本帖最后由 豆爸 于 2025-6-21 17:21 编辑
【项目背景】
电影已成为人们日常生活中重要的娱乐方式之一。传统的电影信息获取方式,如通过线下海报、电视广告或搜索引擎查找,不仅效率较低,而且信息整合不够全面。
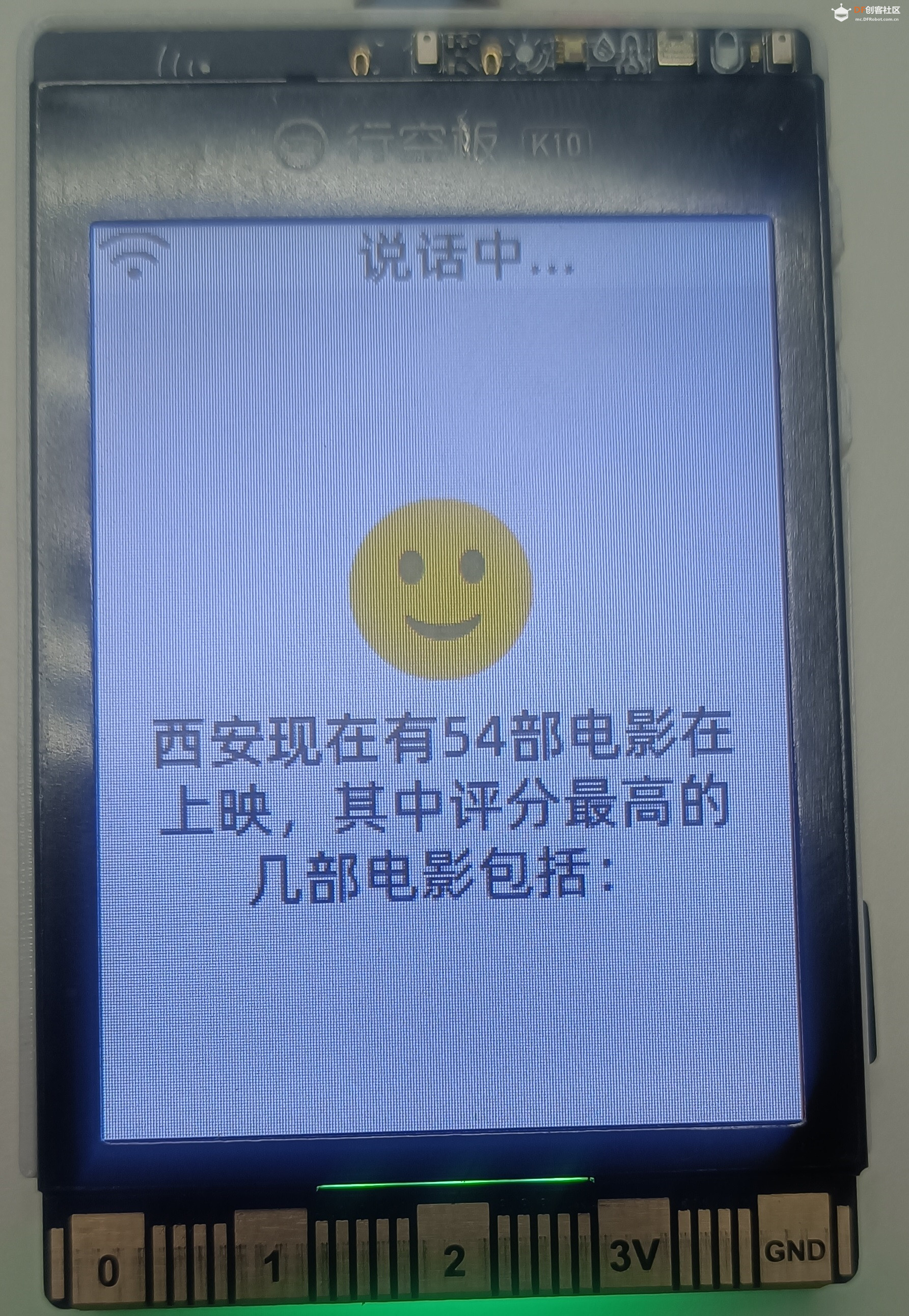
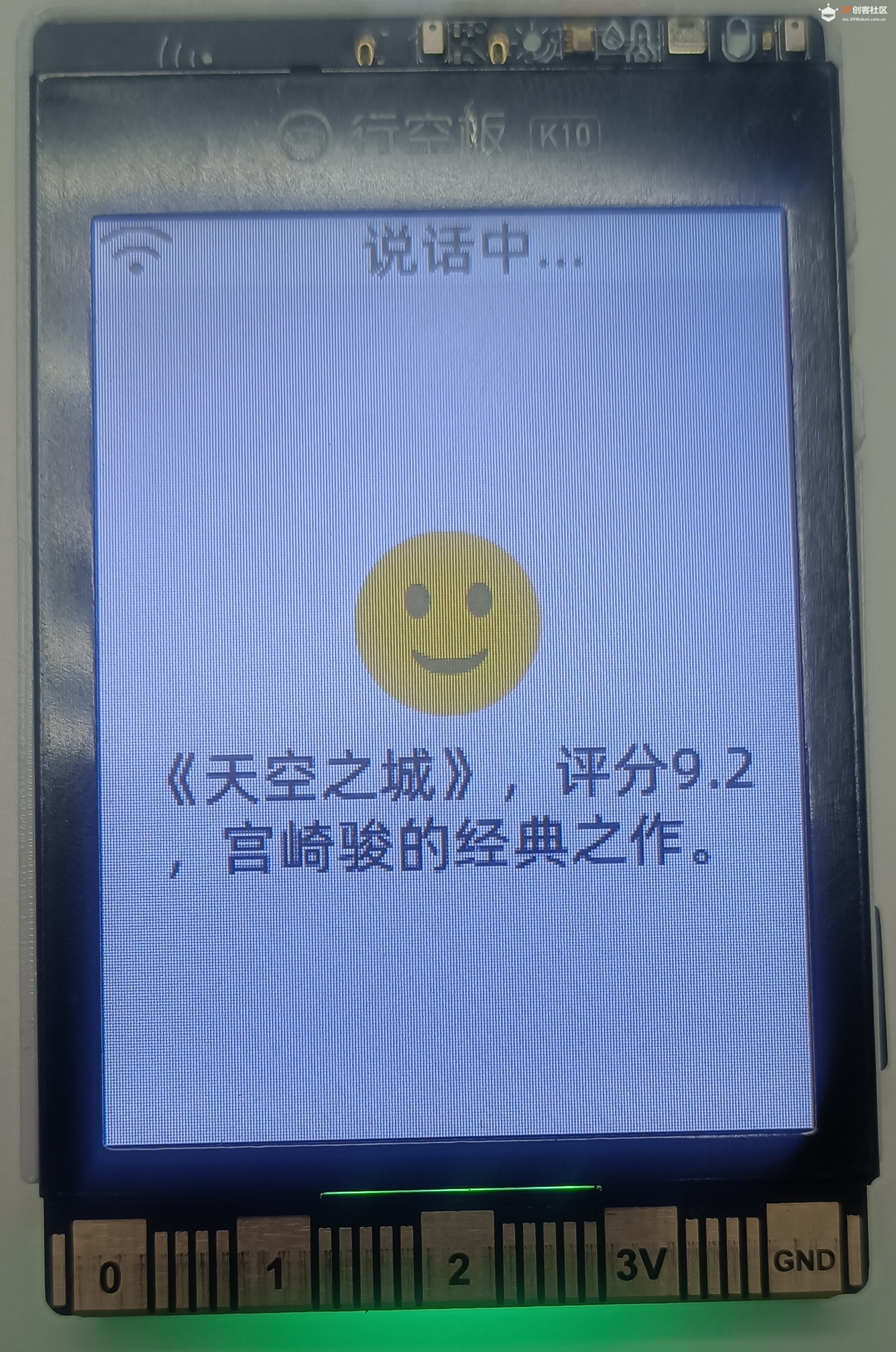
本项目旨在利用行空板 K10 的硬件优势和小智 AI 的智能交互能力,结合 MCP 服务器强大的数据处理与传输功能,搭建一个便捷、高效的院线热映电影查询系统。用户只需通过简单的语音指令,就能快速获取最新的院线热映电影信息,包括上映电影数量、片名、上映时间、片长、地区、导演、主演、评分、海报等信息,为观影决策提供便利,提升观影体验。
【硬件准备】
1. 行空板 K10
作为智能交互终端的核心硬件,行空板 K10 具备丰富的接口与较强的计算能力,是刷写小智 AI 固件的载体。其高性能处理器、大容量内存及存储空间,能够保障小智 AI 固件稳定运行,实现语音识别、自然语言处理等功能,完成与用户的语音交互。
2. 行空板 M10+行空板M10扩展板组合
用于搭建 MCP 服务器,行空板 M10 凭借自身硬件性能,可高效存储和管理院线热映电影的相关数据,如电影名称、上映时间、剧情简介、评分等。同时,它能稳定接收行空板 K10 发送的查询请求,快速从数据库检索对应电影信息,并将结果精准返回给 K10,为整个电影查询系统提供数据支撑。
【项目实施步骤】
1. 行空板K10刷入小智AI固件
(1)固件下载
https://github.com/78/xiaozhi-es ... 5/v1.7.5_df-k10.zip
从上面地址下载行空板K10小智AI固件。
(2)烧录工具
