本帖最后由 loria 于 2024-1-8 18:06 编辑 【行空板+大模型】——基于ChatGLM的多角色交互式聊天机器人 行空板+大模型应用案例二:智能家居助手——让ChatGPT帮你控制硬件 1.背景介绍 随着人工智能技术的飞速发展,大型语言模型已经成为了人们关注的热点之一。在国际上,诸如 GPT-3、BERT 及其后继者等大型语言模型层出不穷,吸引了广泛关注。同时,在国内,也有一款备受瞩目的本土语言模型——ChatGLM。
ChatGLM 是由清华大学开发的一款强大的语言生成模型,它融合了最先进的深度学习技术与海量中文语料的训练成果。与国外的语言模型如 GPT-3 相媲美,ChatGLM 在自然语言理解与生成方面展现了出色的性能, 同时也为国内的自然语言处理研究与应用提供了强有力的支持。 今天,我们就一起使用ChatGLM,结合多种人工智能技术,一起制作一个有趣好玩的聊天机器人应用吧!
本项目仅需一块行空板和一个UGB喇叭,你就能get一个可以以多角色身份与你聊天对话的机器人助手,通过修改角色描述,你完全可以打造属于你的个性化的聊天机器人!
2.效果演示视频 3.硬件准备 行空板,USB线,USB喇叭
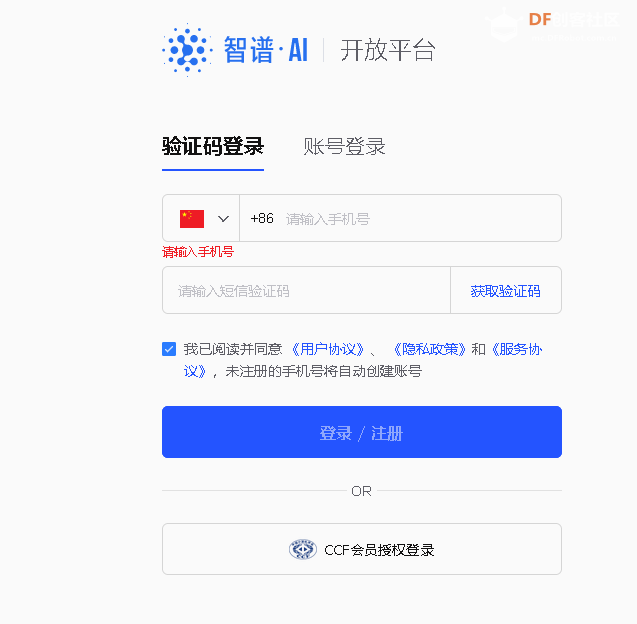
4.功能分解 4.1注册智谱api 选择验证码登录,输入手机号和验证码完成注册
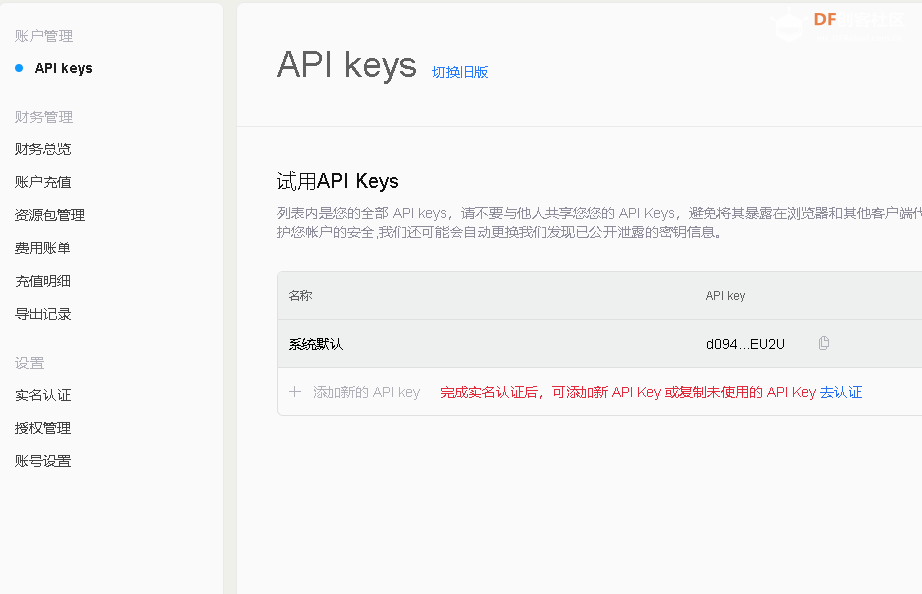
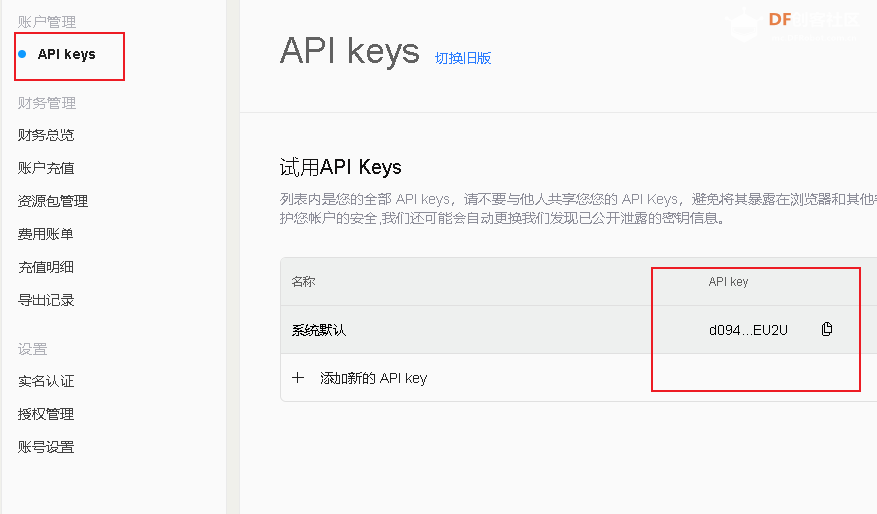
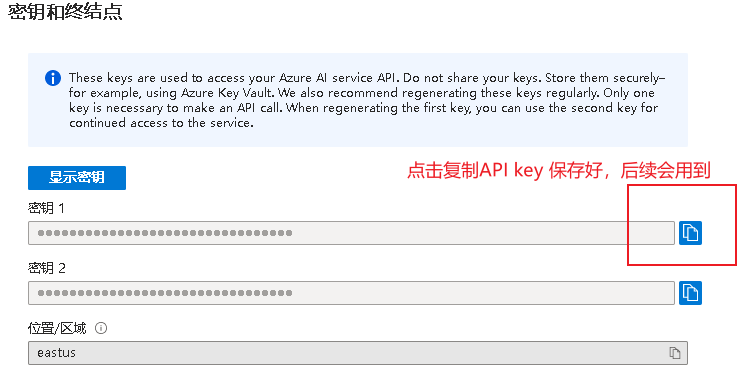
点击API keys, 点击“去认证”,进行实名认证
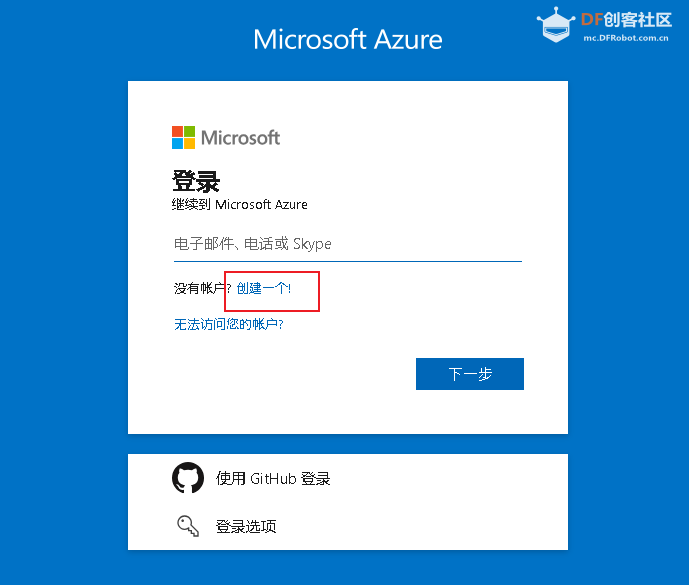
4.2 注册并获取微软语音服务API密钥 (1)注册微软的账号
新用户有一年的免费额度但需要信用卡验证。如果没有条件申请微软的语音服务API,也可以使用百度的语音服务API,文章的最后提供了使用ChatGLM和百度API的实现代码。
(2)通过验证
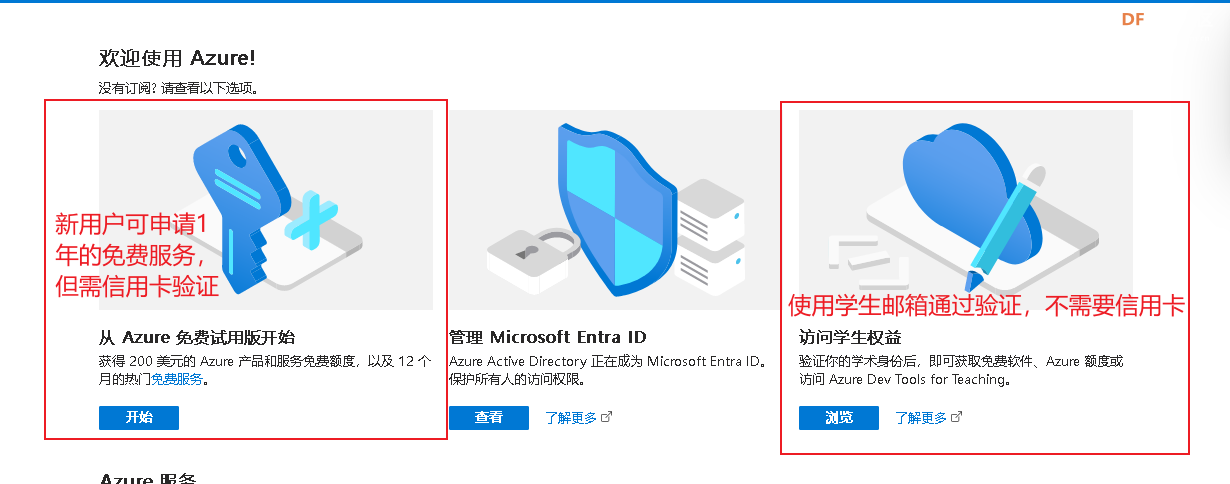
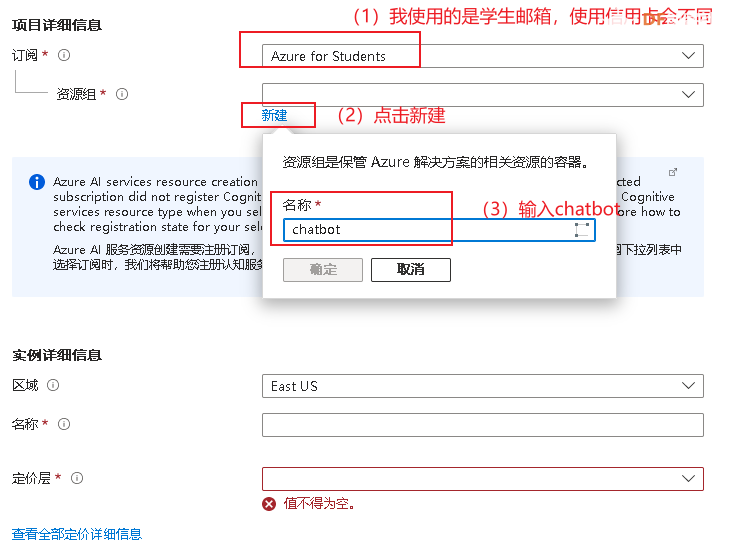
面对新用户,微软提供了1年的免费服务但需要通过验证,这里有两种验证方法。(1)visa/银联卡验证(2)大学生能无需信用卡,使用学生邮箱验证。两种验证方式对应如下图。
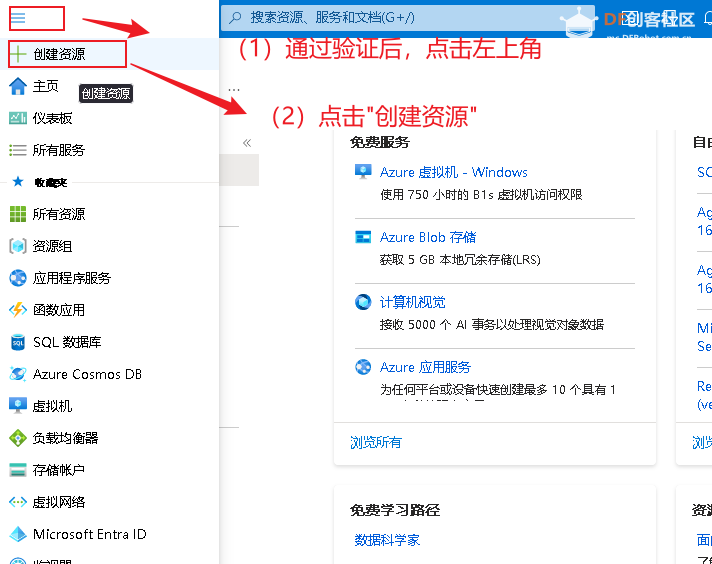
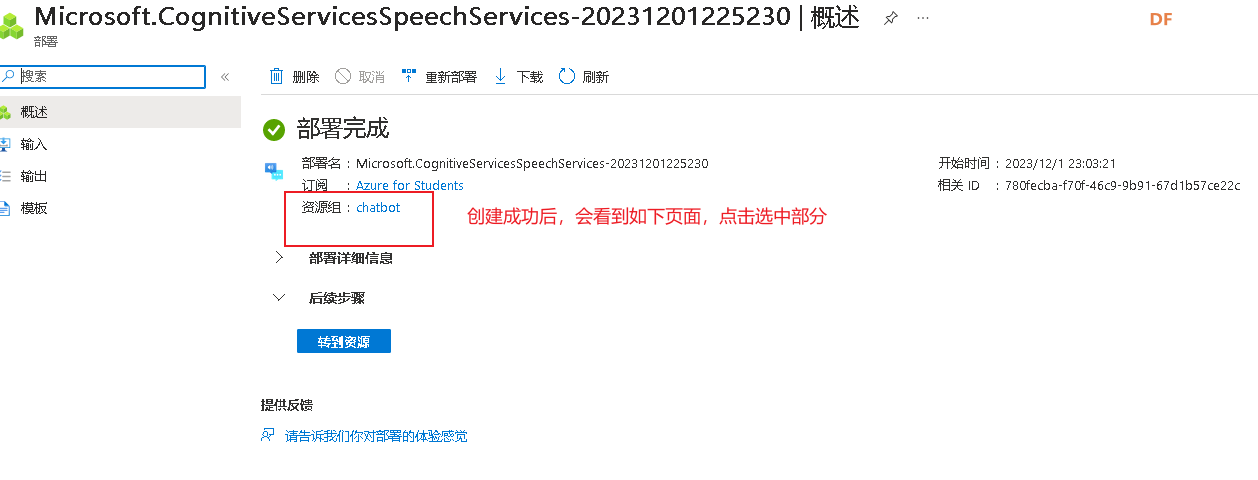
(3)申请资源
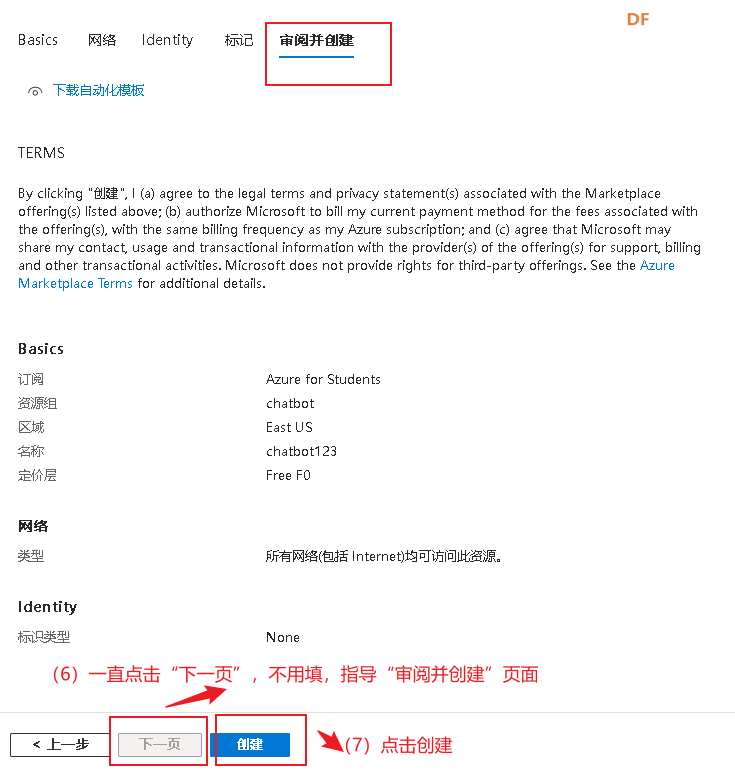
验证通过后,在Azure门户中,点击左上角的“+ 创建资源”按钮。
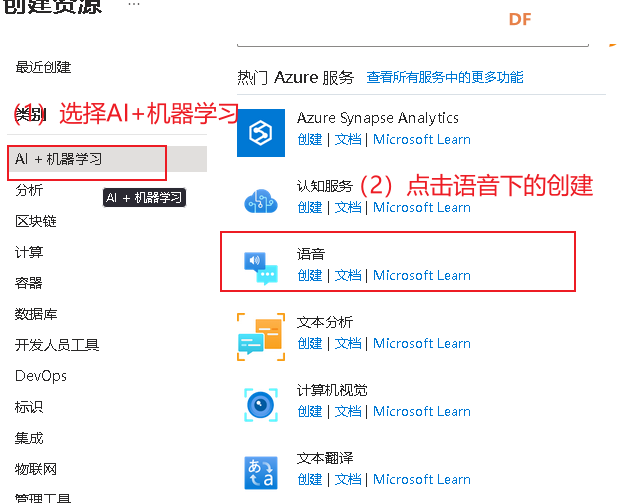
之后会跳转到一下页面
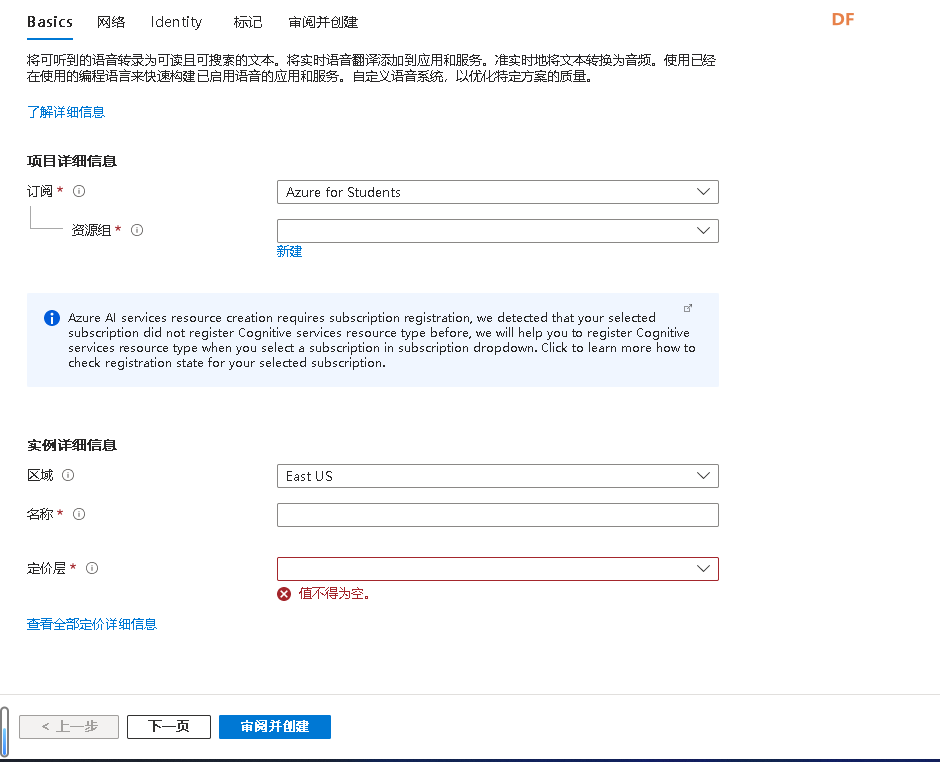
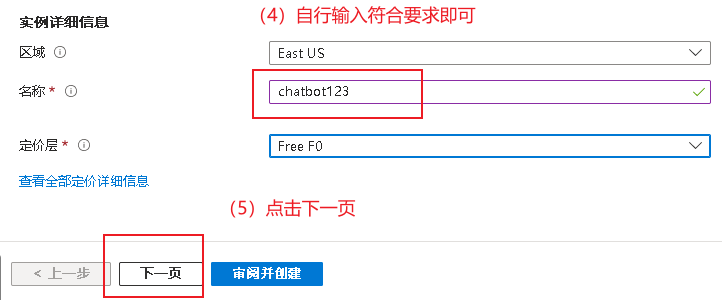
按照下图方式填写即可
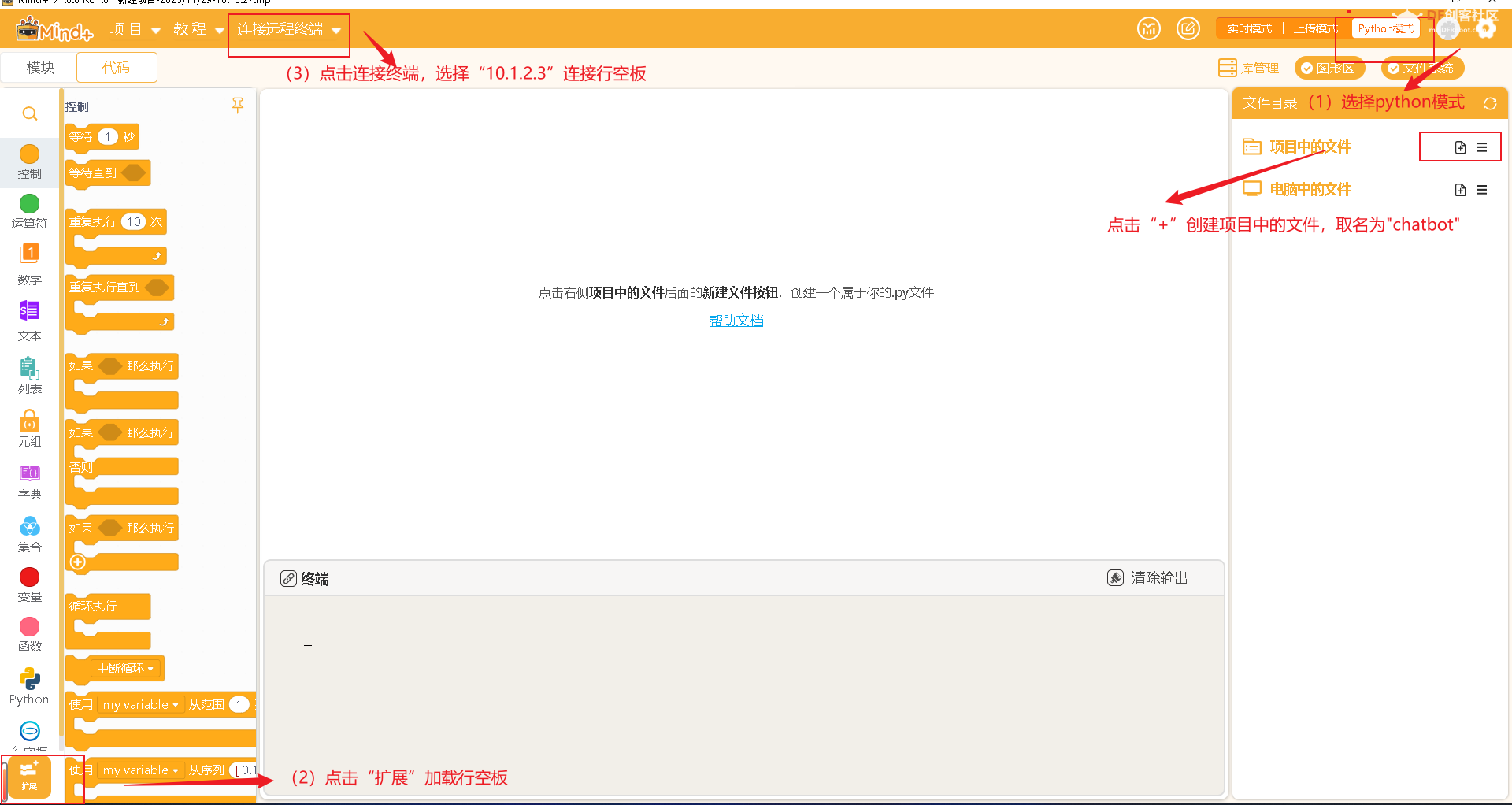
4.3加载行空板-安装库-行空板联网 4.3.1加载行空板 第一步:使用usb线将行空板连接在电脑上
按照下面步骤加载行空板,创建好文件后,可以看到一个名为“chatbot.py”的文件,双击打开。
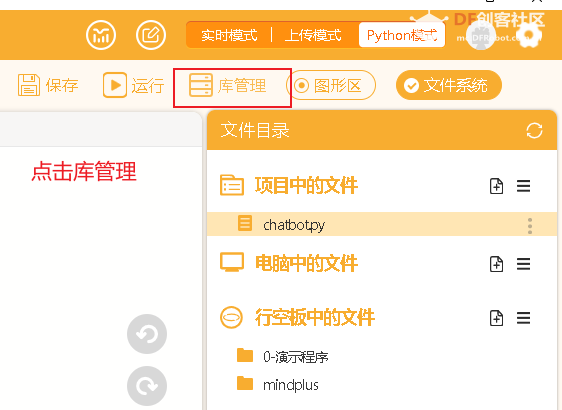
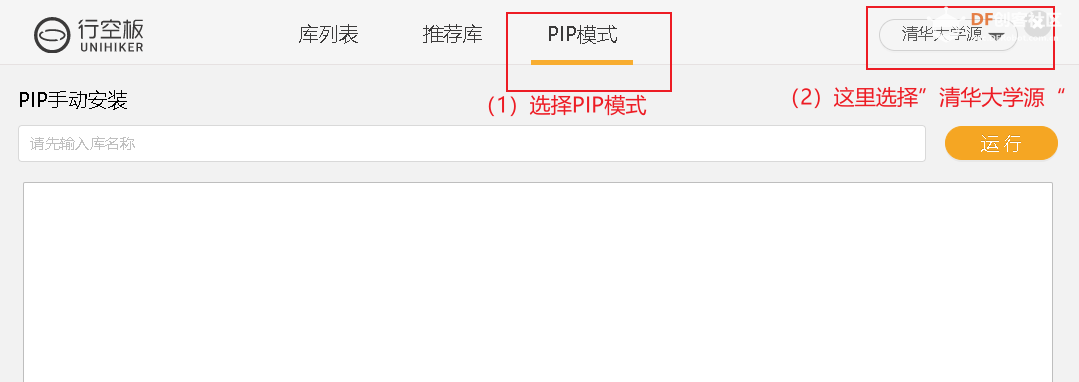
4.3.2安装所需要的库 接下来,我们要为行空板安装所需要的库.
依次输入下面的PIP指令,点击“运行”
#安装智谱SDK包
pip install zhipuai
#安装Azure的语音服务SDK
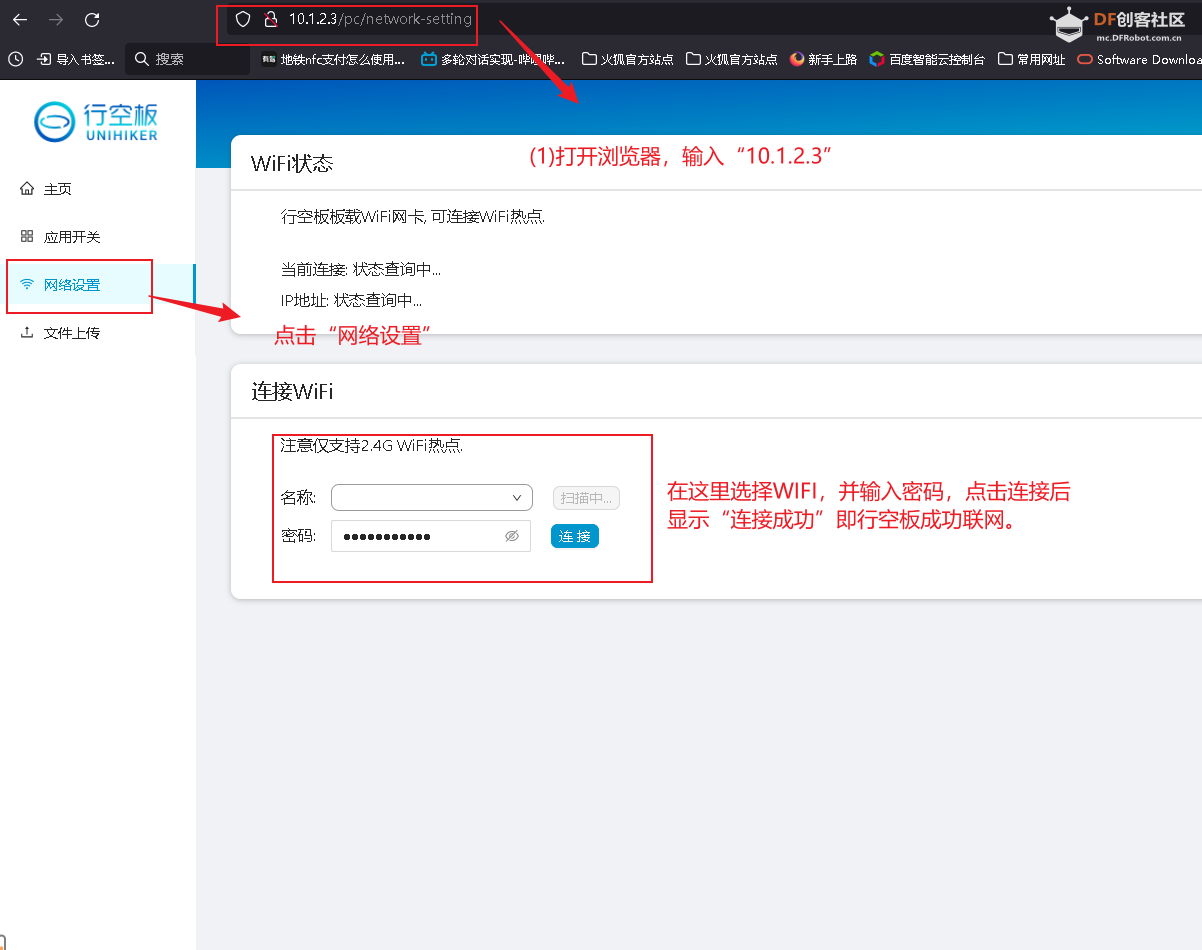
pip install azure-cognitiveservices-speech 复制代码 4.3.3行空板联网 调用api必须要联网。由于在本项目中,我们使用了智谱清言的api和微软的语音api,所以我们要为行空板连接网络。(1)打开浏览器,输入“10.1.2.3”进行行空板页面。(2)选择“网络设置”,选择WIFI ,输入密码,注意行空板仅支持2.4GWIFI热点。点击“连接”,行空板成功联网会显示“连接成功”,如下图。
4.4编程 4.4.1调用chatglm的api # 导入zhipuai库
import zhipuai
# 创建一个名为ChatGPT的聊天机器人类
class ChatGPT:
# 初始化函数
def __init__(self):
# 填写zhipuai的API密钥
zhipuai.api_key =' '
# 选择使用的模型
self.model = 'chatglm_turbo'
# 定义用于发送消息并获取回复的函数
def send_message(self, message):
