|
5106| 2
|
[讨论分享] 如何用LattePanda Mu部署DeepSeek-R1蒸馏模型? |

 前言 在大语言模型的训练过程中,如何有效提升推理能力,一直是科研人员关注的重点。 传统的推理模型通常依赖大量数据和计算资源,但通过调整计算策略和训练方法,许多模型的表现得以显著改善。这一思路,最终催生了DeepSeek的突破性进展——DeepSeek-R1模型。 DeepSeek-R1并不仅仅是一个简单的语言模型,它通过创新性的训练方法,特别是将强化学习(RL)应用于基础语言模型的推理训练,取得了令人瞩目的成果。与传统的监督学习方式不同,DeepSeek-R1的训练完全不依赖人工标注,而是通过强化学习的奖励机制,使模型自行提升推理能力。在这一过程中,模型通过不断自我反馈,逐步学会如何处理复杂的推理任务,如数学问题、编程逻辑等。 这一技术创新的关键在于,DeepSeek-R1采用了一个特别的训练流程,它在基础模型的基础上,通过两轮强化学习和精细调优,逐步完善了模型的推理能力。在最初的“冷启动”阶段,DeepSeek-R1会通过一小部分精心设计的样本进行微调,以提高模型的推理清晰度和可读性。接下来,模型进入了强化学习阶段,通过拒绝低质量的输出,并依据反馈奖励机制进行优化,最终实现了推理能力和答案的清晰度的双重提升。 