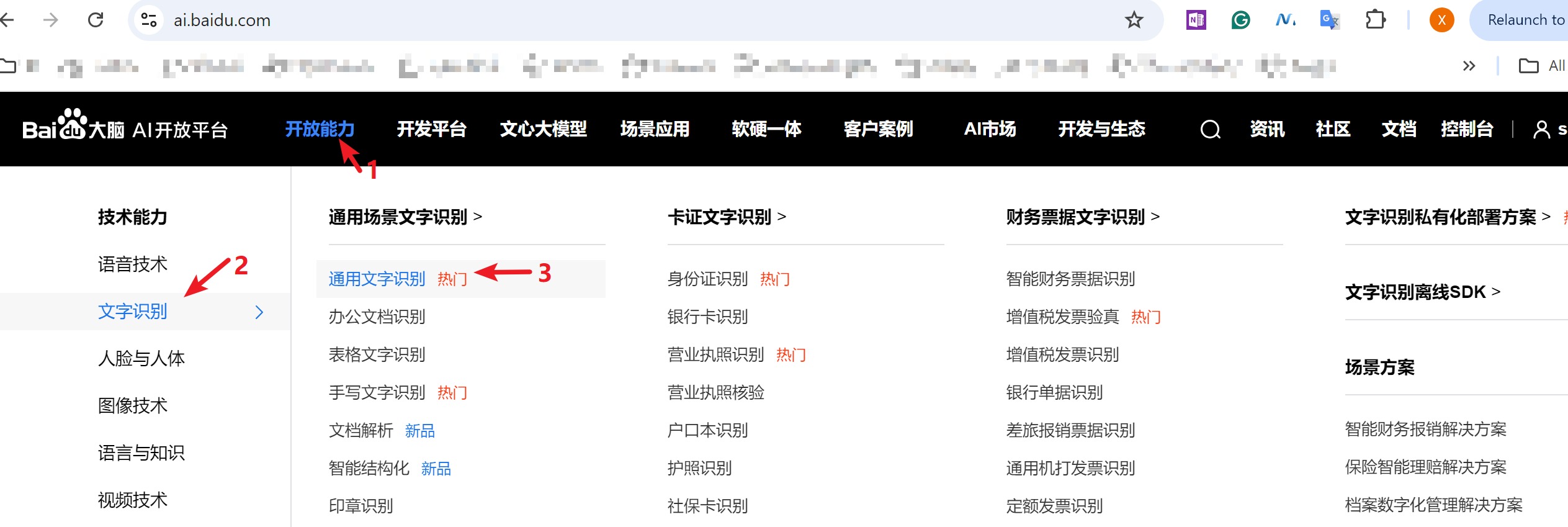
-
点击“立即使用”。
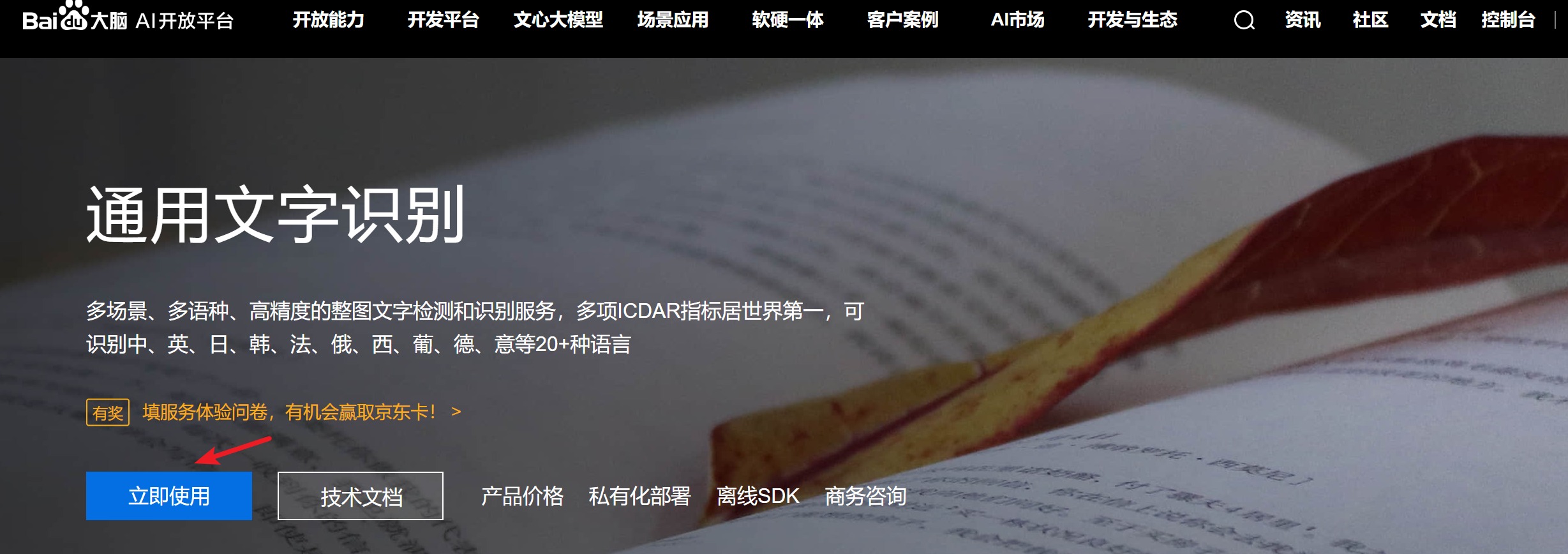
-
早期如是新用户,会有免费的额度,时间大概是半年,现在不清楚是什么情况。目前百度也会有优惠。我购买的是1元优惠包。专项资源包1000次,免费资源5万次,个人调试足够用了。如已购买共享资源包,状态会显示“正在付费使用中”,否则点击箭头所指的“购买共享资源包”,购买需要的资源。
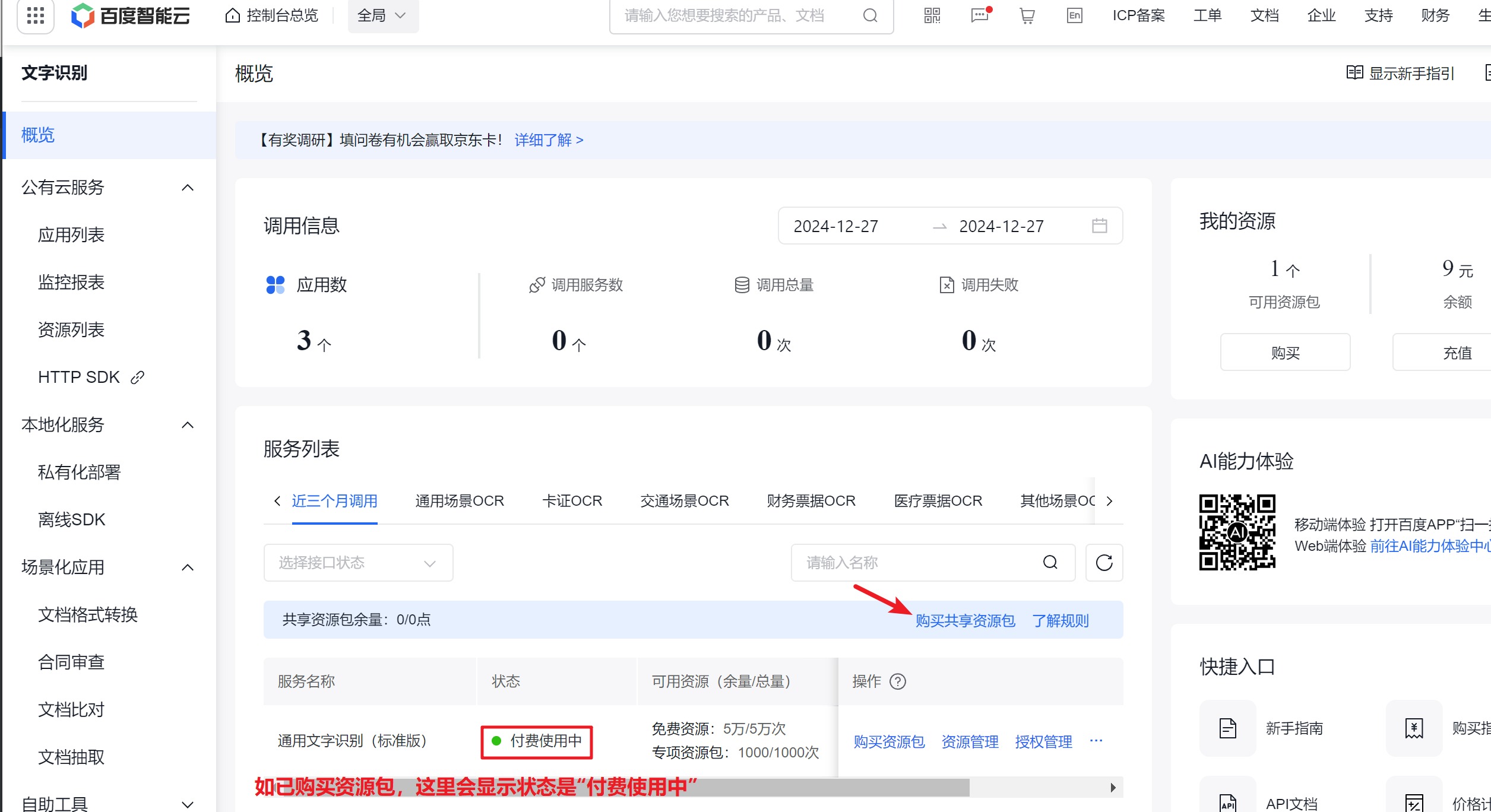
-
下单后,会跳转到支付页面
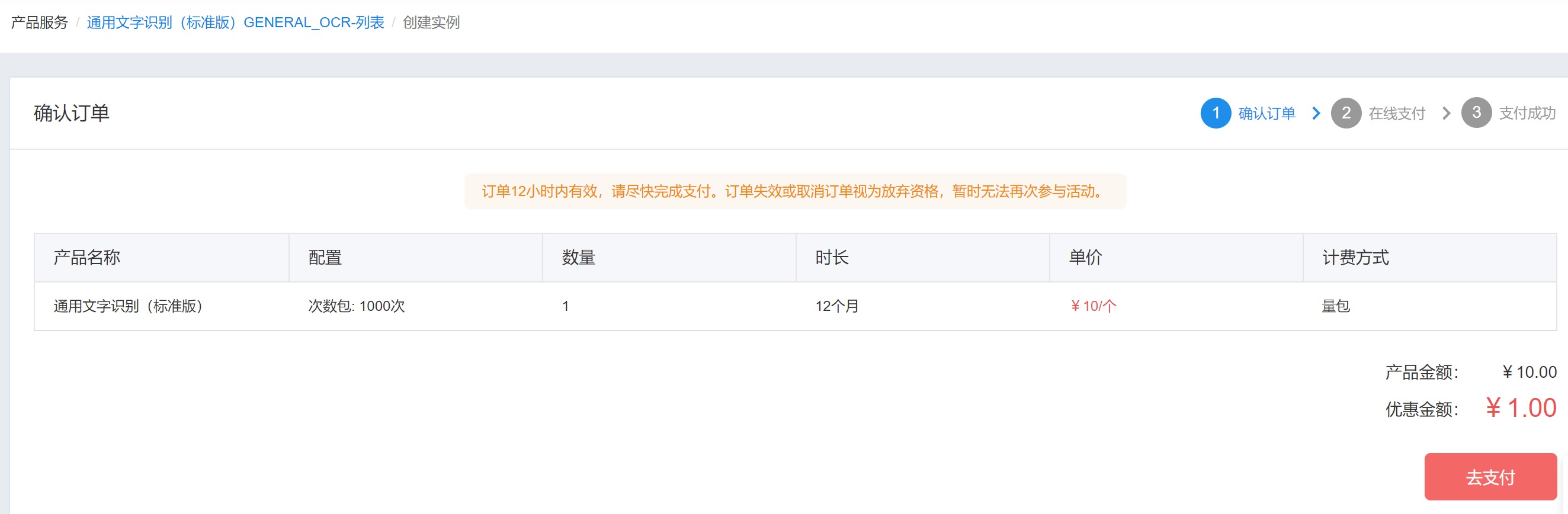
-
支付成功后点击图中“应用数”下方的数字,
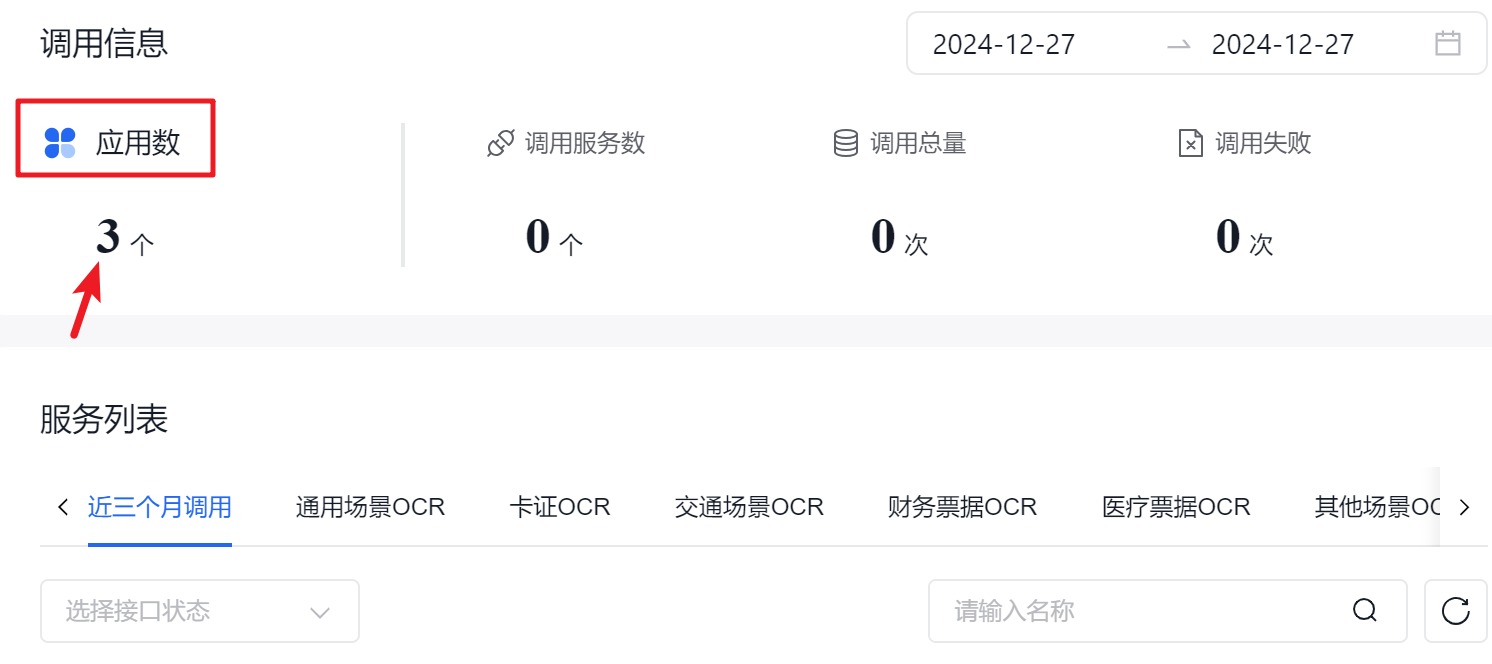
或直接在浏览器地址栏输入地址:
https://console.bce.baidu.com/ai-engine/old/#/ai/ocr/app/list
-
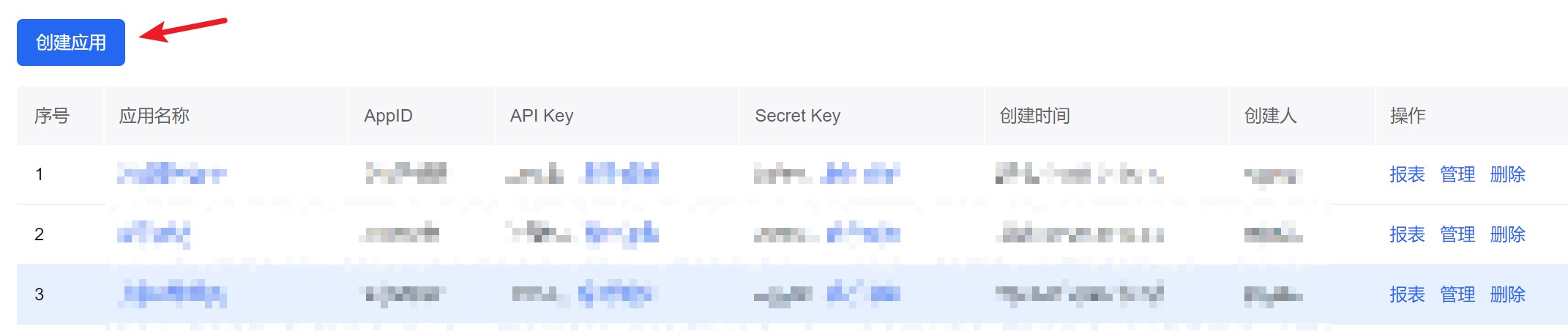
在打开的页面中点击“创建应用”
-
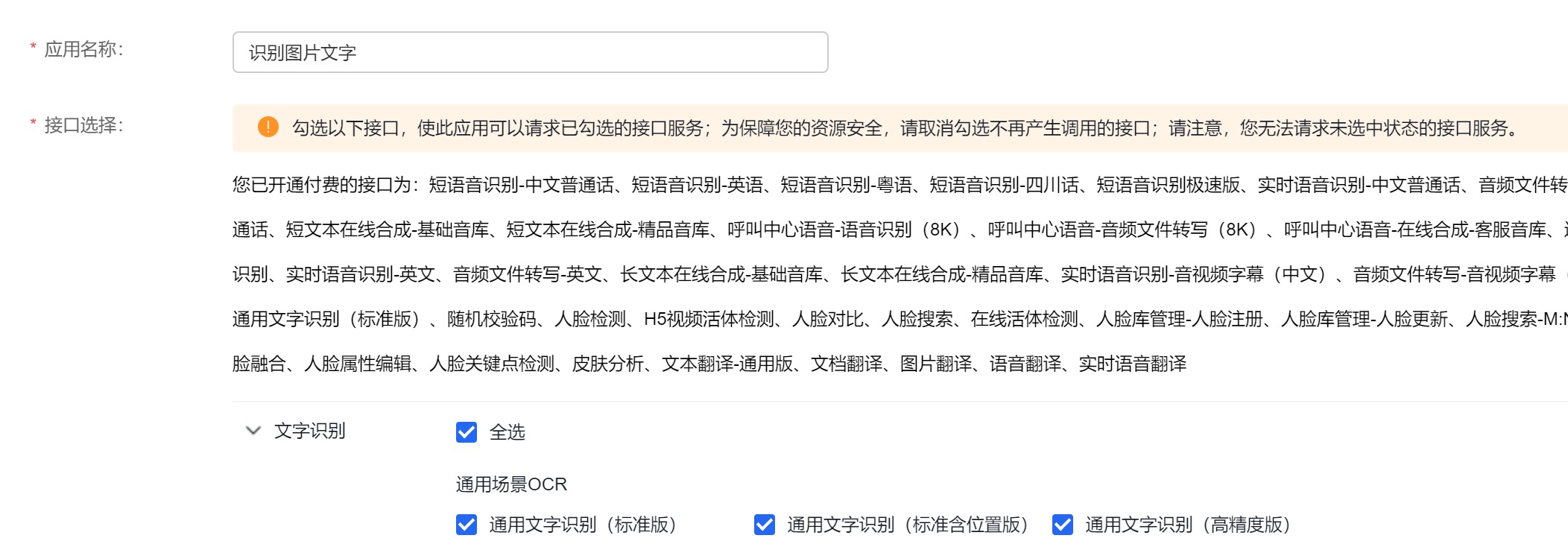
输入应用名称,并选择需要的接口。
设置好其他参数,点击”立即创建“
