|
4047| 4
|
[官方资料] NVIDIA Jetson Nano 2GB 系列文章60:图像分类的模型训练与修剪 |
 图像分类 (image classification) 是视觉人工智能的最基础应用,目前 TAO 模型训练工具支持 resnet、vgg、mobilenet_v1、mobilenet_v2、googlenet、cspdarknet、darknet、efficientnet_b0、efficientnet_b1、cspdarknet_tiny 等 10 种神经网络,其中 resnet、vgg、darknet、cspdarknet 还有不同结构层数的区分。 在 TAO 启动器中只用 “classification” 这个任务指令,去面对上面所列出的十多种网络结构,其关键处就是结合“配置文件”的协助,因此这个配置文件的设置组是 TAO 工具的核心所在,也是本文一开始要花时间说明的部分。 在 cv_samples 下面的 classification 项目,是 TAO 工具的图像分类模型训练的标准范例,里面提供 classification.ipynb 执行脚本与 specs 目录下两个 .cfg 配置文件,基本上在执行脚本里只需要修改一些路径的设定就行,其余细节都在配置文件里面进行调整,包括所选择的神经网络种类与结构。 这个项目以 PascalVOC 2012 数据集作为训练源,与 TAO 所支持的格式并不相同,因此在训练之前还需要进行格式的转换。还好这里的转换比较简单,只要将图像分别存放在以“类别”所命名的目录下就可以,同时分割成训练与校验两个不同用途的数据集,在脚本里透过一段简单的 Python 代码就能完成,并没有什么难度。 最后在训练之前,可以选择是否启动 “迁移学习” 的功能?在这个实验中也会示范这中间所得到的精度差异,让大家直接体验到迁移学习所带来的的好处。 以下就将几个执行重点提出来说明,协助大家可以轻松地执行。
TAO 的 CLI 指令集只使用一个 classification 去面对所有的图形分类应用,其余的工作就全部交给配置文件去处理。在图像分类的配置文件里,主要有以下三个配置组: 1、model_config:存放神经网络种类、结构(层数)与特性的内容,以下列出比较重要的部分: (1) arch:网络名称,可使用所有已支持的网络,包括 resnet、vgg、mobilenet_v1、mobilenet_v2、googlenet、cspdarknet、darknet、efficientnet_b0、efficientnet_b1、cspdarknet_tiny 等; (2) n_layer:有些网络有多种结构层,例如 resnet有10/18/34/50/101、vgg 有16/19、darknet 有 19/53、cspdarknet 有 19/53 等; 其余参数都按照配置文件里面所设定的值,因为 NGC 提供的预训练模型是按照这些参数所训练的,能在迁移学习过程中得到比较好的效果。 2、train_config:执行训练时所需要参考的 (1) train_dataset_path: 训练用数据集的位置,需要输入在容器内的完整路径 (2) val_dataset_path: 校验用数据集的位置,需要输入在容器内的完整路径 (3) pretrained_model_path: 预训练模型位置,需要输入在容器内的完整路径 (4) batch_size_per_gpu:请根据GPU显存大小进行调整 (5) n_epochs:训练的回合数 (6) n_workers:CPU的并行线程数,请根据实际CPU核数量进行调整 其余参数清先安装范例所提供的设置。 3、eval_config:评估模型时所需要用到的参数,需要输入在容器内的完整路径 (1) eval_dataset_path: 测试用数据集路径,与前面相同 (2) model_path: 在前面训练模型过程中所生成的 .tlt 模型文件中,挑选效果最好的一个模型来进行评估,通常最后一个的效果会最好。这里的 “resnet_080.tlt” 是因为训练回合数为 80。 其余参数请先按照范例所提供的设置。 以上关于路径部分的设置,只要遵循脚本一开始 “0. Set up env variables and map drives” 的配置规则,文件里基本上不需要做修改。其他参数的定义与设定值,请访问 https://docs.nvidia.com/tao/tao- ... n.html#model-config 有完整的说明。
TAO 支持的图像分类数据格式,是以“分类名”作为路径名,将所有该类的图像都放置到分类名目录之下,例如有 20 个分类的数据集,就会有 20 个分类目录。 本实验使用 PascalVOC 的 VOCtrainval_11-May-2012.tar (1.9GB) 数据集,可以用脚本提供的链接,也可以在https://pan.baidu.com/s/1JhnBCRi32xblhSSWFmF5aA (密码: gg95) 下载压缩文件。 请按照脚本的数据集处理过程,包括放置路径与解压缩的指令。由于这个数据集的格式并不符合 TAO 的要求,因此脚本中使用一段 Python 代码来进行转换,详细内容请自行阅读代码,其主要功能就是将下图左边 VOC 路径结构转换成右边符合 TAO 要求的结构,存放在 “formated” 目录下。  接着再将 “formated” 的数据,随机分割成 train、val与test 三大类存放到 “split” 目录下,作为后面执行训练、校验与测试时所需要的数据路径。 