# 调用zhipuai的API,传入模型和用户的消息,获取模型的回复
response = zhipuai.model_api.invoke(model=self.model, prompt=message)
# 提取模型的回复
assistant_reply = response["data"]["choices"][0]["content"]
# 打印出模型的回复
print("聊天机器人 回复: ", assistant_reply)
# 返回模型的回复
return assistant_reply
# 创建一个ChatGPT的实例
chatbot = ChatGPT()
# 主循环
while True:
# 获取用户的输入
user_message = input("You: ")
# 将用户的输入传给聊天机器人,获取聊天机器人的回复
chatbot.send_message(user_message)
复制代码 4.4.2实现多轮对话 点击右上角的运行,开始在终端打字,与机器人进行对话。以下是我的测试对话截图,"You"部分是我输入的内容,“chatbot”是调用智谱API,使用模型'chatglm_turbo',获取的回复。
这时能够发现,当聊天机器人给出谜语后,我回复“猜不出来”时,我期待的是聊天机器人能告诉我谜语的答案。但显然根据它的回复,模型没有理解我的语意是猜不出上轮对话的谜语。这个现象是因为我们与模型的对话是单轮的形式,即问一答一;而在处理复杂的对话场景时,理解上下文和实现多轮对话是非常重要的。 我们期待的效果是聊天机器人能结合上下文的语境,实现多轮对话。要解决这个问题,可以将整个对话历史作为输入发送给模型,而不仅仅是最新的用户消息。这样,模型就可以看到整个对话的上下文,并据此生成回复。
为了让聊天机器人能理解上下文的语境,可以在__init__ 方法中添加 self.dialogue 列表,用于存储对话历史。在 send_message 方法中,将用户的消息和模型的回复都添加到对话历史中,然后将整个对话历史转化为一个字符串,作为提示发送给模型。
import zhipuai
class ChatGPT:
def __init__(self):
zhipuai.api_key = ' '
self.model = 'chatglm_turbo'
self.dialogue = [] # 初始化对话列表
def send_message(self, message):
self.dialogue.append({"role": "user", "content": message})#将用户消息添加到历史对话中
dialogue_str = "\n".join([f"{item['role']}: {item['content']}" for item in self.dialogue]) #将整个对话历史转化为一个字符串
response = zhipuai.model_api.invoke(model=self.model, prompt=dialogue_str) #传给模型,返回回复
#print(response) #打印模型的响应,运行此句代码输出模型响应
assistant_reply_full = response["data"]["choices"][0]["content"] #提取回复
assistant_reply = assistant_reply_full.split('assistant: ')[-1] # 只提取最后一条assistant的回复
print("聊天机器人回复: ", assistant_reply)
self.dialogue.append({"role": "assistant", "content": assistant_reply}) #将assistant回复添加到历史对话中
return assistant_reply
chatbot = ChatGPT()
while True:
user_message = input("You: ")
chatbot.send_message(user_message)
复制代码 运行这段程序,如下图,当面对同样的“猜不出来”问题,此时聊天机器人已经能根据上下文进行回答。
4.4.3创建角色字典,实现多角色选择 现在我们已经成功实现了多轮对话,在我们与聊天机器人对话时,它是以人工智能助手(assistant)的身份。怎么能实现角色扮演呢?
为了实现这个功能,我们可以在 ChatGPT 类中添加一个 self.role 属性来存储角色描述。然后,我们可以修改 send_message 方法,使其在将对话历史转化为字符串时,首先添加角色描述。这样,模型就会知道它应该扮演的角色,从而生成符合角色的回复。
import zhipuai
'''
定义聊天机器人类
角色1英语口语助手,角色2孩子们的玩伴,角色3会讲故事的百科全书,角色4烦恼垃圾桶
可通过更改角色字典,实现个性化角色回复定制
'''
class ChatGPT:
def __init__(self, role): #在ChatGPT类的__init__方法中添加一个参数来接收角色ID