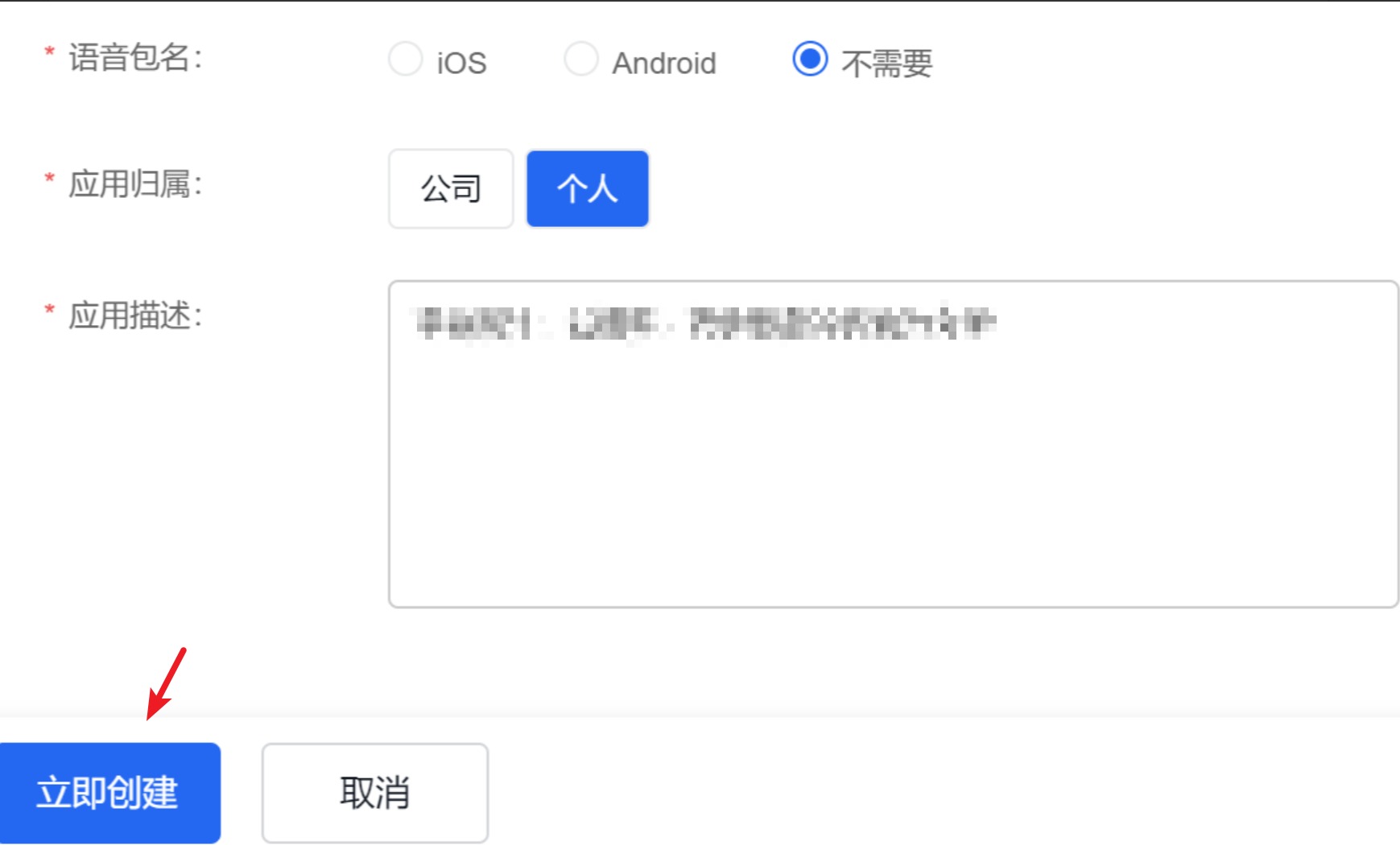
注意:为了安全可以只选择需要的接口。如果应用以后还要需要用到其他接口,可以将接口全选,如果接口没有选择,是无法请求的。
-
应用创建成功后,会进入应用列表,在新创建的应用中,复制该应用对应的APK Key和Secret Key,并保存到相应位置,我们后面获取Access Token的时候需要用到。
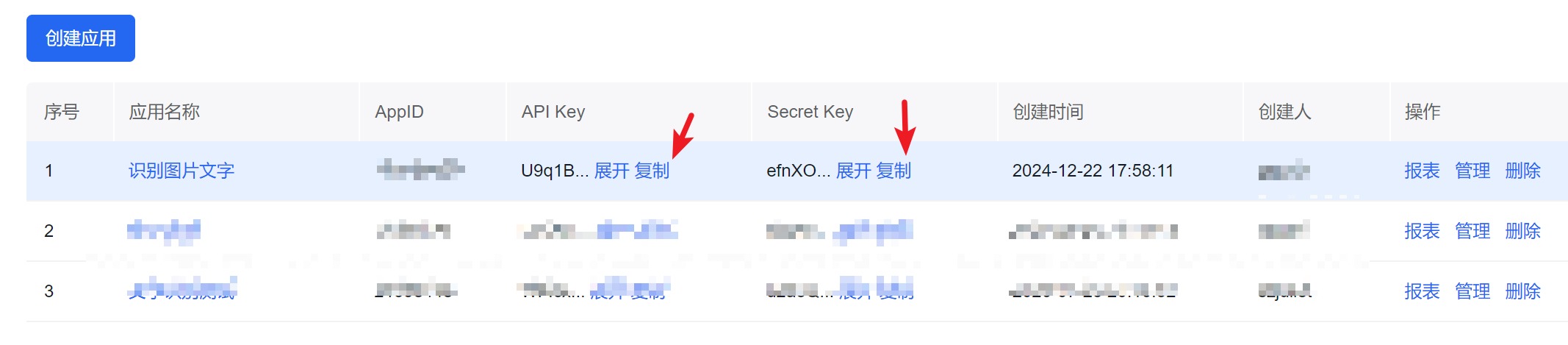
二. 获取百度通用文字识别API相关参数
-
浏览器地址栏输入地址 https://ai.baidu.com/tech/ocr/general ,进入页面后,点击页面上方的“使用方式”,在“公有云服务”下点击“API文档”,
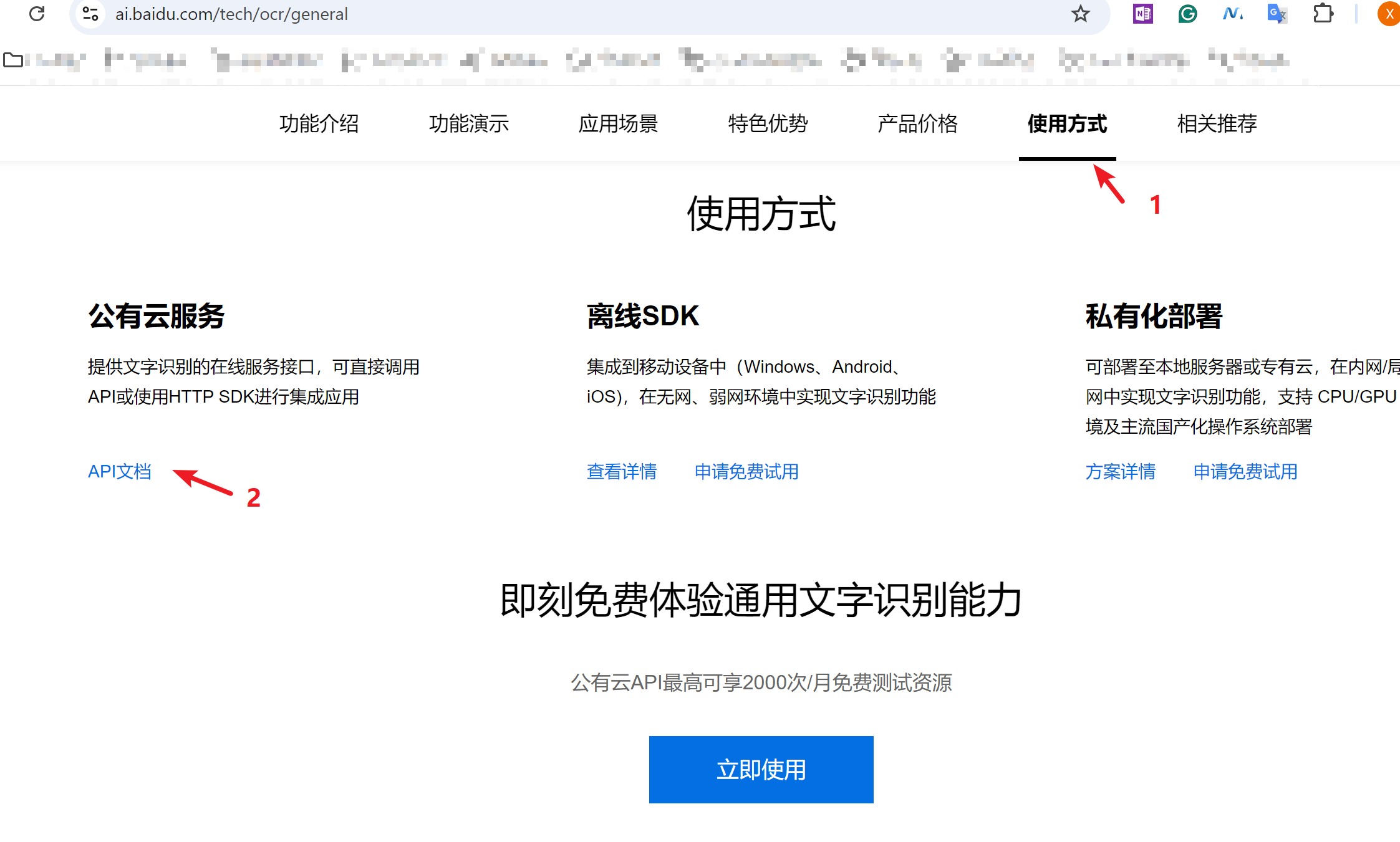
-
下图中的参数是我们在App Inventor中需要使用的:
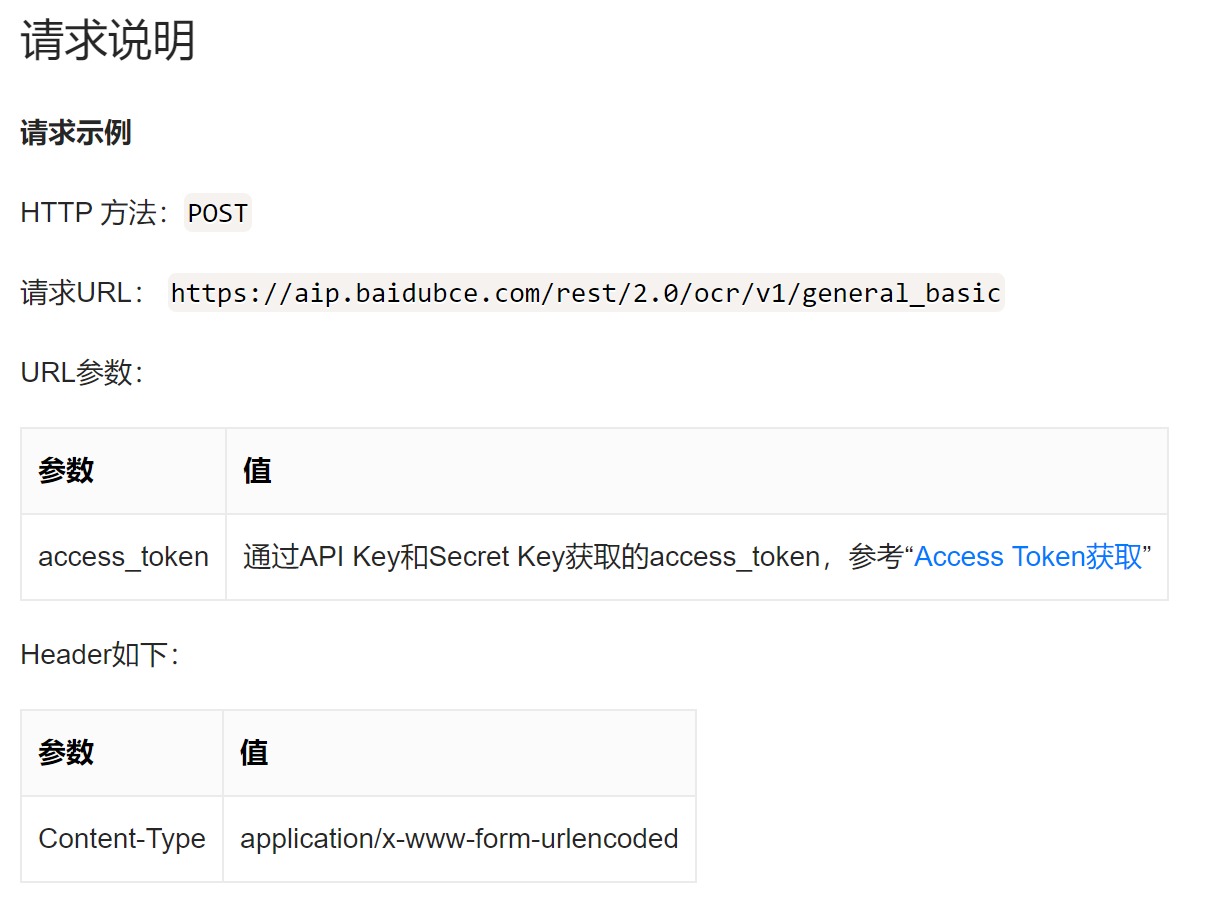
-
输入地址:https://ai.baidu.com/ai-doc/REFERENCE/Ck3dwjhhu 。进入鉴权认证机制页面,准备获取Access_token。

鉴权的主要目的是获取Access_token。Access_token是用户的访问令牌,承载了用户的身份、权限等信息。鉴权主要分为以下两步:
1)获取AK/SK(参考前面步骤一的第9步)