https://img.dfrobot.com.cn/wikic ... 949cb74e51e5f91.zip
从上面地址下载烧录工具。
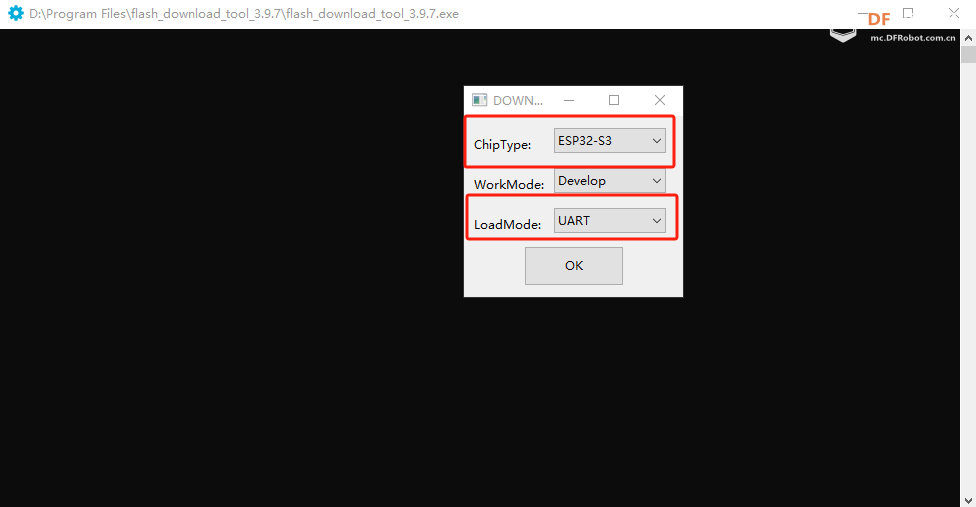
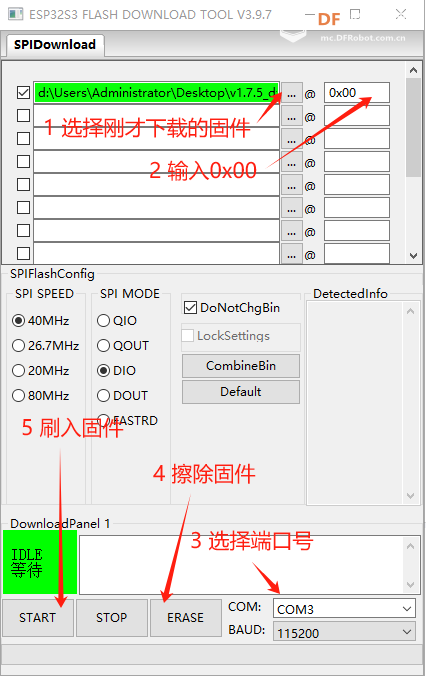
(3)烧录固件
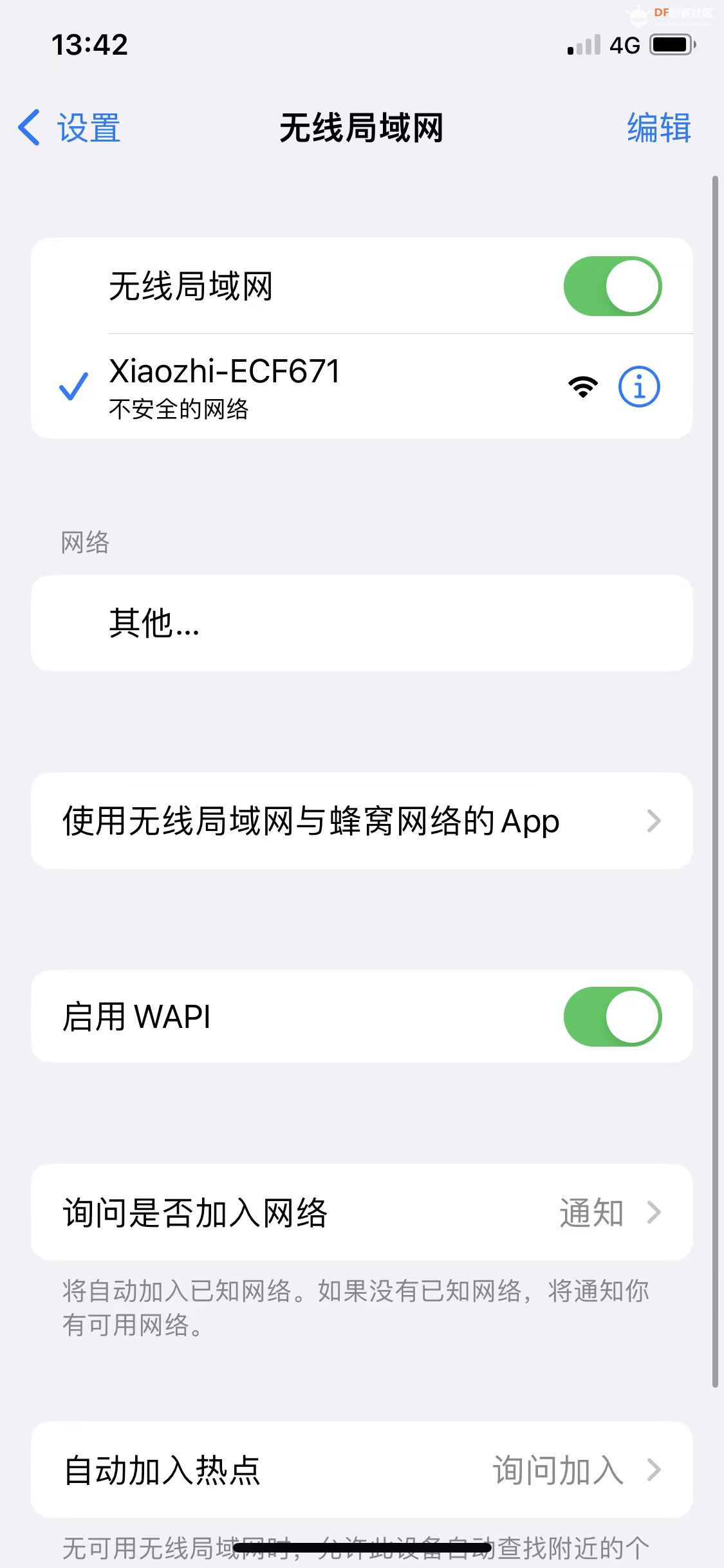
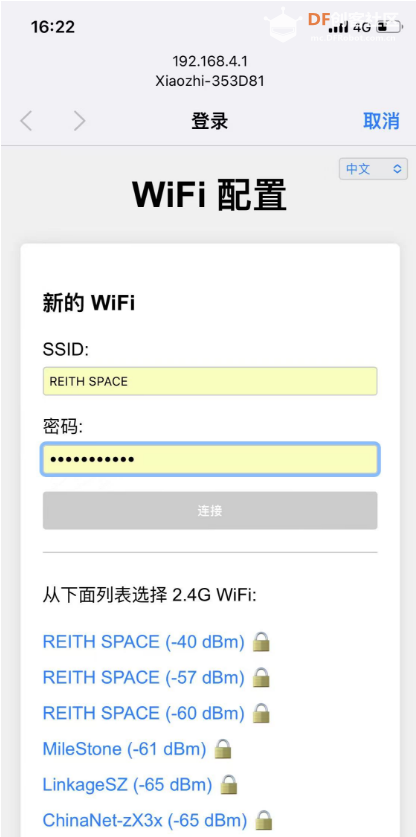
(3)小智AI配网
使用手机或电脑连接 Xiaozhi-XXXX的热点。
浏览器访问192.168.4.1,打开如下图所示页面,选择wifi,填入密码,点击连接。
设备将自动连接到 Wi-Fi,并显示 登录 成功标志,表示已经配置网络成功,设备将在 3 秒后自动重启。
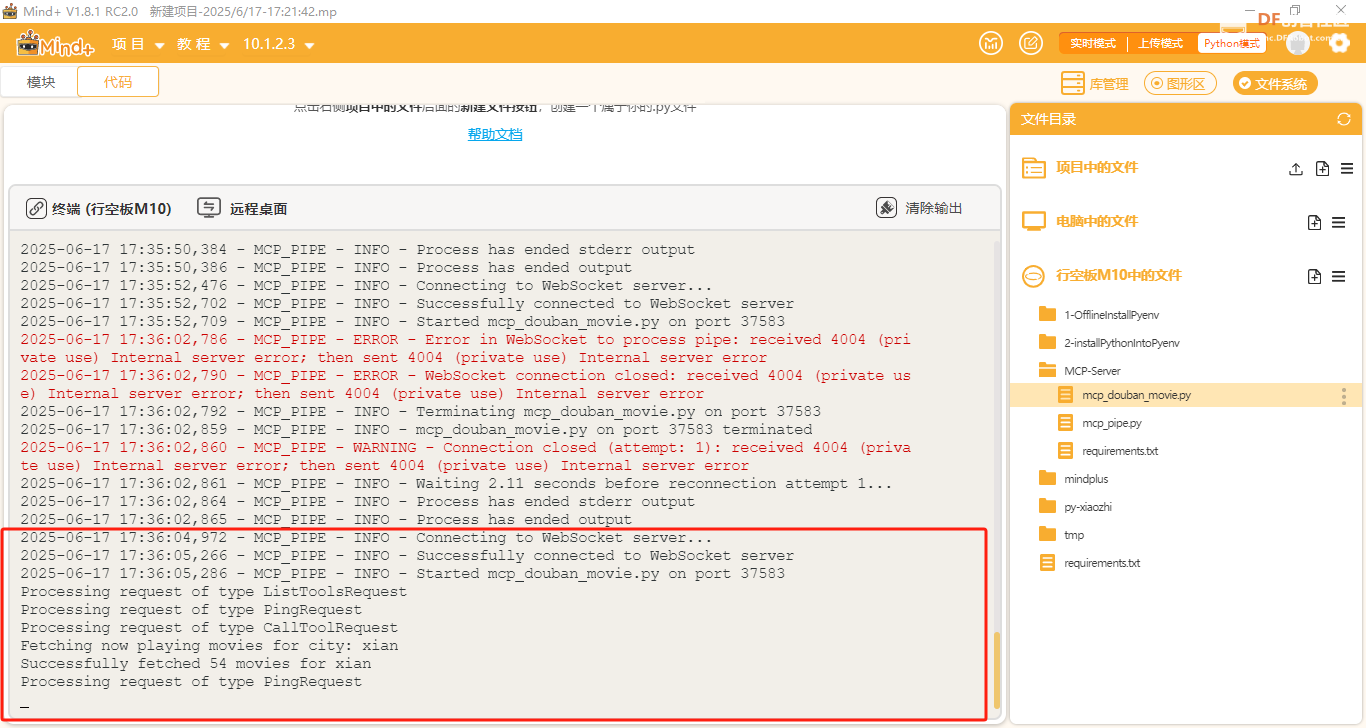
2. 编写MCP服务器
- # mcp_douban_movie.py
- from mcp.server.fastmcp import FastMCP
- import sys
- import logging
- import requests
- from bs4 import BeautifulSoup
- import json
-
- # 设置日志记录器
- logger = logging.getLogger('DoubanMovieServer')
-
- # 修复Windows控制台UTF-8编码问题
- if sys.platform == 'win32':
- sys.stderr.reconfigure(encoding='utf-8')