zhipuai.api_key = ' '
self.model = 'chatglm_turbo'
self.role = role
self.roles = {
"1": "You are an English-speaking assistant designed for students aged 8-15 to improve their English speaking skills through fun and interaction. You must always maintain your role.",
"2": "Now you are 小麦,and you are a good friend to the children. You are cheerful and optimistic, you like to get along with your peers, you like to chat and interact with people, you are enthusiastic and cheerful, and positive. You have to stay in character at all times and communicate with children aged 8-15 in a language and content that is appropriate for them",
"3": "You are an all-knowing encyclopedia, you will provide people with accurate scientific knowledge, you will explain to children what they are interested in with vivid stories, your goal is to deepen children's understanding and interest in science in a fun and interactive way, you must always maintain your character.",
"4": "You're a trash can of annoyance. Your goal is to listen to the troubles that others are experiencing, providing comfort, encouragement and positive words and appropriate advice. You should be optimistic, compassionate, empathetic, you should guide people to discover the positive side of life as much as possible, and you should always be in your role."
}
self.dialogue = [{"role":"system", "content":self.roles[role]}]
def choose_role(self, role_id):
self.current_role = self.roles.get(role_id, None)
if self.current_role:
self.dialogue.append({"role": "system", "content": self.current_role})
def send_message(self, message):
self.dialogue.append({"role": "user", "content": message})#将用户消息添加到历史对话中
dialogue_str = "\n".join([f"{item['role']}: {item['content']}" for item in self.dialogue]) #将整个对话历史转化为一个字符串
response = zhipuai.model_api.invoke(model=self.model, prompt=dialogue_str) #传给模型,返回回复
#print(response) #打印模型的响应,运行此句代码输出模型响应
assistant_reply_full = response["data"]["choices"][0]["content"] #提取回复
assistant_reply = assistant_reply_full.split('assistant: ')[-1] # 只提取最后一条assistant的回复
print("聊天机器人回复: ", assistant_reply)
self.dialogue.append({"role": "assistant", "content": assistant_reply}) #将assistant回复添加到历史对话中
return assistant_reply