值得一提的是,DeepSeek-R1的训练方法不仅仅依赖于传统的数据集,而是精心构建了适用于推理任务的数据混合,以更好地培养模型在特定领域中的表现。通过这种方法,DeepSeek-R1能够在无需大量人工干预的情况下,高效地学习如何进行推理推导和复杂问题的解决。 如何本地部署? 在了解DeepSeek-R1模型的创新和强大推理能力后,我们不禁想要探索一个更具挑战性的问题:如何将这一强大的推理能力带到实际应用中,尤其是在硬件资源相对有限的设备上运行? 传统的主板如Jetson Orin、Nano,虽然性能强大,但是要么价格昂贵要么尺寸偏大,再加上受限于特定的系统环境,在实际场景可能会遇到一系列困难,不过现在你有一个更好的选择——LattePanda Mu。 LattePanda Mu是一款高性能微型x86计算模块,搭载了Intel N100四核处理器,配备了8GB的LPDDR5内存和64GB的存储空间。凭借这些强劲的硬件配置,LattePanda Mu能够提供流畅的计算和推理能力,适合运行复杂的深度学习任务。此外,LattePanda Mu提供了丰富的扩展接口,包括3个HDMI/DisplayPort接口、8个USB 2.0接口、最多4个USB 3.2接口以及最多9个PCIe 3.0通道。