2)获取Access_token
- 代码形式→适用于有计算机基础的用户
- 网页调试工具→适用于零基础的用户
- 在线调试工具(推荐)→快速调试接口效果
-
获取Access_token
1)这里我们使用方式一:代码形式来获取Access_token。在第3步同样的页面下,选择语言,并点击复制:
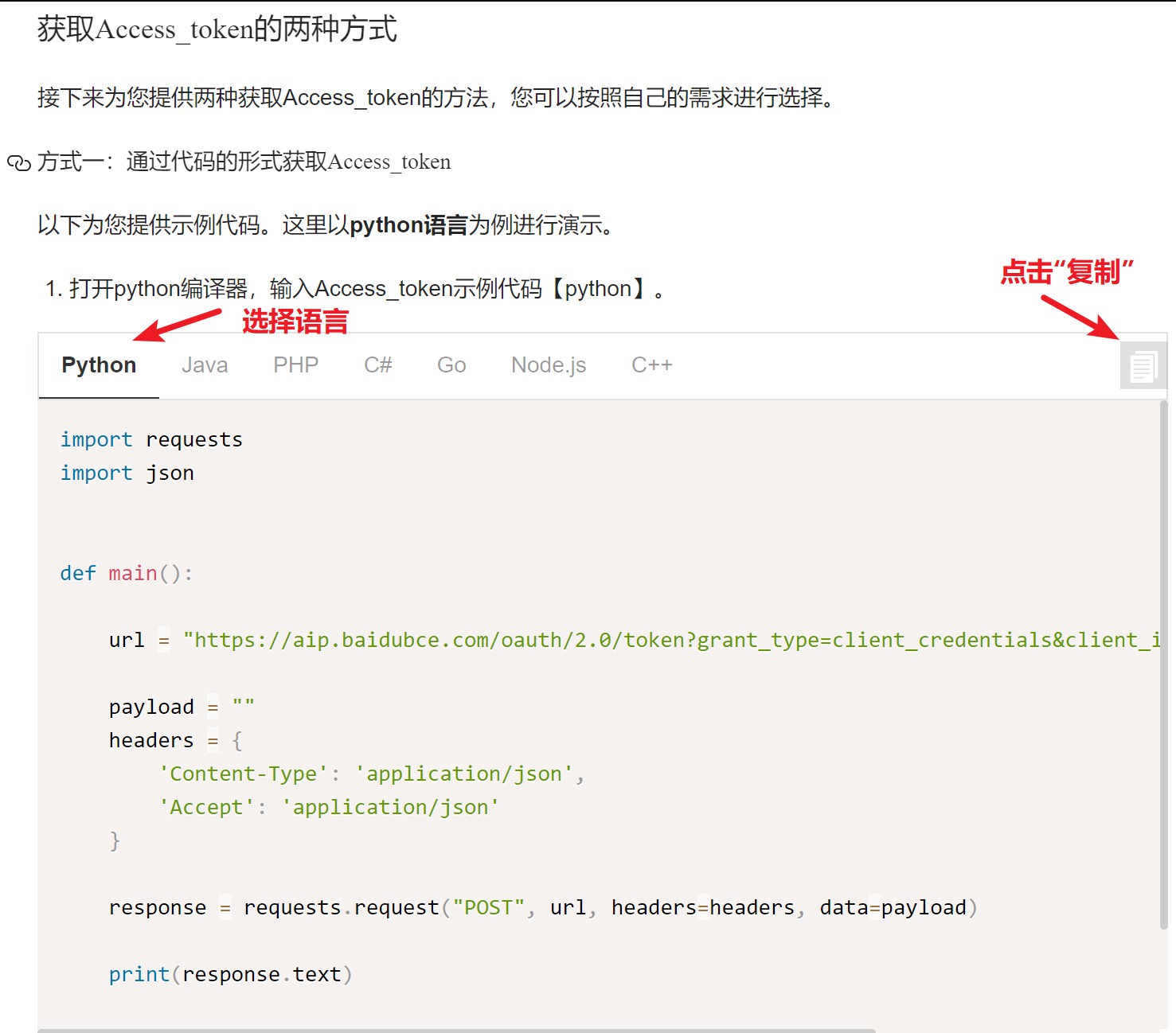
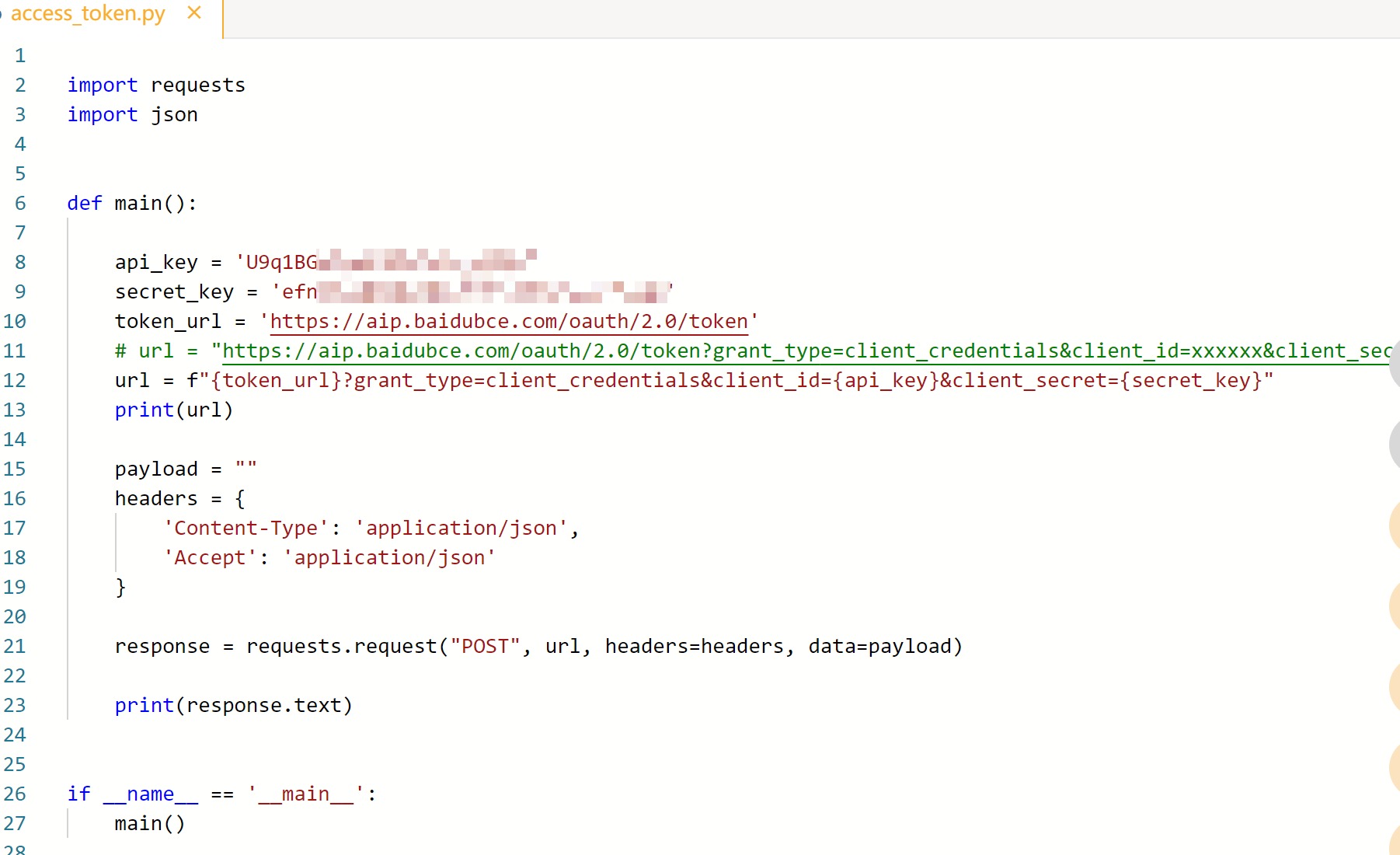
2) 运行Mind+,新建一个python程序,粘贴前面复制的程序,并添加几行代码,api_key和screet_key使用自己前面保存下来的key,如下图:
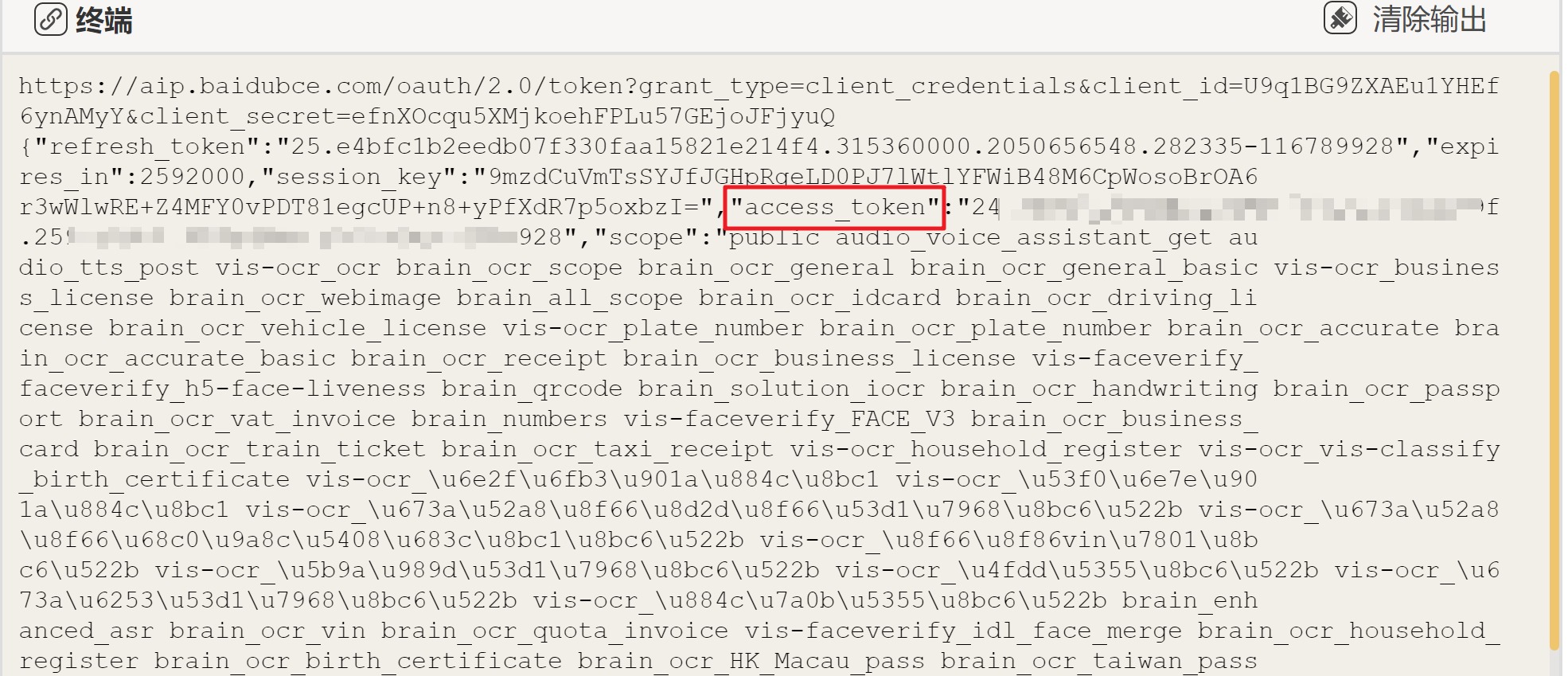
3)运行程序,在终端显示窗口的最上面,可以看到获取的Access_token,复制下来并保存到安全的地方:
三. App组件设计
-
在浏览器地址栏输入 https://code.appinventor.mit.edu/ ,这是国内可稳定访问的MIT官方服务器(点击了解详细使用方法)
-
输入自己的访问码进入编程界面,新建一个项目:
-
按照默认设置输入项目名:
-
导入App需要的扩展文件:
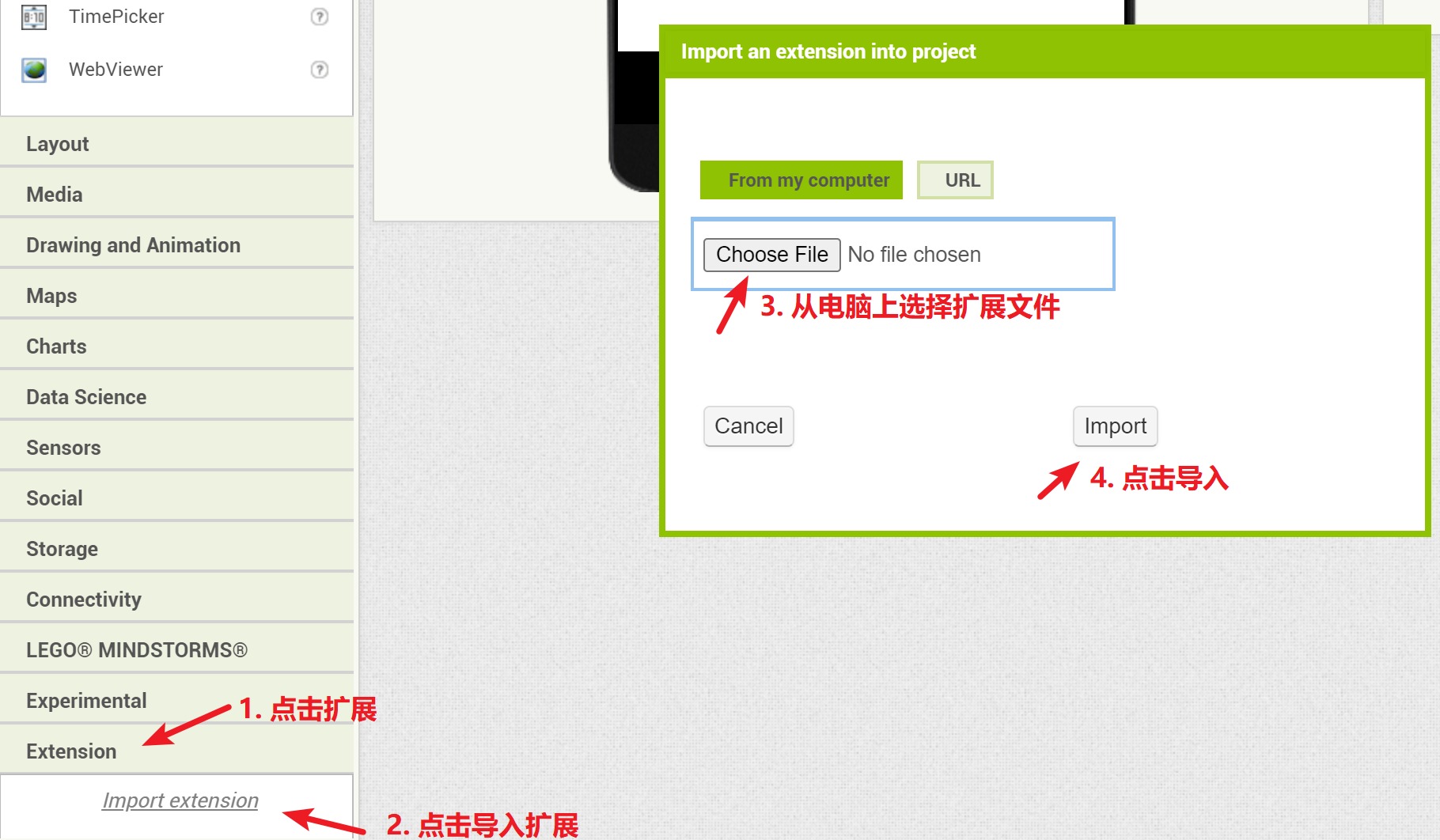