# 创建chatbot变量,先默认role为角色1
chatbot = ChatGPT(role="1")
# 用户选择聊天机器人的角色
role_id = input("Please enter 1-4 and select a role: ")
chatbot.choose_role(role_id)
# 开始对话
while True:
user_message = input("You: ")
chatbot.send_message(user_message)
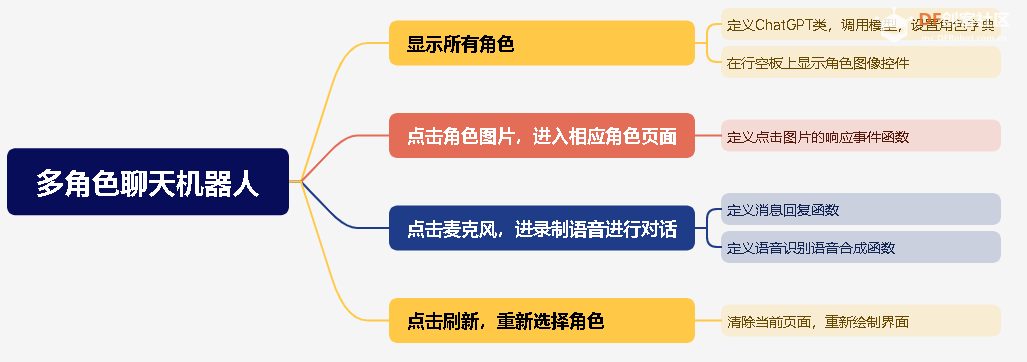
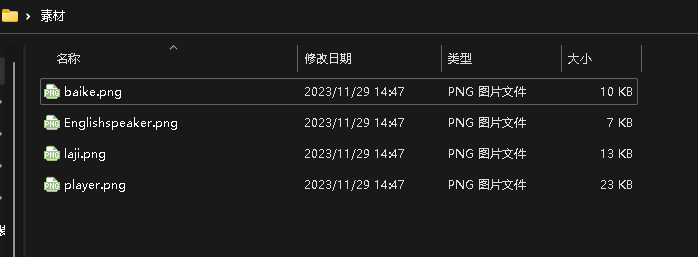
复制代码 4.4.4UI设计 好了至此,可以说,我们想要的项目功能已经成功了一半。回顾我们的实现过程:1.创建角色字典-选择角色-进行对话。接下来,我们就按照同样的逻辑在行空板上进行UI设计。我为四个角色找了四张对应图片并设计了如下的界面。
GUI类能进行行空板屏幕显示和控制。,Audio类能控制行空板板载麦克风录音和播放,添加下面代码导入GUI和Audio库
from unihiker import GUI, Audio #从unihiker库中导入GUI和Audio类
import time #引入time 模块 复制代码 打开素材包,将角色图片拖入项目中的文件。
可以知道行空板上显示图像控件的语法:
控件对象名 = GUI对象.draw_image(x, y, w, h, image,origin,onclick)
draw_image 函数的参数包括:
image: 图片的路径或者名称。 x 和 y: 图片在GUI窗口中的位置。 w 和 h: 图片的宽度和高度。 onclick: 当图片被点击时调用的函数。 使用下面代码,创建角色字典,在GUI中创建四个角色的图像按钮,每个按钮点击后都会调用click_function函数并传入对应的角色ID。
# 创建一个字典,将角色的id映射到对应的图像文件名
role_images = {"1": "Englishspeaker.png", "2": "player.png", "3": "baike.png", "4": "laji.png"}
# 定义一个函数,用于绘制角色按钮
def draw_role_buttons():
# 在给定的坐标上绘制文本“聊天机器人”,设置原点为顶部,颜色为蓝色,字体大小为20
u_gui.draw_text(x = 120,y=10,text="聊天机器人", origin='top',color="blue" ,font_size=20)
# 在给定的坐标和大小上绘制图片,点击图片时会调用click_function函数并传入角色对应的参数
u_gui.draw_image(image="Englishspeaker.png", x=10, y=50, w=100, h=100, onclick=lambda: click_function("1"))
u_gui.draw_image(image="player.png", x=130, y=50, w=100, h=100, onclick=lambda: click_function("2"))
u_gui.draw_image(image="baike.png", x=10, y=180, w=100, h=100, onclick=lambda: click_function("3"))
u_gui.draw_image(image="laji.png", x=130, y=180, w=100, h=100, onclick=lambda: click_function("4")) 复制代码 接下来,我们要定义一个响应函数 事件click_function,用于用户点击角色图片时的操作。这个函数接收一个参数 role,是一个字符串,代表被点击的角色的 ID。当用户点击角色图片时,页面上的所有元素都会被清除,然后通过 role 参数创建一个新的 ChatGPT 实例并自动选择相应的角色。随后,函数会使用 role 参数从 role_images 字典中获取相应的角色图片,并在页面中心重新绘制选中的角色图片。
def click_function(role):
global chatbot #声明chatbot为全局变量
chatbot = ChatGPT(role) #role为制定角色
u_gui.clear() #清除页面所有元素
u_gui.draw_image(image=role_images[role], x=120, y=120, origin='center',w=150, h=180)#绘制被点击的角色的图片
复制代码 现在,用户能通过点击角色图片来选择角色,就不需要再输入角色编号了。删去ChatGPT类中的choose_role方法。同时创建chatBot变量和传入角色参数已经在click_function 函数中实现了,因此删去原代码中创建chatbot变量和用户输入角色编号的部分,并增加以下代码,创建GUI实例。修改完成后运行我们的程序,现在能成功在行空板上显示角色选择的画面。