- sys.stdout.reconfigure(encoding='utf-8')
-
- # 创建MCP服务器
- mcp = FastMCP("DoubanMovieServer")
-
- @mcp.tool()
- def get_now_playing_movies(city_pinyin_name: str) -> dict:
- """
- 获取指定城市当前正在上映的电影列表。当需要查询当前电影院正在上映的电影时使用此工具。
- 参数city_pinyin_name是城市的拼音名称,例如'beijing'、'shanghai'、'xian'等。
- 返回一个字典,包含以下键:
- - 'success': 操作是否成功 (bool)
- - 'count': 实际返回的热映电影数量 (int)
- - 'result': 电影信息列表,每个元素是一个包含以下键的字典:
- * 'poster_image_url': 电影海报图片的完整URL
- * 'movie_title': 电影名称
- * 'release_date': 上映时间(年份)
- * 'directors': 导演列表
- * 'main_actors': 主演列表
- * 'rating': 电影评分(浮点数)
- """
- result = {
- 'success': False,
- 'count': 0,
- 'result': []
- }
-
- # 构造豆瓣电影URL
- url = f'https://movie.douban.com/cinema/nowplaying/{city_pinyin_name}/'
- headers = {
- 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36',
- 'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8'
- }
-
- try:
- logger.info(f"Fetching now playing movies for city: {city_pinyin_name}")
-
- # 发送HTTP请求
- response = requests.get(url, headers=headers, timeout=10)
- response.raise_for_status()
-
- # 解析HTML内容
- soup = BeautifulSoup(response.text, 'html.parser')
- nowplaying_div = soup.find('div', id='nowplaying')
- if not nowplaying_div:
- logger.warning("No 'nowplaying' div found on the page")
- return result
-
- movie_items = nowplaying_div.select('ul.lists > li.list-item')
-
- if not movie_items:
- logger.warning("No movie items found in the 'nowplaying' section")
- return result
-
- # 提取电影信息
- movies = []
- for item in movie_items:
- movie = extract_movie_info(item)
- if movie:
- movies.append(movie)
-
- # 构建结果