注:扩展文件请在附件中下载。本项目中我们需要导入的扩展文件是com.ghostfox.SimpleBase64.aix,用来将图片文件转换为二进制格式。
-
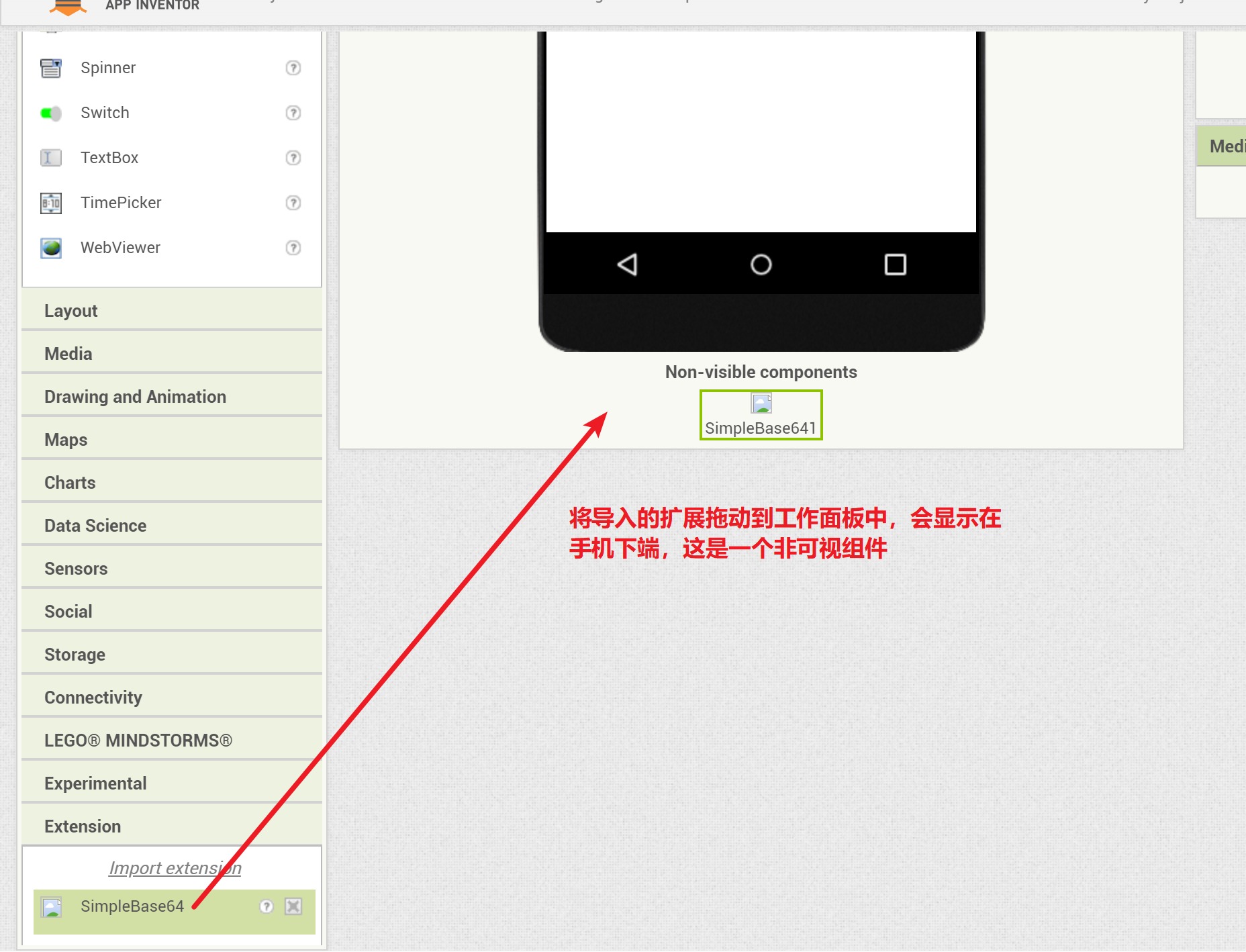
本App我们需要5个组件。
- 从“扩展”抽屉中将SimpleBase64扩展拖动到工作面板中,用来将图片文件转换为二进制格式。
- 从“用户界面”抽屉中添加一个图片组件,用于显示从手机中选择的图片;
- 从“用户界面”抽屉中添加一个标签组件,用于显示识别的文字信息;
- 从“多媒体”抽屉中添加一个“图像选择框”组件,用于从手机相册中选择图片;
- 从“通信连接”抽屉中选择“网络客户端”组件,这也是一个非可视组件,用于向百度大脑发送POST请求并获取图片识别结果。
添加后的界面如下图:
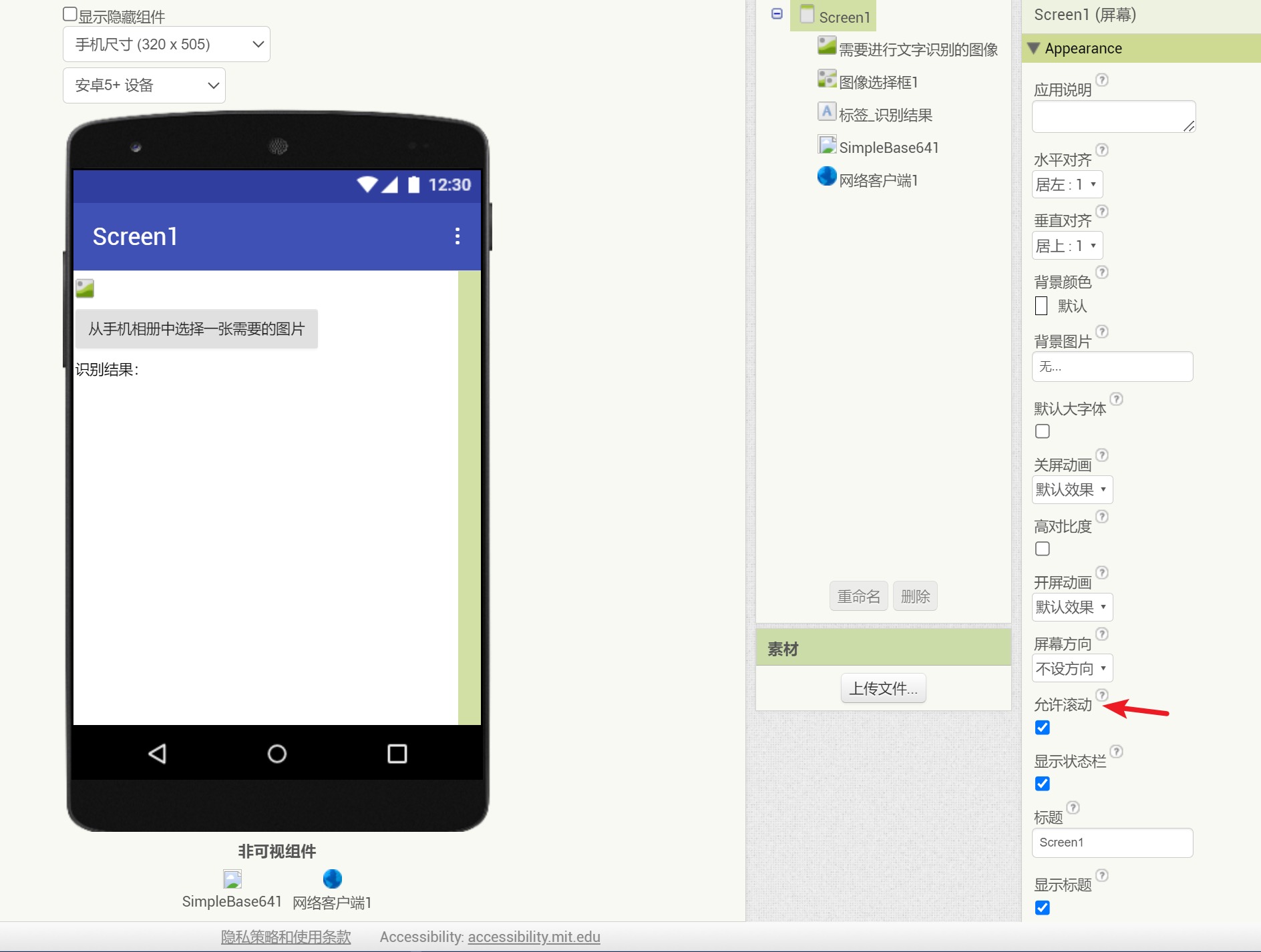
注:将Screen1的“允许滚动”属性勾选,方便我们查看识别的结果。
四. App逻辑设计
切换到逻辑设计窗口
-
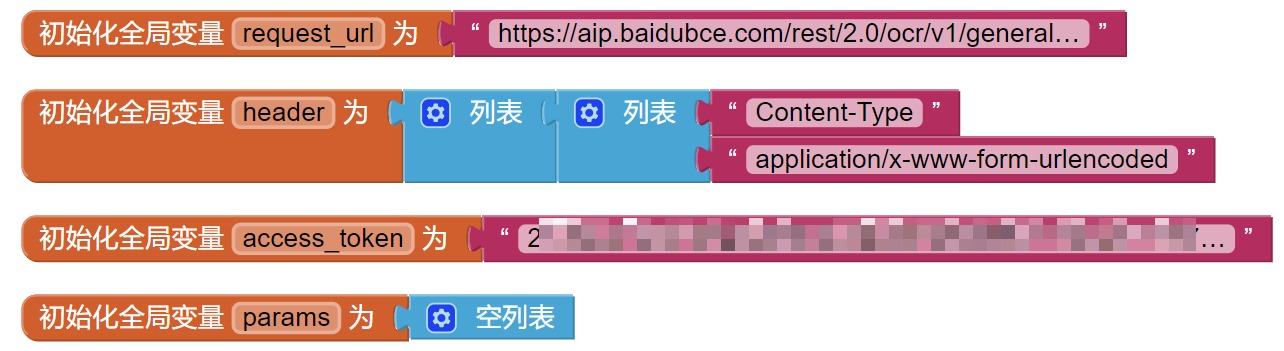
新建几个全局变量:
-
屏幕初始化,按百度要求的格式设置变量request_url

-
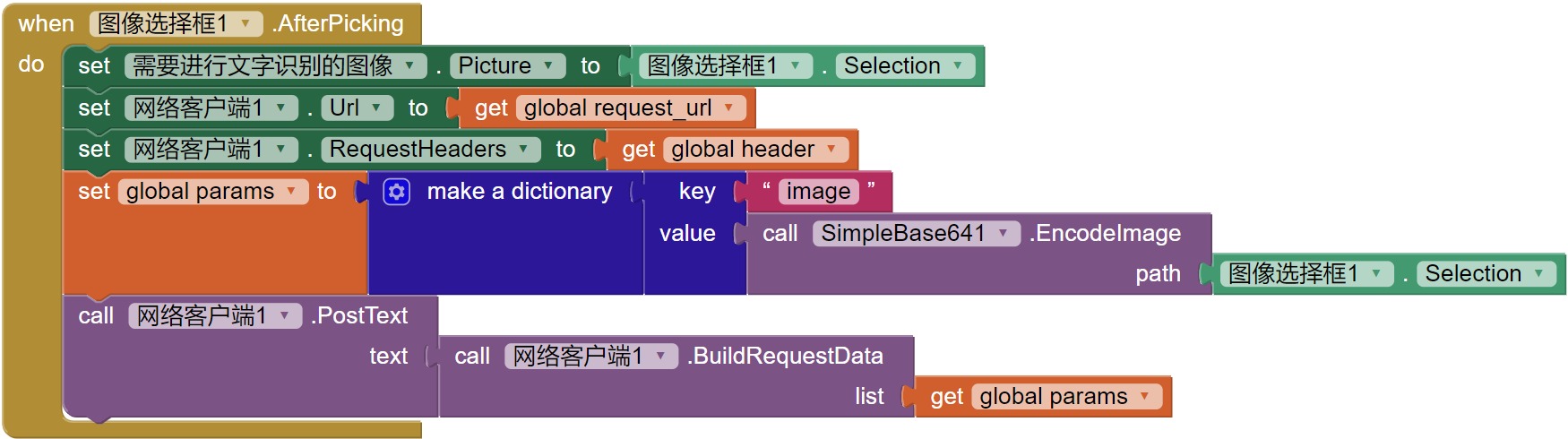
完成从手机相册选择图片后:
- 将“图像”组件的图像属性设置为从相册中选择的图片
- 设置网络客户端1的Url
