|
3249| 0
|
[官方资料] NVIDIA Jetson Nano 2GB 系列文章(56):启动器CLI指令集与配置... |
|
在开始使用 TAO 模型训练工具之前,我们必须先对其操作原理有个基础的理解,因为这套工具能支持 30 多种神经网络的深度学习,并且横跨视觉类与对话类两种不同领域,究竟是如何做到的? 前面介绍的内容中提过,在 TAO 工具使用两个不同的 Docker 容器,去面对视觉类与对话类的模型训练,分别是基于 Tensorflow 与 PyTorch 框架。 不过英伟达将复杂的调用工作进行高度的抽象化处理,以启动器 CLI 指令作为统一的执行接口,并且为每个神经网络提供对应的配置文件组,透过指令集与配置文件的组合,将操作的逻辑变得非常简单,开发人员只要熟悉这套指令集,就能非常轻松地驾驭所有 TAO 支持的神经网络,进行高效率的模型训练任务。 因此在操作 TAO 工具之前,首先得对 CLI 指令集与配置文件有个初步的了解。
这个指令集的语法非常简单,主要是下面三部分所组成: 1. task:包括 TAO 所支持的神经网络算法以及基础的控制指令,主要分为以下三类:
上面所有的信息,可以用 tao info --verbose 指令,查询到不同版本容器所支持的神经网络类型。 当我们单纯执行 tao 的时候,就会进入对应的容器里,例如:
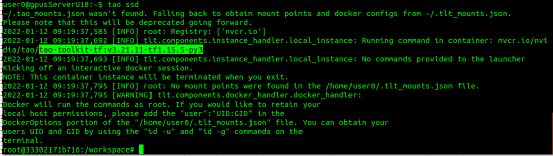
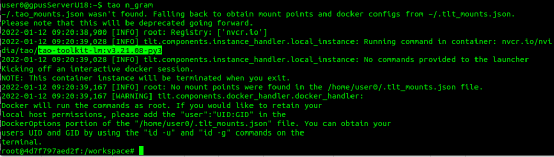 2. sub-task与args:主要是指 TAO 所支持的神经网络算法(task)而不同,最简单的方法就是执行 tao--help 去查询个别 task 后面所需要的。例如:
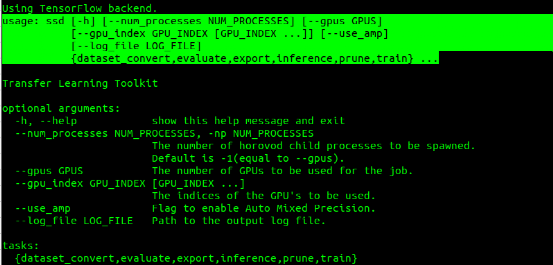
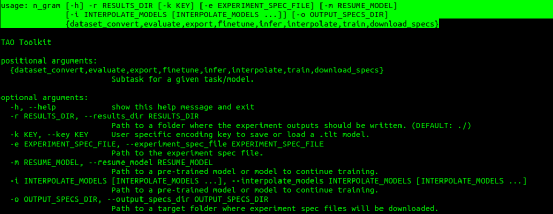 以下6种指令是所有模型都具备的功能:
到这里应该能够感受到这个 CLI 指令集的便利之处,开发人员只要好好记住这组指令,不需要撰写任何 C++ 或 Python 代码,甚至不需要了解任何一个神经网络的结构与算法,就能非常轻松地面对这么多种复杂的模型训练任务。
这里需要透过 TAO 提供的范例来说明配置文件的细节,这里以视觉类的范例为主,请执行下列指令下载范例文件: 在 cv_samples_v1.3.0 文件夹里有 20+ 个子目录,每个子文件夹就对应一个神经网络,下面都有个别的 specs 子目录,里面就存放对应的配置文件。 每个项目应该是由不同的技术人员所处理,在文件格式与命名方式也不尽相同,大部分是 .txt 纯文件格式,有些则使用 .yaml 或 .json 格式,因此需要针对个别项目,去深入了解每个配置文件里的各项参数。 下面是 TAO 视觉类模型训练工具的工作流图,每个项目里的配置文件,都是为不同阶段的任务提供所需要的参数。  这里以英伟达发展的 detectnet_v2 神经网络作为范例,里面的配置文件内容比较完整,包括以下 7 个文件:
这些文件是配合整个执行流程的步骤: 1. 格式转换:由于这个训练的容器是基于 Tensorflow 框架,因此执行训练前需要先将数据集转换成 tf_record 格式,就会用到 detectnet_v2_tfrecords_kitti_trainval.txt 配置文件。其他项目里 xxx_tfrecords_kitti_xxx.txt 主要就是作为这个用途。 2. 训练模型:所有项目里的 xxx_train_xxx.txt 文件,都是该项目进行第一次训练时所需要配置文件,不过每个项目的配置中都不尽相同,以下列出 4 个项目提供参考: 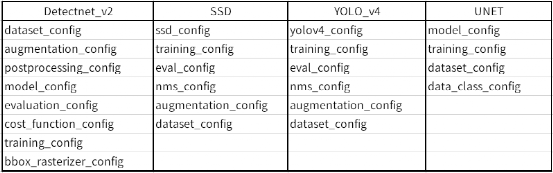 这里的参数设定,是整个 TAO 训练模型过程中技术含量最高的环节,我们所能修改的部分大概就是“training_config”组里的”batch_size_per_gpu”与“num_epochs”这两个参数,以及确认“dataset_config”组里的每一个“target_class_mapping”对应是否正确。 其他参数的调整是需要对个别神经网络的结构预与算法有足够了解,如果没有把握的话,建议就使用英伟达已经优化过的参数。 3. 评估模型:也使用前面一个配置文件。如果不满意评估结果(例如 mAP 低于 0.5),可以试着加大 num_epochs,或者从头检查数据集的图像与标注;如果满意结果的话,就可以继续往下执行。 4. 修剪模型:TAO 使用比较简单的调整阈值(threshold),而不改变其他参数 5. 模型再训练:这个步骤用到的 xxx_retrain_xxx.txt 配置文件,与第一次训练使用的配置文件中的最大不同点,在于“pretrained_model_file”的部分,第一次训练使用 NGC 下载的预训练模型,而再训练的部分是使用步骤 4 修剪步骤所生成的模型,其他设定值是一样的。 6. 评估再训练的模型:与步骤 3 相同。如果对评估结果并不满意,请回到步骤 4 重复进行;如果感到满意,就能接续往下执行推理识别,验证模型的效果。 后面的推理验证与导出模型的步骤,留在实际项目执行的时候再做说明。到此应该能清楚,在 TAO 模型训练阶段,需要的就是 xxx_tfrecords_xxx.txt、xxx_train_xxx.txt 与 xxx_retrain_xxx.txt 这三个配置文件,后面两个文件的内容几乎一样,只有调用的预训练模型不一样,这样就能让事情变得更加单纯。 整个 TAO 训练工具的内容,主要就是围绕着 CLI 指令集与配置文件的组合处理,如此一来,开发人员只要掌握这两个部分,就能轻松驾驭大部分的模型训练任务。 |



 沪公网安备31011502402448
沪公网安备31011502402448© 2013-2026 Comsenz Inc. Powered by Discuz! X3.4 Licensed

 置顶卡
置顶卡 变色卡
变色卡 千斤顶
千斤顶






