|
3250| 2
|
NVIDIA Jetson Nano 2GB 系列文章(58):视觉类的数据格式 |
 前面的系列文章里提过,TAO 工具将模型训练的绝大部分技术难题都进行抽象化处理,大幅度减轻开发人员的负担,唯独数据集的收集与整理仍须由人工自行处理,这几乎是留给操作人员的最后工作了。 大部分关于数据集的问题就是标注格式的转换,包括 Pascal VOC、OpenImages、COCO 这些影响力较大的数据集,个别使用 .xml、.csv、.json 等不同的文件格式,包括标注栏位的内容与顺序也都不尽相同,这通常是困扰使用者的第一个门槛。 好在这些格式之间的转换,只需要一些简单的 Python 小工具就能完成,虽然繁琐但也没有什么技术难度。 在 https://docs.nvidia.com/tao/tao-toolkit/text/data_annotation_format.html 里,提供 TAO 工具针对不同应用类型所支持的格式,简单整理如下:
这里只将使用率较高的图像分类与物件检测两种应用的数据格式进行说明,其他应用的数据格式请自行参照前面提供的说明链接。 1、图像分类的“目录结构”格式: 这是以“图像”为单位的分类应用,每张图片只会有一个分类属性,因此格式相对简单,只要将图片根据目录结构的规则进行分类就可以。  为了配合模型训练的工作,我们需要将数据集切割成 “train”、“val”、“test” 三大类,分别作为训练、校验与测试用途。 在每个数据集下面再延伸出“分类属性”子目录,例如做早期用于识别 0~9 手写数字的 MNIST 数据集,就得在 train/val/test 下面各添加 “0”~“9” 共 10 个子目录,合计是 2 层 33 个目录结构。  如果是使用 ILSVRC 竞赛的 1000 分类 ImageNet 数据的话,就得根据这 1000 个分类在三个目录下创建 1000 个分类属性子目录,例如 dog、cat、person 等等,虽然很繁琐但也不复杂,对模型训练工具而言,图像文件名称是无所谓的。 数据来源通常是两大类,第一种是自行从网上收集与手动拍摄,第二种是从现成数据集进行提取,包括 ImageNet、Pascal VOC、COCO、OpenImages 这些知名的通用数据集,都有非常丰富的资源。 但现在的最大问题是,如何从这些数据集中提取所需要的图像,并根据“目录结构”存放成 TAO 所支持的格式? 这个部分需要使用者自行研究所需要的数据集的结构,撰写简单的提取工具。例如 TAO 提供的 classification 图像分类模型训练范例项目中,使用 Pascal VOC 2012 数据集来进行图像分类的模型训练,但是这个数据集使用下图左的路径分布方式,与 TAO 所支持的“目录结构”格式并不相同,那么该如何处理?  我们必须对这个数据集的相关资源有进一步了解。在 VOC 数据集的 ImageSets/Main 里存放 63个.txt 文件,刨去 train.txt、trainval.txt 与 val.txt 三个文件,其余 60 个分属于数据集的 20 个图像类别的三种用途,例如 xxx_trainval.txt、xxx_train.txt、xxx_val.txt,其中前者的内容是后面两个文件的合并。 在 classification.ipynb 脚本中提供两段数据格式转换的 Python 代码(请自行查阅),在 “A.Split the dataset into train/val/test” 的环节,执行以下处理: (1) 将存放在上图左边 “JPEGImages” 里面的图像文件,借助 xxx_trainval.txt 分类列表的协助,复制到上图右方的 “formated” 下的 20 个分类子目录; (2) 从 “formated” 的每一类图像数据,分别切割出 train/val/test 三大分类,放到 “split” 目录下,作为后面转换成 tfrecords 的数据源。 