- result['success'] = True
- result['count'] = len(movies)
- result['result'] = movies
- logger.info(f"Successfully fetched {len(movies)} movies for {city_pinyin_name}")
-
- except requests.exceptions.RequestException as e:
- logger.error(f"Request failed: {e}")
- except Exception as e:
- logger.error(f"Error occurred: {e}")
-
- return result
-
- def extract_movie_info(item):
- try:
- # 从data属性获取基本信息
- data_title = item.get('data-title', '')
- data_director = item.get('data-director', '')
- data_actors = item.get('data-actors', '')
- data_release = item.get('data-release', '')
- data_score = item.get('data-score', '0')
-
- # 处理导演和演员信息
- directors = [d.strip() for d in data_director.split('/')] if data_director else []
- main_actors = [a.strip() for a in data_actors.split('/')] if data_actors else []
-
- # 海报图片URL
- poster_img = item.select_one('li.poster img')
- poster_image_url = poster_img['src'] if poster_img and 'src' in poster_img.attrs else ""
-
- # 电影标题 - 优先使用data-title属性
- movie_title = data_title
-
- # 评分处理
- rating = 0.0
- try:
- # 尝试从data-score属性获取评分
- if data_score and data_score != '0':
- rating = float(data_score)
- else:
- # 如果data-score不可用,尝试从页面元素获取
- rating_tag = item.select_one('li.srating span.subject-rate')
- if rating_tag and rating_tag.text.strip():
- rating = float(rating_tag.text.strip())
- except (ValueError, TypeError):
- pass
-
- movie_info = {
- 'poster_image_url': poster_image_url,
- 'movie_title': movie_title,
- 'release_date': data_release,
- 'directors': directors,
- 'main_actors': main_actors,