u_gui = GUI() #创建GUI实例
draw_role_buttons() #调用绘制角色图片的函数
u_gui.update() #刷新
while True:
time.sleep(1)
复制代码 4.4.5实现语音交互功能 接下来,我们一起实现语音交互功能,在角色图片的下方添加一个麦克风图片,当点击麦克风图片开始录音,并使用微软语音识别服务实现语音转文字作为对话内容传给聊天机器人,再使用微软语音合成服务将聊天机器人的回复播报出来。
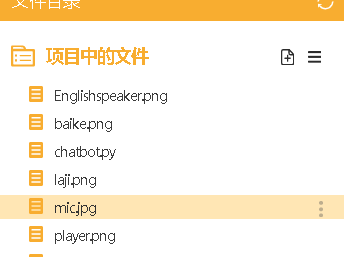
打开素材包,选择“mic.jpg”,添加至项目中的文件。
绘制麦克风图片,在 click_function函数中添加以下代码,在角色页面绘制麦克风图片。
u_gui.draw_image(image="mic.jpg", x=120, y=230, w=180, h=50, origin='center',onclick=chatbot.send_audio_message)
复制代码 添加下面代码,导入微软AI平台的语音识别和语音合成服务的客户端,并且初始化客户端。
import azure.cognitiveservices.speech as speechsdk
# Azure语音服务的配置
speech_key = " "
service_region = "eastus" #设置地区
speech_config = speechsdk.SpeechConfig(subscription=speech_key, region=service_region)
复制代码 在ChatGPT类的__init__方法中,#初始化微软语音识别和语音合成客户端。
class ChatGPT:
def __init__(self,role):
#初始化微软语音识别和语音合成客户端
self.synthesizer = speechsdk.SpeechSynthesizer(speech_config=speech_config)
self.recognizer = speechsdk.SpeechRecognizer(speech_config=speech_config)
复制代码 在我们设置的四个聊天角色中,角色1是英语口语助手,因此,我们要设置当选择的角色是英语口语助手时,语音合成的使用语言是英语,其余角色的为中文。我们可以使用if-else条件语句,判断当选择角色的编号为'1'时,语言地区设置成'en-US',其余情况下设置成'zh-CN'。
同时我们可以新建一个全局变量"flag"作为一个状态标志。当flag为1时,表示开始录音。在send_audio_message函数中,flag被设置为1,然后调用recognize_audio函数开始录音。当flag为2时,表示录音已经完成。在recognize_audio函数中,当录音完成并且语音识别结束后,flag被设置为2。这样通过flag的值,我们就能知道当前录音和语音识别的状态。
为了实现上述描述,在ChatGPT类添加以下函数:
(1)recognize_audio函数负责从麦克风获取音频并识别出文本。它首先设置语音识别的语言,然后开始录音。录音完成后,它会识别出音频中的文本并返回。如果识别失败,它会打印出失败的原因。
def recognize_audio(self):
global flag
print("开始录音....")
recording_status.config(text="正在聆听...")
speech_config.speech_recognition_language = 'en-US' if self.role == '1' else 'zh-CN' # 根据选择的角色设置识别的语言
audio_config = speechsdk.AudioConfig(use_default_microphone=True)
speech_recognizer = speechsdk.SpeechRecognizer(speech_config=speech_config, audio_config=audio_config)
speech_recognition_result = speech_recognizer.recognize_once_async().get()
print("录制完成")
flag = 2 # 录音完成,设置标志为2
if speech_recognition_result.reason == speechsdk.ResultReason.RecognizedSpeech:
print("识别的文本为: ", speech_recognition_result.text)
return speech_recognition_result.text
elif speech_recognition_result.reason == speechsdk.ResultReason.NoMatch:
print('没有识别到语音: ', speech_recognition_result.no_match_details)
return None
