|
3656| 2
|
[官方资料] NVIDIA Jetson Nano 2GB 系列文章(59):视觉类的数据增强 |
 “优质数据”是训练出好模型的前提,如同食材对于料理的重要性,是一样的道理。通用类数据集能应付大部分实验用途的需求,但面对很多特定场景时就不是那么管用了,例如在工业上的 PCB 板瑕疵检测、物流分拣功能、农业蔬果采摘、医学肿瘤分享等应用,就需要在实际场景中采集现场数据。 但是能够呈现我们所要特征的数据量通常是很有限的,所以显得特别珍贵。虽然我们可以在这些图形上进行非常精密的标注,但碍于数量的限制,在最终训练出来的模型效果还是会大打折扣。 数据增强 (augment) 技术能非常有效地解决数据量不足的问题,透过多种图像处理的技巧,例如空间转换、颜色调整、模糊度等方式,将这些珍贵而且有限的图像数据进行极大化的扩充,白话地说就是把一张图像当 10 张用,如果我们手上只有 100 张优质图像,就能扩充到上千张,然后合并到训练用途的数据集中,这样就能解决数据量不足的问题。 TAO 启动器提供的 augment 指令,就是负责处理离线图像增强的功能,目前具备以下三类图像处理的方式:
下图是一个简单的例子,将左边原始数据透过不同图像处理技巧,就能获得更多的变种图像(中间与右边),然后将增强过的图像与标注,纳入训练用的数据集中。  图像增强过程中比较复杂的部分,只要牵涉到“空间增强”的处理,例如将图像做 90 度旋转处理或改变图像尺寸等,就得将标注文件中所有对象的标框坐标也跟着做转换,存放到新图像所对应的标注文件中,这是增强过程中最关键的处理。 执行这项任务还需要一个配置文件的辅助,将要处理的效果写入配置文件中,然后使用 “ tao augment -a <配置文件> -d<原始数据路径> -o <输出路径>” 指令格式,就能执行数据增强的任务。 配置文件里面主要分为以下四个组别: 1、空间增强配置:以 “spatial_config{...}” 进行隔离,包含以下功能与配置
2、颜色增强配置:以 “color_config{...}” 进行隔离,包含以下功能与配置内容
3、模糊增强配置:以 “blur_config{...}” 进行隔离,配置要卷积的内核的大(size)与高斯滤波器的模糊标准差(std)的值 4、图像尺度与格式配置:包括以下
关于各项参数的详细配置细节,请访问 https://docs.nvidia.com/tao/tao-toolkit里面 CV Applications 下的 “Offline Data Augmentation” 部分。 现在就开始执行TAO提供的augment范例,请在Jupyter进入 cv_samples/augment 目录中,里面有 augment.ipynb 脚本以及 specs 目录中有一个 default_spec.txt 配置文件。 点击 augment.ipynb 开启执行脚本,按照以下步骤执行: 0. 配置环境变量:脚本中 “0_Set up env variables” 步骤中,第一个执行块就是配置环境变量。最简单的配置就是将 “LOCAL_PROJECT_DIR” 设为目前执行位置。请执行以下修改:将 os.environ["LOCAL_PROJECT_DIR"] =FIXME改成 os.environ["LOCAL_PROJECT_DIR"] = os.getcwd()然后执行这个步骤的三个指令块。 1. 安装TAO启动器:这个安装步骤在前面已经执行过,因此这里直接跳过去。 2. 准备数据集:因为 augment 功能只支持 KITTI 格式,因此必须准备这种格式的数据集,如果使用其他格式数据集,请先做好格式转换。 执行脚本在这里指引大家去 KITTI 官方网站下载数据集,但整个过程相当繁琐,而且从境外下载的网速也个问题,因此请跳过整个 “A. Download the dataset” 所有执行块,以及 “B.Verify downloaded dataset” 前三个执行块。 我们在 https://pan.baidu.com/s/1WcRt9ONqsYhLRmL8Rg8_YQ(密码855n)百度网盘上存放了 data_object_image_2.zip与data_object_label_2.zip 两个压缩文件,直接在这里下载到 augment 目录下比较方便。 下载完后,请在 Jupyter 开启一个终端,执行以下指令: cd ~/tao/cv_samples/augment # 请根据您实际路径unzip -u data_object_image_2.zip -d dataunzip -u data_object_label_2.zip -d data 然后就会形成以下的目录结构:  现在执行 “B.Verify downloaded dataset” 的最后两个指令块 “# verify” 与 “ SampleKitti label”,能如下图般正常执行就表示数据环境都已经调试完成。 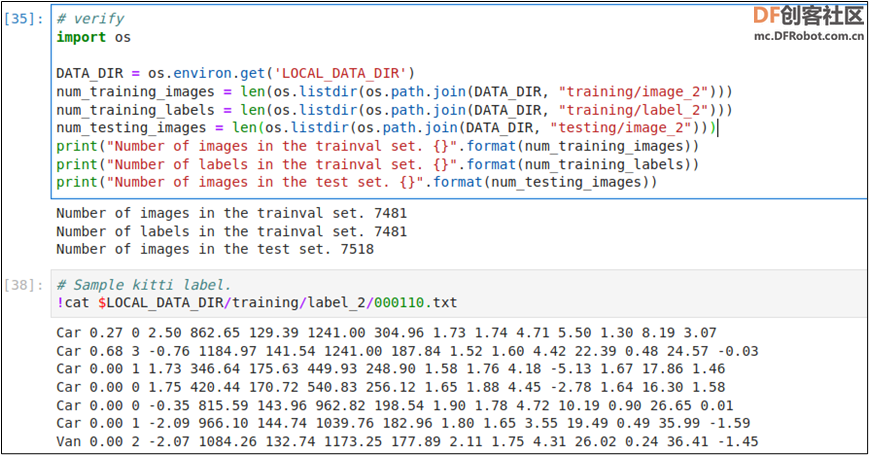 3. 执行数据增强的工作: 在执行以下指令块之前,先打开 specs/dafault_spec.txt 文件,里面的设置组在前面已经讲解过,请自行添加或删除设置组的参数,存档后执行下面指令块:  正确执行时,会在最下面出现下图的信息,表示正在根据配置文件的参数,进行数据增强的作业。  可以比对一下原始数据的标签与增强后的同名标签,看看里面的不同之处,并且试着多修改配置文件里面的各项参数,比对一下不同参数所产生的效果。 4. 增强结果的可视化:这个步骤主要是在 Jupyter 上查看增强后的图片,请自行处理。 由于增强后的数据集文件名与原始数据相同,因此最后还需要再做一个“批量改名”的工作,在 Ubuntu 操作系统可以用以下指令来执行: sudo apt installrename# 在文件名开头添加字符,例如‘a’。注意,图像与标签的文件名必须对应上cd <增强后的图像路径> && rename's/^/a/' *.pngcd <增强后的标签路径> && rename 's/^/a/' *.txt 然后将修改过文件名的图像与标签文件,全部移到原始数据集中,这样就能让数据集的内容快速扩充,即便原本的优质数据量只有 100 张的数量,也可以轻松透过这个 TAO 的数据增强工具,迅速扩充到好几倍的数据量,提高模型训练的结果。 |



 沪公网安备31011502402448
沪公网安备31011502402448© 2013-2026 Comsenz Inc. Powered by Discuz! X3.4 Licensed

 置顶卡
置顶卡 变色卡
变色卡 千斤顶
千斤顶