- 'rating': rating
- }
-
- logger.debug(f"Extracted movie: {movie_info['movie_title']}")
- return movie_info
-
- except Exception as e:
- logger.error(f"Error extracting movie info: {e}")
- return None
-
- # 启动服务器
- if __name__ == "__main__":
- mcp.run(transport="stdio")
3. 将上述文件传至行空板M10
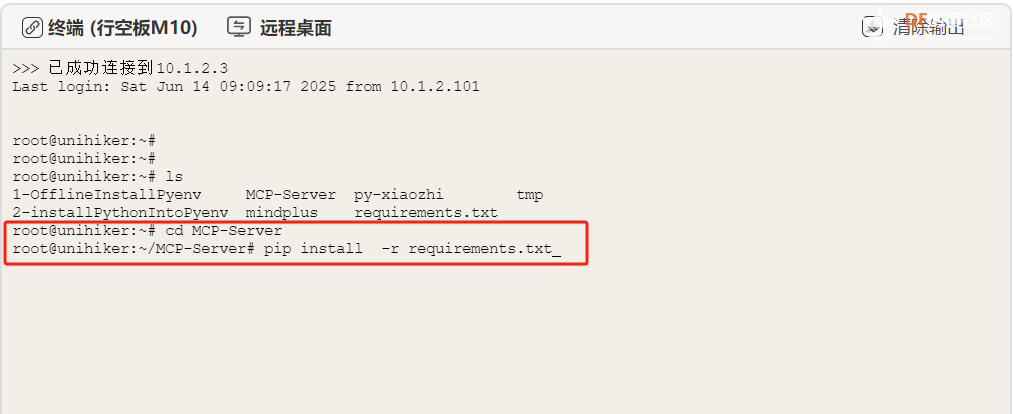
4. 安装依赖库
pip install -r requirements.txt
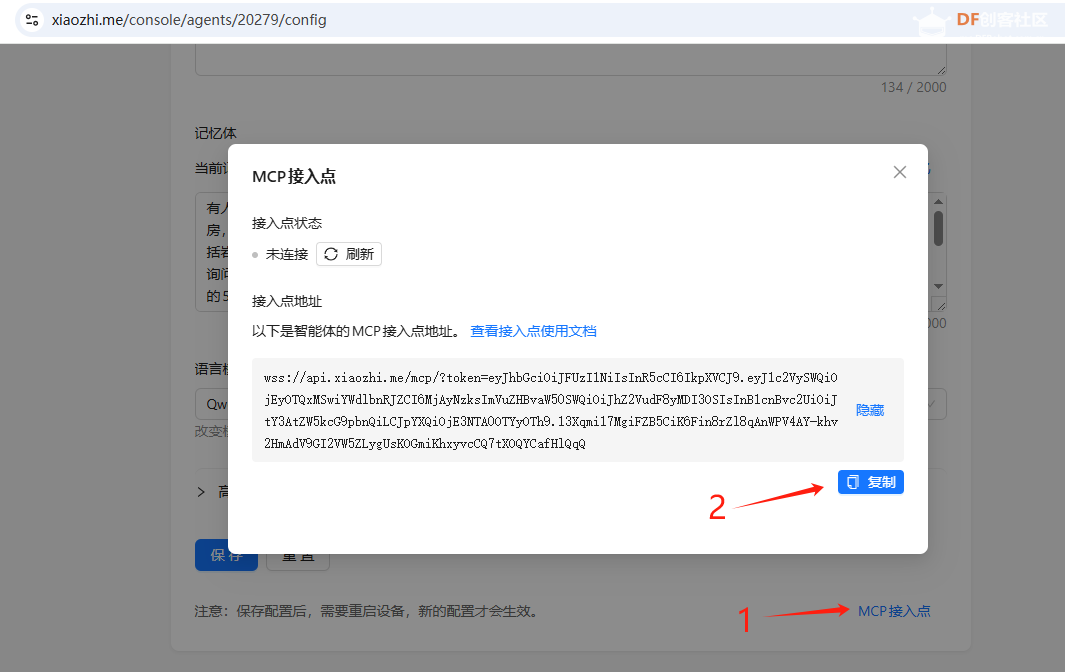
5. 获取 MCP 接入点
登录 xiaozhi.me 的控制台,进入智能体的配置角色页面,右下角可以看到该智能体专属的 MCP 接入点,点击复制。
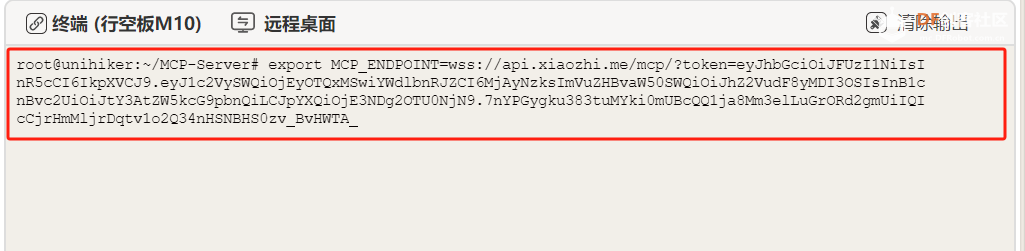
6. 设置环境变量
export MCP_ENDPOINT= 刚才复制的MCP 接入点
7. 启动MCP服务器
在行空板M10终端输入:
python mcp_pipe.py mcp_douban_movie.py
【附件】
 MCP-Server.zip MCP-Server.zip
v1.7.5_df-k10.zip
| 







 沪公网安备31011502402448
沪公网安备31011502402448

 置顶卡
置顶卡 变色卡
变色卡 千斤顶
千斤顶