- 设置网络客户端1的RequestHeaders
- 将图片文件转换为二进制格式,并按照字典格式赋值给变量paramas。字典的key是image,值是图片的二进制格式
- 调用网络客户端1的PostText方法,构建请求数据为参数params
-
当网络客户端1获得文本后,将返回的内容显示到标签中

五. 测试

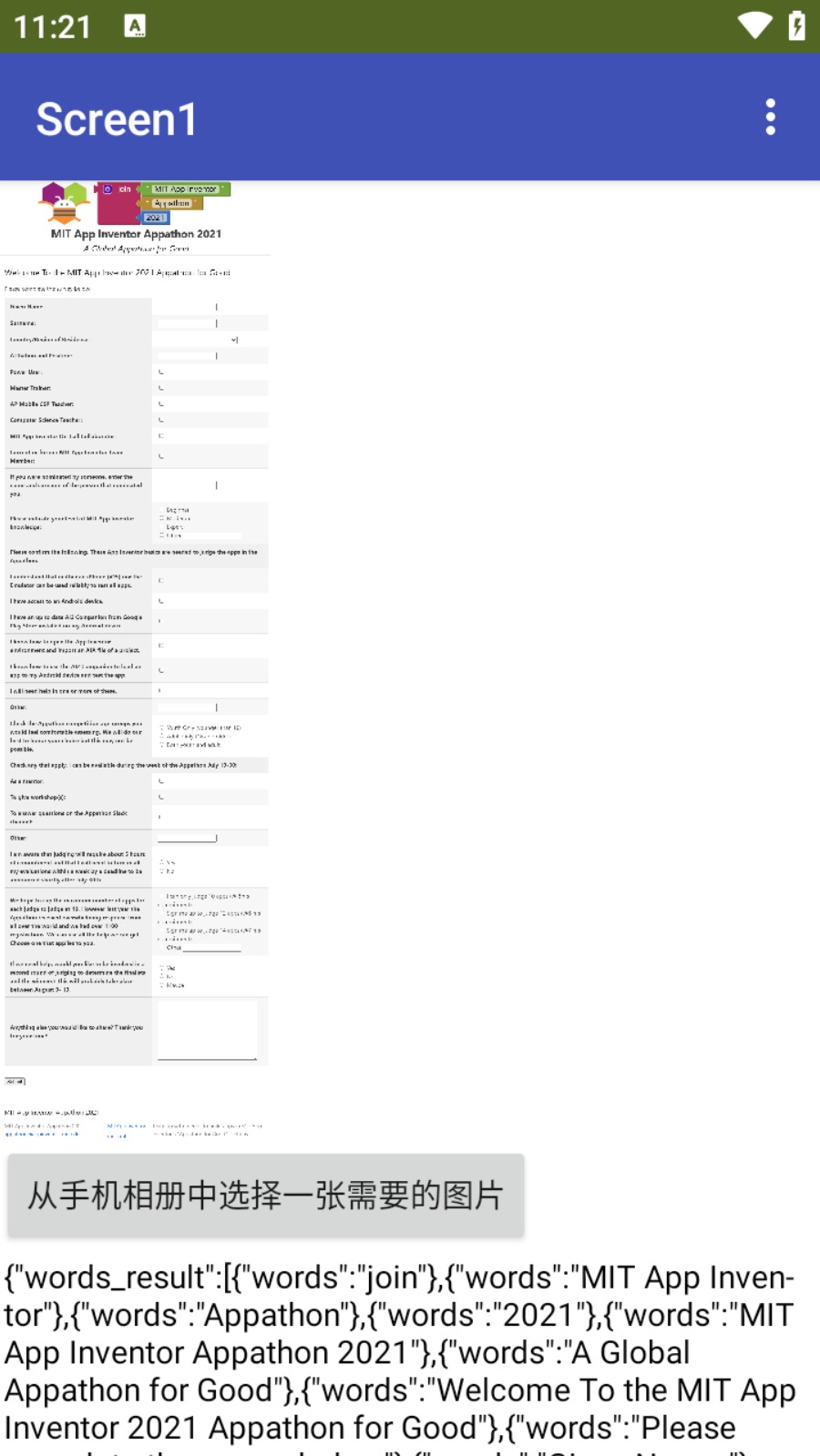
从手机相册中选择一张图片,稍等几秒,识别结果会显示出来:


并登录,登录地址:https://ai.baidu.com/, 如已有百度网盘、百度贴吧账号可以直接登录。
-
登录后,点击左上角的 开放能力 --> 文字识别 --> 通用文字识别
-
点击“立即使用”。
-
早期如是新用户,会有免费的额度,时间大概是半年,现在不清楚是什么情况。目前百度也会有优惠。我购买的是1元优惠包。专项资源包1000次,免费资源5万次,个人调试足够用了。
-
如已购买共享资源包,状态会显示“正在付费使用中”,否则点击箭头所指的“购买共享资源包”,购买需要的资源。
-
下单后,会跳转到支付页面
-
支付成功后点击图中“应用数”下方的数字,
或直接在浏览器地址栏输入地址:
https://console.bce.baidu.com/ai-engine/old/#/ai/ocr/app/list
-
在打开的页面中点击“创建应用”
-