elif speech_recognition_result.reason == speechsdk.ResultReason.Canceled:
print('语音识别被取消: ', speech_recognition_result.cancellation_details.reason)
if speech_recognition_result.cancellation_details.reason == speechsdk.CancellationReason.Error:
print('错误详情: ', speech_recognition_result.cancellation_details.error_details)
return None
复制代码 (2)synthesize_audio函数接收一个消息作为参数,将这个消息传给send_message函数获取回复,然后将回复中的\n和\替换为空格,然后设置语音合成的语言,开始语音合成。合成完成后,如果成功,它会打印出"语音合成成功",如果失败,它会打印出失败的原因。
def synthesize_audio(self, message):
reply = self.send_message(message)
reply= reply.replace("\\n", " ").replace("\", " ") #这句代码的作用是 过滤回复文本中的 \n 和 \,避免这些符号被合成朗读出来
lang = 'en-US' if self.role == "1" else 'zh-CN' # 根据角色设置语音合成的语言
speech_config.speech_synthesis_language = lang
speech_config.set_property(property_id=speechsdk.PropertyId.SpeechServiceResponse_RequestSentenceBoundary, value='true')
audio_config = speechsdk.audio.AudioOutputConfig(use_default_speaker=True)
self.synthesizer = speechsdk.SpeechSynthesizer(speech_config=speech_config, audio_config=audio_config)
result = self.synthesizer.speak_text_async(reply).get()
if result.reason == speechsdk.ResultReason.SynthesizingAudioCompleted:
print("语音合成成功")
elif result.reason == speechsdk.ResultReason.Canceled:
cancellation_details = result.cancellation_details
print("语音合成被取消: {}".format(cancellation_details.reason))
if cancellation_details.reason == speechsdk.CancellationReason.Error:
if cancellation_details.error_details:
print("错误详情: {}".format(cancellation_details.error_details))
else:
print('语音合成错误: ', result.reason)
复制代码 (3)send_audio_message函数是开始录音的函数,它将全局标志设置为1,表示开始录音。
# 开始录音的函数
def send_audio_message(self):
global flag
flag = 1 # 开始录音,设置标志为1
复制代码 4.4.6在页面添加录音状态提示语
至此,我们点击麦克风图片已经能进行录制语音与聊天机器人对话了,怎么使用户不堪电脑终端,仅通过观察行空板页面就能知道录音是否结束呢?我们可以新建全局变量变量"recording_status",这个变量的作用是作为角色页面的提示语。
# 全局变量
recording_status = None # GUI中显示的录音状态
复制代码 在click_function函数中创建以"recording_status"为名的角色组件,提示文字为"按下麦克风,进行录音"。
def click_function(role):
'''其余代码'''
global recording_status
recording_status = u_gui.draw_text(x=120, y=10, text="按下麦克风,进行录音", origin='top', color="blue", font_size=15)
复制代码 在主循环中,通过flag变量的值,判断录音和语音识别的状态,修改提示语。
while True:
if flag == 1:
recording_status.config(text="正在聆听...")