这些接口使得LattePanda Mu在连接外部设备和定制硬件方面非常灵活。 最特别的是,LattePanda Mu还提供了开源的载板设计文件,意味着用户可以根据自己的需求,定制或设计特定的载板。这使得LattePanda Mu不仅仅是一款普通的计算模块,而是一个可以根据项目需求进行灵活扩展和定制的开发平台。 为了在LattePanda Mu上顺利运行DeepSeek-R1模型,我们首先需要选择一个合适的框架来高效加载和执行大语言模型,根据Deepseek官方说明,本地部署可以使用VLLM和SGLang的方式,但是通常情况下,这两种调用方法不仅操作复杂还占用量大,再加上目前MU N100 无法在Lunix环境下使用OpenVINO™加速,因此今天我们推荐另一种高效快捷的方法——Ollama。 只需要执行以下简单的两个指令就可以一键运行R1模型。 安装Ollama  在Ollama官网下载安装:https://ollama.com/download 如果你也使用Ubuntu系统,可以直接通过指令 进行一键安装。 同理你也可以安装在其他系统上。 下载并运行Deepseek-R1 我们根据硬件的性能以及实际的需求来选择不同参数大小的模型: 没有配备专业级显卡的,推荐用14B以内的模型。 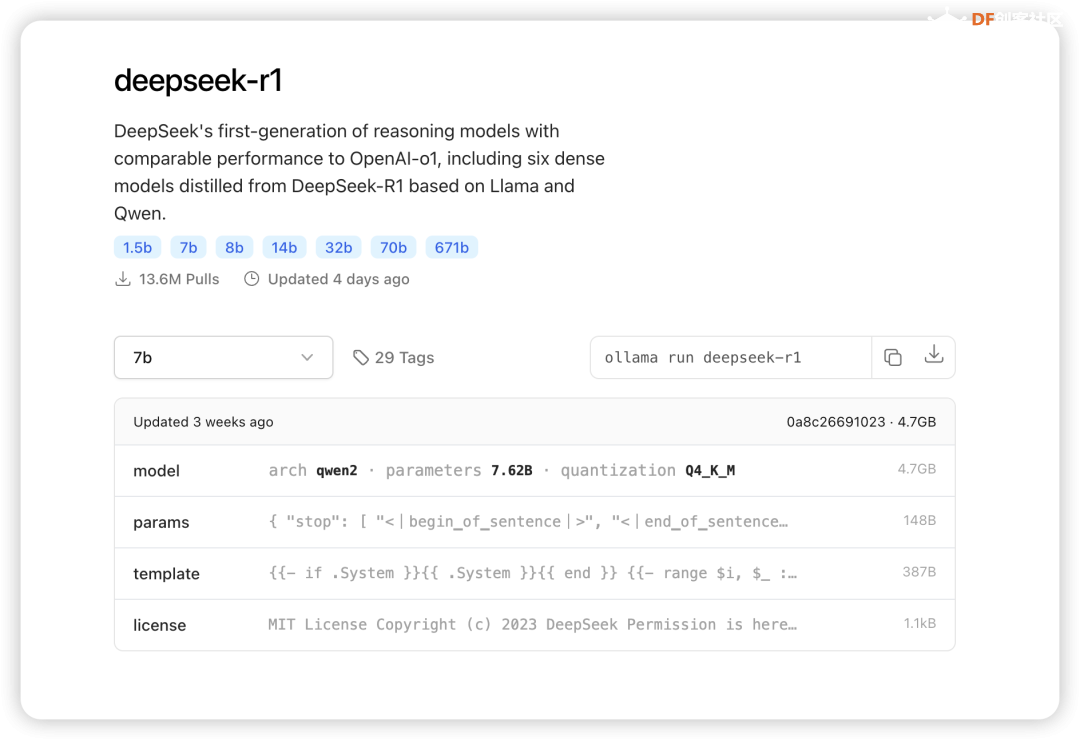 32b,70b,671b对机器的要求如下: DeepSeek-R1-Distill-Qwen-32B
DeepSeek-R1-Distill-Llama-70B
DeepSeek-R1 671B(完整模型)
需要注意的是,对于671B模型:
总的来说,32B和70B模型可以在高端消费级硬件上运行,而671B模型则需要企业级或数据中心级的硬件配置。选择合适的硬件配置时,还需考虑具体的使用场景、性能需求和预算限制。 LP Mu 运行速度参考 对于不同规格的Mu和R1模型,在Ollama的运行速度参考如下(tokens/s): 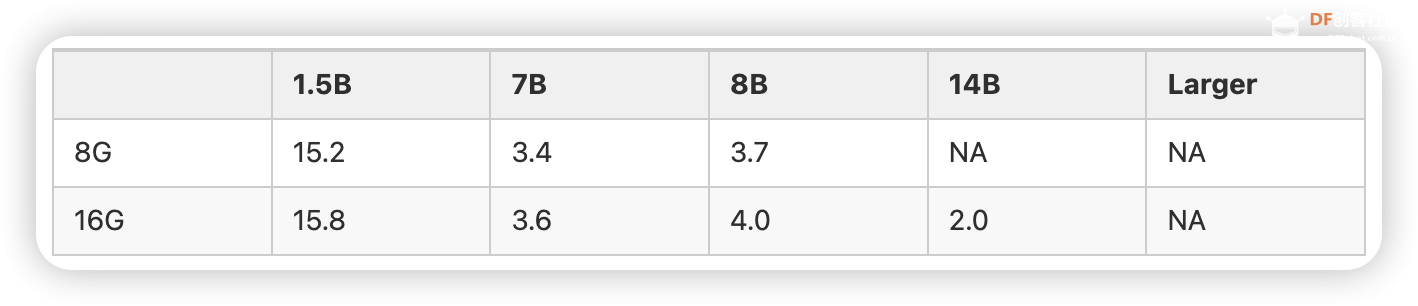 注:8B模型基于Llama-3.1-8B蒸馏,7B模型基于Qwen2.5-Math-7B蒸馏,如果是老师在学校使用更推荐7B,符合中国宝宝体质。 