输入应用名称,并选择需要的接口。
设置好其他参数,点击”立即创建“
注意:为了安全可以只选择需要的接口。如果应用以后还要需要用到其他接口,可以将接口全选,如果接口没有选择,是无法请求的。
-
应用创建成功后,会进入应用列表,在新创建的应用中,复制该应用对应的APK Key和Secret Key,并保存到相应位置,我们后面获取Access Token的时候需要用到。
二. 获取百度通用文字识别API相关参数
-
进入页面后,点击页面上方的“使用方式”,在“公有云服务”下点击“API文档”,
-
下图中的参数是我们在App Inventor中需要使用的:
-
输入地址:https://ai.baidu.com/ai-doc/REFERENCE/Ck3dwjhhu 。进入鉴权谁机制页面,准备获取Access_token。
鉴权的主要目的是获取Access_token。Access_token是用户的访问令牌,承载了用户的身份、权限等信息。鉴权主要分为以下两步:
1)获取AK/SK(参考前面步骤一的第10步)
2) 获取Access_token
- 代码形式→适用于有计算机基础的用户
- 网页调试工具→适用于零基础的用户
- 在线调试工具(推荐)→快速调试接口效果
-
获取Access_token
1). 这里我们使用方式一:代码形式来获取Access_token。在第3步同样的页面下,选择语言,并点击复制:
2) 运行Mind+,新建一个python程序,粘贴前面复制的程序,并添加几行代码,api_key和screet_key使用自己前面保存下来的key,如下图:
3)运行程序,在终端显示窗口的最上面,可以看到获取的Access_token,复制下来并保存到安全的地方:
三. App组件设计
-
在浏览器地址栏输入 https://code.appinventor.mit.edu/ ,这是国内可稳定访问的MIT官方服务器(点击了解详细使用方法)
-
输入自己的访问码进入编程界面,新建一个项目:
-
按照默认设置输入项目名:
-
导入App需要的扩展文件:
注:扩展文件请在附件中下载。本项目中我们需要导入的扩展文件是com.ghostfox.SimpleBase64.aix,用来将图片文件转换为二进制格式。
-
本App我们需要5个组件。
- 从“扩展”抽屉中将SimpleBase64扩展拖动到工作面板中,用来将图片文件转换为二进制格式。
- 从“用户界面”抽屉中添加一个图片组件,用于显示从手机中选择的图片;
- 从“用户界面”抽屉中添加一个标签组件,用于显示识别的文字信息;
- 从“多媒体”抽屉中添加一个图像选择框组件,用于从手机相册中选择图片;
- 从“通信连接”抽屉中选择网络客户端组件,这也是一个非可视组件,用于向百度大脑发送POST请求并获取图片识别结果。
添加后的界面如下图:
注:将Screen1的“允许滚动”属性勾选,方便我们查看识别的结果。