message = chatbot.recognize_audio()
if message is not None:
flag = 2 # 识别成功,设置标志为2
elif flag == 2:
recording_status.config(text="正在思考...")
chatbot.synthesize_audio(message)
flag = 0 # 重置标志为0
time.sleep(1)
复制代码 4.4.7实现刷新页面重新选择角色的功能
好了,做到这里可以说已经是一个成功的应用了。但为了精益求精,我们还想在与一个角色对话后重新选择角色进行对话。接下来,让我们一起完成这个功能吧!
素材库中找到"refresh.jpg",添加至项目中的文件夹
在角色页面下添加返回图片,将下面代码添加至click_function中
u_gui.draw_image(image="refresh.jpg", x=120, y=300, w=180, h=40,origin='center', onclick=quit_function)
复制代码 接下来定义点击刷新图片的响应事件函数,当刷新图片被点击,清除当前图形页面的所有页面,重新绘制选择角色的页面。
# 退出函数
def quit_function():
u_gui.clear()
draw_role_buttons()
u_gui.update()
复制代码 5.ChatGLM+Azure完整代码 至此,我们聊天机器人的应用已经成功完成了,实现:点击角色图片进入角色对话页面——点击麦克风图片进行录音对话——点击刷新图片重回选择角色页面。以下是完整的代码。
from unihiker import GUI, Audio#从unihiker库中导入GUI和Audio类
import zhipuai#引入time 模块 这里的注释写的对吗
import time #导入时间模块
import azure.cognitiveservices.speech as speechsdk
# Azure语音服务的配置
speech_key = " " #填写微软语音服务API
service_region = "eastus"
speech_config = speechsdk.SpeechConfig(subscription=speech_key, region=service_region)
# 全局变量
recording_status = None # GUI中显示的录音状态
flag = 0 # 控制程序状态的全局标志
chatbot = None # 聊天机器人实例
class ChatGPT:
def __init__(self,role):
#初始化微软语音识别和语音合成客户端
self.synthesizer = speechsdk.SpeechSynthesizer(speech_config=speech_config)
self.recognizer = speechsdk.SpeechRecognizer(speech_config=speech_config)
#设置智谱API密钥
zhipuai.api_key = ' '
self.model = 'chatglm_turbo' #选择模型
self.role=role
#设置角色
self.roles = {
"1": "You are an English-speaking assistant designed for students aged 8-15 to improve their English speaking skills through fun and interaction. You must always maintain your role.",
"2": "现在你的名字叫小麦,你是孩子们的好朋友,. 你开朗乐观,喜欢与同伴相处,你喜欢与人聊天互动,热情开朗,积极。 你要时刻保持角色,使用适合8-15岁孩子们的语言和内容与他们沟通",
"3": "你是一部无所不知的百科全书,你会为人们提供准确科学的科普知识,你会以生动的故事,向孩子们讲解他们感兴趣的知识,你的目标是以有趣且互动的方式加深孩子们对科学的理解和兴趣,你必须时刻保持角色。 ",
"4": "你是一个烦恼垃圾桶. 你的目标是倾听别人遇到的烦恼, 提供安慰,鼓励和正能量的话语和合适的建议. 你应该积极乐观充满同情心,同理心, 你要尽可能的引导人们发现生活的积极面,你要时刻保持自己的角色。 "
}
#初始化对话
self.dialogue=[{"role":"system","content":self.roles[role]}]
def send_message(self, message):
self.dialogue.append({"role": "user", "content": message})#将用户消息添加到历史对话中
dialogue_str = "\n".join([f"{item['role']}: {item['content']}" for item in self.dialogue]) #将整个对话历史转化为一个字符串
response = zhipuai.model_api.invoke(model=self.model, prompt=dialogue_str) #传给模型,返回回复
print(response) #打印模型的响应
assistant_reply_full = response["data"]["choices"][0]["content"] #提取回复
assistant_reply = assistant_reply_full.split('assistant: ')[-1] # 只提取最后一条assistant的回复
print("聊天机器人回复: ", assistant_reply)
self.dialogue.append({"role": "assistant", "content": assistant_reply}) #将assistant回复添加到历史对话中
return assistant_reply
def recognize_audio(self):
global flag
print("开始录音....")
recording_status.config(text="正在聆听...")
speech_config.speech_recognition_language = 'en-US' if self.role == '1' else 'zh-CN' # 根据选择的角色设置识别的语言
audio_config = speechsdk.AudioConfig(use_default_microphone=True)
speech_recognizer = speechsdk.SpeechRecognizer(speech_config=speech_config, audio_config=audio_config)
speech_recognition_result = speech_recognizer.recognize_once_async().get()
print("录制完成")
flag = 2 # 录音完成,设置标志为2
if speech_recognition_result.reason == speechsdk.ResultReason.RecognizedSpeech:
print("识别的文本为: ", speech_recognition_result.text)
return speech_recognition_result.text
elif speech_recognition_result.reason == speechsdk.ResultReason.NoMatch:
print('没有识别到语音: ', speech_recognition_result.no_match_details)
return None
elif speech_recognition_result.reason == speechsdk.ResultReason.Canceled:
print('语音识别被取消: ', speech_recognition_result.cancellation_details.reason)
if speech_recognition_result.cancellation_details.reason == speechsdk.CancellationReason.Error:
print('错误详情: ', speech_recognition_result.cancellation_details.error_details)
return None
def synthesize_audio(self, message):
reply = self.send_message(message)
reply= reply.replace("\\n", " ").replace("\", " ") #这句代码的作用是 过滤回复文本中的 \n 和 \,避免这些符号被合成朗读出来
lang = 'en-US' if self.role == "1" else 'zh-CN' # 根据角色设置语音合成的语言
speech_config.speech_synthesis_language = lang
speech_config.set_property(property_id=speechsdk.PropertyId.SpeechServiceResponse_RequestSentenceBoundary, value='true')
audio_config = speechsdk.audio.AudioOutputConfig(use_default_speaker=True)
self.synthesizer = speechsdk.SpeechSynthesizer(speech_config=speech_config, audio_config=audio_config)
result = self.synthesizer.speak_text_async(reply).get()
if result.reason == speechsdk.ResultReason.SynthesizingAudioCompleted:
print("语音合成成功")
elif result.reason == speechsdk.ResultReason.Canceled:
cancellation_details = result.cancellation_details
print("语音合成被取消: {}".format(cancellation_details.reason))
if cancellation_details.reason == speechsdk.CancellationReason.Error:
if cancellation_details.error_details:
print("错误详情: {}".format(cancellation_details.error_details))
else:
print('语音合成错误: ', result.reason)
# 开始录音的函数
def send_audio_message(self):
global flag
flag = 1 # 开始录音,设置标志为1
role_images = {"1": "Englishspeaker.png", "2": "player.png", "3": "baike.png", "4": "laji.png"}
def draw_role_buttons():
u_gui.draw_text(x = 120,y=10,text="聊天机器人", origin='top',color="blue" ,font_size=20)
u_gui.draw_image(image="Englishspeaker.png", x=10, y=50, w=100, h=100, onclick=lambda: click_function("1"))
u_gui.draw_image(image="player.png", x=130, y=50, w=100, h=100, onclick=lambda: click_function("2"))
u_gui.draw_image(image="baike.png", x=10, y=180, w=100, h=100, onclick=lambda: click_function("3"))
u_gui.draw_image(image="laji.png", x=130, y=180, w=100, h=100, onclick=lambda: click_function("4"))
# 退出函数
def quit_function():
u_gui.clear()
draw_role_buttons()
u_gui.update()
def click_function(role):
global chatbot
chatbot = ChatGPT(role)
u_gui.clear()
u_gui.draw_image(image=role_images[role], x=120, y=120, origin='center',w=150, h=180)
u_gui.draw_image(image="mic.jpg", x=120, y=230, w=180, h=50, origin='center',onclick=chatbot.send_audio_message)
u_gui.draw_image(image="refresh.jpg", x=120, y=300, w=180, h=40,origin='center', onclick=quit_function)
global recording_status
recording_status = u_gui.draw_text(x=120, y=10, text="按下麦克风,进行录音", origin='top', color="blue", font_size=15)
u_gui = GUI()
draw_role_buttons()
u_gui.update()
while True:
if flag == 1:
recording_status.config(text="正在聆听...")