经过两次转换处理后,在这里的数据内容就该有 3 份相同的图像数据,只不过使用不同的路径结构去存放而已。如果不想浪费存储空间的话,可以将 VOCdeckit 与 formatted 两个目录删除,只需要保留 split 目录的结构就足够。 至于其他数据的转换,也需要使用者对该数据集有充分的了解,毕竟学习数据转换的精力要远远低于自行收集的时间,绝对是划算的。 2、物件检测的 KITTI 格式: 绝大部分通用数据集为了提高普及度,都提供多种应用类别的标注 (annotations) 内容,其中 “物件位置 (location)” 是最基本的数据,其他还有与人体相关的骨骼结构标注、语义分割的材质标注、场景描述的标注等等,每种数据集都有其侧重点,因此内容种类与格式也都不尽相同,这是大伙要使用数据集的第一个门槛。 物件检测是比图像分类更进一步的深度学习应用,要在一张图像中找出符合条件的物件,数量没有限定,就看训练出来的模型具备哪些分类功能。 每个数据集的差异,就是将所包含的图像,都进行不同功能与不同细腻度的标注内容,这些动辄数万张到上千万张的图像、分类数量从20到数千的不同数据集,也都使用不同的文件格式去储存这些标注内容,有些是图像文件与标注文件一一对应,有些则是将上千万张的标注内容全部存在一个巨大的标注文件里。 例如 COCO 数据集将数百万张的标注存放在上百兆的 .json 文件里、 OpenImages 数据集上千万张的标注存放在 1.3GB 的 .csv 文件中,而 Pascal VOC 与 ImageNet 的标注文件则提供一对一对应的 .txt 与 .xml 格式,莫衷一是。 事实上对应物件检测的应用,我们只需要标注文件中最基本的元素,包括“类别”与“位置”这两组共 5 个栏位数据就可以。类别部分有的数据集直接使用“类别名”,有的数据集只提供“类别编号”,然后再到类别文件中寻找对应;位置信息部分,有些提供“左上角”与“右下角”坐标位置,有些使用“起点坐标”与“长宽”来表示,都是一组 4 个浮点值。 因此,要从庞大的数据集中,提取我们所需要的类别与位置标注,就必须对个别标注结构进行研究,才能得到我们想要的结果,这个步骤是跳不过去的。网上虽然有很多标注格式转换的功能,但是通用性受限制,还是需要进行局部修改。 现在来看看 TAO 工具在物件检测模型训练所支持KITTI格式内容,主要栏位如下: 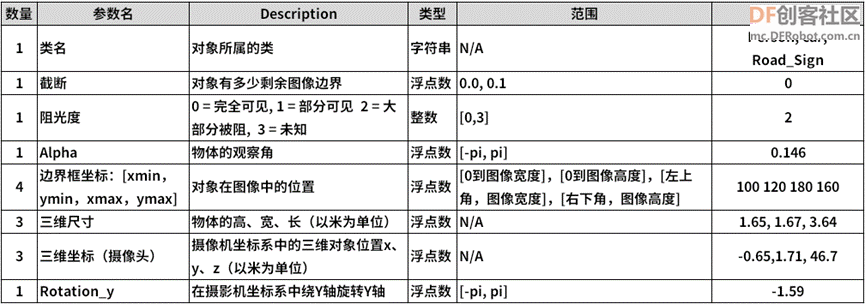 其标注文件是 .txt 纯文字格式,在文件内的表达方式如下:  熟悉物件检测应用的人,可能会觉得这个 KITTI 标注格式中,有一半以上的栏位是用不上的,为何英伟达却十分偏好这个格式呢? 如果将视野放大到自动驾驶与 3D 应用领域的话,就能理解英伟达选择这个格式的理由,因为 KITTI 数据集是由德国卡尔斯鲁厄理工学院和丰田美国技术研究院联合创办,是目前国际上最大的自动驾驶场景下的计算机视觉算法评测数据集。 在物件检测应用中只需要用到“类名”与“边界框坐标”这两部分,如果从其他数据集提取数据时只要找出这 5 个数据,如果坐标格式为“起点坐标+长宽”的格式,也能简单转换成“起点坐标+重点坐标”形式,写入对应的 KITTI 标注文件中,其他栏位的内容 “补 0” 就可以,所以整个转换过程还不是太麻烦。 在 TAO 的视觉项目中的 face-mask-detection/data_utils 里,提供大约 4 转换成 KITTI 格式的工具,能提供大家作为参考。 只要能将不同数据集之间的格式转换弄通,就能非常高效的从庞大的数据集资源中,轻松获取我们所需要的类别数据,进一步训练出自己专属的模型,因此这个过程对使用深度学习的工程师是很重要的基本工作。 |



 沪公网安备31011502402448
沪公网安备31011502402448© 2013-2026 Comsenz Inc. Powered by Discuz! X3.4 Licensed

 置顶卡
置顶卡 变色卡
变色卡 千斤顶
千斤顶