四. App逻辑设计
切换到逻辑设计窗口
-
新建几个全局变量:
-
屏幕初始化,按百度要求的格式设置变量request_url
-
完成从手机相册选择图片后:
- 将“图像”组件的图像属性设置为从相册中选择的图片
- 设置网络客户端1的Url
- 设置网络客户端1的RequestHeaders
- 将图片文件转换为二进制格式,并按照字典格式赋值给变量paramas。字典的key是image,值是图片的二进制格式
- 调用网络客户端1的PostText方法,构建请求数据为参数params
-
当网络客户端1获得文本后,将返回的内容显示到标签中
五. 测试
从手机相册中选择一张图片,稍等几秒,识别结果会显示出来:
选择另一张图片进行识别:
选择一张长图片,识别的结果可以滑动手机查看:
思考:
如何制作实现语音识别、图像识别等功能的App?
视频教程:
|
|
|
|
|
|
|
|
|
|





 沪公网安备31011502402448
沪公网安备31011502402448

 置顶卡
置顶卡 变色卡
变色卡 千斤顶
千斤顶
 版主限定
版主限定
 创作达人
创作达人
 编辑选择奖
编辑选择奖
 ARD DAY
ARD DAY
 编辑选择奖
编辑选择奖
 星球译员
星球译员
 编辑选择奖
编辑选择奖
 编辑选择奖
编辑选择奖
 编辑选择奖
编辑选择奖
 编辑选择奖
编辑选择奖
 编辑选择奖
编辑选择奖