Ollama官方提供了计算推理速度的工具,只要在聊天窗口输入/set verbose就能使其在每次回复后自动输出运行速度, 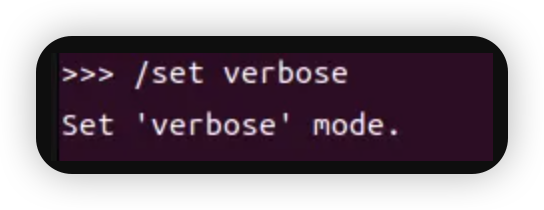 输出结果如下所示: 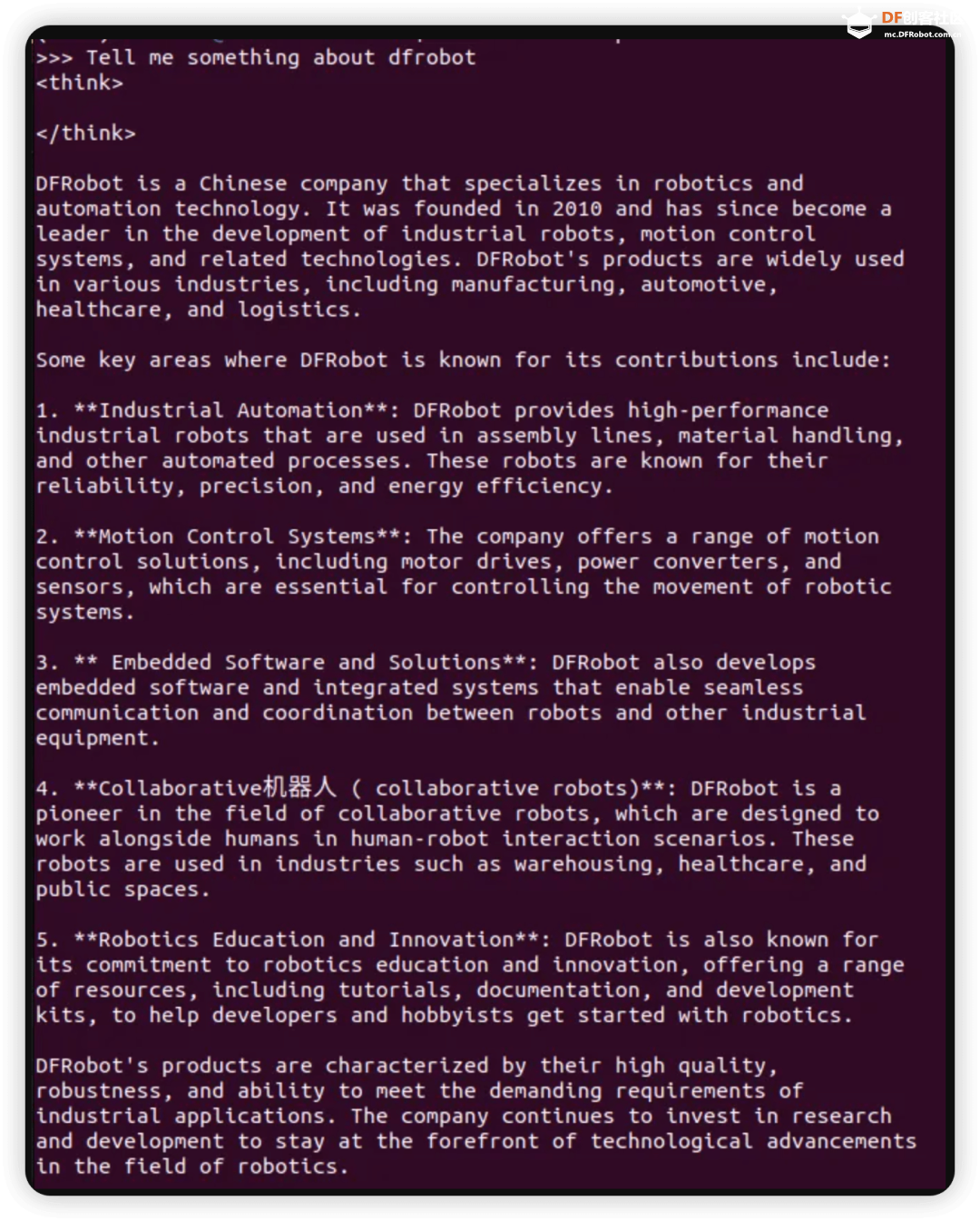 这样,理论上我们已经可以正常使用啦! 配置浏览器访问 除了在命令行里运行Ollama,我们可以使用一个名为Page Assist的浏览器插件,这款插件可以让我们能够在浏览器页面运行我们的本地大模型。  你可以通过访问Chrome插件链接直接安装, 也可以通过 Page Assist的GitHub界面所述的步骤进行安装。 安装好插件后,就可以设置下 Ollama 的模型, 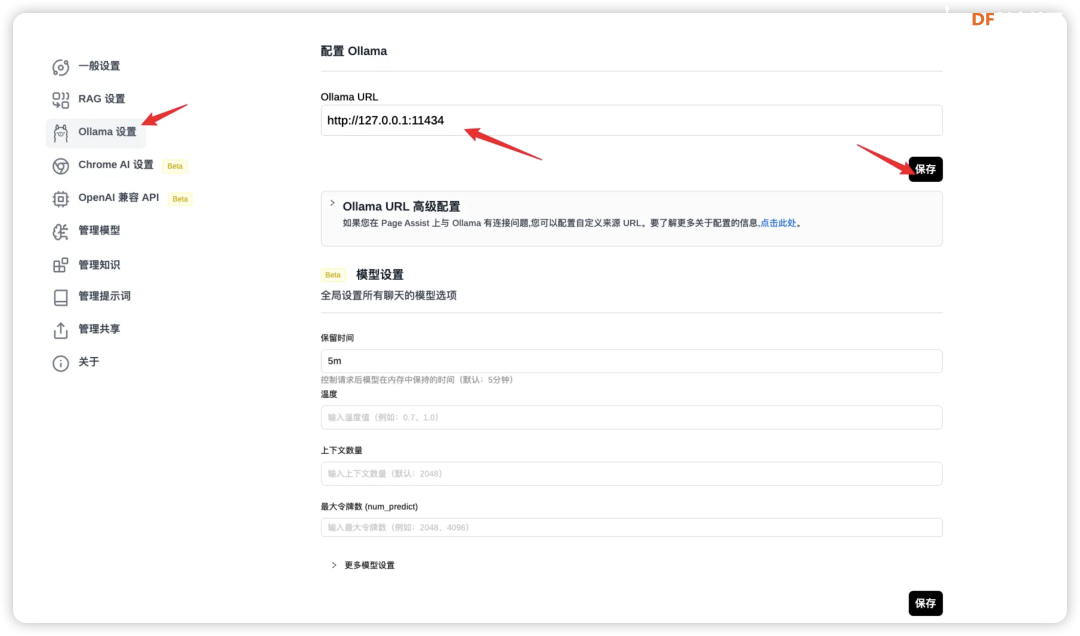 设置好相应的地址后就可以保存了,这样就可以使用相应的模型进行问答了。 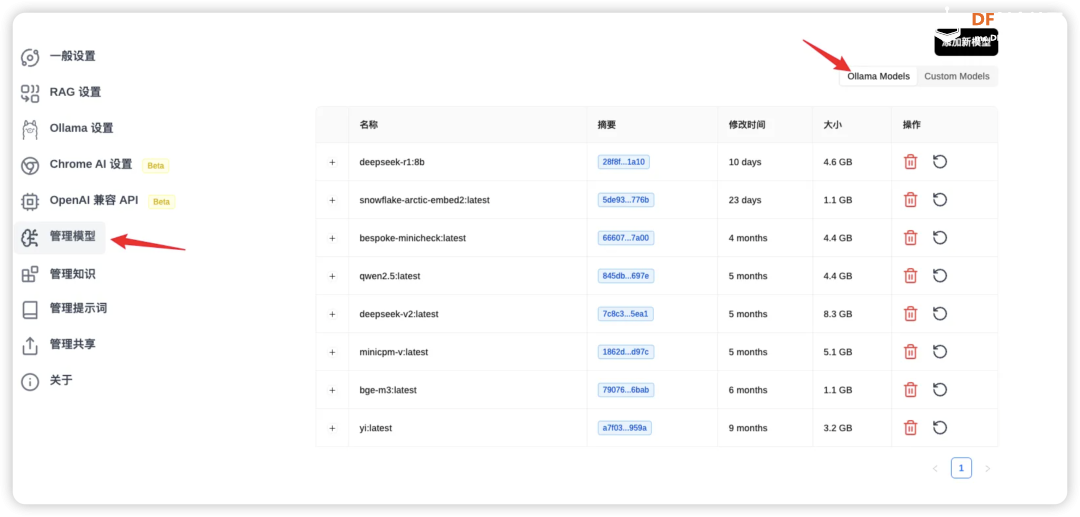 如果有很多的模型,也可以在管理模型中进行管理和添加。 为了更好的使用模型,我们也可以增加自己的知识库,在使用知识库之前需要进行RAG 设置。 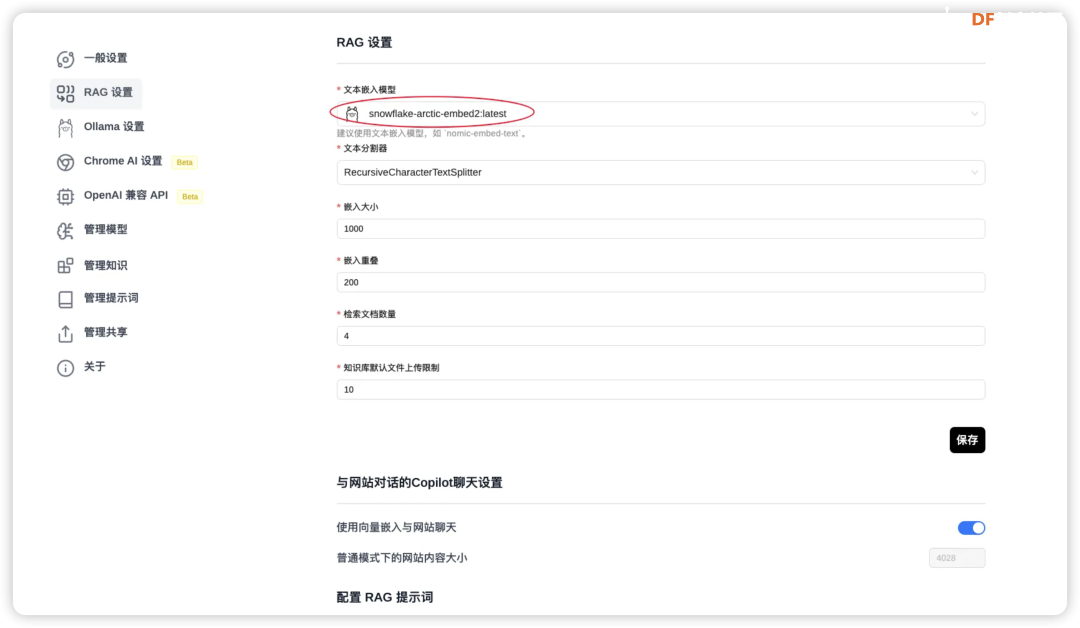 我选择了snowflake-arctic-embed2的 embedded 模型,也可以选择推荐的模型,如果没有,可以到管理模型中添加。 