|
3656| 4
|
NVIDIA Jetson Nano 2GB系列文章(64):将模型部署到Jetson设备 |
 前面我们花了很多力气在 TAO 上面训练模型,其最终目的就是要部署到推理设备上发挥功能。除了将模型训练过程进行非常大幅度的简化,以及整合迁移学习等功能之外,TAO 还有一个非常重要的任务,就是让我们更轻松获得 TensorRT 加速引擎。 将一般框架训练的模型转换成 TensorRT 引擎的过程并不轻松,但是 TensorRT 所带来的性能红利又是如此吸引人,如果能避开麻烦又能享受成果,这是多么好的福利!
下图是将一般模型转成 TesnorRT 的标准步骤,在中间 “Builder” 右边的环节是相对单纯的,比较复杂的是 “Builder” 左边的操作过程。 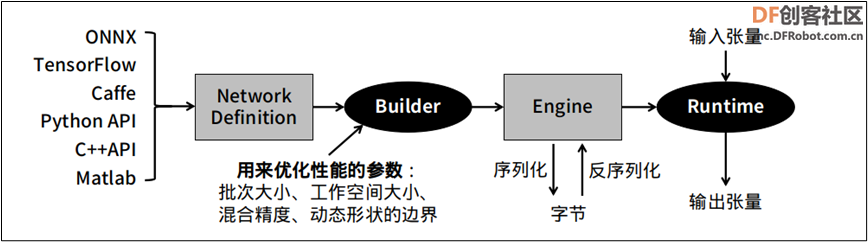 下图就上图 “NetworkDefinition” 比较深入的内容,TensorRT 提供 Caffe、uff 与 ONNX 三种解析器,其中 Caffe 框架已淡出市场、uff 仅支持 TensorFlow 框架,其他的模型就需要透过 ONNX 交换格式进行转换。 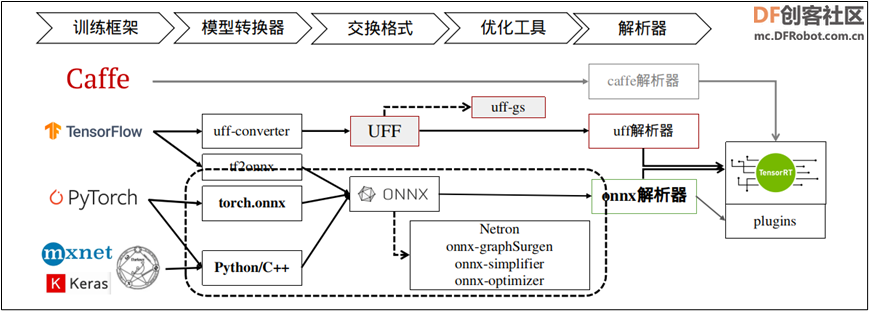 这里以 TensorRT 所提供的 YOLOv3 范例来做范例,在安装 Jetpack 4.6 版本的 Jetson Nano 设备上进行体验,请进入到 TesnorRT 的 YOLOv3 范例中: 根据项目的 README.md 指示,我们需要先为工作环境添加依赖库,不过由于部分库的版本关系,请先将 requirements.txt 的第 1、3 行进行以下的修改: 然后执行以下指令进行安装: 接下来需要先下载 download.yml 里面的三个文件, 然后就能执行以下指令,将 yolov3.weights 转成 yolov3.onnx: 这个执行并不复杂,是因为 TensorRT 已经提供 yolov3_to_onnx.py 的 Python 代码,但如果将代码打开之后,就能感受到这 750+ 行代码要处理的内容是相当复杂,必须对 YOLOv3 的结构与算法有足够了解,包括解析 yolov3.cfg 的 788 行配置。想象一下,如果这个代码需要自行开发的话,这个难度有多高! 接下去再用下面指令,将 yolov3.onnx 转成 yolov3.trt 加速引擎: 以上是从一般神经网络模型转成 TensorRT 加速引擎的标准步骤,这需要对所使用的神经网络的结构层、数学公式、参数细节等等都有相当足够的了解,才有能力将模型先转换成 ONNX 文件,这是技术门槛比较高的环节。
用 TAO 工具所训练、修剪并汇出的 .etlt 文件,可以跳过上述过程,直接在推理设备上转换成 TensorRT 加速引擎,我们完全不需要了解神经网络的任何结构与算法内容,直接将 .etlt 文件复制到推理设备上,然后用 TAO 所提供的转换工具进行转换就可以。 这里总共需要执行三个步骤: 1、下载 tao-converter 工具,并调试环境: 请根据以下 Jetpack 版本,下载对应的 tao-converter 工具: 下载压缩文件后执行解压缩,就会生成 tao-converter 与 README.txt 两个文件,再根据 README.txt 的指示执行以下步骤: (1) 安装 libssl-dev 库: (2) 配置环境,请在 ~/.bashrc 最后面添加两行设置: (3) 将 tao-convert 变成可执行文件: 2、安装 TensorRT 的 OSS (Open Source Software) 这是 TensorRT 的开源插件,项目在 https://github.com/NVIDIA/TensorRT,下面提供的安装说明非常复杂,我们将繁琐的步骤整理之后,就是下面的步骤: 这样就能开始用 tao-converter 来将 .etlt 文件转换成 TensorRT 加速引擎了。 3、用 tao-converter 进行转换 (1)首先将 TAO 最终导出 (export) 的文件复制到 Jetson Nano 上,例如前面的实验中最终导出的文件 ssd_resnet18_epoch_080.etlt, (2)在 Jetson Nano 上执行 TAO 的 ssd.ipynb 最后所提供的转换指令,如下: 这样就能生成在 Jetson Nano 上的 ssd_resnet18_epoch_080.trt 加速引擎文件,整个过程比传统方式要简便许多。 |



 沪公网安备31011502402448
沪公网安备31011502402448© 2013-2026 Comsenz Inc. Powered by Discuz! X3.4 Licensed

 置顶卡
置顶卡 变色卡
变色卡 千斤顶
千斤顶