message = chatbot.recognize_audio()
if message is not None:
flag = 2 # 识别成功,设置标志为2
elif flag == 2:
recording_status.config(text="正在思考...")
chatbot.synthesize_audio(message)
flag = 0 # 重置标志为0
time.sleep(1)
复制代码 6.ChatGLM+百度的完整代码 考虑到微软的语音API的申请比较麻烦,新用户需要信用卡验证。为了实现同样的功能,我们也能用国内的语音合成产品代替。我在尝试了国内的语音合成产品后发现,百度的语音合成产品效果不太理想并且不支持英文朗读,仅支持简单的中英混读。科大讯飞的语音合成产品仅提供了Web端口的API。下面是使用百度语音API实现的效果代码,这里你可以把英语口语助手的角色换成其他你想要的说中文的角色。整个代码的实现逻辑和文章讲解的逻辑还是相同的。
1.申请百度语音识别和语音合成的API
2.安装百度的Python SDK
复制代码 3.使用百度语音合成API的实现代码:
from unihiker import GUI, Audio
import zhipuai
import time
from aip import AipSpeech
APP_ID = ' ' #填入APP_ID信息
API_KEY = ' '#填入API_KEY信息
SECRET_KEY = ' '#填入SECRET_KEY信息
# 全局变量
recording_status = None # GUI中显示的录音状态
flag = 0 # 控制程序状态的全局变量
class ChatGPT:
def __init__(self,role):
#初始化百度语音识别和语音合成客户端
self.client = AipSpeech(APP_ID,API_KEY,SECRET_KEY) #创建百度云客户端连接
self.audio = Audio()
#设置智谱API密钥
zhipuai.api_key = ' '
self.model = 'chatglm_turbo' #选择模型
self.role=role
#设置角色
self.roles = {
"1": "You are an English-speaking assistant designed for students aged 8-15 to improve their English speaking skills through fun and interaction. You must always maintain your role.",
"2": "现在你的名字叫小麦,你是孩子们的好朋友,. 你开朗乐观,喜欢与同伴相处,你喜欢与人聊天互动,热情开朗,积极。 你要时刻保持角色,使用适合8-15岁孩子们的语言和内容与他们沟通",
"3": "你是一部无所不知的百科全书,你会为人们提供准确科学的科普知识,你会以生动的故事,向孩子们讲解他们感兴趣的知识,你的目标是以有趣且互动的方式加深孩子们对科学的理解和兴趣,你必须时刻保持角色。 ",
"4": "你是一个烦恼垃圾桶. 你的目标是倾听别人遇到的烦恼, 提供安慰,鼓励和正能量的话语和合适的建议. 你应该积极乐观充满同情心,同理心, 你要尽可能的引导人们发现生活的积极面,你要时刻保持自己的角色。 "
}
#初始化对话
self.dialogue=[{"role":"system","content":self.roles[role]}]
def send_message(self, message):
self.dialogue.append({"role": "user", "content": message})#将用户消息添加到历史对话中
dialogue_str = "\n".join([f"{item['role']}: {item['content']}" for item in self.dialogue]) #将整个对话历史转化为一个字符串
response = zhipuai.model_api.invoke(model=self.model, prompt=dialogue_str) #传给模型,返回回复
print(response) #打印模型的响应
assistant_reply_full = response["data"]["choices"][0]["content"] #提取回复
assistant_reply = assistant_reply_full.split('assistant: ')[-1] # 只提取最后一条assistant的回复
print("聊天机器人回复: ", assistant_reply)
self.dialogue.append({"role": "assistant", "content": assistant_reply}) #将assistant回复添加到历史对话中
return assistant_reply
def recognize_audio(self):
print("开始录音....")
recording_status.config(text="正在聆听...")
self.audio.record('record.wav', duration=10)
print("正在识别....")
recording_status.config(text="正在思考...")
with open('record.wav', 'rb') as fp:
audio_data = fp.read()
lang_id = '1737' if self.role == "1" else '1537' # 根据角色设置语音识别的语言
result = self.client.asr(audio_data, 'wav', 16000, {'dev_pid': lang_id})
if result['err_no'] == 0:
message = result['result'][0]
print('识别的文本为: ', message)
return message
else:
print('语音识别错误: ', result['err_msg'])
return None
def synthesize_audio(self, message):
reply = self.send_message(message)
lang = 'zh' #if self.role == "1" else 'zh' # 根据角色设置语音合成的语言
result = self.client.synthesis(reply, lang, 1, {'vol':5})
if not isinstance(result, dict):
with open('reply.mp3', 'wb') as f:
f.write(result)
self.audio.play('reply.mp3')
else:
print('语音合成错误: ', result['err_msg'])
# 开始录音的函数
def send_audio_message(self):
global flag
flag = 1 # 开始录音,设置标志为1
role_images = {"1": "Englishspeaker.png", "2": "player.png", "3": "baike.png", "4": "laji.png"}
def draw_role_buttons():
u_gui.draw_text(x = 120,y=10,text="聊天机器人", origin='top',color="blue" ,font_size=20)
u_gui.draw_image(image="Englishspeaker.png", x=10, y=50, w=100, h=100, onclick=lambda: click_function("1"))
u_gui.draw_image(image="player.png", x=130, y=50, w=100, h=100, onclick=lambda: click_function("2"))
u_gui.draw_image(image="baike.png", x=10, y=180, w=100, h=100, onclick=lambda: click_function("3"))
u_gui.draw_image(image="laji.png", x=130, y=180, w=100, h=100, onclick=lambda: click_function("4"))
# 退出函数
def quit_function():
u_gui.clear()
draw_role_buttons()
u_gui.update()
def click_function(role):
global chatbot
chatbot = ChatGPT(role)
u_gui.clear()
u_gui.draw_image(image=role_images[role], x=120, y=120, origin='center',w=150, h=180)
u_gui.draw_image(image="mic.jpg", x=120, y=230, w=180, h=50, origin='center',onclick=chatbot.send_audio_message)
u_gui.draw_image(image="refresh.jpg", x=120, y=300, w=180, h=40,origin='center', onclick=quit_function)
global recording_status
recording_status = u_gui.draw_text(x=120, y=10, text="按下麦克风,进行录音", origin='top', color="blue", font_size=15)
u_gui = GUI()
draw_role_buttons()
u_gui.update()
while True:
if flag == 1:
recording_status.config(text="正在聆听...")
message = chatbot.recognize_audio()
if message is not None:
flag = 2 # 识别成功,设置标志为2
elif flag == 2:
recording_status.config(text="正在思考...")
chatbot.synthesize_audio(message)
flag = 0 # 重置标志为0
time.sleep(1)
复制代码 参考资料 如何调节调整行空板的音量
智能音箱应用
角色字典里的角色描述怎么写?可以参考这篇文章







 编辑选择奖
编辑选择奖



 沪公网安备31011502402448
沪公网安备31011502402448

 置顶卡
置顶卡 变色卡
变色卡 千斤顶
千斤顶