完成后就可以通过管理知识进行知识库的添加。 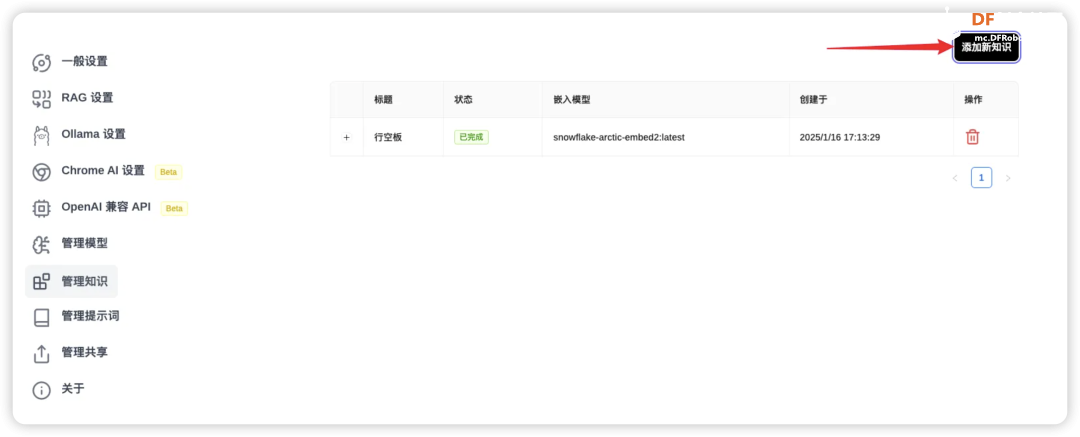  然后就可以打开界面选择模型进行对话了。 Page Assist还有一些其他的功能,比如管理知识,管理提示词等等,大家可以自行研究一下,重要的是,现在我们使用起来更直观一些了! 应用场景 DeepSeek R1 模型在多种领域展现了其强大的适应性和高效的推理能力,其中一个令人印象深刻的应用场景便是通过自然语言指令生成SQL查询。 想象一下,传统上编写复杂的数据库查询语句可能需要开发者深厚的SQL知识和经验,而 DeepSeek 模型的独特之处在于,它能够理解和解析用户的自然语言输入,并自动生成精确的SQL查询。这不仅大大降低了使用门槛,还使得非技术用户也能通过简洁的语言指令与数据库进行高效交互。(特别是他们所在的还是数据敏感型部门) 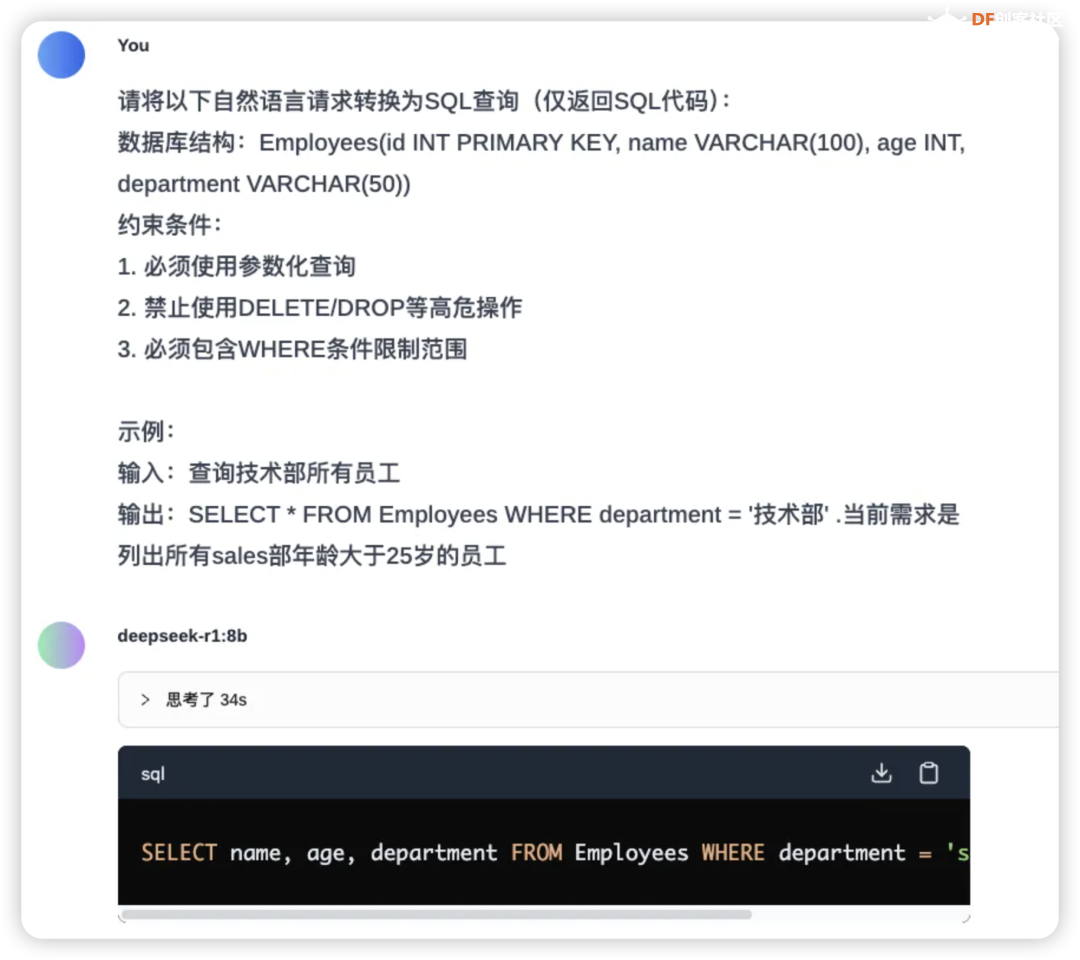 更进一步,DeepSeek 还具备强大的语境理解的能力,能够根据不同的业务背景和需求,生成个性化的查询。无论是关系型数据库的表格操作,还是跨表的复杂查询,DeepSeek都能得心应手地处理,真正实现“人机无缝对接”的理想。 结尾 随着技术不断发展,SBC(单板计算机)和类似 LattePanda Mu 的小型计算平台为边缘计算、低功耗设备和定制化场景提供了更多可能,而 DeepSeek 模型的灵活性和强大推理能力则为这些平台注入了巨大的潜力。无论是在数据库查询生成、文本理解还是其他智能应用领域,DeepSeek都展现了很大的价值。 在未来,随着 LattePanda Mu 和 DeepSeek 等平台的不断优化与进化,我们可以预见,越来越多的开发者和研究者将能在各种硬件环境中充分利用深度学习和大语言模型的优势,推动更智能、更高效的应用落地。 转载请注明来源信息 |



 沪公网安备31011502402448
沪公网安备31011502402448© 2013-2026 Comsenz Inc. Powered by Discuz! X3.4 Licensed

 置顶卡
置顶卡 变色卡
变色卡 千斤顶
千斤顶

 萌萌哒新人
萌萌哒新人
 宣传大使
宣传大使
 小蘑菇
小蘑菇
 ARD DAY
ARD DAY
 编辑选择奖
编辑选择奖
 摸鱼团员
摸鱼团员
 编辑选择奖
编辑选择奖
 编辑选择奖
编辑选择奖
 编辑选择奖
编辑选择奖