TAO 的模型训练继承 TLT 的迁移学习功能,只要在配置文件中的“train_config” 配置组里,指定好 “pretrained_model_path:” 的路径就可以,如果不想启用这个功能,只要在这个参数前面用 “#” 去关闭就行。 在 NGC 提供 300 多个预训练模型,我们需要挑选合适的模型来协助执行迁移学习,这部分的下载需要使用 NGC 的指令来操作,在脚本中已经提供完整的安装步骤,只要执行命令块就行,然后用以下指令去下载所选的模型: ngc registry model download-version 模型全名 --dest 本地存放路径 这里配合所使用的网络种类,挑选 nvidia/tao/pretrained_classification:resnet18 作为本次的预训练模型,文件大小在 80MB 左右。 下图左方是这个实验中,关闭迁移学习功能所训练出来的模型,经过下面评估步骤所测算出来的结果,下图右方则是在基于 NGC 下载的预训练模型基础上,利用迁移学习功能所训练出来的模型效果,总体来说得到的精准度提升还是很明显的。 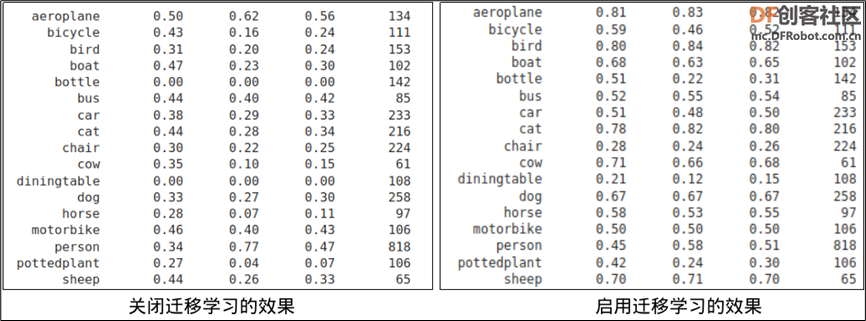 但如果是缺乏合适预训练模型的状况下,也不能硬是挑选不合适的模型来做迁移学习,可能得到的效果会更差。
当前面的准备工作都做到位之后,这个步骤就是水到渠成。执行训练所耗费的时间就只跟 GPU 卡的总体计算资源有关系,如果您的设备有一张以上 GPU 计算卡的话,可以透过 TAO 指令以下参数,去调整可用的计算资源:
例如设备上有 2 片 GPU 卡时,想要全部用上的话就直接用 “--gpus 2” 参数进行调用;如果设备上有 4 片 GPU 计算卡,想要指定调用 0 号与 3 号这两张卡的时,就用 “--gpus 2--gpu_index 0 3” 参数,就能精准调用指定的GPU来进行训练。 在这个图像分类实验中,我们以 NVIDIA RTX2070 与 RTX3070 进行测试,这两张计算卡都具有 8GB 显存。在固定回合数为 80、batch_size_per_gpu 为 64 的条件下,所耗费的训练时间如下:
这个步骤的目的,是要在维持足够精准度的前提下缩小模型的尺寸,越小的模型会消耗更少的计算资源,特别是内存与显存。 这对于计算资源充沛的计算设备来说,所体现的差异并不明显,但是对于计算资源相对吃紧的边缘设备来说,就有非常大的影响,甚至影响推理识别的性能,因此请自行决定是否需要执行这个步骤。 这里的要剪裁的对象是已训练好的模型,而不是从网络结构层进行融合处理,最简单的方法就是调整 “-pth(阈值)” ,在精确度与模型大小之间取得平衡,调整的值越高就会得到越小的模型,但精准度会受到比较大的损失,这就需要经过不断尝试去调节出满足要求的模型。 以这个 classification 项目为例,在 80 回合中训练的模型大小为 87.7MB,通常最后一回合训练的模型精确度会最好,因此用 resnet_080.tlt 模型进行修剪测试:
至于修剪后模型对精确度产生怎样的影响?就需继续往下执行“再训练”之后,看看评估的效果如何!
经过修剪的模型并不能立即使用,而是作为“再训练”的预训练模型,再次利用迁移学习的技巧,以前面的数据集进行模型再训练的工作,唯一不一样的地方是这次使用的配置文件为 classification_retrain_spec.cfg,这个配置内容与前面的 classification_spec.cfg 只有三个差异的地方: 1. 在 model_config 设置组少了两个 “freeze_blocks” 设置; 2. 在 train_config 设置组的 “pretrained_model_path” 换成前面修剪过的模型; 3. 在 eval_config 设置组的 “model_path” 换成修剪后重新训练的模型 继续往下执行 “7. Retrain pruned models” 与 “8. Testing the model” 两个步骤,就能得到修剪过模型的精确度评估结果。 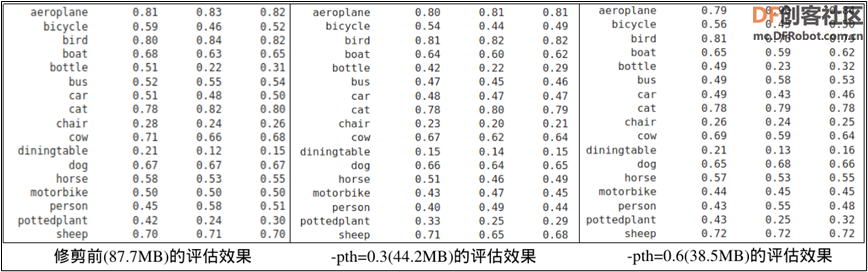 从上面的比较表中可以看出,这个剪裁的方式对模型文件大小的影响是很明显的,但精确度的损失并不是太大,所以这个剪裁应视为有效果。
这个范例主要让大家体会并熟悉 TAO 的配置文件与执行流程,事实上 TAO 所提供的范例几乎都是一样的流程,后面还有导出模型、INT8 优化、生成 TensorRT 引擎的步骤,我们结合在后面的物件检测范例中进行说明。 |



 沪公网安备31011502402448
沪公网安备31011502402448© 2013-2026 Comsenz Inc. Powered by Discuz! X3.4 Licensed

 置顶卡
置顶卡 变色卡
变色卡 千斤顶
千斤顶







